目錄
- 1.Hadoop MapReduce概述
- 2.MapReduce的思想核心
- 3.MapReduce的特點和局限性
- 4.MapReduce入門案例——WordCount
- 4.1.業務需求
- 4.2.編程思路
- 4.3.編程實作
- 4.3.1.創建Maven專案
- 4.3.2.配置pom.xml檔案
- 4.3.3.撰寫Mapper類和Reducer類
- 4.3.4.撰寫客戶端驅動類
- 4.4.運行MapReduce程式
- 4.4.1.YARN集群模式
- 4.4.2.Local本地模式
1.Hadoop MapReduce概述
(1)Hadoop MapReduce(以下簡稱MapReduce)是一個分布式計算框架,用于輕松撰寫分布式應用程式,這些應用程式以可靠,容錯的方式并行處理大型硬體集群(數千個節點)上的大量資料(多TB資料集),
(2)MapReduce是一種面向海量資料處理的一種指導思想,也是一種用于對大規模資料進行分布式計算的編程模型,
(3)它的出現解決了人們在最初面臨海量資料束手無策的問題,同時它還是易于使用和高度可擴展的,使得開發者無需關系分布式系統底層的復雜性即可很容易的撰寫分布式資料處理程式,并在成千上萬臺普通的商用服務器中運行,
2.MapReduce的思想核心
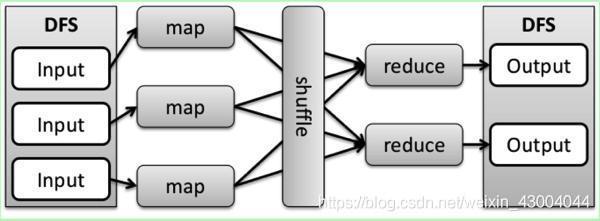
(1)MapReduce的思想核心是==“先分再合,分而治之”==,
(2)Map負責“拆分”:即把復雜的任務分解為若干個“簡單的子任務”來并行處理,可以進行拆分的前提是這些小任務可以并行計算,彼此間幾乎沒有依賴關系,
(3)Reduce負責“合并”:即對map階段的結果進行全域匯總,
3.MapReduce的特點和局限性
(1)特點
| 易于編程 | Mapreduce框架提供了用于二次開發的介面;簡單地實作一些介面,就可以完成一個分布式程式,任務計算交給計算框架去處理,將分布式程式部署到hadoop集群上運行,集群節點可以擴展到成百上千個等, |
|---|---|
| 良好的擴展性 | 當計算機資源不能得到滿足的時候,可以通過增加機器來擴展它的計算能力,基于MapReduce的分布式計算得特點可以隨節點數目增長保持近似于線性的增長,這個特點是MapReduce處理海量資料的關鍵,通過將計算節點增至幾百或者幾千可以很容易地處理數百TB甚至PB級別的離線資料, |
