
文章目錄
- 腳本引數
- 創建Topic腳本
- 創建Topic 原始碼分析
- 1. 原始碼入口
- 2. 創建AdminClientTopicService 物件
- 2.1 先創建 Admin
- 3. AdminClientTopicService.createTopic 創建Topic
- 3.1 KafkaAdminClient.createTopics(NewTopic) 創建Topic
- 4. 發起網路請求
- 5. Controller角色的服務端接受請求處理邏輯
- 5.1 KafkaApis.handle(request) 根據請求傳遞Api呼叫不同介面
- 5.2 KafkaApis.handleCreateTopicsRequest 處理創建Topic的請求
- 5.3 adminManager.createTopics()
- 5.4 寫入zookeeper資料
- 6. Controller監聽 `/brokers/topics/Topic名稱`, 通知Broker將磁區寫入磁盤
- 6.1 onNewPartitionCreation 狀態流轉
- 7. Broker收到LeaderAndIsrRequest 創建本地Log
- 原始碼總結
- Q&A
- 創建Topic的時候 在Zk上創建了哪些節點
- 創建Topic的時候 什么時候在Broker磁盤上創建的日志檔案
- 如果我沒有指定磁區數或者副本數,那么會如何創建
- 如果我手動洗掉了`/brokers/topics/`下的某個節點會怎么樣?
- 如果我手動在zk中添加`/brokers/topics/{TopicName}`節點會怎么樣
- 如果寫入`/brokers/topics/{TopicName}`節點之后Controller掛掉了會怎么樣
- 附件
- --config 可生效引數
Topic創建流程分析+常見問題
全套視頻請關注公眾號:石臻臻的雜貨鋪(首發)
腳本引數
sh bin/kafka-topic -help 查看更具體引數
下面只是列出了跟--create 相關的引數
| 引數 | 描述 | 例子 |
|---|---|---|
--bootstrap-server 指定kafka服務 | 指定連接到的kafka服務; 如果有這個引數,則 --zookeeper可以不需要 | –bootstrap-server localhost:9092 |
--zookeeper | 棄用, 通過zk的連接方式連接到kafka集群; | –zookeeper localhost:2181 或者localhost:2181/kafka |
--replication-factor | 副本數量,注意不能大于broker數量;如果不提供,則會用集群中默認配置 | –replication-factor 3 |
--partitions | 磁區數量 | 當創建或者修改topic的時候,用這個來指定磁區數;如果創建的時候沒有提供引數,則用集群中默認值; 注意如果是修改的時候,磁區比之前小會有問題 |
--replica-assignment | 副本磁區分配方式;創建topic的時候可以自己指定副本分配情況; | --replica-assignment BrokerId-0:BrokerId-1:BrokerId-2,BrokerId-1:BrokerId-2:BrokerId-0,BrokerId-2:BrokerId-1:BrokerId-0 ; 這個意思是有三個磁區和三個副本,對應分配的Broker; 逗號隔開標識磁區;冒號隔開表示副本 |
--config<String: name=value> | 用來設定topic級別的配置以覆寫默認配置;只在–create 和–bootstrap-server 同時使用時候生效; 可以配置的引數串列請看文末附件 | 例如覆寫兩個配置 --config retention.bytes=123455 --config retention.ms=600001 |
--command-config <String: command 檔案路徑> | 用來配置客戶端Admin Client啟動配置,只在–bootstrap-server 同時使用時候生效; | 例如:設定請求的超時時間 --command-config config/producer.proterties; 然后在檔案中配置 request.timeout.ms=300000 |
--create | 命令方式; 表示當前請求是創建Topic | --create |
創建Topic腳本
zk方式(不推薦)
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 3 --topic test
需要注意的是–zookeeper后面接的是kafka的zk配置, 假如你配置的是localhost:2181/kafka 帶命名空間的這種,不要漏掉了
kafka版本 >= 2.2 支持下面方式(推薦)
bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 3 --partitions 3 --topic test
當前分析的kafka原始碼版本為 kafka-2.5
創建Topic 原始碼分析
溫馨提示: 如果閱讀原始碼略顯枯燥,你可以直接看原始碼總結以及后面部分
首先我們找到原始碼入口處, 查看一下 kafka-topic.sh腳本的內容
exec $(dirname $0)/kafka-run-class.sh kafka.admin.TopicCommand "$@"
最終是執行了kafka.admin.TopicCommand這個類,找到這個地方之后就可以斷點除錯原始碼了,用IDEA啟動
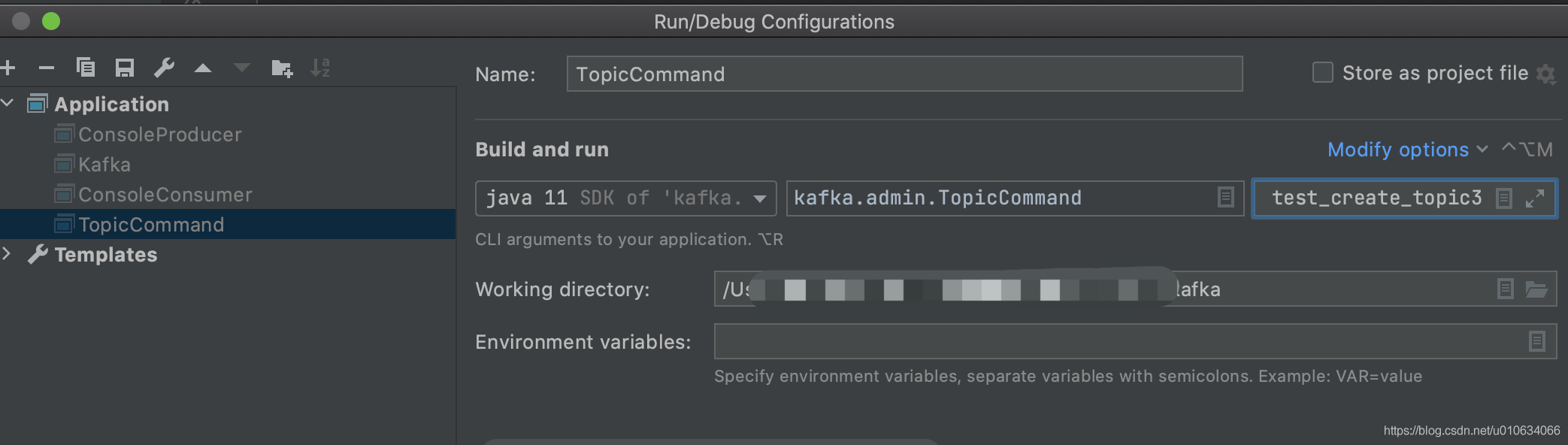
記得配置一下入參
比如: --create --bootstrap-server 127.0.0.1:9092 --partitions 3 --topic test_create_topic3
