文章目錄
- 第一篇 什么是索引?
- 1、來看一個問題
- 方案1
- 方案2
- 方案3
- 方案4
- 2、索引是什么?
- 第二篇 MySQL索引原理詳解
- 1、背景
- 2、預備知識
- 什么是索引?
- 磁盤中資料的存取
- mysql中的頁
- 資料檢索程序
- 3、我們迫切的需求是什么?(資料結構和演算法)
- 3.1、回圈遍歷查找
- 3.2、二分法查找
- 3.3、有序陣列
- 3.4、鏈表
- 單鏈表
- 雙向鏈表
- 3.5、二叉查找樹
- 3.6、平衡二叉樹(AVL樹)
- 3.7、B-樹
- 3.8、B+樹
- 3.9、Mysql的存盤引擎和索引
- 3.10、頁結構
- 資料檢索程序
- 對page的結構總結一下
- 第三篇 MySQL索引管理
- 1、索引分類
- 1.1、聚集索引
- 1.2、非聚集索引(輔助索引)
- mysql中非聚集索引分為
- 1.3、資料檢索的程序
- 2、索引管理
- 2.1、創建索引
- 2.2、洗掉索引
- 2.3、查看索引
- 2.4、索引修改
- 3、示例
- 準備200萬資料
- 無索引我們體驗一下查詢速度
- 創建索引
- 創建索引并指定長度
- 查看表中的索引
- 洗掉索引
- 第四篇 如何正確使用索引
- 1、通常說的這個查詢走索引了是什么意思?
- 2、b+樹中資料檢索程序
- 2.1、唯一記錄檢索
- 2.2、查詢某個值的所有記錄
- 2.3、范圍查找
- 2.4、模糊匹配
- 查詢包含f的記錄
- 2.5、最左匹配原則
- 查詢a=1的記錄
- 查詢a=1 and b=5的記錄
- 查詢b=1的記錄
- 按照c的值查詢
- 按照b和c一起查
- 按照[a,c]兩個欄位查詢
- 查詢a=1 and b>=0 and c=1的記錄
- 3、索引區分度
- 4、正確使用索引
- 4.1、準備400萬測驗資料
- 4.2、無索引檢索效果
- 4.3、主鍵檢索
- 4.4、between and范圍檢索
- 4.5、in的檢索
- 4.6、多個索引時查詢如何走?
- 4.7、模糊查詢
- 4.8、回表
- 4.9、索引覆寫
- 4.10、索引下推
- 4.11、數字使字串類索引失效
- 4.12、函式使索引無效
- 4.13、運算子使索引無效
- 4.14、使用索引優化排序
- 5、總結一下使用索引的一些建議
第一篇 什么是索引?
1、來看一個問題
路人在搞計算機之前,是負責小區建設規劃的,上級領導安排路人負責一個萬人小區建設規劃,并提了一個要求:可以快速通過戶主姓名找到戶主的房子;讓路人出個好的解決方案,
方案1
剛開始路人沒什么經驗,實在想不到什么好辦法,
路人告訴領導:你可以去敲每戶的門,然后開門之后再去詢問房主姓名,是否和需要找的人姓名一致,
領導一聽郁悶了:我敲你的頭,1萬戶,我一個個找,找到什么時候了?你明天不用來上班了,
這里面涉及到的時間有:走到每戶的門口耗時、敲門等待開門耗時、詢問戶主獲取戶主姓名耗時、將戶主姓名和需要查找的姓名對比是否一致耗時,加入要找的人剛好在最后一戶,領導豈不是要瘋掉了,需要重復1萬次上面的操作,
上面是最原始,最耗時的做法,可能要找的人根本不在這個小區,白費力的找了1萬次,豈不是要瘋掉,
方案2
路人靈機一動,想到了一個方案:
-
給所有的戶主制定一個編號,從1-10000,戶主將戶號貼在自家的門口
-
路人自己制作了一個戶主和戶號對應的表格,我們叫做: 戶主目錄表 ,共1萬條記錄,如下:
| 戶主姓名 | 房屋編號 |
|---|---|
| 劉德華 | 00001 |
| 張學友 | 00002 |
| 路人 | 00888 |
| 路人甲java | 10000 |
此時領導要查找 路人甲Java 時,程序如下:
-
按照姓名在 戶主目錄表 查找 路人甲Java ,找到對應的編號: 10000
-
然后從第一戶房子開始找,查看其門口戶號是否是10000,直到找到為止
路人告訴領導,這個方案比方案1有以下好處:
-
如果要找的人不在這個小區,通過 戶主目錄表 就確定,不需要第二步了
-
步驟2中不需要再去敲每戶的門以及詢問戶主的姓名了,只需對比一下門口的戶號就可以了,比方
案1省了不少時間,
領導笑著說,不錯不錯,有進步,不過我找 路人甲Java 還是需要挨家挨戶看門牌號1萬次啊!,,,,,你再去想想吧,看看是否還有更好的辦法來加快查找速度,
路人下去了苦思冥想,想出了方案3,
方案3
方案2中第2步最壞的情況還是需要找1萬次,
路人去上海走了一圈,看了那邊小區搞的不錯,很多小區都是搞成一棟一棟的,每棟樓里面有100戶,路人也決定這么搞,
路人告訴領導:
-
將1萬戶劃分為100棟樓,每棟樓有25層,每層有4戶人家,總共1萬戶
-
給每棟樓一個編號,范圍是[001,100],將棟號貼在每棟樓最顯眼的位置
-
給每棟樓中的每層一個編號,編號范圍是[01,25],將層號貼在每層樓最顯眼的位置
-
戶號變為:棟號-樓層-層中編號,如 路人甲Java 戶號是:100-20-04,貼在每戶門口
戶主目錄表 還是有1萬條記錄,如下:
| 戶主姓名 | 房屋編號 |
|---|---|
| 劉德華 | 001-08-04 |
| 張學友 | 022-18-01 |
| 路人 | 088-25-04 |
| 路人甲java | 100-25-04 |
此時領導要查找 路人甲Java 時,程序如下:
-
按照姓名在 戶主目錄表 查找 路人甲Java ,找到對應的編號是 100-25-04 ,將編號分解,得到:棟號(100)、樓層(25)、樓號(04)
-
從第一棟開始找,看其棟號是否是100,直到找到編號為100為止,這個程序需要找100次,然后到了第100棟樓下
-
從100棟的第一層開始向上走,走到每層看其編號是否為25,直到走到第25層,這個程序需要匹配25次
-
在第25層依次看看戶號是否為 100-25-04 ,匹配了4次,找到了 路人甲Java
此方案分析:
-
查找 戶主目錄表 1萬次,不過這個是在表格中,不用動身走路去找,只需要動動眼睛對比一下數字,速度還是比較快的
-
將方案2中的第2步優化為上面的 2/3/4 步驟,上面最壞需要匹配129次(棟100+層25+樓號4次),相對于方案2的1萬次好多了
領導拍拍路人的肩膀:小伙子,去過上海的人確實不一樣啊,這次方案不錯,不過第一步還是需要很多次,能否有更好的方案呢?
路人下去了又想了好幾天,突然想到了我們常用的字典,可以按照字典的方式對方案3中第一步做優化,然后提出了方案4,
方案4
| 姓首字母:A | |
|---|---|
| 姓名 | 戶號 |
| 阿三 | 010-16-01 |
| 阿郎 | 017-11-04 |
| 啊啊 | 008-08-02 |
| 姓首字母:L | |
|---|---|
| 姓名 | 戶號 |
| 劉德華 | 011-16-01 |
| 路人 | 057-11-04 |
| 路人甲Java | 048-08-02 |
現在查找戶號步驟如下:
-
通過姓名獲取姓對應的首字母
-
在26個表格中找到對應姓的表格,如 路人甲Java ,對應 L表
-
在L表中回圈遍歷,找到 路人甲Java 的戶號
-
根據戶號按照方案3中的(2/3/4)步驟找對應的戶主
理想情況:
1萬戶主的姓氏分配比較均衡,那么每個姓氏下面分配385戶(10000/26) ,那么找到某個戶主,最多需要:26次+385次 = 410次,相對于1萬次少了很多,
最壞的情況:
1萬個戶主的姓氏都是一樣的,導致這1萬個戶主資訊都位于同一個姓氏戶主表,此時查詢又變為了1萬多次,不過出現姓氏一樣的情況比較低,
如果擔心姓氏不足以均衡劃分戶主資訊,那么也可以通過戶主姓名的筆畫數來劃分,或者其他方法,主要是將用戶資訊劃分為不同的區,可以快速過濾一些不相關的戶主,
上面幾個方案為了快速檢索到戶主,用到了一些資料結構,通過這些資料結構對戶主的資訊進行組織,從而可以快速過濾掉一些不相關的戶主,減少查找次數,快速定位到戶主的房子,
2、索引是什么?
通過上面的示例,我們可以概況一下索引的定義:索引是依靠某些資料結構和演算法來組織資料,最終引導用戶快速檢索出所需要的資料,
索引有2個特點:
-
通過資料結構和演算法來對原始的資料進行一些有效的組織
-
通過這些有效的組織,可以引導使用者對原始資料進行快速檢索
第二篇 MySQL索引原理詳解
1、背景
使用mysql最多的就是查詢,我們迫切的希望mysql能查詢的更快一些,我們經常用到的查詢有:
-
按照id查詢唯一一條記錄
-
按照某些個欄位查詢對應的記錄
-
查找某個范圍的所有記錄(between and)
-
對查詢出來的結果排序
mysql的索引的目的是使上面的各種查詢能夠更快,
2、預備知識
什么是索引?
上一篇中有詳細的介紹,可以過去看一下:什么是索引?