| 高容錯性 | Hadoop集群是分布式搭建和部署得,任何單一機器節點宕機了,它可以把上面的計算任務轉移到另一個節點上運行,不影響整個作業任務得完成,程序完全是由Hadoop內部完成的, |
| 適合海量資料的離線處理 | 可以處理GB、TB和PB級別的資料量 |
(2)局限性
| 實時計算性能差 | MapReduce主要應用于離線作業,無法作到秒級或者是亞秒級得資料回應, |
|---|---|
| 不能進行流式計算 | 流式計算特點是資料是源源不斷得計算,并且資料是動態的;而MapReduce作為一個離線計算框架,主要是針對靜態資料集得,資料是不能動態變化得, |
4.MapReduce入門案例——WordCount
4.1.業務需求
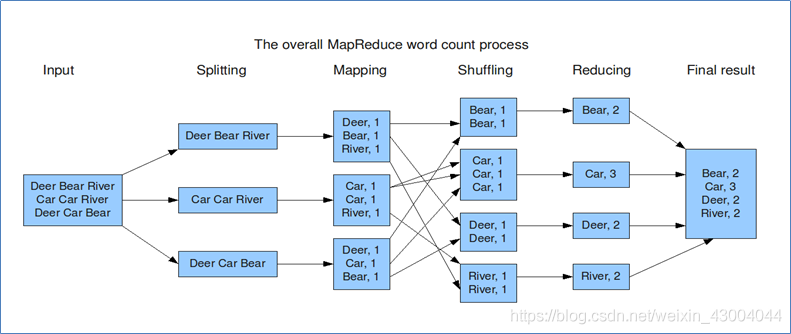
WordCount中文叫做單詞統計、詞頻統計,指的是統計指定檔案中,每個單詞出現的總次數(),這個是大資料計算領域經典的入門案例,相當于學習編程語言時的案例——輸出"Hello World",雖然WordCount業務十分簡單,但是通過案例感受背后MapReduce的執行流程和默認的行為機制才是關鍵所在,

4.2.編程思路
(1)map階段的:把輸入的資料經過切割,全部標記1,因此輸出就是<單詞,1>,
(2)shuffle階段:經過默認的排序磁區分組,key相同的單詞會作為一組資料構成新的kv對,
(3)reduce階段:處理shuffle完的一組資料,該組資料就是該單詞所有的鍵值對,對所有的1進行累加求和,得到單詞總次數,
4.3.編程實作
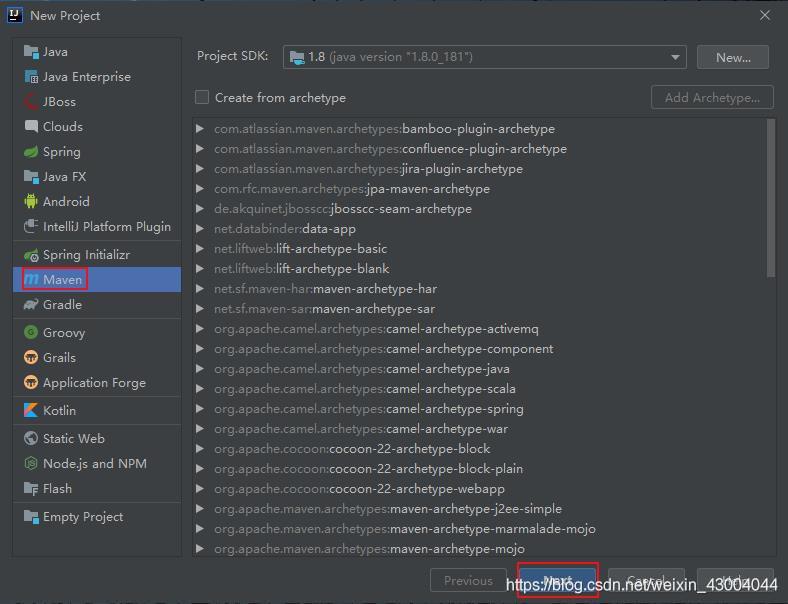
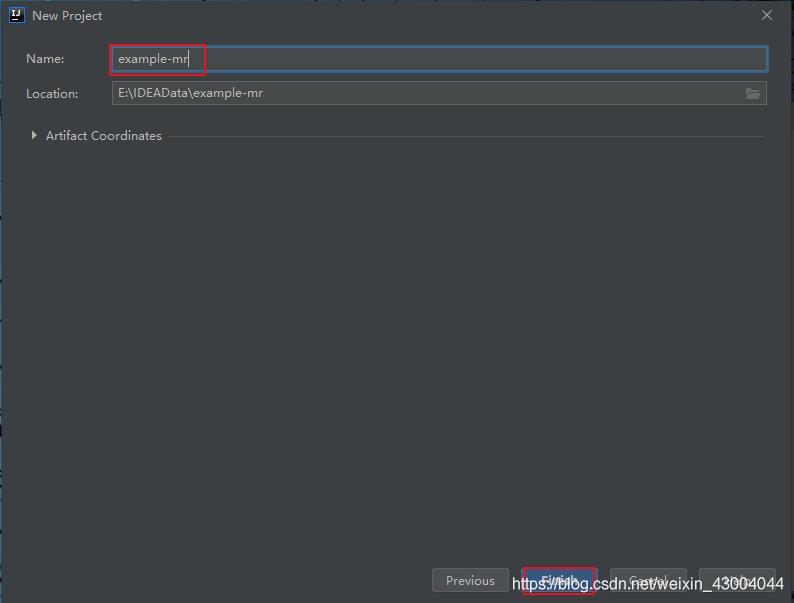
4.3.1.創建Maven專案
打開IDEA→點擊Create New Project→選擇Maven,點擊Next→為自己的專案取名稱,點擊Finish,
注:此處使用的IDEA版本是2019,不同版本之間創建Maven專案的步驟可能會有一些差別!

