文章目錄
- 1.創建檔案+組態檔
- 2. 模型+演算法
- 3.結果展示
資料獲取和處理詳見上一篇文章: https://blog.csdn.net/qq_42754919/article/details/119545130
這一節主要介紹實時推薦系統服務,根據當前用戶最新的商品評價,推薦出相似度接近的商品,并根據當前用戶之前評價的商品,計算每個推薦商品和之前評價商品之間的相似度,從高到低將備選商品推薦給當前用戶,
1.創建檔案+組態檔
pom.xml檔案
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>recommender</artifactId>
<groupId>com.root</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>StreamingRecommender</artifactId>
<groupId>com.root.recommender</groupId>
<dependencies>
<!-- Spark的依賴引入 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
</dependency>
<!-- 引入Scala -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
</dependency>
<!-- 加入MongoDB的驅動 -->
<!-- 用于代碼方式連接MongoDB -->
<dependency>
<groupId>org.mongodb</groupId>
<artifactId>casbah-core_2.11</artifactId>
<version>${casbah.version}</version>
</dependency>
<!-- 用于Spark和MongoDB的對接 -->
<dependency>
<groupId>org.mongodb.spark</groupId>
<artifactId>mongo-spark-connector_2.11</artifactId>
<version>${mongodb-spark.version}</version>
</dependency>
<!-- redis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
<!-- kafka -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.10.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
</project>
2. 模型+演算法
主要演算法思想:
- 首先通過離線獲取商品相似度資料并廣播出去(參見之前的博客)
- 建立kafka輸入資料流,將實時最新商品評價資料傳入演算法中
- 遍歷實時傳入資料,對每一個傳入資料進行處理,計算實時商品推薦
- 從redis中獲取當前用戶之前的所有商品評價資訊
- 從商品相似串列資料中獲取當前商品的相似的商品,作為備選推薦商品,
- 計算備選商品和之前評價商品的相似度,
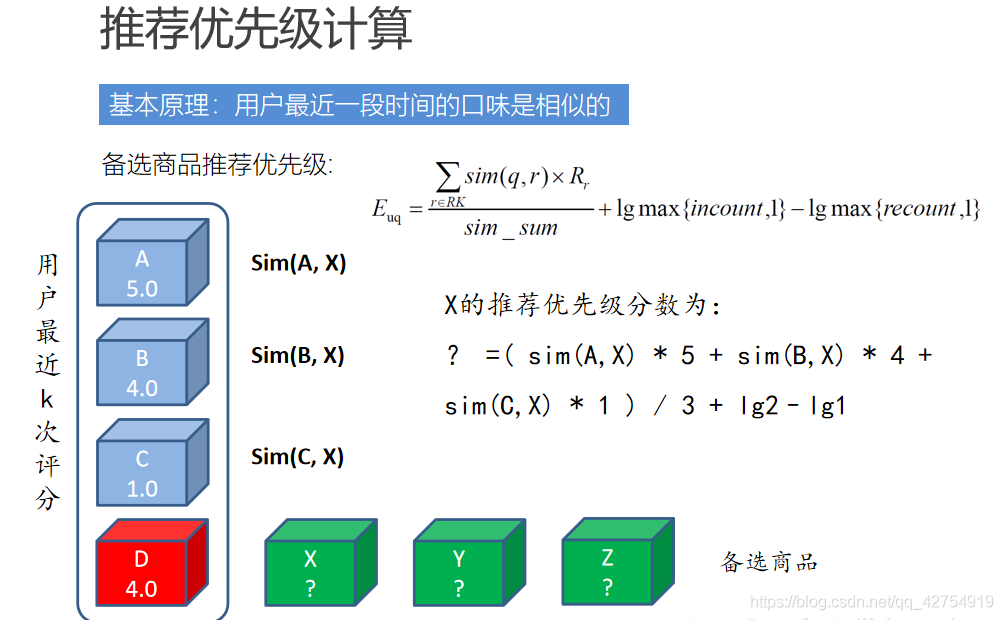 D為用戶最新的商品評價,X,Y,Z為最新商品的相似度最高的相似商品作為備選商品,A,B,C為用戶之前已經評價過的商品資訊,計算每個備選商品與A,B,C之間的相似度,為了展示好評或者差評給出的較大的評分差距,將相似度乘以A,B,C評分的數值,最后再加上一個增強因子(表示最近評分商品A,B,C中大于某個因子的個數)和一個因子,(表示最近評分商品A,B,C中小于某個因子的個數)
D為用戶最新的商品評價,X,Y,Z為最新商品的相似度最高的相似商品作為備選商品,A,B,C為用戶之前已經評價過的商品資訊,計算每個備選商品與A,B,C之間的相似度,為了展示好評或者差評給出的較大的評分差距,將相似度乘以A,B,C評分的數值,最后再加上一個增強因子(表示最近評分商品A,B,C中大于某個因子的個數)和一個因子,(表示最近評分商品A,B,C中小于某個因子的個數)
package com.root.Online
import com.mongodb.casbah.Imports.{MongoClient, MongoClientURI}
import com.mongodb.casbah.commons.MongoDBObject
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import redis.clients.jedis.Jedis
//定義連接助手物件,建立redis和MongoDB的連接
object ConnHelper extends Serializable{
//加載懶變數,使用的時候才初始化
lazy val jedis = new Jedis("localhost")//改成自己redis安裝地址
