OJ題

文章目錄
- OJ題
- 復雜度的OJ練習
- 1.消失的數字
- 2.旋轉陣列
- 陣列的相關OJ題
- 1.移除元素
- 2.洗掉有序陣列中的重復值
- 3.合并兩個有序陣列
- 鏈表OJ題
- 1.移除鏈表元素
- 2.反轉鏈表
- 3.查找一個鏈表的中間結點
- 4.鏈表中倒數第k個結點
- 5.合并兩個有序鏈表
- 6.鏈表分割
- 7.鏈表的回文結構
- 8.鏈表的相交
- 9.環形鏈表
- 10.環形鏈表Ⅱ
- 11.復制帶隨機指標的鏈表
首先我們先了解一下OJ題的形式,形式有兩種:
- 介面型
提供一個介面函式,而不是完整程式,實作這個函式就可以了,提交程式以后,這段代碼被提交到OJ服務器上,它還要和其他測驗程式(頭檔案、main函式)進行合并
測驗用例一般是通過引數和回傳值進行互動的,
- IO型
寫代碼區域什么都不給你,自己寫完整的程式,頭檔案,主函式,演算法邏輯
我們要去介面IO輸入測驗用例,要把結構按格式輸出
復雜度的OJ練習
1.消失的數字
題目描述:
陣列nums包含從0到n的所有整數,但其中缺了一個,請撰寫代碼找出那個缺失的整數,你有辦法在O(n)時間內完成嗎?
示例 1:
輸入:[3,0,1]
輸出:2示例 2:
輸入:[9,6,4,2,3,5,7,0,1]
輸出:8
題目來源:消失的數字
解法1:
首先排序,然后依次查找上一個數+1是否等于下一個數,等于就繼續,不等于這個數就是缺失的數字
但是復雜度不符合要求,qsort快排,時間復雜度O(N*logN),而題目要求是O(n),故我們看下一種解法:
解法2:
求和,回圈計算出0+1+2+…+n,再減去陣列中的值累加就是缺失的數字
代碼如下:
int missingNumber(int* nums,int numssize)
{
int i=0;
int sum=0;
int sum1=0;
for(i=0;i<numssize;i++)
{
sum+=nums[i];
}
for(i=1;i<=numssize;i++)
{
sum1+=i;
}
return sum1-sum;
}
首先計算出陣列中所有數字的和,然后再計算出0-numssize的和,相減就是消失的數字,
解法3:
看解法3的思路之前我們需要知道一個知識:兩個相同的數異或等于0,0和任何數異或等于它本身
比如3異或3,不同為1,他們的二進制位都是相同的,故全是0,所以等于0
解法3思路:
創建一個變數x=0,x先跟陣列中值異或,再跟與0-n之間的數異或,相當于其他數出現了兩次,出現兩次的都異或都成為了0,缺失的數字只出現一次,故最好x就是缺失的數字
時間復雜度O(N),滿足要求
代碼如下:
int missingnumber(int* nums,int numssize)
{
int x=0;
//先跟陣列中值異或
for(int i=0;i<numssize;i++)
{
x^=nums[i];
}
//再跟0-n的數字異或
for(int i=0;i<=numssize;i++)
{
x^=i;
}
return x;
}
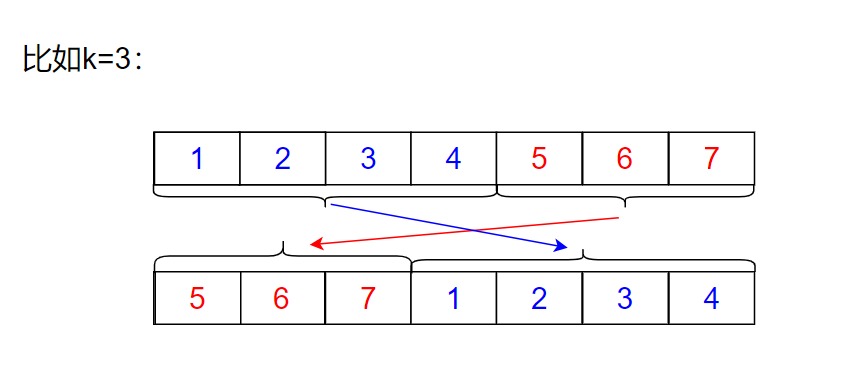
2.旋轉陣列
題目描述:
給定一個陣列,將陣列中的元素向右移動 k 個位置,其中 k 是非負數,
進階:
盡可能想出更多的解決方案,至少有三種不同的方法可以解決這個問題,
你可以使用空間復雜度為 O(1) 的 原地 演算法解決這個問題嗎?示例 1:
輸入: nums = [1,2,3,4,5,6,7], k = 3
輸出: [5,6,7,1,2,3,4]
解釋:
向右旋轉 1 步: [7,1,2,3,4,5,6]
向右旋轉 2 步: [6,7,1,2,3,4,5]
向右旋轉 3 步: [5,6,7,1,2,3,4]
題目來源:旋轉陣列
解法一:
右旋一次:保留最后一個值到temp變數,陣列中值都向右移動一次,再把temp放到最左邊
然后外面套一層回圈,右旋k次
時間復雜度:0(N*(K%N))->最好是K==N時,時間復雜度位O(1) ,最壞是O(N^2) ,是在K==N-1時,時間復雜度考慮最壞情況,故時間復雜度為O(N^2),這個方法的時間性能不高
空間復雜度為O(1)
代碼如下:
void rotate(char*str,int k)
{
int i=0;
int len=strlen(str)
for(i=0;i<k%len;i++)
{
char temp=str[len-1]
int j=0;
for(j=len-1;j>0;j--)
{
str[j]=str[j-1];
}
str[0]=temp;
}
}
這里需要考慮的是k等于len時,相當于沒有旋轉,故我們這里外面for回圈的終止回圈條件為i<k%len,
解法二:
思路:
這是空間換時間的解法,用兩個陣列:直接把后k個放在第二個陣列的前k個上,前n-k個放在第二個陣列的后面
代碼如下:
int main()
{
int arr1[] = { 1,2,3,4,5,6,7 };
int arr2[10] = { 0 };
int k = 0;
scanf("%d", &k);
int sz = sizeof(arr1) / sizeof(arr1[0]);
int i = 0;
//把后k個數放在第二個陣列的前k個上
for (i = 0; i < k; i++)
{
arr2[i] = arr1[sz - k + i];
}
//把前n-k個數放在第二個陣列的后面
for (i = 0; i < sz - k; i++)
{
arr2[k + i] = arr1[i];
}
for (i = 0; i < sz; i++)
{
printf("%d ", arr2[i]);
}
return 0;
}
時間復雜度:O(N)
空間復雜度:O(N)
這樣可以解決這個問題,但是這個OJ題是不能這樣寫的,因為這個OJ題是介面型的:
我們將陣列一的元素放在陣列二,我們沒有改變陣列一的旋轉,只是將陣列一旋轉的結果放在了陣列二,況且這個函式的回傳值為void,我們也不能將陣列二回傳,所有這個思路我們有這個想法就好了,這是解決的一種方法,但是不能過而已,
