鏈表
- 鏈表
- 鏈表和陣列的優缺點
- 鏈表與函式指標
- 鏈表的分類
- 結構體套結構體
- 靜態鏈表的使用
- 創建并遍歷三個結點的靜態鏈表
- 動態鏈表
- 帶有頭結點的單向鏈表
- 1、建立帶有頭結點的單向鏈表
- 2、在單向鏈表中插入結點
- 3、在單向鏈表中洗掉結點
- 4、清空鏈表,釋放所有結點
- 5、在單向鏈表中洗掉值為x的所有結點
- 6、單向鏈表排序
- 指標函式和函式指標
- 指標函式
- 函式指標
- 方式一、先定義函式型別,再根據型別定義指標變數
- 方式二、先定義函式指標型別,再根據型別定義指標變數
- 方式三、直接定義函式指標變數
- 函式指標陣列
- 回呼函式
鏈表
鏈表和陣列的優缺點
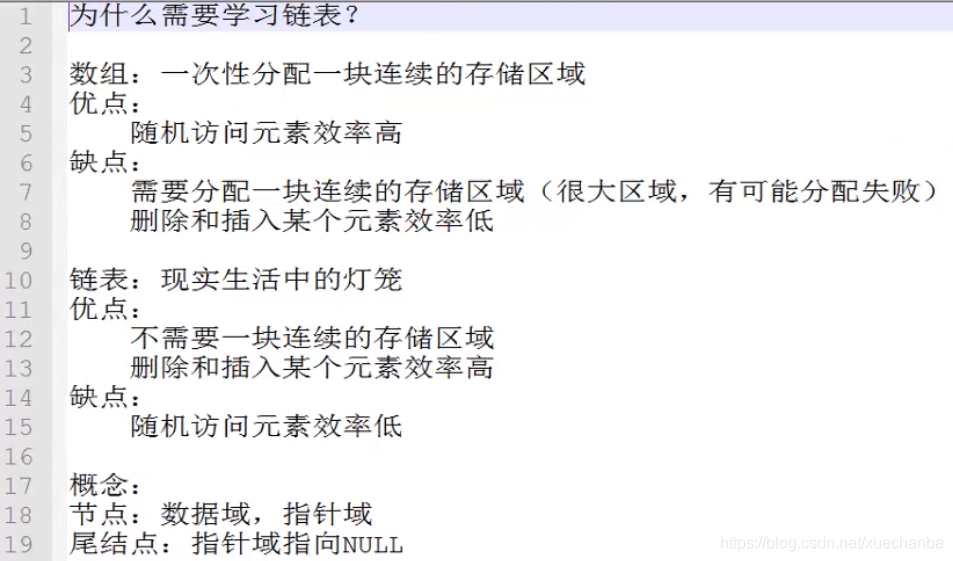
鏈表與函式指標


鏈表的分類

我們使用的都是動態鏈表,

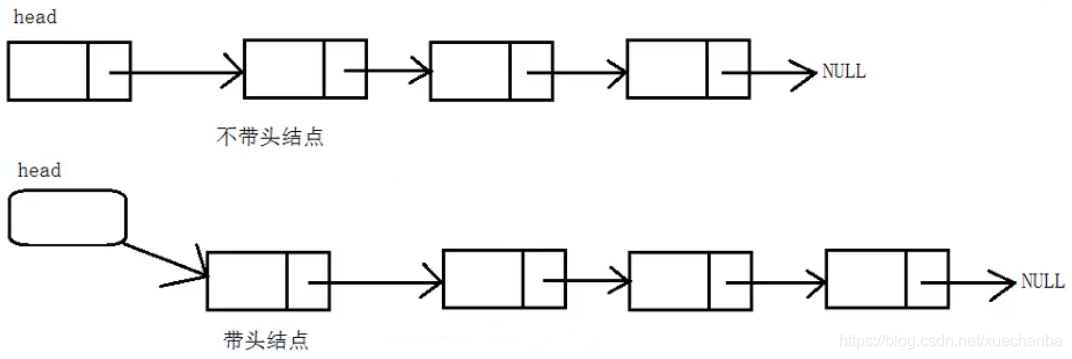
假設后面,想要從不帶頭鏈表的頭結點這邊插入一個結點,它的頭結點是可以變化的,

若想要從帶頭鏈表的頭結點這邊插入一個結點,它的頭結點是不變的,相當于是一種標志位,
不帶頭鏈表的頭結點就存放著有效資料,
而帶頭鏈表的頭結點并不存放有效資料,永遠是頭結點,第二個結點才是有效資料結點,
帶頭鏈表方便一些,我們下面學習的是帶頭結點,
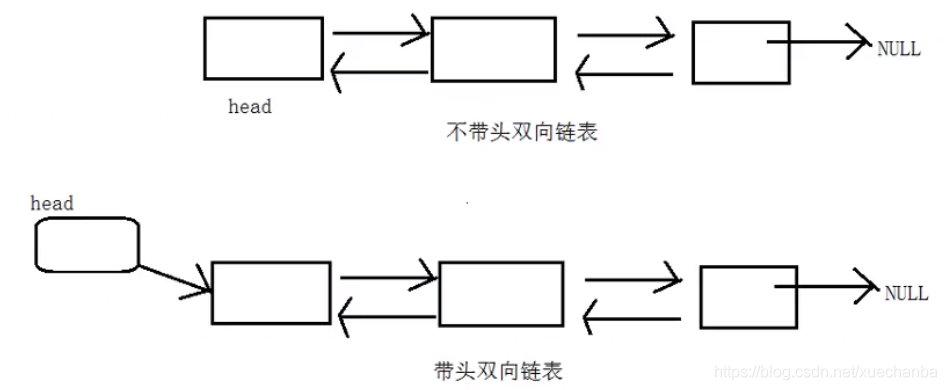
上面介紹的都是單向鏈表,下面再來畫一下雙向鏈表,
結構體套結構體
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
typedef struct A
{
int a;
char* p;
}A;
/*
* 1、結構體可以嵌套另外一個結構體的任何型別變數
*
* 2、結構體嵌套本結構體普通變數是(不可以)的,
因為本結構體的型別大小無法確定,資料型別的本質是:固定大小記憶體塊的別名,
* 3、結構體嵌套本結構體普通變數是(不可以)的,
*/
typedef struct B
{
int a;
A b; //ok
A *p; //ok
//struct B tmp; 錯誤
struct B* next;//指標型別,結構體指標變數的空間可以確定
//B* next;錯誤,因為B是在后面才定義的
}B;
int main(int argc,char *argv[])
{
printf("\n");
system("pause");
return 0;
}
靜態鏈表的使用
創建并遍歷三個結點的靜態鏈表
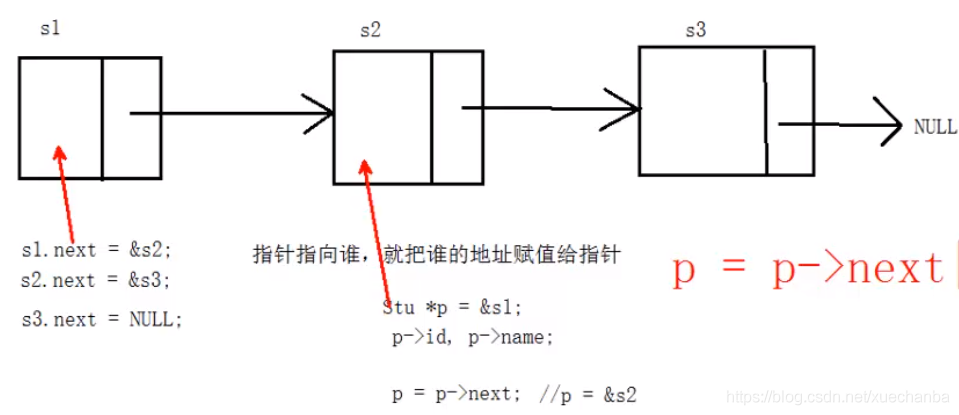
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
