文章目錄
- 0 前言
- 1 RNN to CNN
- 2 Self-Attention
- 2.1 Base Method
- 2.2 Matrix Representation
- 2.3 Multi-head Self-attention
- 2.4 Positional Encoding
- 3 Seq2Seq Based on Self-Attention
- 3.1 Base Method
- 3.2 Transformer
- 4 Attention Visualization
0 前言
本節學習的是Transformer,Google于2017年6月發布在arxiv上的一篇文章《Attention is all you need》,提出解決sequence to sequence問題的transformer模型,用全self-attention的結構代替了lstm,這也是現在主流的BERT模型的基礎,本文由整理李宏毅老師視頻課筆記和個人理解所得,詳細講述了Transformer的原理及實作方法,我會及時回復評論區的問題,如果覺得本文有幫助歡迎點贊 😃,
1 RNN to CNN
一般常用的就是RNN,輸入是一串Vector Sequence,輸出也是一串Vector Sequence,RNN常用于處理輸入是有序的情況,但是RNN有問題——不易被平行化(并行運算),如圖,就單向RNN而言,當僅需要輸出
b
4
b^4
b4時,則需要等候
a
1
,
a
2
,
a
3
,
a
4
a^1, a^2, a^3, a^4
a1,a2,a3,a4的輸入,即使是雙向的RNN,
b
1
,
b
2
,
b
3
,
b
4
b^1, b^2, b^3, b^4
b1,b2,b3,b4也不能同時計算:
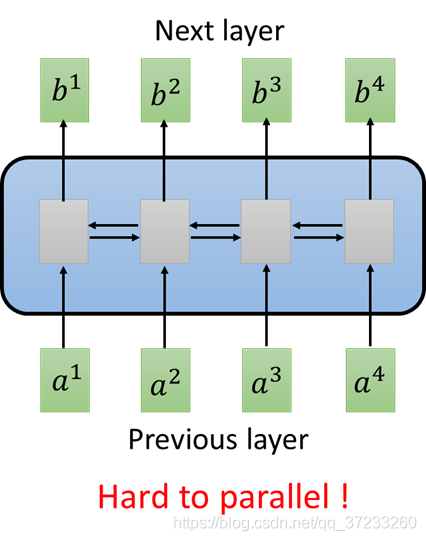
所以有人想使用CNN來代替RNN,輸入不變,三角形代表是一個Filter(不止一個),以3個向量為一組進行掃描,多使用幾組Filter也可以做到,輸入是一個Sequence,對應輸出是一個Sequence:
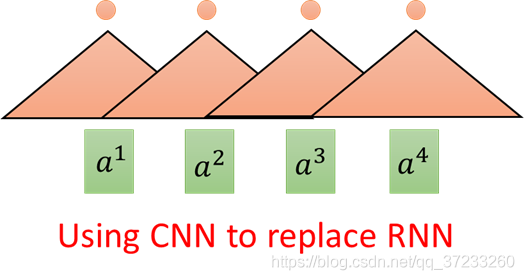
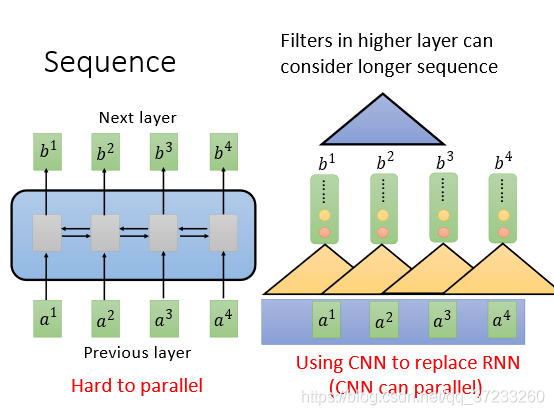
表面上CNN和RNN一樣,但是一層CNN的一個輸出只考慮三個輸入的Vector,但是RNN(雙向的)卻要考慮整個句子,所以考慮增加CNN的層數,這樣就是可以使得感受野增大,即可以考慮所有的輸入,CNN的好處是可以平行化,每一個Filter(三角形)都可以單獨運算,并不需要等之前或者之后的Filter計算結束,
2 Self-Attention
2.1 Base Method
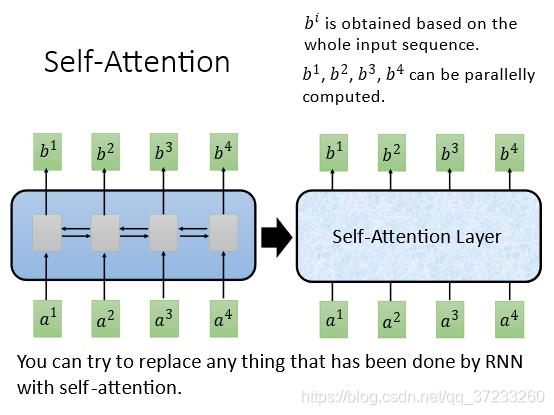
CNN需要疊很多層,如果只要求一層就要獲得所有輸入的資訊怎么做呢?這里就是引入Self-Attention Layer,可以完美替代雙向RNN:
輸入是
x
i
x^i
xi,通過一個embedding(映射)W矩陣得到
a
i
a^i
ai,然后將
a
i
a^i
ai輸入到self-attention layer,分別乘上三個不同的變換,獲得三個不同的vector,即
q
i
,
k
i
,
v
i
q^i,k^i,v^i
qi,ki,vi,代表不同的三種意思:
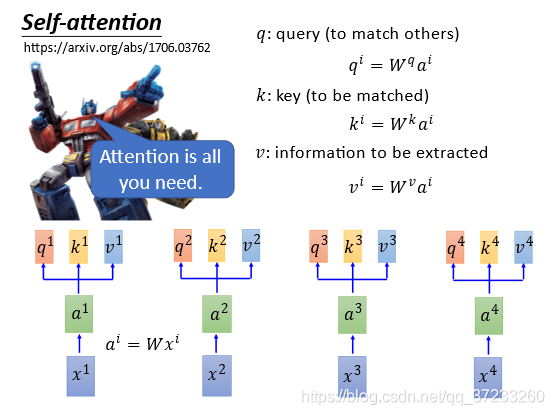
接下來要做拿每一個query
q
q
q去對每一個key
k
k
k做attention(4對4),以
q
1
q^1
q1為例,如下圖,得到4個attention: 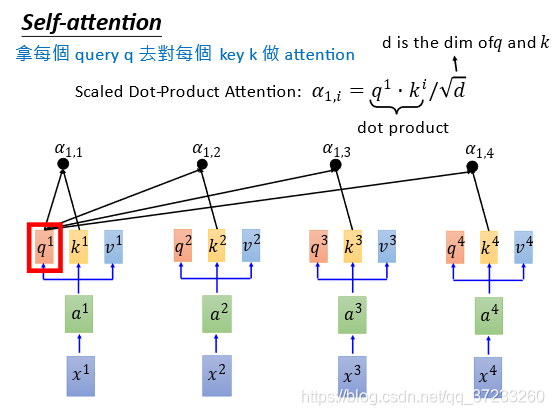
我們已知attention的本質就是匹配度,那么就需要定義匹配度的計算:
α
1
,
i
=
q
1
?
k
i
/
d
\alpha_{1, i}=q^{1} \cdot k^{i} / \sqrt{d}
α1,i?=q1?ki/d
?
