Elasticsearch 操作
- Elasticsearch DSL
- 欄位型別
- 索引操作
- 分片、副本
- 分詞器操作
- 資料操作(增、刪、查、改)
- 資料批量匯入
- 資料查詢
- Elasticsearch SQL
- SQL 與 Elasticsearch 對應關系
- Elasticsearch SQL 語法
- 格式化回傳資料
- SQL 轉換為 DSL
- Scroll分頁查詢
- 全文檢索
Elastic Document APIs
Elasticsearch 操作工具 VS Code 插件安裝及使用
Elasticsearch DSL
Elasticsearch DSL(Domain Specific Language特定領域語言)以JSON請求體的形式出現,提供豐富且靈活的查詢語言叫做DSL查詢(Query DSL),它允許你構建更加復雜、強大的查詢
欄位型別
欄位型別介紹
在 Elasticsearch 中,每一個欄位都有一個型別(type),以下為 Elasticsearch 中可以使用的型別
| 分類 | 型別名稱 | 說明 |
|---|---|---|
| 簡單型別 | text | 需要進行全文檢索的欄位,通常使用text型別來對應郵件的正文、產品描述或者短文等非結構化文本資料,分詞器先會將文本進行分詞轉換為詞條串列,將來就可以基于詞條來進行檢索了,文本欄位不能用戶排序、也很少用戶聚合計算 |
| keyword | 使用keyword來對應結構化的資料,如ID、電子郵件地址、主機名、狀態代碼、郵政編碼或標簽,可以使用keyword來進行排序或聚合計算 注意:keyword是不能進行分詞的 | |
| date | 保存格式化的日期資料,例如:2015-01-01或者2015/01/01 12:10:30,在Elasticsearch中,日期都將以字串方式展示,可以給date指定格式:”format”: “yyyy-MM-dd HH:mm:ss” | |