索引的本質:通過不斷地縮小想要獲取資料的范圍來篩選出最終想要的結果,同時把隨機的事件變成順
序的事件,也就是說,有了這種索引機制,我們可以總是用同一種查找方式來鎖定資料,
磁盤中資料的存取
以機械硬碟來說,先了解幾個概念,
扇區:磁盤存盤的最小單位,扇區一般大小為512Byte,
磁盤塊:檔案系統與磁盤互動的的最小單位(計算機系統讀寫磁盤的最小單位),一個磁盤塊由連續幾個(2^n)扇區組成,塊一般大小一般為4KB,
磁盤讀取資料:磁盤讀取資料靠的是機械運動,每次讀取資料花費的時間可以分為尋道時間、旋轉延遲、傳輸時間三個部分,尋道時間指的是磁臂移動到指定磁道所需要的時間,主流磁盤一般在5ms以下;旋轉延遲就是我們經常聽說的磁盤轉速,比如一個磁盤7200轉,表示每分鐘能轉7200次,也就是說1秒鐘能轉120次,旋轉延遲就是1/120/2 = 4.17ms;傳輸時間指的是從磁盤讀出或將資料寫入磁盤的時間,一般在零點幾毫秒,相對于前兩個時間可以忽略不計,那么訪問一次磁盤的時間,即一次磁盤IO的時間約等于5+4.17 = 9ms左右,聽起來還挺不錯的,但要知道一臺500 -MIPS的機器每秒可以執行5億條指令,因為指令依靠的是電的性質,換句話說執行一次IO的時間可以執行40萬條指令,資料庫動輒十萬百萬乃至千萬級資料,每次9毫秒的時間,顯然是個災難,
mysql中的頁
mysql中和磁盤互動的最小單位稱為頁,頁是mysql內部定義的一種資料結構,默認為16kb,相當于4個磁盤塊,也就是說mysql每次從磁盤中讀取一次資料是16KB,要么不讀取,要讀取就是16KB,此值可以修改的,
資料檢索程序
我們對資料存盤方式不做任何優化,直接將資料庫中表的記錄存盤在磁盤中,假如某個表只有一個欄位,為int型別,int占用4個byte,每個磁盤塊可以存盤1000條記錄,100萬的記錄需要1000個磁盤塊,如果我們需要從這100萬記錄中檢索所需要的記錄,需要讀取1000個磁盤塊的資料(需要1000次io),每次io需要9ms,那么1000次需要9000ms=9s,100條資料隨便一個查詢就是9秒,這種情況我們是無法接受的,顯然是不行的,
一個磁盤塊4kb,一條記錄4byte,4kb / 4byte = 4 * 1024 byte / 4 byte = 1024 條 (1K)
3、我們迫切的需求是什么?(資料結構和演算法)
我們迫切需要這樣的資料結構和演算法:
-
需要一種資料存盤結構:當從磁盤中檢索資料的時候能,夠減少磁盤的io次數,最好能夠降低到一個穩定的常量值
-
需要一種檢索演算法:當從磁盤中讀取磁盤塊的資料之后,這些塊中可能包含多條記錄,這些記錄被加載到記憶體中,那么需要一種演算法能夠快速從記憶體多條記錄中快速檢索出目標資料
我們來找找,看是否能夠找到這樣的演算法和資料結構,我們看一下常見的檢索演算法和資料結構,
3.1、回圈遍歷查找
從一組無序的資料中查找目標資料,常見的方法是遍歷查詢,n條資料,時間復雜度為O(n),最快需要1次,最壞的情況需要n次,查詢效率不穩定,
3.2、二分法查找
二分法查找也稱為折半查找,用于在一個有序陣列中快速定義某一個需要查找的資料,
原理是:
先將一組無序的資料排序(升序或者降序)之后放在陣列中,此處用升序來舉例說明:用陣列中間位置的資料A和需要查找的資料F對比,如果A=F,則結束查找;如果A<F,則將查找的范圍縮小至陣列中A資料右邊的部分;如果A>F,則將查找范圍縮小至陣列中A資料左邊的部分,繼續按照上面的方法直到找到F為止,
示例:
從下列有序數字中查找數字9,程序如下
[1,2,3,4,5,6,7,8,9]
第1次查找:[1,2,3,4,5,6,7,8,9]中間位置值為5,9>5,將查找范圍縮小至5右邊的部分:[6、7、8、9]
第2次查找:[6、7、8、9]中間值為8,9>8 ,將范圍縮小至8右邊部分:[9]
第3次查找:在[9]中查找9,找到了,
可以看到查找速度是相當快的,每次查找都會使范圍減半,如果我們采用順序查找,上面資料最快需要1次,最多需要9次,而二分法查找最多只需要3次,耗時時間也比較穩定,
二分法查找時間復雜度是:O(logN)(N為資料量),100萬資料查找最多只需要20次( =1048576 )
二分法查找資料的優點:定位資料非常快,前提是:目標陣列是有序的,
3.3、有序陣列
如果我們將mysql中表的資料以有序陣列的方式存盤在磁盤中,那么我們定位資料步驟是:
-
取出目標表的所有資料,存放在一個有序陣列中
-
如果目標表的資料量非常大,從磁盤中加載到記憶體中需要的記憶體也非常大
步驟取出所有資料耗費的io次數太多,步驟2耗費的記憶體空間太大,還有新增資料的時候,為了保證陣列有序,插入資料會涉及到陣列內部資料的移動,也是比較耗時的,顯然用這種方式存盤資料是不可取的,
3.4、鏈表
鏈表相當于在每個節點上增加一些指標,可以和前面或者后面的節點連接起來,就像一列火車一樣,每節車廂相當于一個節點,車廂內部可以存盤資料,每個車廂和下一節車廂相連,
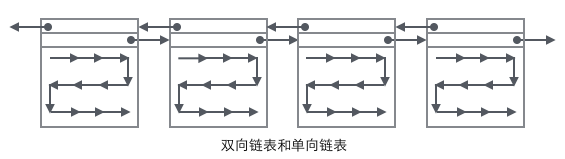
鏈表分為單鏈表和雙向鏈表,
單鏈表
每個節點中有持有指向下一個節點的指標,只能按照一個方向遍歷鏈表,結構如下:
//單項鏈表 class Node1{
private Object data;//存盤資料
private Node1 nextNode;//指向下一個節點
}
雙向鏈表
每個節點中兩個指標,分別指向當前節點的上一個節點和下一個節點,結構如下:
//雙向鏈表
class Node2{
private Object data;//存盤資料
private Node1 prevNode;//指向上一個節點
private Node1 nextNode;//指向下一個節點
}
鏈表的優點:
-
可以快速定位到上一個或者下一個節點
-
可以快速洗掉資料,只需改變指標的指向即可,這點比陣列好
鏈表的缺點:
-
無法向陣列那樣,通過下標隨機訪問資料
-
查找資料需從第一個節點開始遍歷,不利于資料的查找,查找時間和無需資料類似,需要全遍歷,最差時間是O(N)
3.5、二叉查找樹
二叉樹是每個結點最多有兩個子樹的樹結構,通常子樹被稱作“左子樹”(left subtree)和“右子樹” (right subtree),二叉樹常被用于實作二叉查找樹和二叉堆,二叉樹有如下特性:
- 每個結點都包含一個元素以及n個子樹,這里0≤n≤2, 2、左子樹和右子樹是有順序的,次序不能任意顛倒,左子樹的值要小于父結點,右子樹的值要大于父結點,
陣列[20,10,5,15,30,25,35]使用二叉查找樹存盤如下:
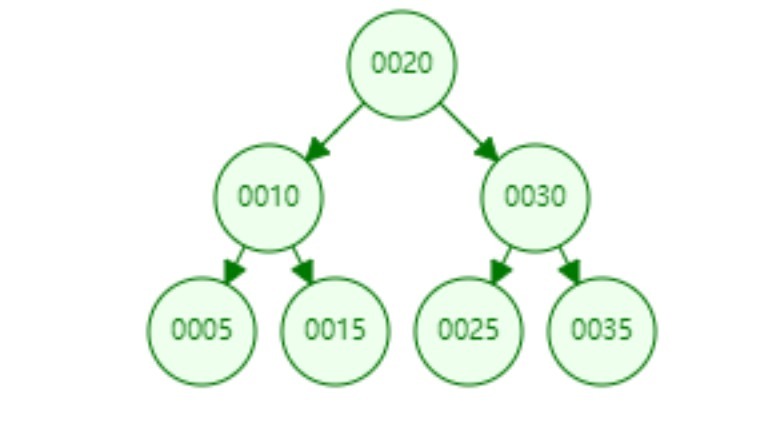
