最近七天內連續三天活躍用戶數
首先,感謝大華公司給的面試機會,非常感謝~!
進入正題,建表:
create table uv_detail_daycount(
mid int
)PARTITIONED BY(dt string);
通過load將hdfs檔案加載到hive中,
資料檔案名如下:

里面的資料只有用戶mid,如下所示:

每個日期對應的用戶mid,即為該天活躍,
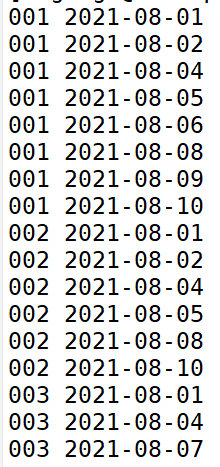
通過上圖可以發現,最近七天內連續三天活躍用戶數應該是001和002號用戶,最終2021-08-10這天的最近七天內連續三天活躍用戶數為2.
實作
第一步,查詢最近七天的資料,并按照日期從小到大進行排序,
select
mid,
dt,
rank() over(partition by mid order by dt) mid_dt_rank
from uv_detail_daycount
where dt >=date_add('2021-08-10',-6) and dt<='2021-08-10'
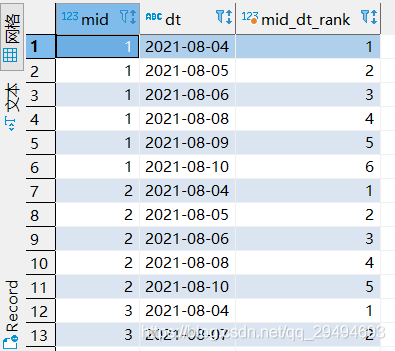
第二步,求日期和排名的差值.
with t1 as (select
mid,
dt,
rank() over(partition by mid order by dt) mid_dt_rank
from uv_detail_daycount
where dt >=date_add('2021-08-10',-6) and dt<='2021-08-10')
select
mid,
date_sub(dt, mid_dt_rank) date_dif
from
t1;
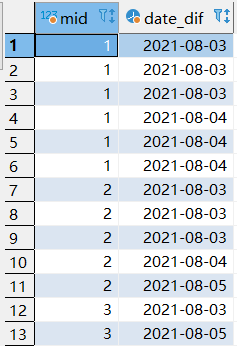
第三步,對用戶和差值進行分組,然后通過having選擇差值相同個數大于等于3的資料取出,
with t1 as (select
mid,
dt,
rank() over(partition by mid order by dt) mid_dt_rank
from uv_detail_daycount
where dt >=date_add('2021-08-10',-6) and dt<='2021-08-10'),
t2 as (select
mid,
date_sub(dt, mid_dt_rank) date_diff
from t1)
SELECT mid
from
t2
group by mid, date_diff
HAVING count(*) >= 3;
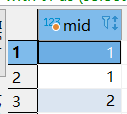
第四步,根據用戶id去重(為什么會出現重復的mid?最近七天可能用戶前3天用戶連續登錄滿足所求指標的要求,后三天也是如此,所以會出現mid重復,這個mid可以理解為該用戶滿足指標的次數吧,但是指標求的是活躍用戶數,所以要去重)
with t1 as (select
mid,
dt,
rank() over(partition by mid order by dt) mid_dt_rank
from uv_detail_daycount
where dt >=date_add('2021-08-10',-6) and dt<='2021-08-10'),
t2 as (select
mid,
date_sub(dt, mid_dt_rank) date_diff
from t1),
t3 as (SELECT mid
from
t2
group by mid, date_diff
HAVING count(*) >= 3)
select mid
from
t3
group by mid;
第五步,整理顯示:
with t1 as (select
mid,
dt,
rank() over(partition by mid order by dt) mid_dt_rank
from uv_detail_daycount
where dt >= date_add('2021-08-10',-6) and dt <= '2021-08-10'),
t2 as (select
mid,
date_sub(dt, mid_dt_rank) date_diff
from t1),
t3 as (SELECT mid
from
t2
group by mid, date_diff
HAVING count(*) >= 3),
t4 as(select mid
from
t3
group by mid)
select
'2021-08-10',
concat(date_add('2021-08-10',-6),'至','2021-08-10'),
count(*)
from
t4;

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293313.html
標籤:其他
上一篇:基于ranger的presto賬號權限管理及事件監聽方案
下一篇:Hadoop之HDFS