typedef struct STU
{
int id;//資料域
char name[10];
struct STU* next;//指標域
}STU;
int main(int argc,char *argv[])
{
//初始化三個結構體變數
STU stu1 = { 1,"one",NULL };
STU stu2 = { 2,"two",NULL };
STU stu3 = { 3,"three",NULL };
stu1.next = &stu2;//stu1的next指標指向stu2
stu2.next = &stu3;//stu2
stu3.next = NULL;//尾結點
STU* p = &stu1;
while (p != NULL)
{
printf("id = %d,name = %s.\n",p->id,p->name);
//結點移動到下一個
p = p->next;
}
printf("\n");
system("pause");
return 0;
}

動態鏈表
帶有頭結點的單向鏈表
1、建立帶有頭結點的單向鏈表

#include<stdio.h>
#include<stdlib.h>
#include<string.h>
typedef struct Node
{
int id;
struct Node* next;
}Node;
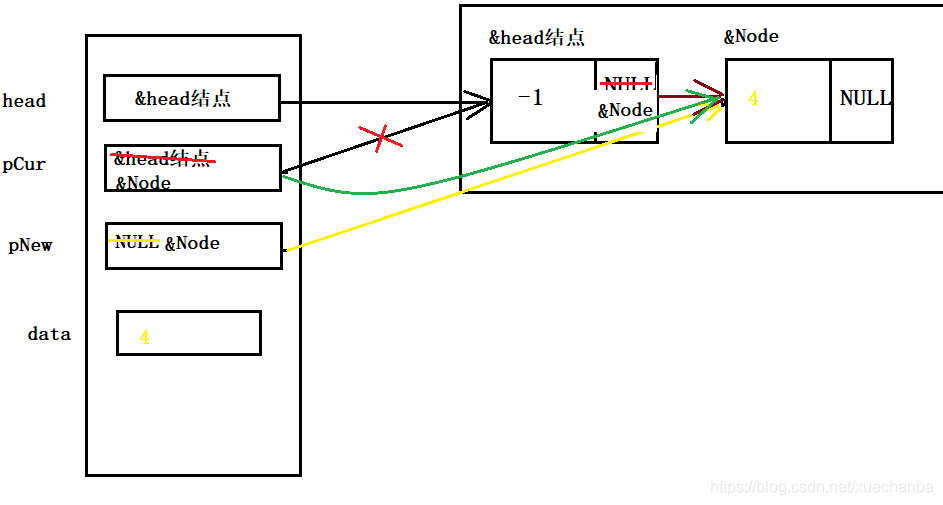
Node* SListCreat()
{
Node* head = NULL;
//頭結點作為標志,不存盤有效資料
head = (Node*)malloc(sizeof(Node));
if (head == NULL)
{
return NULL;
}
//給head的成員變數賦值
head->id = -1;
head->next = NULL;
Node* pCur = head;
Node* pNew = NULL;
int data;
while (1)
{
printf("請輸入資料,輸入-1表示退出,\n");
scanf("%d",&data);
if (data == -1)//輸入-1,退出
{
break;
}
//新結點動態分配空間
pNew = (Node*)malloc(sizeof(Node));
if (pNew == NULL)
{
continue;
}
//給pNew成員變數賦值(初始化)
pNew->id = data;
pNew->next = NULL;
//鏈表建立關系
//當前結點的next指向pNew
pCur->next = pNew;
//pNew的next指向NULL
pNew->next = NULL;
//把pCur移動到pNew,pCur指向pNew
