Pytorch CIFAR10影像分類 ResNet篇
文章目錄
- Pytorch CIFAR10影像分類 ResNet篇
- 4.定義網路(ResNet)
- 殘差結構
- ResNet18/34 的Residual結構
- ResNet50/101/152的Bottleneck結構
- ResNet網路結構配置
- BasicBlock
- Bottleneck Block
- ResNet
- 5. 定義損失函式和優化器
- 6. 訓練
- 損失函式曲線
- 準確率曲線
- 學習率曲線
- 7.測驗
- 查看準確率
- 查看每一類的準確率
- 抽樣測驗并可視化一部分結果
- 8. 保存模型
- 9. 預測
- 讀取本地圖片進行預測
- 讀取圖片地址進行預測
- 10.總結
這里貼一下匯總篇: 匯總篇
4.定義網路(ResNet)
當大家還在驚嘆 GoogLeNet 的 inception 結構的時候,微軟亞洲研究院的研究員已經在設計更深但結構更加簡單的網路 ResNet,并且憑借這個網路斬獲當年ImageNet競賽中分類任務第一名,目標檢測第一名,獲得COCO資料集中目標檢測第一名,影像分割第一名,# 4.定義網路(ResNet)
如果想詳細了解并查看論文,可以看我的另一篇博客【論文泛讀】 ResNet:深度殘差網路
下圖是ResNet18層模型的結構簡圖
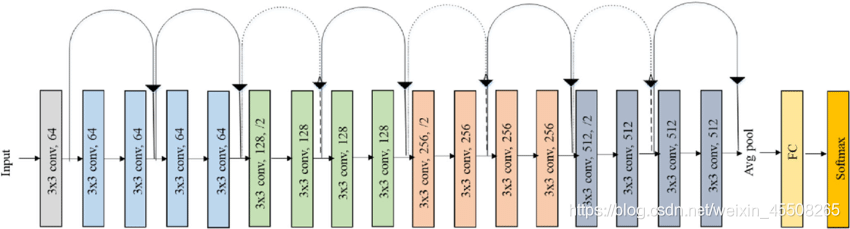
還有ResNet-34模型

在ResNet網路中有如下幾個亮點:
(1)提出residual結構(殘差結構),并搭建超深的網路結構(突破1000層)
(2)使用Batch Normalization加速訓練(丟棄dropout)
在ResNet網路提出之前,傳統的卷積神經網路都是通過將一系列卷積層與下采樣層進行堆疊得到的,但是當堆疊到一定網路深度時,就會出現兩個問題,
(1)梯度消失或梯度爆炸,
(2)退化問題(degradation problem),
殘差結構
在ResNet論文中說通過資料的預處理以及在網路中使用BN(Batch Normalization)層能夠解決梯度消失或者梯度爆炸問題,residual結構(殘差結構)來減輕退化問題,此時擬合目標就變為F(x),F(x)就是殘差
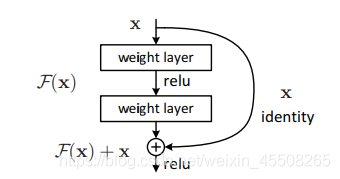
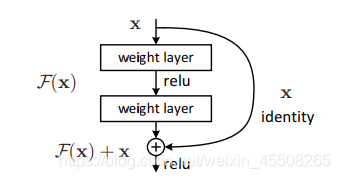
這里有一個點是很重要的,對于我們的第二個layer,它是沒有relu激活函式的,他需要與x相加最后再進行激活函式relu
ResNet18/34 的Residual結構
我們先對ResNet18/34的殘差結構進行一個分析,如下圖所示,該殘差結構的主分支是由兩層3x3的卷積層組成,而殘差結構右側的連接線是shortcut分支也稱捷徑分支(注意為了讓主分支上的輸出矩陣能夠與我們捷徑分支上的輸出矩陣進行相加,必須保證這兩個輸出特征矩陣有相同的shape),我們會發現有一些虛線結構,論文中表述為用1x1的卷積進行降維,下圖給出了詳細的殘差結構,
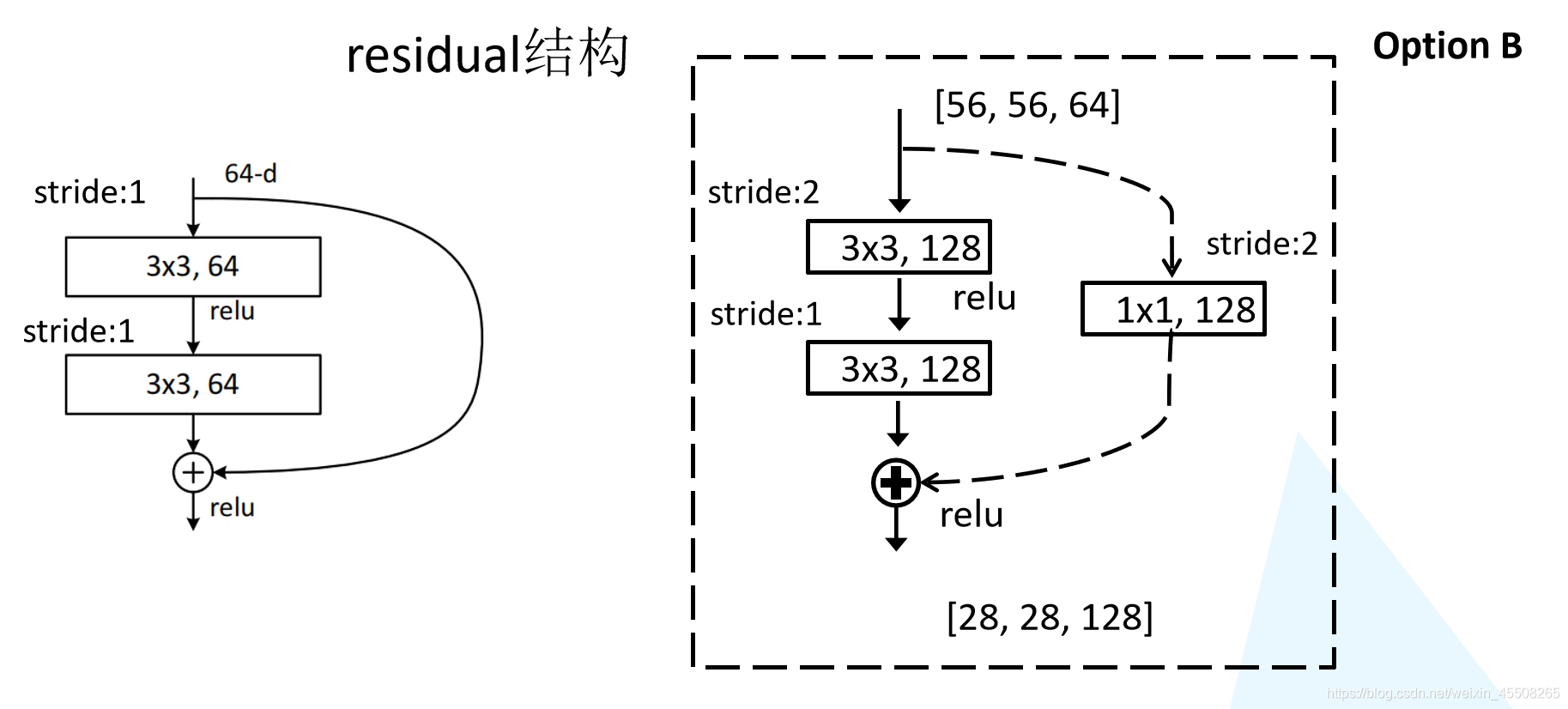
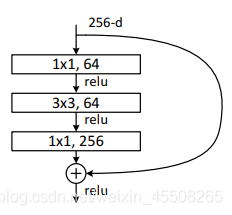
ResNet50/101/152的Bottleneck結構
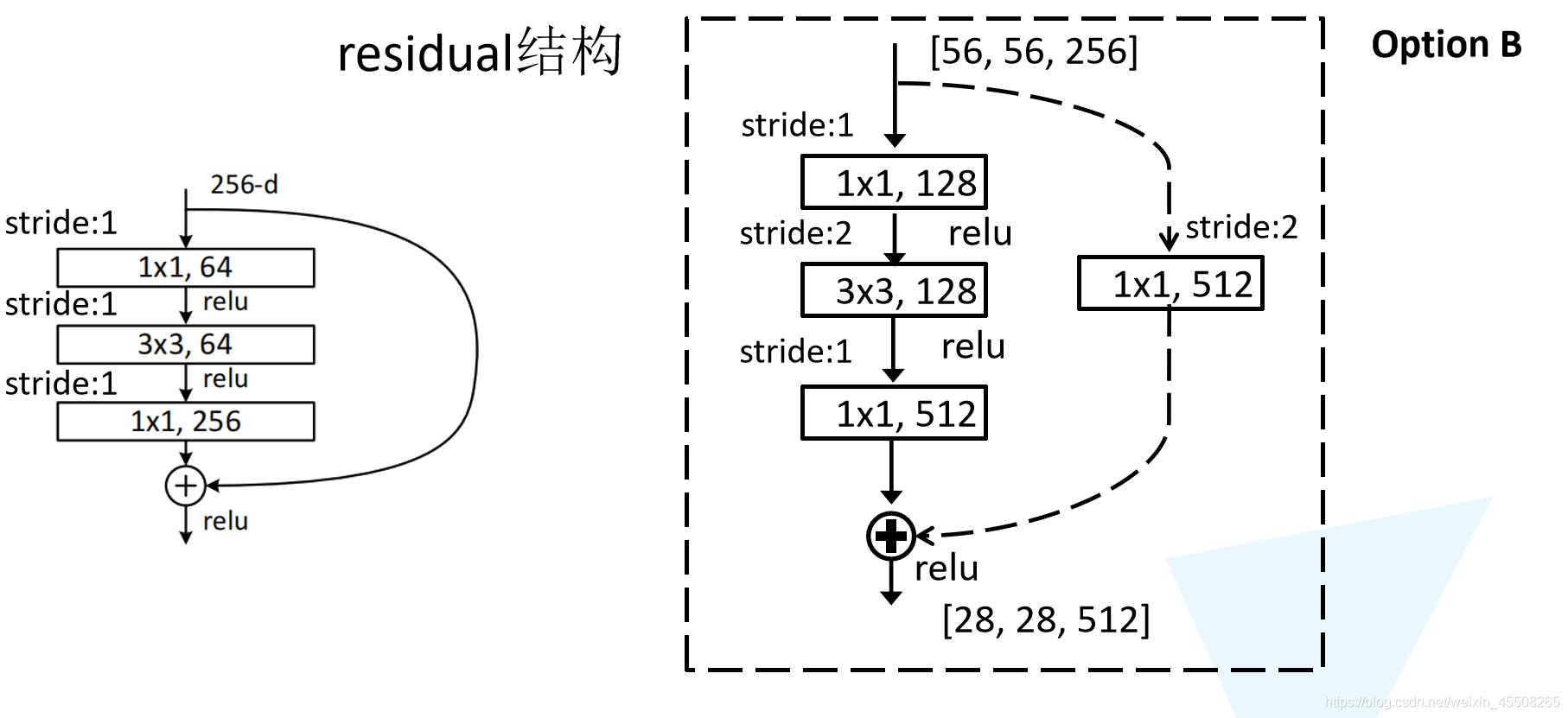
接著我們再來分析下針對ResNet50/101/152的殘差結構,如下圖所示,在該殘差結構當中,主分支使用了三個卷積層,第一個是1x1的卷積層用來壓縮channel維度,第二個是3x3的卷積層,第三個是1x1的卷積層用來還原channel維度(注意主分支上第一層卷積層和第二次卷積層所使用的卷積核個數是相同的,第三次是第一層的4倍),這種又叫做bottleneck模型
ResNet網路結構配置
這是在ImageNet資料集中更深的殘差網路的模型,這里面給出了殘差結構給出了主分支上卷積核的大小與卷積核個數,表中的xN表示將該殘差結構重復N次,
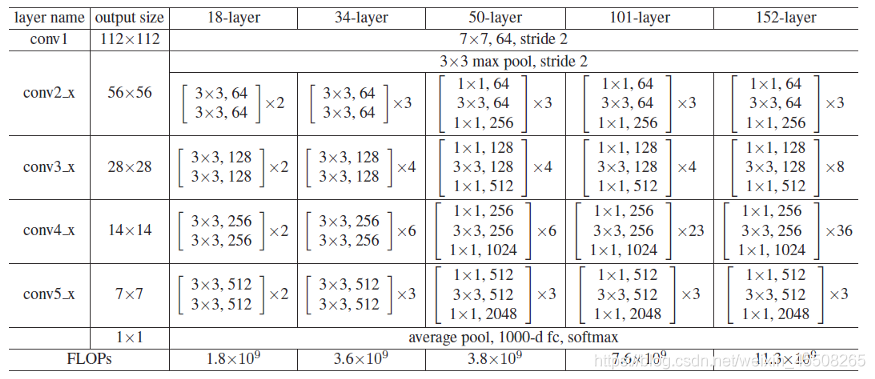
對于我們ResNet18/34/50/101/152,表中conv3_x, conv4_x, conv5_x所對應的一系列殘差結構的第一層殘差結構都是虛線殘差結構,因為這一系列殘差結構的第一層都有調整輸入特征矩陣shape的使命(將特征矩陣的高和寬縮減為原來的一半,將深度channel調整成下一層殘差結構所需要的channel)
- ResNet-50:我們用3層瓶頸塊替換34層網路中的每一個2層塊,得到了一個50層ResNe,我們使用1x1卷積核來增加維度,該模型有38億FLOP,
- ResNet-101/152:我們通過使用更多的3層瓶頸塊來構建101層和152層ResNets,值得注意的是,盡管深度顯著增加,但152層ResNet(113億FLOP)仍然比VGG-16/19網路(153/196億FLOP)具有更低的復雜度,
首先我們還是得判斷是否可以利用GPU,因為GPU的速度可能會比我們用CPU的速度快20-50倍左右,特別是對卷積神經網路來說,更是提升特別明顯,
device = 'cuda' if torch.cuda.is_available() else 'cpu'
BasicBlock
對于淺層網路,如ResNet-18/34等,用基本的Block
class BasicBlock(nn.Module):
"""
對于淺層網路,如ResNet-18/34等,用基本的Block
基礎模塊沒有壓縮,所以expansion=1
"""
expansion = 1
def __init__(self, in_channels, out_channels, stride=1):
super(BasicBlock,self).__init__()
self.features = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(True),
nn.Conv2d(out_channels,out_channels, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(out_channels)
)
# 如果輸入輸出維度不等,則使用1x1卷積層來改變維度
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != self.expansion * out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, self.expansion * out_channels, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion * out_channels),