lazy val mongoClient = MongoClient(MongoClientURI("mongodb://localhost:27017/recommender"))//改成自己mongodb安裝地址
}
//MongoDB的連接配置
case class MongoConfig(uri:String, db:String)
//定義推薦標準物件
case class Recommenderdation(productId:Int, score:Double)
//定義用戶推薦串列
case class UserRecs(userId:Int, recs:Seq[Recommenderdation])
//定義商品相似度串列
case class ProductRecs(productId:Int,recs:Seq[Recommenderdation])
object OnlineRecommender {
val MAX_USER_RATINGS_NUM = 20
val MAX_SIM_PRODUCTS_NUM = 20
val STREAM_RECS = "StreamRecs"
val PRODUCT_RECS = "ProductRecs"
val MongoDB_Rating = "Rating"
def main(args: Array[String]): Unit = {
val config = Map(
"spark.cores" -> "local[*]",
"mongo.uri" -> "mongodb://localhost:27017/recommender",
"mongo.db" -> "recommender",
"kafka.topic" -> "recommender"
)
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("OnlineRecommender")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
val sc = spark.sparkContext
val ssc = new StreamingContext(sc, Seconds(2))
import spark.implicits._
implicit val mongoConfig = MongoConfig(config("mongo.uri"), config("mongo.db"))
//加載資料,相似度矩陣,廣播出去.獲取商品相似度串列
val simProductsMatrix = spark.read
.option("uri", mongoConfig.uri)
.option("collection", PRODUCT_RECS)
.format("com.mongodb.spark.sql")
.load()
.as[ProductRecs]
.rdd
//為了后續查詢相似度方便,將資料轉化為map形式<k,v>,map<productID,map<productID,score>>
.map { item => (item.productId, item.recs.map(x => (x.productId, x.score)).toMap) }
//將元組型別轉換為Map型別:RDD[(Int,Map[Int,Double]]->Map[Int,Map[Int,Double]]
.collectAsMap()
//定義廣播變數,減少變數的發送防止資料重復
val simProductsMatrixBC = sc.broadcast(simProductsMatrix)
//創建kafka連接配置
val kafkaParam = Map(
"bootstrap.servers" -> "hadoop100:9092",//改成自己kafka安裝地址
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "recommender",
"auto.offset.reset" -> "latest"
)
//創建DStream,獲取kafka內部傳輸資料
val kafkaStream = KafkaUtils.createDirectStream[String, String](ssc, LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](Array(config("kafka.topic")), kafkaParam))
//對kafkastream進行處理,產生評分流,userId|productId|score|time,獲取當前用戶最新的商品評價用于推薦相似的商品資訊
val ratingStream = kafkaStream.map { msg =>
val attr = msg.value().split("\\|")
(attr(0).toInt, attr(1).toInt, attr(2).toDouble, attr(3).toInt)
}
//核心演算法部分,定義評分流的處理流程
ratingStream.foreachRDD {
rdds =>
rdds.foreach {
