你好,我是悅創,最近實習然后一對一學員上課備課,所以有點耽擱更新文章了,下一篇,會在公眾號:AI悅創,發布,敬請關注!
然后,手里有個單子,但是奈何自己實習公司事情太多,所以就把我一對一學員的專案,介紹給 Panda4u ,最后他遇到加密就頭疼了,然后我就幾十斤把這個加密稍微研究了一下,故這也是這篇文章的誕生!
本文將會對這個系列的爬蟲進行分析和抓取,僅供學習交流使用!
近期爬取了私募排排網上的歷史凈值,寫一下爬取程序中的一些心得體會,
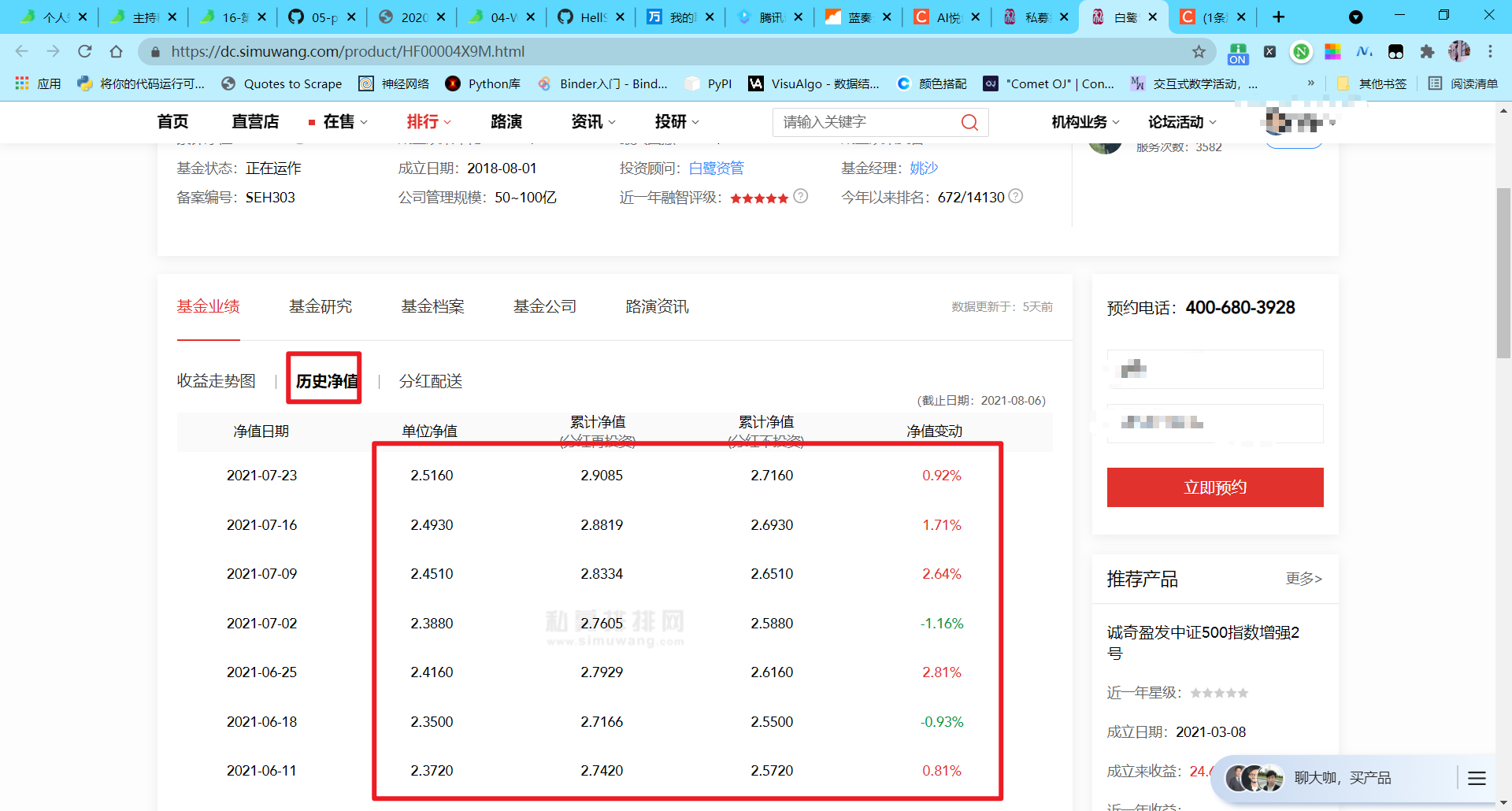
原本,思考的時候覺得,selenium 是“萬能的”,應該可以一力破萬法,結果果然栽跟頭了,
上面有很多的難點,例如直接利用 selenium 會被檢測出反爬、爬取的數值被加密(頁面上看到的和 html 中不一樣,多了一些隱藏值)等等,爬取的方法主要就是 selenium、正則、beautifulsoup、xpath,這里先把這里使用的庫匯入,
from selenium import webdriver
from bs4 import BeautifulSoup
from selenium.webdriver.common.by import By
import pandas
import time
import re
from lxml import html