下面看解法3,這個是最優的解法
解法3:三步翻轉法
1、將前n-k個數逆置
2、后k個數逆置
3、整體逆置
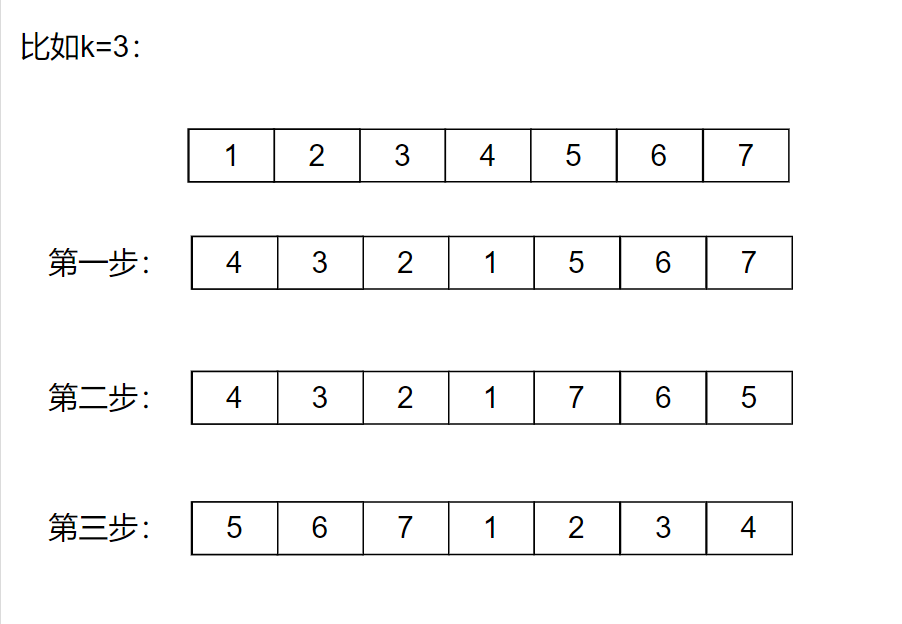
void reverse(int *nums,int begin,int end)
{
while(begin<end)
{
int temp=nums[begin];
nums[begin]=nums[end];
nums[end]=temp;
begin++;
end--;
}
}
void rotate(int *nums,int numssize,int k)
{
k%=numssize;
reverse(nums,0,numssize-k-1);
//將前n-k個數逆置
reverse(nums,numssize-k,numssize-1);
//后k個數逆置
reverse(nums,0,numssize-1);
//整體逆置
}
這個解法的時間復雜度:O(N),空間復雜度:O(1),都是最優的,建議大家寫第三個解法,代碼也不難,只需寫一個逆置的函式,只需要注意逆置傳參時對于前n-k個和后k個的引數的把握要明確,
下面我們來看順序表陣列中的一些OJ題:
陣列的相關OJ題
1.移除元素
題目描述:
給你一個陣列 nums 和一個值 val,你需要 原地 移除所有數值等于 val 的元素,并回傳移除后陣列的新長度,
不要使用額外的陣列空間,你必須僅使用 O(1) 額外空間并 原地 修改輸入陣列,
元素的順序可以改變,你不需要考慮陣列中超出新長度后面的元素,
題目來源:移除元素
原地移除陣列中所有的元素val,要求時間復雜度為O(N),空間復雜度為O(1)
思路1:
遍歷陣列,遇到val值,將后面資料挪動一個單位洗掉
時間復雜度:O(N^2)
空間復雜度:O(1)
int removeElement(int* nums, int numsSize, int val)
{
int i = 0;
int temp = numsSize;
//1234546
for (i = 0; i < numsSize; i++)
{
if (nums[i] == val)
{
int begin = i;
while (begin<numsSize-1)
{
nums[begin] = nums[begin + 1];
begin++;
}
temp--;//陣列當前元素個數
i--;
numsSize--;
}
}
return temp;
}
//測驗代碼
int main()
{
int nums[]={1,2,3,4,5,4,6};
int numsSize=sizeof(nums)/sizeof(nums[0]);
int ret = removeElement(nums,numsSize,4);
for(int i=0;i<ret;i++)
{
printf("%d ",nums[i]);
}
return 0;
}
在每次挪動資料后我們需要將i–,因為此時下標的i值為val的下標,val后面的元素前移了,此時的i下標對應的是val的下一個元素,故應該讓i保持不變繼續遍歷,同時遍歷的次數也應該少,防止越界,我們也要讓numsSize–,temp來記錄元素個數,
思路2:
空間換時間:把原陣列中不是3的所有值,拷貝到新陣列,再拷貝回來,時間復雜度O(N),空間復雜度O(N),只不過這里不滿足題的要求,因為題目空間復雜度要求O(N)
我們這里能知道這個思路就可以了,這個思路是不能解這道題的,因為題目空間復雜度要求O(N),思路2測驗代碼如下:
int removeElement(int* nums1, int* nums2, int numsSize, int val)
{
int i = 0;
int temp = 0;
for (i = 0; i < numsSize; i++)
{
if (nums1[i] != val)
{
nums2[i] = nums1[i];
temp++;
}
else
{
nums2--;
}
}
return temp;
}
int main()
{
int nums1[] = { 1,2,3,4,5,4,6 };
int nums2[8] = {0};//1,2,3,5,6
int numsSize = sizeof(nums1) / sizeof(nums1[0]);
int ret = removeElement(nums1, nums2, numsSize, 4);
for (int i = 0; i < ret; i++)
{
printf("%d ", nums2[i]);
}
return 0;
}
下面給出最優的思路:
思路3:
給兩個指標dest,src,指向起始位置,src找不是val的,放到dest指向的位置,時間復雜度:O(N),空間復雜度:O(1)
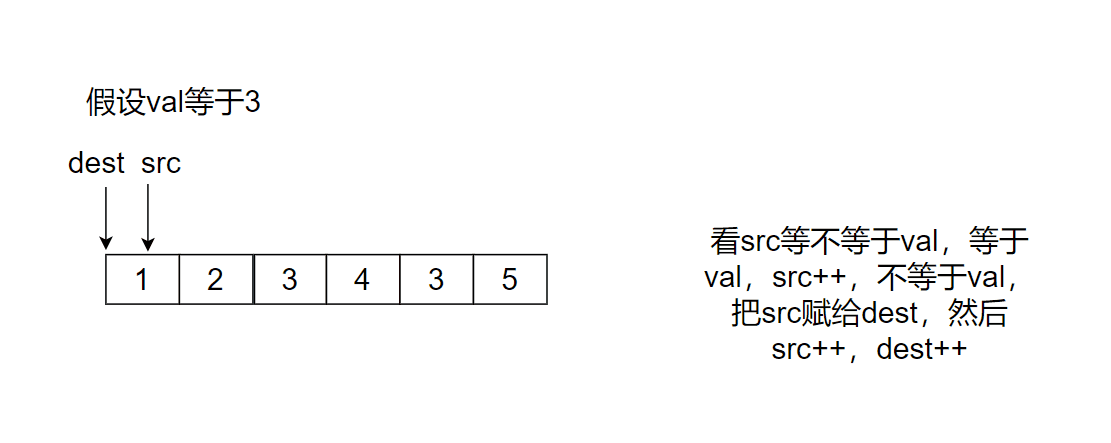
src指向陣列外時停止,然后回傳dest,恰好就是洗掉val值后的陣列
代碼如下:
int removeElement(int *nums,int numsSize)
{
int src=0,dest=0;
while(src<numssize)
{
if(nums[src]==val)
{
src++;
}
else
{
nums[dest]=nums[src];
src++;
dest++;
}
}
return dest;
}
2.洗掉有序陣列中的重復值
題目描述:
給你一個有序陣列 nums ,請你 原地 洗掉重復出現的元素,使每個元素 只出現一次 ,回傳洗掉后陣列的新長度,
不要使用額外的陣列空間,你必須在 原地 修改輸入陣列 并在使用 O(1) 額外空間的條件下完成,
示例 1:
輸入:nums = [1,1,2]
輸出:2, nums = [1,2]
解釋:函式應該回傳新的長度 2 ,并且原陣列 nums 的前兩個元素被修改為 1, 2 ,不需要考慮陣列中超出新長度后面的元素,示例 2:
輸入:nums = [0,0,1,1,1,2,2,3,3,4]
輸出:5, nums = [0,1,2,3,4]
解釋:函式應該回傳新的長度 5 , 并且原陣列 nums 的前五個元素被修改為 0, 1, 2, 3, 4 ,不需要考慮陣列中超出新長度后面的元素,
題目來源:洗掉有序陣列中的重復值
思路:
src找跟dest不相等的值,沒找到src++,找到了,dest++,把src放入dest然后src++
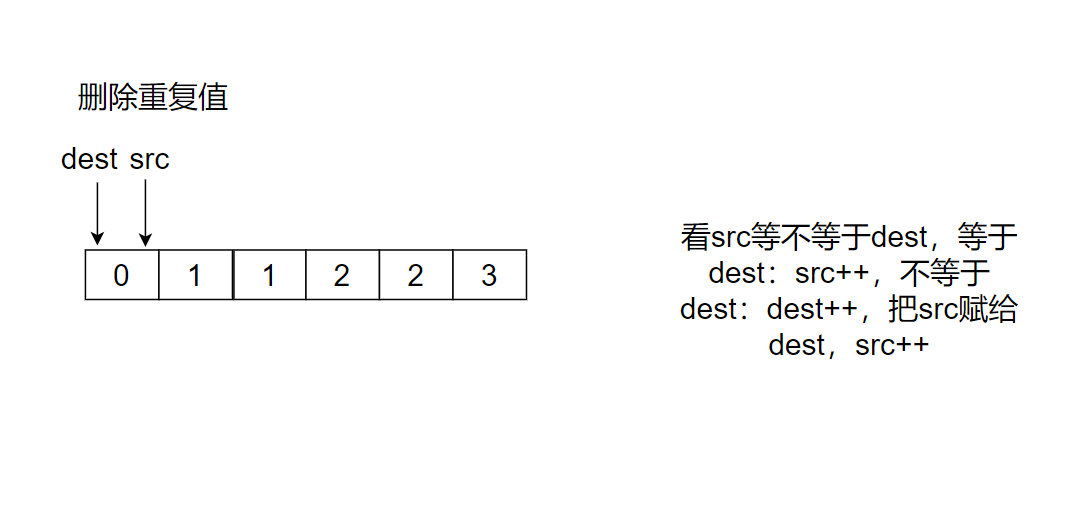
代碼如下:
int removeDuplicates(int* nums, int numsSize){
int src=0;
int dest=0;
if(numsSize==0)
{
return 0;
}
while(src<numsSize)
{
if(nums[src]==nums[dest])
{
src++;
}
else
{
dest++;
nums[dest]=nums[src];
src++;
}
}
return dest+1;//回傳陣列的長度
}
3.合并兩個有序陣列
題目描述:
給你兩個有序整數陣列 nums1 和 nums2,請你將 nums2 合并到 nums1 中,使 nums1 成為一個有序陣列,初始化 nums1 和 nums2 的元素數量分別為 m 和 n ,你可以假設 nums1 的空間大小等于 m + n,這樣它就有足夠的空間保存來自 nums2 的元素,
示例 1:
輸入:nums1 = [1,2,3,0,0,0], m = 3, nums2 = [2,5,6], n = 3
輸出:[1,2,2,3,5,6]
示例 2:輸入:nums1 = [1], m = 1, nums2 = [], n = 0
輸出:[1]
題目來源:合并兩個陣列
思路:
解法1:將nums2資料拷貝到nums1,qsort快排nums1,時間復雜度為(m+n)*log(m+n)
解法2:開辟一個m+n新陣列,歸并兩個小陣列,從頭比較兩個陣列的值,把小的放到新陣列,再拷貝到nums1,時間復雜度O(M+N),空間復雜度O(m+n)
解法3:依次比較取大的從后往前放到nums1里面
這里我們講解解法3:
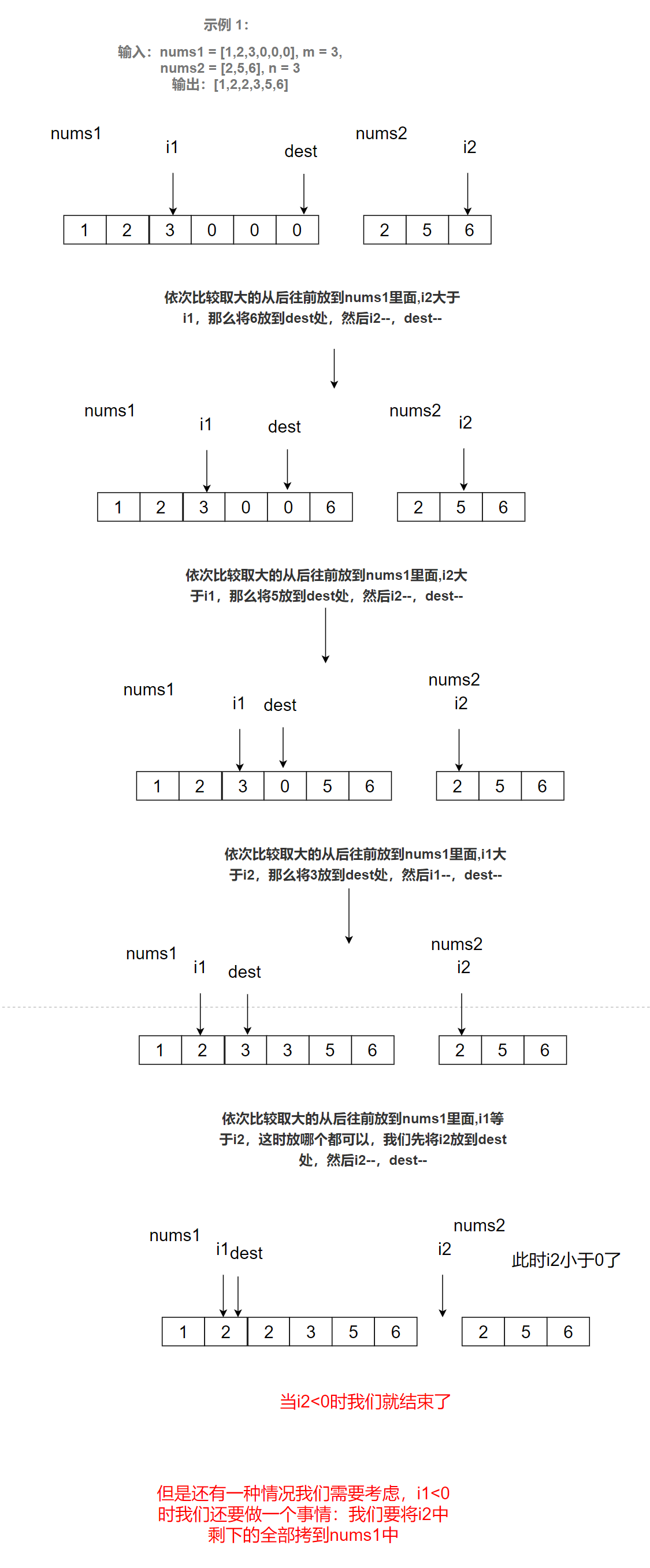
經過上圖分析,代碼如下:
void merge(int* nums1, int nums1Size, int m, int* nums2, int nums2Size, int n){
int i1 = m-1,i2 = n-1;
int dest=m+n-1;
while(i1>=0 && i2>=0)//兩個都大于等于0時繼續
{
if(nums1[i1]>nums2[i2])//取大的放入nums1的后面
{
nums1[dest--]=nums1[i1--];
}
else
{
nums1[dest--]=nums2[i2--];
}
}
//如果是i2<0,nums2拷貝結束,那就處理結束了,因為剩下的數本來就在nums1里面
//如果是nums1結束,得把nums2的資料挪過去
while(i2>=0)
{
nums1[dest--]=nums2[i2--];
}
}
需要注意的是:
如果是i2<0,nums2拷貝結束,那就處理結束了,因為剩下的數本來就在nums1里面
如果是nums1結束,得把nums2的資料挪過去
我們OJ報錯如何分析OJ程式?
-
如果沒過,先習慣用它報錯給的測驗用例去走讀代碼
-
代碼拷貝到vs上,補齊其他代碼,用沒過的測驗去測驗
鏈表OJ題
1.移除鏈表元素
題目描述:
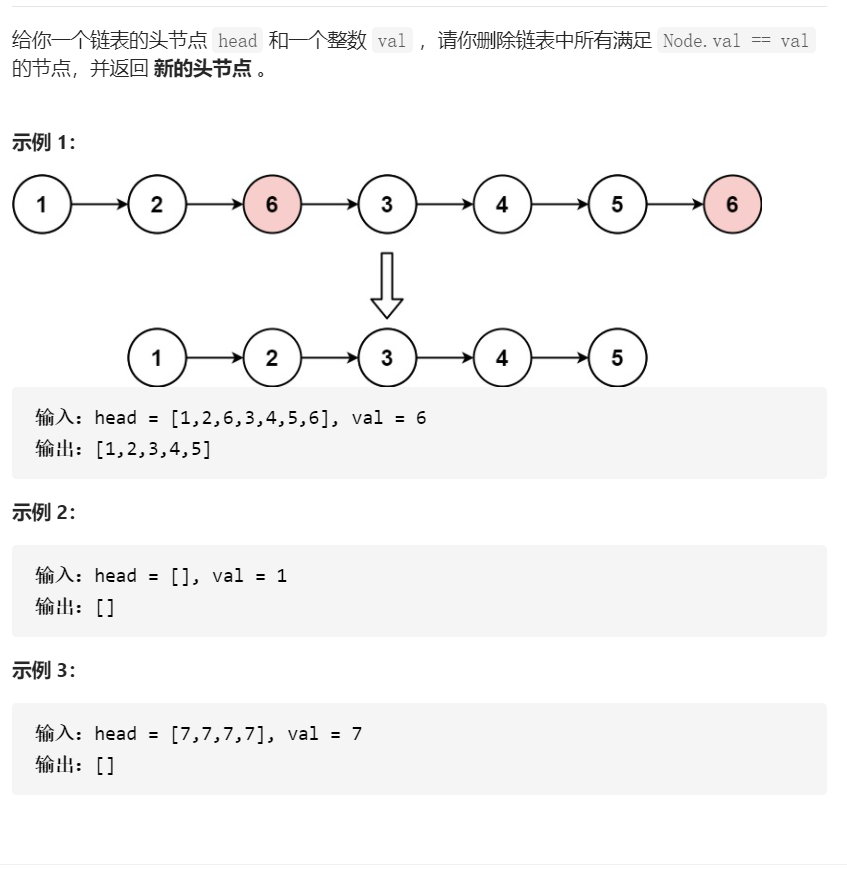
題目來源:移除鏈表元素
思路一:把鏈表中所有不是val的值尾插到新鏈表中,洗掉等于val的結點
思路決議:
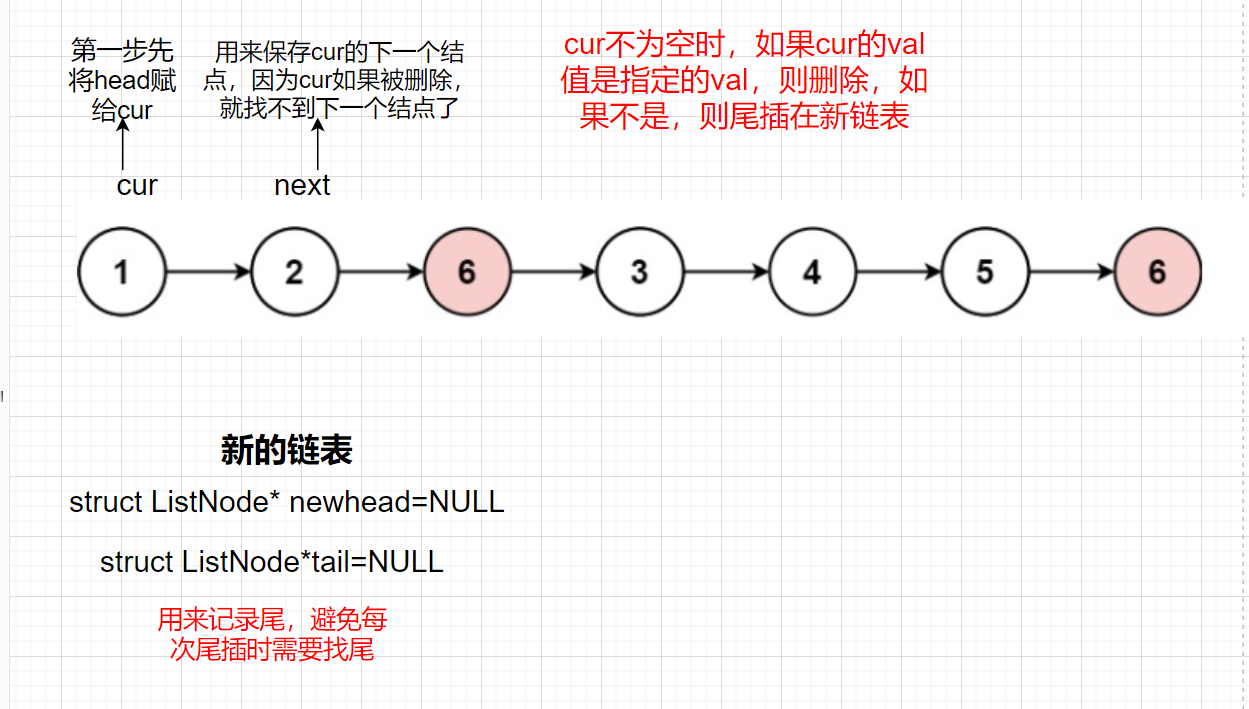
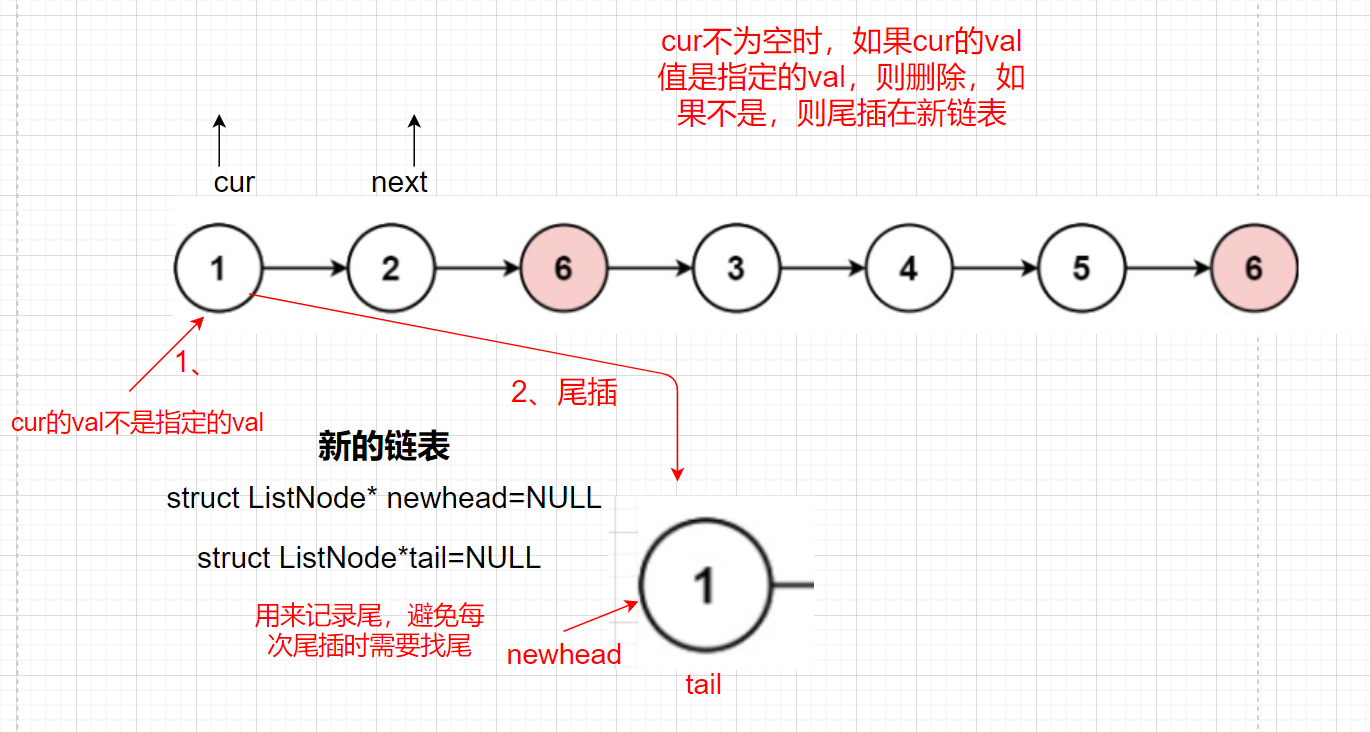
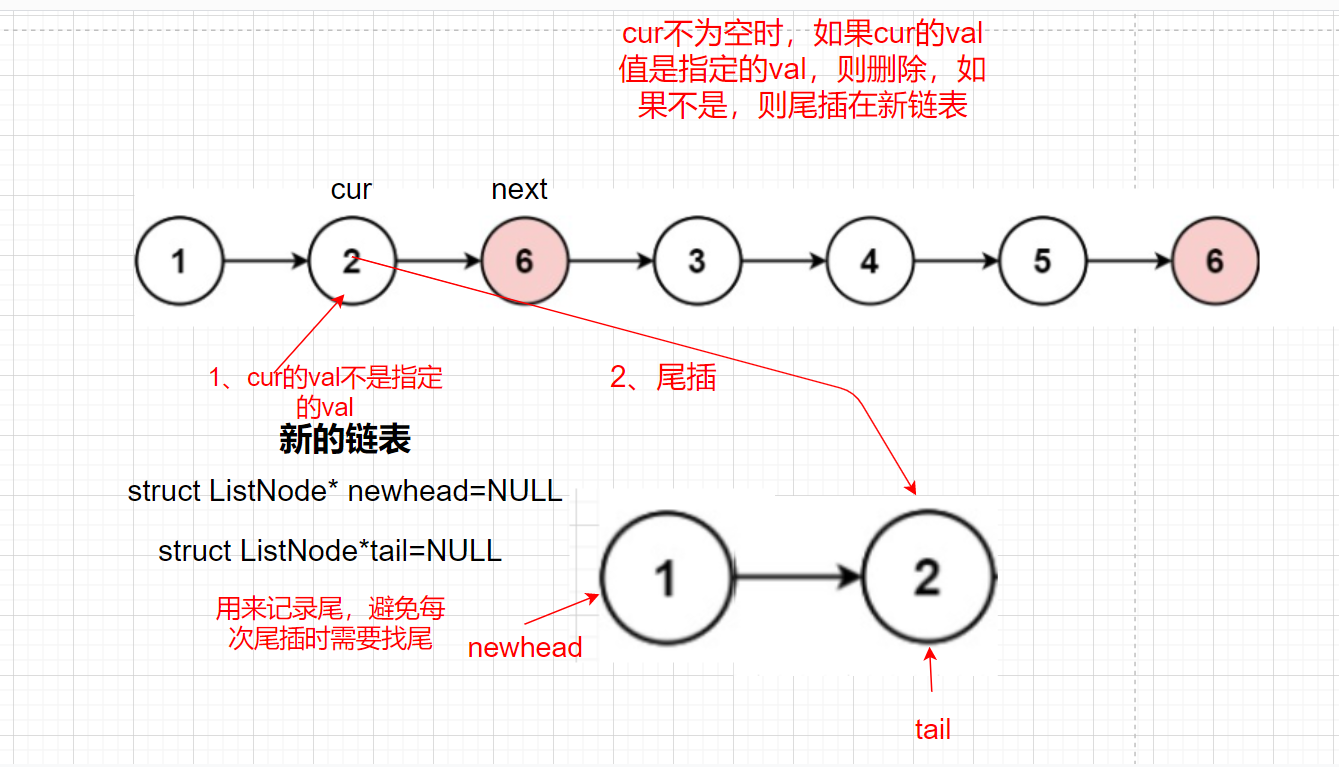
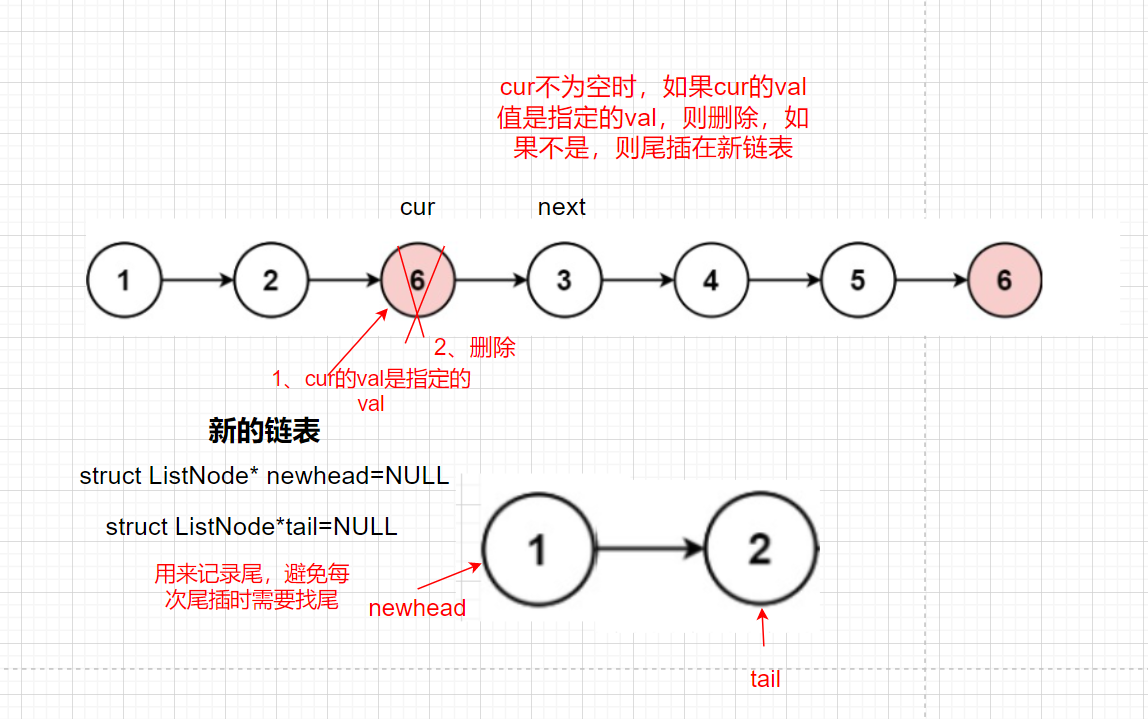
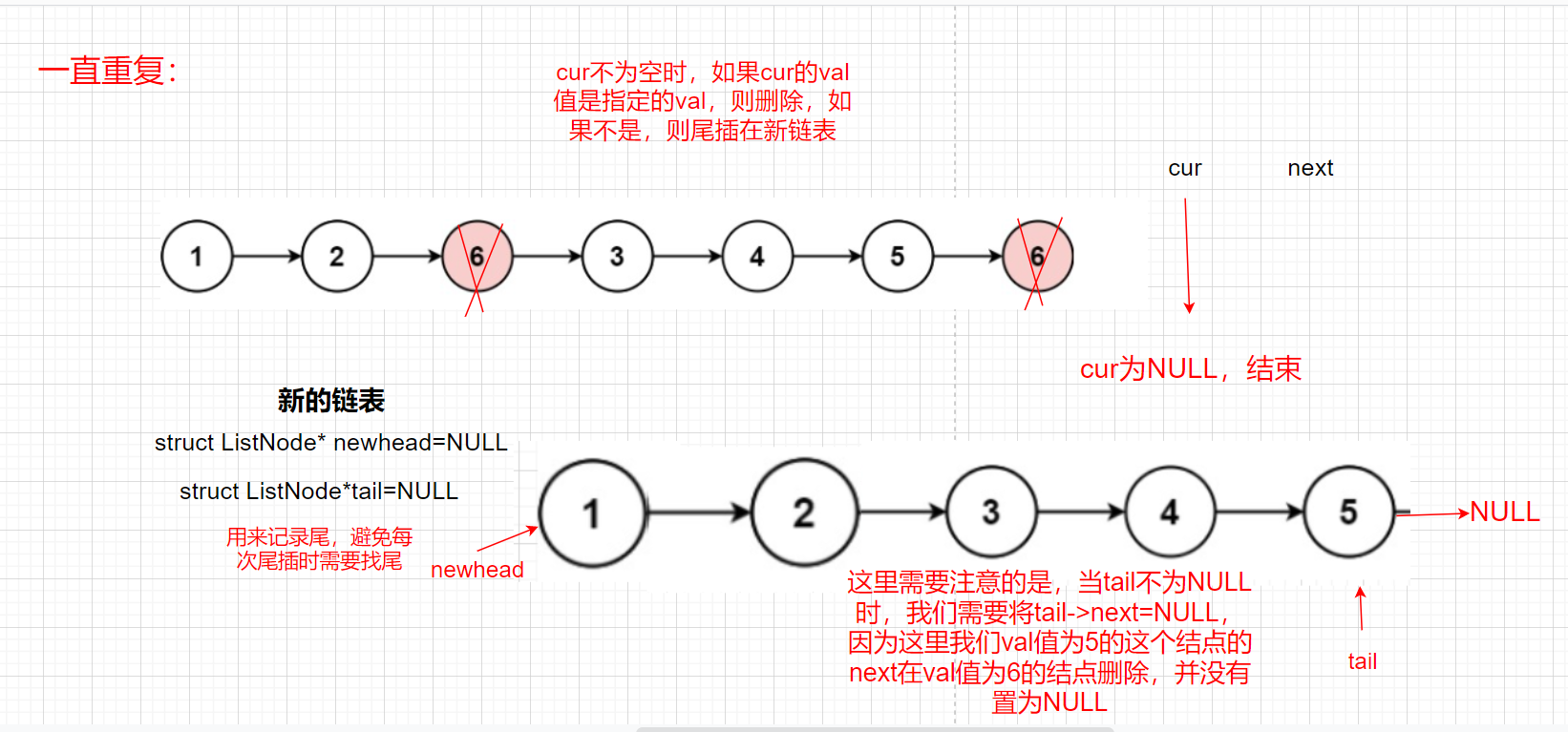
此外我們需要考慮傳進來的head為NULL的情況,如果head為NULL,我們直接回傳NULL
思路一代碼如下:
struct ListNode* removeElements(struct ListNode* head, int val)
{
if(head==NULL)
{
return NULL;
}
struct ListNode*newhead=NULL,*tail=NULL;//新鏈表的頭節點和記錄尾結點
//是val洗掉,不是val尾插到新鏈表
struct ListNode*cur=head;
while(cur)
{
struct ListNode* next=cur->next;//便于找到當前結點的下一個結點,定義一個next
if(cur->val==val)//是val洗掉
{
free(cur);
}
else//不是val進行尾插
{
//tail是NULL時,說明沒有元素
if(tail==NULL)//尾插第一個元素
{
newhead=cur;
tail=cur;
}
else
{
tail->next=cur;
tail=cur;
}
}
cur=next;
}
//當鏈表的最后一個結點的data是val時,前一個結點不是val時,我們將前一個結點尾插到新鏈表,將最后一個結點洗掉時,然而我們并沒有將前一個結點的next置為NULL,所以這里要將其置空;并且我們這里需要判斷tail是不是NULL,不是NULL我們才能進行此操作,當鏈表的val值都是指定洗掉的val值時,此時沒有尾插進新鏈表元素,此時tail為NULL,就不能將tail的next置為NULL了