pCur = pNew;
}
return head;
}
//鏈表的遍歷
int SListPrint(Node* head)
{
if (head == NULL)
{
return NULL;
}
//取出第一個有效結點(頭結點的next)
Node* pCur = head->next;
printf("head -> ");
while (pCur != NULL)
{
printf("%d -> ",pCur->id);
//當前結點往下移動一位,pCur指定下一個
pCur = pCur->next;
}
printf("NULL\n");
return 0;
}
void test()
{
Node* head = NULL;
head = SListCreat();//創建頭結點
SListPrint(head);
}
int main(int argc,char *argv[])
{
test();
printf("\n");
system("pause");
return 0;
}
畫圖分析:
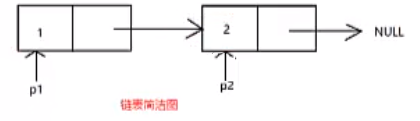
我們很多時候畫的鏈表圖都是簡潔圖,
運行:
2、在單向鏈表中插入結點
在值為x的結點前插入一個值為y的結點,若值為x的結點不存在,則插在表尾,
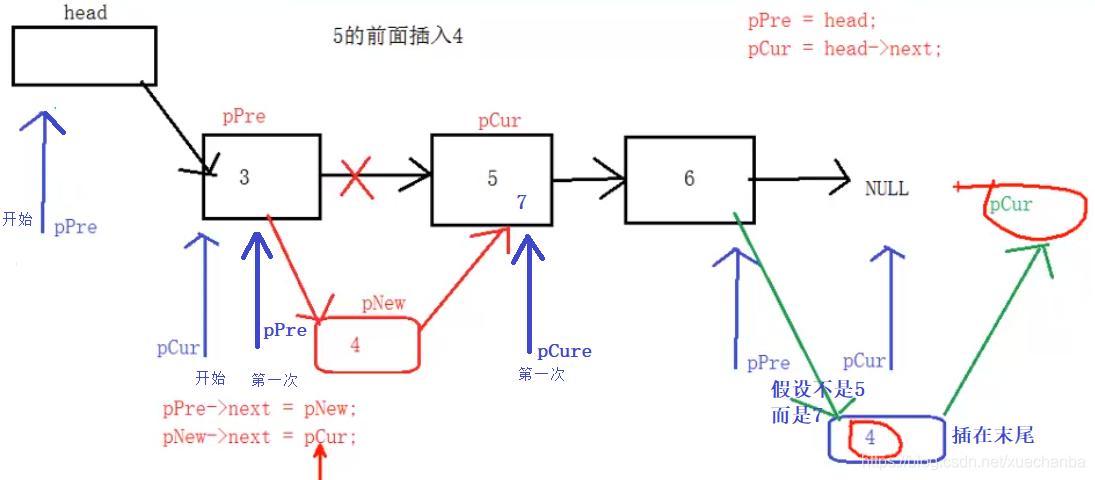
兩種情況:
1、找到匹配的結點,pCur為匹配結點,pPre為pCur的上一個結點,
2、沒有找到匹配結點,pCur為空結點,pPre為最后一個結點,
兩種情況均按下述插入:
pPre->next = pNew;
pNew->next = pCur;
插入結點函式的具體代碼如下:
//在值為x的結點前插入一個值為y的結點,若值為x的結點不存在,則插在表尾,
int SListNodeInsert(Node* head, int x, int y)
{
if (head == NULL)
{
return NULL;
}
Node* pNew = NULL;
//新結點動態分配空間
pNew = (Node*)malloc(sizeof(Node));
if (pNew == NULL)
{
return NULL;
}
//給pNew成員變數賦值(初始化)
pNew->id = y;
pNew->next = NULL;
//定義兩個輔助變數并設定初始值
Node* pPre = head;
Node* pCur = head->next;
while (pCur!=NULL)
{
if (pCur->id == x)
{
break;
}
pPre = pCur;
pCur = pCur->next;
}
//兩種情況