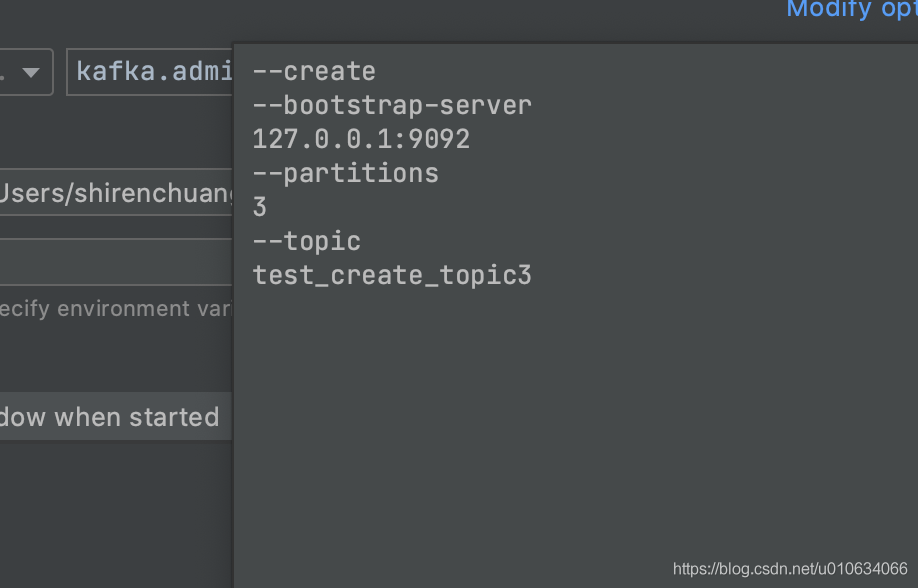
1. 原始碼入口
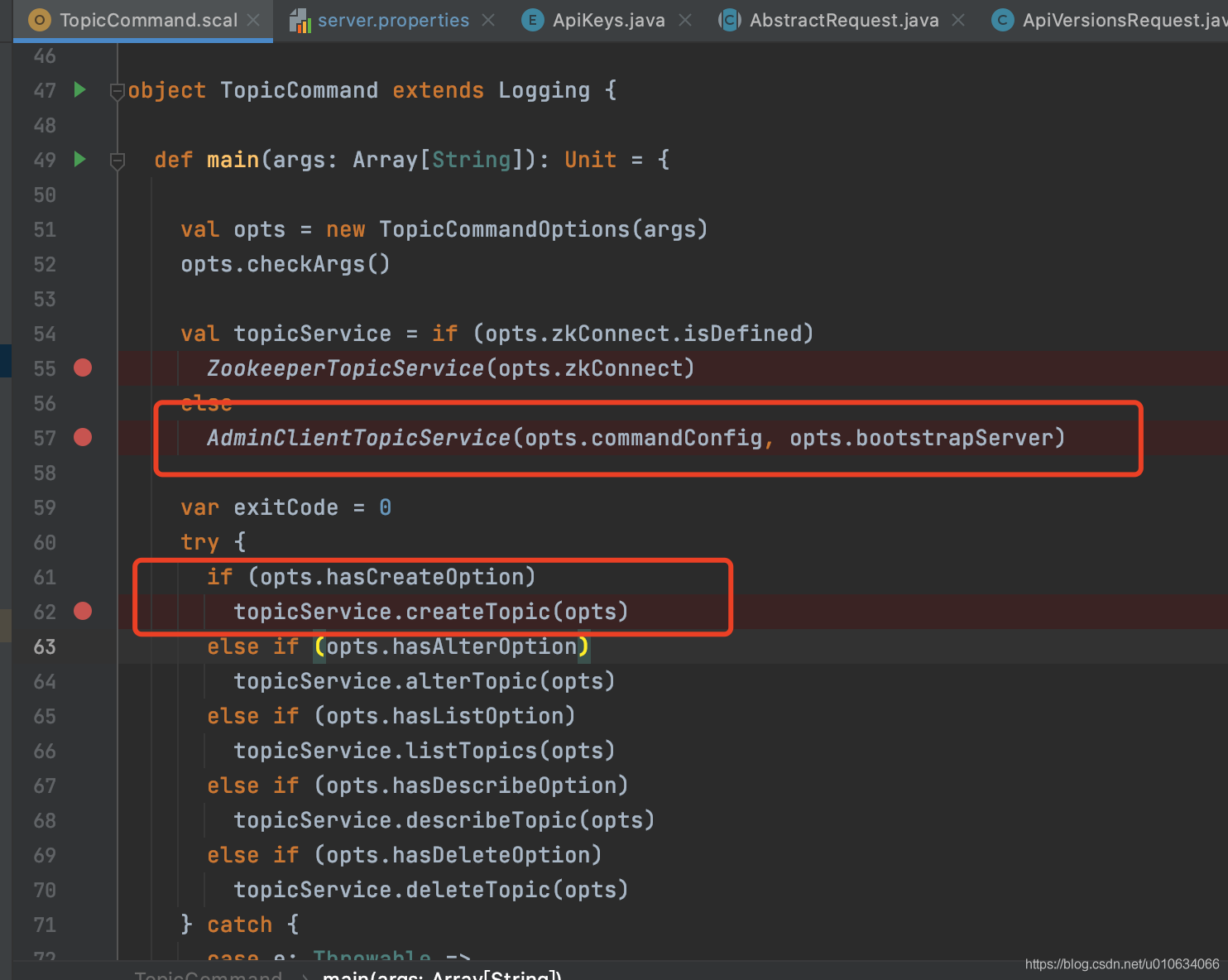
上面的原始碼主要作用是
- 根據是否有傳入引數
--zookeeper來判斷創建哪一種 物件topicService
如果傳入了--zookeeper則創建 類ZookeeperTopicService的物件
否則創建類AdminClientTopicService的物件(我們主要分析這個物件) - 根據傳入的引數型別判斷是創建topic還是洗掉等等其他 判斷依據是 是否在引數里傳入了
--create
2. 創建AdminClientTopicService 物件
val topicService = new AdminClientTopicService(createAdminClient(commandConfig, bootstrapServer))
2.1 先創建 Admin
object AdminClientTopicService {
def createAdminClient(commandConfig: Properties, bootstrapServer: Option[String]): Admin = {
bootstrapServer match {
case Some(serverList) => commandConfig.put(CommonClientConfigs.BOOTSTRAP_SERVERS_CONFIG, serverList)
case None =>
}
Admin.create(commandConfig)
}
def apply(commandConfig: Properties, bootstrapServer: Option[String]): AdminClientTopicService =
new AdminClientTopicService(createAdminClient(commandConfig, bootstrapServer))
}
- 如果有入參
--command-config,則將這個檔案里面的引數都放到mapcommandConfig里面, 并且也加入bootstrap.servers的引數;假如組態檔里面已經有了bootstrap.servers配置,那么會將其覆寫 - 將上面的
commandConfig作為入參呼叫Admin.create(commandConfig)創建 Admin; 這個時候呼叫的Client模塊的代碼了, 從這里我們就可以看出,我們呼叫kafka-topic.sh腳本實際上是kafka模擬了一個客戶端Client來創建Topic的程序;
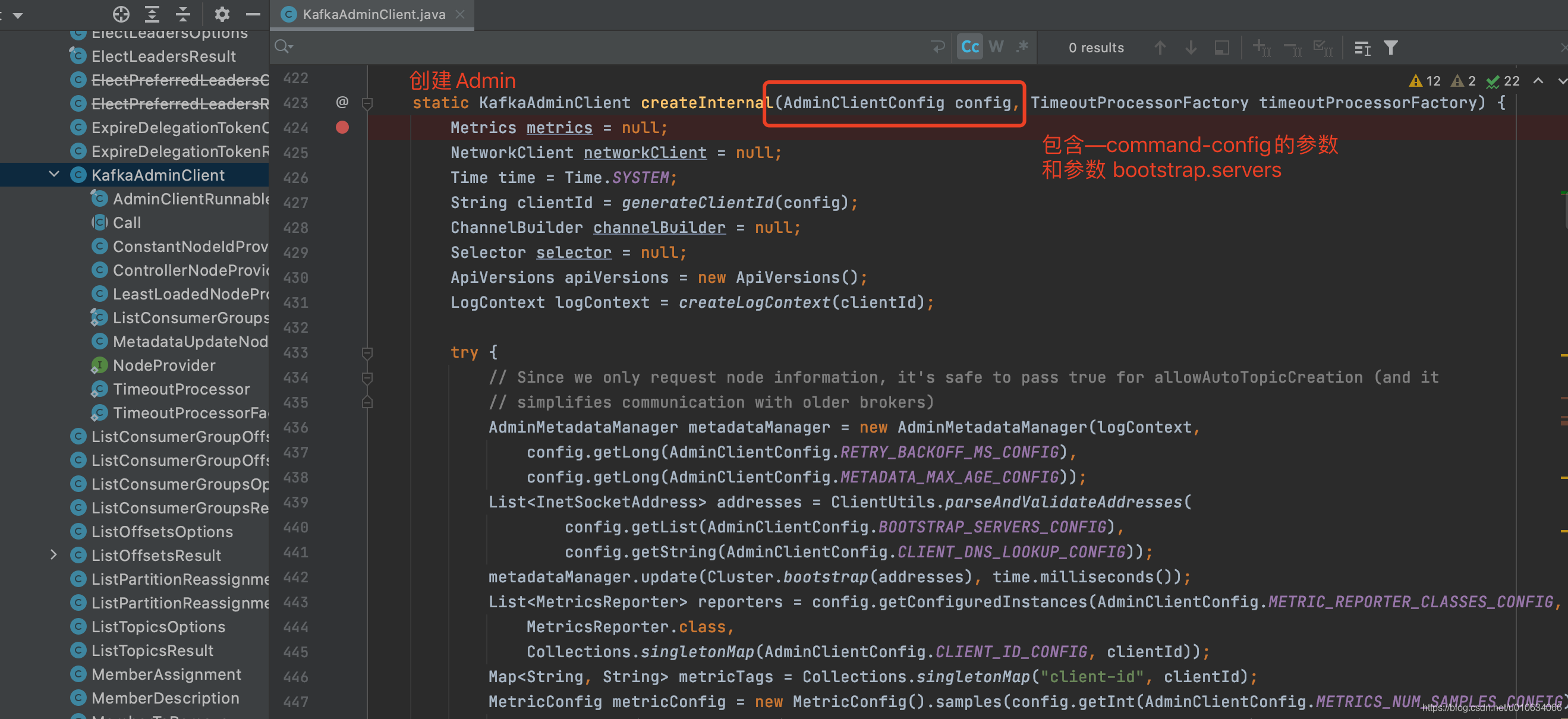
3. AdminClientTopicService.createTopic 創建Topic
topicService.createTopic(opts)
case class AdminClientTopicService private (adminClient: Admin) extends TopicService {
override def createTopic(topic: CommandTopicPartition): Unit = {
//如果配置了副本副本數--replication-factor 一定要大于0
if (topic.replicationFactor.exists(rf => rf > Short.MaxValue || rf < 1))
throw new IllegalArgumentException(s"The replication factor must be between 1 and ${Short.MaxValue} inclusive")
//如果配置了--partitions 磁區數 必須大于0
if (topic.partitions.exists(partitions => partitions < 1))
throw new IllegalArgumentException(s"The partitions must be greater than 0")
//查詢是否已經存在該Topic
if (!adminClient.listTopics().names().get().contains(topic.name)) {
val newTopic = if (topic.hasReplicaAssignment)
//如果指定了--replica-assignment引數;則按照指定的來分配副本
new NewTopic(topic.name, asJavaReplicaReassignment(topic.replicaAssignment.get))
else {
new NewTopic(
topic.name,
topic.partitions.asJava,
topic.replicationFactor.map(_.toShort).map(Short.box).asJava)
}
// 將配置--config 決議成一個配置map
val configsMap = topic.configsToAdd.stringPropertyNames()
.asScala
.map(name => name -> topic.configsToAdd.getProperty(name))
.toMap.asJava
newTopic.configs(configsMap)
//呼叫adminClient創建Topic
val createResult = adminClient.createTopics(Collections.singleton(newTopic))
createResult.all().get()
println(s"Created topic ${topic.name}.")