其中d是
q
q
q和
k
k
k的維度,關于除以
d
\sqrt{d}
d
?有個這樣的解釋:
q
q
q和
k
k
k的內積的值和維度d大小關系很大,這樣除了之后方差就會為1了,當然定義別的匹配度也可以,
接下來通過一個Softmax Layer得到對應的概率值
α
^
1
,
1
α
^
1
,
2
α
^
1
,
3
α
^
1
,
4
\begin{array}{llll}\hat{\alpha}_{1,1} & \hat{\alpha}_{1,2} & \hat{\alpha}_{1,3} & \hat{\alpha}_{1,4}\end{array}
α^1,1??α^1,2??α^1,3??α^1,4??:
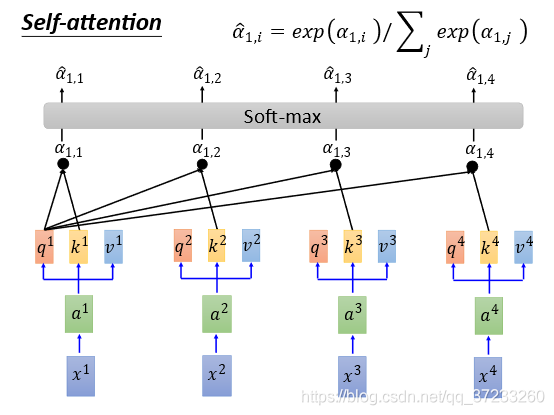
將
α
^
1
,
1
α
^
1
,
2
α
^
1
,
3
α
^
1
,
4
\begin{array}{llll}\hat{\alpha}_{1,1} & \hat{\alpha}_{1,2} & \hat{\alpha}_{1,3} & \hat{\alpha}_{1,4}\end{array}
α^1,1??α^1,2??α^1,3??α^1,4??與各自的
v
v
v相乘之后相加(
b
1
=
∑
i
α
^
1
,
i
v
i
b^{1}=\sum_{i} \hat{\alpha}_{1, i} v^{i}
b1=∑i?α^1,i?vi 等價于weight sum),得到一個向量
b
1
b^1
b1:
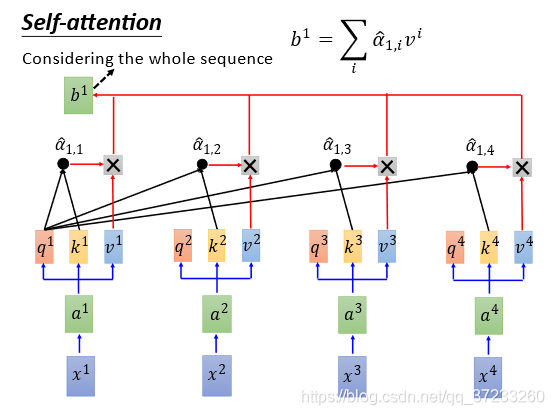
這樣Self-Attention就輸出一個vector,而且產生這個
b
1
b^1
b1已經考慮了所有輸入的資訊,如果只想考慮local的資訊,只需要將
α
^
1
,
1
α
^
1
,
2
α
^
1
,
3
α
^
1
,
4