每個節點上面有兩個指標(left,rigth),可以通過這2個指標快速訪問左右子節點,檢索任何一個資料最多只需要訪問3個節點,相當于訪問了3次資料,時間為O(logN),和二分法查找效率一樣,查詢資料還是比較快的,
但是如果我們插入資料是有序的,如[5,10,15,20,30,25,35],那么結構就變成下面這樣:
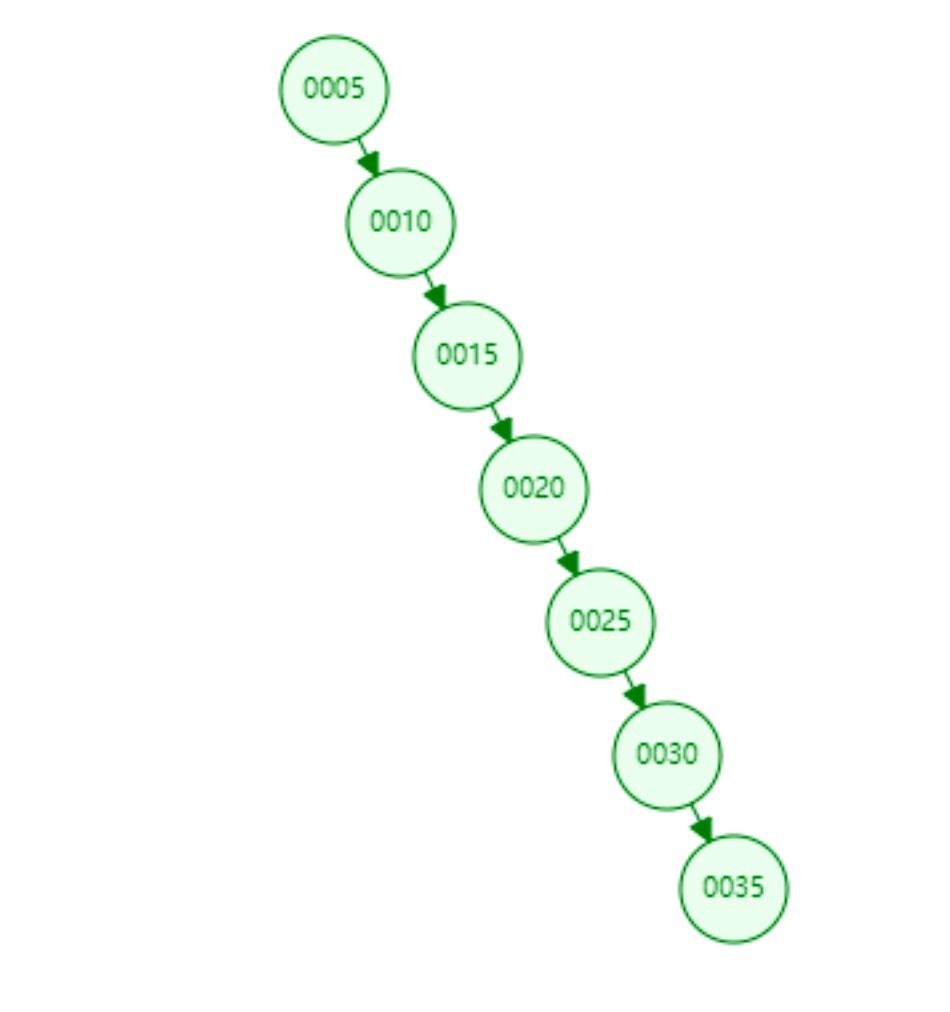
二叉樹退化為了一個鏈表結構,查詢資料最差就變為了O(N),
二叉樹的優缺點:
-
查詢資料的效率不穩定,若樹左右比較平衡的時,最差情況為O(logN),如果插入資料是有序的,退化為了鏈表,查詢時間變成了O(N)
-
資料量大的情況下,會導致樹的高度變高,如果每個節點對應磁盤的一個塊來存盤一條資料,需io次數大幅增加,顯然用此結構來存盤資料是不可取的
3.6、平衡二叉樹(AVL樹)
平衡二叉樹是一種特殊的二叉樹,所以他也滿足前面說到的二叉查找樹的兩個特性,同時還有一個特性:
- 它的左右兩個子樹的高度差的絕對值不超過1,并且左右兩個子樹都是一棵平衡二叉樹,
平衡二叉樹相對于二叉樹來說,樹的左右比較平衡,不會出現二叉樹那樣退化成鏈表的情況,不管怎么插入資料,最終通過一些調整,都能夠保證樹左右高度相差不大于1,
這樣可以讓查詢速度比較穩定,查詢中遍歷節點控制在O(logN)范圍內
如果資料都存盤在記憶體中,采用AVL樹來存盤,還是可以的,查詢效率非常高,不過我們的資料是存在磁盤中,用過采用這種結構,每個節點對應一個磁盤塊,資料量大的時候,也會和二叉樹一樣,會導致樹的高度變高,增加了io次數,顯然用這種結構存盤資料也是不可取的,
3.7、B-樹
B杠樹 ,千萬不要讀作B減樹了,B-樹在是平衡二叉樹上進化來的,前面介紹的幾種樹,每個節點上面只有一個元素,而B-樹節點中可以放多個元素,主要是為了降低樹的高度,
一棵m階的B-Tree有如下特性【特征描述的有點繞,看不懂的可以跳過,看后面的圖】:
-
每個節點最多有m個孩子,m稱為b樹的階
-
除了根節點和葉子節點外,其它每個節點至少有Ceil(m/2)個孩子
-
若根節點不是葉子節點,則至少有2個孩子
-
所有葉子節點都在同一層,且不包含其它關鍵字資訊
-
每個非終端節點包含n個關鍵字(健值)資訊
-
關鍵字的個數n滿足:ceil(m/2)-1 <= n <= m-1
-
ki(i=1,…n)為關鍵字,且關鍵字升序排序
-
Pi(i=1,…n)為指向子樹根節點的指標,P(i-1)指向的子樹的所有節點關鍵字均小于ki,但都大于k(i-1)
B-Tree結構的資料可以讓系統高效的找到資料所在的磁盤塊,為了描述B-Tree,首先定義一條記錄為一個二元組[key, data] ,key為記錄的鍵值,對應表中的主鍵值,data為一行記錄中除主鍵外的資料,對于不同的記錄,key值互不相同,
B-Tree中的每個節點根據實際情況可以包含大量的關鍵字資訊和分支,如下圖所示為一個3階的B-Tree:
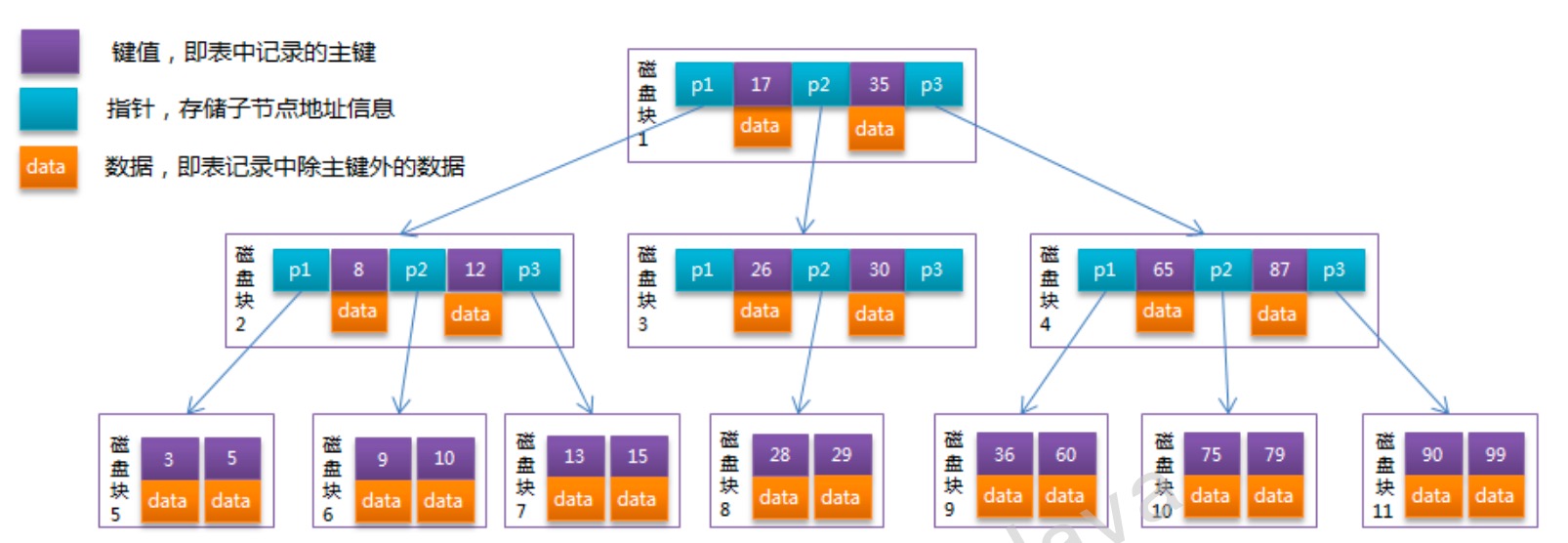
每個節點占用一個盤塊的磁盤空間,一個節點上有兩個升序排序的關鍵字和三個指向子樹根節點的指標,指標存盤的是子節點所在磁盤塊的地址,兩個鍵將資料劃分成的三個范圍域,對應三個指標指向的子樹的資料的范圍域,以根節點為例,關鍵字為17和35,P1指標指向的子樹的資料范圍為小于17,P2指標指向的子樹的資料范圍為17~35,P3指標指向的子樹的資料范圍為大于35,
模擬查找關鍵字29的程序:
-
根據根節點找到磁盤塊1,讀入記憶體,【磁盤I/O操作第1次】
-
比較關鍵字29在區間(17,35),找到磁盤塊1的指標P2
-
根據P2指標找到磁盤塊3,讀入記憶體,【磁盤I/O操作第2次】
-
比較關鍵字29在區間(26,30),找到磁盤塊3的指標P2
-
根據P2指標找到磁盤塊8,讀入記憶體,【磁盤I/O操作第3次】
-
在磁盤塊8中的關鍵字串列中找到關鍵字29
分析上面程序,發現需要3次磁盤I/O操作,和3次記憶體查找操作,由于記憶體中的關鍵字是一個有序表結構,可以利用二分法快速定位到目標資料,而3次磁盤I/O操作是影響整個B-Tree查找效率的決定因素,B-樹相對于avl樹,通過在節點中增加節點內部資料的個數來減少磁盤的io操作,
上面我們說過mysql是采用頁方式來讀寫資料,每頁是16KB,我們用B-樹來存盤mysql的記錄,每個節點對應mysql中的一頁(16KB),假如每行記錄加上樹節點中的1個指標占160Byte,那么每個節點可以存盤1000(16KB/160byte)條資料,樹的高度為3的節點大概可以存盤(第一層1000+第二層10002+第三層10003)10億條記錄,是不是非常驚訝,一個高度為3個B-樹大概可以存盤10億條記錄,我們從10億記錄中查找資料只需要3次io操作可以定位到目標資料所在的頁,而頁內部的資料又是有序的,然后將其加載到記憶體中用二分法查找,是非常快的,
可以看出使用B-樹定位某個值還是很快的(10億資料中3次io操作+記憶體中二分法),但是也是有缺點的:
- B-不利于范圍查找,比如上圖中我們需要查找[15,36]區間的資料,需要訪問7個磁盤塊(1/2/7/3/8/4/9),io次數又上去了,范圍查找也是我們經常用到的,所以]b-樹也不太適合在磁盤中存盤需要檢索的資料,
3.8、B+樹
先看個b+樹結構圖:

b+樹的特征
-
每個結點至多有m個子女
-
除根結點外,每個結點至少有[m/2]個子女,根結點至少有兩個子女
-
有k個子女的結點必有k個關鍵字
-
父節點中持有訪問子節點的指標
-
父節點的關鍵字在子節點中都存在(如上面的1/20/35在每層都存在),要么是最小值,要么是最大值,如果節點中關鍵字是升序的方式,父節點的關鍵字是子節點的最小值
-
最底層的節點是葉子節點
-
除葉子節點之外,其他節點不保存資料,只保存關鍵字和指標
-
葉子節點包含了所有資料的關鍵字以及data,葉子節點之間用鏈表連接起來,可以非常方便的支
持范圍查找
b+樹與b-樹的幾點不同:
-
b+樹中一個節點如果有k個關鍵字,最多可以包含k個子節點(k個關鍵字對應k個指標);而b-樹對應k+1個子節點(多了一個指向子節點的指標)
-
b+樹除葉子節點之外其他節點值存盤關鍵字和指向子節點的指標,而b-樹還存盤了資料,這樣同樣大小情況下,b+樹可以存盤更多的關鍵字
-
b+樹葉子節點中存盤了所有關鍵字及data,并且多個節點用鏈表連接,從上圖中看子節點中資料從左向右是有序的,這樣快速可以支撐范圍查找(先定位范圍的最大值和最小值,然后子節點中依靠鏈表遍歷范圍資料)
B-Tree和B+Tree該如何選擇?