)
def forward(self, x):
out = self.features(x)
# print(out.shape)
out += self.shortcut(x)
out = torch.relu(out)
return out
# 測驗
basic_block = BasicBlock(64, 128)
print(basic_block)
x = torch.randn(2, 64, 32, 32)
y = basic_block(x)
print(y.shape)
BasicBlock( (features): Sequential( (0): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (2): ReLU(inplace=True) (3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (shortcut): Sequential( (0): Conv2d(64, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) torch.Size([2, 128, 32, 32])
Bottleneck Block
對于深層網路,我們使用BottleNeck,論文中提出其擁有近似的計算復雜度,但能節省很多資源
class Bottleneck(nn.Module):
"""
對于深層網路,我們使用BottleNeck,論文中提出其擁有近似的計算復雜度,但能節省很多資源
zip_channels: 壓縮后的維數,最后輸出的維數是 expansion * zip_channels
針對ResNet50/101/152的網路結構,主要是因為第三層是第二層的4倍的關系所以expansion=4
"""
expansion = 4
def __init__(self, in_channels, zip_channels, stride=1):
super(Bottleneck, self).__init__()
out_channels = self.expansion * zip_channels
self.features = nn.Sequential(
nn.Conv2d(in_channels, zip_channels, kernel_size=1, bias=False),
nn.BatchNorm2d(zip_channels),
nn.ReLU(inplace=True),
nn.Conv2d(zip_channels, zip_channels, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(zip_channels),
nn.ReLU(inplace=True),
nn.Conv2d(zip_channels, out_channels, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channels)
)
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
out = self.features(x)
# print(out.shape)
out += self.shortcut(x)
out = torch.relu(out)
return out
# 測驗
bottleneck = Bottleneck(256, 128)
print(bottleneck)
x = torch.randn(2, 256, 32, 32)
y = bottleneck(x)
print(y.shape)
Bottleneck( (features): Sequential( (0): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (2): ReLU(inplace=True) (3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (5): ReLU(inplace=True) (6): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (7): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (shortcut): Sequential( (0): Conv2d(256, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) torch.Size([2, 512, 32, 32])
ResNet
不同的ResNet架構都是統一的一層特征提取、四層殘差,不同點在于每層殘差的深度,
class ResNet(nn.Module):
"""
不同的ResNet架構都是統一的一層特征提取、四層殘差,不同點在于每層殘差的深度,
對于cifar10,feature map size的變化如下:
(32, 32, 3) -> [Conv2d] -> (32, 32, 64) -> [Res1] -> (32, 32, 64) -> [Res2]
-> (16, 16, 128) -> [Res3] -> (8, 8, 256) ->[Res4] -> (4, 4, 512) -> [AvgPool]
-> (1, 1, 512) -> [Reshape] -> (512) -> [Linear] -> (10)
"""
def __init__(self, block, num_blocks, num_classes=10, verbose = False):
super(ResNet, self).__init__()
self.verbose = verbose
self.in_channels = 64
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True)
)
#使用_make_layer函式生成上表對應的conv2_x, conv3_x, conv4_x, conv5_x的結構
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)