4.3.2.配置pom.xml檔案
將以下配置添加到pom.xml檔案中(在project標簽下)
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.32</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>2.4</version>
<configuration>
<archive>
<manifest>
<addClasspath>true</addClasspath>
<classpathPrefix>lib/</classpathPrefix>
<!--在剛配置時此處先空著-->
<mainClass></mainClass>
</manifest>
</archive>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
</plugins>
</build>
4.3.3.撰寫Mapper類和Reducer類
WordCountMapper.java
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/*
* @description:WordCount Mapper類,對應Maptask
KEYIN: 表示map階段輸入kv中的k型別 在默認組件下 是起始位置偏移量 因此是LongWritable
* VALUEIN:表示map階段輸入kv中的v型別 在默認組件下 是每一行內容 因此是Text.
* todo MapReduce有默認的讀取資料組件 叫做TextInputFormat
* todo 讀資料的行為是:一行一行讀取資料 回傳kv鍵值對
* k:每一行的起始位置的偏移量 通常無意義
* v:這一行的文本內容
* KEYOUT: 表示map階段輸出kv中的k型別 跟業務相關 本需求中輸出的是單詞 因此是Text
* VALUEOUT: 表示map階段輸出kv中的v型別 跟業務相關 本需求中輸出的是單詞次數1 因此是LongWritable
* */
public class WordCountMapper extends Mapper<LongWritable,Text,Text,LongWritable> {
private Text outkey = new Text();
private final static LongWritable outvalue = new LongWritable(1);
/*
* map方法是mapper階段核心方法 也是具體業務邏輯實作的方法
* 注意,該方法被呼叫的次數和輸入的kv鍵值對有關,每當TextInputFormat讀取回傳一個kv鍵值對,就呼叫一次map方法進行業務處理
* 默認情況下,map方法是基于行來處理資料
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//獲取一行資料轉換為String
String line = value.toString(); //hello hello hello hello allen
//根據分隔符進行切割(此處使用正則運算式,即split("\\s+")按空格或制表符等進行拆分)
String[] words = line.split("\\s+"); //[hello,hello,hello,hello,allen]
//遍歷陣列(快捷鍵:iter+Enter)
for (String word : words) {
outkey.set(word);
//輸出資料,把每個單詞標記1,即輸出的結果為<單詞,1>
//使用背景關系物件將資料輸出
context.write(outkey,outvalue); //<hello,1>
}
}
}
WordCountReducer.java
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/*
* @description: 本類就是MapReduce程式中Reduce階段的處理類 對應著ReduceTask
*
* KEYIN: 表示的是reduce階段輸入kv中k的型別 對應著map的輸出的key 因此本需求中 就是單詞 Text
* VALUEIN:表示的是reduce階段輸入kv中v的型別 對應著map的輸出的value 因此本需求中 就是單詞次數1 LongWritable
* KEYOUT: 表示的是reduce階段輸出kv中k的型別 跟業務相關 本需求中 還是單詞 Text
* VALUEOUT:表示的是reduce階段輸出kv中v的型別 跟業務相關 本需求中 還是單詞總次數 LongWritable
*/
public class WordCountReducer extends Reducer<Text, LongWritable,Text,LongWritable> {
private LongWritable outvalue=new LongWritable();
/**
* todo Q:當map的所有輸出資料來到reduce之后 該如何呼叫reduce方法進行處理呢?
