文章目錄
- 單鏈表
- 申請空間
- 查
- 增
- 尾插
- 頭插
- 任意位置插
- 判空
- 刪
- 頭刪
- 尾刪
- 任意位置刪
- 銷毀
- 帶頭雙向回圈鏈表
- 申請空間
- 初始化
- 查
- 增
- 尾插
- 頭插
- 任意插
- 刪
- 尾刪
- 頭刪
- 任意刪
- 銷毀
- 總結
單鏈表
預先準備4個東西
- ListNode.h(宣告)
- ListNode.c(介面實作)
- main.c(呼叫介面)
申請空間
- 所謂巧婦難為無米之炊,這申請空間就是鏈表的米
LTN* BuySListNode(Value x)//申請一個節點
{
LTN *NewNode=(LTN *)malloc(sizeof(LTN));
NewNode->data=x;
NewNode->next=NULL;
return NewNode;
}
查
- 他是是如何查的是不是和順序表一樣挨個挨個的找或者是別的方法?
LTN* ListNodeFind(LTN **phead,int find)
{
LTN *cur=*phead;
while(cur)
{
if(cur->data==find)
{
return cur;
}
cur=cur->next;
}
return NULL;
}
顯而易見他和順序表一樣是挨個挨個找但是區別在于順序表回傳的是下標,而鏈表回傳的是地址