self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)
# cifar10經過上述結構后,到這里的feature map size是 4 x 4 x 512 x expansion
# 所以這里用了 4 x 4 的平均池化
self.avg_pool = nn.AvgPool2d(kernel_size=4)
self.classifer = nn.Linear(512 * block.expansion, num_classes)
def _make_layer(self, block, out_channels, num_blocks, stride):
# 第一個block要進行降采樣
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers.append(block(self.in_channels, out_channels, stride))
# 如果是Bottleneck Block的話需要對每層輸入的維度進行壓縮,壓縮后再增加維數
# 所以每層的輸入維數也要跟著變
self.in_channels = out_channels * block.expansion
return nn.Sequential(*layers)
def forward(self, x):
out = self.features(x)
if self.verbose:
print('block 1 output: {}'.format(out.shape))
out = self.layer1(out)
if self.verbose:
print('block 2 output: {}'.format(out.shape))
out = self.layer2(out)
if self.verbose:
print('block 3 output: {}'.format(out.shape))
out = self.layer3(out)
if self.verbose:
print('block 4 output: {}'.format(out.shape))
out = self.layer4(out)
if self.verbose:
print('block 5 output: {}'.format(out.shape))
out = self.avg_pool(out)
out = out.view(out.size(0), -1)
out = self.classifer(out)
return out
def ResNet18(verbose=False):
return ResNet(BasicBlock, [2,2,2,2],verbose=verbose)
def ResNet34(verbose=False):
return ResNet(BasicBlock, [3,4,6,3],verbose=verbose)
def ResNet50(verbose=False):
return ResNet(Bottleneck, [3,4,6,3],verbose=verbose)
def ResNet101(verbose=False):
return ResNet(Bottleneck, [3,4,23,3],verbose=verbose)
def ResNet152(verbose=False):
return ResNet(Bottleneck, [3,8,36,3],verbose=verbose)
net = ResNet18(True).to(device)
summary(net,(3,32,32))
block 1 output: torch.Size([2, 64, 32, 32]) block 2 output: torch.Size([2, 64, 32, 32]) block 3 output: torch.Size([2, 128, 16, 16]) block 4 output: torch.Size([2, 256, 8, 8]) block 5 output: torch.Size([2, 512, 4, 4]) ---------------------------------------------------------------- Layer (type) Output Shape Param # ================================================================ Conv2d-1 [-1, 64, 32, 32] 1,728 BatchNorm2d-2 [-1, 64, 32, 32] 128 ReLU-3 [-1, 64, 32, 32] 0 Conv2d-4 [-1, 64, 32, 32] 36,864 BatchNorm2d-5 [-1, 64, 32, 32] 128 ReLU-6 [-1, 64, 32, 32] 0 Conv2d-7 [-1, 64, 32, 32] 36,864 BatchNorm2d-8 [-1, 64, 32, 32] 128 BasicBlock-9 [-1, 64, 32, 32] 0 Conv2d-10 [-1, 64, 32, 32] 36,864 BatchNorm2d-11 [-1, 64, 32, 32] 128 ReLU-12 [-1, 64, 32, 32] 0 Conv2d-13 [-1, 64, 32, 32] 36,864 BatchNorm2d-14 [-1, 64, 32, 32] 128 BasicBlock-15 [-1, 64, 32, 32] 0 Conv2d-16 [-1, 128, 16, 16] 73,728 BatchNorm2d-17 [-1, 128, 16, 16] 256 ReLU-18 [-1, 128, 16, 16] 0 Conv2d-19 [-1, 128, 16, 16] 147,456 BatchNorm2d-20 [-1, 128, 16, 16] 256 Conv2d-21 [-1, 128, 16, 16] 8,192 BatchNorm2d-22 [-1, 128, 16, 16] 256 BasicBlock-23 [-1, 128, 16, 16] 0 Conv2d-24 [-1, 128, 16, 16] 147,456 BatchNorm2d-25 [-1, 128, 16, 16] 256 ReLU-26 [-1, 128, 16, 16] 0 Conv2d-27 [-1, 128, 16, 16] 