- 論文: Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks
- 官方代碼(caffe): https://github.com/ZhaofanQiu/pseudo-3d-residual-networks
- 非官方(pytorch): https://github.com/qijiezhao/pseudo-3d-pytorch
- 由微軟和中科大提出
- 被ICCV2017收錄
一、核心創新
- 提出將3D卷積進行時間和空間的拆分來代替一個3D卷積
- 提出了幾種變形的殘差塊
- 提出了P3D(Presudo-3D) ResNet
二、P3D Blocks和P3D ResNet
2.1 3D卷積解耦
3D卷積是同時提取空間資訊和時間資訊,拿核大小為3 x 3 x 3大小的3D卷積核來說,可以將其自然的解耦為一個1 x 3 x 3大小的卷積核和一個3 x 1 x 1大小的卷積核的組合,解耦的3D卷積稱為偽(Pseudo)3D卷積,
2.2 Pseudo-3D Blocks
思想是將3D CNN按照2.1里面的解耦思想改造成P3D CNN,但是需要考慮兩點:
- 時間維度和空間維度的計算是否需要直接或者間接的互相關聯
- 兩種維度的計算是否需要直接與輸出關聯
基于這兩點考慮設計出下面三種P3D CNN:
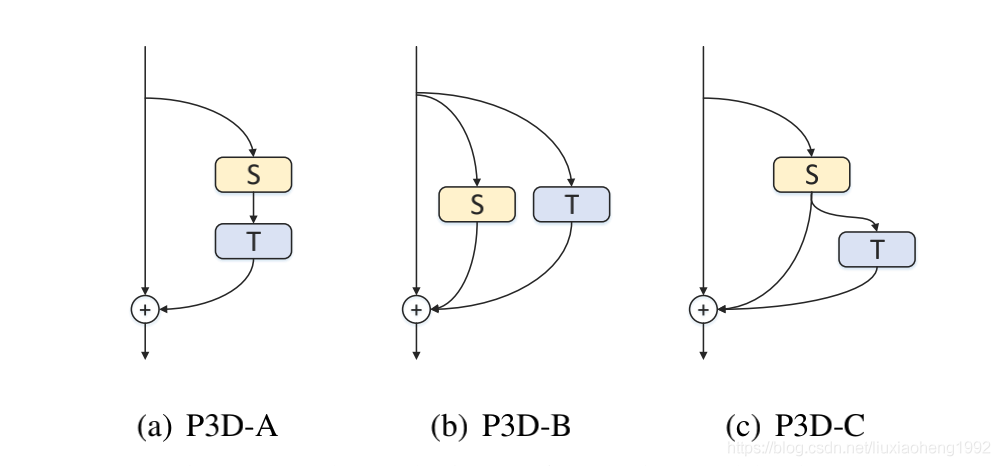
又基于上面的三種鏈接的CNN和原始ResNet Block,提出下列三種P3D Block:
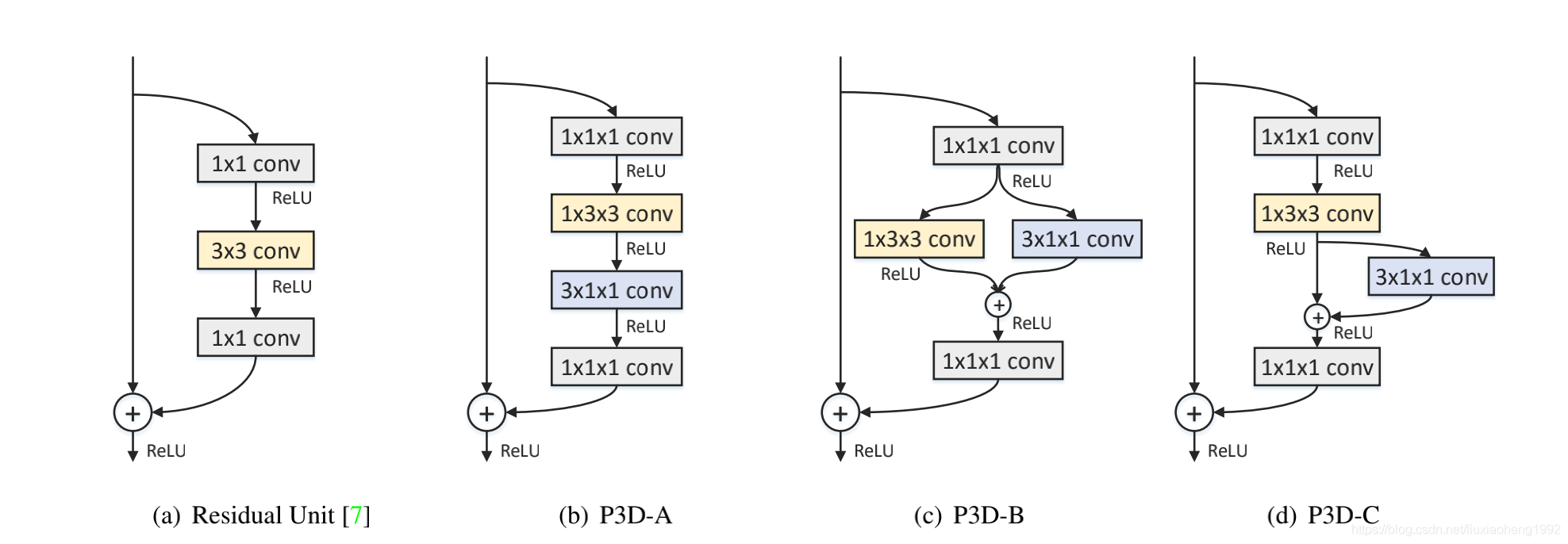