增
尾插
- 為插相比順序表來說麻煩許多不能向他一樣之間下標訪問之間插入
- 需要遍歷鏈表,找尾 時間復雜度O(N)
- 那么他是如何遍歷的呢??
void ListNodePushBack(LTN **phead,int num)//尾插
{
assert(phead);
LTN*cur=*phead;
if(cur==NULL)
{
cur=BuySListNode(num);
*phead=cur;
}
else
{
while(cur->next)
{
cur=cur->next;
}
LTN* Newhead=BuySListNode(num);
cur->next=Newhead;
}
}
遍歷是找最后一個元素的next,應為最后那個元素指向的是NULL
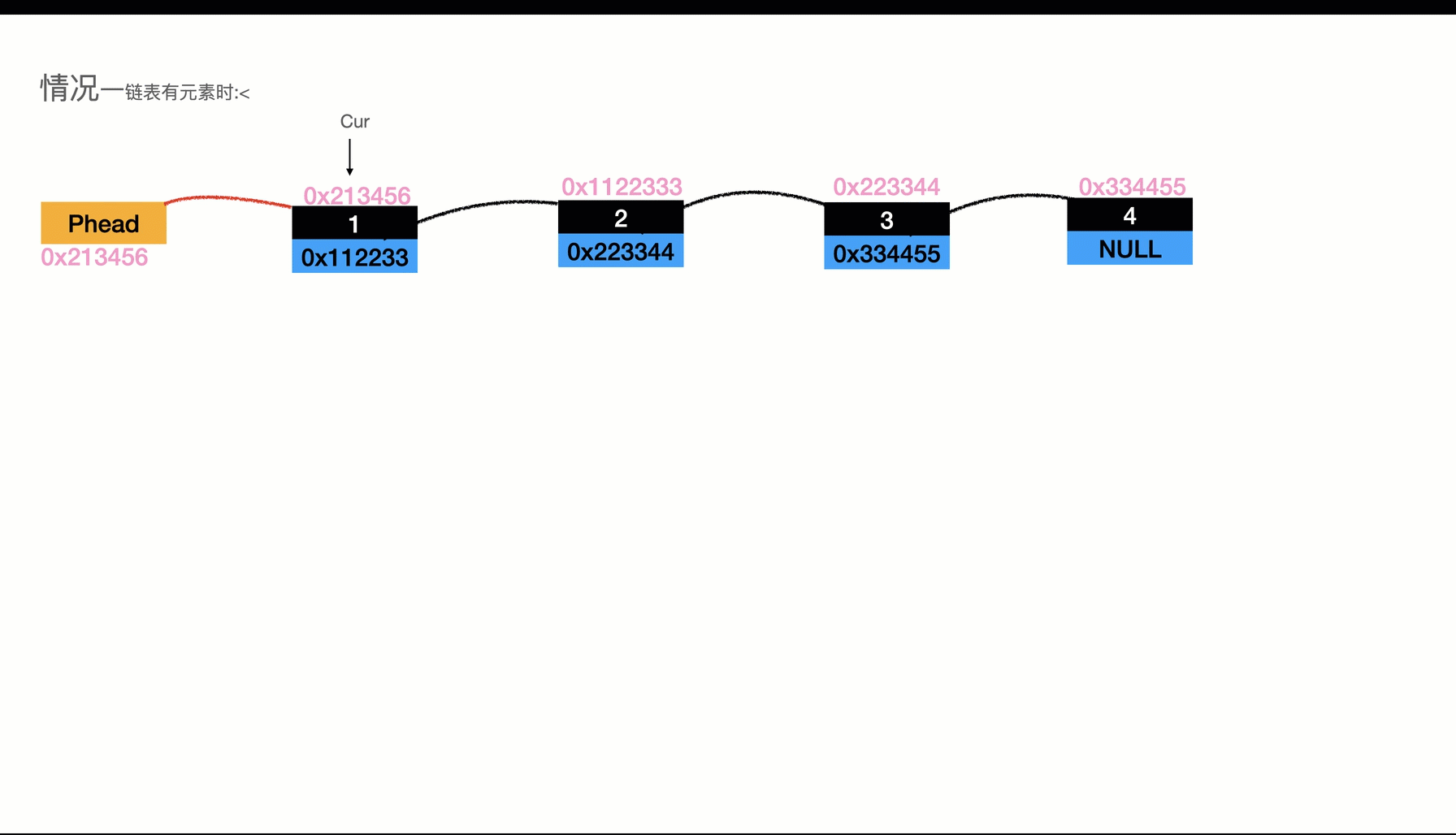
上面還遇到了倆種情況
- 空鏈表插入
- 非空鏈表插入
如圖所示:
頭插
- 頭插可謂是最簡單了只需要找到頭和他next的地址就可以插入
- 他和順序表的效率相差甚微 復雜度 O(1)
void ListNodePushFront(LTN **phead,int num)//頭插
{
assert(phead);
if(ListNodeEmpty(phead)==1)//鏈表為空