147,456 BatchNorm2d-28 [-1, 128, 16, 16] 256 BasicBlock-29 [-1, 128, 16, 16] 0 Conv2d-30 [-1, 256, 8, 8] 294,912 BatchNorm2d-31 [-1, 256, 8, 8] 512 ReLU-32 [-1, 256, 8, 8] 0 Conv2d-33 [-1, 256, 8, 8] 589,824 BatchNorm2d-34 [-1, 256, 8, 8] 512 Conv2d-35 [-1, 256, 8, 8] 32,768 BatchNorm2d-36 [-1, 256, 8, 8] 512 BasicBlock-37 [-1, 256, 8, 8] 0 Conv2d-38 [-1, 256, 8, 8] 589,824 BatchNorm2d-39 [-1, 256, 8, 8] 512 ReLU-40 [-1, 256, 8, 8] 0 Conv2d-41 [-1, 256, 8, 8] 589,824 BatchNorm2d-42 [-1, 256, 8, 8] 512 BasicBlock-43 [-1, 256, 8, 8] 0 Conv2d-44 [-1, 512, 4, 4] 1,179,648 BatchNorm2d-45 [-1, 512, 4, 4] 1,024 ReLU-46 [-1, 512, 4, 4] 0 Conv2d-47 [-1, 512, 4, 4] 2,359,296 BatchNorm2d-48 [-1, 512, 4, 4] 1,024 Conv2d-49 [-1, 512, 4, 4] 131,072 BatchNorm2d-50 [-1, 512, 4, 4] 1,024 BasicBlock-51 [-1, 512, 4, 4] 0 Conv2d-52 [-1, 512, 4, 4] 2,359,296 BatchNorm2d-53 [-1, 512, 4, 4] 1,024 ReLU-54 [-1, 512, 4, 4] 0 Conv2d-55 [-1, 512, 4, 4] 2,359,296 BatchNorm2d-56 [-1, 512, 4, 4] 1,024 BasicBlock-57 [-1, 512, 4, 4] 0 AvgPool2d-58 [-1, 512, 1, 1] 0 Linear-59 [-1, 10] 5,130 ================================================================ Total params: 11,173,962 Trainable params: 11,173,962 Non-trainable params: 0 ---------------------------------------------------------------- Input size (MB): 0.01 Forward/backward pass size (MB): 13.63 Params size (MB): 42.63 Estimated Total Size (MB): 56.27 ----------------------------------------------------------------
首先從我們summary可以看到,我們定義的模型的引數大概是11 millions,我們輸入的是(batch,3,32,32)的張量,并且這里也能看到每一層后我們的影像輸出大小的變化,最后輸出10個引數,再通過softmax函式就可以得到我們每個類別的概率了,
我們也可以列印出我們的模型觀察一下
print(net)
ResNet( (features): Sequential( (0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (2): ReLU(inplace=True) ) (layer1): Sequential( (0): BasicBlock( (features): Sequential( (0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (2): ReLU(inplace=True) (3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (shortcut): Sequential() ) (1): BasicBlock( (features): Sequential( (0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (2): ReLU(inplace=True) (3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (shortcut): Sequential() ) ) (layer2): Sequential( (0): BasicBlock( (features): Sequential( (0): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (2): ReLU(inplace=True) (3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (shortcut): Sequential( (0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): BasicBlock( (features): Sequential( (0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (2): ReLU(inplace=True) (3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (shortcut): Sequential() ) ) (layer3): Sequential( (0): BasicBlock( (features): Sequential( (0): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (2): ReLU(inplace=True) (3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (shortcut): Sequential( (0