case (userId, productId, score, time) =>
println("rating data coming!>>>>>>>>>>>>>>>>")
//TODO:核心演算法流程
//1.從Redis里取出當前用戶的最近評分,保存成一個陣列Array[(productId,score)]
val userRecentlyRatings = getUserRecentlyRatings(MAX_USER_RATINGS_NUM, userId, ConnHelper.jedis)
//2.從相似度矩陣中獲取當前商品最相似的商品串列,作為備選串列,保存成一個陣列Array[productId]
val candidateProducts = getTopSimProducts(MAX_SIM_PRODUCTS_NUM, productId, userId, simProductsMatrixBC.value)
//3.計算每個備選商品的推薦優先級,得到當前用戶的實時推薦串列,保存成Array[(productId,score)]
val streamRecs = computeProductScore(candidateProducts, userRecentlyRatings, simProductsMatrixBC.value)
//4.把推薦串列保存到MongoDB中
saveDataToMongoDB(userId, streamRecs)
}
}
//啟動streaming
ssc.start()
println("streaming started!")
ssc.awaitTermination()
import scala.collection.JavaConversions._
//從Redis中獲取最近num次評分
def getUserRecentlyRatings(num: Int, userId: Int, jedis: Jedis): Array[(Int, Double)] = {
//從redis中用戶的評分佇列里獲取評分資料,list鍵名為uid:USERID,值格式為 productID:SCORE
jedis.lrange("userId:" + userId.toString, 0, num).map {
item =>
val attr = item.split("\\:")
println("*************")
(attr(0).trim.toInt, attr(1).trim.toDouble)
}.toArray
}
//獲取當前商品的相似串列,并過濾掉用戶已經評分過的,作為備用串列
def getTopSimProducts(num: Int, productId: Int, userId: Int,
simProducts: scala.collection.Map[Int, scala.collection.immutable.Map[Int, Double]])
(implicit mongoConfig: MongoConfig): Array[Int] = {
//從廣播變數相似度矩陣中拿到當前商品的相似度串列
val allSimProducts = simProducts(productId).toArray
//獲得用戶已經評分過的商品,過濾掉并排序輸出
val ratingCollection = ConnHelper.mongoClient(mongoConfig.db)(MongoDB_Rating)
//find(MongoDBObject())將需要查找collection中物件名為userId傳入.然后只獲取productId
val ratingExist = ratingCollection.find(MongoDBObject("userId" -> userId))
.toArray
.map { item => item.get("productId").toString.toInt }
//從所有商品中過濾已經評分的productId,allSimProducts(productId,score)[Int,Double]
allSimProducts.filter(x => !ratingExist.contains(x._1)).sortWith(_._2 > _._2).take(num).map(x => x._1)
}
//計算每個備選商品的推薦得分
def computeProductScore(candidateProducts: Array[Int], userRecentlyRatings: Array[(Int, Double)],
simProducts: scala.collection.Map[Int, scala.collection.immutable.Map[Int, Double]]):
Array[(Int, Double)] = {
//定義一個長度可變陣列ArrayBuffer,用于保存每一個備選商品的基礎得分,(productId,score)
val scores = scala.collection.mutable.ArrayBuffer[(Int, Double)]()