} else {
throw new IllegalArgumentException(s"Topic ${topic.name} already exists")
}
}
- 檢查各項入參是否有問題
adminClient.listTopics(),然后比較是否已經存在待創建的Topic;如果存在拋出例外;- 判斷是否配置了引數
--replica-assignment; 如果配置了,那么Topic就會按照指定的方式來配置副本情況 - 決議配置
--config配置放到configsMap中;configsMap給到NewTopic物件 - 呼叫
adminClient.createTopics創建Topic; 它是如何創建Topic的呢?往下分析原始碼
3.1 KafkaAdminClient.createTopics(NewTopic) 創建Topic
@Override
public CreateTopicsResult createTopics(final Collection<NewTopic> newTopics,
final CreateTopicsOptions options) {
//省略部分原始碼...
Call call = new Call("createTopics", calcDeadlineMs(now, options.timeoutMs()),
new ControllerNodeProvider()) {
@Override
public CreateTopicsRequest.Builder createRequest(int timeoutMs) {
return new CreateTopicsRequest.Builder(
new CreateTopicsRequestData().
setTopics(topics).
setTimeoutMs(timeoutMs).
setValidateOnly(options.shouldValidateOnly()));
}
@Override
public void handleResponse(AbstractResponse abstractResponse) {
//省略
}
@Override
void handleFailure(Throwable throwable) {