if(tail)
{
tail->next=NULL;
}
return newhead;
}
需要注意的是:
當鏈表的最后一個結點的data是val時,前一個結點不是val時,我們將前一個結點尾插到新鏈表,將最后一個結點洗掉時,然而我們并沒有將前一個結點的next置為NULL,所以這里要將其置空;并且我們這里需要判斷tail是不是NULL,不是NULL我們才能進行此操作,當鏈表的val值都是指定洗掉的val值時,此時沒有尾插進新鏈表元素,此時tail為NULL,就不能將tail的next置為NULL了
思路二:cur找到val所在結點,prev記錄前一個結點,進行鏈表的洗掉操作,鏈表的洗掉操作需要找到洗掉的結點的前一個結點
struct ListNode* removeElements(struct ListNode* head, int val)
{
if (head == NULL)
{
return NULL;
}
struct ListNode* cur = head;
struct ListNode* prev = head;
while (cur)
{
while ( cur && (cur->val) != val )
{
prev = cur;//記錄當前結點的前一個結點
cur = cur->next;
}
//while出來有兩種情況1、cur為NULL,說明走到結束了,2、(cur->val) == val,此時要洗掉
if(cur==NULL)
{
return head;
}
//找到val、洗掉
if (cur == head)//如果第一個就為val值,頭刪
{
struct ListNode* newhead = cur->next;
free(cur);
cur = newhead;
head = newhead;
}
else//后面的洗掉
{
prev->next = cur->next;
free(cur);
cur = prev->next;
}
}
return head;
}
定義一個cur和prev來進行遍歷,prev記錄cur的前一個結點,cur不為空進回圈,然后再用一個回圈來找是val值的結點,while出來有兩種情況:1、cur為NULL,說明走到結束了,2、(cur->val) == val,此時要洗掉;所以接下來需要判斷cur是不是NULL,是NULL則直接回傳head,否則進行結點的洗掉,洗掉又要分頭刪和不是頭刪的情況,
2.反轉鏈表
題目描述:
給你單鏈表的頭節點
head,請你反轉鏈表,并回傳反轉后的鏈表,
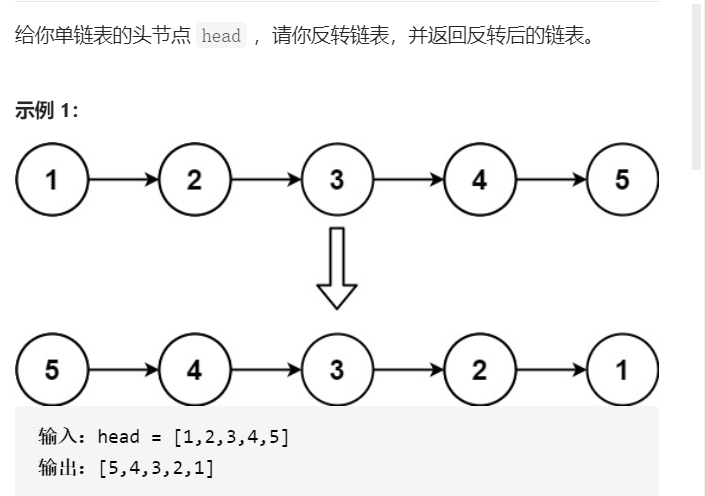
題目來源:反轉鏈表
思路一:
調整結點指標的方向,n1和n2倒方向,n3進行迭代
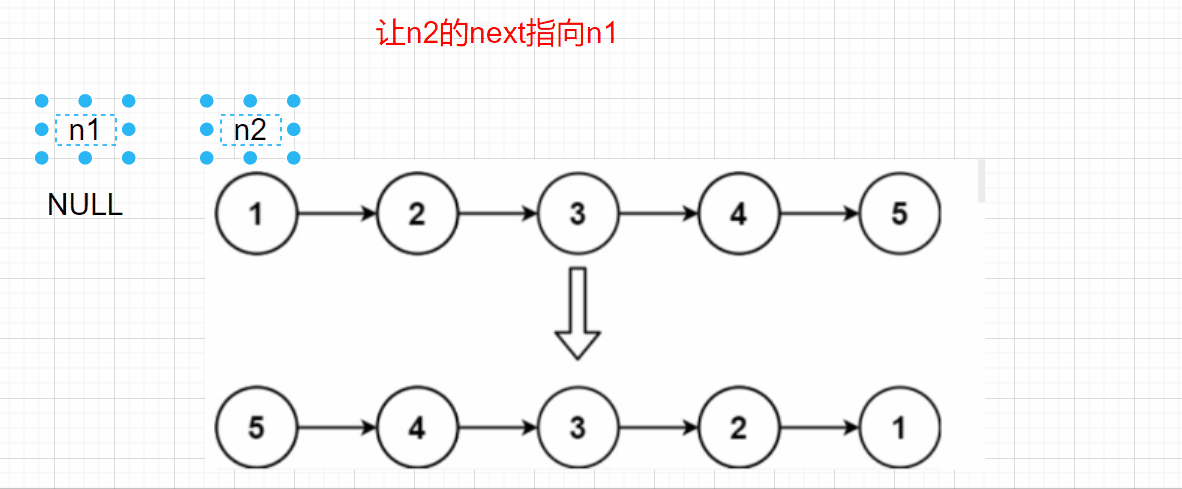
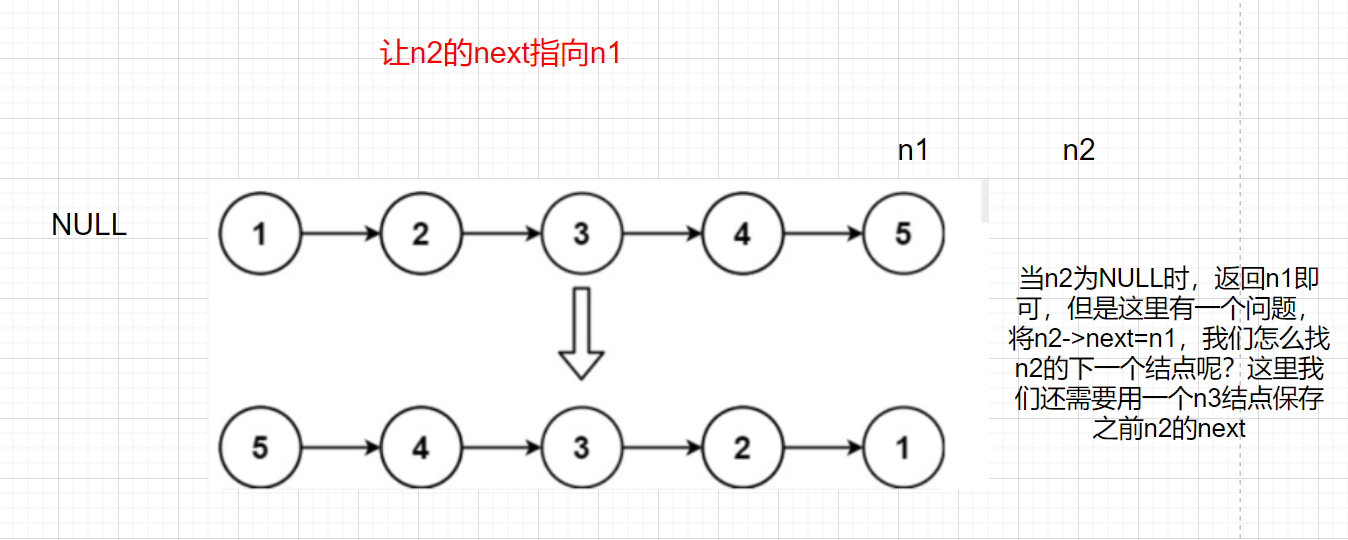
當n2為NULL時,回傳n1即可,但是這里有一個問題,將n2->next=n1,我們怎么找n2的下一個結點呢?這里我們還需要用一個n3結點保存之前n2的next
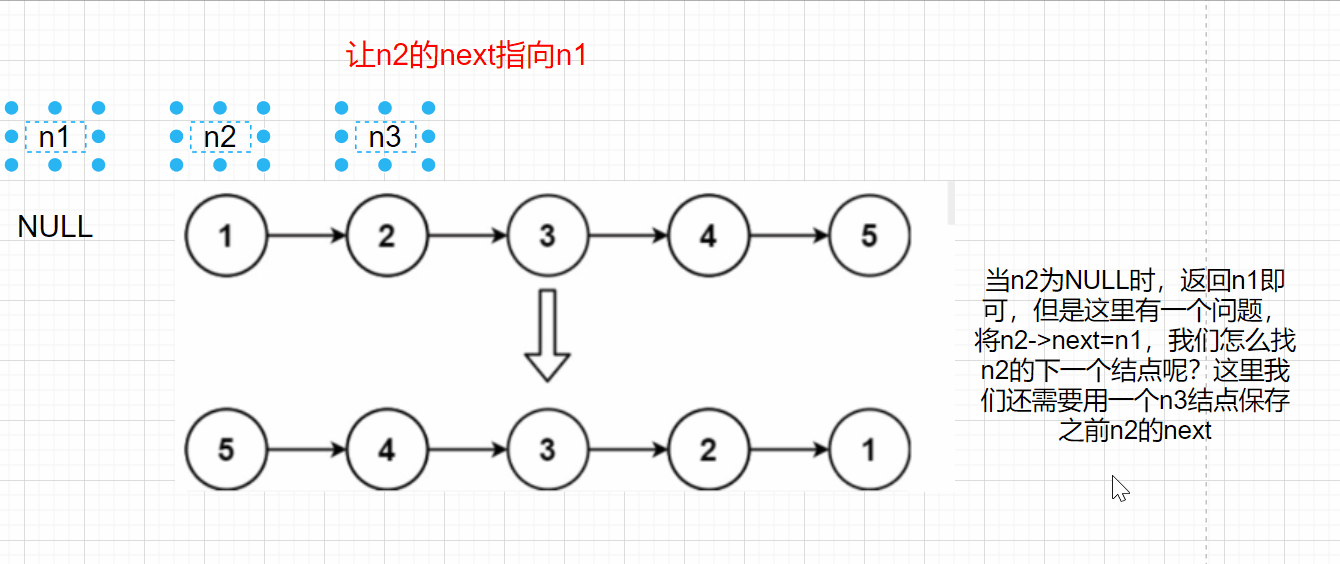
struct ListNode* reverseList(struct ListNode* head)
{
if(head==NULL)
{
return NULL;
}
struct ListNode* n1,*n2,*n3;
n1=NULL;
n2=head;
n3=head->next;
while(n2)
{
n2->next=n1;
n1=n2;
n2=n3;
if(n3)//當n3為NULL時,n3就沒有next了
{
n3=n3->next;
}
}
return n1;
}
思路二:
頭插法,定義一個新鏈表,newhead=NULL,原鏈表定義cur和next,next記錄cur的下一個結點
struct ListNode* reverseList(struct ListNode* head)
{
if(head==NULL)
{
return NULL;
}
struct ListNode* cur=head;
struct ListNode* newhead=NULL;
struct ListNode* next=cur->next;
while(cur)
{
next=cur->next;
cur->next=newhead;
newhead=cur;
cur=next;
}
return newhead;
}
3.查找一個鏈表的中間結點
題目描述:
給定一個頭結點為 head 的非空單鏈表,回傳鏈表的中間結點,
如果有兩個中間結點,則回傳第二個中間結點,
示例 1:
輸入:[1,2,3,4,5]
輸出:此串列中的結點 3 (序列化形式:[3,4,5])
回傳的結點值為 3 ,
示例 2:輸入:[1,2,3,4,5,6]
輸出:此串列中的結點 4 (序列化形式:[4,5,6])
由于該串列有兩個中間結點,值分別為 3 和 4,我們回傳第二個結點,
題目來源:查找一個鏈表的中間結點
思路:
利用快慢指標
slow一次走1步
fast一次走2步
fast走到結尾時,slow就走到了中間結點
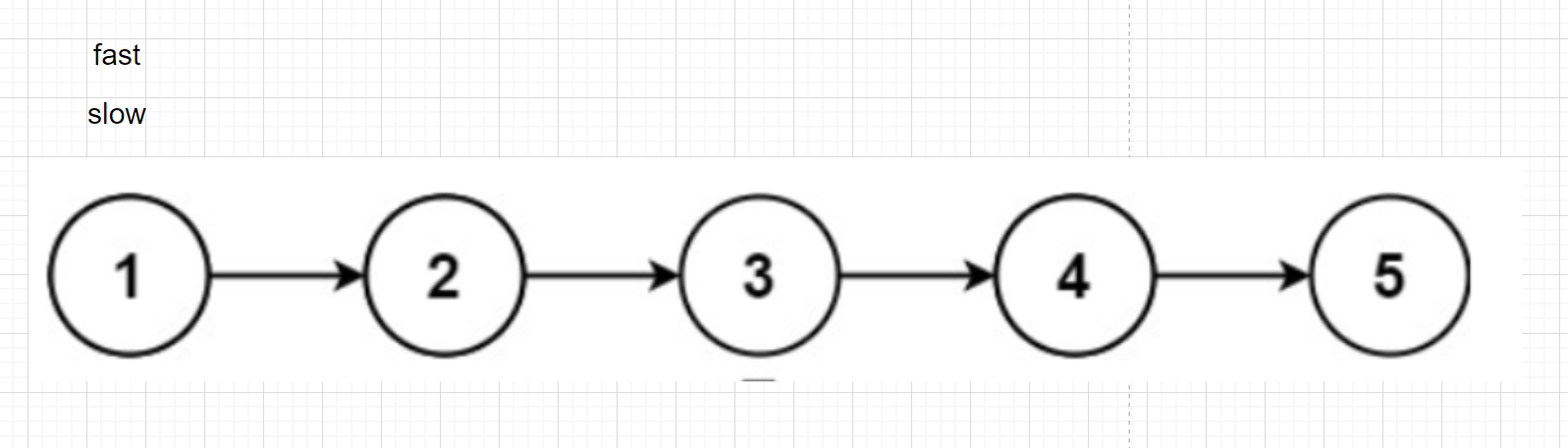
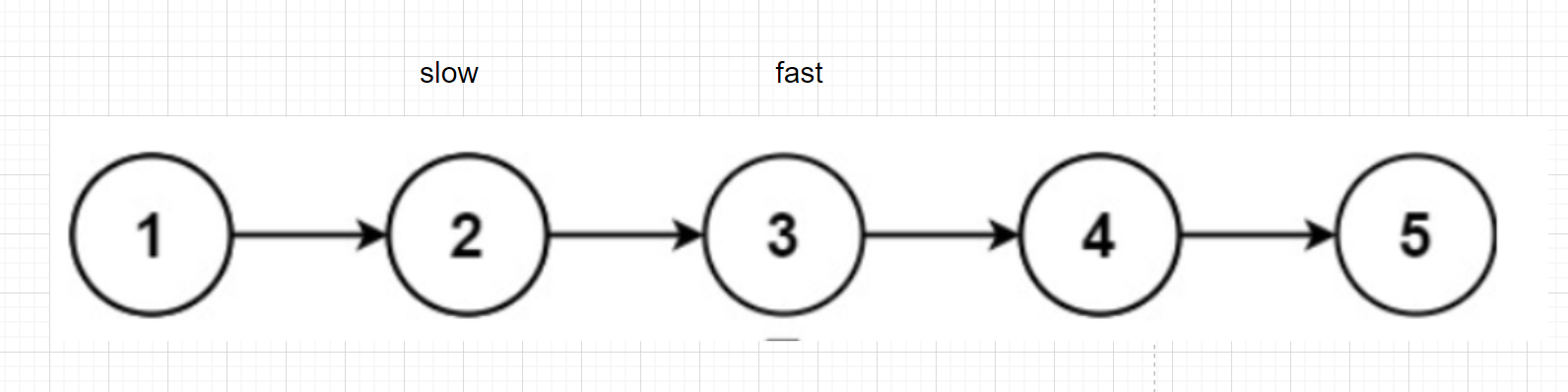
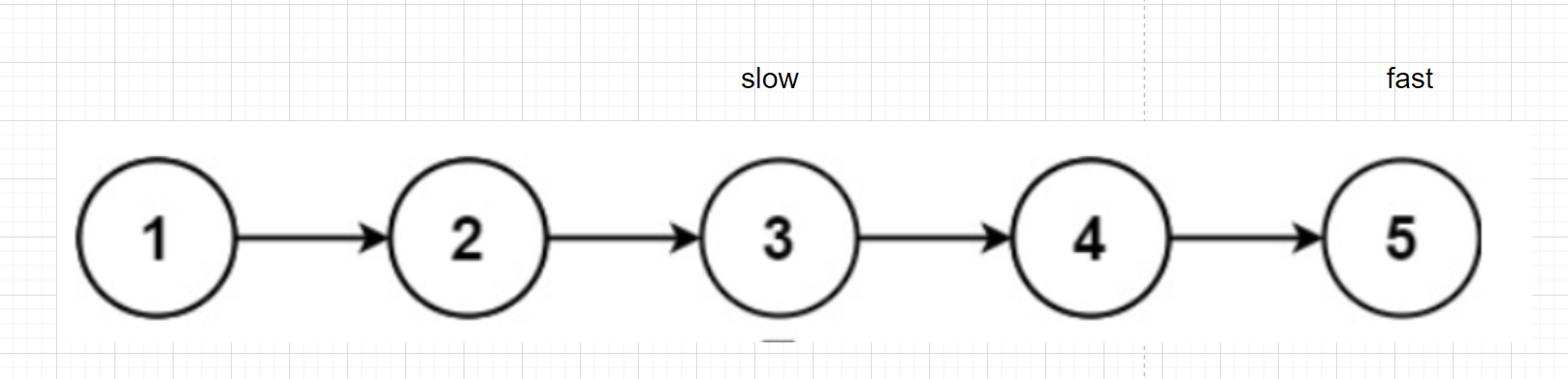
slow一次走1步,fast一次走2步,fast走到結尾時,slow就走到了中間結點
但是當時偶數個結點呢?題目的要求是回傳:如果有兩個中間結點,則回傳第二個中間結點,
經過畫圖理解,發現:

fast走到NULL時,slow到達第二個中間結點,
故回圈終止的條件應為fast不為NULL并且fast->next不為NULL
解題代碼如下:
struct ListNode* middleNode(struct ListNode* head)
{
if(head==NULL)
{
return NULL;
}
//快慢指標
struct ListNode* slow=head;
struct ListNode* fast=head;
while(fast&&fast->next!=NULL)
{
slow=slow->next;
fast=fast->next->next;
}
return slow;
}
4.鏈表中倒數第k個結點
題目描述:
輸入一個鏈表,輸出該鏈表中倒數第k個結點,
示例1
輸入:
1,{1,2,3,4,5}回傳值:
{5}
題目來源:查找一個鏈表的中間結點
思路:
和上面那個題一樣,我們先定義兩個指標slow,fast,fast先走k步,然后再一起走,我們看下面的動圖:
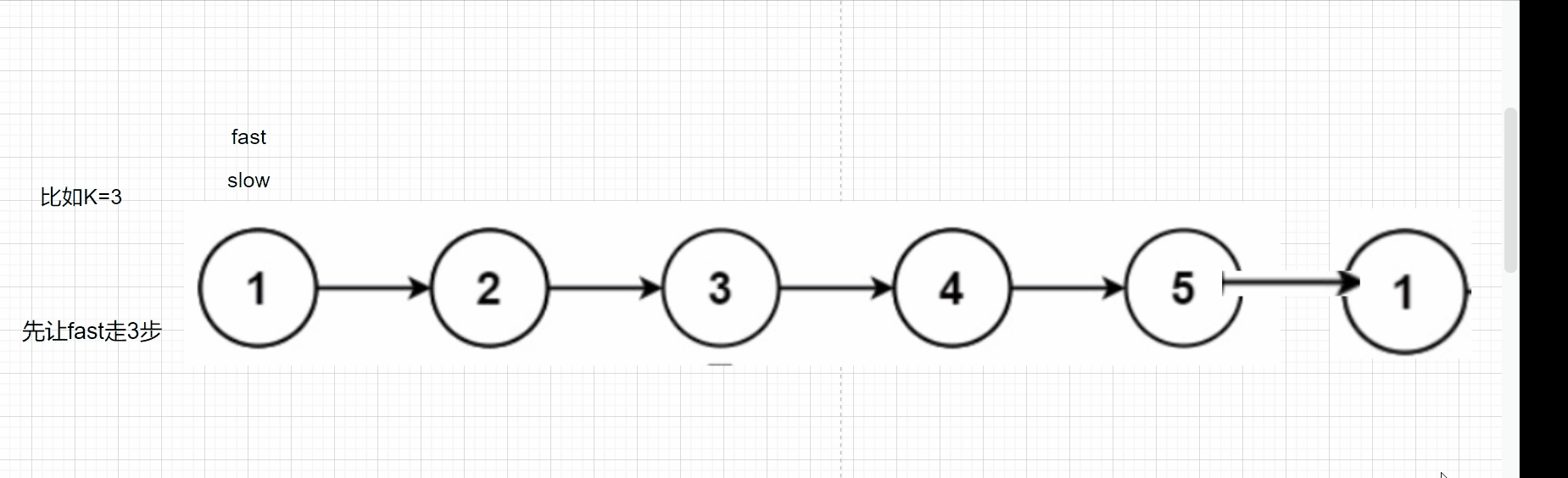
當fast為NULL時,此時的slow就為倒數第k個結點
需要注意的是:輸入的k如果大于結點的個數,fast還沒走完k步就變為NULL了,這里要特別回傳NULL
struct ListNode* FindKthToTail(struct ListNode* pListHead, int k )
{
if(k==0)
{
return NULL;
}
struct ListNode*slow,*fast;
slow=fast=pListHead;
//fast先走k步
while(k--)
{
if(fast==NULL)//輸入的k大于結點的個數,fast還沒走完k步就變為NULL了
{
return NULL;
}
fast=fast->next;
}
while(fast)
{
slow=slow->next;
fast=fast->next;
}
return slow;
}
fast先走k步時,要是輸入的k大于結點的個數,fast還沒走完k步就變為NULL了,這里要特別判斷一下fast是不是等于NULL,等于NULL直接回傳NULL,
5.合并兩個有序鏈表
題目描述:
將兩個升序鏈表合并為一個新的升序鏈表并回傳,新鏈表是通過拼接給定的兩個鏈表的所有節點組成的,
思路:取小的結點下來尾插到新鏈表
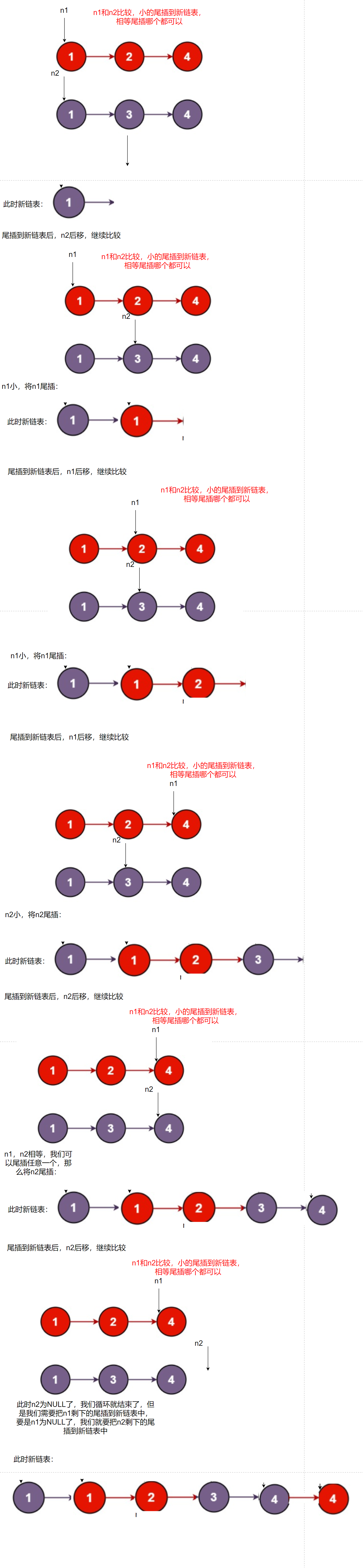
由思路分析,我們的代碼如下:
struct ListNode* mergeTwoLists(struct ListNode* l1, struct ListNode* l2)
{
//l1為NULL,則回傳l2
if(l1==NULL)
{
return l2;
}
//l2為NULL,則回傳l1
if(l2==NULL)
{
return l1;
}
struct ListNode*newhead=NULL;//新鏈表的頭節點
struct ListNode*tail=NULL;//記錄新鏈表的尾
struct ListNode* n1=l1;
struct ListNode* n2=l2;
while(n1&&n2)
{
//比較n1,n2的val,將小的尾插在新鏈表
if(n1->val<n2->val)
{
//新鏈表為NULL時,即沒有結點時
if(tail==NULL)
{
newhead=tail=n1;
}
//不為NULL時,有結點時
else
{
tail->next=n1;
tail=n1;
}
n1=n1->next;//此時已經將較小的尾插進新鏈表,這里進行迭代
}
else
{
if(tail==NULL)
{
newhead=tail=n2;
}
else
{
tail->next=n2;
tail=n2;
}
n2=n2->next;
}
//n1或者n2為NULL時結束
}
//將不為NULL的剩下的結點鏈接到新鏈表的尾
if(n1)
{
tail->next=n1;
}
if(n2)
{
tail->next=n2;
}
return newhead;
}
那么我們還能不能優化一下呢?
既然不管插n1還是n2我們第一次插進新鏈表時都要特殊處理,那么我們可以先在外面先給它插一個結點進去,這里就不用再回圈里面if和else里面都要考慮沒有結點時的尾插情況了,代碼如下:
struct ListNode* mergeTwoLists(struct ListNode* l1, struct ListNode* l2)
{
if(l1==NULL)
{
return l2;
}
if(l2==NULL)
{
return l1;
}
struct ListNode*newhead=NULL;
struct ListNode*tail=NULL;
struct ListNode* n1=l1;
struct ListNode* n2=l2;
if(n1->val<n2->val)
{
newhead=tail=n1;
n1=n1->next;
}
else
{
newhead=tail=n2;
n2=n2->next;
}
while(n1&&n2)
{
if(n1->val<n2->val)
{
//尾插n1
tail->next=n1;
tail=n1;
n1=n1->next;
}
else
{
//尾插n2
tail->next=n2;
tail=n2;
n2=n2->next;
}
}
if(n1)
{
tail->next=n1;
}
if(n2)
{
tail->next=n2;
}
return newhead;
}
還有一種方法不需要考慮尾插時新鏈表為NULL的情況,那就是我們設定一個帶哨兵位的頭結點,下面我們介紹一下:
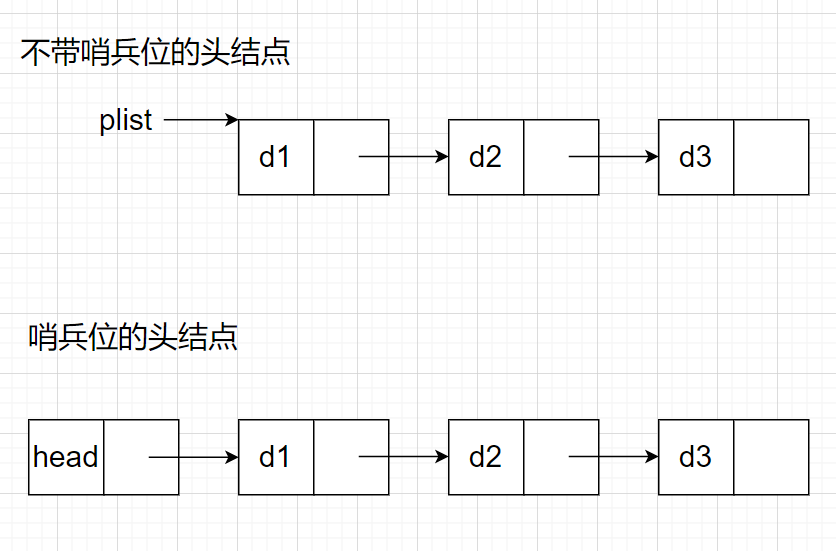
帶哨兵位的頭節點,這個結點不存盤有效資料,函式永遠不會修改到指向存盤有效資料的第一個結點的指標plist,因為擁有這個帶哨兵位的頭節點,對在第一元素結點前插入結點和洗掉第一結點時,其操作與其他結點的操作就統一了,
這個帶哨兵位的頭節點看起來簡單一點,為什么我們的單鏈表不設計這個結構呢?
