文章目錄
- 分布式存盤
- 路由
- 新增、索引和洗掉檔案
- 取回檔案
- 并發控制
- 分布式搜索
- 查詢階段
- 取回階段
分布式存盤
路由
當索引一個檔案的時候,Elasticsearch會通過哈希來決定將檔案存盤到哪一個主分片中,路由計算公式如下:
shard = hash(routing) % number_of_primary_shards
//routing:默認為檔案id,也可以自定義,
//number_of_primary_shards:主分片的數量
-
查詢時指定routing:可以直接根據routing資訊定位到某個分片查詢,不需要查詢所有的分配,經
過協調節點排序,
-
查詢時不指定routing:因為不知道要查詢的資料具體在哪個分片上,所以整個程序分為 2 個步驟
- 分發:請求到達協調節點后,協調節點將查詢請求分發到每個分片上,
- 聚合:協調節點搜集到每個分片上查詢結果,在將查詢的結果進行排序,之后給用戶回傳結果,
從上面的這個公式我們也可以看到一個問題,路由的邏輯與當前主分片的數量強關聯,也就是說如果分片數量變化了,那么所有之前路由的值都會無效,檔案也再也找不到了,這也就是為什么我們要在創建索引的時候就確定好主分片的數量并且永遠不會改變這個數量,
分片數量固定是否意味著會使索引難以進行擴容?
答案是否定的,Elasticsearch還提供了其他的一些方案來讓我們輕松的實作擴容,如:
- 分片預分配:一個分片存在于單個節點,但一個節點可以持有多個分片,因此我們可以根據未來的資料的擴張狀況來預先分配一定數量的分片到各個節點中,(注意??:預先分配過多的分片會導致性能的下降以及影響搜索結果的相關度)
- 新建索引:分片數不夠時,可以考慮新建索引,搜索1個有著50個分片的索引與搜索50個每個都有1個分片的索引完全等價,
更多關于水平拓展的內容可以參考官方檔案擴容設計,
新增、索引和洗掉檔案
我們可以發送請求到集群中的任一節點, 每個節點都有能力處理任意請求, 每個節點都知道集群中任一檔案位置,所以可以直接將請求轉發到需要的節點上, 在下面的例子中,將所有的請求發送到 Node 1 ,我們將其稱為協調節點(coordinating node) ,
當發送請求的時候, 為了擴展負載,更好的做法是輪詢集群中所有的節點,
新建、索引和洗掉請求都是寫操作, 必須在主分片上面完成之后才能被復制到相關的副本分片,
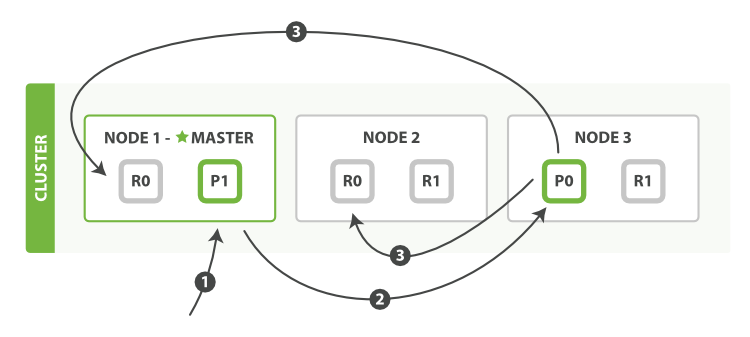
流程如下:
- 客戶端向
Node 1發送新建、索引或者洗掉請求, - 節點使用檔案的
_id確定檔案屬于分片 0 ,請求會被轉發到Node 3,因為分片 0 的主分片目前被分配在Node 3上, Node 3在主分片上面執行請求,如果成功了,它將請求并行轉發到Node 1和Node 2的副本分片上,一旦所有的副本分片都報告成功,Node 3將向協調節點報告成功,協調節點向客戶端報告成功,
取回檔案