completeAllExceptionally(topicFutures.values(), throwable);
}
};
}
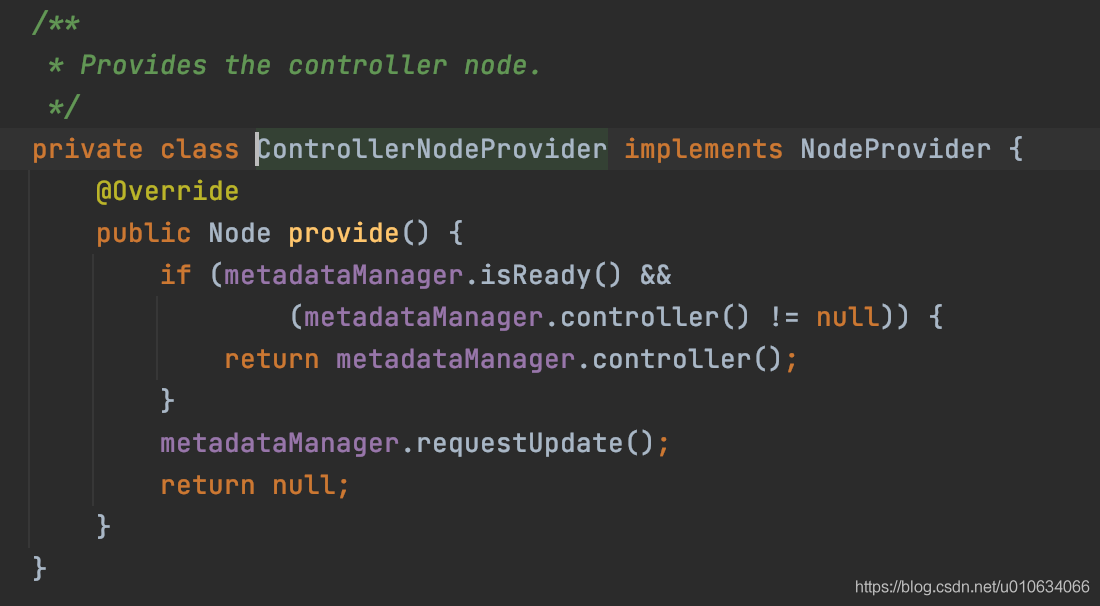
這個代碼里面主要看下Call里面的介面; 先不管Kafka如何跟服務端進行通信的細節; 我們主要關注創建Topic的邏輯;
createRequest會構造一個請求引數CreateTopicsRequest例如下圖

- 選擇ControllerNodeProvider這個節點發起網路請求

可以清楚的看到, 創建Topic這個操作是需要Controller來執行的;
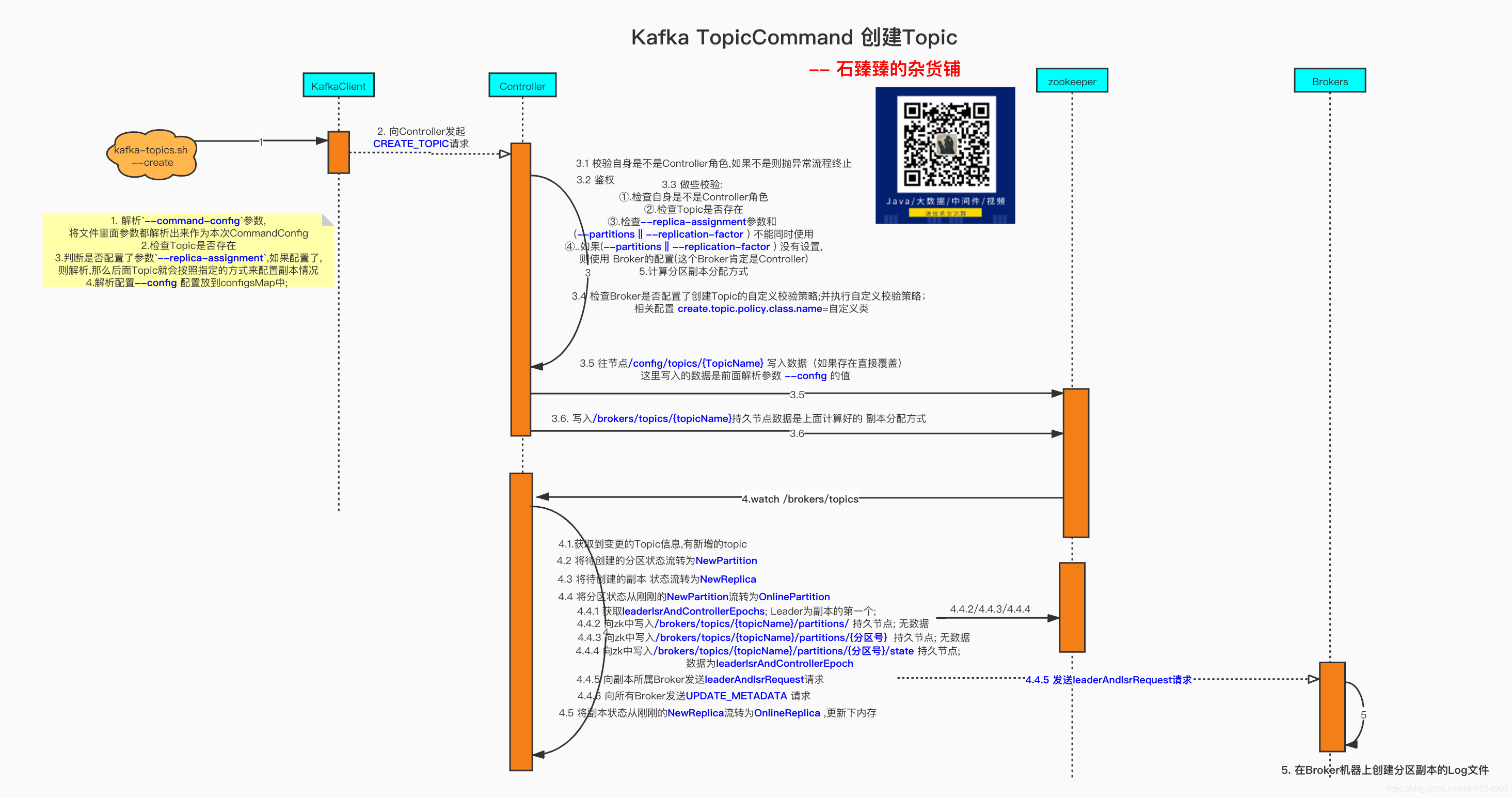
4. 發起網路請求
==>服務端客戶端網路模型
5. Controller角色的服務端接受請求處理邏輯
首先找到服務端處理客戶端請求的 原始碼入口 ? KafkaRequestHandler.run()
主要看里面的 apis.handle(request) 方法; 可以看到客戶端的請求都在request.bodyAndSize()里面
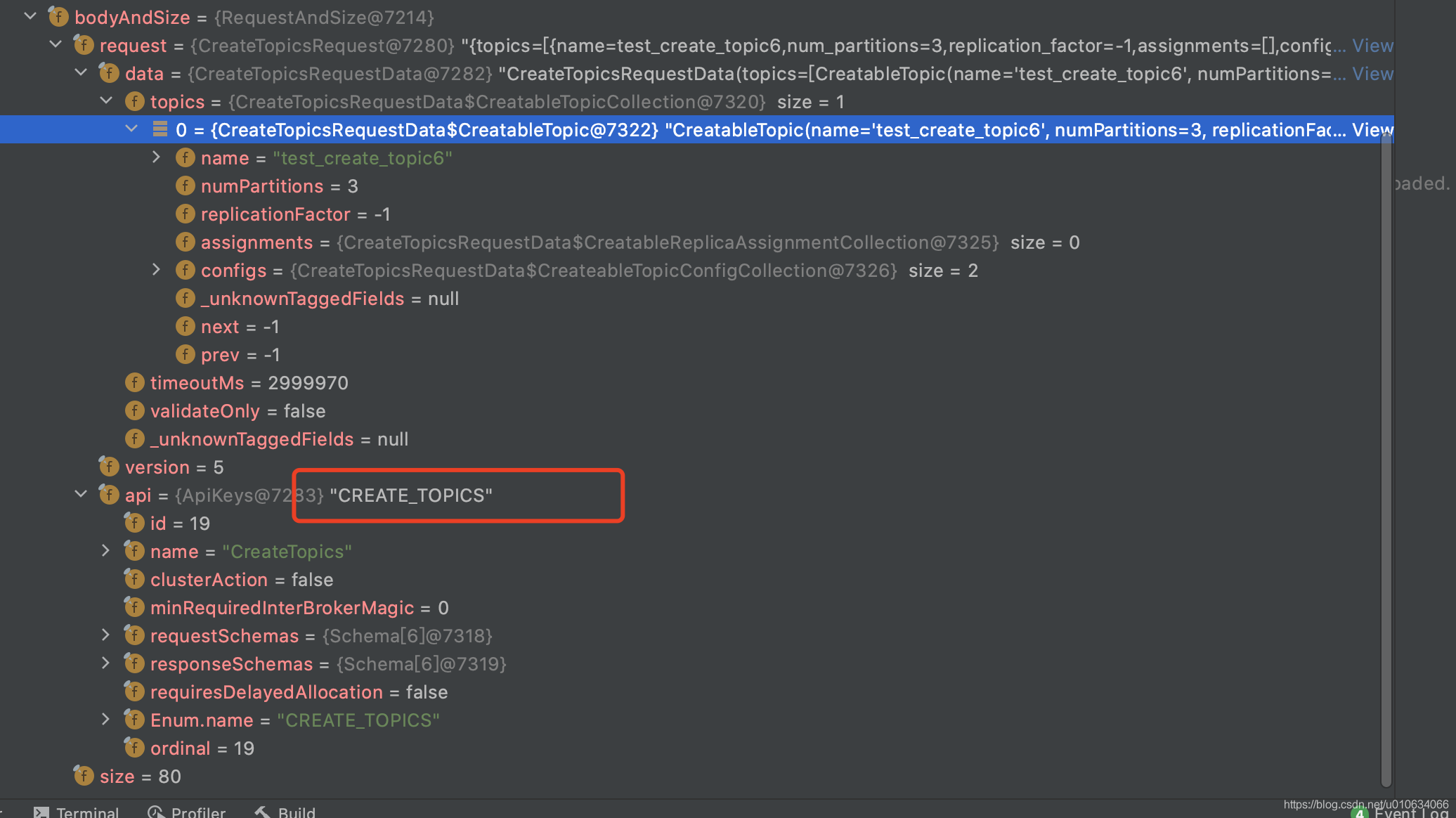
5.1 KafkaApis.handle(request) 根據請求傳遞Api呼叫不同介面
進入方法可以看到根據request.header.apiKey 呼叫對應的方法,客戶端傳過來的是CreateTopics
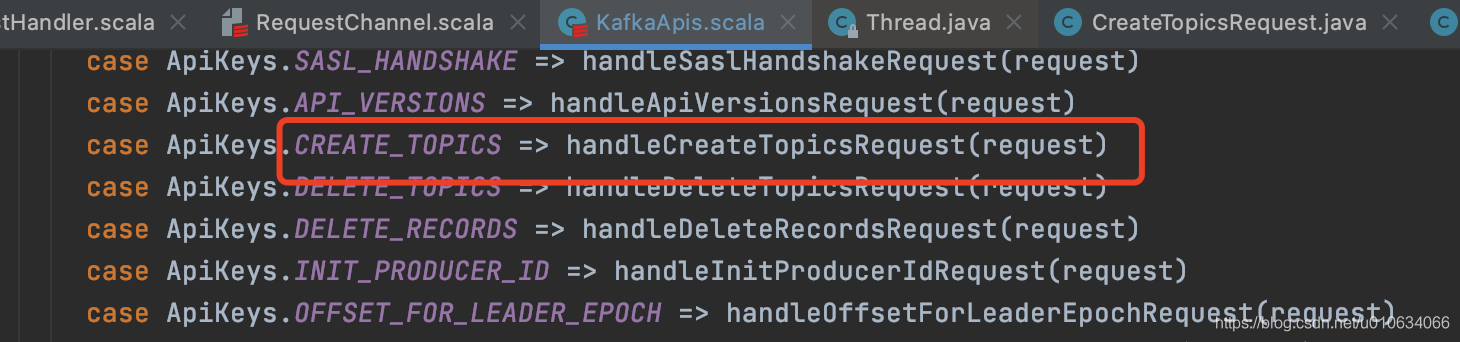
5.2 KafkaApis.handleCreateTopicsRequest 處理創建Topic的請求
def handleCreateTopicsRequest(request: RequestChannel.Request): Unit = {
// 部分代碼省略
//如果當前Broker不是屬于Controller的話,就拋出例外
if (!controller.isActive) {
createTopicsRequest.data.topics.asScala.foreach { topic =>
results.add(new CreatableTopicResult().setName(topic.name).