//1、找到匹配的結點,pCur為匹配結點,pPre為pCur的上一個結點,
//2、沒有找到匹配結點,pCur為空結點,pPre為最后一個結點,
//兩種情況均按下述插入
pPre->next = pNew;
pNew->next = pCur;
return 0;
}
3、在單向鏈表中洗掉結點
洗掉值為x的結點,單次呼叫洗掉第一個被遍歷到的結點,多次洗掉,需多次呼叫,
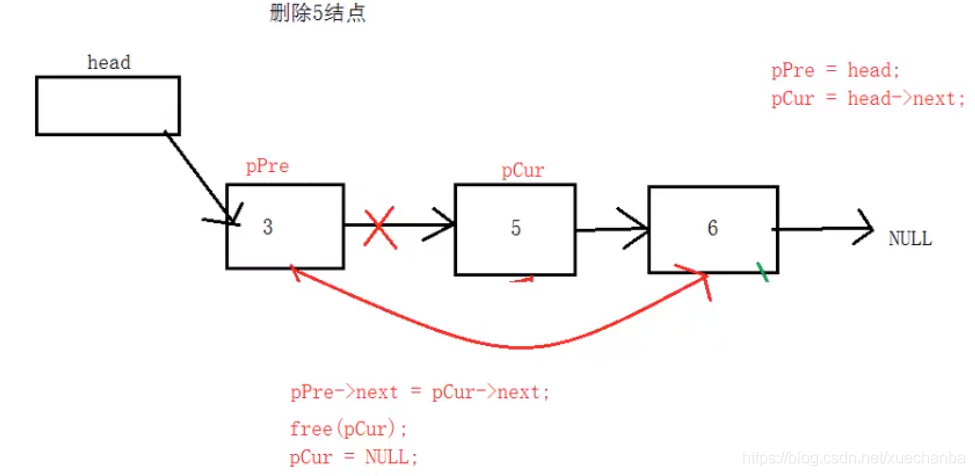
//洗掉值為x的結點,洗掉第一個被遍歷到的值
int SListNodeDel(Node* head, int x)
{
//定義兩個輔助變數并設定初始值
Node* pPre = head;
Node* pCur = head->next;
//標志位:0代表沒有找到,1代表找到了,
int flag = 0;
while (pCur != NULL)
{
if (pCur->id == x)
{
//pPre的下一個指向pCur的下一個
pPre->next = pCur->next;
free(pCur);
pCur = NULL;
flag = 1;
break;
}
pPre = pCur;
pCur = pCur->next;
}
if (!flag)
{
printf("no find.\n");
return -2;
}
return 0;
}
4、清空鏈表,釋放所有結點
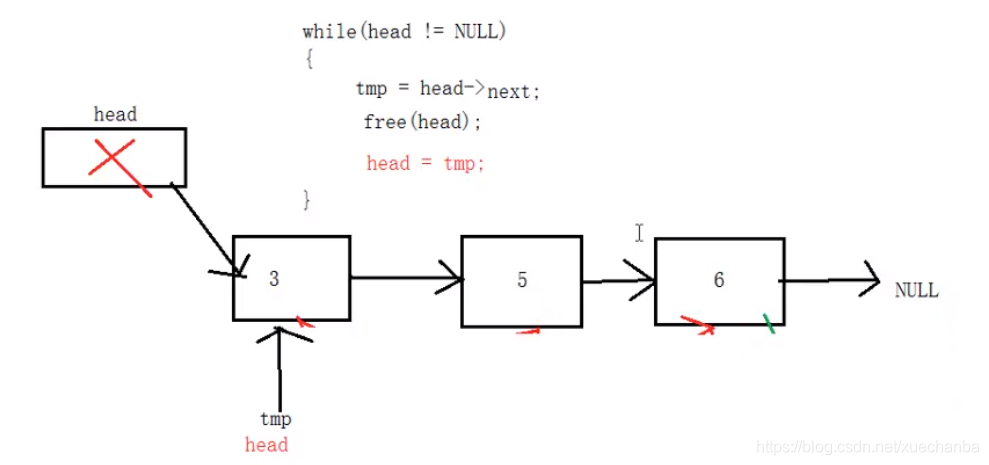
//清空鏈表,釋放所有結點
int SListDestroy(Node* head)
{
if (head == NULL)
{
return -1;
}
//定義臨時變數來保存每次的下一個結點的位置
Node* pTmp = NULL;
int i = 0;
while (head != NULL)
{
i++;
pTmp = head->next;
free(head);
head = pTmp;
}
printf("i = %d.\n",i);
return 0;
}
在測驗程式中:釋放完所有結點之后,也要將頭結點head指向NULL
void test()
{
Node* head = NULL;
head = SListCreat();//創建頭結點
SListPrint(head);
SListDestroy(head);
head = NULL;
}
5、在單向鏈表中洗掉值為x的所有結點
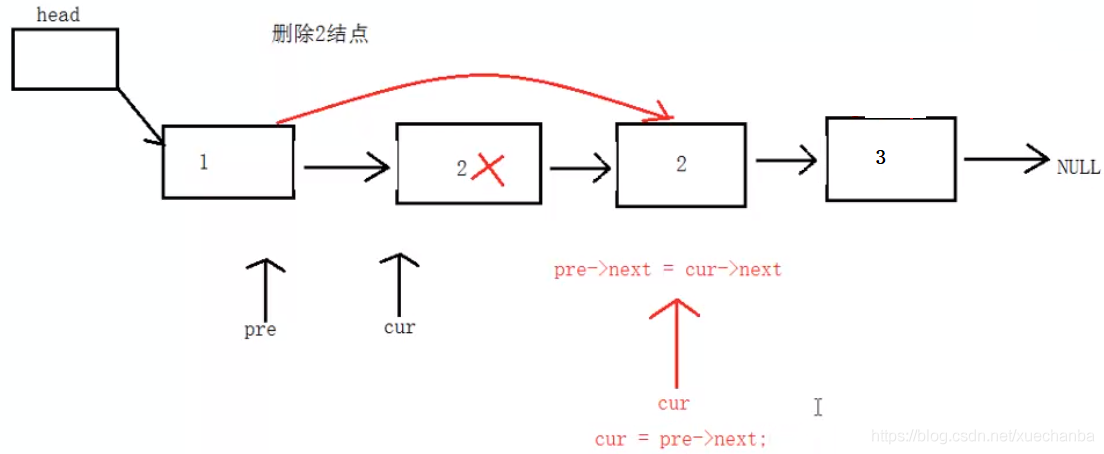
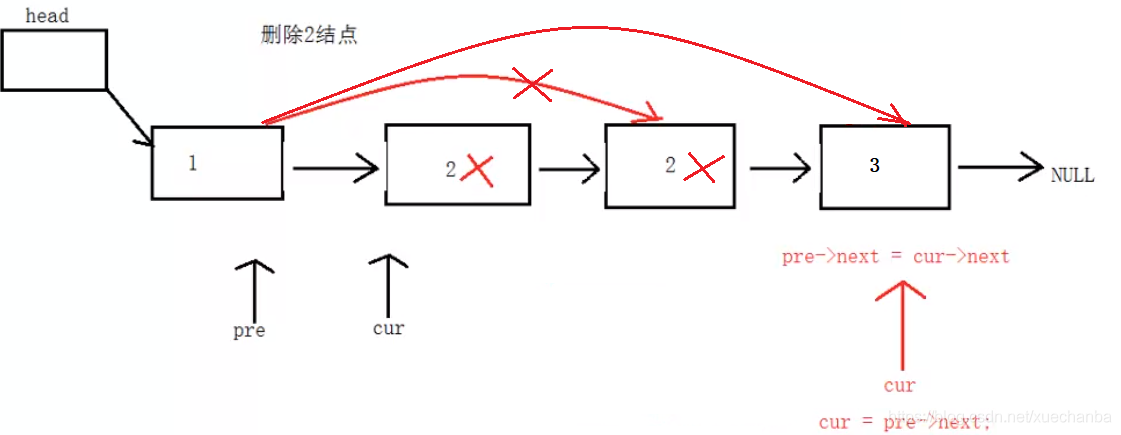
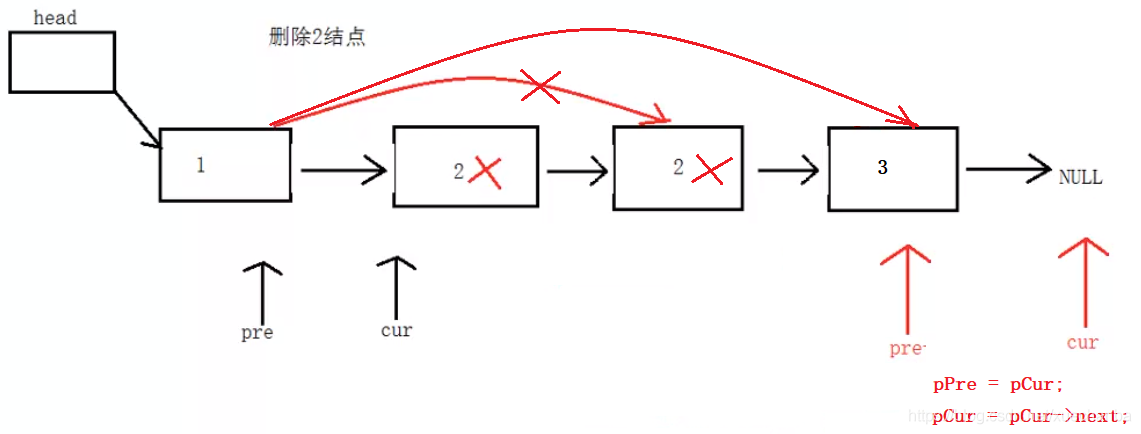