-
B-Tree因為非葉子結點也保存具體資料,所以在查找某個關鍵字的時候找到即可回傳,而B+Tree所有的資料都在葉子結點,每次查找都得到葉子結點,所以在同樣高度的B-Tree和B+Tree中,BTree查找某個關鍵字的效率更高
-
由于B+Tree所有的資料都在葉子結點,并且結點之間有指標連接,在找大于某個關鍵字或者小于某個關鍵字的資料的時候,B+Tree只需要找到該關鍵字然后沿著鏈表遍歷就可以了,而B-Tree還需要遍歷該關鍵字結點的根結點去搜索,
-
由于B-Tree的每個結點(這里的結點可以理解為一個資料頁)都存盤主鍵+實際資料,而B+Tree非葉子結點只存盤關鍵字資訊,而每個頁的大小有限是有限的,所以同一頁能存盤的B-Tree的資料會比B+Tree存盤的更少,這樣同樣總量的資料,B-Tree的深度會更大,增大查詢時的磁盤I/O次數,進而影響查詢效率,
3.9、Mysql的存盤引擎和索引
mysql內部索引是由不同的引擎實作的,主要說一下InnoDB和MyISAM這兩種引擎中的索引,這兩種引擎中的索引都是使用b+樹的結構來存盤的,
InnoDB中的索引:
Innodb中有2種索引:主鍵索引(聚集索引)、輔助索引(非聚集索引),
-
主鍵索引:每個表只有一個主鍵索引,b+樹結構,葉子節點同時保存了主鍵的值也資料記錄,其他節點只存盤主鍵的值,
-
輔助索引:每個表可以有多個,b+樹結構,葉子節點保存了索引欄位的值以及主鍵的值,其他節點只存盤索引指端的值,
MyISAM引擎中的索引:
B+樹結構,MyISM使用的是非聚簇索引,非聚簇索引的兩棵B+樹看上去沒什么不同,節點的結構完全一致只是存盤的內容不同而已,主鍵索引B+樹的節點存盤了主鍵,輔助鍵索引B+樹存盤了輔助鍵,表資料存盤在獨立的地方,這兩顆B+樹的葉子節點都使用一個地址指向真正的表資料,對于表資料來說,這兩個鍵沒有任何差別,由于索引樹是獨立的,通過輔助鍵檢索無需訪問主鍵的索引樹,
如下圖:為了更形象說明這兩種索引的區別,我們假想一個表存盤了4行資料,其中Id作為主索引,Name作為輔助索引,圖中清晰的顯示了聚簇索引和非聚簇索引的差異,
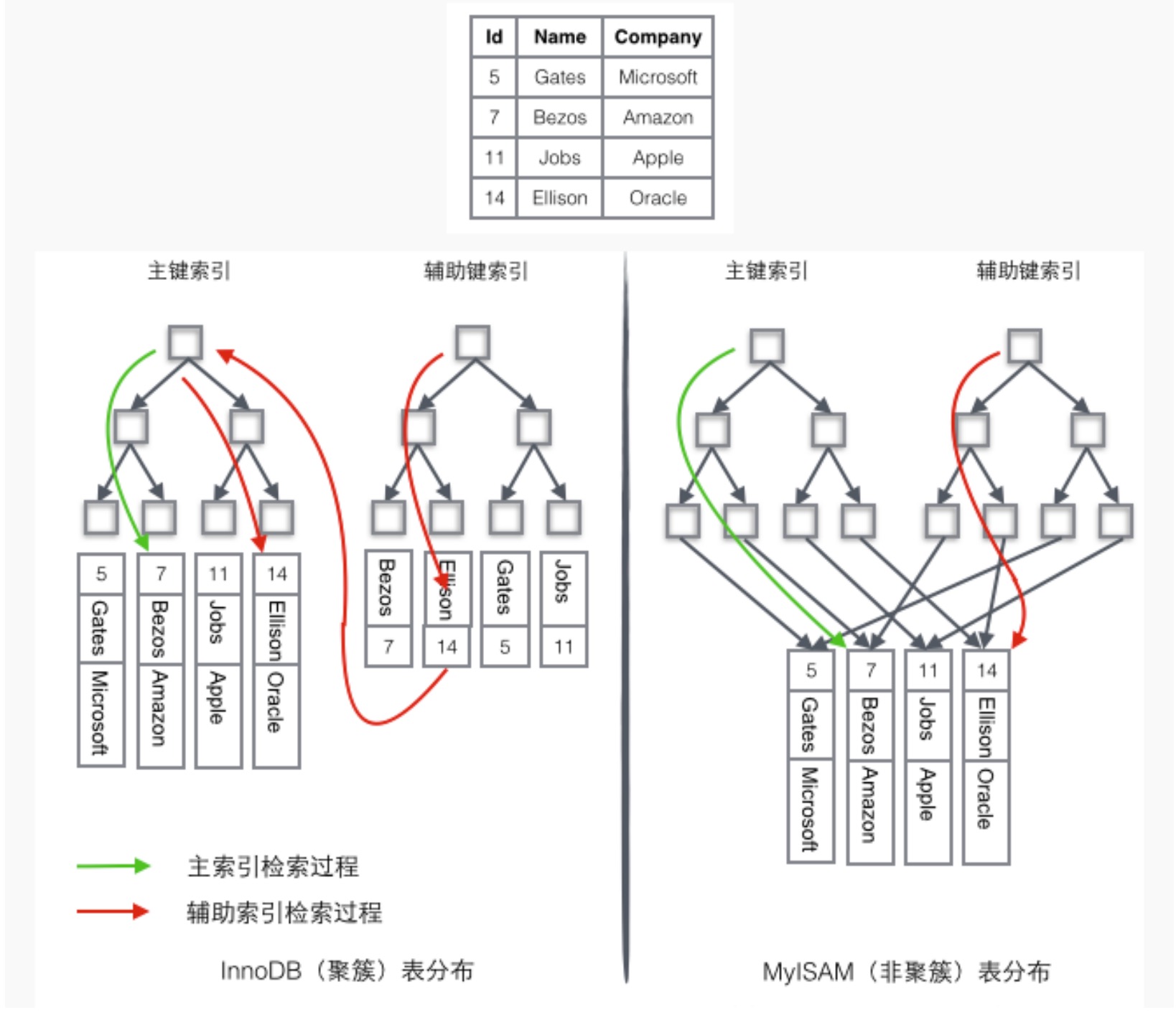
我們看一下上圖中資料檢索程序,
InnoDB資料檢索程序:
如果需要查詢id=14的資料,只需要在左邊的主鍵索引中檢索就可以了,
如果需要搜索name='Ellison’的資料,需要2步:
-
先在輔助索引中檢索到name='Ellison’的資料,獲取id為14
-
再到主鍵索引中檢索id為14的記錄
輔助索引這個查詢程序在mysql中叫做回表,
MyISAM資料檢索程序:
-
在索引中找到對應的關鍵字,獲取關鍵字對應的記錄的地址
-
通過記錄的地址查找到對應的資料記錄
我們用的最多的是innodb存盤引擎,所以此處主要說一下innodb索引的情況,innodb中最好是采用主鍵查詢,這樣只需要一次索引,如果使用輔助索引檢索,涉及到回表操作,比主鍵查詢要耗時一些,
innodb中輔助索引為什么不像myisam那樣存盤記錄的地址?
表中的資料發生變更的時候,會影響其他記錄地址的變化,如果輔助索引中記錄資料的地址,此時會受影響,而主鍵的值一般是很少更新的,當頁中的記錄發生地址變更的時候,對輔助索引是沒有影響的,我們來看一下mysql中頁的結構,頁是真正存盤記錄的地方,對應B+樹中的一個節點,也是mysql中讀寫資料的最小單位,頁的結構設計也是相當有水平的,能夠加快資料的查詢,
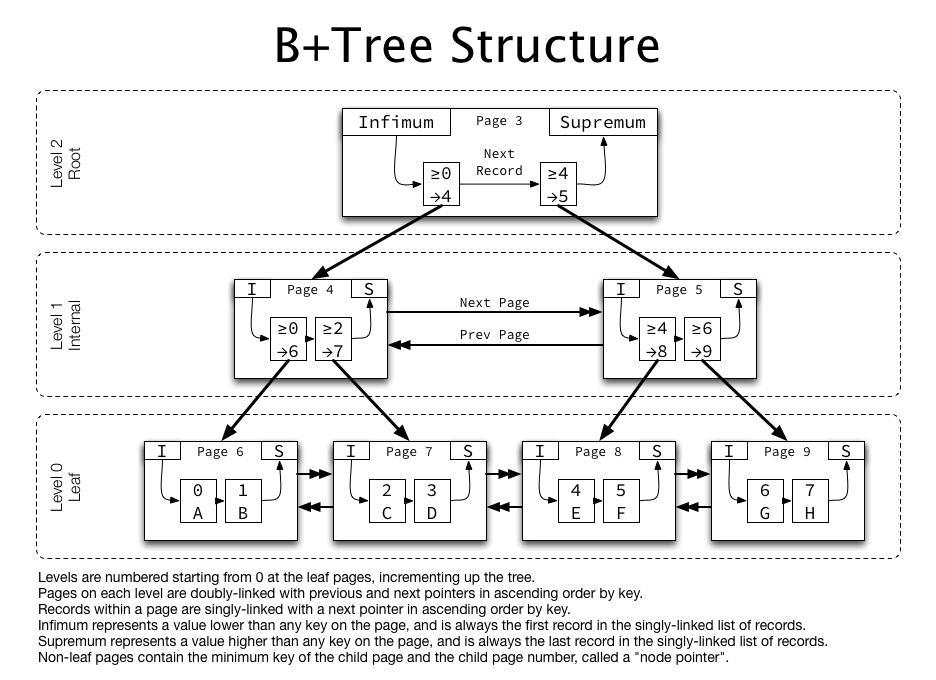
3.10、頁結構
mysql中頁是innodb中存盤資料的基本單位,也是mysql中管理資料的最小單位,和磁盤互動的時候都是以頁來進行的,默認是16kb,mysql中采用b+樹存盤資料,頁相當于b+樹中的一個節點,
頁的結構如下圖:
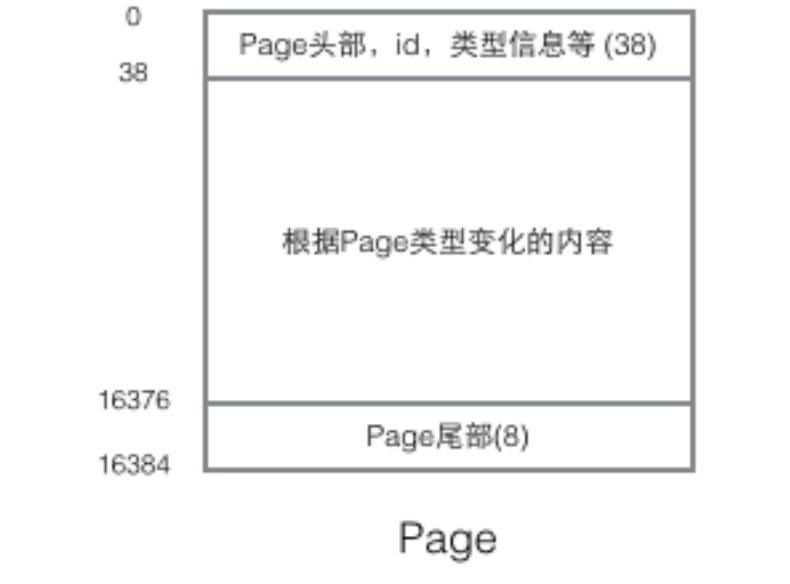
每個Page都有通用的頭和尾,但是中部的內容根據Page的型別不同而發生變化,Page的頭部里有我們關心的一些資料,下圖把Page的頭部詳細資訊顯示出來:
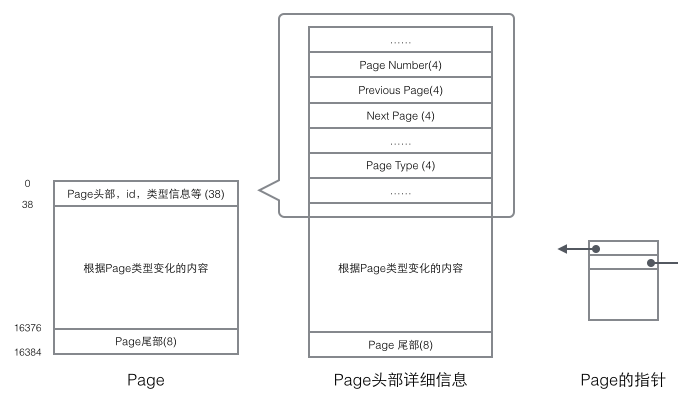
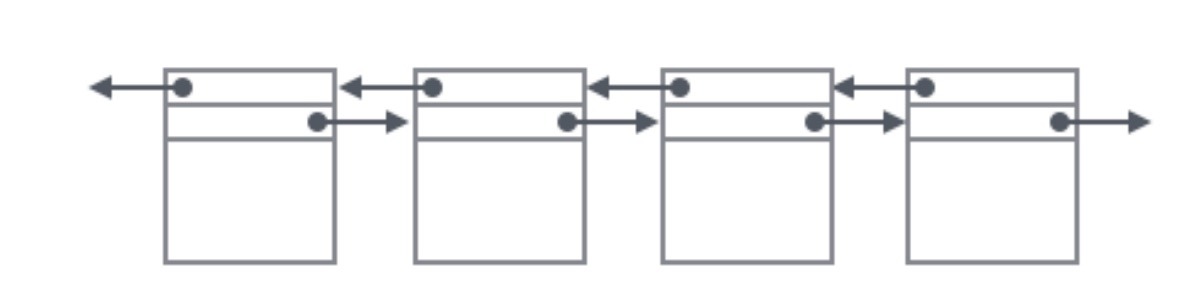
我們重點關注和資料組織結構相關的欄位:Page的頭部保存了兩個指標,分別指向前一個Page和后一個Page,根據這兩個指標我們很容易想象出Page鏈接起來就是一個雙向鏈表的結構,如下圖:
再看看Page的主體內容,我們主要關注行資料和索引的存盤,他們都位于Page的User Records部分,User Records占據Page的大部分空間,User Records由一條一條的Record組成,在一個Page內部,單鏈表的頭尾由固定內容的兩條記錄來表示,字串形式的"Infimum"代表開頭,"Supremum"代表結尾,這兩個用來代表開頭結尾的Record存盤在System Records的,Infinum、Supremum和User Records組成了一個單向鏈表結構,最初資料是按照插入的先后順序排列的,但是隨著新資料的插入和舊資料的洗掉,資料物理順序會變得混亂,但他們依然通過鏈表的方式保持著邏輯上的先后順序,如下圖:
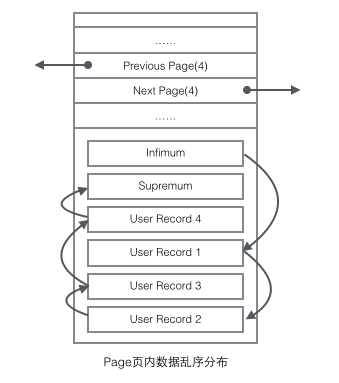
把User Record的組織形式和若干Page組合起來,就看到了稍微完整的形式,
innodb為了快速查找記錄,在頁中定義了一個稱之為page directory的目錄槽(slots),每個槽位占用兩個位元組(用于保存指向記錄的地址),page directory中的多個slot組成了一個有序陣列(可用于二分法快速定位記錄,向下看),行記錄被Page Directory邏輯的分成了多個塊,塊與塊之間是有序的,能夠加速記錄的查找,如下圖:
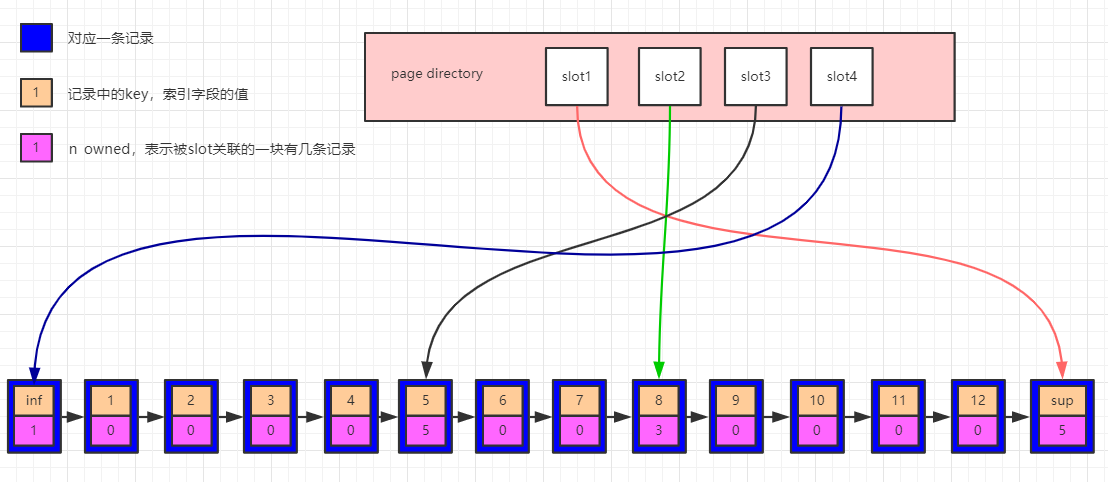
看上圖,每個行記錄的都有一個n_owned的區域(圖中粉色區域),n_owned標識所屬的slot這個這個塊有多少條資料,偽記錄Infimum的n_owned值總是1,記錄Supremum的n_owned的取值范圍為[1,8],其他用戶記錄n_owned的取值范圍[4,8],并且只有每個塊中最大的那條記錄的n_owned才會有值,其他的用戶記錄的n_owned為0,
資料檢索程序
在page中查詢資料的時候,先通過b+樹中查詢方法定位到資料所在的頁,然后將頁內整體加載到記憶體中,通過二分法在page directory中檢索資料,縮小范圍,比如需要檢索7,通過二分法查找到7位于slot2和slot3所指向的記錄中間,然后從slot3指向的記錄5開始向后向后一個個找,可以找到記錄7,如果里面沒有7,走到slot2向的記錄8結束,
n_owned范圍控制在[4,8]內,能保證每個slot管轄的范圍內資料量控制在[4,8]個,能夠加速目標資料的查找,當有資料插入的時候,page directory為了控制每個slot對應塊中記錄的個數([4,8]),此時page directory中會對slot的數量進行調整,
對page的結構總結一下
-
b+樹中葉子頁之間用雙向鏈表連接的,能夠實作范圍查找
-
頁內部的記錄之間是采用單向鏈表連接的,方便訪問下一條記錄
-
為了加快頁內部記錄的查詢,對頁內記錄上加了個有序的稀疏索引,叫頁目錄(page directory)
整體上來說mysql中的索參考到了b+樹,鏈表,二分法查找,做到了快速定位目標資料,快速范圍查找,
第三篇 MySQL索引管理
1、索引分類
分為聚集索引和非聚集索引,
1.1、聚集索引
每個表有且一定會有一個聚集索引,整個表的資料存盤在聚集索引中,mysql索引是采用B+樹結構保存在檔案中,葉子節點存盤主鍵的值以及對應記錄的資料,非葉子節點不存盤記錄的資料,只存盤主鍵的值,當表中未指定主鍵時,mysql內部會自動給每條記錄添加一個隱藏的rowid欄位(默認4個位元組)作為主鍵,用rowid構建聚集索引,
聚集索引在mysql中又叫主鍵索引,
1.2、非聚集索引(輔助索引)
也是b+樹結構,不過有一點和聚集索引不同,非聚集索引葉子節點存盤欄位(索引欄位)的值以及對應記錄主鍵的值,其他節點只存盤欄位的值(索引欄位),
每個表可以有多個非聚集索引,
mysql中非聚集索引分為
單列索引:即一個索引只包含一個列,
多列索引(又稱復合索引): 即一個索引包含多個列,
唯一索引: 索引列的值必須唯一,允許有一個空值,
1.3、資料檢索的程序
看一張圖:
上面的表中有2個索引:id作為主鍵索引,name作為輔助索引,
innodb我們用的最多,我們只看圖中左邊的innodb中資料檢索程序:
如果需要查詢id=14的資料,只需要在左邊的主鍵索引中檢索就可以了,
如果需要搜索name='Ellison’的資料,需要2步:
-
先在輔助索引中檢索到name='Ellison’的資料,獲取id為14
-
再到主鍵索引中檢索id為14的記錄
輔助索引相對于主鍵索引多了第二步,
2、索引管理
2.1、創建索引
方式1:
create [unique] index 索引名稱 on 表名(列名[(length)]);
方式2:
alter 表名 add [unique] index 索引名稱 on (列名[(length)]);
如果欄位是char、varchar型別,length可以小于欄位實際長度,如果是blog、text等長文本型別,必須指定length,
[unique]:中括號代表可以省略,如果加上了unique,表示創建唯一索引,
如果table后面只寫一個欄位,就是單列索引,如果寫多個欄位,就是復合索引,多個欄位之間用逗號隔開,
