文章目錄
- 1. 卷積神經網路(LeNet)發展
- 2. LeNet網路結構
- 3. 代碼實作(將LeNet應用在簡單的Fashion-MNIST上)
- 3.1 匯入相關包
- 3.2 網路結構定義及驗證
- 3.3 模型訓練
- 3.4 訓練結果
講解LeNet的材料比較多,這個Blog的內容主要是李沐老師《動手學深度學習V2》課程的markdown檔案,
LeNet還是比較簡單的,根據目錄跳轉到自己想看的部分吧!
1. 卷積神經網路(LeNet)發展
????LeNet,它是最早發布的卷積神經網路之一,因其在計算機視覺任務中的高效性能而受到廣泛關注,這個模型是由 AT&T 貝爾實驗室的研究員 Yann LeCun 在1989年提出的(并以其命名),目的是識別影像 LeCun.Bottou.Bengio.ea.1998 中的手寫數字,
????當時,Yann LeCun 發表了第一篇通過反向傳播成功訓練卷積神經網路的研究,這項作業代表了十多年來神經網路研究開發的成果,當時, LeNet 取得了與支持向量機(support vector machines)性能相媲美的成果,成為監督學習的主流方法,LeNet 被廣泛用于自動取款機(ATM)機中,幫助識別處理支票的數字,
????時至今日,一些自動取款機仍在運行 Yann LeCun 和他的同事 Leon Bottou 在上世紀90年代寫的代碼呢!
2. LeNet網路結構
總體來看,(LeNet(LeNet-5)由兩個部分組成:- 卷積編碼器:由兩個卷積層組成;
- 全連接層密集塊:由三個全連接層組成,
該結構如下所展示,
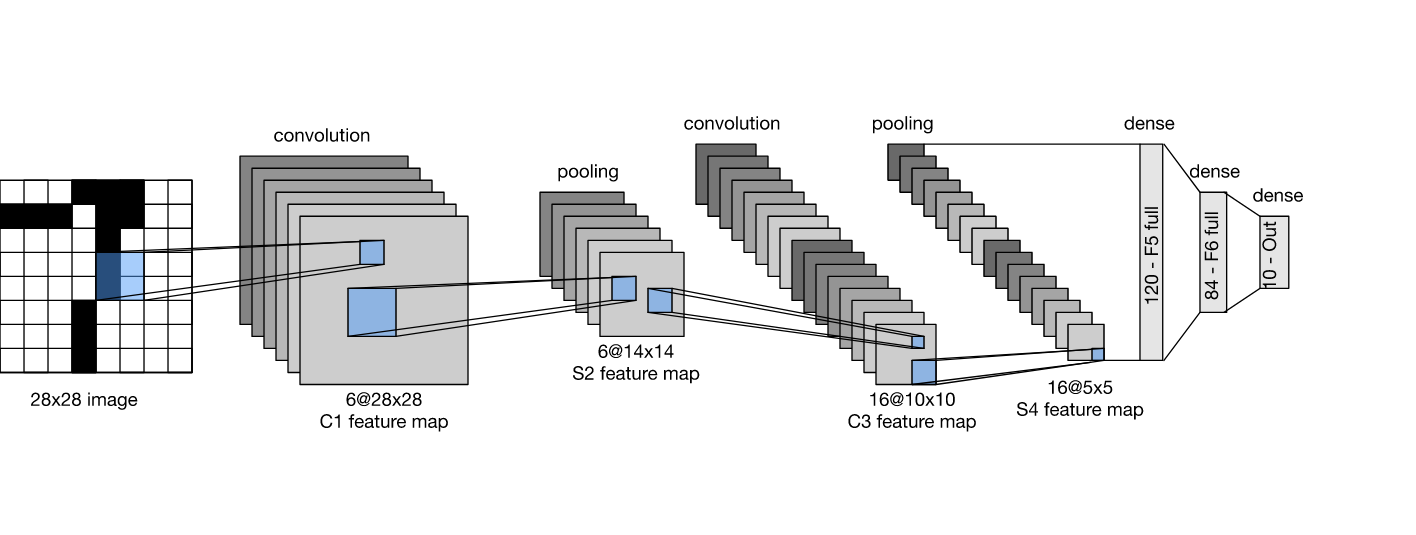
????每個卷積塊中的基本單元是一個卷積層、一個 sigmoid 激活函式和平均池化層,請注意,雖然 ReLU 和最大池化層更有效,但它們在20世紀90年代還沒有出現,每個卷積層使用 5 × 5 5\times 5 5×5 卷積核和一個 sigmoid 激活函式,這些層將輸入映射到多個二維特征輸出,通常同時增加通道的數量,第一卷積層有 6 個輸出通道,而第二個卷積層有 16 個輸出通道,每個 2 × 2 2\times2 2×2 池操作(步驟2)通過空間下采樣將維數減少 4 倍,卷積的輸出形狀由批量大小、通道數、高度、寬度決定,
????為了將卷積塊的輸出傳遞給稠密塊,我們必須在小批量中展平每個樣本,換言之,我們將這個四維輸入轉換成全連接層所期望的二維輸入,這里的二維表示的第一個維度索引小批量中的樣本,第二個維度給出每個樣本的平面向量表示,LeNet 的稠密塊有三個全連接層,分別有 120、84 和 10 個輸出,因為我們仍在執行分類,所以輸出層的 10 維對應于最后輸出結果的數量,
????通過下面的 LeNet 代碼,你會相信用深度學習框架實作此類模型非常簡單,我們只需要實體化一個 Sequential 塊并將需要的層連接在一起,
總結:
- LeNet早期成功的神經網路
- 先使用卷積層來學習圖片空間資訊
- 然后使用全連接層來轉換到類別空間
3. 代碼實作(將LeNet應用在簡單的Fashion-MNIST上)
3.1 匯入相關包
import torch
from torch import nn
from d2l import torch as d2l
3.2 網路結構定義及驗證
class Reshape(torch.nn.Module):
"""將資料轉換成批量數不變、通道數為1,大小為(28,28)的資料"""
def forward(self, x):
return x.view(-1, 1, 28, 28)
net = torch.nn.Sequential(
Reshape(),
nn.Conv2d(1, 6, kernel_size=5,padding=2),
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(),
nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),
nn.Linear(120, 84), nn.Sigmoid(), nn.Linear(84, 10))
檢查網路結構
????我們對原始模型做了一點小改動,去掉了最后一層的高斯激活,除此之外,這個網路與最初的 LeNet-5 一致,下面,我們將一個大小為