| long/integer/short/byte | 64位整數/32位整數/16位整數/8位整數 | |
| double/float/half_float | 64位雙精度浮點/32位單精度浮點/16位半進度浮點 | |
| boolean | “true”/”false” | |
| ip | IPV4(192.168.1.110)/IPV6(192.168.0.0/16) | |
| JSON分層嵌套型別 | object | 用于保存JSON物件 |
| nested | 用于保存JSON陣列 | |
| 特殊型別 | geo_point | 用于保存經緯度坐標 |
| geo_shape | 用于保存地圖上的多邊形坐標 |
索引操作
注意:判斷欄位型別是使用text、還是keyword,主要就看是否需要分詞
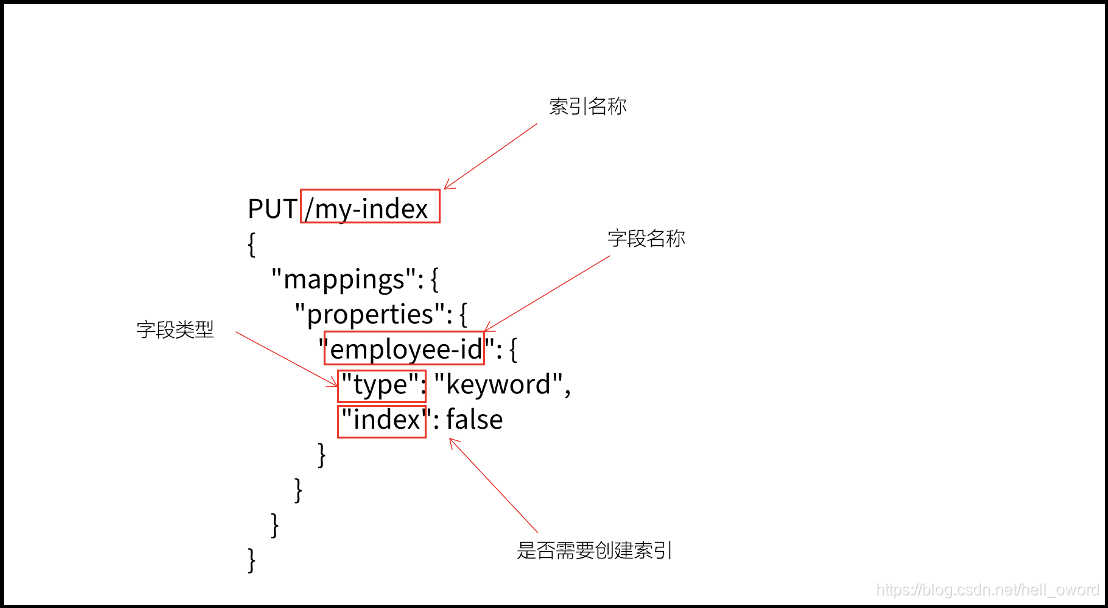
創建帶有映射的索引
# 格式
PUT /my-index
{
"mapping": {
"properties": {
"employee-id": {
"type": "keyword",
"index": false
}
}
}
}
# 示例
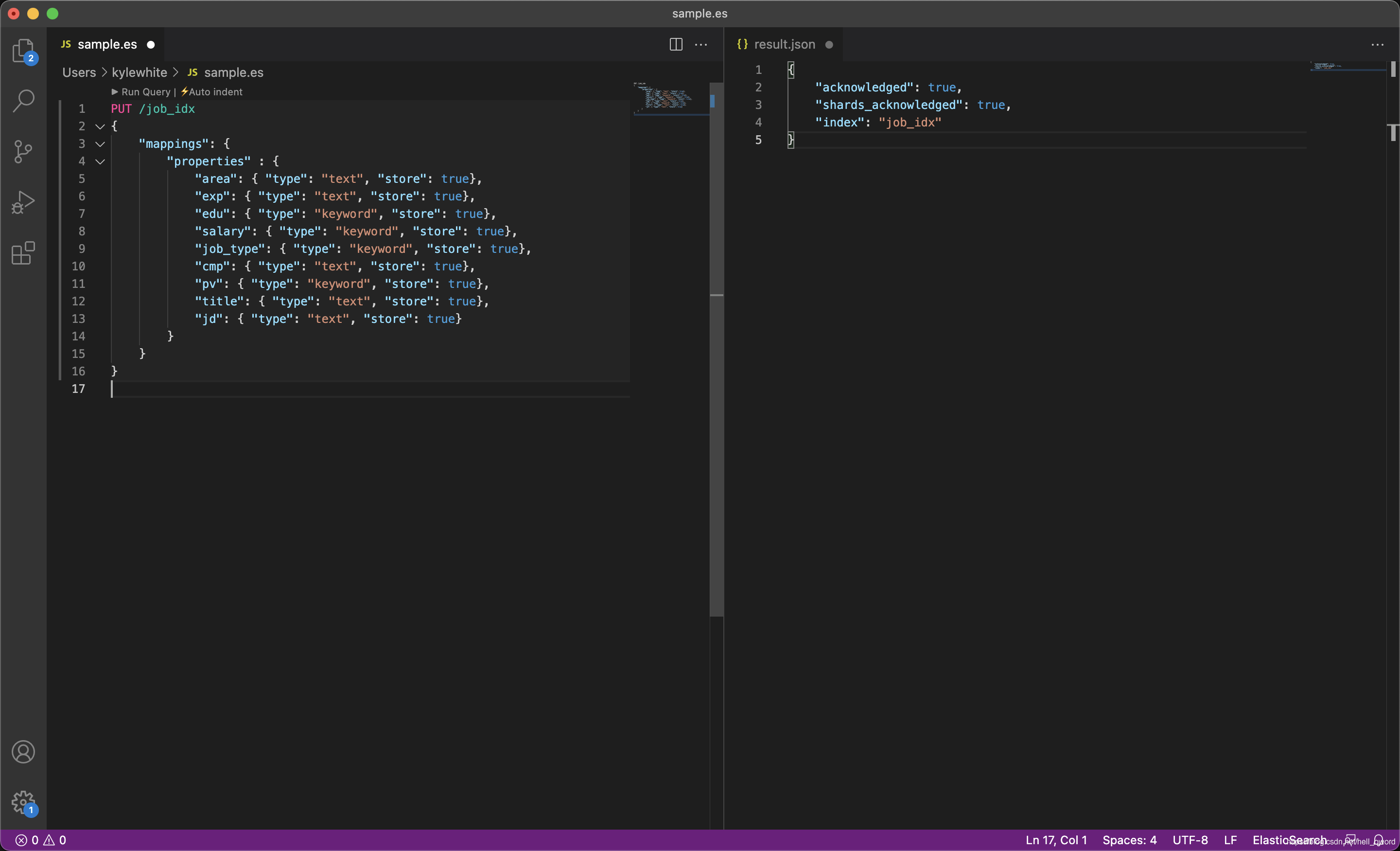
PUT /job_idx
{
"mappings": {
"properties" : {
"area": { "type": "text", "store": true},
"exp": { "type": "text", "store": true},
"edu": { "type": "keyword", "store": true},
"salary": { "type": "keyword", "store": true},
"job_type": { "type": "keyword", "store": true},
