1.典型的激活函式
1.1 sigmoid函式
該函式可以將元素的值轉化到0~1之間,其公式和圖形表示形式如下:
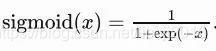
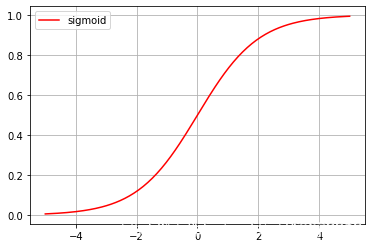
從圖形可以看出該函式存在以下缺點:
(1)BP神經網路是依據梯度進行的,而該函式在無窮小或無窮大的時函式的導數趨近于0.因此在輸出值較大或較小時,網路更新慢,容易造成梯度消失,
(2)函式輸出的不是以0為中心,而是以0.5為中心,函式輸出值始終大于0,因此導致模型訓練收斂速度變慢,
1.2 ReLu函式
ReLu函式通常作為CNN網路默認的激活函式,當函式輸入為正數時,導數恒為1,可以緩解梯度消失,當小于0時,可以稀疏網路,其函式形式及圖形如下:
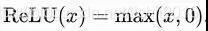
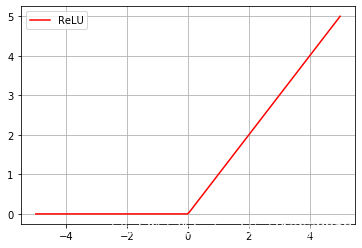
從影像可以看出,ReLU函式將小于0的全部過濾掉了,雖然它在正區間緩解了梯度消失問題,但卻會造成負區間的大量神經元死亡的問題,因為當輸入小于零時,導數恒為0,會使很多神經元無法得到更新,也就是負區間的梯度會消失,
1.3 Leaky ReLU函式
由于Relu在負區間的神經元死亡問題,于是有了一個變種Leaky Relu,Leaky ReLU給所有負值賦予一個非零斜率,也就是該函式輸出對負值輸入有很小的坡度,由于導數總是不為零,這能減少靜默神經元的出現,允許基于梯度的學習(盡管會很慢),函式表現形式及圖形如下:
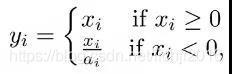
1.4 PReLU函式
來自于何凱明于ICCV2015的paper,地址為:https://arxiv.org/pdf/1502.01852.pdf,
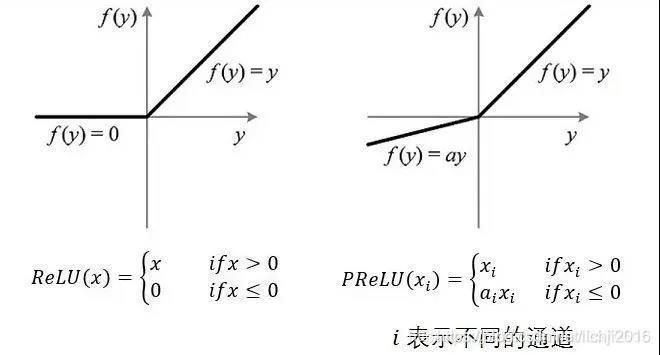
如果ai=0,那么PReLU退化為ReLU;如果是一個很小的固定值(如ai=0.01),則PReLU退化為Leaky ReLU,PReLU和 RReLU 以及 Leaky ReLU 有一些共同點,即為負值輸入添加了一個線性項,而且這個線性項的斜率實際上是在模型訓練中學習到的,公式及圖形如下:
1.5 RReLU函式
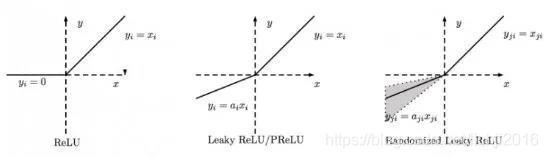
RReLU同樣屬于 Leaky ReLU的變體之一,在RReLU中,負區間的斜率在訓練中是隨機的,在之后的測驗中就變成了固定的了,RReLU在訓練環節中, aji是從一個均勻的分布U(I,u)中隨機抽取的數值,函式及圖形如下:
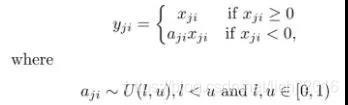
1.6 1.2 Tanh函式
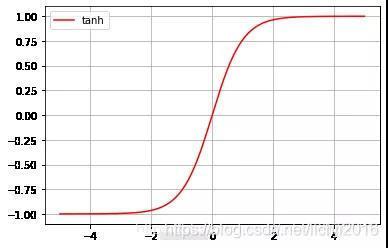