明白 continue 的作用
//洗掉值為x的所有結點
int SListNodeDelAll(Node * head, int x)
{
//定義兩個輔助變數并設定初始值
Node* pPre = head;
Node* pCur = head->next;
//標志位:0代表沒有找到,1代表找到了,
int flag = 0;
int count = 0;
while (pCur != NULL)
{
if (pCur->id == x)
{
//pPre的下一個指向pCur的下一個
pPre->next = pCur->next;
free(pCur);
pCur = NULL;
flag = 1;//說明找到了
count++; //找到的次數
pCur = pPre->next;
continue;//必須加上,跳出本次回圈,break是直接跳出回圈體
}
pPre = pCur;
pCur = pCur->next;
}
if (flag)
{
printf("Node = %d.\n",count);
}
else
{
printf("no find.\n");
return -2;
}
return 0;
}
6、單向鏈表排序
按照鏈表資料域中的某一成員的大小進行升/降排序
需要區分不同的情況,
1、假設該鏈表資料域中只有一個成員變數或者只交換這一個成員變數,假設為int型別,
//鏈表排序
int SListSort(Node* head)
{
if (head == NULL|| head->next == NULL)
{
return -1;
}
Node* pPre = NULL;
Node* pCur = NULL;
int tmp;
for (pPre = head->next; pPre->next != NULL; pPre = pPre->next)
{
for (pCur = pPre->next; pCur != NULL; pCur = pCur->next)
{
if (pPre->id < pCur->id)
{
tmp = pPre->id;
pPre->id = pCur->id;
pCur->id = tmp;
}
}
}
return 0;
}
2、鏈表資料域中的多個成員都交換
//鏈表排序
int SListSort(Node* head)
{
if (head == NULL|| head->next == NULL)
{
return -1;
}
Node* pPre = NULL;
Node* pCur = NULL;
Node tmp;
for (pPre = head->next; pPre->next != NULL; pPre = pPre->next)
{