2.2、洗掉索引
drop index 索引名稱 on 表名;
2.3、查看索引
查看某個表中所有的索引資訊如下:
show index from 表名;
2.4、索引修改
可以先洗掉索引,再重建索引,
3、示例
準備200萬資料
/*建庫javacode2018*/
DROP DATABASE IF EXISTS javacode2018;
CREATE DATABASE javacode2018;
USE javacode2018;
/*建表test1*/
DROP TABLE IF EXISTS test1;
CREATE TABLE test1 (
id INT NOT NULL COMMENT '編號',
name VARCHAR(20) NOT NULL COMMENT '姓名',
sex TINYINT NOT NULL COMMENT '性別,1:男,2:女',
email VARCHAR(50)
);
/*準備資料*/
DROP PROCEDURE IF EXISTS proc1;
DELIMITER $
CREATE PROCEDURE proc1()
BEGIN
DECLARE i INT DEFAULT 1;
START TRANSACTION;
WHILE i <= 2000000 DO
INSERT INTO test1 (id, name, sex, email) VALUES (i,concat('javacode',i),if(mod(i,2),1,2),concat('javacode',i,'@163.com'));
SET i = i + 1;
if i%10000=0 THEN
COMMIT;
START TRANSACTION;
END IF;
END WHILE;
COMMIT;
END $
DELIMITER ;
CALL proc1();
SELECT count(*) FROM test1;
上圖中使用存盤程序回圈插入了200萬記錄,表中有4個欄位,除了sex列,其他列的值都是沒有重復的,表中還未建索引,
插入的200萬資料中,id,name,email的值都是沒有重復的,
無索引我們體驗一下查詢速度
mysql> select * from test1 a where a.id = 1;
+----+-----------+-----+-------------------+
| id | name | sex | email |
+----+-----------+-----+-------------------+
| 1 | javacode1 | 1 | javacode1@163.com |
+----+-----------+-----+-------------------+
1 row in set (0.77 sec)
上面我們按id查詢了一條記錄耗時770毫秒,我們在id上面創建個索引感受一下速度,
創建索引
我們在id上面創建一個索引,感受一下:
mysql> create index idx1 on test1 (id);
Query OK, 0 rows affected (2.82 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> select * from test1 a where a.id = 1;
+----+-----------+-----+-------------------+
| id | name | sex | email |
+----+-----------+-----+-------------------+
| 1 | javacode1 | 1 | javacode1@163.com |
+----+-----------+-----+-------------------+
1 row in set (0.00 sec)
上面的查詢是不是非常快,耗時1毫秒都不到,
我們在name上也創建個索引,感受一下查詢的神速,如下:
mysql> create unique index idx2 on test1(name);
Query OK, 0 rows affected (9.67 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> select * from test1 where name = 'javacode1';
+----+-----------+-----+-------------------+
| id | name | sex | email |
+----+-----------+-----+-------------------+
| 1 | javacode1 | 1 | javacode1@163.com |
+----+-----------+-----+-------------------+
1 row in set (0.00 sec)
查詢快如閃電,有沒有,索引是如此的神奇,
創建索引并指定長度
通過email檢索一下資料
mysql> select * from test1 a where a.email = 'javacode1000085@163.com';
+---------+-----------------+-----+-------------------------+
| id | name | sex | email |
+---------+-----------------+-----+-------------------------+
| 1000085 | javacode1000085 | 1 | javacode1000085@163.com |
+---------+-----------------+-----+-------------------------+
1 row in set (1.28 sec)
耗時1秒多,回頭去看一下插入資料的sql,我們可以看到所有的email記錄,每條記錄的前面15個字符是不一樣的,結尾是一樣的(都是@163.com),通過前面15個字符就可以定位一個email了,那么我們可以對email創建索引的時候指定一個長度為15,這樣相對于整個email欄位更短一些,查詢效果是一樣的,這樣一個頁中可以存盤更多的索引記錄,命令如下:
mysql> create index idx3 on test1 (email(15));
Query OK, 0 rows affected (7.67 sec)
Records: 0 Duplicates: 0 Warnings: 0
然后看一下查詢效果:
mysql> select * from test1 a where a.email = 'javacode1000085@163.com';
+---------+-----------------+-----+-------------------------+
| id | name | sex | email |
+---------+-----------------+-----+-------------------------+
| 1000085 | javacode1000085 | 1 | javacode1000085@163.com |
+---------+-----------------+-----+-------------------------+
1 row in set (0.00 sec)
耗時不到1毫秒,神速,
查看表中的索引
我們看一下test1表中的所有索引,如下
mysql> show index from test1;
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| test1 | 0 | idx2 | 1 | name | A | 1992727 | NULL | NULL | | BTREE | | |
| test1 | 1 | idx1 | 1 | id | A | 1992727 | NULL | NULL | | BTREE | | |
| test1 | 1 | idx3 | 1 | email | A | 1992727 | 15 | NULL | YES | BTREE | | |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
3 rows in set (0.00 sec)
可以看到test1表中3個索引的詳細資訊(索引名稱、型別,欄位),
洗掉索引
我們洗掉idx1,然后再列出test1表所有索引,如下:
mysql> drop index idx1 on test1;
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show index from test1;
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| test1 | 0 | idx2 | 1 | name | A | 1992727 | NULL | NULL | | BTREE | | |
| test1 | 1 | idx3 | 1 | email | A | 1992727 | 15 | NULL | YES | BTREE | | |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
2 rows in set (0.00 sec)
本篇主要是mysql中索引管理相關一些操作,屬于基礎知識,必須掌握,
第四篇 如何正確使用索引
1、通常說的這個查詢走索引了是什么意思?
