文章目錄
- 1、語音編/解碼簡述
- 2、聲音可以進行編碼的原理
- 3、語音編碼的程序
- 4、LPC編碼
- 5、SILK編解碼
- 6、Opus編解碼
1、語音編/解碼簡述
?編碼的程序就是對語音進行壓縮,壓縮應該能夠保留語音的主要資訊甚至是全部資訊,解碼就是對語音進行解壓縮,恢復原始語音信號,編解碼可分為有損和無損兩類,有損情況下,取語音中少量冗余資訊,丟掉其他不重要的資訊,
?語音編碼分為波形編碼、引數編碼和混合編碼三種,基于波形的編碼分為時域編碼和頻域編碼兩種,如PCM編碼,引數編碼用若干引數對發生程序建模,接收端根據這些引數將接收到的信號恢復為原始語音信號,如LPC、MELP編碼,在低位元率下引數編碼的效果比波形編碼好,不同的語音編碼器在位元率、復雜度、延遲和解碼后的語音感知質量等方面有差異,根據編碼語音的帶寬,可以分為窄帶、寬帶、超寬帶和全通帶四種帶寬編碼,
| 帶寬 | 窄帶 | 寬帶 | 超寬帶 | 全通帶 |
|---|---|---|---|---|
| 頻率 | 8kHz | 16kHz | 32kHz | 48kHz |
2、聲音可以進行編碼的原理
人類發聲時聲帶振動產生濁音,不振動產生清音,音調/音高反映了人耳對聲音調子高低的主觀感受,聲音的高低主要取決于聲波基頻 F 0 F_0 F0?的高低,音色/音品由聲音波形的諧波頻譜和包絡決定,音效中會用雙二階濾波器控制音色,聲碼器是對發聲源的建模,在傳輸程序中還受聲道、嘴唇的影響,這可以用線性預測濾波器來建模,濾波器的系數反映發聲時聲道等各器官的狀態,在10~30ms時間內器官移動的距離有限, 所以位置基本不變化,這就使得可以使用線性預測濾波器對語音編碼,而濾波器系數的個數可以做到遠小于時域對應幀的采樣點數,這就實作了壓縮的功能,
3、語音編碼的程序
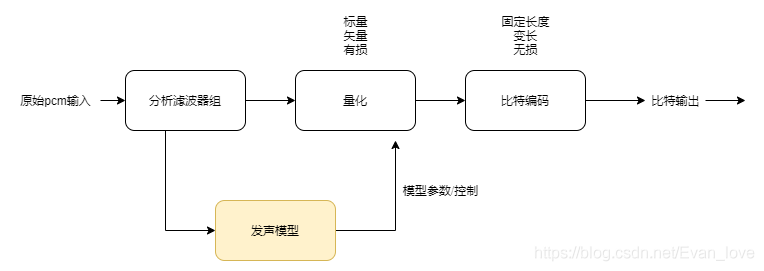
分析濾波器組包括分幀、加窗STFT變換以將時域信號變換到頻域,發聲模型模塊被稱為分析階段,通常包括LPC系數計算、基頻估計,將LPC系數轉換成LSF系數,量化模塊對LSF系數進行向量量化,位元編碼模塊可以是定長編碼或者基于碼本的定長編碼,在解碼端,LSF系數轉換成LPC系數,再用基頻、增益和量化的LPC系數合成語音,音頻編碼器常用幀間互相關資訊來減少位元率,然而這會導致誤差逐幀傳遞,在丟失一個資料包后,需要多個連續的資料包,以便解碼器能夠精確重構源信號,位元率和誤差傳播影響幀間依賴性的強弱,
4、LPC編碼
線性預測系數(LPC)基于發聲源和濾波發聲模型,非常適合元音的建模,式(10-1)的線性預測方程使用了若干先前值預測n時刻的值:
y
(
n
)
=
a
1
y
(
n
?
1
)
+
a
2
y
(
n
?
2
)
+
a
3
y
(
n
?
3
)
+
?