for (pCur = pPre->next; pCur != NULL; pCur = pCur->next)
{
if (pPre->id < pCur->id)
{
//交換資料域
tmp = *pPre;
*pPre = *pCur;
*pCur = tmp;
//交換指標域
tmp.next = pPre->next;
pPre->next = pCur->next;
pCur->next = tmp.next;
}
}
}
return 0;
}
交換完資料域之后,為什么還要交換指標域?
上面代碼中的pPre是下圖中的p1,pCur是下圖中的p2,
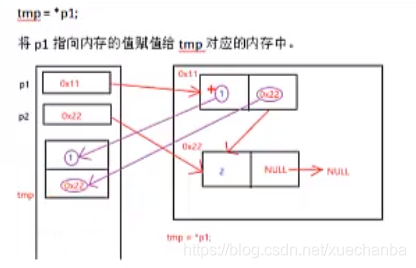
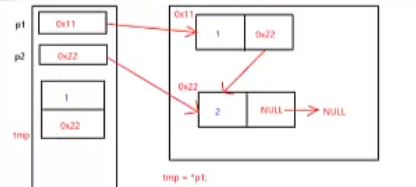
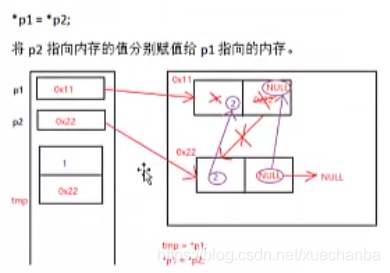
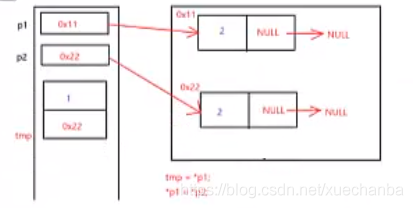
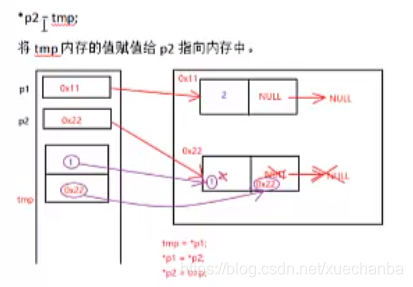
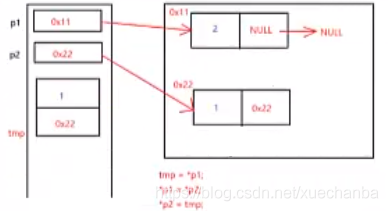
紅色的箭頭代表指向,而紫色的箭頭則代表賦值,


因此,交換完資料域之后,還要交換指標域,
指標函式和函式指標
指標函式
指標函式就是回傳值為指標的函式,本質是一個函式,
宣告形式:type *func (引數串列)
()比 * 的優先級要高,
函式指標
函式指標就是指向函式的指標,本質是一個指標,
函式名字就是程式的入口地址,
定義函式指標變數有三種方式,
方式一、先定義函式型別,再根據型別定義指標變數
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
int fun(int a)
{
printf("a == %d.\n",a);
return 0;
}
int main(int argc,char *argv[])
{
//有typedef是型別,沒有是變數,
typedef int FUN(int a);//定義FUN函式型別
FUN* p = NULL;//定義函式指標變數
p = fun;//p指向fun函式
fun(5);//傳統呼叫
p(5);//函式指標變數呼叫方式
printf("\n");
system("pause");
return 0;
}
方式二、先定義函式指標型別,再根據型別定義指標變數
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
int fun(int a)
{
printf("a == %d.\n",a);
return 0;
}
int main(int argc,char *argv[])
{