"cmp": { "type": "text", "store": true},
"pv": { "type": "keyword", "store": true},
"title": { "type": "text", "store": true},
"jd": { "type": "text", "store": true}
}
}
}
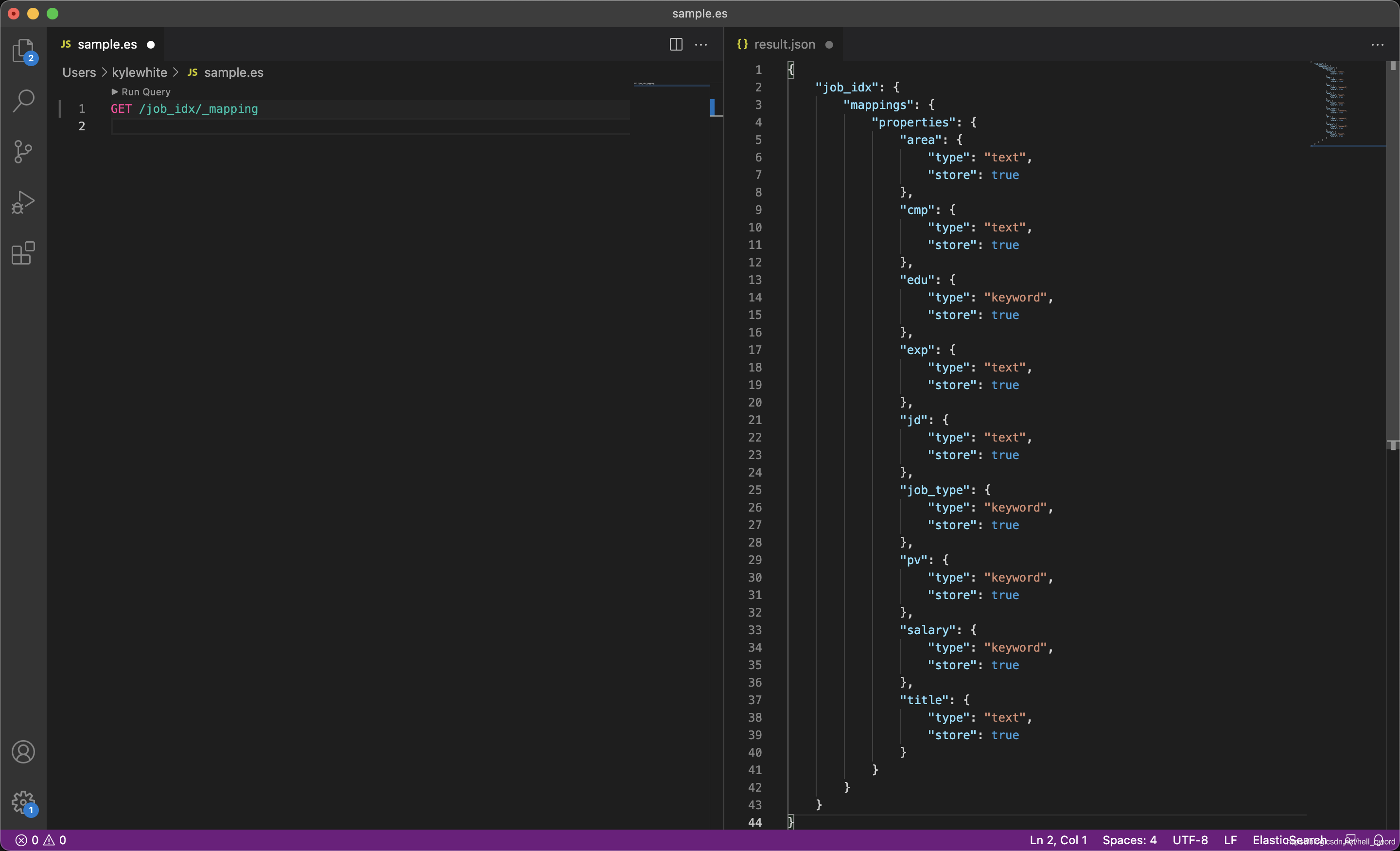
查看指定的索引
// 格式
GET /索引名稱/_mapping
// 示例
GET /job_idx/_mapping
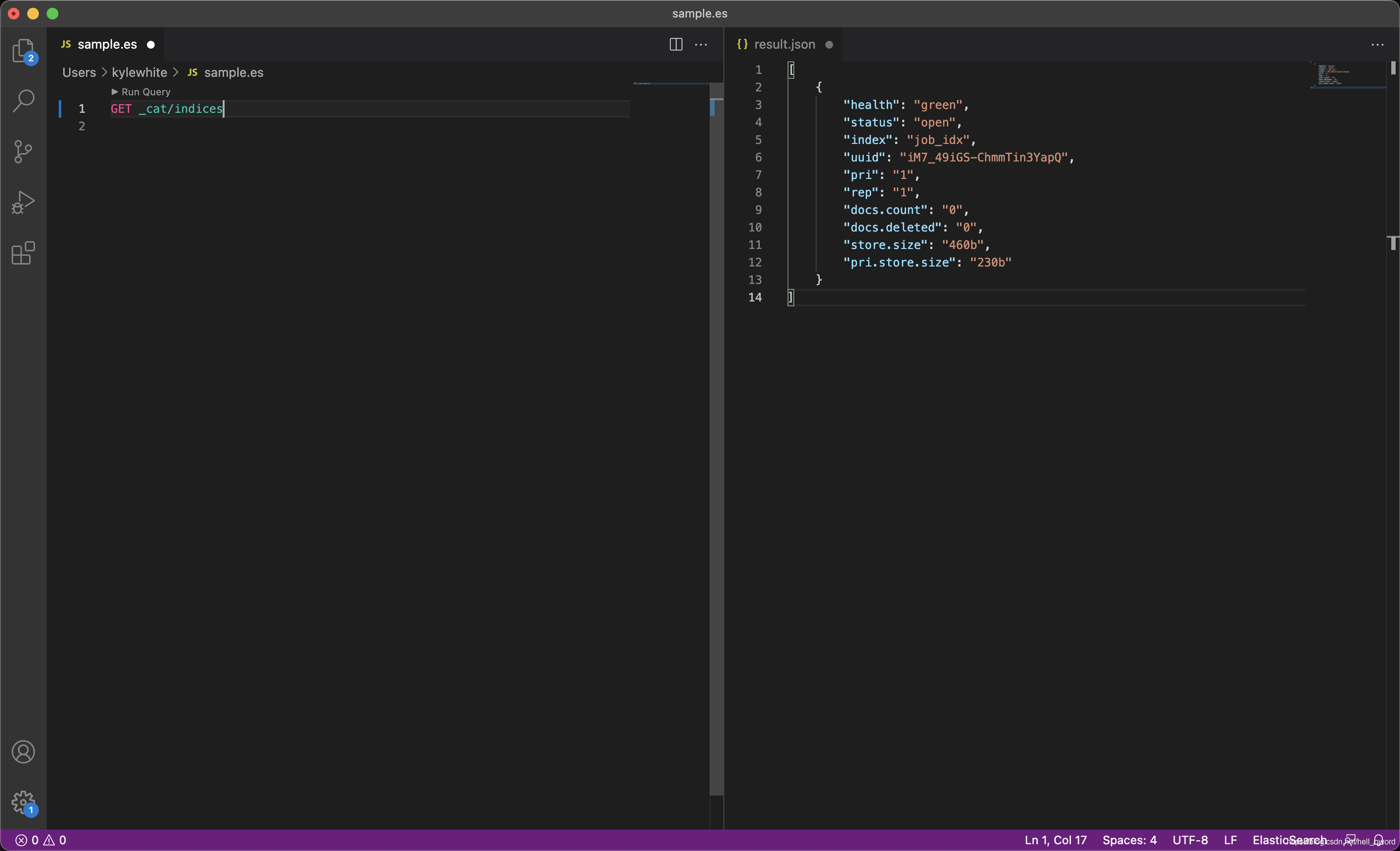
查看所有的索引
GET _cat/indices
查看索引的狀態
// 查看 job_idx 索引的狀態
GET _cat/indices?index=job_idx


洗掉指定的索引
// 格式
delete /索引名稱
// 示例
delete /job_idx

分片、副本
創建索引并指定分片和副本
創建索引,并指定該索引有 3 個分片和 2 個副本
# 格式
PUT /my-index
{
"mapping": {
"properties": {
"employee-id": {
"type": "keyword",
"index": false
}
}
},
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2
}
}
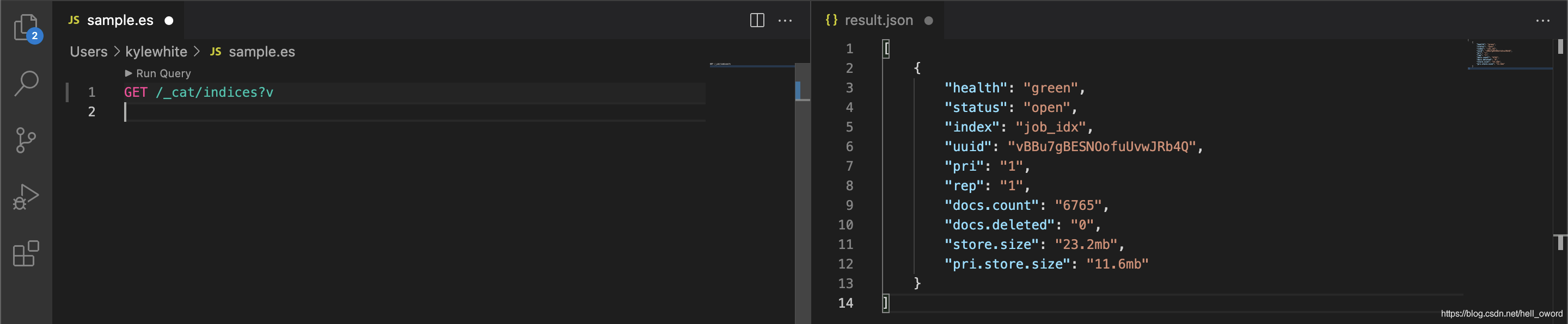
查看分片和副本
GET /_cat/indices?v
分詞器操作
指定分詞器
// 指定分詞器為標準分詞器
post _analyze
{
"analyzer":"standard",
"text":"我愛你中國"
}
// 指定分詞器為 IK分詞器
post _analyze
{