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): BasicBlock( (features): Sequential( (0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (2): ReLU(inplace=True) (3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (shortcut): Sequential() ) ) (layer4): Sequential( (0): BasicBlock( (features): Sequential( (0): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (2): ReLU(inplace=True) (3): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (shortcut): Sequential( (0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): BasicBlock( (features): Sequential( (0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (2): ReLU(inplace=True) (3): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (shortcut): Sequential() ) ) (avg_pool): AvgPool2d(kernel_size=4, stride=4, padding=0) (classifer): Linear(in_features=512, out_features=10, bias=True) )
我們也可以測驗一下輸出
# 測驗
x = torch.randn(2, 3, 32, 32).to(device)
y = net(x)
print(y.shape)
block 1 output: torch.Size([2, 64, 32, 32])
block 2 output: torch.Size([2, 64, 32, 32])
block 3 output: torch.Size([2, 128, 16, 16])
block 4 output: torch.Size([2, 256, 8, 8])
block 5 output: torch.Size([2, 512, 4, 4])
torch.Size([2, 10])
如果你的電腦有多個GPU,這段代碼可以利用GPU進行并行計算,加快運算速度
net = ResNet34().to(device)
if device == 'cuda':
net = nn.DataParallel(net)
# 當計算圖不會改變的時候(每次輸入形狀相同,模型不改變)的情況下可以提高性能,反之則降低性能
torch.backends.cudnn.benchmark = True
5. 定義損失函式和優化器
pytorch將深度學習中常用的優化方法全部封裝在torch.optim之中,所有的優化方法都是繼承基類optim.Optimizier
損失函式是封裝在神經網路工具箱nn中的,包含很多損失函式
這里我使用的是SGD + momentum演算法,并且我們損失函式定義為交叉熵函式,除此之外學習策略定義為動態更新學習率,如果5次迭代后,訓練的損失并沒有下降,那么我們便會更改學習率,會變為原來的0.5倍,最小降低到0.00001
如果想更加了解優化器和學習率策略的話,可以參考以下資料
- Pytorch Note15 優化演算法1 梯度下降(Gradient descent varients)
- Pytorch Note16 優化演算法2 動量法(Momentum)
- Pytorch Note34 學習率衰減
這里決定迭代20次
import torch.optim as optimoptimizer = optim.SGD(net.parameters(), lr=1e-1, momentum=0.9, weight_decay=5e-4)criterion = nn.CrossEntropyLoss()scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min', factor=0.5 ,patience = 5,min_lr = 0.000001) # 動態更新學習率# scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[75, 150], gamma=0.5)import timeepoch = 20
6. 訓練
首先定義模型保存的位置
import os
if not os.path.exists('./model'):
os.makedirs('./model')
else:
print('檔案已存在')
save_path = './model/ResNet34.pth'
我定義了一個train函式,在train函式中進行一個訓練,并保存我們訓練后的模型
from utils import train
from utils import plot_history
Acc, Loss, Lr = train(net, trainloader, testloader, epoch, optimizer, criterion, scheduler, save_path, verbose = True)