from selenium.webdriver.common.action_chains import ActionChains # 匯入滑鼠事件庫
總體流程:打開網頁,然后登錄,到達需要決議的頁面,得到原始碼,然后破解加密,最后輸出資料保存在 excel 中,
一、開啟網頁
有的網站直接使用 selenium 就可以開啟,例如
from selenium import webdriver
driver = webdriver.Chrome() # 啟動驅動器
driver.get('https://www.simuwang.com/user/option') # 加載網站
但是在這里就會出現以下情況,那是因為如果直接開啟網頁,就會被發現是爬蟲,

解決這個問題要使用以下代碼
driver = webdriver.Chrome() # 啟動驅動器
# 谷歌瀏覽器 79和79版本后防止被檢測
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
driver.get('https://www.simuwang.com/user/option') # 加載網站
最后就能完美的開啟網頁了,
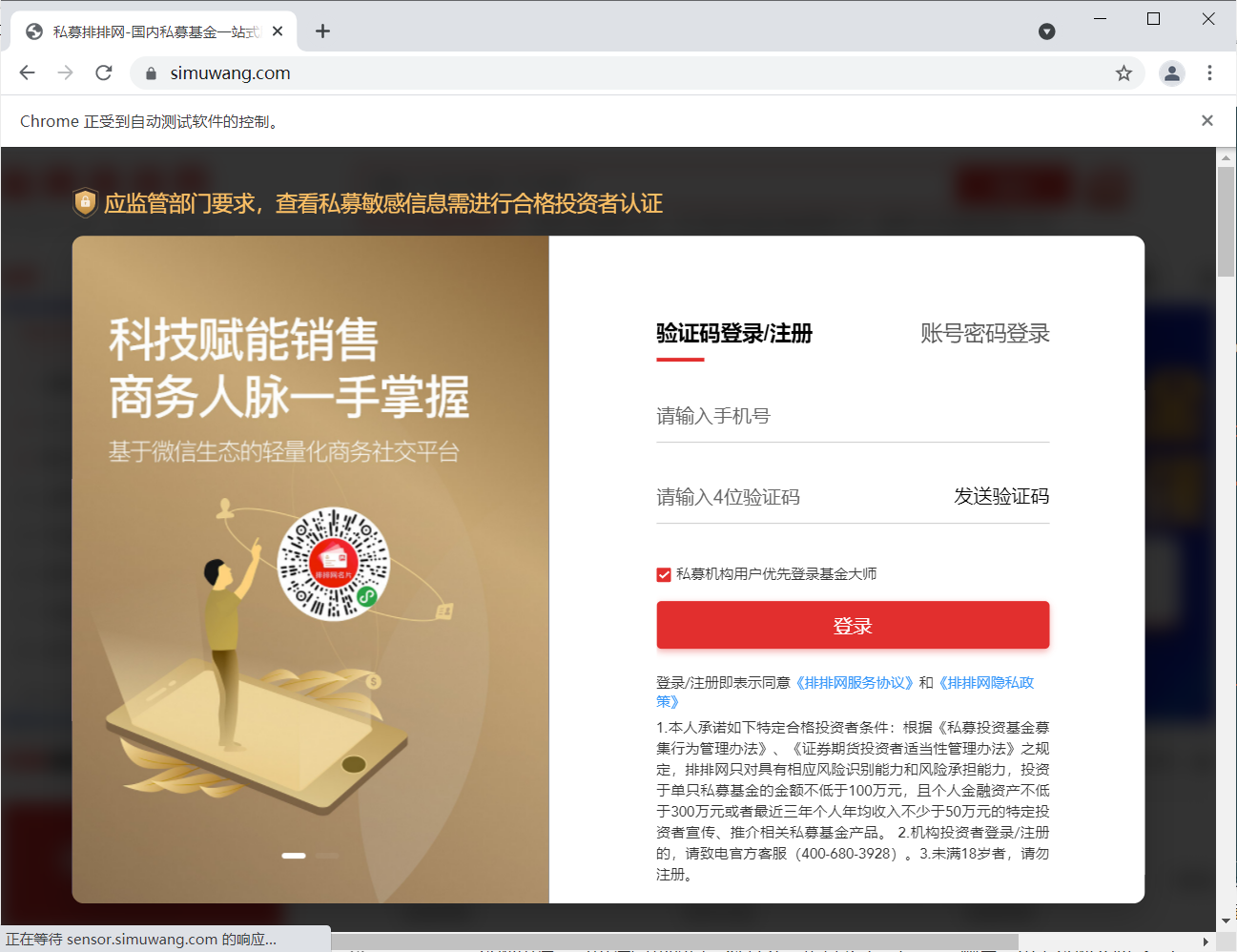
注意: 這里設定開發者模式也是不可行的!
二、selenium 定位元素決議網頁