"analyzer":"ik_max_word",
"text":"我愛你中國"
}
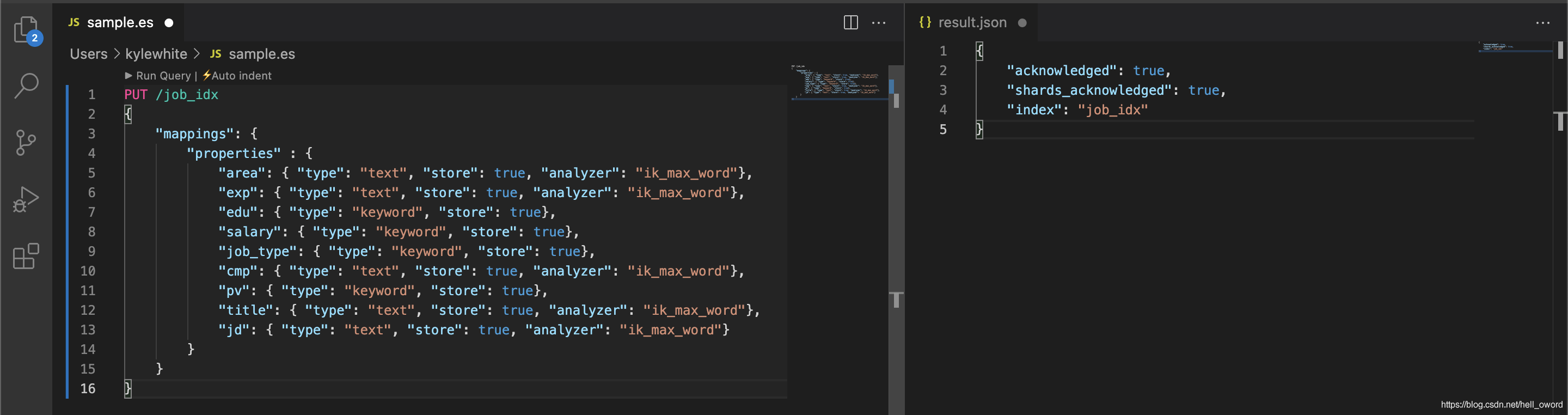
創建索引并指定分詞器
PUT /job_idx
{
"mappings": {
"properties" : {
"area": { "type": "text", "store": true, "analyzer": "ik_max_word"},
"exp": { "type": "text", "store": true, "analyzer": "ik_max_word"},
"edu": { "type": "keyword", "store": true},
"salary": { "type": "keyword", "store": true},
"job_type": { "type": "keyword", "store": true},
"cmp": { "type": "text", "store": true, "analyzer": "ik_max_word"},
"pv": { "type": "keyword", "store": true},
"title": { "type": "text", "store": true, "analyzer": "ik_max_word"},
"jd": { "type": "text", "store": true, "analyzer": "ik_max_word"}
}
}
}
資料操作(增、刪、查、改)
添加資料
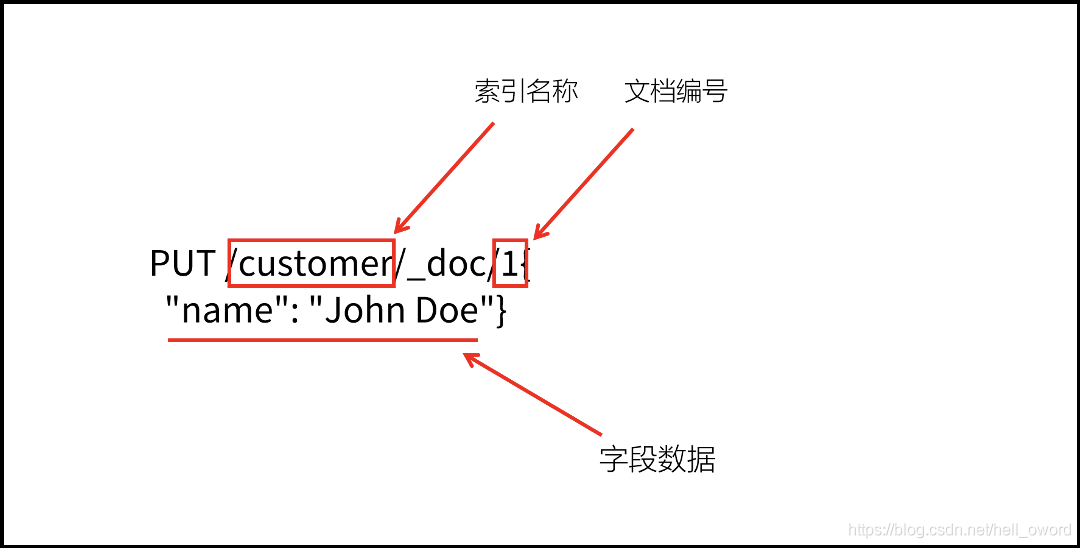
在 Elasticsearch 中,每一個檔案都有唯一的 ID,也是使用 JSON 格式來描述資料,例如
// 如果在 customer 中,不存在 ID 為 1 的檔案,Elasticsearch 會自動創建
PUT /customer/_doc/1{