28
×
28
28 \times 28
28×28 的單通道(黑白)影像通過 LeNet, 通過在每一層列印輸出的形狀,我們可以[檢查模型],以確保其操作與我們期望的

# 檢查模型
X = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32)
for layer in net:
X = layer(X)
print(layer.__class__.__name__, 'output shape: \t', X.shape)
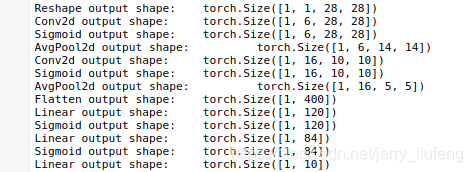
其中值的注意的是:
????在整個卷積塊中,與上一層相比,每一層特征的高度和寬度都減小了,第一個卷積層使用 2 個像素的填充,來補償
5
×
5
5 \times 5
5×5 卷積核導致的特征減少,相反,第二個卷積層沒有填充,因此高度和寬度都減少了 4 個像素,隨著層疊的上升,通道的數量從輸入時的 1 個,增加到第一個卷積層之后的 6 個,再到第二個卷積層之后的 16 個,同時,每個池化層的高度和寬度都減半,最后,每個全連接層減少維數,最終輸出一個維數與結果分類數相匹配的輸出,
3.3 模型訓練
現在我們已經實作了 LeNet ,讓我們看看LeNet在Fashion-MNIST資料集上的表現,
from torchvision import transforms
import torchvision
from torch.utils import data
batch_size = 256
def get_dataloader_workers():
"""使用四個行程讀取資料"""
return 4
def load_data_fashion_mnist(batch_size,resize=None):
"""下載Fashion-MNIST資料集,并將其保存至記憶體中"""
trans = [transforms.ToTensor()]
if resize:
trans.insert(0,transforms.Resize(resize)) # transforms.Resize將圖片最小的一條邊縮放到指定大小,另一邊縮放對應比例
trans = transforms.Compose(trans) # compose用于串聯多個操作
mnist_train = torchvision.datasets.FashionMNIST(root="./data",
train=True,
transform=trans,
download=True)
mnist_test = torchvision.datasets.FashionMNIST(root="./data",
train=False,
transform=trans,
download=True)
return (data.DataLoader(mnist_train,batch_size,shuffle=True,
num_workers=get_dataloader_workers()),
data.DataLoader(mnist_test,batch_size,shuffle=True,
num_workers = get_dataloader_workers()))
batch_size = 256
train_iter, test_iter = load_data_fashion_mnist(batch_size=batch_size)
雖然卷積神經網路的引數較少,但與深度的多層感知機相比,它們的計算成本仍然很高,因為每個引數都參與更多的乘法,如果你有機會使用GPU,可以用它加快訓練,
為了進行評估,我們需對 softmax回歸演算法處理Fashion-MNIST演算法中描述的evaluate_accuracy函式進行輕微的修改,由于完整的資料集位于記憶體中,因此在模型使用 GPU 計算資料集之前,我們需要將其復制到顯存中,
def evaluate_accuracy_gpu(net, data_iter, device=None): #@save
"""使用GPU計算模型在資料集上的精度,"""
if isinstance(net, torch.nn.Module):