在進入網頁之后,就開始元素定位,selenium 定位一共有八個 name , id ,link_text ,partial_link_text ,class_name ,xpath,css,tag_name ,其中最少也要掌握 xpath 或者 css 一種方法(使用這兩種方法基本上能解決所有的定位),后面,我會考慮出一個 Xpath 的提取視頻教程,看大家的對于這篇文章的閱讀量,如果過三百我就馬上錄,
詳細用法,可以關注后續的文章,這里就不多贅述了,在這里就講講 selenium 這里的用法,我使用的方法是 xpath,
1. 輸入賬號和輸入密碼點擊登錄
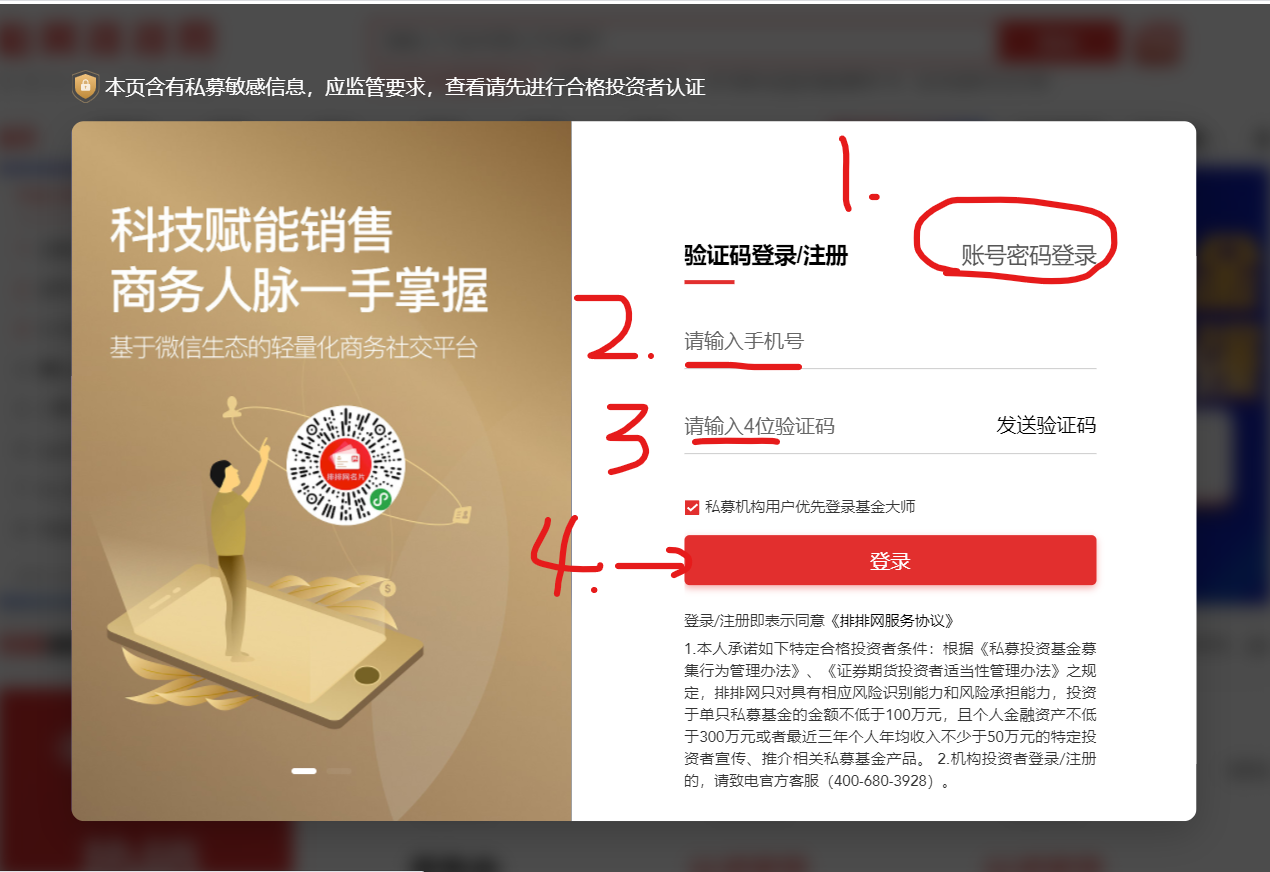
driver.find_element(By.XPATH,'//button[@class="comp-login-method comp-login-b2"]').click() #點擊賬號密碼登錄
driver.find_element(By.XPATH,'//input[@name="username"]').send_keys('xxxxxxxxxxxx') # 輸入賬號
driver.find_element(By.XPATH,'//input[@type="password"]').send_keys('xxxxxxxxxxxx') # 輸入密碼