"name": "John Doe"}

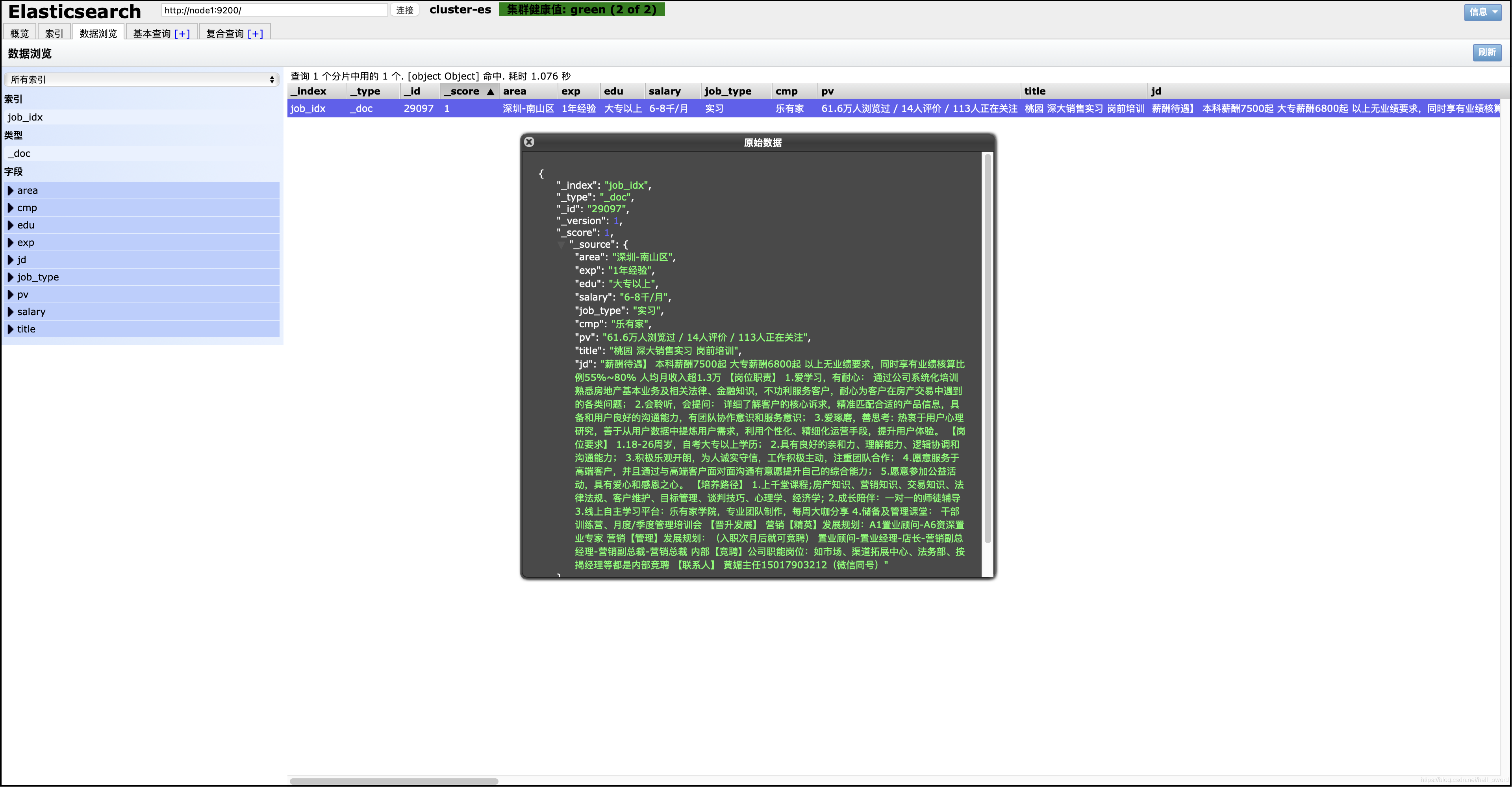
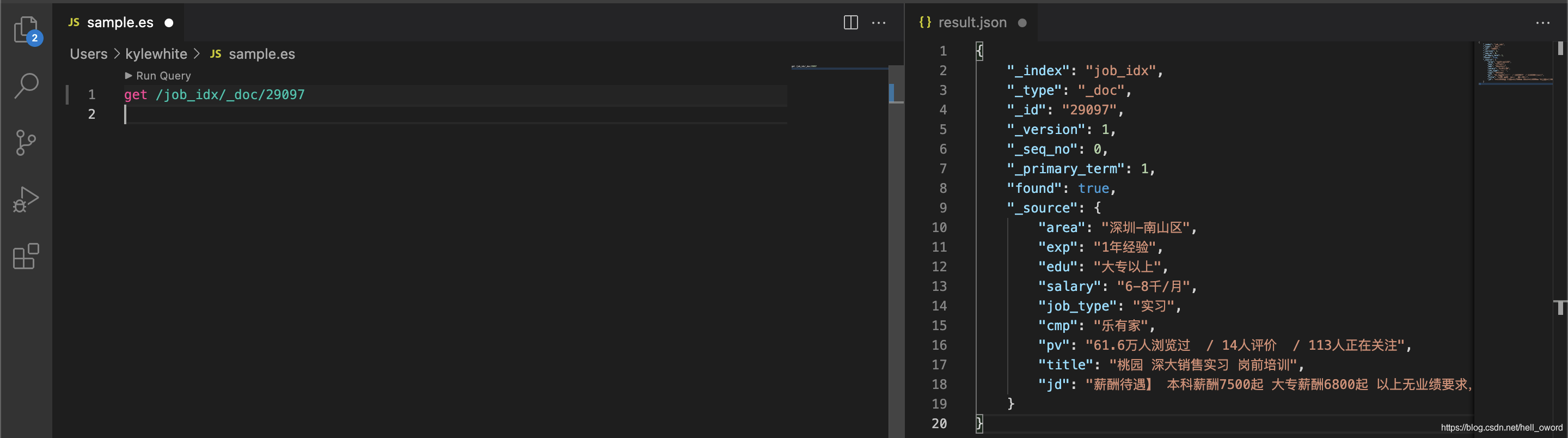
查看資料
① 使用 ES-head 插件瀏覽資料
② 使用 DSL 查看
get /job_idx/_doc/29097
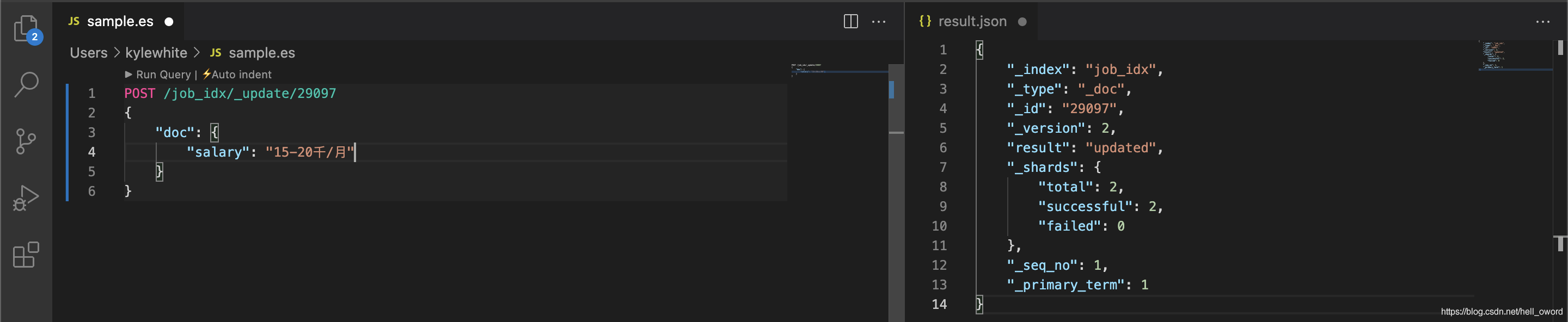
修改資料
// 將 doc_id 為 29097 的 salary 由 '6-8千/月' 修改為 '15-20千/月'
POST /job_idx/_update/29097
{
"doc": {
"salary": "15-20千/月"
}
}
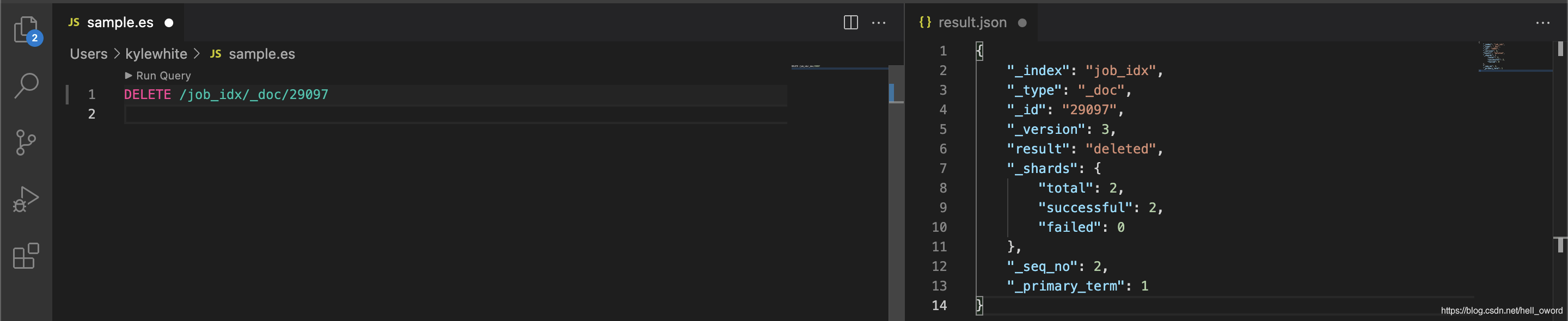
洗掉資料
// 將 索引 job_idx 下 doc_id 為 29097 的資料洗掉
DELETE /job_idx/_doc/29097
資料批量匯入
Elasticsearch 中自帶的 bulk 介面可以實作資料匯入
① 將檔案上傳至 ElasticSearch 服務器
② 執行匯入命令
curl -H "Content-Type: application/json" -XPOST "node1:9200/job_idx/_bulk?pretty&refresh" --data-binary "@/opt/server/job_info.json"
資料查詢
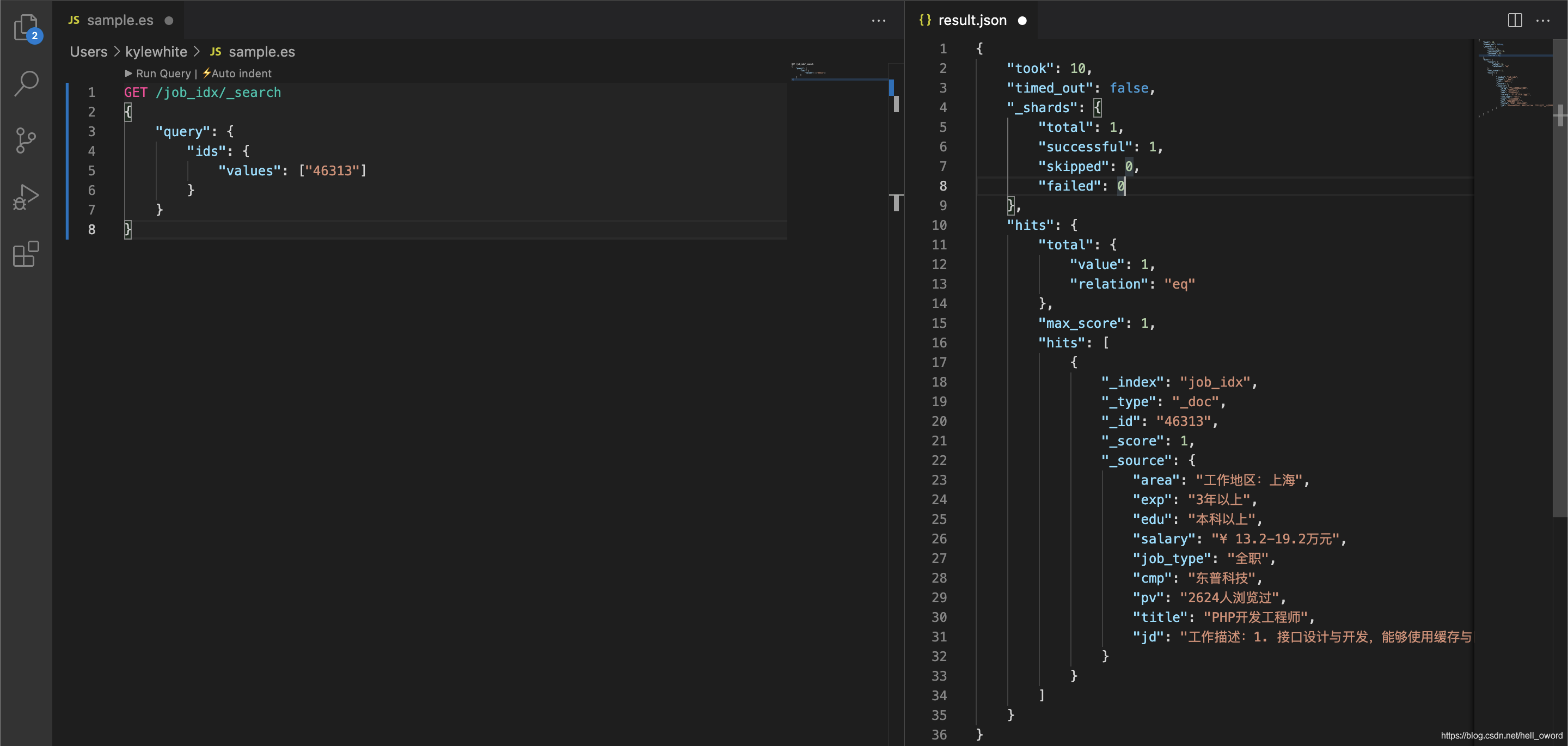
根據檔案 ID 查詢資料
// 格式
GET /索引名稱/_search
{
"query": {
"ids": {
"values": ["46313"]
}
}
}

// 示例:查詢 job_idx 索引下的檔案 id 為 46313 的資料
GET /job_idx/_search
{
"query": {
"ids": {
