影像遷移學習
- 3.PyTorch實作遷移學習
- 3.1資料集預處理
- 3.2構建模型
- 3.3模型訓練與驗證
3.PyTorch實作遷移學習
檔案目錄
3.1資料集預處理
這里實作一個螞蟻與蜜蜂的影像分類,用到的資料集data下載
dataset.py
from torchvision import datasets, transforms
import torch
train=transforms.Compose([
transforms.RandomResizedCrop(224), # 隨機裁剪一個area然后再resize
transforms.RandomHorizontalFlip(), # 隨機水平翻轉
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
val=transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
trainset=datasets.ImageFolder(root='hymenoptera_data/train',transform=train)
valset=datasets.ImageFolder(root='hymenoptera_data/val',transform=val)
trainloader=torch.utils.data.DataLoader(trainset,batch_size=4,
shuffle=True, num_workers=4)
valloader=torch.utils.data.DataLoader(valset,batch_size=4,
shuffle=True, num_workers=4)
3.2構建模型
model.py
from torchvision import models
import torch.nn as nn
#初始化模型
#保證模型不改變的層的引數,不發生梯度變化
def set_parameter_requires_grad(model, feature_extracting):
if feature_extracting:
for param in model.parameters():
param.requires_grad = False
def initialize_model(model_name, num_classes, feature_extract):
model_ft=None
input_size=0
if model_name =='resnet':
#resnet18
model_ft = models.resnet18(pretrained=True)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "alexnet":
model_ft = models.alexnet(pretrained=True)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.classifier[6].in_features
model_ft.classifier[6] = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "vgg":
#vgg11
model_ft = models.vgg11_bn(pretrained=True)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.classifier[6].in_features
model_ft.classifier[6] = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "squeezenet":
model_ft = models.squeezenet1_0(pretrained=True)
set_parameter_requires_grad(model_ft, feature_extract)
model_ft.classifier[1] = nn.Conv2d(512, num_classes, kernel_size=(1, 1), stride=(1, 1))
model_ft.num_classes = num_classes
input_size = 224
elif model_name == "densenet":
model_ft = models.densenet121(pretrained=True)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.classifier.in_features
model_ft.classifier = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "inception":
model_ft = models.inception_v3(pretrained=True)
set_parameter_requires_grad(model_ft, feature_extract)
# Handle the auxilary net
num_ftrs = model_ft.AuxLogits.fc.in_features
model_ft.AuxLogits.fc = nn.Linear(num_ftrs, num_classes)
# Handle the primary net
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, num_classes)
input_size = 299
else:
print("沒有合適的模型...")
return model_ft, input_size
3.3模型訓練與驗證
run.py
from __future__ import print_function
from __future__ import division
import torch.nn as nn
import torch.optim as optim
from model import initialize_model
from torch.optim import lr_scheduler
import time
import copy
from dataset import *
import argparse
parser=argparse.ArgumentParser()
#模型選擇
parser.add_argument('-m','--model_name',type=str,choices=['resnet', 'alexnet', 'vgg', 'squeezenet', 'densenet', 'inception'],help="input model_name",default='resnet')
#分類類別數
parser.add_argument('-n','--num_classes',type=int,help="input num_classes",default=2)
#定義一個批次的樣本數
parser.add_argument('-b','--batch_size',type=int,help="input batch_size",default=8)
#定義迭代批次
parser.add_argument('-e','--num_epochs',type=int,help="input num_epochs",default=25)
args=parser.parse_args()
#用于特征提取的標志,如果為False,則對整個模型進行微調,
#如果為True,則僅更新重塑的圖層引數
feature_extract = True
#定義資料字典
datasets={train:trainset,val:valset}
#定義資料集字典
dataloaders={train:trainloader,val:valloader}
model_ft, input_size = initialize_model(args.model_name, args.num_classes, feature_extract)
criterion = nn.CrossEntropyLoss()
# 觀察所有引數都正在優化
optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9)
# 每7個epochs衰減LR通過設定gamma=0.1
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
def train_model(model,criterion,optimizer,scheduler,num_epochs):
since=time.time()
val_acc_history = []
#獲取模型初始引數
best_model_wts=copy.deepcopy(model.state_dict())
best_acc=0.0
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch,num_epochs-1))
print('-'*10)
for data in ['train','val']:
if data=='train':
scheduler.step()
model.train()
else:
model.eval()
running_loss = 0.0
running_corrects = 0
for inputs,labels in dataloaders[data]:
optimizer.zero_grad()
with torch.set_grad_enabled(data=='train'):
outputs=model(inputs)
_,preds=torch.max(outputs,1)
loss=criterion(outputs,labels)
if data=='train':
loss.backward()
optimizer.step()
running_loss+=loss.item()*inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(datasets[data])
epoch_acc = running_corrects.double() / len(datasets[data])
print('{} Loss: {:.4f} Acc: {:.4f}'.format(
data, epoch_loss, epoch_acc))
# 深度復制mo
if data=='val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
print()
time_elapsed = time.time() - since
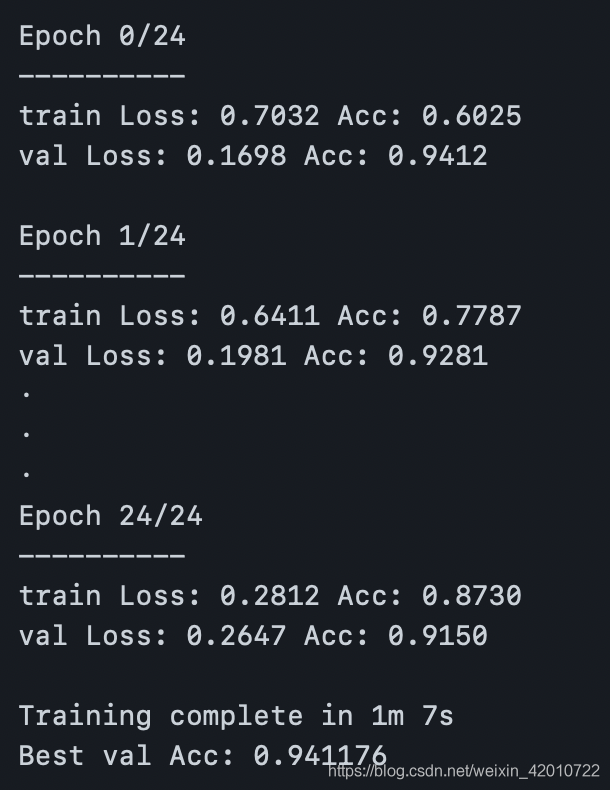
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
model.load_state_dict(best_model_wts)
return model
train_model(model_ft,criterion, optimizer_ft, exp_lr_scheduler,args.num_epochs)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293269.html
標籤:其他
上一篇:Opencv常見資料型別(二)
下一篇:2021-08-10