{
*phead=BuySListNode(num);
}
else//不為空
{
LTN *OldHead= *phead;
LTN *newnode=BuySListNode(num);
*phead=newnode;
(*phead)->next=OldHead;
}
}
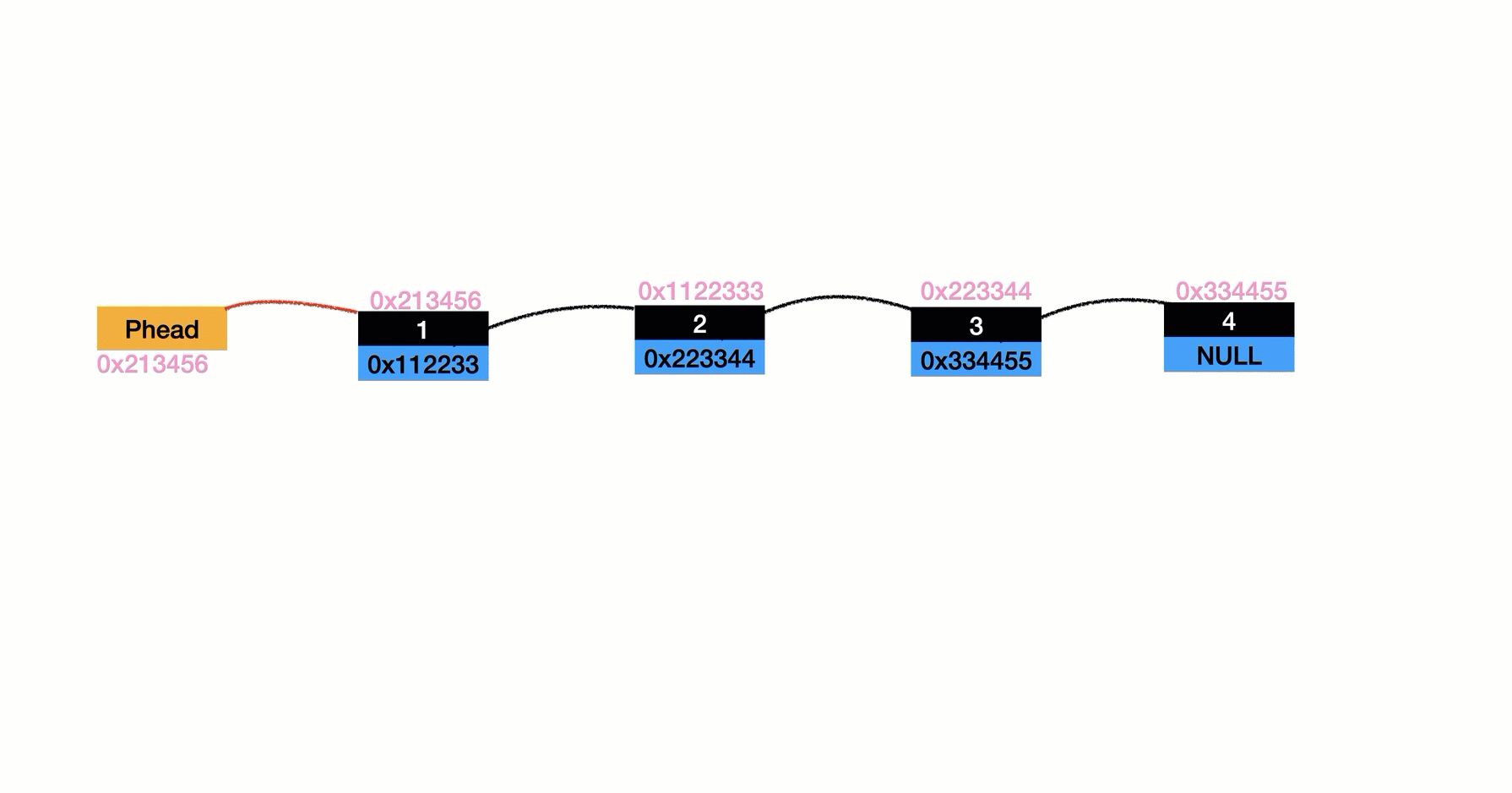
頭插的時候依然是遇到了倆種情況
- 空鏈表(和尾插一樣)
- 和非空(如圖所示)
任意位置插
- 和順序表一樣她是基于查找這個介面實作的但相同有不同
為什么相同有不同?他有什么缺陷?
void ListNotPopInsert(LTN*find,int num)//插入
void ListNotPopInsert(LTN*find,int num)//插入
{
LTN*next=find->next;
LTN *newnode=BuySListNode(num);
find->next=newnode;
newnode->next=next;
}
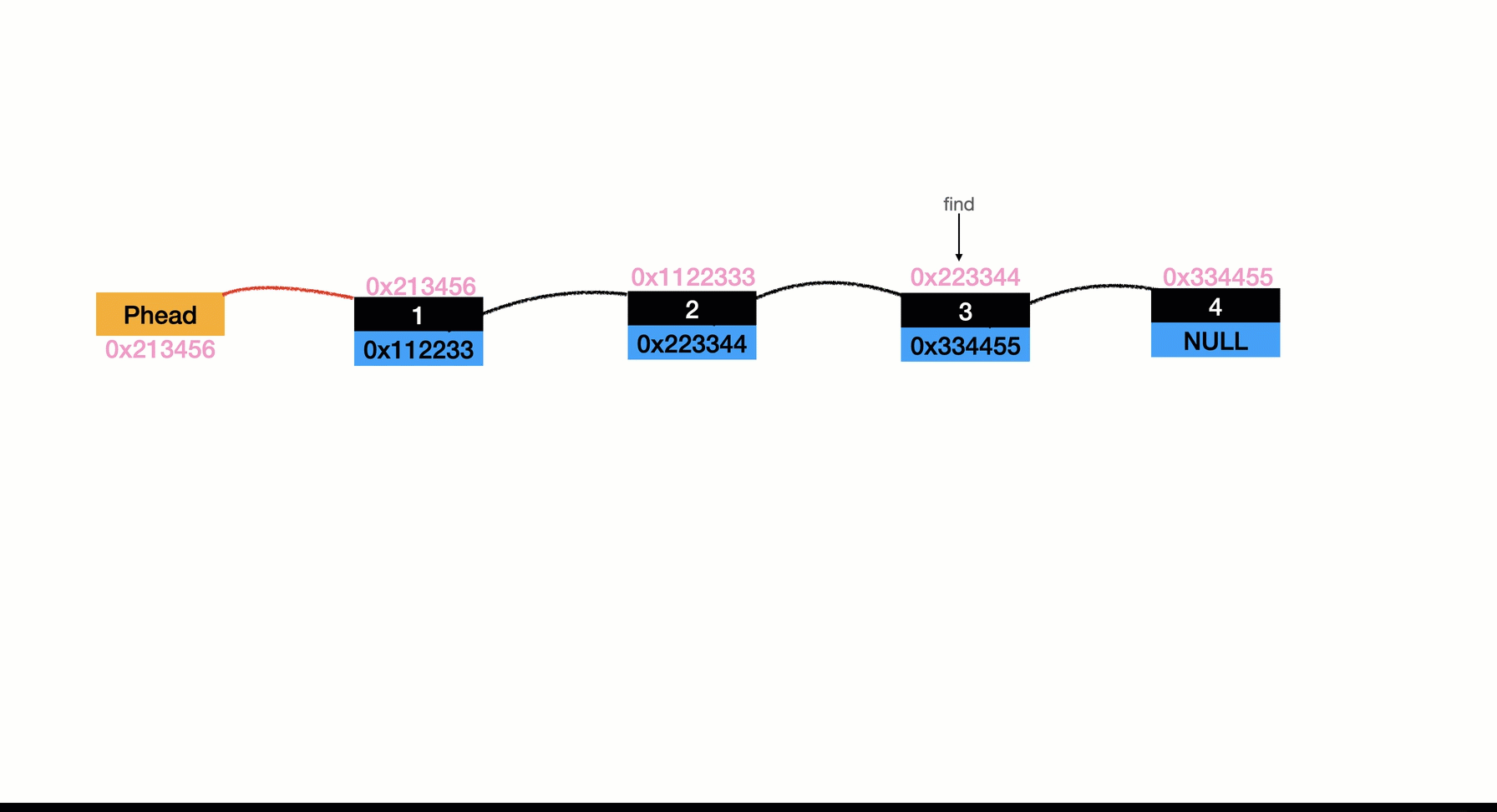
實作依然是有倆種情況
- 空鏈表
- 非空鏈表(如圖所示)
- 這樣上面的代碼其實都可以更改了傳頭指標和資料就可以頭插,為插也同理
