編號按照對應的內容,1-1代表第一大部分遇到的第一題,R代表Review,C代表運行的代碼(Code),
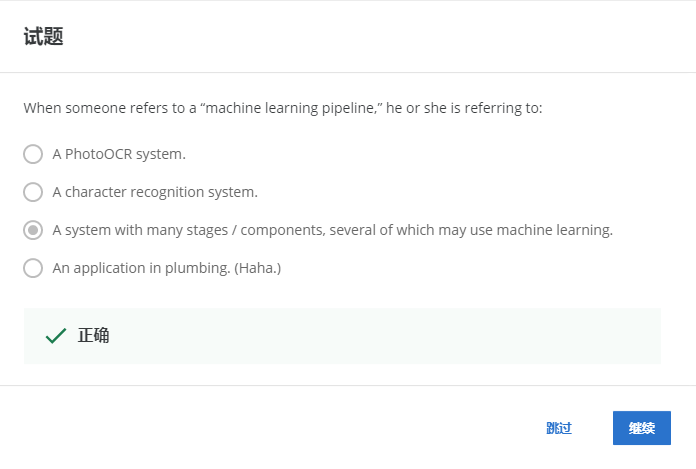
1-1
解:C
具有多個階段/組件的系統,其中幾個可以使用機器學習,
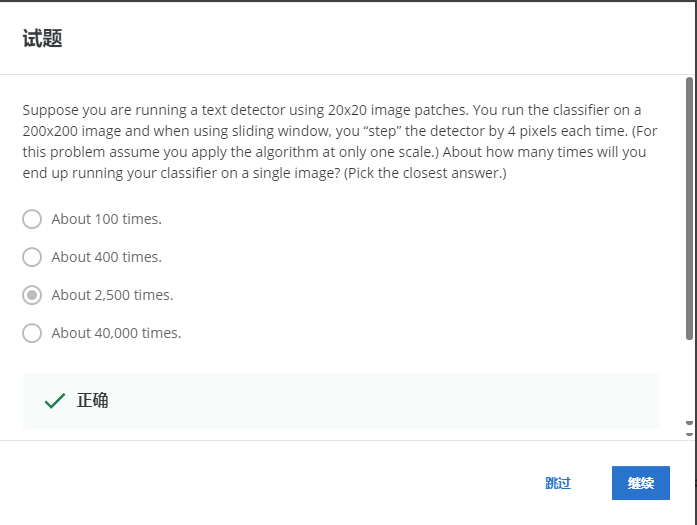
1-2
解:C
200 * 200,每次移動4像素,總共是50 * 50=2500次,
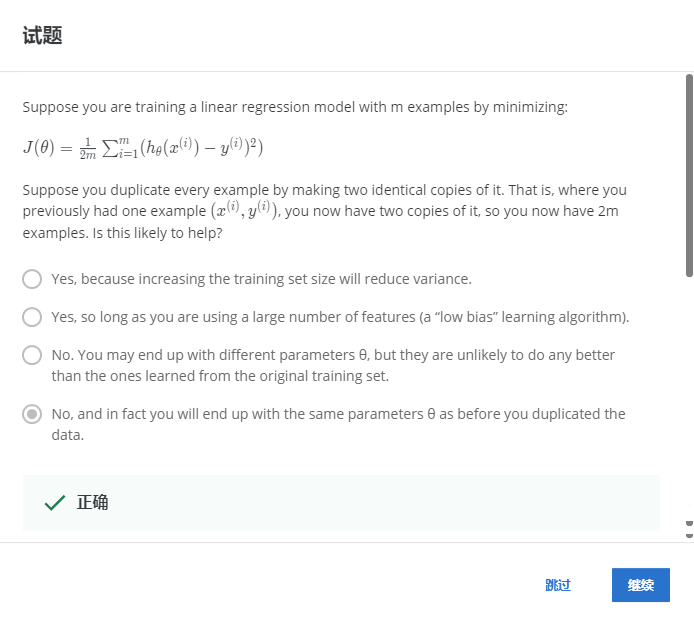
1-3
解:D
復制樣本沒有用途,還是會以與之前訓練相同的結果θ結束,
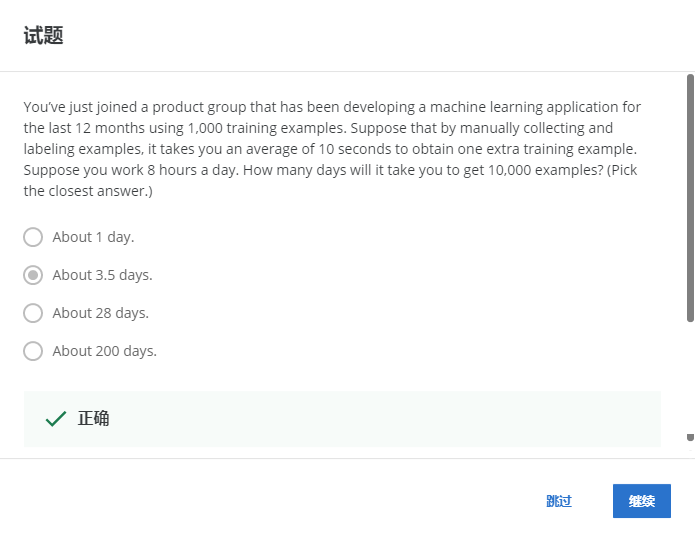
1-4
解:B
您剛剛加入了一個產品組,該產品組在過去12個月中使用1000個培訓示例開發了一個機器學習應用程式,假設通過手工收集和標注例子,你平均需要10秒鐘才能獲得額外的訓練樣本,假設你每天作業8小時,你需要多少天才能得到10,000個例子?(最接近的答案)