+
e
(
n
)
y(n)=a_1y(n-1)+a_2 y(n-2)+a_3y(n-3)+\cdots +e(n)
y(n)=a1?y(n?1)+a2?y(n?2)+a3?y(n?3)+?+e(n)
如果根據系數
a
0
,
a
1
,
.
.
.
,
a
n
?
1
a_0, a_1,...,a_{n-1}
a0?,a1?,...,an?1?能夠預測出n時刻的值
y
(
n
)
y(n)
y(n),則可以傳輸這個觀測視窗(10~25ms)內的線性預測系數,而不需要傳輸觀測視窗內的資料到遠端,在下一個觀測窗內做類似的處理,重寫為
y
(
n
)
=
?
a
1
y
(
n
?
1
)
?
a
2
y
(
n
?
2
)
?
a
3
y
(
n
?
3
)
+
.
.
.
+
x
(
n
)
y(n)=-a_1y(n-1)-a_2y(n-2)-a_3y(n-3)+...+x(n)
y(n)=?a1?y(n?1)?a2?y(n?2)?a3?y(n?3)+...+x(n)
上述變成了遞回濾波器的形式,LPC系數對應遞回濾波器系數,誤差信號變成了原始信號
x
(
n
)
x(n)
x(n),能用最小化誤差信號LPC系數求法的前提是誤差信號頻譜是平坦的,脈沖串和白噪聲具有頻譜平坦這一特性,人類發音最開始的源看起來就像脈沖串和白噪聲,該源通過聲道激勵濾波后最終輸出,編碼時常通過預加重LPC濾波器彌補LPC不包含聲門、脣輻射建模濾波器的影響,
和倒譜方法相比,LPC方法可以獲得更清晰的共振峰,通過計算LPC系數可以實時跟蹤共振峰情況,由于LPC建模模型是無損耗的全零點濾波,而聲道中聲音是有損耗的,也非全極點濾波,這會產生假共振峰,
?LPC系數和采樣率的關系如下:
- 10kHz采樣率,男性LPC系數選12-14階,女性選8-10階,
- 20kHz采樣率,男性LPC系數為24-26階,女性為22-24階,
5、SILK編解碼
(1)SILK編碼
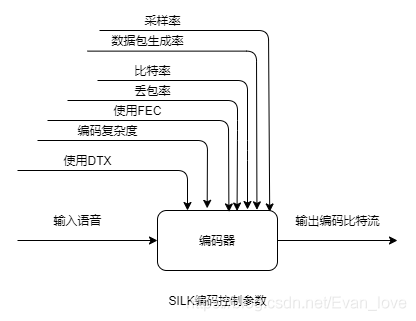
①采樣率
- 窄帶(NB):8kHz采樣率
- 中頻頻帶(MB):8kHz或者12kHz采樣率
- 寬帶(WB):8kHz、12kHz或者16kHz采樣率
- 超寬帶(SWB):8kHz/12kHz/16kHz/24kHz
②資料包生成率