當我們對某個欄位的值進行某種檢索的時候,如果這個檢索程序中,我們能夠快速定位到目標資料所在的頁,有效的降低頁的io操作,而不需要去掃描所有的資料頁的時候,我們認為這種情況能夠有效的利用索引,也稱這個檢索可以走索引,如果這個程序中不能夠確定資料在那些頁中,我們認為這種情況下索引對這個查詢是無效的,此查詢不走索引,
2、b+樹中資料檢索程序
2.1、唯一記錄檢索
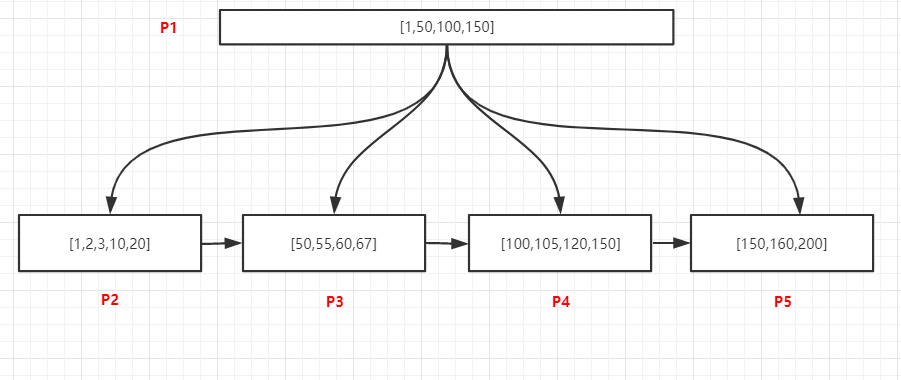
如上圖,所有的資料都是唯一的,查詢105的記錄,程序如下:
- 將P1頁加載到記憶體
- 在記憶體中采用二分法查找,可以確定105位于[100,150)中間,所以我們需要去加載100關聯P4頁
- 將P4加載到記憶體中,采用二分法找到105的記錄后退出
2.2、查詢某個值的所有記錄
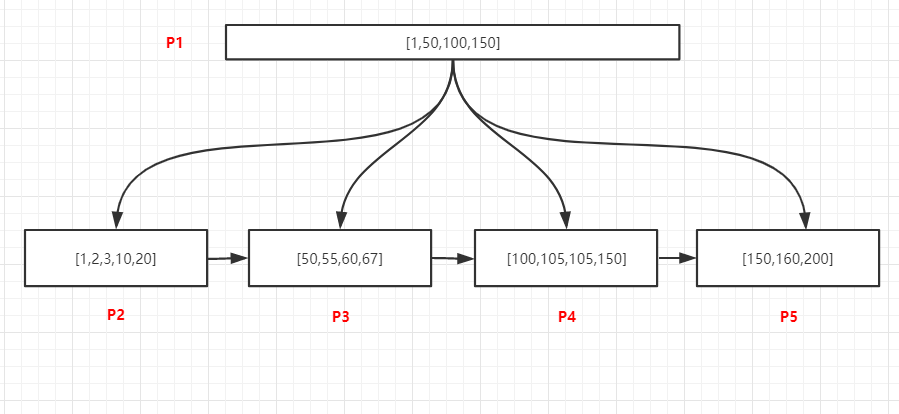
如上圖,查詢105的所有記錄,程序如下:
- 將P1頁加載到記憶體
- 在記憶體中采用二分法查找,可以確定105位于[100,150)中間,100關聯P4頁
- 將P4加載到記憶體中,采用二分法找到最有一個小于105的記錄,即100,然后通過鏈表從100開始向后訪問,找到所有的105記錄,直到遇到第一個大于100的值為止
2.3、范圍查找
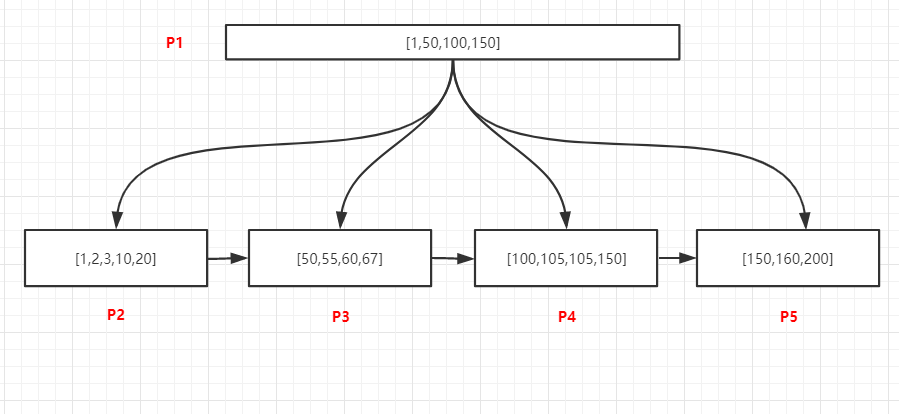
資料如上圖,查詢[55,150]所有記錄,由于頁和頁之間是雙向鏈表升序結構,頁內部的資料是單項升序鏈表結構,所以只用找到范圍的起始值所在的位置,然后通過依靠鏈表訪問兩個位置之間所有的資料即可,程序如下:
- 將P1頁加載到記憶體
- 記憶體中采用二分法找到55位于50關聯的P3頁中,150位于P5頁中
- 將P3加載到記憶體中,采用二分法找到第一個55的記錄,然后通過鏈表結構繼續向后訪問P3中的60、67,當P3訪問完畢之后,通過P3的nextpage指標訪問下一頁P4中所有記錄,繼續遍歷P4中的所有記錄,直到訪問到P5中的150為止,
2.4、模糊匹配
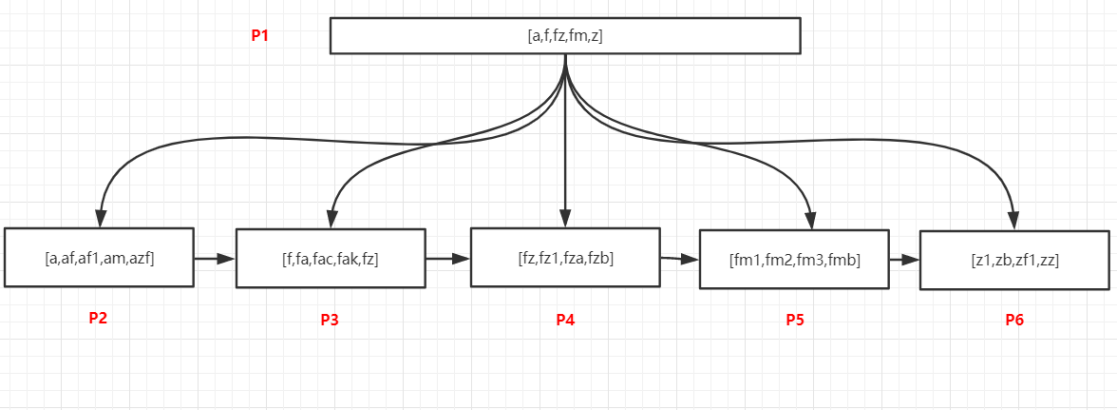
資料如上圖,
查詢以 f 開頭的所有記錄
程序如下:
-
將P1資料加載到記憶體中
-
在P1頁的記錄中采用二分法找到最后一個小于等于f的值,這個值是f,以及第一個大于f的,這個值是z,f指向葉節點P3,z指向葉節點P6,此時可以斷定以f開頭的記錄可能存在于[P3,P6)這個范圍的頁內,即P3、P4、P5這三個頁中
-
加載P3這個頁,在內部以二分法找到第一條f開頭的記錄,然后以鏈表方式繼續向后訪問P4、P5中的記錄,即可以找到所有已f開頭的資料
查詢包含f的記錄
包含的查詢在sql中的寫法是%f%,通過索引我們還可以快速定位所在的頁么?