10000/(8 * 60 * 60 / 10)=3.47天,
1-5
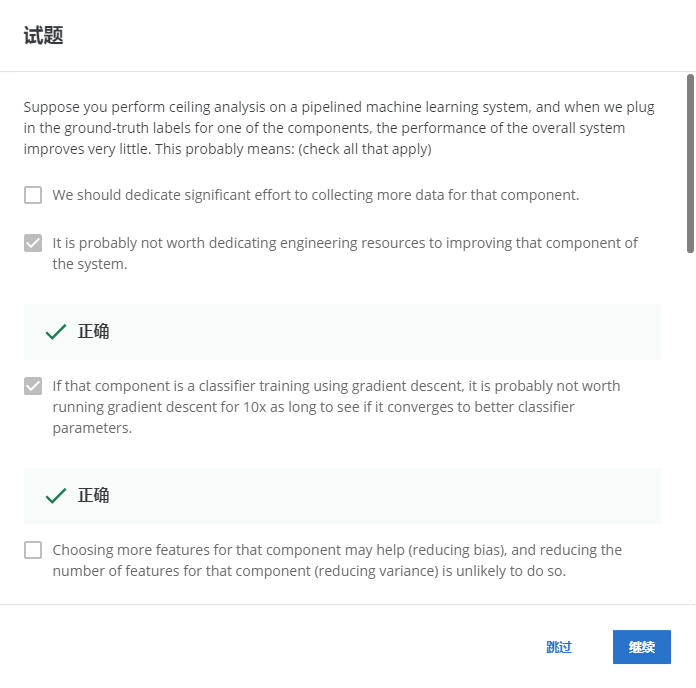
解:BC
假設您在流水線機器學習系統上執行上限分析,當我們為其中一個組件插入正確的標簽時,整個系統的性能幾乎沒有什么改善,這可能意味著:(檢查所有應用程式)
這可能不值得投入工程資源來改進系統的組成部分,
如果該組件是一個使用梯度下降的分類器訓練,需要看它是否收斂到最好的引數,
R
R1-1

解:A
1000 * 1000,每次移動2像素(兩個視窗),總共是500 * 500 * 2=500000次,
R1-2

解:A
(10000 * 10)/(4 * 60)約等于400,
R1-3

解:AD
B是學習曲線的優點,
C是人工合成資料的優點,
R1-4

解:A
獲取更多資料,我們可以對原有資料進行鏡像,不會更改資料中的車輛資訊,
R1-5

解:AB
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293087.html
標籤:AI