net.eval() # 設定為評估模式
if not device:
device = next(iter(net.parameters())).device
# 正確預測的數量,總預測的數量
metric = d2l.Accumulator(2)
for X, y in data_iter:
if isinstance(X, list):
# BERT微調所需的(之后將介紹)
X = [x.to(device) for x in X]
else:
X = X.to(device)
y = y.to(device)
metric.add(d2l.accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
[為了使用 GPU,我們還需要一點小改動],
與 softmax 中定義的 train 不同,在進行正向和反向傳播之前,我們需要將每一小批量資料移動到我們指定的設備(例如 GPU)上,
????如下所示,訓練函式 train 也類似于softmax 中定義的 train ,由于我們將實作多層神經網路,因此我們將主要使用高級 API,以下訓練函式假定從高級 API 創建的模型作為輸入,并進行相應的優化,我們使用在 初始化引數xavier 中介紹的 Xavier 隨機初始化模型引數,與全連接層一樣,我們使用交叉熵損失函式和小批量隨機梯度下降,
#@save
def train(net, train_iter, test_iter, num_epochs, lr, device):
"""用GPU訓練模型"""
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print('training on', device)
net.to(device) # 將網路挪到gpu上
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['train loss', 'train acc', 'test acc'])
timer, num_batches = d2l.Timer(), len(train_iter)
for epoch in range(num_epochs):
# 訓練損失之和,訓練準確率之和,范例數
metric = d2l.Accumulator(3)
net.train()
for i, (X, y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
with torch.no_grad():
metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(train_l, train_acc, None))
test_acc = evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, '
f'test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec '
f'on {str(device)}')
3.4 訓練結果
lr, num_epochs = 0.9, 10
train(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
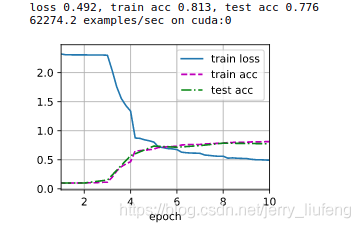
對比之前使用softmax進行回歸分類得到的結果,LeNet的loss進一步降低,精度提高了一些,仔細調整LeNet的引數(如learning rate、卷積kernel大小、padding大小、輸出通道數等等)其對我們使用的
Fashion-MNIST資料集的分類精確取大概能達到84%,當然這就是煉丹了,訓練10個epoch我這里沒有明顯的過擬合,但是增加迭代次數還是會有過擬合的風險的,所以使用一些我們之前章節中提及的解決過擬合的方法就有了勇武之地了,在后面的章節中也將繼續實際應用起來,包括
dropout、正則化、初始化引數等等,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293079.html
標籤:AI
下一篇:8.空間位置解算