* <hello,1><hadoop,1><hello,1><hello,1><hadoop,1>
* 1.排序 規則:根據key的字典序進行排序 a-z
* <hello,1><hello,1><hello,1><hello,1><allen,1>
* 2.分組 規則:key相同的分為一組
* <hello,1><hello,1><hello,1><hello,1>
* <allen,1>
* 3.分組之后,同一組的資料組成一個新的kv鍵值對,呼叫一次reduce方法, reduce方法基于分組呼叫的 一個分組呼叫一次,
* todo 同一組中資料組成一個新的kv鍵值對,
* 新key:該組共同的key
* 新value:該組所有的value組成的一個迭代器Iterable
* <hadoop,1><hadoop,1><hadoop,1>----><hadoop,Iterable[1,1,1]>
* <hello,1><hello,1>----> <hello,Iterable[1,1]>
*/
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
//定義統計變數
long count=0;
//遍歷該組的values(快捷鍵:iter+Enter)
for (LongWritable value : values) {
//累加計算總次數
count+=value.get();
}
outvalue.set(count);
//最終使用背景關系物件輸出結果
context.write(key,outvalue);
}
}
4.3.4.撰寫客戶端驅動類
方式1:創建Job作業實體提交程式
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/*
* @description: 該類就是MapReduce程式客戶端驅動類 主要是構造Job物件實體
* 指定各種組件屬性 包括:mapper reducer類、輸入輸出的資料型別、輸入輸出的資料路徑
* 提交job作業 job.submit()
*/
public class WordCountDriver_v1 {
public static void main(String[] args) throws Exception {
//創建配置物件
Configuration conf = new Configuration();
//conf.set("mapreduce.framework.name","yarn");
//構建Job作業的實體 引數(配置物件、Job名字)
Job job = Job.getInstance(conf, WordCountDriver_v1.class.getSimpleName());
//設定mr程式運行的主類
job.setJarByClass(WordCountDriver_v1.class);
//設定本次mr程式的mapper型別 reducer類
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
//指定mapper階段輸出的key value資料型別
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//指定reducer階段輸出的key value型別 也是mr程式最終的輸出資料型別
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//配置本次作業的輸入資料路徑 和輸出資料路徑
Path input = new Path(args[0]);
Path output = new Path(args[1]);
//todo 默認組件 TextInputFormat TextOutputFormat
FileInputFormat.setInputPaths(job,input);
FileOutputFormat.setOutputPath(job,output);
//todo 判斷輸出路徑是否已經存在 如果存在先洗掉
FileSystem fs = FileSystem.get(conf);
if(fs.exists(output)){
fs.delete(output,true);//rm -rf
}
//最終提交本次job作業
//job.submit();
//采用waitForCompletion提交job 引數表示是否開啟實時監視追蹤作業的執行情況
boolean resultflag = job.waitForCompletion(true);
//退出程式 和job結果進行系結
System.exit(resultflag ? 0: 1);
}
}
方式2:使用ToolRunner提交程式(推薦使用)
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/*
* @description: 使用工具類ToolRunner提交MapReduce作業
*/
public class WordCountDriver_v2 extends Configured implements Tool {
public static void main(String[] args) throws Exception {
//創建配置物件
Configuration conf = new Configuration();
//todo 使用工具類ToolRunner提交程式
int status = ToolRunner.run(conf, new WordCountDriver_v2(), args);
//退出客戶端
System.exit(status);
}
@Override
public int run(String[] args) throws Exception {
//構建Job作業的實體 引數(配置物件、Job名字)
Job job = Job.getInstance(getConf(), WordCountDriver_v2.class.getSimpleName());
//設定mr程式運行的主類
job.setJarByClass(WordCountDriver_v2.class);
//設定本次mr程式的mapper型別 reducer類
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
//指定mapper階段輸出的key value資料型別
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//指定reducer階段輸出的key value型別 也是mr程式最終的輸出資料型別
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//配置本次作業的輸入資料路徑 和輸出資料路徑
Path input = new Path(args[0]);
Path output = new Path(args[1]);
//todo 默認組件 TextInputFormat TextOutputFormat
FileInputFormat.setInputPaths(job,input);
FileOutputFormat.setOutputPath(job,output);
//todo 判斷輸出路徑是否已經存在 如果存在先洗掉
FileSystem fs = FileSystem.get(conf);
if(fs.exists(output)){
fs.delete(output,true);//rm -rf
}
return job.waitForCompletion(true)? 0:1;
}
}
4.4.運行MapReduce程式
MapReduce程式的運行模式有兩種:YARN集群模式和本地模式,
在何種模式下運行取決于引數mapreduce.framework.name,當其值為yarn時,為YARN集群模式;當為local時,則是Local本地模式,如果不指定,默認是Local本地模式(在匯入的包中的mapred-default.xml中有定義),但在搭建好的Hadoop集群的Linux上運行時,Hadoop中的配置(mapred-site.xml和yarn-site.xml)會覆寫原本的default配置,從而使用YARN集群模式,
不過如果在代碼中直接設定mapreduce.framework.name=local,即conf.set(“mapreduce.framework.name”,“local”),那么當在Linux中運行jar包時還是會使用Local本地模式,因為在代碼中設定的優先級最高!