"values": ["46313"]
}
}
}
根據關鍵字查詢資料
// 第一種:檢索 jd 欄位中包含 '銷售' 的資料
GET /job_idx/_search
{
"query": {
"match": {
"jd": "銷售"
}
}
}
// 第二種:檢索多個欄位中包含 '銷售' 的資料
GET /job_idx/_search
{
"query": {
"multi_match": {
"query": "銷售",
"fields": ["title", "jd"]
}
}
}
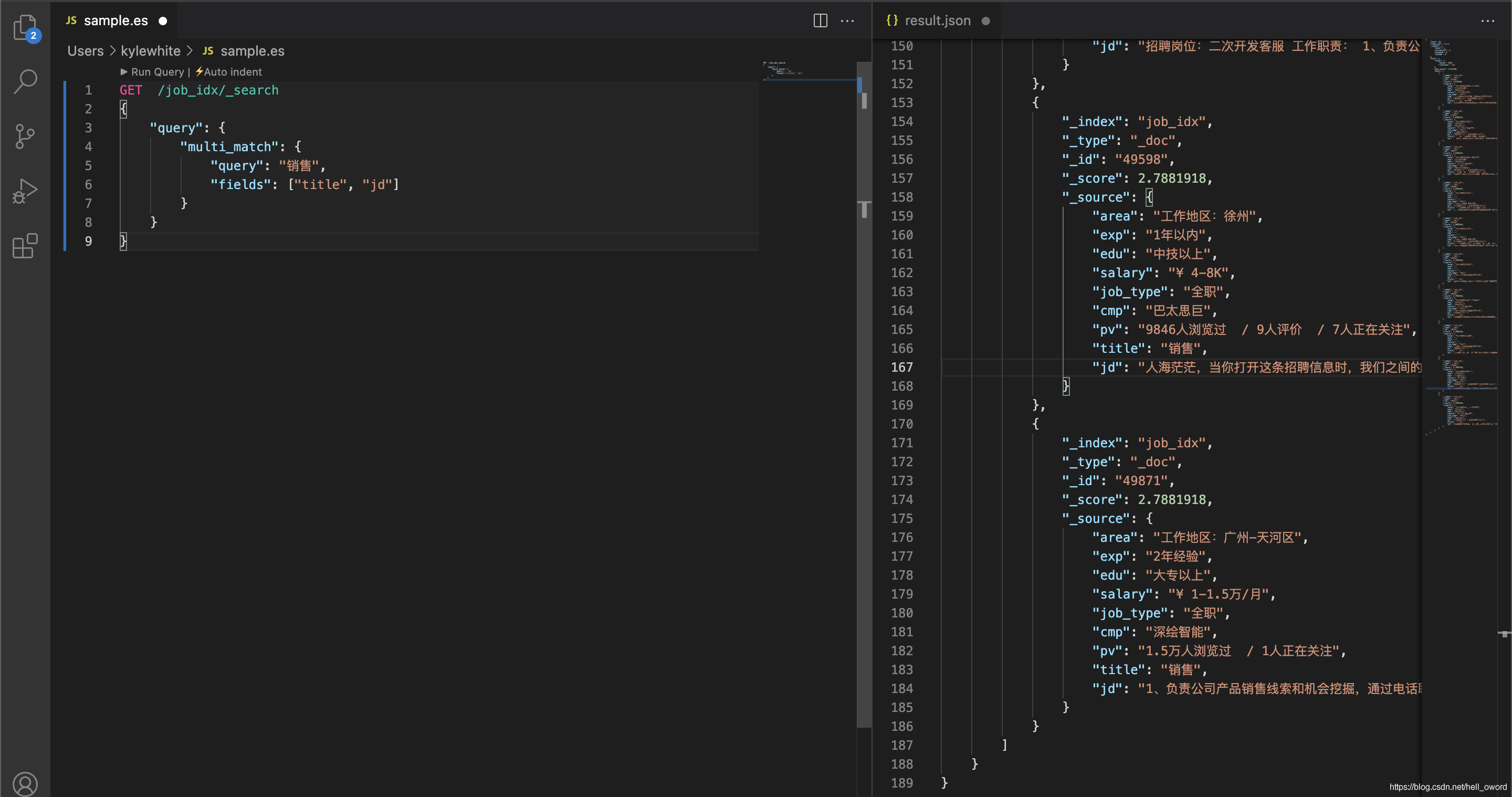
分頁查詢(from…size…)
指定頁碼、并指定每頁顯示多少條資料,然后 Elasticsearch 回傳對應頁碼的資料
// from = (page – 1) * size
GET /job_idx/_search
{
"from": 0,
"size": 5,
"query": {
"multi_match": {
"query": "銷售",
"fields": ["title", "jd"]
}
}
}
分頁查詢(scroll)
使用 from 和 size 方式,查詢超過 5W 的資料,會出現性能問題,Elasticsearch 做了一個限制,不允許查詢的是 1W 條以后的資料,如果要查詢 1W 條以后的資料,需要使用 Elasticsearch 中提供的 scroll 游標來查詢
在進行大量分頁時,每次分頁都需要將要查詢的資料進行重新排序,這樣非常浪費性能,使用 scroll 是將要用的資料一次性排序好,然后分批取出,性能要比 from + size 好得多,使用scroll查詢后,排序后的資料會保持一定的時間,后續的分頁查詢都從該快照取資料即可,
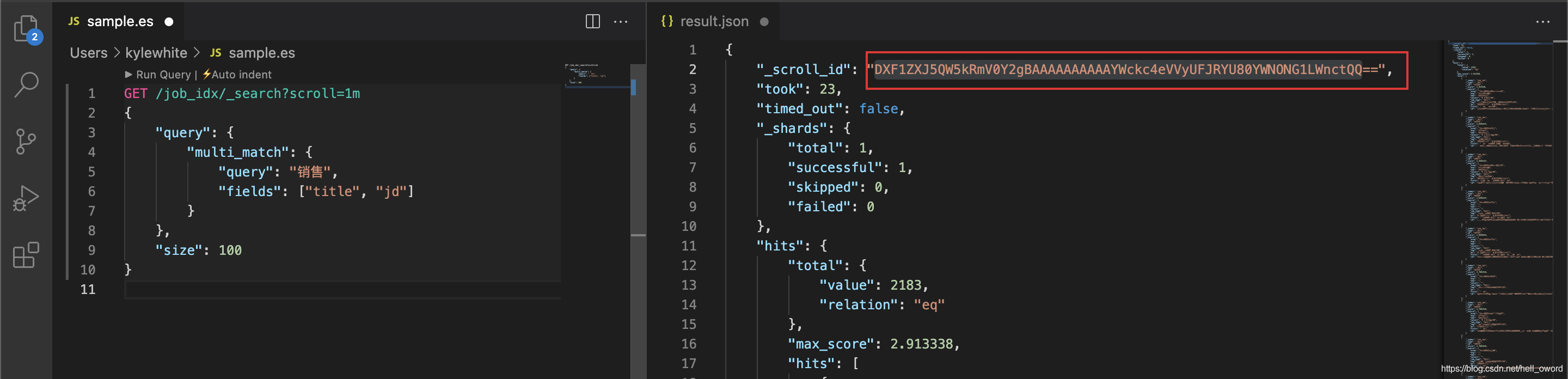
① 第一次使用 scroll