Epoch [ 1/ 20] Train Loss:2.159606 Train Acc:23.53% Test Loss:1.755478 Test Acc:33.49% Learning Rate:0.100000 Time 03:02 Epoch [ 2/ 20] Train Loss:1.638957 Train Acc:38.55% Test Loss:1.501977 Test Acc:45.09% Learning Rate:0.100000 Time 02:57 Epoch [ 3/ 20] Train Loss:1.406517 Train Acc:48.46% Test Loss:1.428001 Test Acc:48.31% Learning Rate:0.100000 Time 02:56 Epoch [ 4/ 20] Train Loss:1.206273 Train Acc:56.53% Test Loss:1.172715 Test Acc:58.97% Learning Rate:0.100000 Time 02:56 Epoch [ 5/ 20] Train Loss:1.038469 Train Acc:62.78% Test Loss:1.046036 Test Acc:63.54% Learning Rate:0.100000 Time 03:10 Epoch [ 6/ 20] Train Loss:0.910261 Train Acc:67.88% Test Loss:0.980679 Test Acc:65.65% Learning Rate:0.100000 Time 03:30 Epoch [ 7/ 20] Train Loss:0.806868 Train Acc:71.54% Test Loss:0.863342 Test Acc:69.91% Learning Rate:0.100000 Time 03:27 Epoch [ 8/ 20] Train Loss:0.718442 Train Acc:74.87% Test Loss:0.922080 Test Acc:68.44% Learning Rate:0.100000 Time 03:11 Epoch [ 9/ 20] Train Loss:0.639691 Train Acc:77.75% Test Loss:0.760849 Test Acc:73.81% Learning Rate:0.100000 Time 02:57 Epoch [ 10/ 20] Train Loss:0.588514 Train Acc:79.64% Test Loss:0.627114 Test Acc:78.40% Learning Rate:0.100000 Time 02:58 Epoch [ 11/ 20] Train Loss:0.531749 Train Acc:81.48% Test Loss:0.810104 Test Acc:73.08% Learning Rate:0.100000 Time 03:02 Epoch [ 12/ 20] Train Loss:0.493843 Train Acc:82.86% Test Loss:0.604436 Test Acc:79.85% Learning Rate:0.100000 Time 03:03 Epoch [ 13/ 20] Train Loss:0.464070 Train Acc:84.13% Test Loss:0.703119 Test Acc:76.75% Learning Rate:0.100000 Time 03:08 Epoch [ 14/ 20] Train Loss:0.435086 Train Acc:85.07% Test Loss:0.573155 Test Acc:81.00% Learning Rate:0.100000 Time 03:05 Epoch [ 15/ 20] Train Loss:0.408148 Train Acc:86.04% Test Loss:0.762852 Test Acc:76.57% Learning Rate:0.100000 Time 03:06 Epoch [ 16/ 20] Train Loss:0.385001 Train Acc:86.77% Test Loss:0.602157 Test Acc:78.96% Learning Rate:0.100000 Time 03:05 Epoch [ 17/ 20] Train Loss:0.381946 Train Acc:86.90% Test Loss:0.476164 Test Acc:83.56% Learning Rate:0.100000 Time 02:57 Epoch [ 18/ 20] Train Loss:0.364283 Train Acc:87.46% Test Loss:0.442250 Test Acc:85.27% Learning Rate:0.100000 Time 03:03 Epoch [ 19/ 20] Train Loss:0.353942 Train Acc:87.81% Test Loss:0.487022 Test Acc:83.77% Learning Rate:0.100000 Time 02:56 Epoch [ 20/ 20] Train Loss:0.342116 Train Acc:88.22% Test Loss:0.554701 Test Acc:81.68% Learning Rate:0.100000 Time 03:00
接著可以分別列印,損失函式曲線,準確率曲線和學習率曲線
plot_history(epoch ,Acc, Loss, Lr)
損失函式曲線

準確率曲線
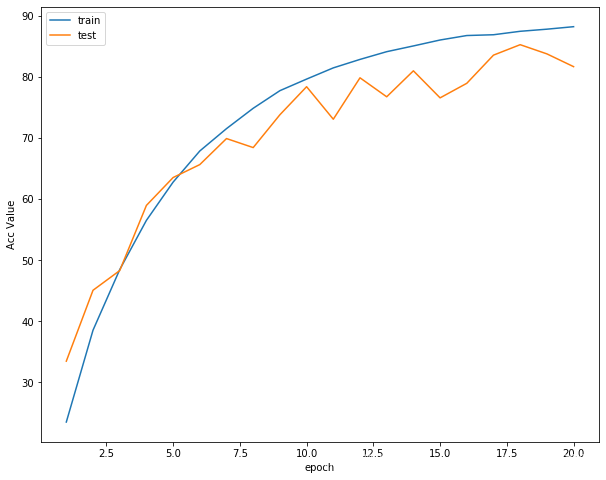
學習率曲線
7.測驗
查看準確率
correct = 0 # 定義預測正確的圖片數,初始化為0
total = 0 # 總共參與測驗的圖片數,也初始化為0
# testloader = torch.utils.data.DataLoader(testset, batch_size=32,shuffle=True, num_workers=2)
for data in testloader: # 回圈每一個batch
images, labels = data
images = images.to(device)
labels = labels.to(device)
net.eval() # 把模型轉為test模式
if hasattr(torch.cuda, 'empty_cache'):
torch.cuda.empty_cache()
outputs = net(images) # 輸入網路進行測驗
# outputs.data是一個4x10張量,將每一行的最大的那一列的值和序號各自組成一個一維張量回傳,第一個是值的張量,第二個是序號的張量,
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0) # 更新測驗圖片的數量
correct += (predicted == labels).sum() # 更新正確分類的圖片的數量
print('Accuracy of the network on the 10000 test images: %.2f %%' % (100 * correct / total))