driver.find_element(By.XPATH,'//button[@style="margin-top: 65px;"]').click() # 點擊登錄
補充:
-
以后使用定位最好都用 By(也就是以上的方法),而
driver.find_element_by_xpath(),因為后面的這種不利于封裝, -
元素定位是做什么的?我們為什么要定位元素?有什么用呢?
- 元素定位就是在 html 中找到我們在網頁中看到內容對應的元素,
- 找到之后可以使用滑鼠事事件和鍵盤事件,對網頁進行人工模擬操作,
- 在這里就是簡單的鍵盤事件
send_keys和滑鼠事件click,
2. 叉掉廣告,網頁后退
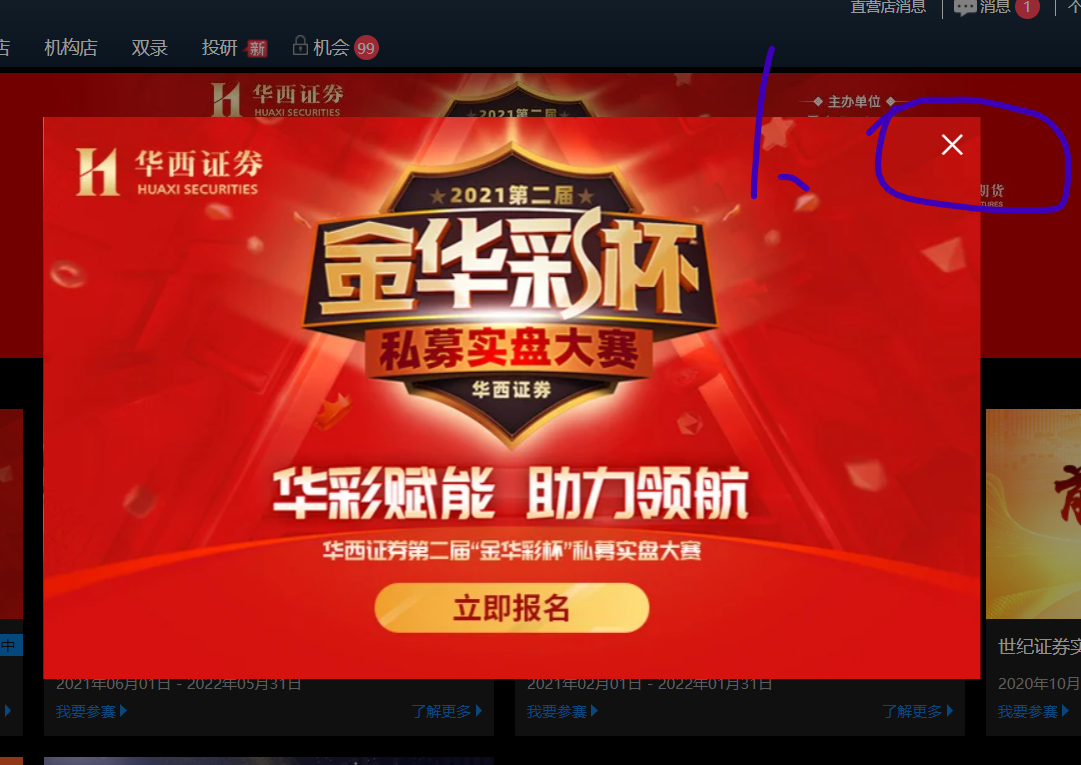
time.sleep(15) # 等待登錄時間
driver.find_element(By.XPATH,'//span[@class="el-icon-close close-icon"]').click() # 叉掉廣告
driver.back() # 網頁后退
補充:
-
注意這里必須要 sleep 幾秒,那是因為登錄程序需要時間加載,不然會報錯,
-
driver.back()是將當前頁面回傳上一級,那么driver.forward()前進到上一級,
3. 滑鼠懸停點擊自選