setErrorCode(Errors.NOT_CONTROLLER.code))
}
sendResponseCallback(results)
} else {
// 部分代碼省略
}
adminManager.createTopics(createTopicsRequest.data.timeoutMs,
createTopicsRequest.data.validateOnly,
toCreate,
authorizedForDescribeConfigs,
handleCreateTopicsResults)
}
}
- 判斷當前處理的broker是不是Controller,如果不是Controller的話直接拋出例外,從這里可以看出,CreateTopic這個操作必須是Controller來進行, 出現這種情況有可能是客戶端發起請求的時候Controller已經變更;
- 鑒權 【Kafka原始碼】kafka鑒權機制
- 呼叫
adminManager.createTopics()
5.3 adminManager.createTopics()
創建主題并等等主題完全創建,回呼函式將會在超時、錯誤、或者主題創建完成時觸發
該方法過長,省略部分代碼
def createTopics(timeout: Int,
validateOnly: Boolean,
toCreate: Map[String, CreatableTopic],
includeConfigsAndMetatadata: Map[String, CreatableTopicResult],
responseCallback: Map[String, ApiError] => Unit): Unit = {
// 1. map over topics creating assignment and calling zookeeper
val brokers = metadataCache.getAliveBrokers.map { b => kafka.admin.BrokerMetadata(b.id, b.rack) }
val metadata = toCreate.values.map(topic =>
try {
//省略部分代碼
//檢查Topic是否存在
//檢查 --replica-assignment引數和 (--partitions || --replication-factor ) 不能同時使用
// 如果(--partitions || --replication-factor ) 沒有設定,則使用 Broker的配置(這個Broker肯定是Controller)
// 計算磁區副本分配方式
createTopicPolicy match {
case Some(policy) =>
//省略部分代碼
adminZkClient.validateTopicCreate(topic.name(), assignments, configs)
if (!validateOnly)
adminZkClient.createTopicWithAssignment(topic.name, configs, assignments)
case None =>
if (validateOnly)
//校驗創建topic的引數準確性
adminZkClient.validateTopicCreate(topic.name, assignments, configs)
else
//把topic相關資料寫入到zk中
adminZkClient.createTopicWithAssignment(topic.name, configs, assignments)
}
}
-
做一些校驗檢查
①.檢查Topic是否存在
②. 檢查--replica-assignment引數和 (--partitions || --replication-factor) 不能同時使用
③.如果(--partitions || --replication-factor) 沒有設定,則使用 Broker的配置(這個Broker肯定是Controller)
④.計算磁區副本分配方式 -
createTopicPolicy根據Broker是否配置了創建Topic的自定義校驗策略; 使用方式是自定義實作org.apache.kafka.server.policy.CreateTopicPolicy介面;并 在服務器配置create.topic.policy.class.name=自定義類; 比如我就想所有創建Topic的請求磁區數都要大于10; 那么這里就可以實作你的需求了 -
createTopicWithAssignment把topic相關資料寫入到zk中; 進去分析一下
5.4 寫入zookeeper資料
我們進入到adminZkClient.createTopicWithAssignment(topic.name, configs, assignments)看看有哪些資料寫入到了zk中;
def createTopicWithAssignment(topic: String,
config: Properties,
partitionReplicaAssignment: Map[Int, Seq[Int]]): Unit = {
validateTopicCreate(topic, partitionReplicaAssignment, config)
// 將topic單獨的配置寫入到zk中
zkClient.setOrCreateEntityConfigs(ConfigType.Topic, topic, config)
// 將topic磁區相關資訊寫入zk中
writeTopicPartitionAssignment(topic, partitionReplicaAssignment.mapValues(ReplicaAssignment(_)).toMap, isUpdate = false)
}
原始碼就不再深入了,這里直接詳細說明一下
寫入Topic配置資訊
- 先呼叫
SetDataRequest請求往節點/config/topics/Topic名稱寫入資料; 這里
一般這個時候都會回傳NONODE (NoNode);節點不存在; 假如zk已經存在節點就直接覆寫掉 - 節點不存在的話,就發起
CreateRequest請求,寫入資料; 并且節點型別是持久節點
這里寫入的資料,是我們入參時候傳的topic配置--config; 這里的配置會覆寫默認配置
寫入Topic磁區副本資訊
- 將已經分配好的副本分配策略寫入到
/brokers/topics/Topic名稱中; 節點型別 持久節點
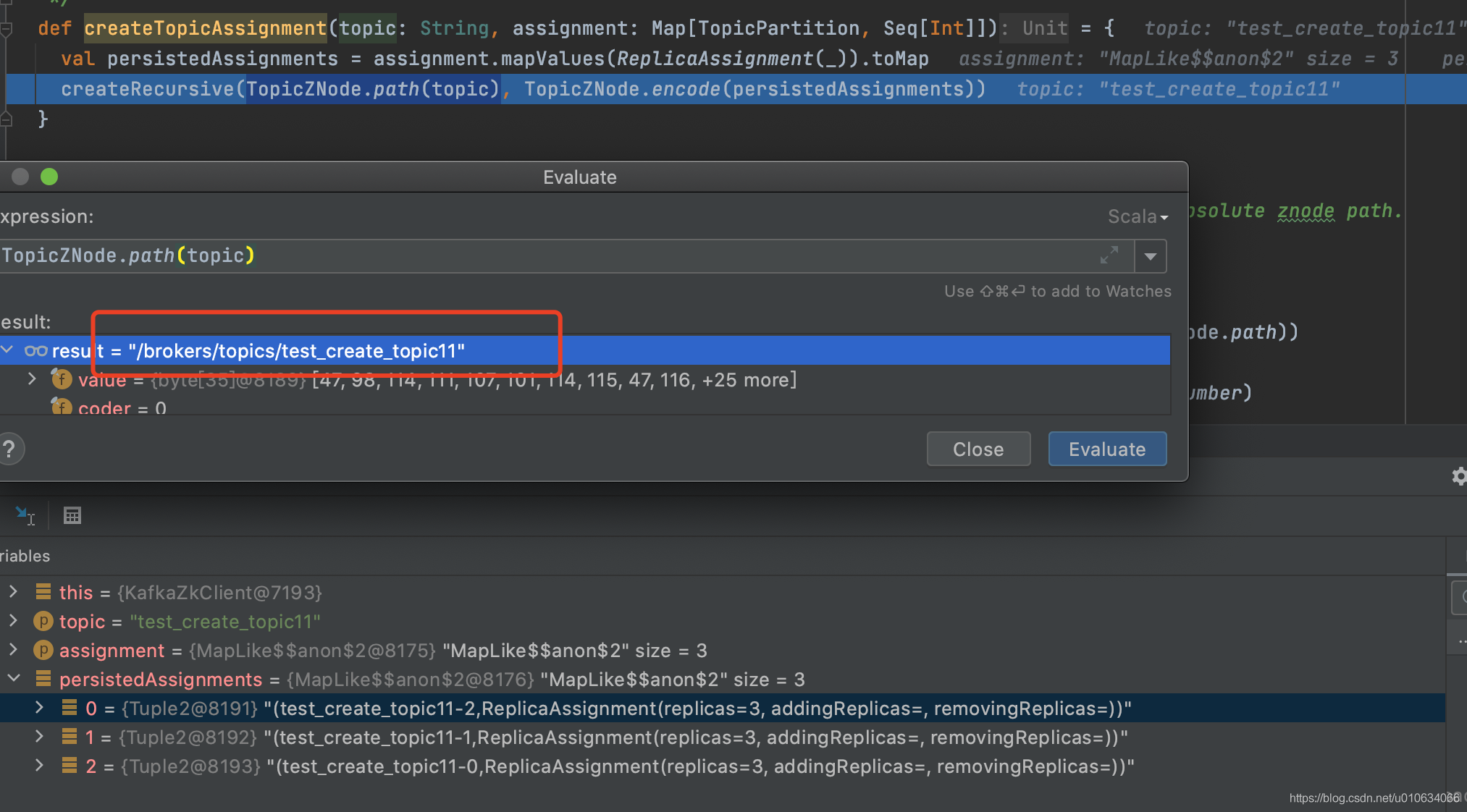
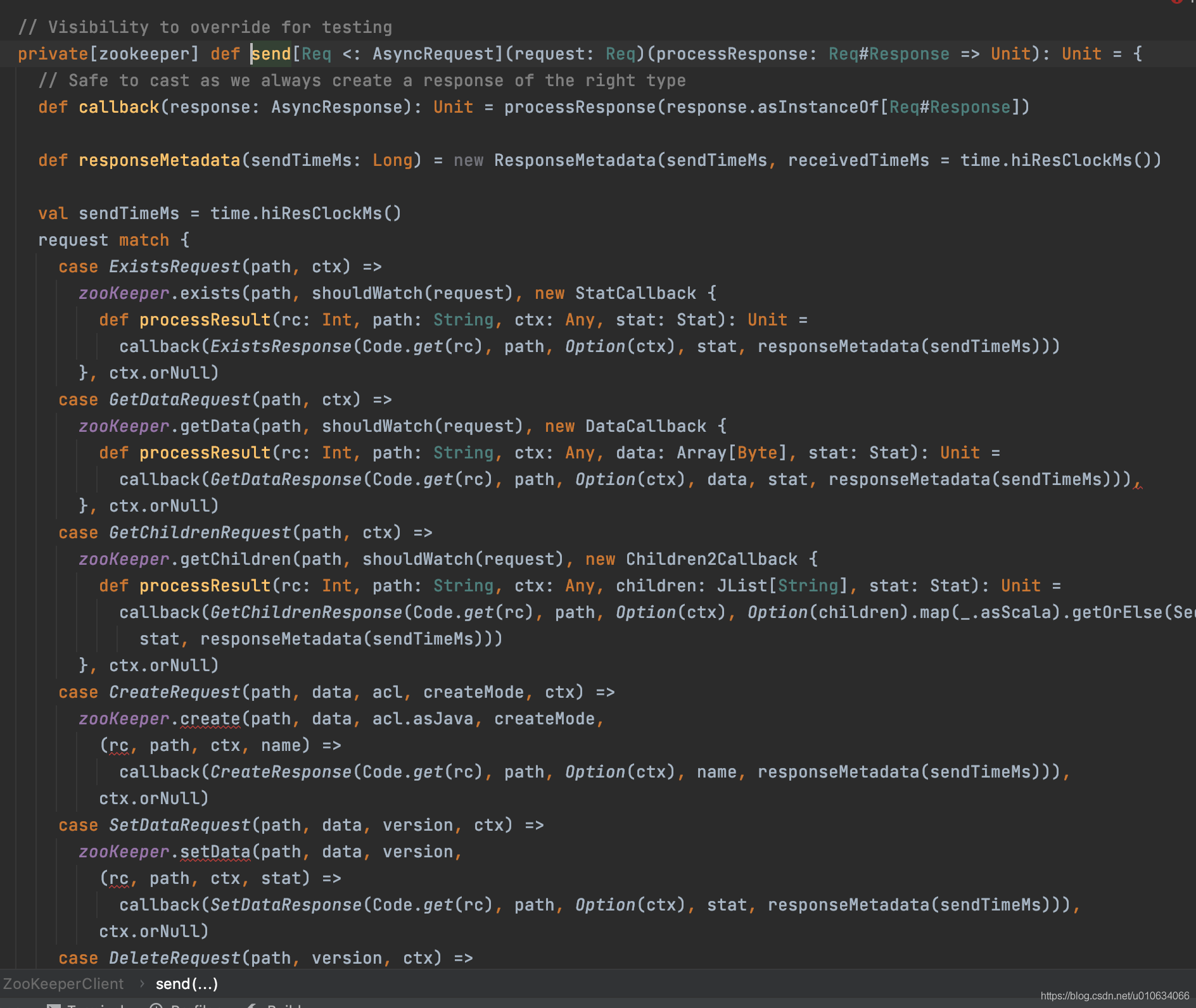
具體跟zk互動的地方在
ZookeeperClient.send() 這里包裝了很多跟zk的互動;
6. Controller監聽 /brokers/topics/Topic名稱, 通知Broker將磁區寫入磁盤
Controller 有監聽zk上的一些節點; 在上面的流程中已經在zk中寫入了
/brokers/topics/Topic名稱; 這個時候Controller就監聽到了這個變化并相應;
KafkaController.processTopicChange
private def processTopicChange(): Unit = {
//如果處理的不是Controller角色就回傳
if (!isActive) return
//從zk中獲取 `/brokers/topics 所有Topic
val topics = zkClient.getAllTopicsInCluster
//找出哪些是新增的
val newTopics = topics -- controllerContext.allTopics
//找出哪些Topic在zk上被洗掉了
val deletedTopics = controllerContext.allTopics -- topics
controllerContext.allTopics = topics
registerPartitionModificationsHandlers(newTopics.toSeq)
val addedPartitionReplicaAssignment = zkClient.getFullReplicaAssignmentForTopics(newTopics)
deletedTopics.foreach(controllerContext.removeTopic)
