文章目錄
- K-近鄰演算法
- 1.K-近鄰演算法簡介
- 1.1 定義
- 1.2 KNN演算法流程
- 2.K-近鄰演算法優缺點匯總
- 3.kd樹
- 3.1 kd樹的構建程序
- 3.2 kd樹的搜索程序
- 4.交叉驗證
- 5.?格搜索
K-近鄰演算法
1.K-近鄰演算法簡介
1.1 定義
如果?個樣本在特征空間中的k個最相似(即特征空間中最鄰近)的樣本中的?多數屬于某?個類別,則該樣本也屬于這個類別,
1.2 KNN演算法流程
1)計算已知類別資料集中的點與當前點之間的距離
2)按距離遞增次序排序
3)選取與當前點距離最?的k個點
4)統計前k個點所在的類別出現的頻率
5)回傳前k個點出現頻率最?的類別作為當前點的預測分類
常?距離公式
歐式距離(Euclidean Distance): 通過距離平?值進?計算
曼哈頓距離(Manhattan Distance): 通過距離的絕對值進?計算
切?雪夫距離 (Chebyshev Distance): 維度的最?值進?計算
閔可夫斯基距離(Minkowski Distance): 當p=1時,就是曼哈頓距離; 當p=2時,就是歐?距離; 當p→∞時,就是切?雪夫距離,
2.K-近鄰演算法優缺點匯總
優點:
- 簡單有效
- 重新訓練的代價低
- 適合類域交叉樣本
- KNN?法主要靠周圍有限的鄰近的樣本,?不是靠判別類域的?法來確定所屬類別的,因此對于類域的交叉或重疊較多的待分樣本集來說,KNN?法較其他?法更為適合,
- 適合?樣本?動分類
- 該演算法?較適?于樣本容量?較?的類域的?動分類,?那些樣本容量較?的類域采?這種演算法?較容易產?誤分,
缺點:
- 惰性學習
- KNN演算法是懶散學習?法(lazy learning,基本上不學習),?些積極學習的演算法要快很多
- 類別評分不是規格化
- 不像?些通過概率評分的分類
- 輸出可解釋性不強
- 例如決策樹的輸出可解釋性就較強
- 對不均衡的樣本不擅?
- 當樣本不平衡時,如?個類的樣本容量很?,?其他類樣本容量很?時,有可能導致當輸??個新樣本 時,該樣本的K個鄰居中?容量類的樣本占多數,該演算法只計算“最近的”鄰居樣本,某?類的樣本數量很 ?,那么或者這類樣本并不接近?標樣本,或者這類樣本很靠近?標樣本,?論怎樣,數量并不能影響運 ?結果,可以采?權值的?法(和該樣本距離?的鄰居權值?)來改進,
- 計算量較?
- ?前常?的解決?法是事先對已知樣本點進?剪輯,事先去除對分類作?不?的樣本,
3.kd樹
根據KNN每次需要預測?個點時,我們都需要計算訓練資料集?每個點到這個點的距離,然后選出距離最近的k個點進?投票,當資料集很?時,這個計算成本?常?,
為了避免每次都重新計算?遍距離,演算法會把距離資訊保存在?棵樹?,這樣在計算之前從樹?查詢距離資訊, 盡量避免重新計算,其基本原理是,如果A和B距離很遠,B和C距離很近,那么A和C的距離也很遠,有了這個資訊, 就可以在合適的時候跳過距離遠的點,
3.1 kd樹的構建程序
1.構造根節點
2.通過遞回的?法,不斷地對k維空間進?切分,?成?節點
3.重復第?步驟,直到?區域中沒有示例時終?