第一次查詢后,得到了 “_scroll_id”: “DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAAYWckc4eVVyUFJRYU80YWNONG1LWnctQQ==” ,在后續的 1 分鐘內,可以直接通過這個 _scroll_id 去查詢資料
// scroll = 1m 保持查詢結果 1min
GET /job_idx/_search?scroll=1m
{
"query": {
"multi_match": {
"query": "銷售",
"fields": ["title", "jd"]
}
},
"size": 100
}
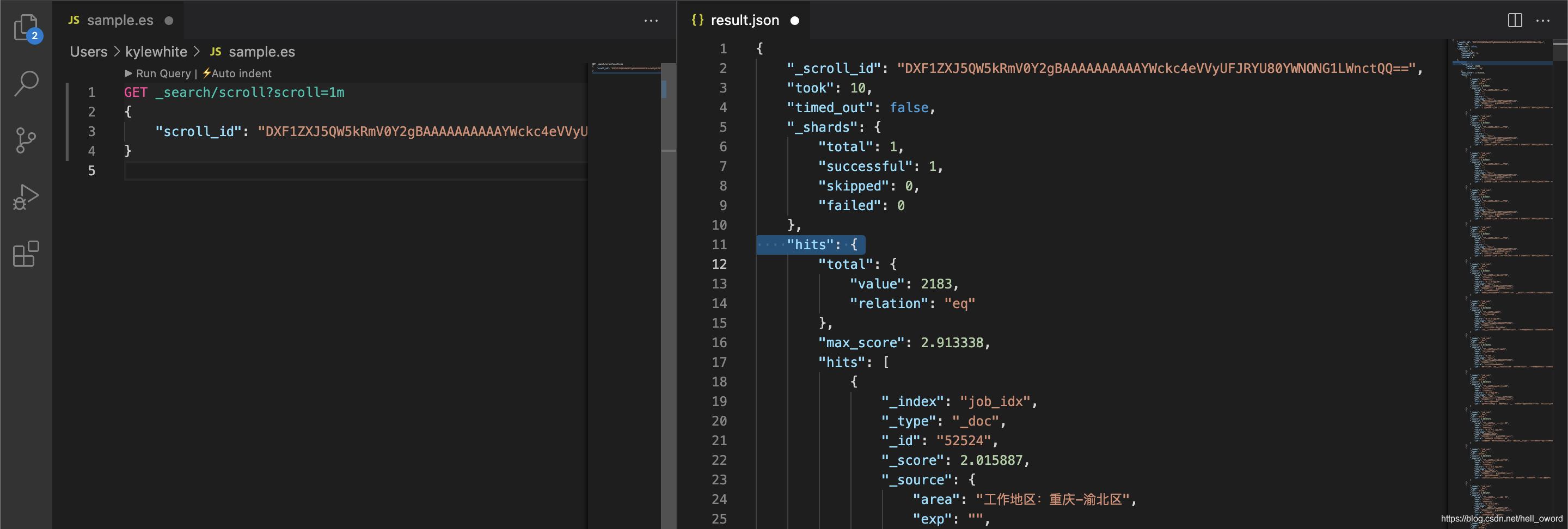
② 第二次使用 scroll
直接使用第一次得到的 _scroll_id 查詢
GET _search/scroll?scroll=1m
{
"scroll_id": "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAAYWckc4eVVyUFJRYU80YWNONG1LWnctQQ=="
}
Elasticsearch SQL
Elasticsearch SQL 的缺陷
不支持JOIN、不支持較復雜的子查詢,所以,有一些相對復雜一些的功能,還得借助于DSL方式來實作
SQL 與 Elasticsearch 對應關系
| SQL | Elasticsearch |
|---|---|
| column(列) | field(欄位) |
| row(行) | document(檔案) |
| table(表) | index(索引) |
| schema(模式) | N/A |
| database(資料庫) | Elasticsearch集群實體 |
Elasticsearch SQL 語法
-- 目前 FROM 只支持一個表
SELECT select_expr [, ...]