addedPartitionReplicaAssignment.foreach {
case (topicAndPartition, newReplicaAssignment) => controllerContext.updatePartitionFullReplicaAssignment(topicAndPartition, newReplicaAssignment)
}
info(s"New topics: [$newTopics], deleted topics: [$deletedTopics], new partition replica assignment " +
s"[$addedPartitionReplicaAssignment]")
if (addedPartitionReplicaAssignment.nonEmpty)
onNewPartitionCreation(addedPartitionReplicaAssignment.keySet)
}
-
從zk中獲取
/brokers/topics所有Topic跟當前Broker記憶體中所有BrokercontrollerContext.allTopics的差異; 就可以找到我們新增的Topic; 還有在zk中被洗掉了的Broker(該Topic會在當前記憶體中remove掉) -
從zk中獲取
/brokers/topics/{TopicName}給定主題的副本分配,并保存在記憶體中
-
執行
onNewPartitionCreation;磁區狀態開始流轉
6.1 onNewPartitionCreation 狀態流轉
關于Controller的狀態機 詳情請看: 【kafka原始碼】Controller中的狀態機
/**
* This callback is invoked by the topic change callback with the list of failed brokers as input.
* It does the following -
* 1. Move the newly created partitions to the NewPartition state
* 2. Move the newly created partitions from NewPartition->OnlinePartition state
*/
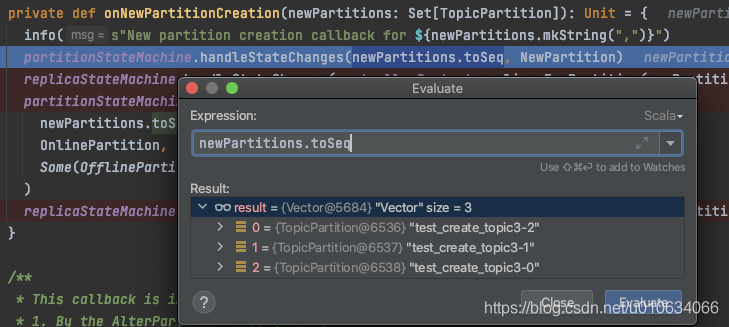
private def onNewPartitionCreation(newPartitions: Set[TopicPartition]): Unit = {
info(s"New partition creation callback for ${newPartitions.mkString(",")}")
partitionStateMachine.handleStateChanges(newPartitions.toSeq, NewPartition)
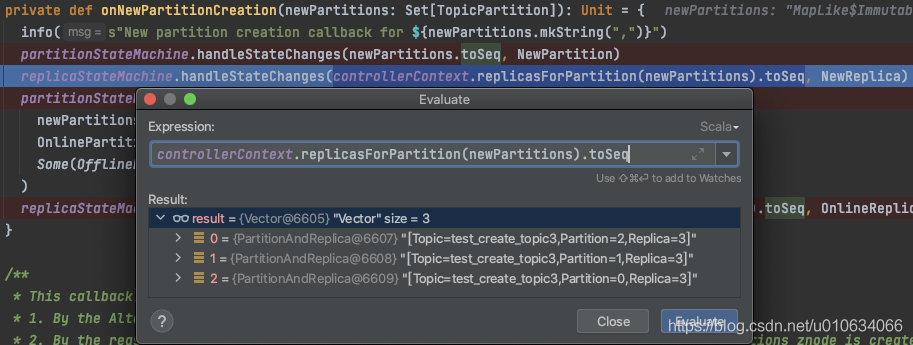
replicaStateMachine.handleStateChanges(controllerContext.replicasForPartition(newPartitions).toSeq, NewReplica)
partitionStateMachine.handleStateChanges(
newPartitions.toSeq,
OnlinePartition,
Some(OfflinePartitionLeaderElectionStrategy(false))
)
replicaStateMachine.handleStateChanges(controllerContext.replicasForPartition(newPartitions).toSeq, OnlineReplica)
}
- 將待創建的磁區狀態流轉為
NewPartition;
- 將待創建的副本 狀態流轉為
NewReplica;
- 將磁區狀態從剛剛的
NewPartition流轉為OnlinePartition
0. 獲取leaderIsrAndControllerEpochs; Leader為副本的第一個;
1. 向zk中寫入/brokers/topics/{topicName}/partitions/持久節點; 無資料
2. 向zk中寫入/brokers/topics/{topicName}/partitions/{磁區號}持久節點; 無資料
3. 向zk中寫入/brokers/topics/{topicName}/partitions/{磁區號}/state持久節點; 資料為leaderIsrAndControllerEpoch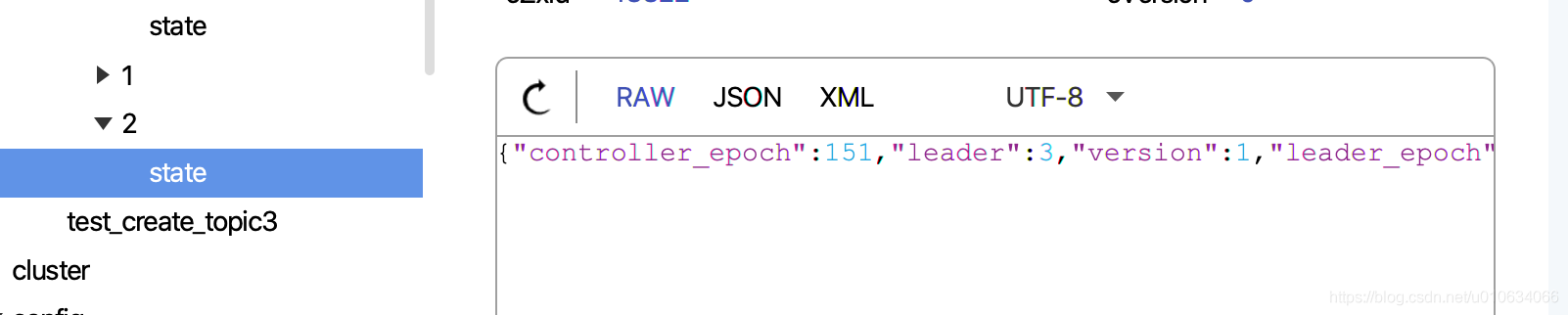
- 向副本所屬Broker發送
leaderAndIsrRequest請求 - 向所有Broker發送
UPDATE_METADATA請求
- 向副本所屬Broker發送
- 將副本狀態從剛剛的
NewReplica流轉為OnlineReplica,更新下記憶體
關于磁區狀態機和副本狀態機詳情請看【kafka原始碼】Controller中的狀態機
7. Broker收到LeaderAndIsrRequest 創建本地Log
上面步驟中有說到向副本所屬Broker發送
leaderAndIsrRequest請求,那么這里做了什么呢
其實主要做的是 創建本地Log
代碼太多,這里我們直接定位到只跟創建Topic相關的關鍵代碼來分析
KafkaApis.handleLeaderAndIsrRequest->replicaManager.becomeLeaderOrFollower->ReplicaManager.makeLeaders...LogManager.getOrCreateLog
/**
* 如果日志已經存在,只回傳現有日志的副本否則如果 isNew=true 或者如果沒有離線日志目錄,則為給定的主題和給定的磁區創建日志 否則拋出 KafkaStorageException
*/
def getOrCreateLog(topicPartition: TopicPartition, config: LogConfig, isNew: Boolean = false, isFuture: Boolean = false): Log = {
logCreationOrDeletionLock synchronized {
getLog(topicPartition, isFuture).getOrElse {
// create the log if it has not already been created in another thread
if (!isNew && offlineLogDirs.nonEmpty)
throw new KafkaStorageException(s"Can not create log for $topicPartition because log directories ${offlineLogDirs.mkString(",")} are offline")
val logDirs: List[File] = {
val preferredLogDir = preferredLogDirs.get(topicPartition)
if (isFuture) {
if (preferredLogDir == null)
throw new IllegalStateException(s"Can not create the future log for $topicPartition without having a preferred log directory")
else if (getLog(topicPartition).get.dir.getParent == preferredLogDir)
throw new IllegalStateException(s"Can not create the future log for $topicPartition in the current log directory of this partition")
}
if (preferredLogDir != null)
List(new File(preferredLogDir))
else
nextLogDirs()
}
val logDirName = {
if (isFuture)
Log.logFutureDirName(topicPartition)
else