4.4.1.YARN集群模式
(1)啟動在Linux中搭建好的Hadoop集群(包括HDFS集群和YARN集群)
(2)復制main方法所在類路徑(以上的兩種驅動類都可以,此處復制的是第一種)

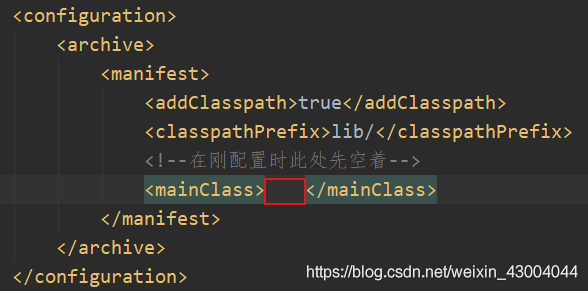
然后在pom.xml檔案中配置main方法所在類路徑,即將剛才復制的內容粘貼到之前留下的空白處
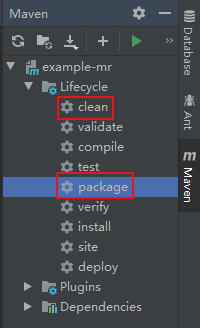
(3)點擊右側的Maven,再依次點擊clean、package,將程式打成jar包
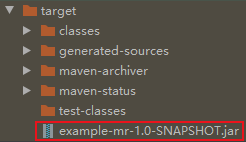
將打包完成的jar包上傳到Hadoop集群的任意一個節點的目錄下(此處選擇放到node1的root目錄下)
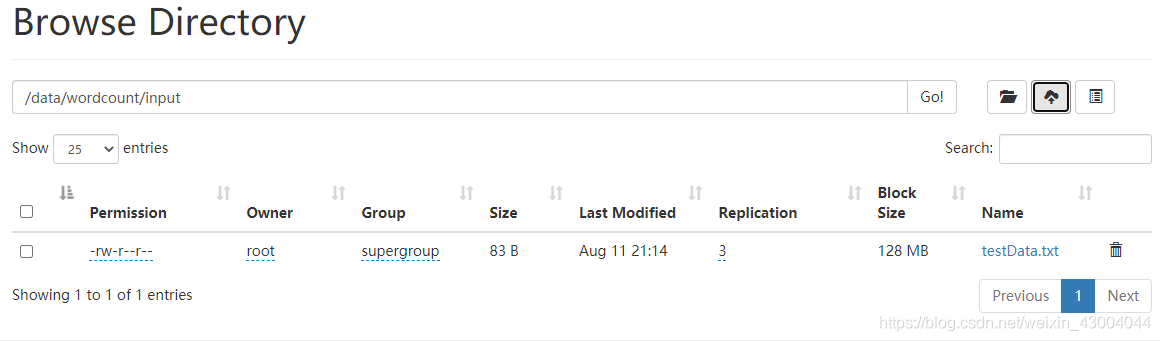
(4)將測驗資料所在的檔案testData.txt上傳到HDFS的任意一個目錄下
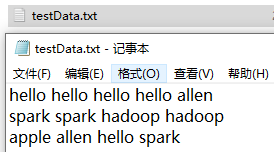
此處選擇放到/data/wordcount/input目錄下
(5)在node1的終端中(當前所在路徑為/root,因為jar在該目錄下),執行如下的啟動命令:
hadoop jar example-mr-1.0-SNAPSHOT.jar /data/wordcount/input /data/wordcount/output