以20ms為一幀進行編碼,以1、2、3、4、或者5幀作為網路傳輸的一次有效載荷,一次有效載荷的選擇是一個權衡,將5幀作為一次有效載荷,則只有一次傳輸IP/UDP和RIP頭的開銷,相對于5幀作為5次有效載荷的情況,前者節省了4次傳輸頭的開銷,這減少了傳輸網路貸款需求,但延遲和丟包影響均會變大,
③位元率
位元率越高,量化噪聲的影響越小,
④丟包率
使用幀間互相關技術抗網路丟包
⑤使用FEC
FEC(in-band Forward Error Correction)主要是為了對抗丟包,
⑥編碼復雜度
分為高、中、低三種,復雜度引數越高,編碼的語音質量越高,
⑦DTX
非連續傳輸(DTX)可以在安靜和只有背景噪聲語音段減少位元率,當DTX使能時,對噪聲段每400ms只編碼一幀發送到對端,
(2)編碼器
SILK編碼器處理流程為:
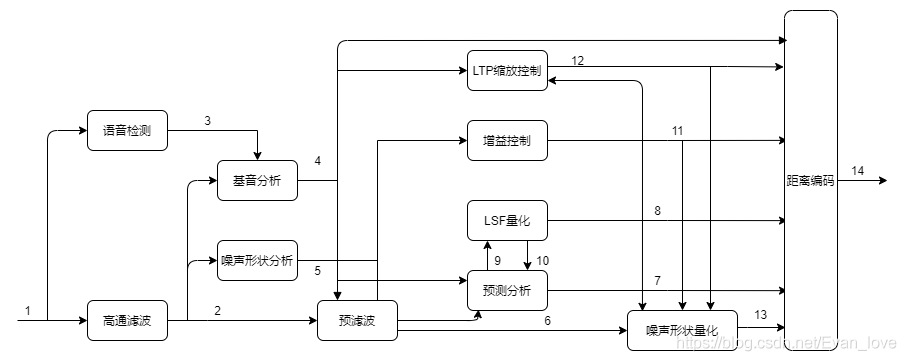
其中:
- 1是輸入信號
- 2是高通濾波后的信號
- 3是語音檢測的結果
- 4是基音和語音檢測資訊
- 5是噪聲包絡估計系數
- 6是經過分析噪聲包絡濾波器濾波后的輸入語音信號
- 7是LPC的短時(5ms)和長時(20ms)估計
- 8是LSF量化指數
- 9是LSF系數
- 10是LSF系數量化
- 11是處理后增益值,綜合噪聲包絡系數
- 12是LTTP狀態縮放系數,是控制誤差傳播和預測增益這兩者的權衡
- 13是量化后信號
- 14是距離編碼位元流
(1)語音檢測
該模塊計算每幀(20ms)語音的存在概率、權重信噪比(tilt)和SNR,計算程序將輸入語音分成4個子帶,分別是
0
?
1
k
H
z
、
1
?
2
k
H
z
、
2
?
4
k
H
z
、
4
?
8
k
H
z
0-1kHz 、1-2kHz、2-4kHz、4-8kHz
0?1kHz、1?2kHz、2?4kHz、4?8kHz,采用了半帶寬濾波器和正交鏡像濾波器作為原型濾波器對每個子帶進行背景噪聲估計跟蹤,計算每個子帶的平滑SNR、子帶間的平均信噪比和語音概率,
(2)高通濾波
因為絕大多數語音信號的有效資訊都在60Hz以上,故為了減少干擾,使用了截止頻率約在70Hz的高通濾波器先對信號進行處理,對于音樂信號,70Hz以下是存在有用信號的,使用了二階自回歸平滑(ARMA)處理,
(3)基音分析
基音(pitch)是人耳感知到的發音基頻
F
0
F_0
F0?,即聲帶振動的頻率,是人耳聽到的音調高低,其在SILK編碼器中的計算方法為:
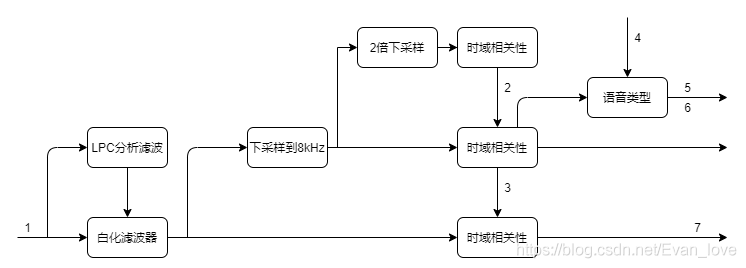
基音估計首先區分是語音還是非語音,對于語音段,每幀計算4個基音周期(每5ms為一個),基音的相關性體現了信號的周期性,輸入信號首先經過線性預測(LP)白化濾波器處理,濾波器的系數由LPC分析獲得,低、中、高三種復雜度的LPC系數分別是8、12、16,復雜度越高,白化效果越好,白化后的信號用于尋找基音周期(也就是時域相關極大值的位置),
(4)噪聲形狀分析
首先計算預濾波、噪聲譜包絡增益和濾波器量化系數,
(5)預濾波
使用前一節估計到的系數對信號進行去加重,
(6)預測分析
根據基音分析待編碼音頻是否是語音并做相應的處理,輸入信號是基音分析白化處理之后的信號,對于語音段,白化處理后的信號基音仍然占主要部分,
對于非語音段,由于沒有基音,分段內不存在基音周期,不需要進行LTP濾波,所以不使用白化后的信號,而是直接用Burgs方法計算高通濾波信號的LPC系數,將LPC系數轉化成LSF向量,對LSF向量進行量化,然后將量化后的LSF向量轉換成量化版的LPC系數,使用量化后的LPC系數對高通濾波后信號進行濾波,并計算4個子幀殘差信號的能量,
(7)LSF量化
主要目的是減少位元率,代價是引起失真,位元率越高,失真越小,常用的方法是使用定位元率的量化方法,即在位元率一定的時候使量化誤差最小,
(8)LTP縮放控制
給定權重矩陣
W
l
t
p
W_{ltp}
Wltp?和LTP向量b,對于給定的碼表
c
b
i
cb_i
cbi?和位元率
r
i
r_i
ri?,其加權位元率-失真率是:
R
D
=
u
×
(
b
?
c
b
l
)
′
×
W
l
t
p
×
(
b
?
c
b
i
)
+
r
i
RD=u\times (b-cb_l)' \times W_{ltp} \times (b-cb_i)+r_i
RD=u×(b?cbl?)′×Wltp?×(b?cbi?)+ri?
其中,
u
u
u是位元率-失真率之間平衡的固定引數,
(9)噪聲形狀量比
預濾波輸出的信號在噪聲包絡分析中先乘以補償增益G,然后用綜合包絡濾波器和預測濾波器的差值獲得殘差信號,
(10)距離編碼
SILK將語音、非語音、LTP+LPC量化、殘差信號和一些瞬時增益編碼進行距離編碼后傳輸,
(11)LPC合成
由于短時互相關在LPC分析濾波器中被去掉了,這里通過下式所示的綜合濾波器進行恢復,
y
(
n
)
=
e
L
