目錄
一.什么是Hadoop?
二.Hadoop 經典問題來認識Hadoop的思想
1.分而治之:有一個非常大的檔案,計算檔案每個單詞出現的次數
2.分而治之+合理磁區:有兩個非常大的檔案,每一行存放一個字串,統計出兩個檔案相同的字串
3.Hbase 布隆過濾器:一個非常大的檔案,存著一行行的url,給一個url,怎么快速查找到這個url是否在這個檔案中
三.Hadoop 進階歷史
1.總有高手能實作別人的論文理論
2.Hadoop 1.0 與 Hadoop 2.0的區別
一.什么是Hadoop?
誕生:為了處理大資料(簡單粗暴)
本質:分而治之
在我理解中是分成三大部分:存盤,計算,中間協調組件
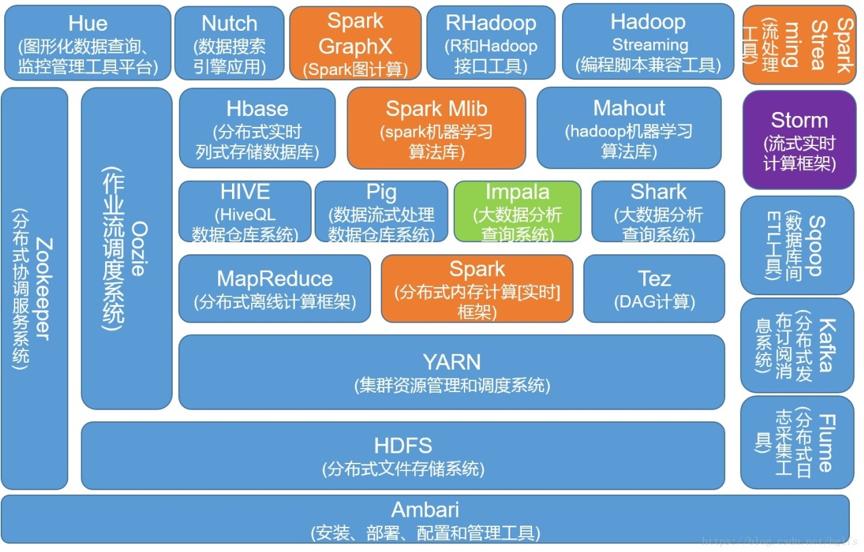
下面這張圖(來自度娘)很好的畫出了Hadoop的生態圈
二.Hadoop 經典問題來認識Hadoop的思想
1.分而治之:有一個非常大的檔案,計算檔案每個單詞出現的次數
眾人拾柴火焰高,面對大資料,一臺機器算不過來而且性能也差,分多臺機器算,是不是很像多執行緒的思想,如檔案是1個T,那么把1個T的檔案分成10個,由10臺機器計算一個檔案,每臺機器統計出自己計算檔案的單詞,和單詞出現的次數,算完之后,再由一臺機器進行聚合,就可以得出最好的結果,
---這里用到的思想就是Hadoop的重要思想:分而治之
2.分而治之+合理磁區:有兩個非常大的檔案,每一行存放一個字串,統計出兩個檔案相同的字串
如果用最粗暴的方法,遍歷去取的話,性能會非常差,
(1)這里提出第一個想法,能否按照第一個問題的思路,
分而治之:用多臺機器,或者分成多個任務來實作,答案是可以的:
我們將兩個檔案如:分別切成3個,那么每臺機器分別拿著左邊三個磁區,跟右邊的三個磁區進行對比,分成了9個任務:A-->(A1,B1,C1),B-->(A1,B1,C1) , C-->(A1,B1,C1),
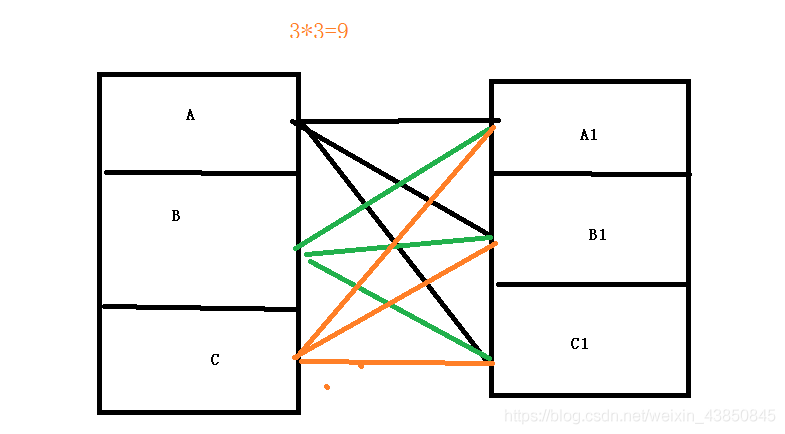
用多臺機器同時算的話,其實性能的消耗也非常大,因為每一臺機器自己那部分也要跟另一個大檔案做類似全表掃描的動作,
(2) 這時候我們遇到第一個問題就是:如何降低做類似全表掃描的動作
如果把相同的字串放在相同的磁區里,那么只要對應的磁區做比較,不用與其他磁區做比較,那么我們可以再進一步優化性能,
優化開始了:
兩個大檔案的字串分別取hashcode值,然后按照磁區數量取%,比如3個磁區,就%3,相同的字串的hashcode %3 得到的結果是一樣的,那么就會落入同一個磁區里面,那只要同個磁區的相互比較即可,任務數量從9降到了3,而且性能也提升了,
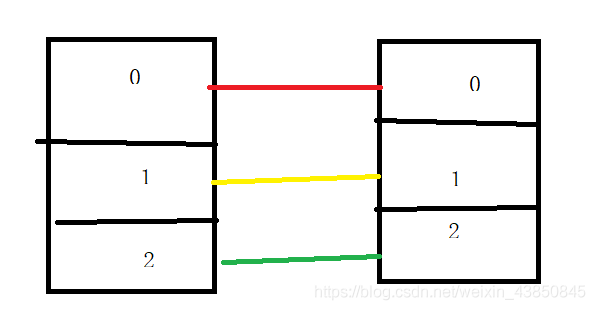
---這里用到的思想就是Hadoop的重要思想:分而治之+合理磁區
3.Hbase 布隆過濾器:一個非常大的檔案,存著一行行的url,給一個url,怎么快速查找到這個url是否在這個檔案中
快速快速快速!!!!!