這個頭節點的結構在實際中很少出現,包括哈希桶、鄰接表做子結構都是不帶頭,其次就是OJ中給的鏈表基本都是不帶頭的,
帶哨兵位的頭節點方法:
struct ListNode* mergeTwoLists(struct ListNode* l1, struct ListNode* l2)
{
if(l1==NULL)
{
return l2;
}
if(l2==NULL)
{
return l1;
}
struct ListNode*newhead=NULL;
struct ListNode*tail=NULL;
newhead=tail=(struct ListNode*)malloc(sizeof(struct ListNode));
while(l1&&l2)
{
if(l1->val<l2->val)
{
//尾插l1
tail->next=l1;
tail=l1;
l1=l1->next;
}
else
{
//尾插l2
tail->next=l2;
tail=l2;
l2=l2->next;
}
}
if(l1)
{
tail->next=l1;
}
if(l2)
{
tail->next=l2;
}
//return newhead->next;直接return這個會造成記憶體泄漏
struct ListNode* first = newhead->next;//將newhead的next先保存,然后將newhead free
free(newhead);
return first;
}
需要注意的是,我們最后要將這個開辟的帶哨兵位的頭結點需要釋放掉,否則會有記憶體泄漏,我們需要回傳newhead的next,那么我們先用first將newhead的next先保存,然后將newhead free掉
6.鏈表分割
題目描述:
現有一鏈表的頭指標 ListNode pHead,給一定值x,撰寫一段代碼將所有小于x的結點排在其余結點之前,且不能改變原來的資料順序,回傳重新排列后的鏈表的頭指標,*
思路:
1、把比x小的尾插入一個鏈表
2、把比x大的尾插入一個鏈表
3、再把兩個鏈表鏈接在一起
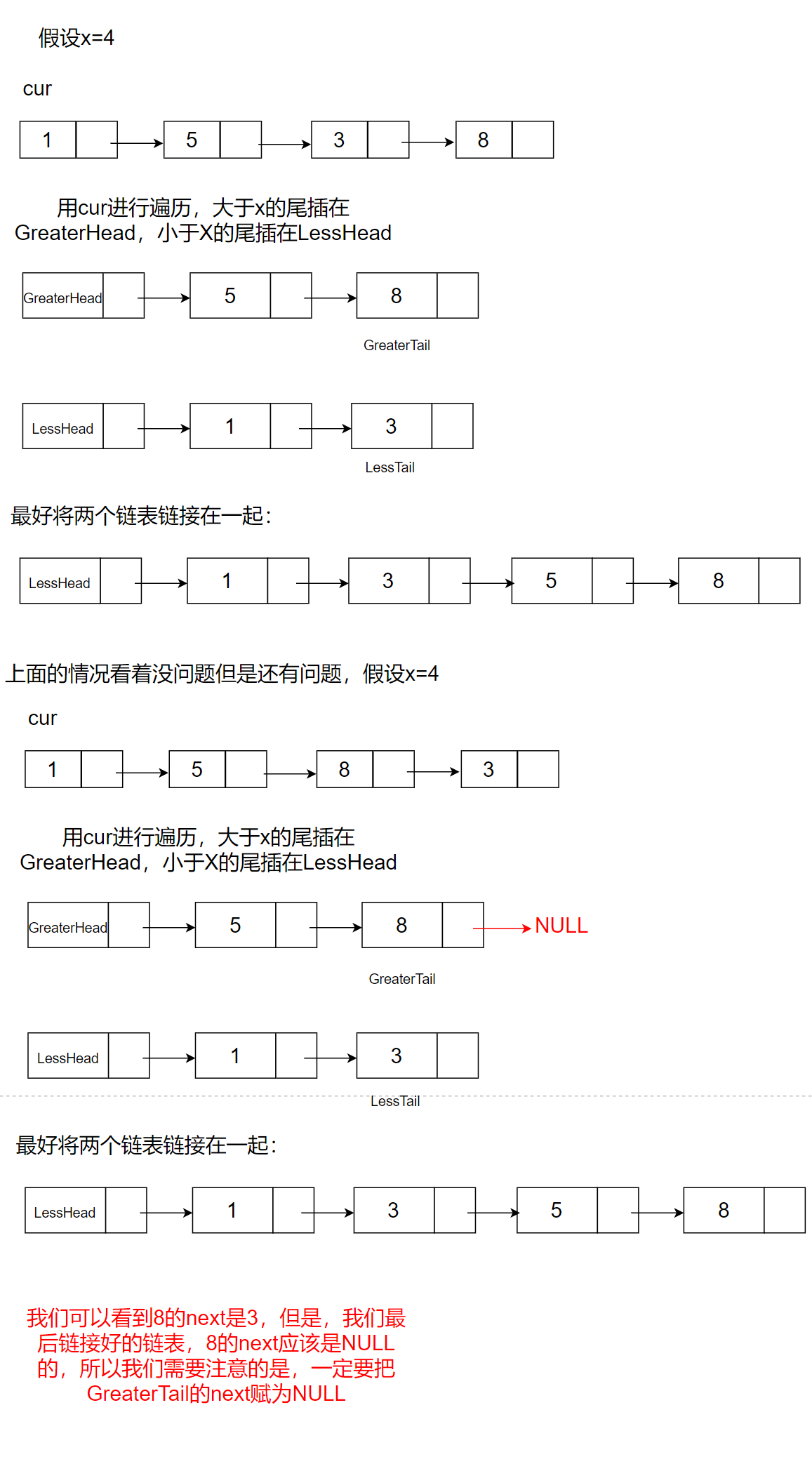
代碼如下:
ListNode* partition(ListNode* pHead, int x)
{
// write code here
struct ListNode* LessHead=(struct ListNode*)malloc(sizeof(struct ListNode));//較小值的帶哨兵位頭節點
struct ListNode* GreaterHead=(struct ListNode*)malloc(sizeof(struct ListNode));//較大值的帶哨兵位頭節點
struct ListNode* LessTail=LessHead;
struct ListNode* GreaterTail=GreaterHead;
struct ListNode* cur = pHead;
while(cur)
{
if(cur->val<x)
{
//尾插到存放較小值的鏈表
LessTail->next=cur;
LessTail=cur;
}
else
{
//尾插到存放較大值的鏈表
GreaterTail->next=cur;
GreaterTail=cur;
}
cur=cur->next;
}
LessTail->next=GreaterHead->next;//鏈接
GreaterTail->next=NULL;
struct ListNode* first=LessHead->next;
free(LessHead);
LessHead=NULL;
free(GreaterHead);
GreaterHead=NULL;
return first;
}
7.鏈表的回文結構
題目描述:
對于一個鏈表,請設計一個時間復雜度為O(n),額外空間復雜度為O(1)的演算法,判斷其是否為回文結構,
給定一個鏈表的頭指標A,請回傳一個bool值,代表其是否為回文結構,保證鏈表長度小于等于900,
測驗樣例:
1->2->2->1 回傳:true 1->2->3->2->1 回傳:true
題目來源:鏈表的回文結構
思路1:
定義一個陣列將鏈表中的val值都拷貝進去,然后通過下標去比較第一個和最后一個是不是相等
bool chkPalindrome(ListNode* A) {
// write code here
int a[900];
struct ListNode* cur=A;
int n=0;
while(cur)
{
a[n++]=cur->val;
cur=cur->next;
}
int left=0;
int right=n-1;
while(left<right)
{
if(a[left]!=a[right])
{
return false;
}
left++;
right--;
}
return true;
}
這種解法空間復雜度為O(n),空間復雜度不符合要求,但是牛客網給過了,有些OJ題目,有時間復雜度和空間復雜度的要求,但是后臺測驗用例的檢查對于時間復雜度和空間復雜度是不好檢查的,對于復雜度,OJ系統通常檢查的都不是很嚴格,這一塊leetcode會嚴格一些,牛客會更松散,包括測驗用例完整度,也是這樣的,
下面我們看一種正確的解法:
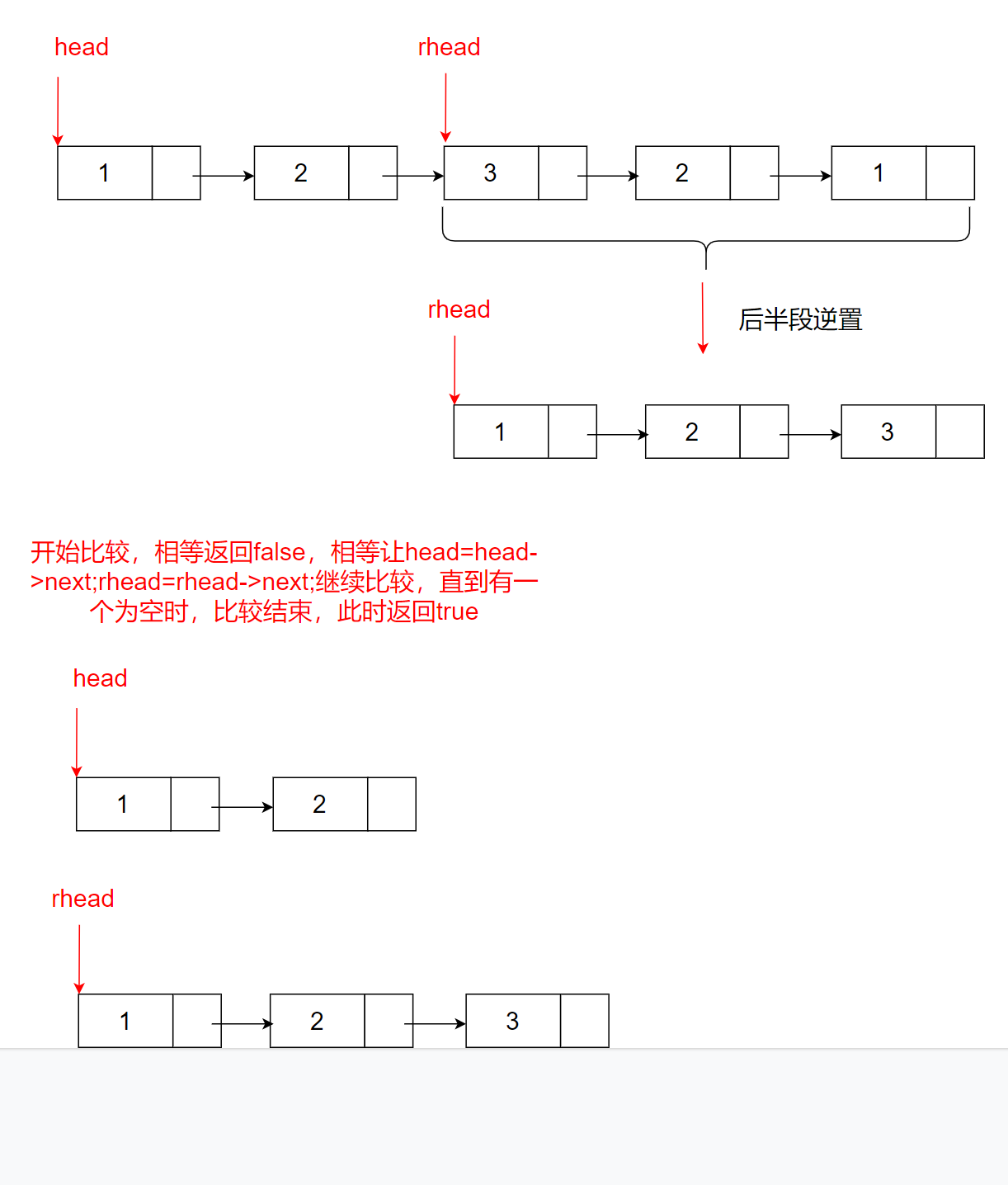
思路2:
1、先找到中間結點
2、將后半段逆置
3、比較前半段和后半段
找中間結點和逆置鏈表我們前面已經講過了,剩下的就是比較前半段和后半段了
代碼如下:
struct ListNode* FindMidNode(struct ListNode* phead)//找到中間結點
{
struct ListNode*slow,fast;
slow=fast=phead;
while(fast&&fast->next)
{
slow=slow->next;
fast=fast->next;
}
return slow;
}
//傳一級指標,用回傳值回傳頭指標
/*struct ListNode* reverseList(struct ListNode* phead)//逆置鏈表
{
struct ListNode*cur=phead;
struct ListNode*newhead=NULL;
while(cur)
{
struct ListNode*next=cur->next;
cur->next=newhead;
newhead=cur;
cur=next;
}
return newhead;
}*/
//傳二級指標,在函式里面修改頭指標
void reverseList(struct ListNode** pphead)
{
struct ListNode*cur=pphead;
struct ListNode*newhead=NULL;
while(cur)//頭插法逆置
{
struct ListNode*next=cur->next;
cur->next=newhead;
newhead=cur;
cur=next;
}
*pphead = newhead;
bool chkPalindrome(ListNode* A)
{
struct ListNode*mid = FindMidNode(A);
//struct ListNode*rHead = reverseList(mid);
struct ListNode*rhead=mid;
reverseList(&rhead);
struct ListNode*head=A;
while(rhead && head)
{
if(rhead->val!=head->val)
return false;
rhead=rhead->next;
head=head->next;
}
return true;
}
8.鏈表的相交
題目描述:
給你兩個單鏈表的頭節點 headA 和 headB ,請你找出并回傳兩個單鏈表相交的起始節點,如果兩個鏈表沒有交點,回傳 null ,
圖示兩個鏈表在節點 c1 開始相交:
題目資料 保證 整個鏈式結構中不存在環,
注意,函式回傳結果后,鏈表必須 保持其原始結構 ,
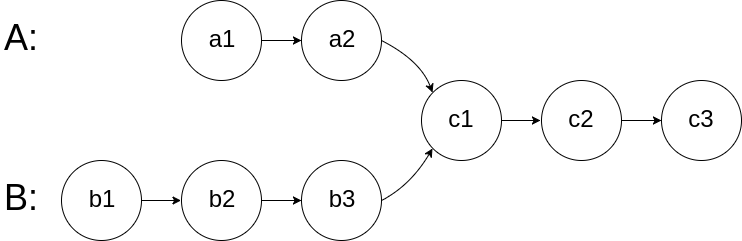
題目來源:鏈表的相交
如何判斷A、B鏈表是否相交?