//有typedef是型別,沒有是變數,
typedef int (*PFUN)(int a);//PFUN,函式指標型別
PFUN p = fun;//函式指標變數,p指向fun函式,
p(5);
printf("\n");
system("pause");
return 0;
}
方式三、直接定義函式指標變數
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
int fun(int a)
{
printf("a = %d.\n",a);
return 0;
}
int main(int argc,char *argv[])
{
//有typedef是型別,沒有是變數,
int (*p)(int a)=fun;
//或者
int (*p1)(int a);
p1 = fun;
p(5);
p1(5);
printf("\n");
system("pause");
return 0;
}
函式指標陣列
在實作一些功能時,我們又可能會遇到下面這種情況:
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
void add(void)
{
printf("add1\n");
}
void minu(void)
{
printf("minu2\n");
}
void mult(void)
{
printf("mult3\n");
}
void divd(void)
{
printf("divd4\n");
}
void myexit(void)
{
exit(0);
}
int main(int argc,char *argv[])
{
char cmd[100];
while (1)
{
printf("請輸入指令: ");
scanf("%s",cmd);
if (strcmp(cmd, "add") == 0)
{
add();
}
else if (strcmp(cmd, "minu") == 0)
{
minu();
}
else if (strcmp(cmd, "mult") == 0)
{
mult();
}
else if (strcmp(cmd, "divd") == 0)
{
divd();
}
else if (strcmp(cmd, "myexit") == 0)
{
myexit();
}
else
{
myexit();
}
}
printf("\n");
system("pause");
return 0;
}
可以發現上面定義的函式都有相同的規律,
可以利用函式指標陣列來改進代碼,
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
void add(void)
{