可以看一下上面的資料,f在每個頁中都存在,我們通過P1頁中的記錄是無法判斷包含f的記錄在那些頁的,只能通過io的方式加載所有葉子節點,并且遍歷所有記錄進行過濾,才可以找到包含f的記錄,
所以如果使用了%值%這種方式,索引對查詢是無效的,
2.5、最左匹配原則
當b+樹的資料項是復合的資料結構,比如(name,age,sex)的時候,b+樹是按照從左到右的順序來建立搜索樹的, 比如當(張三,20,F)這樣的資料來檢索的時候,b+樹會優先比較name來確定下一步的所搜方向,如果name相同再依次比較age和sex,最后得到檢索的資料;但當(20,F)這樣的沒有name的資料來的時候,b+樹就不知道下一步該查哪個節點,因為建立搜索樹的時候name就是第一個比較因子,必須要先根據name來搜索才能知道下一步去哪里查詢,比如當(張三,F)這樣的資料來檢索時,b+樹可以用name來指定搜索方向,但下一個欄位age的缺失,所以只能把名字等于張三的資料都找到,然后再匹配性別是F的資料了, 這個是非常重要的性質,即索引的最左匹配特性,
來一些示例我們體驗一下,
下圖中是3個欄位(a,b,c)的聯合索引,索引中資料的順序是以 a asc,b asc,c asc 這種排序方式存盤在節點中的,索引先以a欄位升序,如果a相同的時候,以b欄位升序,b相同的時候,以c欄位升序,節點中每個資料認真看一下,
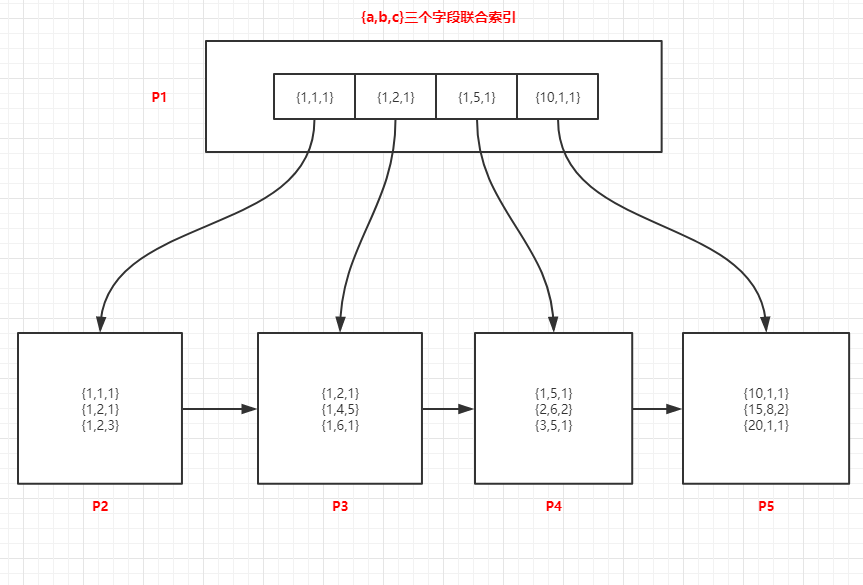
查詢a=1的記錄
由于頁中的記錄是以a asc,b asc,c asc這種排序方式存盤的,所以a欄位是有序的,可以通過二分法快速檢索到,程序如下:
- 將P1加載到記憶體中
- 在記憶體中對P1中的記錄采用二分法找,可以確定a=1的記錄位于{1,1,1}和{1,5,1}關聯的范圍內,這兩個值子節點分別是P2、P4
- 加載葉子節點P2,在P2中采用二分法快速找到第一條a=1的記錄,然后通過鏈表向下一條及下一頁開始檢索,直到在P4中找到第一個不滿足a=1的記錄為止
查詢a=1 and b=5的記錄
方法和上面的一樣,可以確定a=1 and b=5的記錄位于{1,1,1}和{1,5,1}關聯的范圍內,查找程序和a=1查找步驟類似,
查詢b=1的記錄
這種情況通過P1頁中的記錄,是無法判斷b=1的記錄在那些頁中的,只能加鎖索引樹所有葉子節點,對所有記錄進行遍歷,然后進行過濾,此時索引是無效的,
按照c的值查詢
這種情況和查詢b=1也一樣,也只能掃描所有葉子節點,此時索引也無效了,
按照b和c一起查
這種也是無法利用索引的,也只能對所有資料進行掃描,一條條判斷了,此時索引無效,
按照[a,c]兩個欄位查詢
這種只能利用到索引中的a欄位了,通過a確定索引范圍,然后加載a關聯的所有記錄,再對c的值進行過濾,
查詢a=1 and b>=0 and c=1的記錄
這種情況只能先確定a=1 and b>=0所在頁的范圍,然后對這個范圍的所有頁進行遍歷,c欄位在這個查詢的程序中,是無法確定c的資料在哪些頁的,此時我們稱c是不走索引的,只有a、b能夠有效的確定索引頁的范圍,
類似這種的還有>、<、between and,多欄位索引的情況下,mysql會一直向右匹配直到遇到范圍查詢(>、<、between、like)就停止匹配,
上面說的各種情況,大家都多看一下圖中資料,認真分析一下查詢的程序,基本上都可以理解了,
上面這種查詢叫做最左匹配原則,
3、索引區分度
我們看2個有序陣列
[1,2,3,4,5,6,7,8,8,9,10]
[1,1,1,1,1,8,8,8,8,8]
上面2個陣列是有序的,都是10條記錄,如果我需要檢索值為8的所有記錄,那個更快一些?
咱們使用二分法查找包含8的所有記錄程序如下:先使用二分法找到最后一個小于8的記錄,然后沿著這條記錄向后獲取下一個記錄,和8對比,知道遇到第一個大于8的數字結束,或者到達陣列末尾結束,
采用上面這種方法找到8的記錄,第一個陣列中更快的一些,因為第二個陣列中含有8的比例更多的,需要訪問以及匹配的次數更多一些,
這里就涉及到資料的區分度問題:
索引區分度 = count(distint 記錄) / count(記錄),
當索引區分度高的時候,檢索資料更快一些,索引區分度太低,說明重復的資料比較多,檢索的時候需要訪問更多的記錄才能夠找到所有目標資料,
當索引區分度非常小的時候,基本上接近于全索引資料的掃描了,此時查詢速度是比較慢的,
第一個陣列索引區分度為1,第二個區分度為0.2,所以第一個檢索更快的一些,
所以我們創建索引的時候,盡量選擇區分度高的列作為索引,
4、正確使用索引
4.1、準備400萬測驗資料
/*建庫javacode2018*/
DROP DATABASE IF EXISTS javacode2018;
CREATE DATABASE javacode2018;
USE javacode2018;
/*建表test1*/
DROP TABLE IF EXISTS test1;
CREATE TABLE test1 (
id INT NOT NULL COMMENT '編號',
name VARCHAR(20) NOT NULL COMMENT '姓名',
sex TINYINT NOT NULL COMMENT '性別,1:男,2:女',
email VARCHAR(50)
);
/*準備資料*/
DROP PROCEDURE IF EXISTS proc1;
DELIMITER $
CREATE PROCEDURE proc1()
BEGIN
DECLARE i INT DEFAULT 1;
START TRANSACTION;
WHILE i <= 4000000 DO
INSERT INTO test1 (id, name, sex, email) VALUES (i,concat('javacode',i),if(mod(i,2),1,2),concat('javacode',i,'@163.com'));
SET i = i + 1;
if i%10000=0 THEN
COMMIT;
START TRANSACTION;
END IF;
END WHILE;
COMMIT;
END $
DELIMITER ;
CALL proc1();
上面插入的400萬資料,除了sex列,其他列的值都是沒有重復的,
4.2、無索引檢索效果
400萬資料,我們隨便查詢幾個記錄看一下效果,
按照id查詢記錄
mysql> select * from test1 where id = 1;
+----+-----------+-----+-------------------+
| id | name | sex | email |
+----+-----------+-----+-------------------+
| 1 | javacode1 | 1 | javacode1@163.com |
+----+-----------+-----+-------------------+
1 row in set (1.91 sec)
id=1的資料,表中只有一行,耗時近2秒,由于id列無索引,只能對400萬資料進行全表掃描,
4.3、主鍵檢索
test1表中沒有明確的指定主鍵,我們將id設定為主鍵:
mysql> alter table test1 modify id int not null primary key;
Query OK, 0 rows affected (10.93 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show index from test1;
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| test1 | 0 | PRIMARY | 1 | id | A | 3980477 | NULL | NULL | | BTREE | | |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
1 row in set (0.00 sec)
id被置為主鍵之后,會在id上建立聚集索引,隨便檢索一條我們看一下效果:
mysql> select * from test1 where id = 1000000;
+---------+-----------------+-----+-------------------------+
| id | name | sex | email |
+---------+-----------------+-----+-------------------------+
| 1000000 | javacode1000000 | 2 | javacode1000000@163.com |
+---------+-----------------+-----+-------------------------+
1 row in set (0.00 sec)
這個速度很快,這個走的是上面介紹的唯一記錄檢索,
4.4、between and范圍檢索
mysql> select count(*) from test1 where id between 100 and 110;
+----------+
| count(*) |
+----------+
| 11 |
+----------+
1 row in set (0.00 sec)
速度也很快,id上有主鍵索引,這個采用的上面介紹的范圍查找可以快速定位目標資料,
但是如果范圍太大,跨度的page也太多,速度也會比較慢,如下:
mysql> select count(*) from test1 where id between 1 and 2000000;
+----------+
| count(*) |
+----------+
| 2000000 |
+----------+
1 row in set (1.17 sec)
上面id的值跨度太大,1所在的頁和200萬所在頁中間有很多頁需要讀取,所以比較慢,
所以使用between and的時候,區間跨度不要太大,
4.5、in的檢索
in方式檢索資料,我們還是經常用的,
平時我們做專案的時候,建議少用表連接,比如電商中需要查詢訂單的資訊和訂單中商品的名稱,可以先查詢查詢訂單表,然后訂單表中取出商品的id串列,采用in的方式到商品表檢索商品資訊,由于商品id是商品表的主鍵,所以檢索速度還是比較快的,
通過id在400萬資料中檢索100條資料,看看效果:
mysql> select * from test1 a where a.id in (100000, 100001, 100002, 100003, 100004, 100005, 100006, 100007, 100008, 100009, 100010, 100011, 100012, 100013, 100014, 100015, 100016, 100017, 100018, 100019, 100020, 100021, 100022, 100023, 100024, 100025, 100026, 100027, 100028, 100029, 100030, 100031, 100032, 100033, 100034, 100035, 100036, 100037, 100038, 100039, 100040, 100041, 100042, 100043, 100044, 100045, 100046, 100047, 100048, 100049, 100050, 100051, 100052, 100053, 100054, 100055, 100056, 100057, 100058, 100059, 100060, 100061, 100062, 100063, 100064, 100065, 100066, 100067, 100068, 100069, 100070, 100071, 100072, 100073, 100074, 100075, 100076, 100077, 100078, 100079, 100080, 100081, 100082, 100083, 100084, 100085, 100086, 100087, 100088, 100089, 100090, 100091, 100092, 100093, 100094, 100095, 100096, 100097, 100098, 100099);
+--------+----------------+-----+------------------------+
| id | name | sex | email |
+--------+----------------+-----+------------------------+
| 100000 | javacode100000 | 2 | javacode100000@163.com |
| 100001 | javacode100001 | 1 | javacode100001@163.com |
| 100002 | javacode100002 | 2 | javacode100002@163.com |
.......
| 100099 | javacode100099 | 1 | javacode100099@163.com |
+--------+----------------+-----+------------------------+
100 rows in set (0.00 sec)
耗時不到1毫秒,還是相當快的,
這個相當于多個分解為多個唯一記錄檢索,然后將記錄合并,
4.6、多個索引時查詢如何走?
我們在name、sex兩個欄位上分別建個索引
mysql> create index idx1 on test1(name);
Query OK, 0 rows affected (13.50 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> create index idx2 on test1(sex);
Query OK, 0 rows affected (6.77 sec)
Records: 0 Duplicates: 0 Warnings: 0
看一下查詢:
mysql> select * from test1 where name='javacode3500000' and sex=2;
+---------+-----------------+-----+-------------------------+
| id | name | sex | email |
+---------+-----------------+-----+-------------------------+
| 3500000 | javacode3500000 | 2 | javacode3500000@163.com |
+---------+-----------------+-----+-------------------------+
1 row in set (0.00 sec)
上面查詢速度很快,name和sex上各有一個索引,覺得上面走哪個索引?