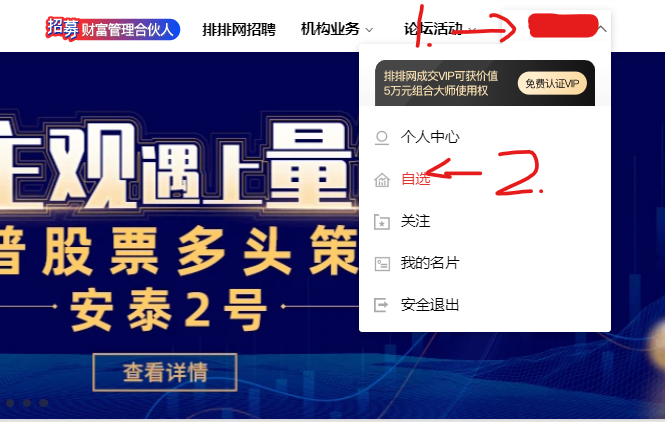
滑鼠懸停在用戶上,然后點擊自選進入網頁,
time.sleep(5) # 加載網頁需要等待時間
mouse = driver.find_element(By.XPATH,'//div[@class="comp-header-nav-item fz14"]/div/span[@class="ellipsis"]')
ActionChains(driver).move_to_element(mouse).perform() # 懸停滑鼠在名片
driver.find_element(By.XPATH,'//a[@class="comp-header-user-item icon-trade"]').click() # 點擊自選
這里的懸停操作就是定位用戶然后使用 ActionChains 進行懸停,在懸停中找到自選并點擊,
4. 決議網頁
經歷以上的步驟就來到了我們需要爬取資料的頁面了,我們需要的資料在每一個基金里面的歷史凈值,所以我們先要得到每一個基金的網址,然后進入網站里面進行處理,
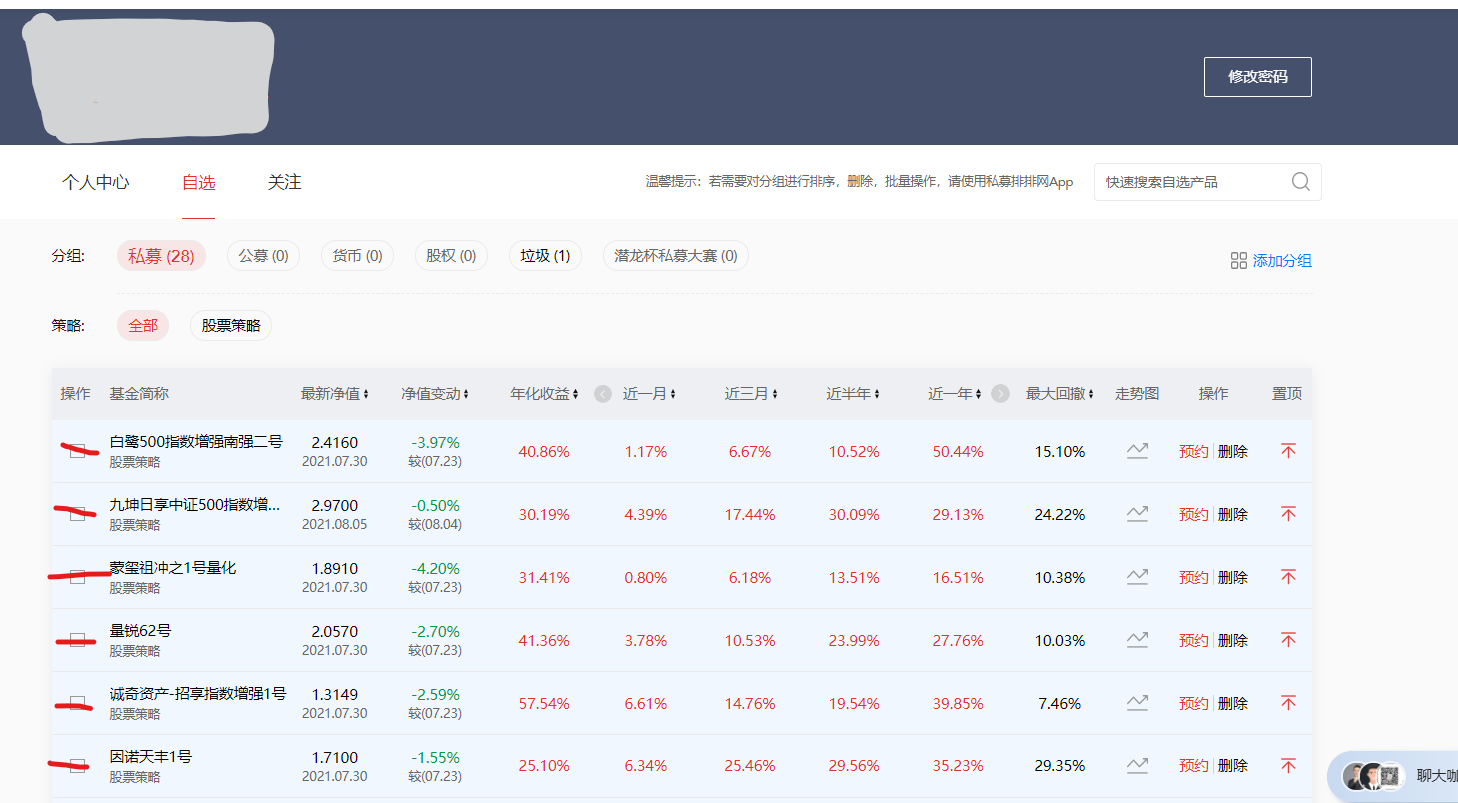
# 決議網頁
page = driver.page_source
soup = BeautifulSoup(page,'html.parser')
list_url = [] # 用于保存目標網站
list_name = [] # 用于保存目標名稱
url_a = soup.select('div:nth-child(2) > div.shortName > a') # 找到所爬取的網頁
names = soup.select('div> div > div:nth-child(2) > div.shortName > a') # 找到名稱
for u in url_a:
url = u['href'] # 得到網站
list_url.append(url)
for name in names:
list_name.append(name.get_text())
這里使用了 BeautifulSoup 對 page 進行決議,然后使用 select 定位找到每個基金的網址和基金名稱,如果,有這個網站的爬蟲需求可以聯系我!這篇文章為上篇,下次繼續!
AI悅創·推出輔導班啦,包括「Python 語言輔導班、C++輔導班、演算法/資料結構輔導班、少兒編程、pygame 游戲開發」,全部都是一對一教學:一對一輔導 + 一對一答疑 + 布置作業 + 專案實踐等,QQ、微信在線,隨時回應!V:Jiabcdefh

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293820.html
標籤:其他
上一篇:工控機在物聯網中的應用有哪些?