\begin{array}{llll}\hat{\alpha}_{1,1} & \hat{\alpha}_{1,2} & \hat{\alpha}_{1,3} & \hat{\alpha}_{1,4}\end{array}
α^1,1??α^1,2??α^1,3??α^1,4??中不需要的變成0就可以了,需要什么資訊,就獲取什么資訊,
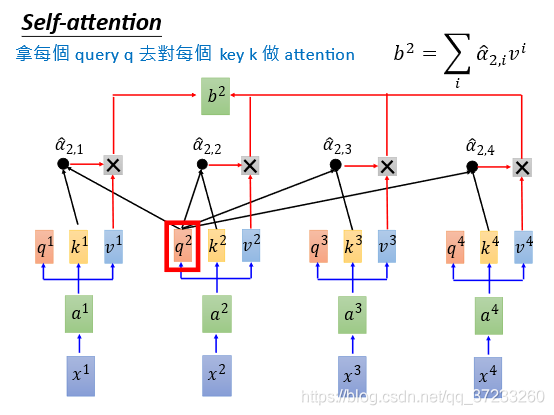
因為資訊是已知的,在同一個時間如下圖可以計算
b
2
b^2
b2,并不沖突:
總而言之,輸入了
x
1
,
x
2
,
x
3
,
x
4
x^1, x^2, x^3 ,x^4
x1,x2,x3,x4,輸出了
b
1
,
b
2
,
b
3
,
b
4
b^1, b^2, b^3, b^4
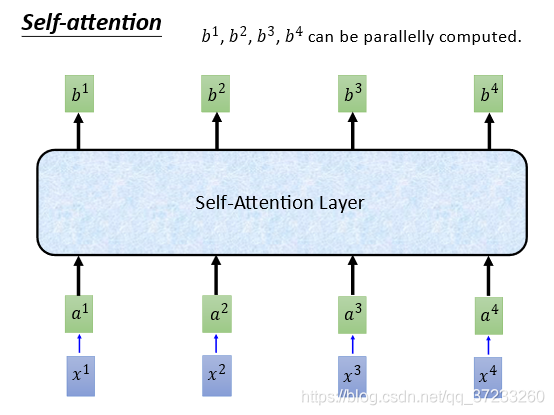
b1,b2,b3,b4,和RNN做了一樣的作業,但是可以平行計算的:
2.2 Matrix Representation
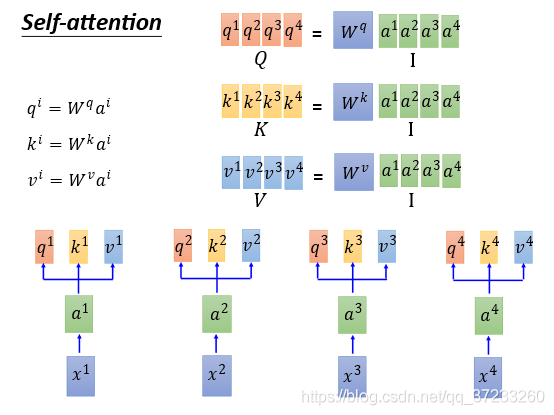
接下來用矩陣的形式表述Self-Attention是怎么做平行化的,將所有的
q
q
q收集起來作為一個
Q
Q
Q矩陣,每一列作為一個
q
q
q,同理可以得到其他的矩陣:
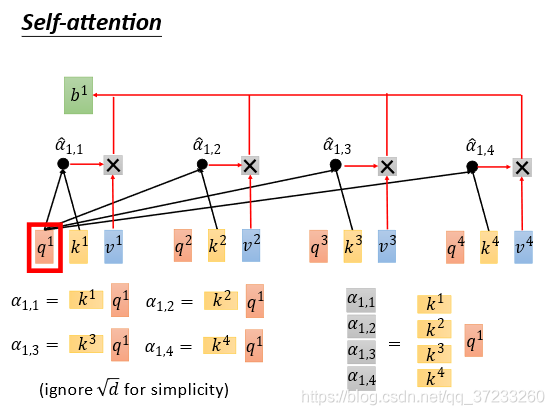
接下來表述
α
i
,
j
\alpha_{i,j}
αi,j?(注意還沒有經過Softmax層)的計算,單獨的一個
α
1
,
1
\alpha_{1,1}
α1,1?等于
k
1
k^1
k1的轉置乘上
q
1
q^1
q1,為了方便表述先忽略系數
d
\sqrt{d}
d
?,將4個都合并起來可以得到:
將所有的
α
i
,
j
\alpha_{i,j}
αi,j?合并為一個矩陣,可以得到
A
=
K
T
Q
A=K^TQ
A=KTQ,經過softmax層后得到
A
/
h
a
t
A^/hat
A/hat:
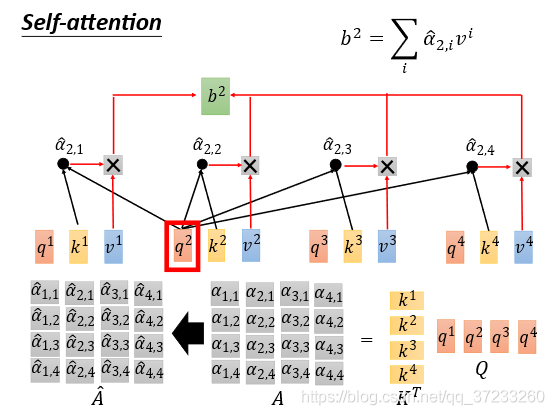