Tanh函式可以將元素的值變換到-1和1之間,Tanh函式 的輸出均值比 sigmoid 更接近 0,SGD會更接近natural gradient(一種二次優化技術),從而降低所需的迭代次數,主要解決了上面說到的sigmod函式的第二個不足,
當為非常大或者非常小的時候,由導數推斷公式可知,此時導數接近與0,會導致梯度很小,權重更新非常緩慢,從而導致所謂的梯度消失的問題,其公式及圖形如下所示:
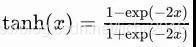
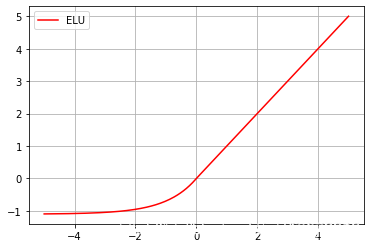
1.6 ELU函式
ELU在正區間內的導數處處為1,緩解了梯度消失問題,ELU的輸出均值是接近于零的,如果均值非0,就會對下一層造成一個bias,這時候如果激活函式的輸出值之間不能相互抵消(即均值非0),就會導致下一層的激活單元有bias shift,
當單元很多的時候,bias shift會一直累加,越來越大,相比ReLU,ELU可以取到負值,這讓單元激活輸出的均值可以更接近0,這比較類似于Batch Normalization的效果但是只需要更低的計算復雜度,雖然LReLU和PReLU都也有負值,但是它們不保證在不激活狀態下(就是在輸入為負的狀態下)對噪聲魯棒,反觀ELU在輸入取較小值時具有軟飽和的特性,提升了對噪聲的魯棒性,其公式及圖形如下:
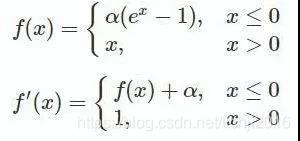
1.7 Swish函式
來自于谷歌大腦的paper:Searching for Activation Functionshttps://arxiv.org/abs/1710.05941,β是個常數或可訓練的引數.Swish 具備無上界有下界、平滑、非單調的特性,其公式及函式圖形如下:
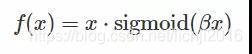
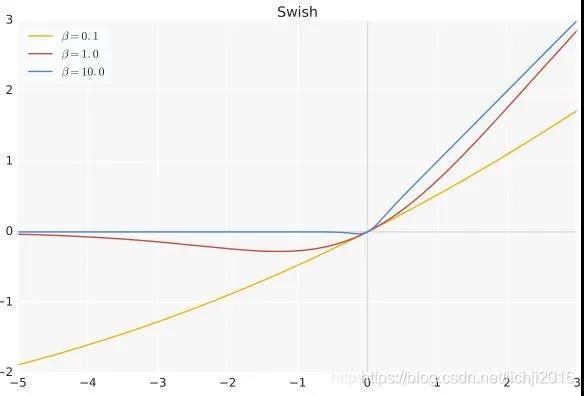
Swish與ReLU一樣有下界而無上界,但是其非單調性確與其他常見的激活函式不同,同時也擁有平滑和一階導數,二階導數平滑的特性,
谷歌的實驗證明了Swish在不同的資料集上的表現都要優于很多其他的激活函式,,Swish適應于區域回應歸一化,并且在40以上全連接層的效果要遠優于其他激活函式,而在40全連接層之內則性能差距不明顯,但是根據在mnist資料上AleNet的測驗效果卻證明,Swish在低全連接層上與Relu的性能差距依舊有較大的優勢,谷歌通過對比,各種激活函式ACC如下:
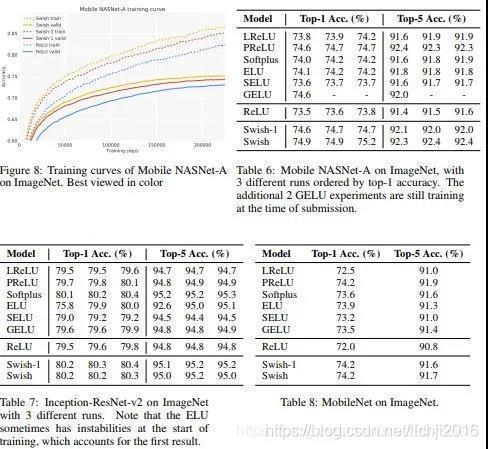
2.如何選擇激活函式
一般而言,首先應該嘗試的就是ReLU,由于梯度消失問題,有時要避免使用sigmoid和tanh函式,如果網路學習效果不佳,可能由神經元死亡導致的梯度消失,那么可以嘗試ReLU的一些變種激活函式,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293093.html
標籤:AI
上一篇:人工智能正在學習如何創造自己