(1) 能想到快的就是計數排序吧!
就是把url轉化為陣列的下標,通過下標取值是很快的,時間復雜度是O(n),但是計數排序是以空間換時間,它的缺陷有三個:
1.陣列的長度不好確定
2.會造成空間的極大浪費
3.陣列的型別不能確定
那我們能不能在這個解題思路上進行優化呢?比如可以確定下長度,型別,因為是超大的檔案,如果能將陣列的長度降低更好,
(2)解決長度:比如我們假設建立陣列的長度為10000,那我們可以將這個檔案的url求hashcode,然后%10000,將得到的值作為陣列的索引;
解決型別:因為我們是想要找這個url在不在,所以對于目標檔案的url得到的索引對應的值我們只要放0,1,0代表該索引對應的url是不存在的,1代表該索引對應的url是存在的,那么陣列的型別就可以設定為byte型別;
以上的思路舉個例子:
比如,想查找的url為:"https://blog.csdn.net/weixin_43850845?spm=1011.2124.3001.5343",假如在檔案中存在這個url,那這個url取完hashcode 再%10000得到5,假設陣列為 find[5]=1,那么我們直接查陣列find[5]是否等于1,就知道在檔案中是否存在目標url,
寫到這里,大家應該發現了bug,如果檔案中有另外個url hashcode取完%后也是等于5,那不就是有誤判了么?
(3)hash演算法沒有絕對完美的 ,是 存在hash沖突的問題,陣列長度越小沖突也就越大,沒有完美的演算法,那我們可以把誤判率降到最低,最好是能接近于0,
解決方案:
多設計幾個hash演算法:
每一個url存數的時候 需要經過多個hash演算法計算之后才能進行存盤
比如:"https://blog.csdn.net/weixin_43850845?spm=1011.2124.3001.5343",用5個hash演算法
hashcode01%10000=5;
hashcode02%10000=8;
hashcode03%10000=10;
hashcode04%10000=12;
hashcode05%10000=20;
那我們判斷url是否存在,那我們只要求find[5],find[8],find[10],find[12],find[20]都等于1,代表存在,存在有一個或以上為0,則代表不存在,
但是!!! 仍然存在誤判(因為仍然有可能存在另外一個url滿足上述的值):
總結以上:
誤判因素:
1.陣列的長度 m 陣列長度越長 誤判率越低
2.hashCode的演算法的個數 k 演算法的個數越多 誤判率越低的
3.資料量 資料量越小 誤判率越低
那是否是把陣列長度取到最長,hash演算法全部都來一遍??這樣子做,性能也會非常差,太多hash演算法也是很耗性能,那hash演算法到底取多少個的時候,性能又好,誤判率又能足夠低??
有的!!人類的腦袋真的太聰明了,False positives 概率推導(演算法是我的弱項,所以我直接拿結果,乖乖做一個在前人栽樹下乘涼的后人吧~~~)
即當k=0.7(m/n) 時,誤判率最低,m陣列長度,n是資料量
假如:m=100000 n=10000
那么 k=7 則只需要設計7個hash演算法 誤判率最低
但是誤判一定存在 , 接近0
--整個思路就是布隆過濾器的大致思路,而布隆過濾器也是hbase的一個查詢演算法
三.Hadoop 進階歷史
1.總有高手能實作別人的論文理論
在沒有Hadoop之前,很多搜索引擎公司都會遇到相同的問題,谷歌處理這些問題有對應的方案,但沒有將代碼開源,而是以論文的形式發表:
(1)如何存盤日益增長的資料?---2003年,Google發布Google File System論文,簡寫為GFS,分布式檔案存盤系統
(2)如何對大資料進行計算?--2004年公布的 MapReduce論文,論文描述了大資料的分布式計算方式
(3)如何對大資料進行快速查詢?--2006年,bigTable
而Doung cutting 看了這三篇論文后用java實作了,分別對應的是:
(1)GFS---->HDFS 分布式檔案存盤系統
(2)MapReduce-----> MapReduce 分布式計算
(3)bigTable ----->Hbase NoSql資料庫
具體的論文地址和資源可以看下這位大佬的博客: https://blog.csdn.net/zhongqi2513/article/details/88708723
2.Hadoop 1.0 與 Hadoop 2.0的區別
待續
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293310.html
標籤:其他
上一篇:Java專案:在線淘房系統(租房、購房)(java+SpringBoot+Redis+MySQL+Vue+SpringSecurity+JWT+ElasticSearch+WebSocket)
下一篇:31.分隔符例外分析