需要關注細節:a.選擇向量的哪?維進?劃分;b.如何劃分資料
第?個問題簡單的解決?法可以是隨機選擇某?維或按順序選擇,但是更好的?法應該是在資料?較分散的那?維進? 劃分(分散的程度可以根據?差來衡量),
第?個問題中,好的劃分?法可以使構建的樹?較平衡,可以每次選擇中位數來進?劃分,
3.2 kd樹的搜索程序
1.?叉樹搜索?較待查詢節點和分裂節點的分裂維的值,(?于等于就進?左?樹分?,?于就進?右?樹分 ?直到葉?結點)
2.順著“搜索路徑”找到最近鄰的近似點
3.回溯搜索路徑,并判斷搜索路徑上的結點的其他?結點空間中是否可能有距離查詢點更近的資料點,如果有 可能,則需要跳到其他?結點空間中去搜索
4.重復這個程序直到搜索路徑為空
4.交叉驗證
交叉驗證:將拿到的訓練資料,分為訓練和驗證集,以下圖為例:將資料分成4份,其中?份作為驗證集,然后經過4次 (組)的測驗,每次都更換不同的驗證集,即得到4組模型的結果,取平均值作為最終結果,?稱4折交叉驗證,
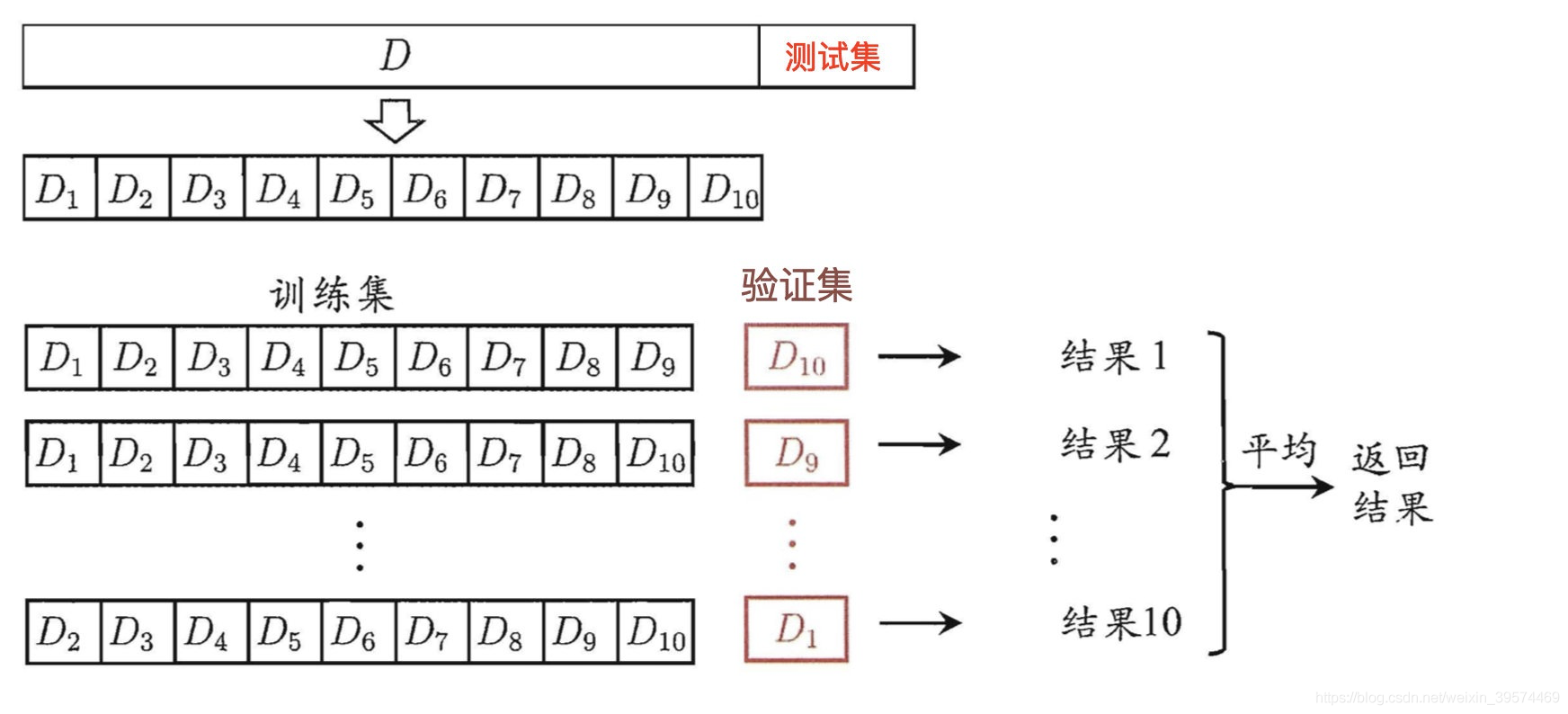
為什么需要交叉驗證
交叉驗證?的:為了讓被評估的模型更加準確可信
5.?格搜索
通常情況下,有很多引數是需要?動指定的(如k-近鄰演算法中的K值),這種叫超引數,但是?動程序繁雜,所以需要 對模型預設?種超引陣列合,每組超引數都采?交叉驗證來進?評估,最后選出最優引陣列合建?模型,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293701.html
標籤:AI