printf("add1\n");
}
void minu(void)
{
printf("minu2\n");
}
void mult(void)
{
printf("mult3\n");
}
void divd(void)
{
printf("divd4\n");
}
void myexit(void)
{
exit(0);
}
int main(int argc,char *argv[])
{
char cmd[100];
//函式指標陣列
void (*fun[5])(void) = { add, minu, mult, divd, myexit };
//指標陣列
char* buf[] = { "add", "minu","mult", "divd", "myexit" };
int i;
while (1)
{
printf("請輸入指令: ");
scanf("%s",cmd);
for (i = 0; i < 5; i++)
{
if (strcmp(cmd, buf[i]) == 0)
{
fun[i]();
break;//跳出本次回圈
}
}
}
printf("\n");
system("pause");
return 0;
}
回呼函式
函式的引數是變數,可以是函式指標變數嗎?
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
int add(int a,int b)
{
return a+b;
}
int minu(int a, int b)
{
return a - b;
}
//函式的引數是變數,可以是函式指標變數嗎?
//框架:相當于一個介面
//void fun(int x, int y, int (*p)(int a, int b))
//還可以先定義函式指標型別,再定義函式指標變數
typedef int (*PFUN)(int a, int b);//PFUN,函式指標型別
void fun(int x, int y, PFUN p)
{
int a = p(x, y);//回呼函式
printf("a = %d.\n", a);
}
int main(int argc,char *argv[])
{
//add呼叫時
fun(1, 2, add);
//minu呼叫時
fun(5, 2, minu);
printf("\n");
system("pause");
return 0;
}
從回呼函式可以引出 C++ 中的多型,
多型:多種形態,呼叫同一介面,不一樣表現,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/292954.html
標籤:其他
上一篇:資料結構-堆疊
下一篇:MySQL資料庫(基礎)