Log.logDirName(topicPartition)
}
val logDir = logDirs
.toStream // to prevent actually mapping the whole list, lazy map
.map(createLogDirectory(_, logDirName))
.find(_.isSuccess)
.getOrElse(Failure(new KafkaStorageException("No log directories available. Tried " + logDirs.map(_.getAbsolutePath).mkString(", "))))
.get // If Failure, will throw
val log = Log(
dir = logDir,
config = config,
logStartOffset = 0L,
recoveryPoint = 0L,
maxProducerIdExpirationMs = maxPidExpirationMs,
producerIdExpirationCheckIntervalMs = LogManager.ProducerIdExpirationCheckIntervalMs,
scheduler = scheduler,
time = time,
brokerTopicStats = brokerTopicStats,
logDirFailureChannel = logDirFailureChannel)
if (isFuture)
futureLogs.put(topicPartition, log)
else
currentLogs.put(topicPartition, log)
info(s"Created log for partition $topicPartition in $logDir with properties " + s"{${config.originals.asScala.mkString(", ")}}.")
// Remove the preferred log dir since it has already been satisfied
preferredLogDirs.remove(topicPartition)
log
}
}
}
- 如果日志已經存在,只回傳現有日志的副本否則如果 isNew=true 或者如果沒有離線日志目錄,則為給定的主題和給定的磁區創建日志 否則拋出
KafkaStorageException
詳細請看 【kafka原始碼】LeaderAndIsrRequest請求
原始碼總結
如果上面的原始碼分析,你不想看,那么你可以直接看這里的簡潔敘述
- 根據是否有傳入引數
--zookeeper來判斷創建哪一種 物件topicService
如果傳入了--zookeeper則創建 類ZookeeperTopicService的物件
否則創建類AdminClientTopicService的物件(我們主要分析這個物件) - 如果有入參
--command-config,則將這個檔案里面的引數都放到mapl型別commandConfig里面, 并且也加入bootstrap.servers的引數;假如組態檔里面已經有了bootstrap.servers配置,那么會將其覆寫 - 將上面的
commandConfig作為入參呼叫Admin.create(commandConfig)創建 Admin; 這個時候呼叫的Client模塊的代碼了, 從這里我們就可以猜測,我們呼叫kafka-topic.sh腳本實際上是kafka模擬了一個客戶端Client來創建Topic的程序; - 一些例外檢查
①.如果配置了副本副本數–replication-factor 一定要大于0
②.如果配置了–partitions 磁區數 必須大于0
③.去zk查詢是否已經存在該Topic - 判斷是否配置了引數
--replica-assignment; 如果配置了,那么Topic就會按照指定的方式來配置副本情況 - 決議配置
--config配置放到configsMap中; configsMap給到NewTopic物件 - 將上面所有的引數包裝成一個請求引數
CreateTopicsRequest;然后找到是Controller的節點發起請求(ControllerNodeProvider) - 服務端收到請求之后,開始根據
CreateTopicsRequest來呼叫創建Topic的方法; 不過首先要判斷一下自己這個時候是不是Controller; 有可能這個時候Controller重新選舉了; 這個時候要拋出例外 - 服務端進行一下請求引數檢查
①.檢查Topic是否存在
②.檢查--replica-assignment引數和 (--partitions||--replication-factor) 不能同時使用 - 如果(
--partitions||--replication-factor) 沒有設定,則使用 Broker的默認配置(這個Broker肯定是Controller) - 計算磁區副本分配方式;如果是傳入了
--replica-assignment;則會安裝自定義引數進行組裝;否則的話系統會自動計算分配方式; 具體詳情請看 【kafka原始碼】創建Topic的時候是如何磁區和副本的分配規則 createTopicPolicy根據Broker是否配置了創建Topic的自定義校驗策略; 使用方式是自定義實作org.apache.kafka.server.policy.CreateTopicPolicy介面;并 在服務器配置create.topic.policy.class.name=自定義類; 比如我就想所有創建Topic的請求磁區數都要大于10; 那么這里就可以實作你的需求了- zk中寫入Topic配置資訊 發起
CreateRequest請求,這里寫入的資料,是我們入參時候傳的topic配置--config; 這里的配置會覆寫默認配置;并且節點型別是持久節點;path =/config/topics/Topic名稱 - zk中寫入Topic磁區副本資訊 發起
CreateRequest請求 ,將已經分配好的副本分配策略 寫入到/brokers/topics/Topic名稱中; 節點型別 持久節點 Controller監聽zk上面的topic資訊; 根據zk上變更的topic資訊;計算出新增/洗掉了哪些Topic; 然后拿到新增Topic的 副本分配資訊; 并做一些狀態流轉- 向新增Topic所在Broker發送
leaderAndIsrRequest請求, - Broker收到
發送leaderAndIsrRequest請求; 創建副本Log檔案;
Q&A
創建Topic的時候 在Zk上創建了哪些節點
接受客戶端請求階段:
- topic的配置資訊
/config/topics/Topic名稱持久節點- topic的磁區資訊
/brokers/topics/Topic名稱持久節點Controller監聽zk節點
/brokers/topics變更階段
/brokers/topics/{topicName}/partitions/持久節點; 無資料- 向zk中寫入
/brokers/topics/{topicName}/partitions/{磁區號}持久節點; 無資料- 向zk中寫入
/brokers/topics/{topicName}/partitions/{磁區號}/state持久節點;
創建Topic的時候 什么時候在Broker磁盤上創建的日志檔案
當Controller監聽zk節點
/brokers/topics變更之后,將新增的Topic 決議好的磁區狀態流轉
NonExistentPartition->NewPartition->OnlinePartition當流轉到OnlinePartition的時候會像磁區分配到的Broker發送一個leaderAndIsrRequest請求,當Broker們收到這個請求之后,根據請求引數做一些處理,其中就包括檢查自身有沒有這個磁區副本的本地Log;如果沒有的話就重新創建;
如果我沒有指定磁區數或者副本數,那么會如何創建
我們都知道,如果我們沒有指定磁區數或者副本數, 則默認使用Broker的配置, 那么這么多Broker,假如不小心默認值配置不一樣,那究竟使用哪一個呢? 那肯定是哪臺機器執行創建topic的程序,就是使用誰的配置;
所以是誰執行的? 那肯定是Controller啊! 上面的原始碼我們分析到了,創建的程序,會指定Controller這臺機器去進行;
如果我手動洗掉了/brokers/topics/下的某個節點會怎么樣?