然后表示weight sum,就是self-attention的輸出:
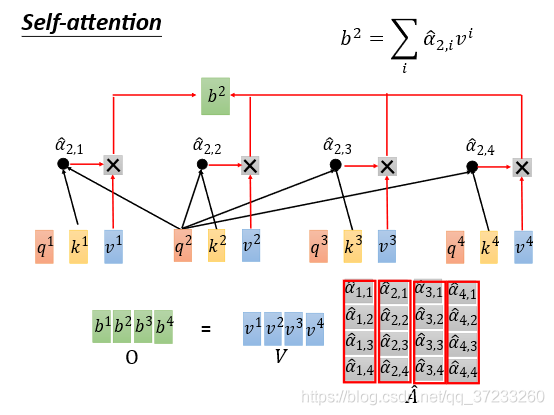
完整的程序如下,矩陣乘法可以用GPU計算:
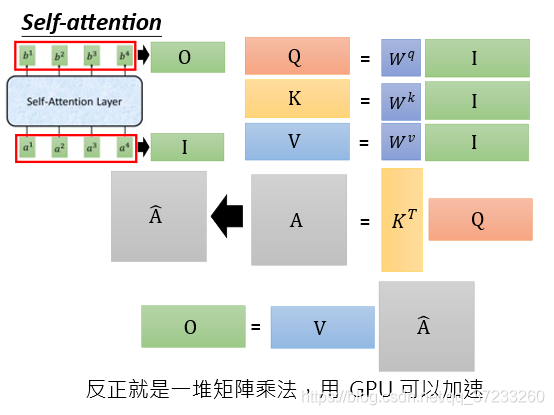
2.3 Multi-head Self-attention
Multi-head Self-attention,首先使用2 head的情況舉例,每一組的
q
I
,
k
I
,
v
i
q^I, k^I, v^i
qI,kI,vi都分別分裂為兩個,但是對應的下標
q
,
k
,
v
q, k, v
q,k,v還是去找其他相同位置的
q
,
k
,
v
q, k, v
q,k,v運算,如圖:
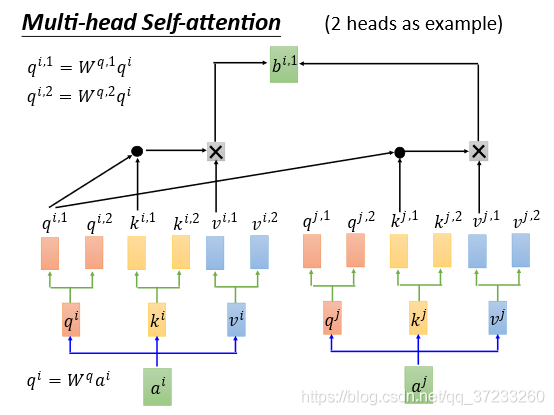
相同的操作得到
b
i
,
2
b^{i,2}
bi,2:
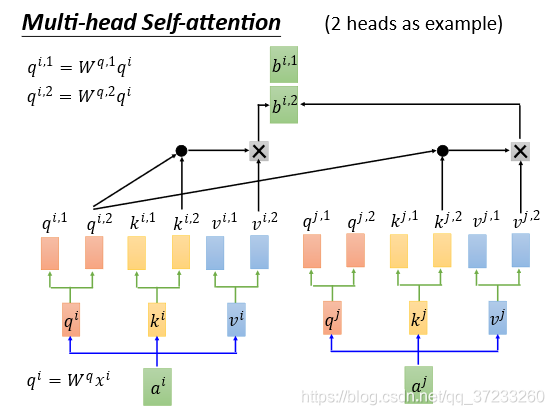
通過矩陣拼接可求出
b
i
b^i
bi,也可以使用一個
W
0
W^0
W0獲得一個降維的
b
i
b^i
bi:
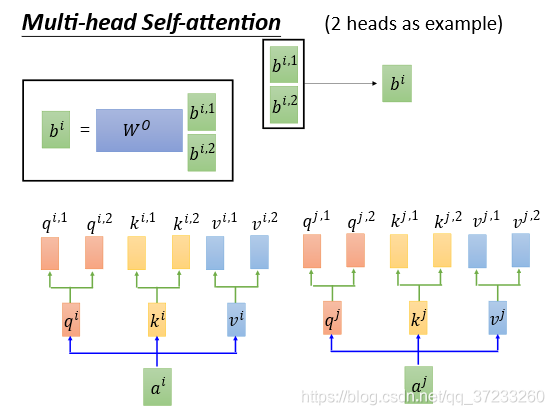
實際在做的時候head的個數是可以調整的,
2.4 Positional Encoding
對于一般的self-attention來說,input的順序和位置是不重要的,因為做attention的時候所有的輸入都會用到,但是這樣就少了位置資訊,為了解決這個問題,就在
a
i
a^i
ai旁邊加上位置向量
e
i
e^i
ei,這兩個vector的維度是一樣的,這個
e
i
e^i
ei不是學出來的,而是超引數:
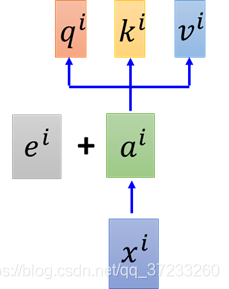
為什么是相加而不是接起來呢?這里李宏毅老師給出了一個解釋:將每個原始輸入
x
i
x^i
xi下面接上一個表征位置資訊的獨熱向量
