1、執行流程
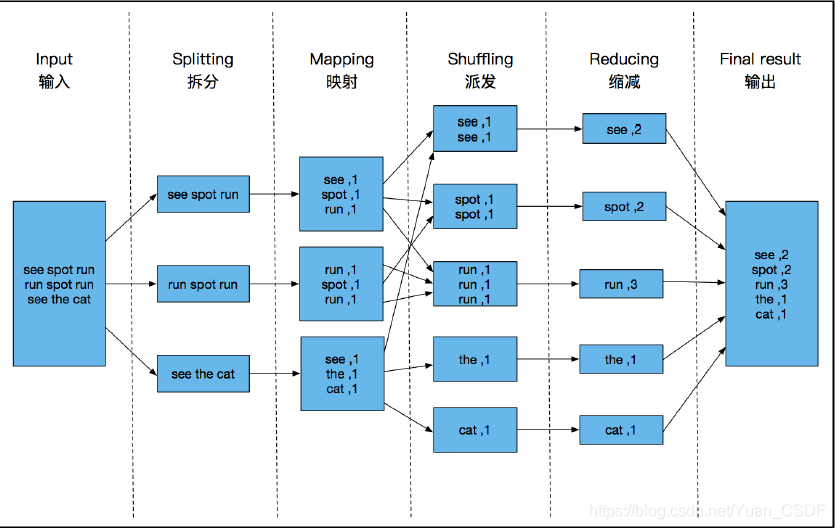
1.1、MapReduce執行流程
核心思想:大問題拆分成多個小問題,然后分布式的并行執行
兩個階段:
1、mapper階段: 提取資料,賦予特征 映射 value ====> key, value
mapreducce框架是怎么把相同特征的資料組合到一起來,然后交給reduceTask執行一次聚合操作的呢
2、reducer階段: 把相同特征的資料進行聚合操作 key, (value, value, ...)
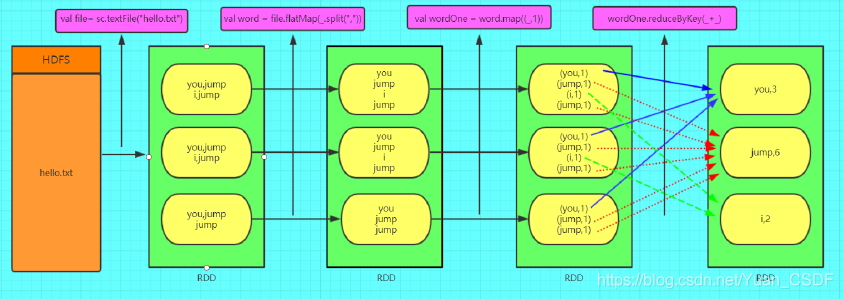
1.2、Spark應用程式執行流程
sparkContext.rextFile().flatMap().map().reduceByKey()
首先讓你確認,導致分布式計算應用改程式出現資料傾斜的原因就是 Shuffle 資料傾斜的調優,都是圍繞著:
- 要么就不要使用shuffle
- 要么就讓shuffle在執行程序中均勻分發資料
最終的目的:Spark 中的同一個 stage 中的多個 Task 處理的資料量大小幾乎是一致的,
2、資料傾斜解決方案
2.1、使用Hive ETL預處理資料
- 優點:實作起來簡單便捷,效果還非常好,完全規避掉了資料傾斜,Spark作業的性能會大幅度提升,
- 缺點:治標不治本,Hive ETL中還是會發生資料傾斜,
2.2、調整shuffle操作的并行度
- 實用場景:大量不同的Key被分配到了相同的Task造成該Task資料量過大,
- 實作思路:在對RDD執行Shuffle算子時,給Shuffle算子傳入一個引數,比如reduceByKey(1000),該引數就設定了這個shuffle算子執行時shuffle read task的數量,對于Spark SQL中的Shuffle類陳述句,比如group by、join等,需要設定一個引數,即spark.sql.shuffle.partitions,該引數代表了shufflereadTask的并行度,該值默認是200,對于很多場景來說都有點過小,
- 優點:實作起來比較簡單,可以有效緩解和減輕資料傾斜的影響,實作簡單,可在需要Shuffle的操作算子上直接設定并行度或者使用spark.default.parallelism設定,如果是Spark SQL,還可通過SET spark.sql.shuffle.partitions=[num_tasks]設定并行度,可用最小的代價解決問題,一般如果出現資料傾斜,都可以通過這種方法先試驗幾次,如果問題未解決,再嘗試其它方法,
- 缺點:只是緩解了資料傾斜而已,沒有徹底根除問題,根據實踐經驗來看,其效果有限,適用場景少,只能將分配到同一Task的不同Key分散開,但對于同一Key傾斜嚴重的情況該方法并不適用,并且該方法一般只能緩解資料傾斜,沒有徹底消除問題,從實踐經驗來看,其效果一般,
2.3、過濾少數導致傾斜的key
- 優點:實作簡單,而且效果也很好,可以完全規避掉資料傾斜,
- 缺點:適用場景不多,大多數情況下,導致傾斜的key還是很多的,并不是只有少數幾個,
2.4、將reduce join轉為map join
普通的join是會走shuffle程序的,而一旦shuffle,就相當于會將相同key的資料拉取到一個shuffle read task中再進行join,此時就是reduce join,但是如果一個RDD是比較小的,則可以采用廣播小RDD全量資料+map算子來實作與join同樣的效果,也就是map join,此時就不會發生shuffle操作,也就不會發生資料傾斜,
- 優點:對join操作導致的資料傾斜,效果非常好,因為根本就不會發生shuffle,也就根本不會發生資料傾斜,
- 缺點:適用場景較少,因為這個方案只適用于一個大表和一個小表的情況,畢竟我們需要將小表進行廣播,此時會比較消耗記憶體資源,driver和每個Executor記憶體中都會駐留一份小RDD的全量資料,如果我們廣播出去的RDD資料比較大,比如10G以上,那么就可能發生記憶體溢位了,因此并不適合兩個都是大表的情況,
2.5、采樣傾斜key并分拆join操作
- 優點:對于join導致的資料傾斜,如果只是某幾個key導致了傾斜,采用該方式可以用最有效的方式打散key進行join,而且只需要針對少數傾斜key對應的資料進行擴容n倍,不需要對全量資料進行擴容,避免了占用過多記憶體,