缺陷其實很顯而易見,他“只能”在這個位置后面插入(
后面雙向回圈指標可以解決)
不同的是順序表前后插入都方便,相同他們都可以直接找到這個位置插入但是鏈表插入更優秀
判空
- 這一步對于刪資料來說至關重要,如果鏈表為慷訓造成
越界訪問
int ListNodeEmpty(LTN **phead)//判空
{
if(*phead==NULL)
return 1;
else
return 0;
}
刪
一定要判斷鏈表是不是為空,一定要判斷鏈表是不是為空,一定要判斷鏈表是不是為空,重要的事情說三遍
頭刪
- 邏輯和頭插的邏輯是反的不懂就在看下頭插,就不過多介紹了
void ListNodePopFront(LTN **phead)//頭刪
{
if(ListNodeEmpty(phead)==1)//鏈表為空
{
exit(-1);
}
LTN* OldHead=*phead;
LTN*Newhead=OldHead->next;
free(OldHead);
*phead=Newhead;
}
尾刪
- 這里和頭插稍微有點細微的區別
- 是啥區別呢?
- 帶著這個問題在看代碼
void ListNodePopBack(LTN **phead)//尾刪
{
assert(phead);
if(ListNodeEmpty(phead)==1)//鏈表為空
{
exit(-1);
}
LTN *cur=*phead;
while(cur->next->next)
{
cur=cur->next;
}
free(cur->next);
cur->next=NULL;
}
圖解
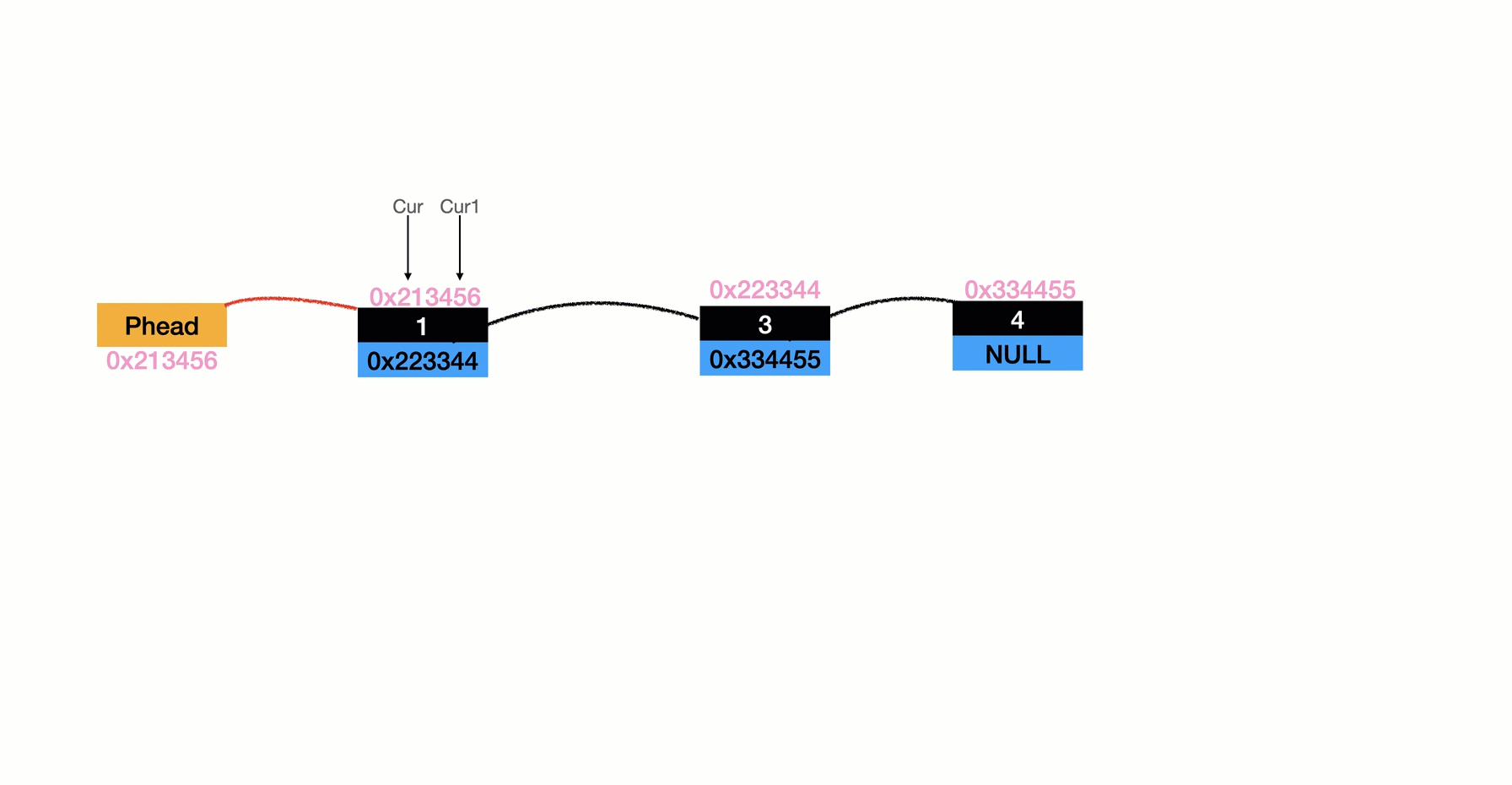
任意位置刪
- 這里要注意一下他最后的元素
指向是否為空 - 他的邏輯和任意位置刪基本一樣
void ListNotPopInsert(LTN*find,int num)//pos后洗掉
{
LTN *Next=find->next;
if(find->next!=NULL)
{
LTN *Nextnext=Next->next;
free(Next);
find->next=Nextnext;
}
else
{
exit(-1);
}
}
銷毀
void ListNodeDestroy(LTN **phead)//銷毀
{
assert(phead);
LTN *cur=*phead;
while(cur)
{
LTN *Next=cur->next;
free(cur);
cur=Next;
}
}
帶頭雙向回圈鏈表
- 相比單鏈表的實作稍微復雜了點,但是他的是鏈表中最
實用的,且用的最多的一種 - 為什么最實用,他和單鏈表的區別在哪里?