//定義兩個map,用于保存每個商品的高分和低分的計數器,productId->count
val increMap = scala.collection.mutable.HashMap[Int, Int]()
val decreMap = scala.collection.mutable.HashMap[Int, Int]()
//遍歷每個備選商品,計算和已評分商品的相似度
for (candidateProduct <- candidateProducts; userRecentlyRating <- userRecentlyRatings) {
//從相似度矩陣中獲取當前備選商品和當前已評分商品間的相似度
val simScore = getProductsScore(candidateProduct, userRecentlyRating._1, simProducts)
if (simScore > 0.4) {
//按照公式進行加權計算,得到基礎評分
scores += ((candidateProduct, simScore * userRecentlyRating._2))
if (userRecentlyRating._2 > 3) {
increMap(candidateProduct) = increMap.getOrDefault(candidateProduct, 0) + 1
} else {
decreMap(candidateProduct) = decreMap.getOrDefault(candidateProduct, 0) + 1
}
}
}
scores.groupBy(_._1).map {
case (productId, scoreList) => {
(productId, scoreList.map(_._2).sum / scoreList.length + log(increMap.getOrDefault(productId, 1)) - log(decreMap.getOrDefault(productId, 1)))
}
}.toArray.sortWith(_._2 > _._2)
}
//根據公式計算所有的推薦優先級,首先以productId做groupby
def getProductsScore(product1: Int, product2: Int,
simProducts: scala.collection.Map[Int, scala.collection.immutable.Map[Int, Double]]): Double = {
simProducts.get(product1) match {
case Some(sims) => sims.get(product2) match {
case Some(score) => score
case None => 0.0
}
case None => 0.0
}
}
//自定義log函式,以N為底
def log(m: Int): Double = {
val N = 10
math.log(m) / math.log(N)
}
def saveDataToMongoDB(userId: Int, streamRecs: Array[(Int, Double)])(implicit mongoConfig: MongoConfig): Unit = {
//到StreamRecs的連接
val streamRecsCollection = ConnHelper.mongoClient(mongoConfig.db)(STREAM_RECS)
//按照userId查詢并更新
streamRecsCollection.findAndRemove(MongoDBObject("userId" -> userId))
streamRecsCollection.insert(MongoDBObject("userId" -> userId, "recs" ->
streamRecs.map(x => MongoDBObject("productId" -> x._1, "score" -> x._2))))
}
}
}
3.結果展示
- 首先啟動zookeeper和kafka集群
- 啟動redis并輸入下列資料
創建userId:4867
輸入資料:425715:5.0 457976:5.0 294209:1.0 250451:3.0 231449:3.0
- 啟動主程式
- 啟動kafka
bin/kafka-console-producer.sh --broker-list hadoop100:9092 --topic recommmender
>4867|8195|4.0|1556433066
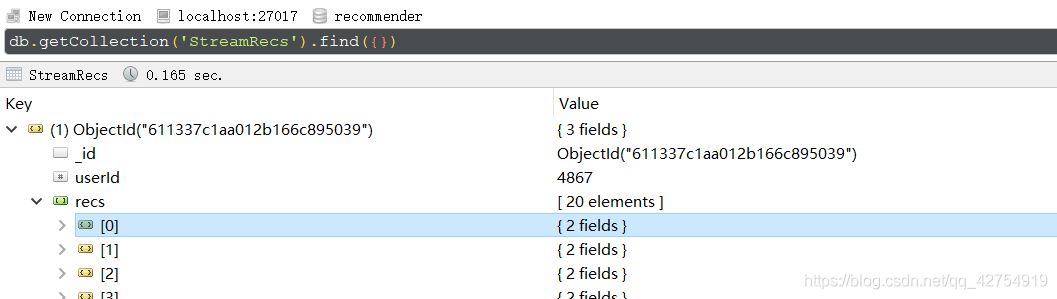
最終輸出:
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293539.html
標籤:其他
上一篇:3年時光,從工廠到自動化測驗工程師,改變人生的都是堅持到底的毅力···
下一篇:互聯網黑話匯總大合集