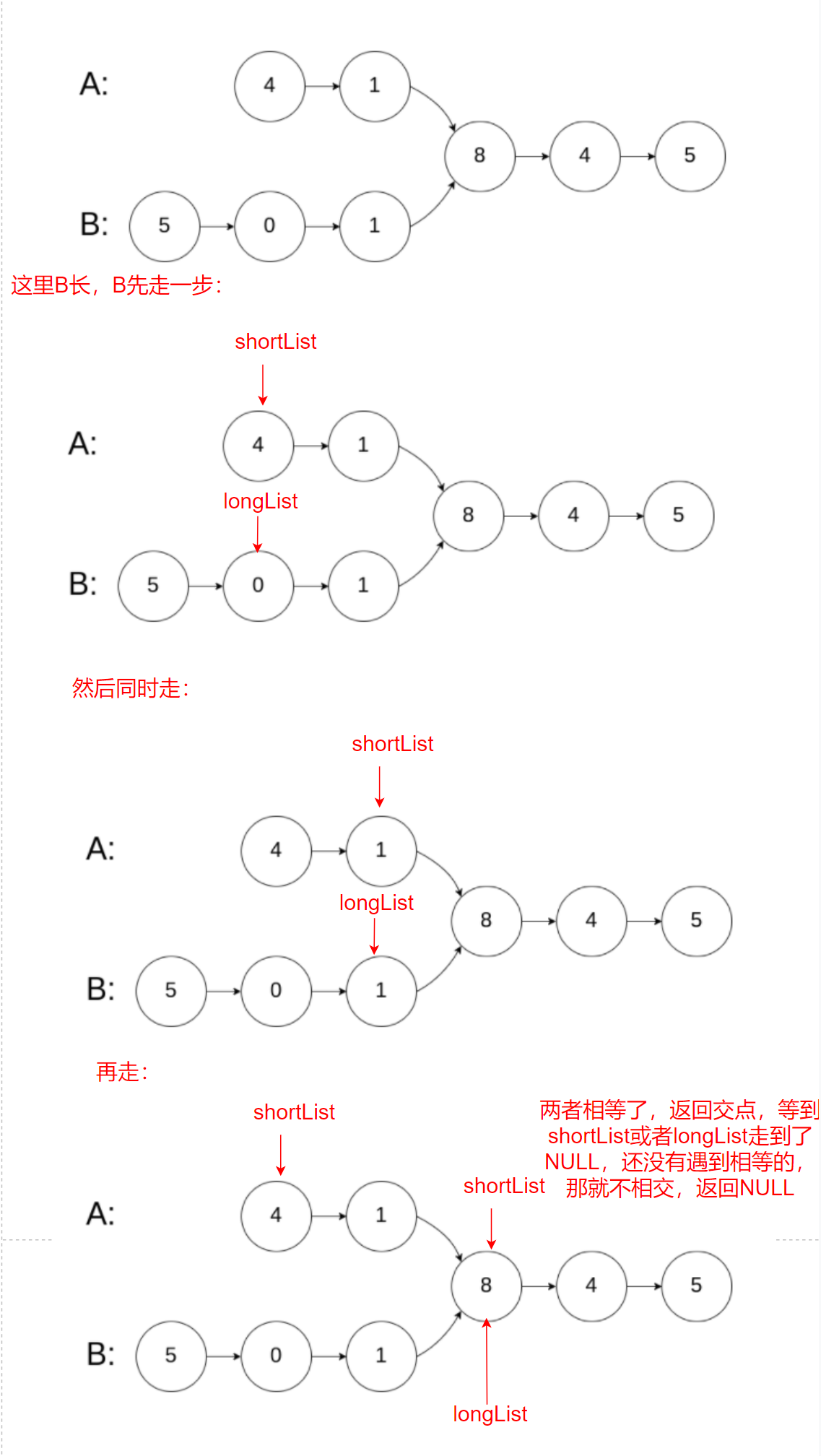
思路1:
常規思路:A鏈表的每個結點依次和b鏈表的所有結點比較,如果有相等,就是交點,時間復雜度O(N^2)
優化思路:分別算出A和B的長度,lenA和lenB,讓長的先走|lenA-lenB|步,再比較找交點,時間復雜度O(N)
思路2:判斷最后一個結點是否相同
題目要求我們回傳相交的結點,所以我們用思路1的優化思路來解這道題:
代碼如下:
struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB) {
struct ListNode *curA = headA;
struct ListNode *curB = headB;
int lenB=0;
int lenA=0;
while(curA)//計算A的長度
{
lenA++;
curA=curA->next;
}
while(curB)//計算B的長度
{
lenB++;
curB=curB->next;
}
//假設A長B短
struct ListNode *longList=headA;
struct ListNode *shortList=headB;
if(lenA<lenB)
{
longList=headB;
shortList=headA;
}
//讓長的先走差距步
int gap=abs(lenA-lenB);
while(gap--)
{
longList=longList->next;
}
//同時走,找交點
while(longList && shortList)
{
if(longList == shortList)
{
return longList;//找到了回傳
}
longList=longList->next;
shortList=shortList->next;
}
//表示不相交
return NULL;
}
首先我們計算出A、B鏈表的長度,然后我們先假設長的鏈表為A,短的是B,然后如果lenA<lenB的話,再將B賦給長鏈表,A賦給短鏈表,然后我們讓長的先走差距步,最后一起走然后找交點
9.環形鏈表
問題描述:
給定一個鏈表,判斷鏈表中是否有環,
如果鏈表中有某個節點,可以通過連續跟蹤 next 指標再次到達,則鏈表中存在環, 為了表示給定鏈表中的環,我們使用整數 pos 來表示鏈表尾連接到鏈表中的位置(索引從 0 開始), 如果 pos 是 -1,則在該鏈表中沒有環,注意:pos 不作為引數進行傳遞,僅僅是為了標識鏈表的實際情況,
如果鏈表中存在環,則回傳 true , 否則,回傳 false ,
進階:
你能用 O(1)(即,常量)記憶體解決此問題嗎?
示例 1:
輸入:head = [3,2,0,-4], pos = 1 輸出:true 解釋:鏈表中有一個環,其尾部連接到第二個節點,示例 2:
輸入:head = [1,2], pos = 0 輸出:true 解釋:鏈表中有一個環,其尾部連接到第一個節點,示例 3:
輸入:head = [1], pos = -1 輸出:false 解釋:鏈表中沒有環,
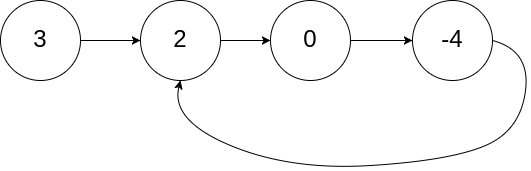
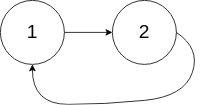

題目來源:環形鏈表
思路:
快慢指標,慢指標一次走一步,快指標一次走兩步,如果快指標能等于慢指標,則是環形鏈表,否則則不是
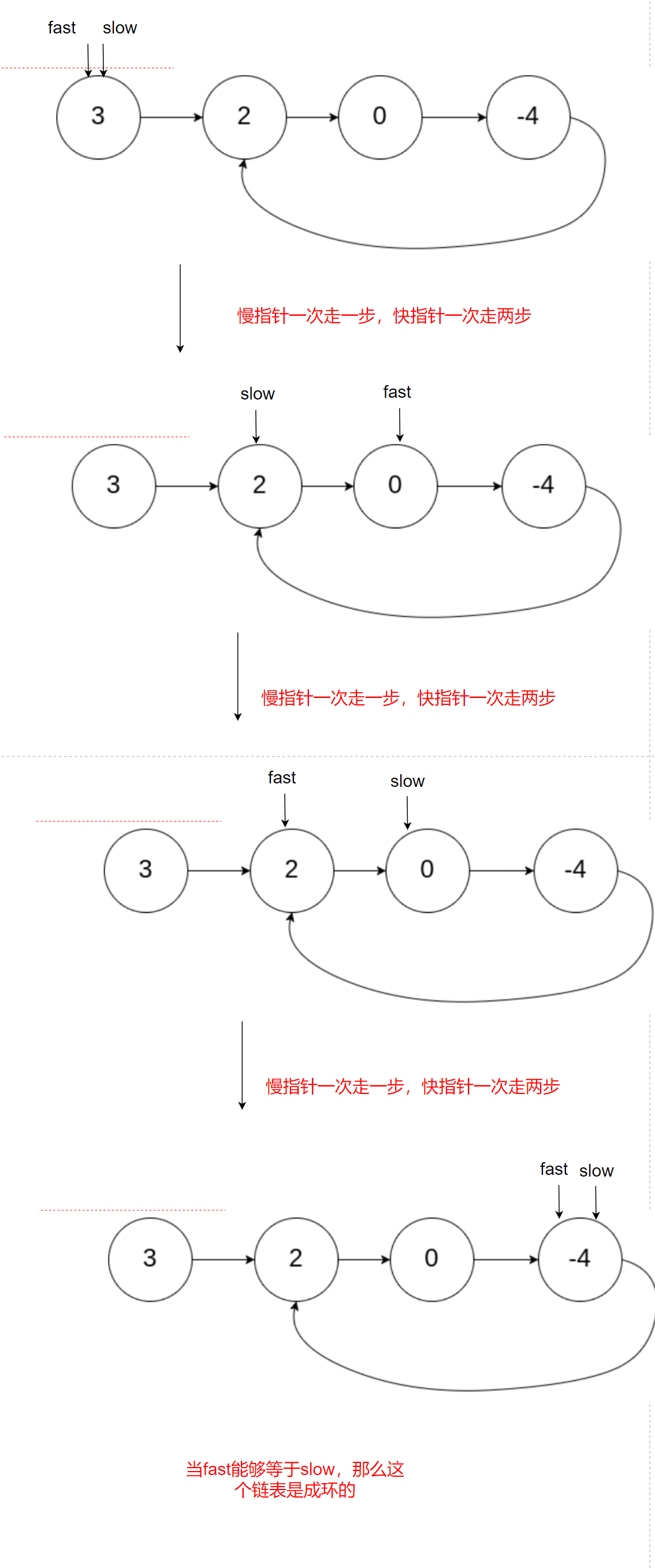
代碼如下:
bool hasCycle(struct ListNode *head) {
struct ListNode *slow,*fast;
slow=fast=head;
while(fast && fast->next)
{
slow=slow->next;
fast=fast->next->next;
if(slow==fast)
{
return true;
}
}
return false;
}
這道題代碼很簡單,但是考面試中考察這道題可能不止會讓你寫出代碼就完事了,面試官可能會問:
面試提問:
- slow一次走一步,fast一次走兩步?一定可以追上嗎?請證明:
解答:
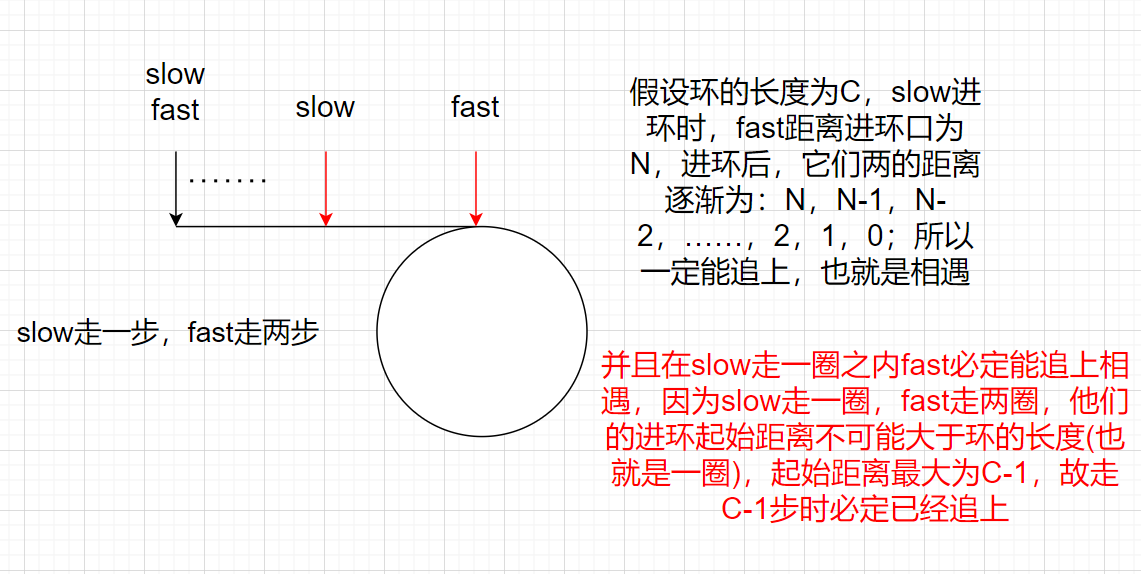
一定可以追上,slow進環時,fast已經在環里面走了一定長度了,那么這時在環里面就形成追趕,fast去追slow,假設slow進環時,fast和slow之間的距離為N,環的大小為C,那么N一定小于C
追趕中,slow一次走1步,fast一次走兩步
fast和slow之間的距離變化是:
N,N-1,N-2,N-3…2,1,0
N最后一定會被縮小到0,那么距離為0就一定相遇了
slow進入環里面,一圈之內,fast一定追上slow
- slow一次走一步,fast一次走n步,n>(2,3,4,5…),可以嗎?首先環的大小,和環前面的長度,都是不確定的,請證明:
解答:
不一定能追上
假設slow一次走1步,fast一次走3步,slow進環時,它們之間差距是N,環的長度是C
fast和slow之間的距離變化如下:
N,N-2,N-4,…,
slow和fast之間的距離是0的時候就追上了,那么說明N是偶數,就一定能追上
假設N是奇數,C-1也是奇數,就永遠追不上
fast追到距離為-1時,此時它們的距離為C-1,C-1也是奇數時,就永遠追不上
總結:fast一次走x,slow一次走y步都是可以的,最重要的是,追趕程序中的步差為x-y,步差為1就一定能追上,其他不一定能追上
10.環形鏈表Ⅱ
題目描述:
給定一個鏈表,回傳鏈表開始入環的第一個節點, 如果鏈表無環,則回傳 null,
為了表示給定鏈表中的環,我們使用整數 pos 來表示鏈表尾連接到鏈表中的位置(索引從 0 開始), 如果 pos 是 -1,則在該鏈表中沒有環,注意,pos 僅僅是用于標識環的情況,并不會作為引數傳遞到函式中,
說明:不允許修改給定的鏈表,
進階:
你是否可以使用 O(1) 空間解決此題?