申請空間
- 和單鏈一樣不多講
DLN* BuySListNode(Value x)
{
DLN *NewNode=(DLN *)malloc(sizeof(DLN));
NewNode->data=x;
NewNode->next=NULL;
NewNode->prev=NULL;
return NewNode;
}
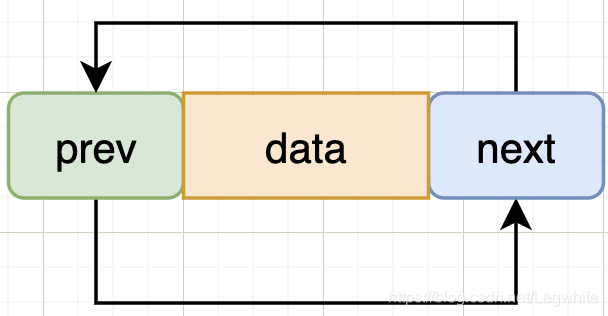
初始化
- 雙向回圈就像是一個蛹
DLN *Nenode=BuyDListNode(0);
Nenode->data=0;
Nenode->next=Nenode;
Nenode->prev=Nenode;
*phead=Nenode;
如圖所示
查
- 其實邏輯和點鏈表差不多
- 唯一區別就是判斷條件因為最后一個元素
指向的是頭節點
DLN *DListNodeFind(DLN **phead,int num)//查找
{
assert(*phead);
DLN *cur=*phead;
while(cur->next!=*phead)
{
if(cur->data==num)
{
return cur;
cur=cur->next;
}
}
return NULL;
}
增
尾插
- 其實邏輯和單鏈表差不多
- 但是找尾變的
容易了,并且不用擔心空鏈表 - 帶來的是代碼變得
復雜了,果然啥事都是一把雙刃劍有好有壞