[ FROM table_name ]
[ WHERE condition ]
[ GROUP BY grouping_element [, ...] ]
[ HAVING condition]
[ ORDER BY expression [ ASC | DESC ] [, ...] ]
[ LIMIT [ count ] ]
[ PIVOT ( aggregation_expr FOR column IN ( value [ [ AS ] alias ] [, ...] ) ) ]
格式化回傳資料
格式化型別
| 格式 | 描述 |
|---|---|
| csv | 逗號分隔符 |
| json | JSON格式 |
| tsv | 制表符分隔符 |
| txt | 類cli表示 |
| yaml | YAML人類可讀的格式 |
格式化語法
// format 為指定的型別
GET /_sql?format=txt
{
"query": "SELECT * FROM job_idx limit 1"
}

SQL 轉換為 DSL
GET /_sql/translate
{
"query": "SELECT * FROM job_idx limit 1"
}
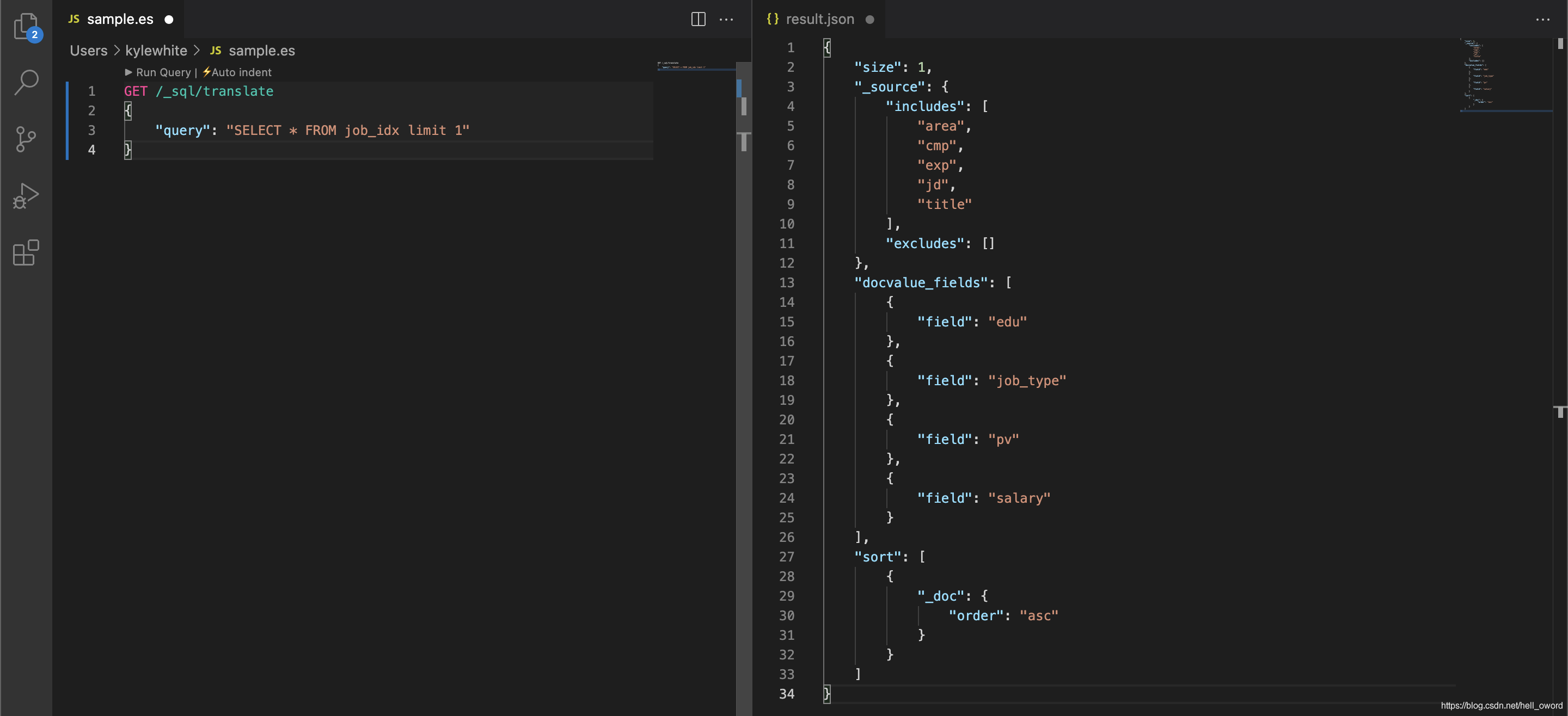
Scroll分頁查詢
游標查詢
① Scroll 第一次分頁查詢
// 格式
GET /_sql?format=json
{
"query": "SELECT * FROM 索引",
"fetch_size": 10
}
// 示例:分頁查詢索引為 job_idx 的資料
GET /_sql?format=json
{
"query": "SELECT * FROM job_idx",
"fetch_size": 10
}

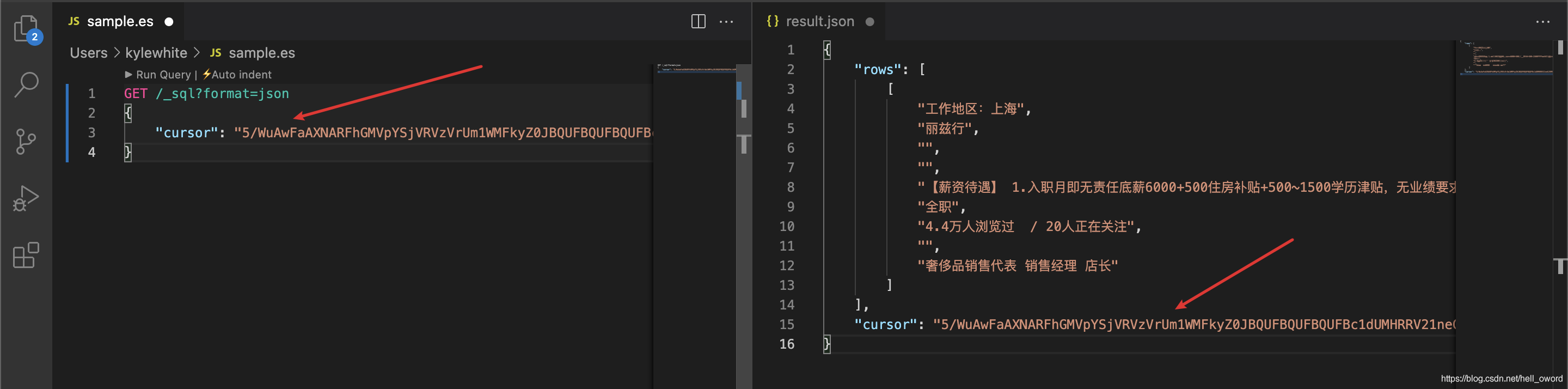
② Scroll 第二次分頁查詢 (查詢時使用 Scroll ID)
GET /_sql?format=json
{
"cursor": "Scroll ID"
}
清除游標
POST /_sql/close
{
"cursor": "Scroll ID"
}

全文檢索
MATCH 函式介紹
// field_exp:匹配欄位
// constant_exp:匹配常量運算式
MATCH(
field_exp,
constant_exp
[, options])
)
// 示例:匹配在 title 欄位中包含 '銷售' 的資料
MATCH(title, '銷售')
全文檢索實作
// 示例:搜索在 title 和 jd 欄位中包含 '銷售' 的資料
GET /_sql?format=txt
{
"query": "select * from job_idx where MATCH(title, '銷售') or MATCH(jd, '銷售') limit 10"
}

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293547.html
標籤:其他