由于取回檔案為讀操作,我們可以從主分片或者從其它任意副本分片檢索檔案,
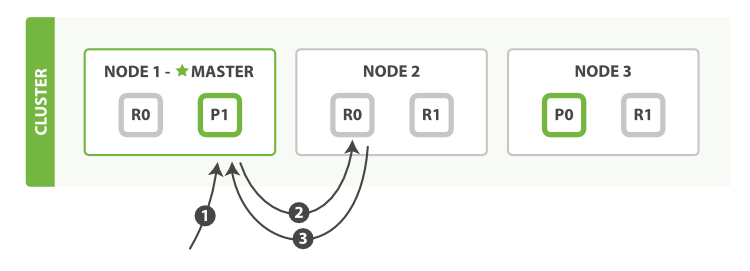
流程如下:
- 客戶端向
Node 1發送獲取請求, - 節點使用檔案的
_id來確定檔案屬于分片0,分片0的副本分片存在于所有的三個節點上, 在這種情況下,它將請求轉發到Node 2, Node 2將檔案回傳給Node 1,然后將檔案回傳給客戶端,
在處理讀取請求時,協調結點在每次請求的時候都會通過輪詢所有的副本分片來達到負載均衡,
并發控制
在資料庫領域中,有兩種方法通常被用來確保并發更新時變更不會丟失:
- 悲觀并發控制:這種方法被關系型資料庫廣泛使用,它假定有變更沖突可能發生,因此阻塞訪問資源以防止沖突, 一個典型的例子是讀取一行資料之前先將其鎖住,確保只有放置鎖的執行緒能夠對這行資料進行修改,
- 樂觀并發控制:Elasticsearch中使用的這種方法假定沖突是不可能發生的,并且不會阻塞正在嘗試的操作, 然而,如果源資料在讀寫當中被修改,更新將會失敗,應用程式接下來將決定該如何解決沖突, 例如,可以重試更新、使用新的資料、或者將相關情況報告給用戶,
Elasticsearch是分布式的,當檔案創建、更新或洗掉時, 新版本的檔案必須復制到集群中的其他節點,Elasticsearch也是異步和并發的,這意味著這些復制請求被并行發送,并且到達目的地時也許會亂序,所以Elasticsearch 需要一種方法確保檔案的舊版本不會覆寫新的版本,
在Elasticsearch中,其通過版本號機制來實作樂觀并發控制,即每一個檔案中都會有一個_version版本號欄位,當檔案被修改時版本號遞增, Elasticsearch使用_version來確保變更以正確順序得到執行,如果舊版本的檔案在新版本之后到達,它可以被簡單的忽略,
我們可以利用_version號來確保應用中相互沖突的變更不會導致資料丟失,我們通過指定想要修改檔案的 version 號來達到這個目的, 如果該版本不是當前版本號,我們的請求將會失敗,
// 例如我們想更新檔案的內容,并指定版本號為1
PUT /website/blog/1?version=1
{
"title": "My first blog entry",
"text": "Starting to get the hang of this..."
}
// 當檔案的版本號為1時,次請求成功,同時響應體告訴我們版本號遞增到2
{
"_index": "website",
"_type": "blog",
"_id": "1",
"_version": 2
"created": false
}
// 此時我們再次嘗試更新檔案的內容,仍然指定版本號為1,由于版本號不符合,此時回傳409 Conflict HTTP 回應碼
{
"error": {
"root_cause": [
{
"type": "version_conflict_engine_exception",