p
i
p^i
pi,相接的結果乘上一個變換矩陣W,這里的W可以拆解為
W
I
W^I
WI和
W
P
W^P
WP,最后的結果仍然是
a
i
+
e
i
a^i+e^i
ai+ei:
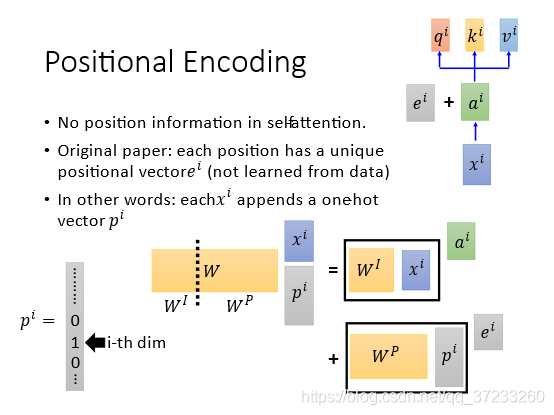
W
I
W^I
WI部分(類似之前的
W
W
W)和
x
i
x^i
xi相乘得到了
a
i
a^i
ai,
W
P
W^P
WP和
p
i
p^i
pi相乘得到了
e
i
e^i
ei,這個
W
P
W^P
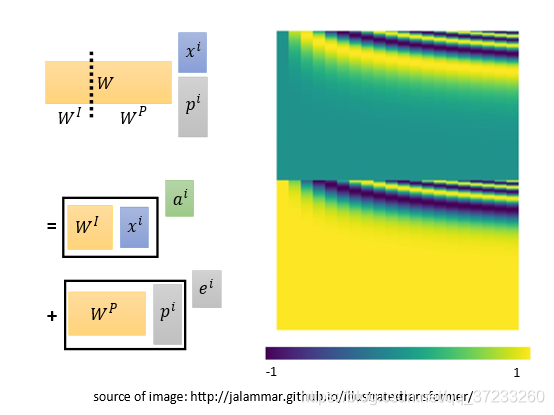
WP是可以學習的,不過最好是手動設定的,一般依據的
W
P
W^P
WP畫圖出來是下面的樣子:
3 Seq2Seq Based on Self-Attention
3.1 Base Method
Self-Attention在Seq2Seq模型里是怎么使用的?RNN實作Seq2Seq模型我們已經知道了,一個是Encoder,另外一邊是Decoder,可以用來比如訓練一個翻譯器之類的:
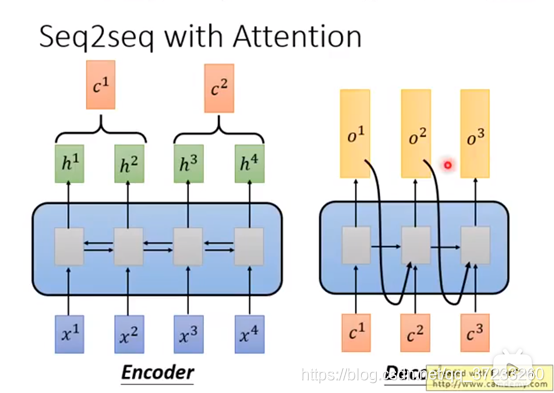
這里的雙向的RNN和Decoder的RNN都可以用self-attention替換: 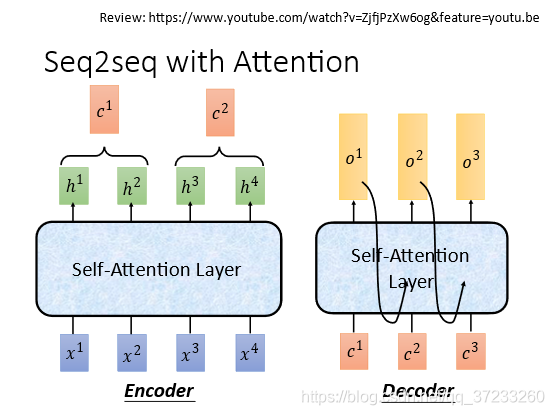
下圖是谷歌制作的self-attention的Encoder和Decoder的運行流程:

3.2 Transformer
這個圖是Transformer的模型,輸入是“機器學習“,輸出是”machine learning“:
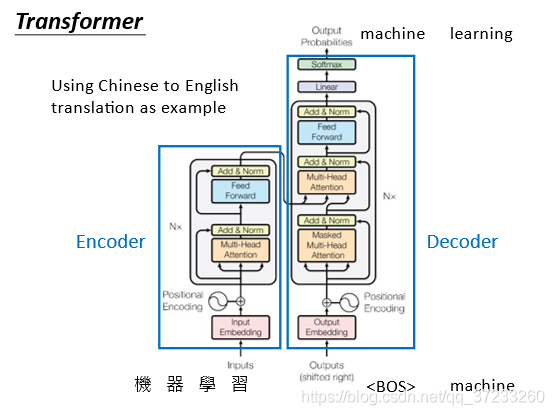
1)先看Encoder的部分,輸入input
x
i
x^i
xi經過一個embedding 提取特征之后變成之前的
a
i
a^i
ai,然后與位置編碼
p
i
p^i
pi在這里加入,會進入灰色的框中,再輸入到一個self-attention layer中,輸出