P
C
(
n
)
+
∑
i
=
1
d
L
P
C
(
n
?
i
)
×
a
i
y(n)=e_{LPC(n)+\sum_{i=1}^{d_{LPC}}(n-i)\times a_i}
y(n)=eLPC(n)+∑i=1dLPC??(n?i)×ai??
其中,y(n)是解碼輸出信號,
(3)解碼器
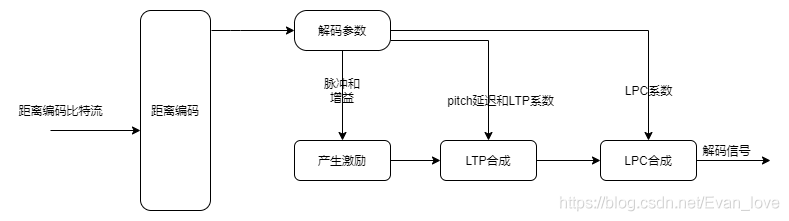
解碼器從接收到的距離編碼位元流中獲取解碼引數,根據脈沖、最低有效位和符號生成激勵信號,根據基音延遲、長時預測系數(LTPC)和LPC合成反饋做LTP合成,根據LPC系數和符號做LPC合成,LPC合成的信號要么是單聲道,要么是混合的立體聲,
6、Opus編解碼
opus是第一個從窄帶一直支持到全通帶的語音編/解碼器,其內部有一個音樂監測器判斷當前音頻是語音還是音樂,窄帶和寬帶部分用低位元率的SILK(LP層)編碼,超寬帶和全通帶用CELT(MDCT層)編碼,opus作業時可以只使用LP層或MDCT層編碼,或同時使用兩層編碼,同時編碼對音樂電臺這種人聲加音樂的場景較為適用,使用LP和MDCT兩種變換的原因是,低頻率的語音LP方法比CELP變換域方法更高效,但是對于語音或者音樂的高頻部分變換域方法更有效,
(1) Opus解碼
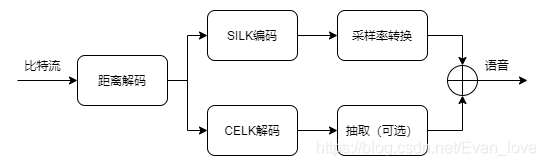
其中,CELT解碼是編碼的逆程序,解碼程序為:
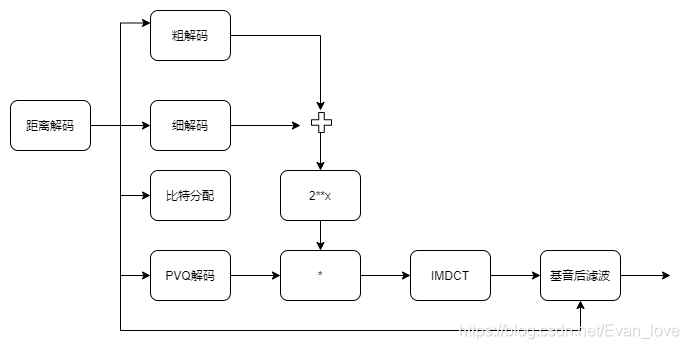
CELT增加了前置濾波和后置濾波以提高周期性信號的質量,前置濾波在編碼側減少諧波分量,后置濾波在解碼側用于恢復諧波分量的初始增益且讓噪聲和諧波分量差不多,以使人耳感受不到,粗/細解碼器用于解碼頻帶內信號的能量,IMDCT變換后濾波解碼的信號經過去加重、丟包隱藏和時鐘偏移補償后輸出,
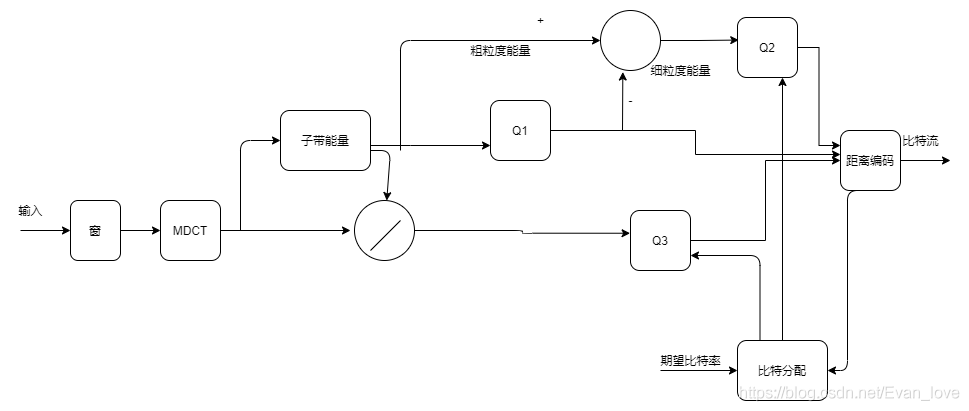
(2)Opus編碼
opus由SILK編碼器和CELT解碼組成,當對超帶寬和全通帶信號編碼時,SILK和CELT同時作業,編/解碼流程如下:
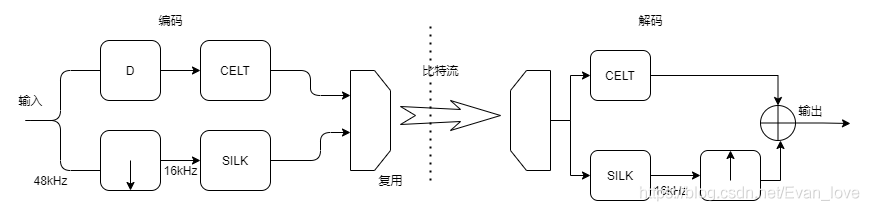
CELT編碼流程
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293448.html
標籤:其他