"reason": "[blog][1]: version conflict, current [2], provided [1]",
"index": "website",
"shard": "3"
}
],
"type": "version_conflict_engine_exception",
"reason": "[blog][1]: version conflict, current [2], provided [1]",
"index": "website",
"shard": "3"
},
"status": 409
}
分布式搜索
搜索需要一種更加復雜的執行模型,因為我們不知道查詢會命中哪些檔案,這些檔案有可能在集群的任何分片上, 一個搜索請求必須詢問我們關注的索引的所有分片的某個副本來確定它們是否含有任何匹配的檔案,
但是找到所有的匹配檔案僅僅完成事情的一半, 在 search 介面回傳一個 page 結果之前,多分片中的結果必須組合成單個排序串列, 為此,搜索被執行成一個兩階段程序,我們稱之為query then fetch(查詢后取回),
查詢階段
在查詢階段時, 查詢會廣播到索引中每一個分片拷貝(主分片或者副本分片), 每個分片在本地執行搜索并構建一個匹配檔案的優先佇列,
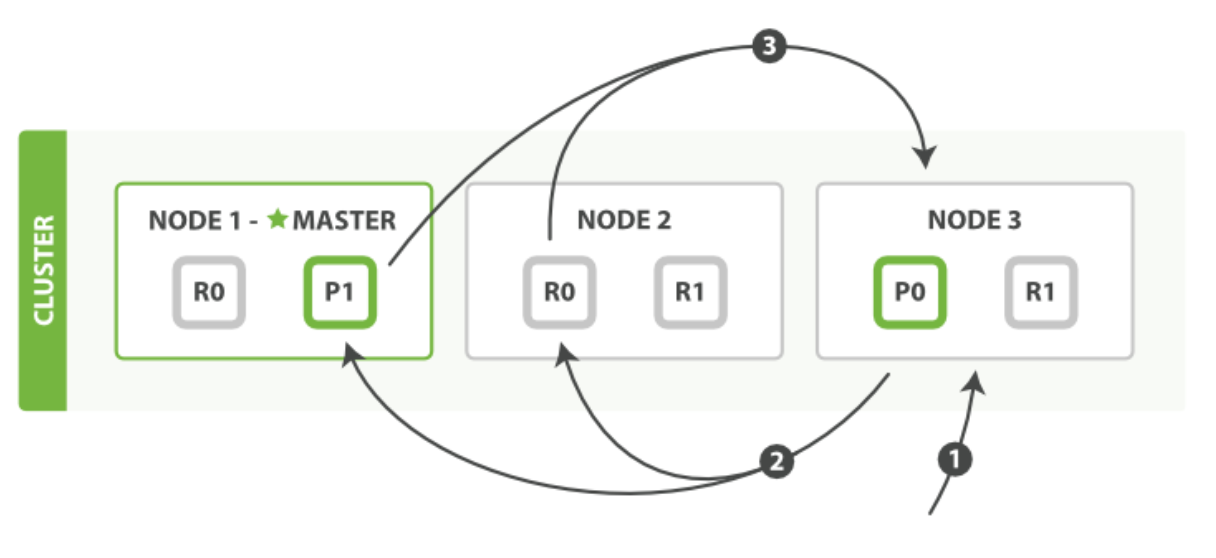
查詢階段包含以下三個步驟
- 客戶端發送一個
search請求到Node 3,此時Node 3成為協調節點,由它來負責本次的查詢, Node 3將查詢請求廣播到索引的每個主分片或副本分片中,每個分片在本地執行查詢并添加結果到大小為from + size的本地有序優先佇列中,- 每個分片回傳各自優先佇列中所有檔案的ID和排序值給協調節點,也就是
Node 3,它合并這些值到自己的優先佇列中來產生一個全域排序后的結果串列,至此查詢程序結束,
一個索引可以由一個或幾個主分片組成, 所以一個針對單個索引的搜索請求需要能夠把來自多個分片的結果組合起來, 針對 multiple 或者 all 索引的搜索作業方式也是完全一致的——僅僅是包含了更多的分片而已,
取回階段
在查詢階段中,我們標識了哪些檔案滿足搜索請求,而接下來我們就需要取回這些檔案,
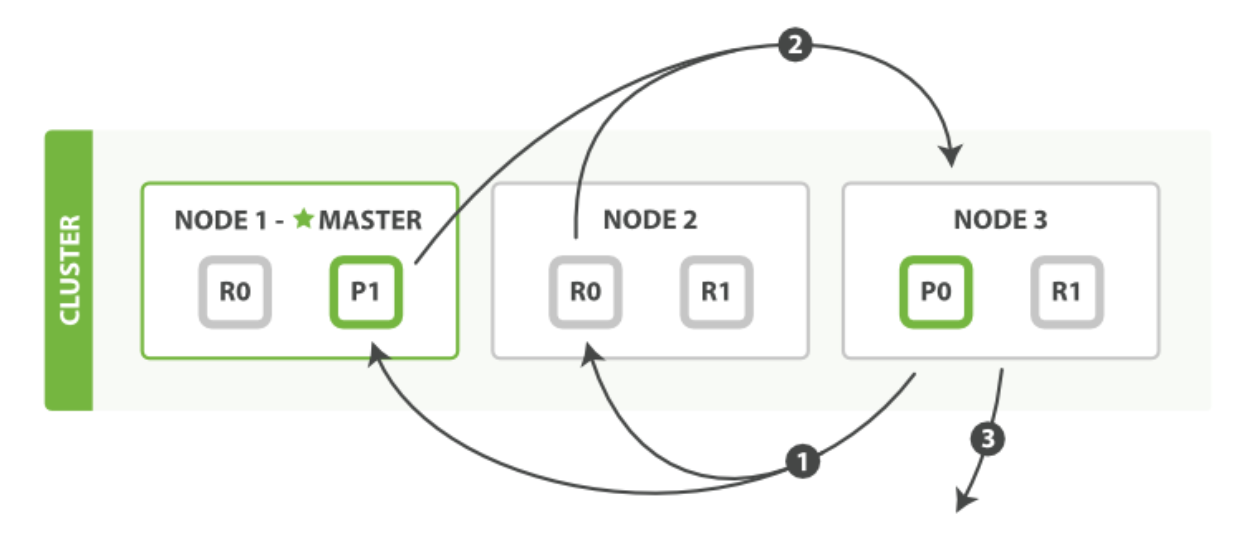
取回階段由以下步驟構成
- 協調節點辨別出哪些檔案需要被取回并向相關的分片提交多個
GET請求,例如,如果我們的查詢指定了{ "from": 90, "size": 10 },最初的90個結果會被丟棄,只有從第91個開始的10個結果需要被取回, - 每個分片加載并豐富檔案(如_source欄位和高亮引數),接著回傳檔案給協調節點,
- 協調節點等待所有檔案被取回,將結果回傳給客戶端,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293316.html
標籤:其他