DLN *DListNodePushBack(DLN **phead,int num)//尾插
{
assert(*phead);
DLN *cur=(*phead)->prev;
DLN*newnode= BuyDListNode(num);
cur->next=newnode;
newnode->prev=newnode;
newnode->next=*phead;
(*phead)->prev=newnode;
}
圖解
- 插入分為倆種情況
- 有元素(如圖所示)
- 沒有元素(如圖二三步所示)
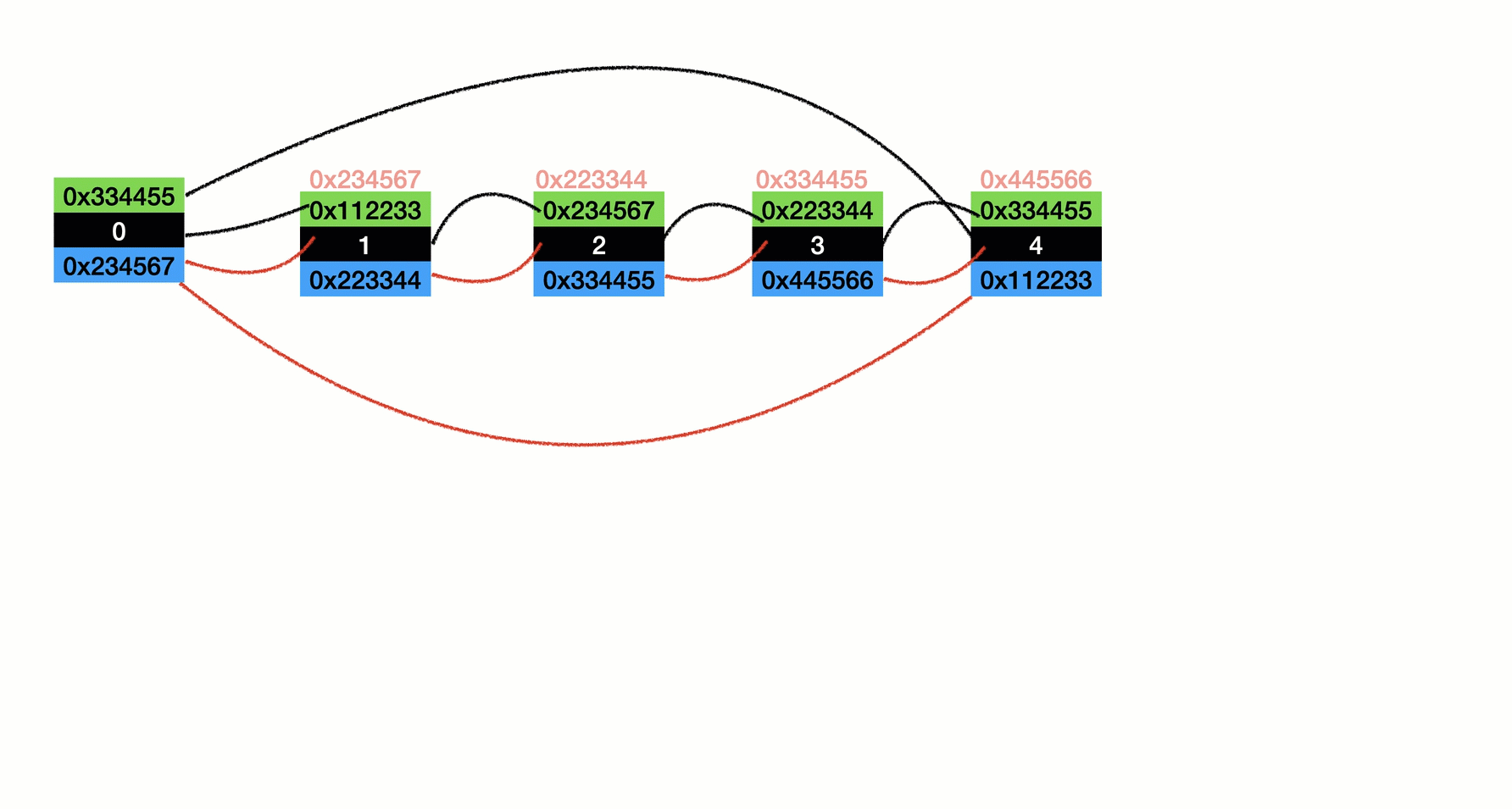
頭插
- 大體邏輯和單鏈表一樣
void DListNodePushFront(DLN **phead,int num)//頭插
{
assert(pphead);
DLN *OldHead=(*phead)->next;
DLN *newnode=BuyDListNode(num);
(*phead)->next=newnode;
newnode->prev=(*phead);
newnode->next=OldHead;
OldHead->prev=newnode;
}
- 插入分為倆種情況
- 有元素(如圖所示)
- 沒有元素(如圖一、二、三步)
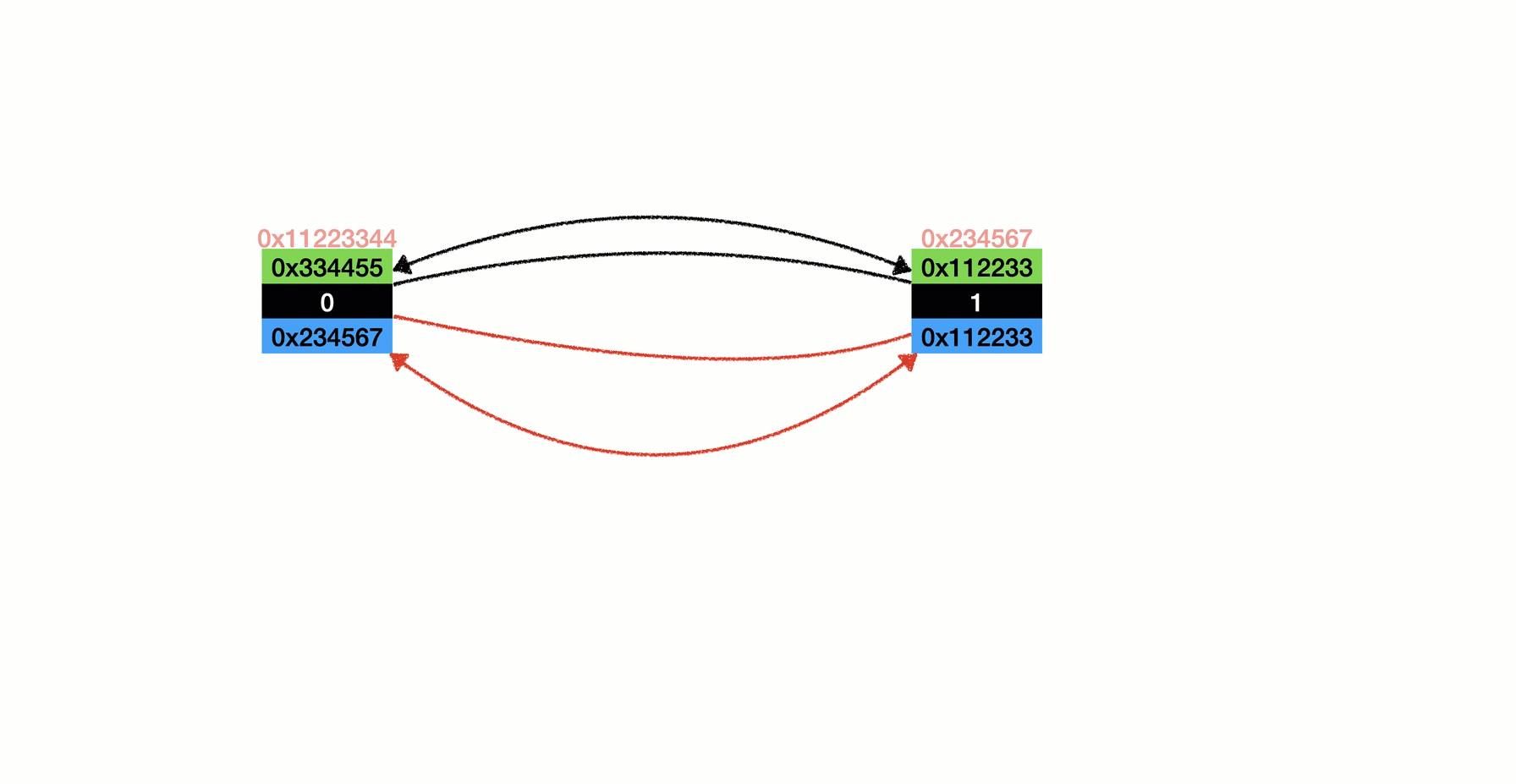
任意插
- 他邏輯也和單鏈表一樣
- 但是她是pos位頭插和尾插都可以!!!!