詳情請看 【kafka實戰】一不小心洗掉了
/brokers/topics/下的某個Topic
如果我手動在zk中添加/brokers/topics/{TopicName}節點會怎么樣
先說結論: 根據上面分析過的原始碼畫出的時序圖可以指定; 客戶端發起創建Topic的請求,本質上是去zk里面寫兩個資料
- topic的配置資訊
/config/topics/Topic名稱持久節點- topic的磁區資訊
/brokers/topics/Topic名稱持久節點
所以我們繞過這一步驟直接去寫入資料,可以達到一樣的效果;不過我們的資料需要保證準確
因為在這一步已經沒有了一些基本的校驗了; 假如這一步我們寫入的副本Brokerid不存在會怎樣,從時序圖中可以看到,leaderAndIsrRequest請求; 就不會正確的發送的不存在的BrokerId上,那么那臺機器就不會創建Log檔案;下面不妨讓我們來驗證一下;
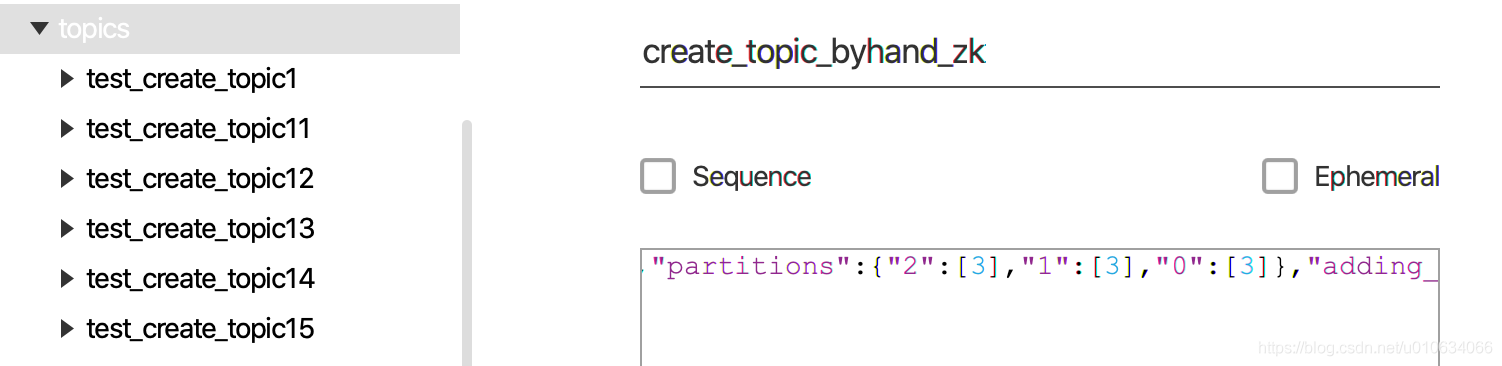
創建一個節點/brokers/topics/create_topic_byhand_zk節點資料為下面資料;{"version":2,"partitions":{"2":[3],"1":[3],"0":[3]},"adding_replicas":{},"removing_replicas":{}}
這里我用的工具PRETTYZOO手動創建的,你也可以用命令列創建;
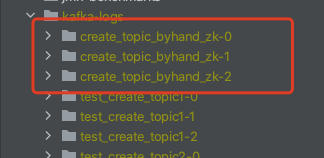
創建完成之后我們再看看本地有沒有生成一個Log檔案
可以看到我們指定的Broker,已經生成了對應的磁區副本Log檔案;
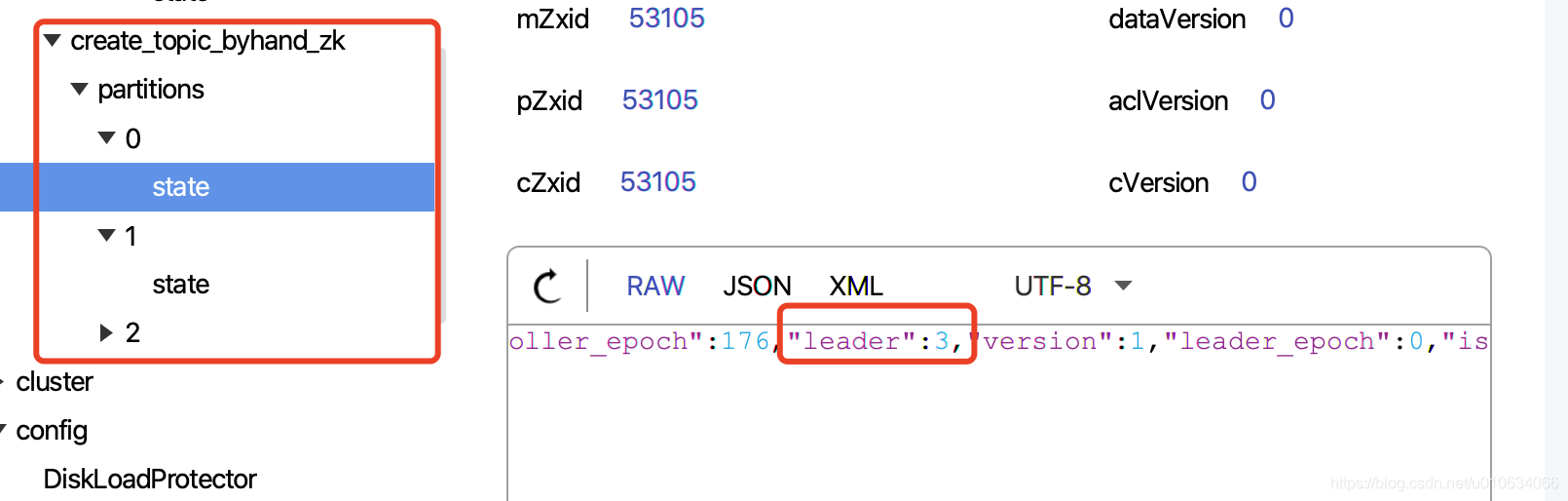
而且zk中也寫入了其他的資料
在我們寫入zk資料的時候,就已經確定好了哪個每個磁區的Leader是誰了,那就是第一個副本默認為Leader
如果寫入/brokers/topics/{TopicName}節點之后Controller掛掉了會怎么樣
先說結論:Controller 重新選舉的時候,會有一些初始化的操作; 會把創建程序繼續下去
然后我們來模擬這么一個程序,先停止集群,然后再zk中寫入
/brokers/topics/{TopicName}節點資料; 然后再啟動一臺Broker;
原始碼分析: 我們之前分析過Controller的啟動程序與選舉 有提到過,這里再提一下Controller當選之后有一個地方處理這個事情replicaStateMachine.startup() partitionStateMachine.startup()啟動狀態機的程序是不是跟上面的6.1 onNewPartitionCreation 狀態流轉 的程序很像; 最終都把狀態流轉到了
OnlinePartition; 伴隨著是不發起了leaderAndIsrRequest請求; 是不是Broker收到請求之后,創建本地Log檔案了
附件
–config 可生效引數
請以sh bin/kafka-topic -help 為準
configurations:
cleanup.policy
compression.type
delete.retention.ms
file.delete.delay.ms
flush.messages
flush.ms
follower.replication.throttled.
replicas
index.interval.bytes
leader.replication.throttled.replicas
max.compaction.lag.ms
max.message.bytes
message.downconversion.enable
message.format.version
message.timestamp.difference.max.ms
message.timestamp.type
min.cleanable.dirty.ratio
min.compaction.lag.ms
min.insync.replicas
preallocate
retention.bytes
retention.ms
segment.bytes
segment.index.bytes
segment.jitter.ms
segment.ms
unclean.leader.election.enable
Tips:如果關于本篇文章你有疑問,可以在公眾號給我留言,我會進行解答
PS: 文章閱讀的原始碼版本是kafka-2.5
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293136.html
標籤:其他