b
b
b之后,經過Add & Norm layer,這個層就是將
b
b
b和self-attention layer的輸入會加起來,加起來之后做一個Layer normalization,可以簡單理解為做一個標準化,Feed forward 層可以彌補self-attention的非線性(這里不展開),
2)再看Decoder部分,Input部分是前一個time step產生的output,這里的第一層是一個叫帶masked 的self-attention layer,masked意識是做attention的時候只會關注到已經產生的sequence,然后和Encoder的輸出一起做Attention,接下來經過一系列變換后輸出:
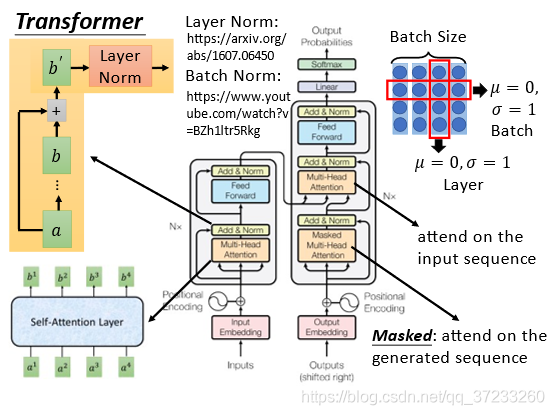
以上就是完整的Transformer的流程,
4 Attention Visualization
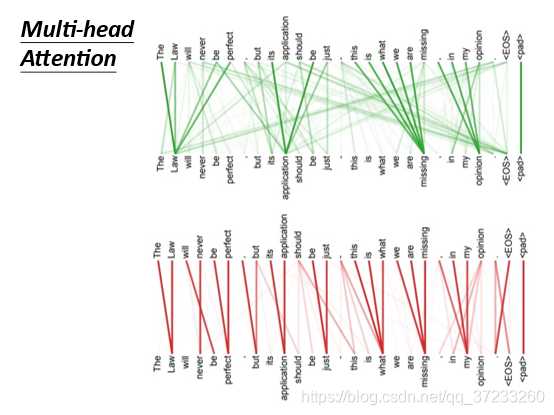
將self-attention的結果做可視化操作,當結尾的單詞是“tired“時,”it“ attend 更多的是”animal“;如右邊的圖,當結尾單詞是”wide“的時候,”it“ attend 更多的是”street“,

而對于Multi-head Attention來說,一個word可以attend更多的其他詞匯:
輸入一個文章集合,使用transformer生成一篇文章:
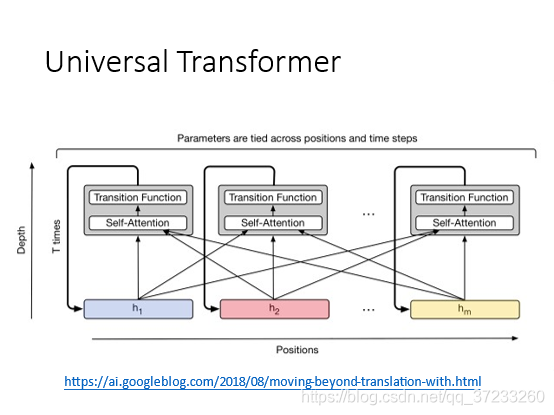
在深度上使用RNN的原理將transformer疊加:
Self-Attention GAN
大意是影像處理時為了獲得更多的影像資訊,也可以使用Self-Attention:

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293301.html
標籤:AI
下一篇:深度神經網路中的卷積