- 缺點:如果導致傾斜的key特別多的話,比如成千上萬個key都導致資料傾斜,那么這種方式也不適合,
2.6、兩階段聚合(區域聚合+全域聚合)
- 適用場景: 對RDD執行reduceByKey等聚合類shuffle算子或者在Spark SQL中使用group by陳述句進行分組聚合時,比較適用這種方案,
- 實作原理:將原本相同的key通過附加隨機前綴的方式,變成多個不同的key,就可以讓原本被一個task處理的資料分散到多個task上去做區域聚合,進而解決單個task處理資料量過多的問題,接著去除掉隨機前綴,再次進行全域聚合,就可以得到最終的結果,
- 優點:對于聚合類的shuffle操作導致的資料傾斜,效果是非常不錯的,通常都可以解決掉資料傾斜,或者至少是大幅度緩解資料傾斜,將Spark作業的性能提升數倍以上,
- 缺點:僅僅適用于聚合類的shuffle操作,適用范圍相對較窄,如果是join類的shuffle操作,還得用其他的解決方案,
2.7、使用隨機前綴和擴容RDD進行join
- 適用場景:如果在進行 join 操作時,RDD 中有大量的 key 導致資料傾斜,那么進行分拆 key 也沒什么意義,
- 實作原理:將原先一樣的 key 通過附加隨機前綴變成不一樣的key,然后就可以將這些處理后的“不同key”分散到多個task中去處理,而不是讓一個task處理大量的相同key,該方案與“解決方案六”的不同之處就在于,上一種方案是盡量只對少數傾斜key對應的資料進行特殊處理,由于處理程序需要擴容RDD,因此上一種方案擴容RDD后對記憶體的占用并不大;而這一種方案是針對有大量傾斜key的情況,沒法將部分key拆分出來進行單獨處理,因此只能對整個RDD進行資料擴容,對記憶體資源要求很高,
- 優點:對join型別的資料傾斜基本都可以處理,而且效果也相對比較顯著,性能提升效果非常不錯,
- 缺點:該方案更多的是緩解資料傾斜,而不是徹底避免資料傾斜,而且需要對整個RDD進行擴容,對記憶體資源要求很高,
2.8、任務橫切,一分為二,單獨處理
- 適用場景:導致資料傾斜的因素比較多,比較復雜的場景中,
- 實作思路:在了解清楚資料的分布規律,以及確定了資料傾斜是由何種原因導致的,那么按照這些原因,進行資料的拆分,然后單獨處理每個部分的資料,最后把結果合起來,
- 優點:將多種簡單的方案綜合起來,解決一個復雜的問題,可以算上一種萬能的方案,
- 缺點:確定資料傾斜的因素比較復雜,導致解決該資料傾斜的方案比較難實作落地,代碼復雜度也較高,
2.9、多種方案組合使用
即使用上述方案的組合,
2.10、自定義Partitioner
使用自定義的 Partitioner 實作類代替默認的 HashPartitioner,盡量將所有不同的 Key 均勻分配到不同的 Task中,
- 適用場景:大量不同的Key被分配到了相同的Task造成該Task資料量過大,
- 實作思路:先通過抽樣,了解資料的key的分布規律,然后根據規律,去定制自己的資料磁區規則,盡量保證所有的Task的資料量相差無幾,
- 實作原理:使用自定義的Partitioner(默認為HashPartitioner),將原本被分配到同一個Task的不同Key分配到不同Task,
- 實作方案選擇:
- 隨機磁區
- 優點:資料分布均勻
- 缺點:具有相同特點的資料不會保證被分配到相同的磁區
- 輪詢磁區
- 優點:確保一定不會出現資料傾斜
- 缺點:無法根據存盤/計算能力分配存盤/計算壓力
- Hash散列
- 優點:具有相同特點的資料保證被分配到相同的磁區
- 缺點:極容易產生資料傾斜
- 范圍磁區
- 優點:相鄰的資料都在相同的磁區
- 缺點:部分磁區的資料量會超出其他的磁區,需要進行裂變以保持所有磁區的資料量是均勻的,如果每個磁區不排序,那么裂變就會非常困難
- 隨機磁區
- 優點:靈活,通用,
- 缺點:必須根據對應的場景設計合理的磁區方案,沒有現成的方案可用,需臨時實作,
2.11、Spark整合BitMap求Join
- 優點:占用記憶體少,處理速度高,
- 缺點:維護BitMap要求高,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293543.html
標籤:其他
上一篇:MQ相關基礎知識