| /data/wordcount/input | 測驗檔案testData.txt所在的目錄 |
|---|---|
| /data/wordcount/output | 計算得到的結果所在的目錄(不需要提前創建,否則會報錯) |
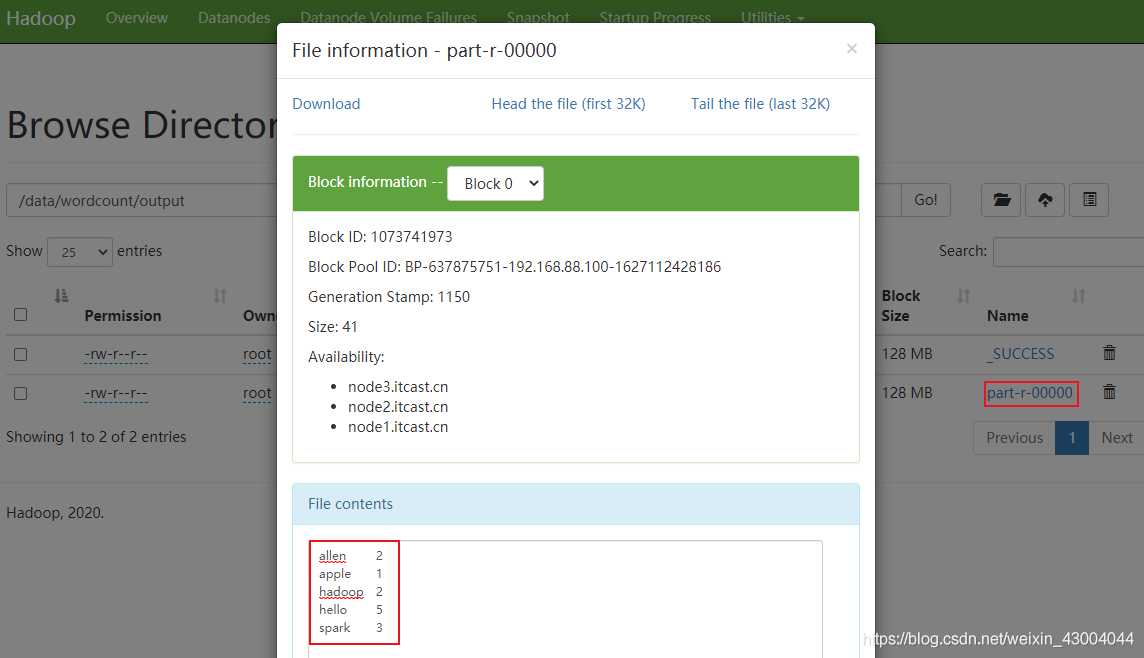
(6)到HDFS的/data/wordcount/output目錄下查看或下載結果(已按字典序進行排序):
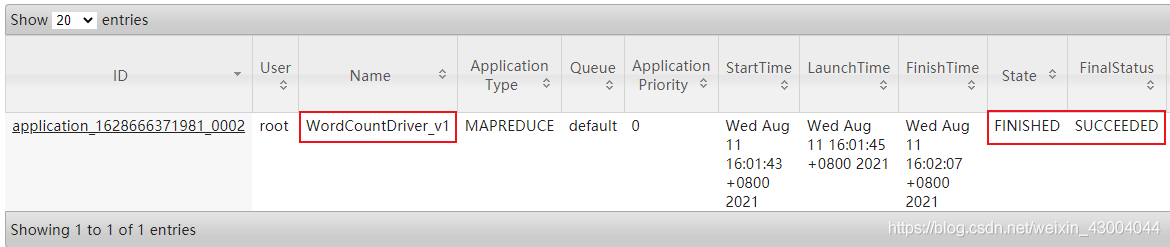
此外還可以在YARN中查看該任務的執行情況:
4.4.2.Local本地模式
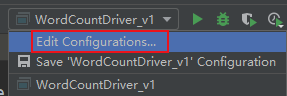
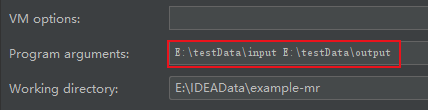
(1)點擊Edit Configurations…
添加呼叫main函式時需要的引數,即測驗檔案testData.txt所在的目錄以及計算得到的結果所在的目錄(后者不需要自己創建)
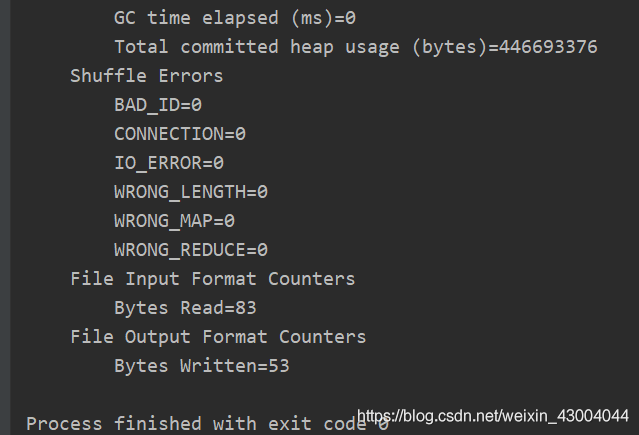
(2)出現"Process finished with exit code 0"則說明運行成功
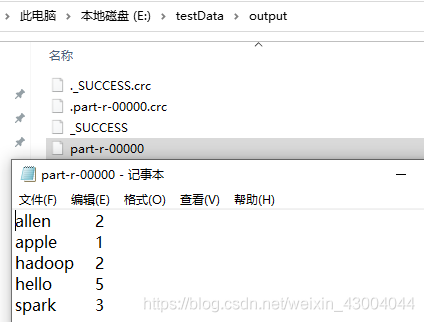
(3)查看結果
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293545.html
標籤:其他