Accuracy of the network on the 10000 test images: 82.01 %
可以看到自定義網路的模型在測驗集中準確率達到82.01%
程式中的 torch.max(outputs.data, 1) ,回傳一個tuple (元組)
而這里很明顯,這個回傳的元組的第一個元素是image data,即是最大的 值,第二個元素是label, 即是最大的值 的 索引!我們只需要label(最大值的索引),所以就會有_,predicted這樣的賦值陳述句,表示忽略第一個回傳值,把它賦值給_, 就是舍棄它的意思;
查看每一類的準確率
# 定義2個存盤每類中測驗正確的個數的 串列,初始化為0
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
# testloader = torch.utils.data.DataLoader(testset, batch_size=64,shuffle=True, num_workers=2)
net.eval()
with torch.no_grad():
for data in testloader:
images, labels = data
images = images.to(device)
labels = labels.to(device)
if hasattr(torch.cuda, 'empty_cache'):
torch.cuda.empty_cache()
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
#4組(batch_size)資料中,輸出于label相同的,標記為1,否則為0
c = (predicted == labels).squeeze()
for i in range(len(images)): # 因為每個batch都有4張圖片,所以還需要一個4的小回圈
label = labels[i] # 對各個類的進行各自累加
class_correct[label] += c[i]
class_total[label] += 1
for i in range(10):
print('Accuracy of %5s : %.2f %%' % (classes[i], 100 * class_correct[i] / class_total[i]))
Accuracy of airplane : 62.40 % Accuracy of automobile : 91.80 % Accuracy of bird : 86.10 % Accuracy of cat : 58.70 % Accuracy of deer : 87.30 % Accuracy of dog : 82.50 % Accuracy of frog : 93.90 % Accuracy of horse : 84.70 % Accuracy of ship : 89.20 % Accuracy of truck : 83.20 %
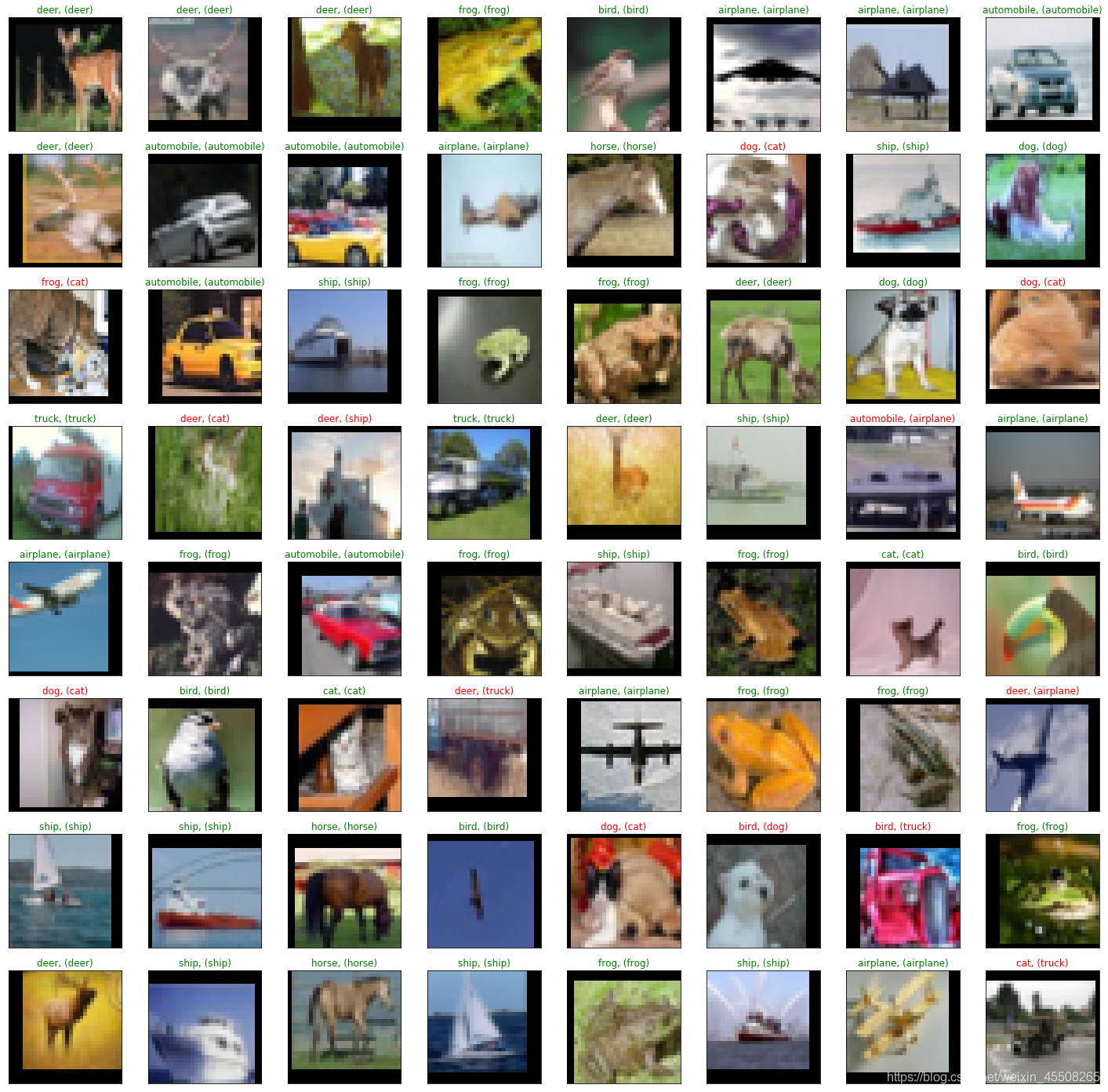
抽樣測驗并可視化一部分結果
dataiter = iter(testloader)
images, labels = dataiter.next()
images_ = images
#images_ = images_.view(images.shape[0], -1)
images_ = images_.to(device)
labels = labels.to(device)
val_output = net(images_)
_, val_preds = torch.max(val_output, 1)
fig = plt.figure(figsize=(25,4))
correct = torch.sum(val_preds == labels.data).item()
val_preds = val_preds.cpu()
labels = labels.cpu()
print("Accuracy Rate = {}%".format(correct/len(images) * 100))
fig = plt.figure(figsize=(25,25))
for idx in np.arange(64):
ax = fig.add_subplot(8, 8, idx+1, xticks=[], yticks=[])
#fig.tight_layout()
# plt.imshow(im_convert(images[idx]))
imshow(images[idx])
ax.set_title("{}, ({})".format(classes[val_preds[idx].item()], classes[labels[idx].item()]),
color = ("green" if val_preds[idx].item()==labels[idx].item() else "red"))
Accuracy Rate = 81.25% <Figure size 1800x288 with 0 Axes>
8. 保存模型
torch.save(net,save_path[:-4]+'_'+str(epoch)+'.pth')
# torch.save(net, './model/ResNet34.pth')
9. 預測
讀取本地圖片進行預測
import torch
from PIL import Image
from torch.autograd import Variable
import torch.nn.functional as F
from torchvision import datasets, transforms
import numpy as np
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = ResNet34()
model = torch.load(save_path) # 加載模型
# model = model.to('cuda')
model.eval() # 把模型轉為test模式
# 讀取要預測的圖片
img = Image.open("./airplane.jpg").convert('RGB') # 讀取影像
img

接著我們就進行預測圖片,不過這里有一個點,我們需要對我們的圖片也進行transforms,因為我們的訓練的時候,對每個影像也是進行了transforms的,所以我們需要保持一致
trans = transforms.Compose([transforms.Scale((32,32)),