有人說name位于where第一個,所以走的是name欄位所在的索引,程序可以解釋為這樣:
- 走name所在的索引找到javacode3500000對應的所有記錄
- 遍歷記錄過濾出sex=2的值
我們看一下name='javacode3500000’檢索速度,確實很快,如下:
mysql> select * from test1 where name='javacode3500000';
+---------+-----------------+-----+-------------------------+
| id | name | sex | email |
+---------+-----------------+-----+-------------------------+
| 3500000 | javacode3500000 | 2 | javacode3500000@163.com |
+---------+-----------------+-----+-------------------------+
1 row in set (0.00 sec)
走name索引,然后再過濾,確實可以,速度也很快,果真和where后欄位順序有關么?我們把name和sex的順序對調一下,如下:
mysql> select * from test1 where sex=2 and name='javacode3500000';
+---------+-----------------+-----+-------------------------+
| id | name | sex | email |
+---------+-----------------+-----+-------------------------+
| 3500000 | javacode3500000 | 2 | javacode3500000@163.com |
+---------+-----------------+-----+-------------------------+
1 row in set (0.00 sec)
速度還是很快,這次是不是先走sex索引檢索出資料,然后再過濾name呢?我們先來看一下sex=2查詢速度:
mysql> select count(id) from test1 where sex=2;
+-----------+
| count(id) |
+-----------+
| 2000000 |
+-----------+
1 row in set (0.36 sec)
看上面,查詢耗時360毫秒,200萬資料,如果走sex肯定是不行的,
我們使用explain來看一下:
mysql> explain select * from test1 where sex=2 and name='javacode3500000';
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | test1 | NULL | ref | idx1,idx2 | idx1 | 62 | const | 1 | 50.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
possible_keys:列出了這個查詢可能會走兩個索引(idx1、idx2)
實際上走的卻是idx1(key列:實際走的索引),
當多個條件中有索引的時候,并且關系是and的時候,會走索引區分度高的,顯然name欄位重復度很低,走name查詢會更快一些,
4.7、模糊查詢
看兩個查詢
mysql> select count(*) from test1 a where a.name like 'javacode1000%';
+----------+
| count(*) |
+----------+
| 1111 |
+----------+
1 row in set (0.00 sec)
mysql> select count(*) from test1 a where a.name like '%javacode1000%';
+----------+
| count(*) |
+----------+
| 1111 |
+----------+
1 row in set (1.78 sec)
上面第一個查詢可以利用到name欄位上面的索引,下面的查詢是無法確定需要查找的值所在的范圍的,只能全表掃描,無法利用索引,所以速度比較慢,這個程序上面有說過,
4.8、回表
當需要查詢的資料在索引樹中不存在的時候,需要再次到聚集索引中去獲取,這個程序叫做回表,如查詢:
mysql> select * from test1 where name='javacode3500000';
+---------+-----------------+-----+-------------------------+
| id | name | sex | email |
+---------+-----------------+-----+-------------------------+
| 3500000 | javacode3500000 | 2 | javacode3500000@163.com |
+---------+-----------------+-----+-------------------------+
1 row in set (0.00 sec)
上面查詢是*,由于name列所在的索引中只有name、id兩個列的值,不包含sex、email,所以上面程序如下:
- 走name索引檢索javacode3500000對應的記錄,取出id為3500000
- 在主鍵索引中檢索出id=3500000的記錄,獲取所有欄位的值
4.9、索引覆寫
查詢中采用的索引樹中包含了查詢所需要的所有欄位的值,不需要再去聚集索引檢索資料,這種叫索引覆寫,
我們來看一個查詢:
select id,name from test1 where name='javacode3500000';
name對應idx1索引,id為主鍵,所以idx1索引樹葉子節點中包含了name、id的值,這個查詢只用走idx1這一個索引就可以了,如果select后面使用*,還需要一次回表獲取sex、email的值,
所以寫sql的時候,盡量避免使用*,*可能會多一次回表操作,需要看一下是否可以使用索引覆寫來實作,效率更高一些,
4.10、索引下推
簡稱ICP,Index Condition Pushdown(ICP)是MySQL 5.6中新特性,是一種在存盤引擎層使用索引過濾資料的一種優化方式,ICP可以減少存盤引擎訪問基表的次數以及MySQL服務器訪問存盤引擎的次數,
舉個例子來說一下:
我們需要查詢name以javacode35開頭的,性別為1的記錄數,sql如下:
mysql> select count(id) from test1 a where name like 'javacode35%' and sex = 1;
+-----------+
| count(id) |
+-----------+
| 55556 |
+-----------+
1 row in set (0.19 sec)
程序:
- 走name索引檢索出以javacode35的第一條記錄,得到記錄的id
- 利用id去主鍵索引中查詢出這條記錄R1
- 判斷R1中的sex是否為1,然后重復上面的操作,直到找到所有記錄為止,
上面的程序中需要走name索引以及需要回表操作,
如果采用ICP的方式,我們可以這么做,創建一個(name,sex)的組合索引,查詢程序如下:
- 走(name,sex)索引檢索出以javacode35的第一條記錄,可以得到(name,sex,id),記做R1
- 判斷R1.sex是否為1,然后重復上面的操作,知道找到所有記錄為止
這個程序中不需要回表操作了,通過索引的資料就可以完成整個條件的過濾,速度比上面的更快一些,
4.11、數字使字串類索引失效
mysql> insert into test1 (id,name,sex,email) values (4000001,'1',1,'javacode2018@163.com');
Query OK, 1 row affected (0.00 sec)
mysql> select * from test1 where name = '1';
+---------+------+-----+----------------------+
| id | name | sex | email |
+---------+------+-----+----------------------+
| 4000001 | 1 | 1 | javacode2018@163.com |
+---------+------+-----+----------------------+
1 row in set (0.00 sec)
mysql> select * from test1 where name = 1;
+---------+------+-----+----------------------+
| id | name | sex | email |
+---------+------+-----+----------------------+
| 4000001 | 1 | 1 | javacode2018@163.com |
+---------+------+-----+----------------------+
1 row in set, 65535 warnings (3.30 sec)
上面3條sql,我們插入了一條記錄,
第二條查詢很快,第三條用name和1比較,name上有索引,name是字串型別,字串和數字比較的時候,會將字串強制轉換為數字,然后進行比較,所以第二個查詢變成了全表掃描,只能取出每條資料,將name轉換為數字和1進行比較,
數字欄位和字串比較什么效果呢?如下:
mysql> select * from test1 where id = '4000000';
+---------+-----------------+-----+-------------------------+
| id | name | sex | email |
+---------+-----------------+-----+-------------------------+
| 4000000 | javacode4000000 | 2 | javacode4000000@163.com |
+---------+-----------------+-----+-------------------------+
1 row in set (0.00 sec)
mysql> select * from test1 where id = 4000000;
+---------+-----------------+-----+-------------------------+
| id | name | sex | email |
+---------+-----------------+-----+-------------------------+
| 4000000 | javacode4000000 | 2 | javacode4000000@163.com |
+---------+-----------------+-----+-------------------------+
1 row in set (0.00 sec)
id上面有主鍵索引,id是int型別的,可以看到,上面兩個查詢都非常快,都可以正常利用索引快速檢索,所以如果欄位是陣列型別的,查詢的值是字串還是陣列都會走索引,
4.12、函式使索引無效
mysql> select a.name+1 from test1 a where a.name = 'javacode1';
+----------+
| a.name+1 |
+----------+
| 1 |
+----------+
1 row in set, 1 warning (0.00 sec)
mysql> select * from test1 a where concat(a.name,'1') = 'javacode11';
+----+-----------+-----+-------------------+
| id | name | sex | email |
+----+-----------+-----+-------------------+
| 1 | javacode1 | 1 | javacode1@163.com |
+----+-----------+-----+-------------------+
1 row in set (2.88 sec)
name上有索引,上面查詢,第一個走索引,第二個不走索引,第二個使用了函式之后,name所在的索引樹是無法快速定位需要查找的資料所在的頁的,只能將所有頁的記錄加載到記憶體中,然后對每條資料使用函式進行計算之后再進行條件判斷,此時索引無效了,變成了全表資料掃描,
結論:索引欄位使用函式查詢使索引無效,
4.13、運算子使索引無效
mysql> select * from test1 a where id = 2 - 1;
+----+-----------+-----+-------------------+
| id | name | sex | email |
+----+-----------+-----+-------------------+
| 1 | javacode1 | 1 | javacode1@163.com |
+----+-----------+-----+-------------------+
1 row in set (0.00 sec)
mysql> select * from test1 a where id+1 = 2;
+----+-----------+-----+-------------------+
| id | name | sex | email |
+----+-----------+-----+-------------------+
| 1 | javacode1 | 1 | javacode1@163.com |
+----+-----------+-----+-------------------+
1 row in set (2.41 sec)
id上有主鍵索引,上面查詢,第一個走索引,第二個不走索引,第二個使用運算子,id所在的索引樹是無法快速定位需要查找的資料所在的頁的,只能將所有頁的記錄加載到記憶體中,然后對每條資料的id進行計算之后再判斷是否等于1,此時索引無效了,變成了全表資料掃描,
結論:索引欄位使用了函式將使索引無效,
4.14、使用索引優化排序
我們有個訂單表t_order(id,user_id,addtime,price),經常會查詢某個用戶的訂單,并且按照addtime升序排序,應該怎么創建索引呢?我們來分析一下,
在user_id上創建索引,我們分析一下這種情況,資料檢索的程序:
- 走user_id索引,找到記錄的的id
- 通過id在主鍵索引中回表檢索出整條資料
- 重復上面的操作,獲取所有目標記錄
- 在記憶體中對目標記錄按照addtime進行排序
我們要知道當資料量非常大的時候,排序還是比較慢的,可能會用到磁盤中的檔案,有沒有一種方式,查詢出來的資料剛好是排好序的,
我們再回顧一下mysql中b+樹資料的結構,記錄是按照索引的值排序組成的鏈表,如果將user_id和addtime放在一起組成聯合索引(user_id,addtime),這樣通過user_id檢索出來的資料自然就是按照addtime排好序的,這樣直接少了一步排序操作,效率更好,如果需addtime降序,只需要將結果翻轉一下就可以了,
5、總結一下使用索引的一些建議
- 在區分度高的欄位上面建立索引可以有效的使用索引,區分度太低,無法有效的利用索引,可能需要掃描所有資料頁,此時和不使用索引差不多
- 聯合索引注意最左匹配原則:必須按照從左到右的順序匹配,mysql會一直向右匹配直到遇到范圍查詢(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)順序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引則都可以用到,a,b,d的順序可以任意調整
- 查詢記錄的時候,少使用*,盡量去利用索引覆寫,可以減少回表操作,提升效率
- 有些查詢可以采用聯合索引,進而使用到索引下推(IPC),也可以減少回表操作,提升效率
- 禁止對索引欄位使用函式、運算子操作,會使索引失效
- 字串欄位和數字比較的時候會使索引無效
- 模糊查詢’%值%'會使索引無效,變為全表掃描,但是’值%'這種可以有效利用索引
- 排序中盡量使用到索引欄位,這樣可以減少排序,提升查詢效率
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293182.html
標籤:其他