- 他結合了頭插和尾插于一身
void DListNodePushInsert(DLN **pos,int num)//pos位插入
{
assert(pphead);
//pos位尾插
DLN *next= (*pos)->next;
DLN *newnode=BuyDListNode(num);
(*pos)->next=newnode;
newnode->prev=(*pos);
newnode->next->next;
next->prev=newnode;
//pos頭插
DLN *prev= (*pos)->prev;
DLN *newnode=BuyDListNode(num);
prev->next=newnode;
newnode->prev=prev;
newnode->next=(*pos);
(*pos)->prev=newnode;
}
刪
- 其實邏輯和點鏈表差不多
尾刪
- 邏輯和尾插相反就不多介紹了
- 代碼里面有
注釋
void DListNodePopBack(DLN **phead)//尾刪
{
assert(pphead);
if(ListNodeEmpty(phead)==1)//鏈表是否空
{
exit(-1);
}
DLN *tail=(*phead)->prev;//尾巴
DLN *newtail=tail->prev;//尾巴前一個
free(tail);//洗掉尾巴
(*phead)->prev=newtail;//頭節點prev指向老尾巴的前一個
newtail->next=(*phead);//老尾巴的前一個成為新的尾巴
}
頭刪
- 邏輯和頭插,尾刪相反就不多介紹了
- 代碼里面有
注釋
void DListNodePophFront(DLN **phead)//頭刪
{
assert(pphead);
if(ListNodeEmpty(phead)==1)//鏈表是否為空
{
exit(-1);
}
DLN *OldHead=(*phead)->next;//現在的頭
DLN*newhead=OldHead->next;//現在的頭后一個節點
free(OldHead);//洗掉現在的頭
(*phead)->next=newhead;
newhead->prev=(*phead);
}
任意刪
- 邏輯和頭插,尾刪相反就不多介紹了
在這里插入代碼片void DListNodePopInsert(DLN **pos)//pos位插入
{
assert(pos);
if(ListNodeEmpty(phead)==1)//鏈表是否為空
{
exit(-1);
}
//pos位后插
DLN *next= (*pos)->next;
DLN *nextnext=next->next;
free(next);
(*pos)->next=nextnext;
nextnext->prev= (*pos);
// pos位前刪
DLN *prevprev=prec->prev;
free(prev);
prevprev->next=(*pos);
(*pos)->prev=prevprev;
}
圖解以上洗掉

以上可以發現洗掉其實是先存要洗掉的
前面一個節點or后面一個節點
銷毀
void DListNode(DLN **phead)
{
while((*phead)->next==(*phead)->prev)
{
DLN *tail=(*phead)->prev;
DLN *newtail=tail->next;
free(tail);
newtail->next=(*phead);
(*phead)->prev=tail;
}
if((*phead)->next!=NULL)
{
free((*phead)->next);
free(*phead);
}
}
總結
- 單鏈表的劣勢就是
找不到前一個節點 - 而雙向帶頭回圈鏈表優化了這個一點,但是他的
代碼量也大大的增加了 - 且雙向鏈表的
鏈表的銷毀也比單鏈表麻煩
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293728.html
標籤:其他
下一篇:list介紹和基本使用