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5),
std=(0.5, 0.5, 0.5)),
])
img = trans(img)
img = img.to(device)
# 圖片擴展多一維,因為輸入到保存的模型中是4維的[batch_size,通道,長,寬],而普通圖片只有三維,[通道,長,寬]
img = img.unsqueeze(0)
# 擴展后,為[1,3,32,32]
output = model(img)
prob = F.softmax(output,dim=1) #prob是10個分類的概率
print("概率",prob)
value, predicted = torch.max(output.data, 1)
print("類別",predicted.item())
print(value)
pred_class = classes[predicted.item()]
print("分類",pred_class)
概率 tensor([[9.9965e-01, 3.6513e-06, 1.7105e-04, 5.1874e-06, 9.1150e-05, 2.3654e-07, 1.0426e-06, 3.9004e-07, 7.9401e-05, 2.4640e-06]], device='cuda:0', grad_fn=<SoftmaxBackward>) 類別 0 tensor([10.8828], device='cuda:0') 分類 plane
這里就可以看到,我們最后的結果,分類為plane,我們的置信率大概是99.96%,可以說是比較準確的了
讀取圖片地址進行預測
我們也可以通過讀取圖片的url地址進行預測,這里我找了多個不同的圖片進行預測
import requests
from PIL import Image
url = 'https://dss2.bdstatic.com/70cFvnSh_Q1YnxGkpoWK1HF6hhy/it/u=947072664,3925280208&fm=26&gp=0.jpg'
url = 'https://ss0.bdstatic.com/70cFuHSh_Q1YnxGkpoWK1HF6hhy/it/u=2952045457,215279295&fm=26&gp=0.jpg'
url = 'https://ss0.bdstatic.com/70cFvHSh_Q1YnxGkpoWK1HF6hhy/it/u=2838383012,1815030248&fm=26&gp=0.jpg'
url = 'https://gimg2.baidu.com/image_search/src=http%3A%2F%2Fwww.goupuzi.com%2Fnewatt%2FMon_1809%2F1_179223_7463b117c8a2c76.jpg&refer=http%3A%2F%2Fwww.goupuzi.com&app=2002&size=f9999,10000&q=a80&n=0&g=0n&fmt=jpeg?sec=1624346733&t=36ba18326a1e010737f530976201326d'
url = 'https://ss3.bdstatic.com/70cFv8Sh_Q1YnxGkpoWK1HF6hhy/it/u=2799543344,3604342295&fm=224&gp=0.jpg'
# url = 'https://ss1.bdstatic.com/70cFuXSh_Q1YnxGkpoWK1HF6hhy/it/u=2032505694,2851387785&fm=26&gp=0.jpg'
response = requests.get(url, stream=True)
print (response)
img = Image.open(response.raw)
img

這里和前面是一樣的
trans = transforms.Compose([transforms.Scale((32,32)),
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5),
std=(0.5, 0.5, 0.5)),
])
img = trans(img)
img = img.to(device)
# 圖片擴展多一維,因為輸入到保存的模型中是4維的[batch_size,通道,長,寬],而普通圖片只有三維,[通道,長,寬]
img = img.unsqueeze(0)
# 擴展后,為[1,3,32,32]
output = model(img)
prob = F.softmax(output,dim=1) #prob是10個分類的概率
print("概率",prob)
value, predicted = torch.max(output.data, 1)
print("類別",predicted.item())
print(value)
pred_class = classes[predicted.item()]
print("分類",pred_class)
概率 tensor([[5.0480e-02, 3.3666e-04, 9.2583e-03, 7.4729e-01, 3.3520e-03, 1.6813e-01, 7.2700e-03, 3.9508e-03, 8.4040e-03, 1.5270e-03]], device='cuda:0', grad_fn=<SoftmaxBackward>) 類別 3 tensor([4.2263], device='cuda:0') 分類 cat
對于這個網路圖片來說,我們分類的結果是cat,符合我們的判斷,置信率達到了92.58%,可以看出來,我們的殘差網路在影像識別中取得了不錯的結果,
10.總結
殘差網路的出現,可以說極大的提高了我們的準確率,簡化比以前使用的網路更深的網路的訓練,而且有更多的證據表明這些殘差網路更容易優化,并且可以從顯著增加的深度中獲得準確性,并且利用殘差網路結構,我們也可以堆疊我們網路的深度,這種堆疊不會出現退化問題,所以殘差網路的出現體現了very deep的未來,對計算機視覺領域作出了很大的貢獻
順帶提一句,我們的資料和代碼都在我的匯總篇里有說明,如果需要,可以自取
這里再貼一下匯總篇:匯總篇
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293274.html
標籤:其他
上一篇:開始使用OpenCV
下一篇:redis(七)、運維配置注意