2.3 Pseudo-3D ResNet
為了檢驗那種P3D Block效果好,進行如下實驗:
- 對于原始的ResNet,使用UCF101視幀進行finetune,輸入圖片從resized為240 x 320的視頻幀中隨機截取240 x 240,固定除去第一層BN后的所有BN引數,并且最后加入了droprate為0.9的dropout操作
- 對于原始的ResNet,測驗時對每一幀進行預測,然后算平均值
- 其它的三類P3D ResNet引數初始化使用上一步訓練好的引數
- P3D ResNet的輸入為16 x 160 x 160,來源于從視頻中截取不重疊的視頻段16 x 182 x 242中隨機截取
- 輸入片段隨機水平翻轉
- batch為128
- SGD,lr初始為0.001,每迭代3k除以10,迭代7.5k
- 其它的三類P3D ResNet測驗結果計算方法沒提
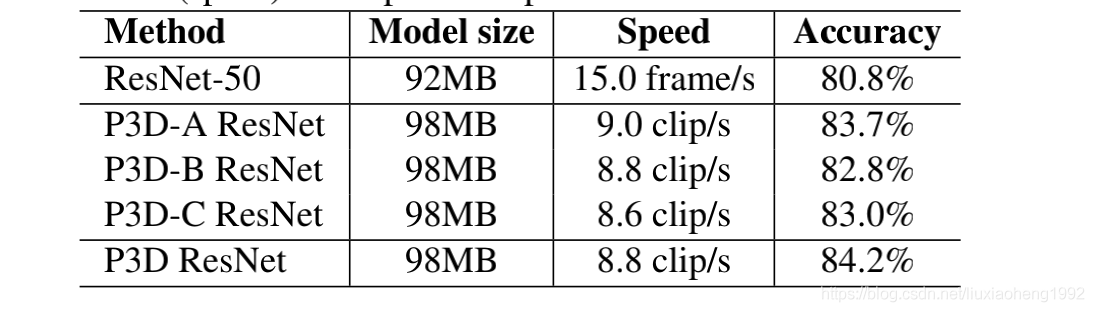
為了使得P3D Block在網路中多樣,文章簡單的按照P3D-A→P3D-B→P3D-C順序進行block替換這種網路就稱為P3D ResNet,實驗結果在上面表中也有顯示,

其他具體的引數和實驗結果詳情可以看原文和代碼,
視頻演算法QQ交流群:657626967
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293057.html
標籤:其他
上一篇:【游戲開發高階】從零到一教你Unity使用ToLua實作熱更新(含Demo工程 | LuaFramework | 增量 | HotUpdate)
下一篇:Opencv學習3.形狀識別模塊