題目來源:環形鏈表Ⅱ
解題思路1:
一個指標從相遇點開始走,一個指標從head走,它們會在入口點相遇
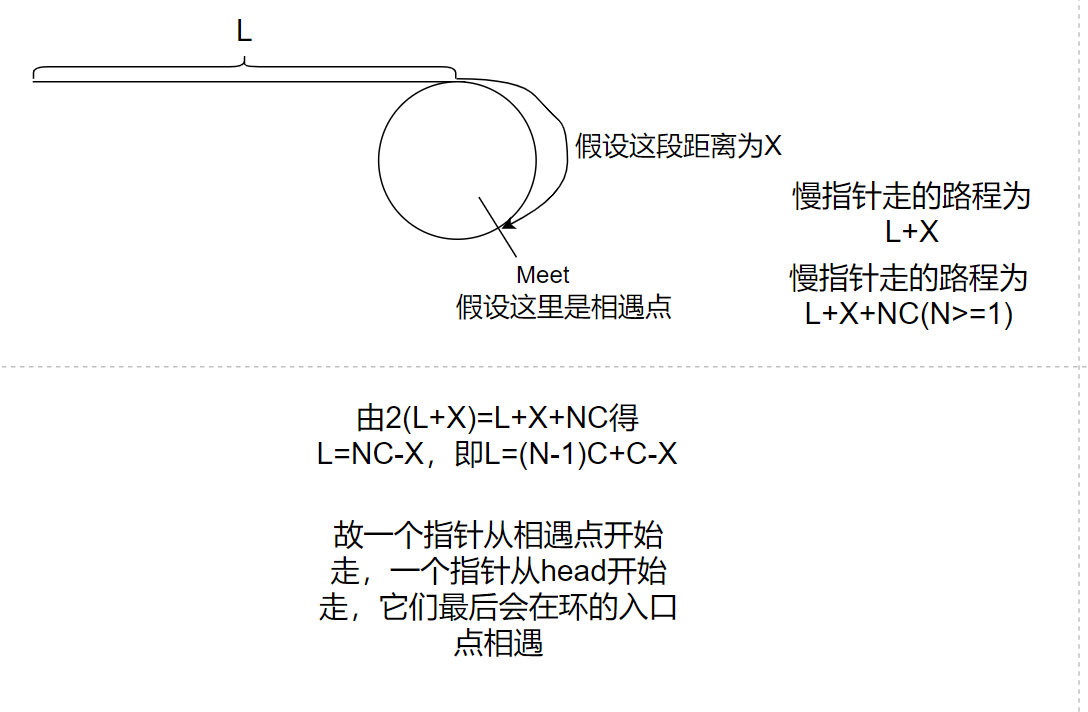
證明:
假設:鏈表頭到入口點的距離是L,相遇點到入口點的距離是X,環的長度為C,
慢指標走的路程是L+X
快指標走的路程是L+C+X
2(L+X)=L+C+X得L=C-X*
很多文章的證明是這個,但是這個證明是錯的,因為slow進環之前,fast不一定在環里面只走了一圈
正確的證明
相遇時:慢指標走的路程L+X
快指標走的路程L+NC+X(N>=1)
2(L+X)=L+NC+X
L+X=NC
L=NC-X
L=(N-1)C+C-X
結論:一個指標從相遇點開始走,一個指標從head走,它們會在入口點相遇
解題思路2:
斷開meet點,然后判斷相交,回傳交點
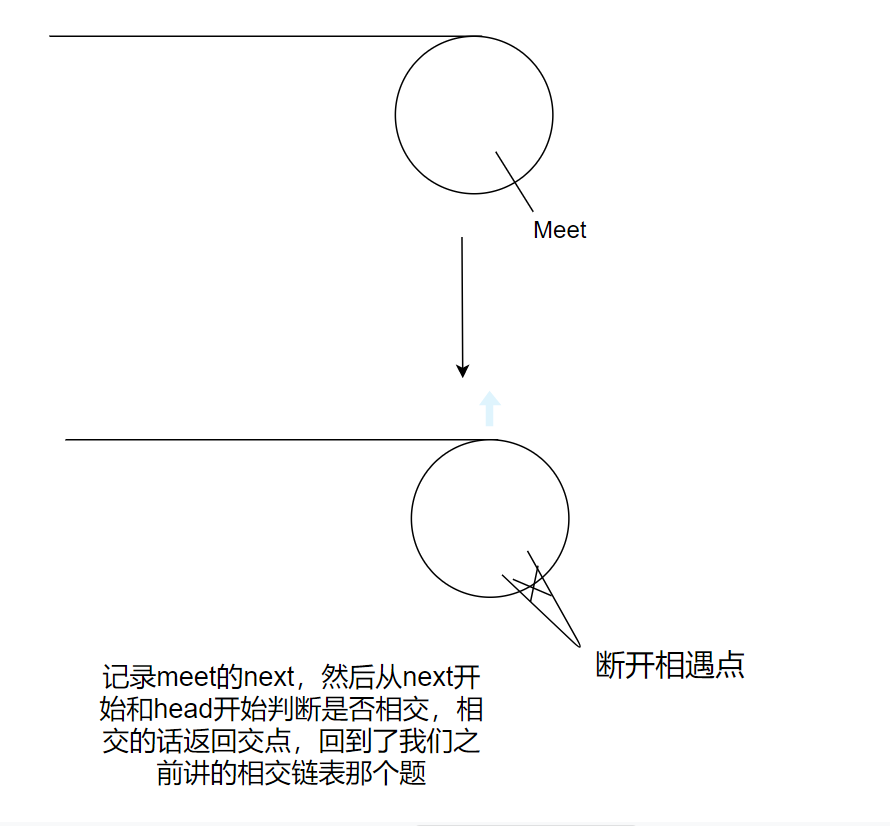
代碼如下:
struct ListNode* getIntersectionNode(struct ListNode* headA, struct ListNode* headB) {
//1、計算A、B長度
struct ListNode*curA = headA;
struct ListNode*curB = headB;
int lenA=0;
int lenB=0;
while(curA)
{
lenA++;
curA=curA->next;
}
while(curB)
{
lenB++;
curB=curB->next;
}
//2、計算長度差值,長的先走差值步
int gap = abs(lenA-lenB);
struct ListNode* longList = headA;
struct ListNode* shortList = headB;
if(lenA<lenB)
{
longList = headB;
shortList = headA;
}
while(gap--)
{
longList=longList->next;
}
//3、然后一起走
while(longList && shortList)
{
if(longList==shortList)
{
return longList;
}
longList=longList->next;
shortList=shortList->next;
}
return NULL;
}
struct ListNode *detectCycle(struct ListNode *head) {
struct ListNode *slow=head;
struct ListNode *fast=head;
while(fast &&fast->next)
{
slow=slow->next;
fast=fast->next->next;
if(slow==fast)
{
//相遇了
struct ListNode *meet=slow;
struct ListNode *next=meet->next;//記錄相遇點的下一個節點
meet->next=NULL;//斷開相遇點
return getIntersectionNode(head,next);
}
}
return NULL;
}
記錄meet的next,然后從next開始和head開始判斷是否相交,相交的話回傳交點,回到了我們之前講的相交鏈表那個題
11.復制帶隨機指標的鏈表
題目描述:
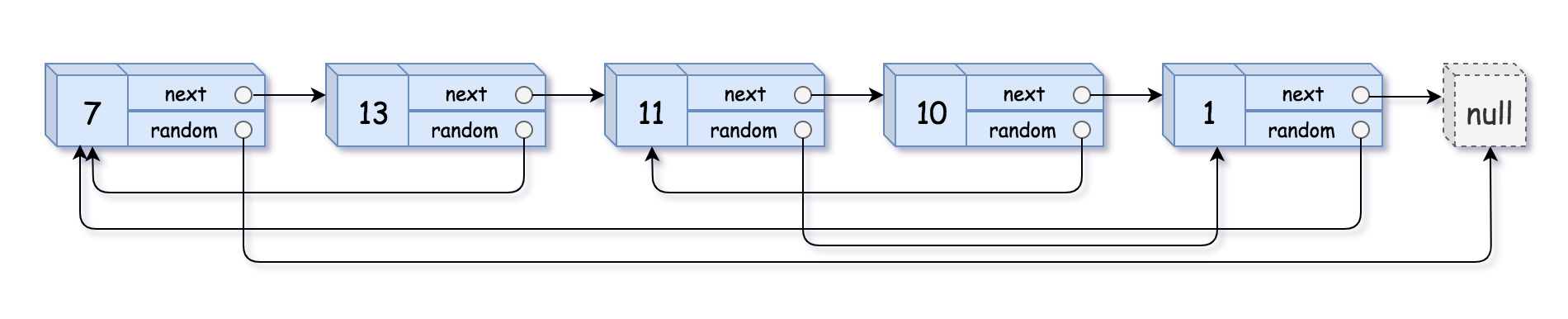
給你一個長度為 n 的鏈表,每個節點包含一個額外增加的隨機指標 random ,該指標可以指向鏈表中的任何節點或空節點,
構造這個鏈表的 深拷貝, 深拷貝應該正好由 n 個 全新 節點組成,其中每個新節點的值都設為其對應的原節點的值,新節點的 next 指標和 random 指標也都應指向復制鏈表中的新節點,并使原鏈表和復制鏈表中的這些指標能夠表示相同的鏈表狀態,復制鏈表中的指標都不應指向原鏈表中的節點 ,
例如,如果原鏈表中有 X 和 Y 兩個節點,其中 X.random --> Y ,那么在復制鏈表中對應的兩個節點 x 和 y ,同樣有 x.random --> y ,
回傳復制鏈表的頭節點,
鏈接:https://leetcode-cn.com/problems/copy-list-with-random-pointer示例 1
輸入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]]
輸出:[[7,null],[13,0],[11,4],[10,2],[1,0]]示例 2:
輸入:head = [[1,1],[2,1]]
輸出:[[1,1],[2,1]]示例 3:
輸入:head = [[3,null],[3,0],[3,null]]
輸出:[[3,null],[3,0],[3,null]]示例 4:
輸入:head = []
輸出:[]
解釋:給定的鏈表為空(空指標),因此回傳 null,


題目來源:復制帶隨機指標的鏈表
思路1:
1、先復制原鏈表的每個節點,將復制好的新節點鏈接起來
2、求出原鏈表中每個結點cur的random和cur的相對距離
再去復制新鏈表到當前節點相對距離的結點,賦值給random,找每個節點的random時間復雜度是O(N),N個節點就是O(N^2)——效率低
思路2:
1、在原鏈表的每個節點的后面,鏈接插入一個拷貝節點
2、置random
3、把拷貝節點剪下來,鏈接到一起,同時恢復原鏈表
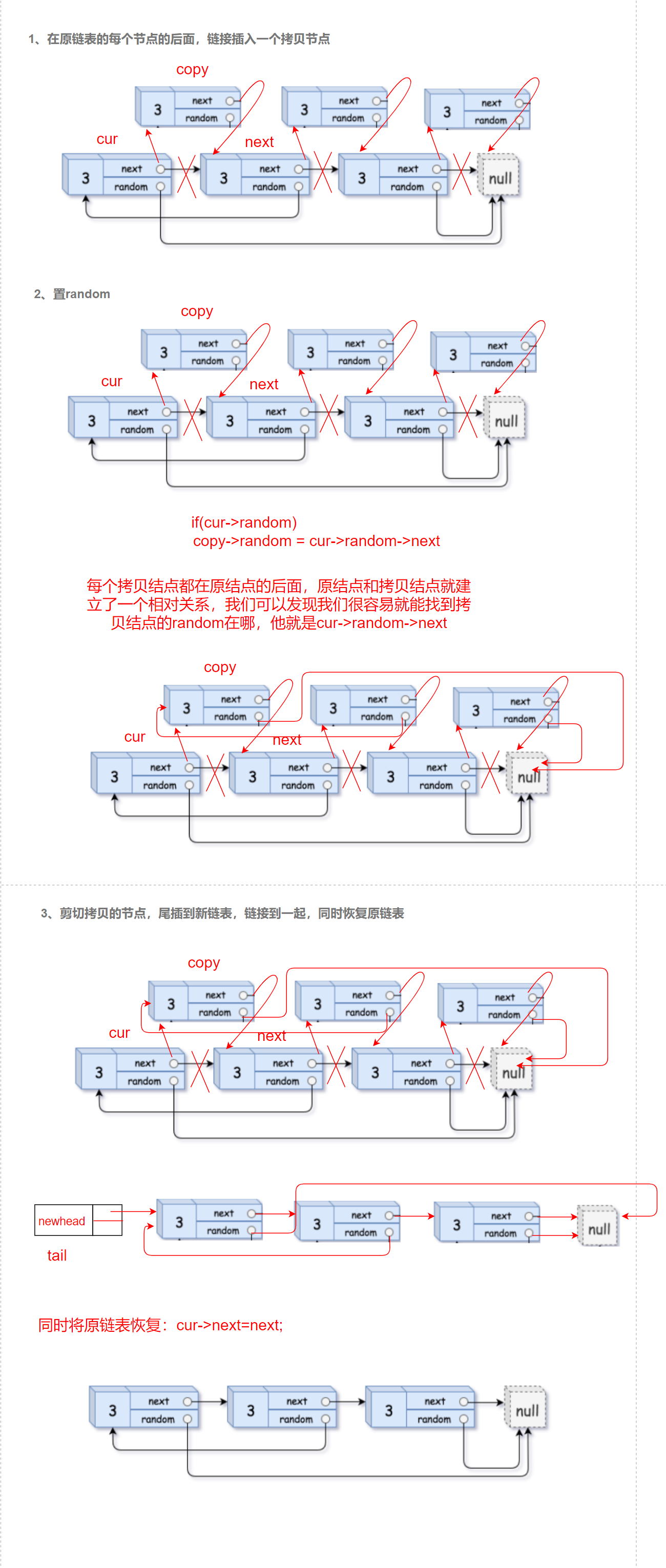
代碼如下:
struct Node* copyRandomList(struct Node* head) {
if(head==NULL)
{
return NULL;
}
//1、每個節點的拷貝鏈接在該節點后面
struct Node* cur=head;
while(cur)
{
struct Node* next = cur->next;
struct Node* copy = (struct Node*)malloc(sizeof(struct Node));
copy->val=cur->val;
cur->next=copy;
copy->next=next;
cur=next;
}
//2、置random
cur=head;
while(cur)
{
struct Node* copy=cur->next;
if(cur->random)
{
copy->random = cur->random->next;
}
else
{
copy->random=NULL;
}
cur=copy->next;
}
//3、剪切拷貝的節點,尾插到新鏈表
cur=head;
struct Node* newhead,*tail;
newhead=tail=(struct Node*)malloc(sizeof(struct Node));
while(cur)
{
struct Node* copy=cur->next;
struct Node* next=copy->next;
tail->next=copy;
tail=copy;
cur->next=next;
cur=next;
}
struct Node* first=newhead->next;
free(newhead);
newhead=NULL;
return first;
}
將每個節點的拷貝鏈接在該節點后面相當于鏈表當中的插入操作,每個拷貝結點都在原結點的后面,原結點和拷貝結點就建立了一個相對關系,我們可以發現我們很容易就能找到拷貝結點的random在哪,他就是cur->random->next,然后通過相對位置置拷貝的結點random,最后將拷貝的結點尾插到新鏈表,這里我們對新鏈表使用了帶哨兵位的頭結點,
以上就是博主關于復雜度、陣列、鏈表的熱門OJ的講解,期待你的點贊哦!歡迎大家學習討論,如有錯誤,希望大家評論區留言,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293604.html
標籤:其他
上一篇:【Linux系列】無法創建用戶useradd:無法打開 /etc/passwd
下一篇:資料結構 順序表