文章目錄
- 如何解決高并發、限流、資料同步問題
- 1、如何解決高并發
- 2、OpenResty
- 2.1、安裝openresty
- 3、廣告快取的載入與讀取
- 3.1、Lua+nginx配置
- 3.2、Lua+nginx配置(從redis中獲取資料)
- 3.3、添加openresty快取
- 4、限流配置
- 4.1、控制速率
- 4.2、控制并發量(連接數)
- 5、資料同步的問題
- 5.1、配置master Mysql(開啟binlog模式)
- 5.2、canal的安裝
- 5.3、canal微服務的搭建
- 5.4、邏輯分析
- 5.5、代碼撰寫
如何解決高并發、限流、資料同步問題
1、如何解決高并發
? 在開發一個專案的時候,首頁門戶系統需要展示各種各樣的資料,如京東:

? 這些資料通常為變更頻率低的資料,但是訪問量卻很高,我們可以利用多級快取來解決這個問題,當然了也可以讓網頁做為靜態頁面,但是這樣要是前端的資料需要進行變動,就需要將服務關閉,然后進行代碼的修改,這樣對用戶的體驗是極度不友好的,
? 按照我們的一般的思路,那么我們一般的服務結構是這么設計的:
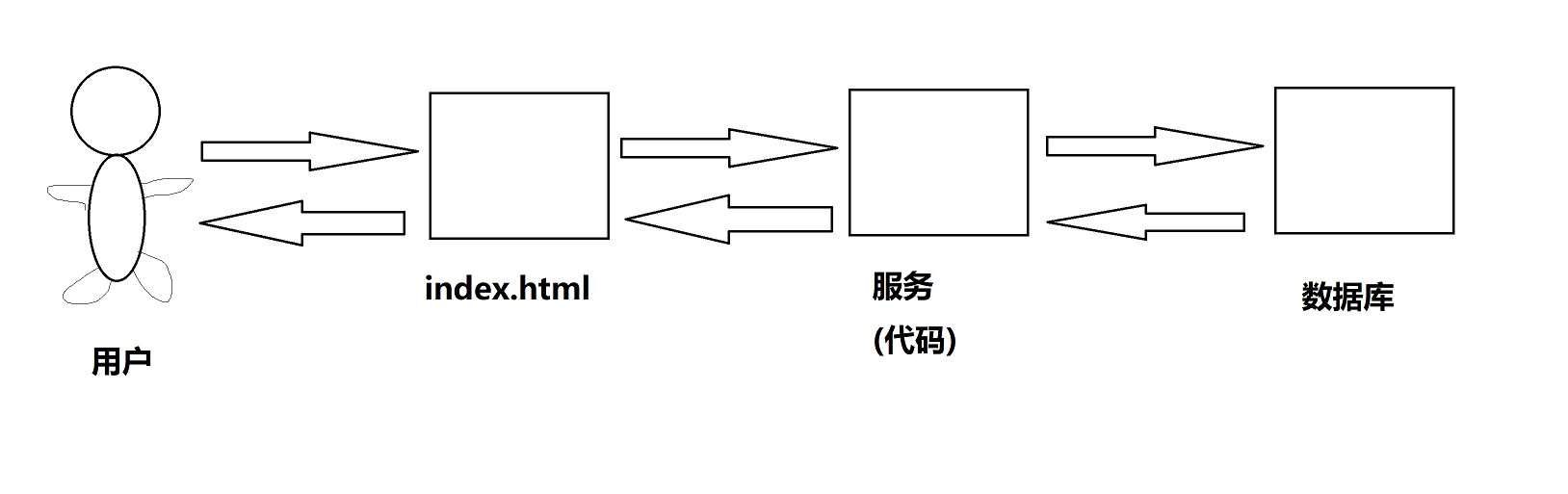
? 但是由于首頁的資料一般不會有太頻繁的改動,所以對于用戶的每一次請求都要去資料庫進行查詢訪問是不太好的行為,所以我們可以利用快取的方式,
設計思路:
1.首先訪問nginx ,我們可以采用快取的方式,先從nginx本地快取中獲取,獲取到直接回應
2.如果沒有獲取到,再次訪問redis,我們可以從redis中獲取資料,如果有 則回傳,并快取到nginx中
3.如果沒有獲取到,再次訪問mysql,我們從mysql中獲取資料,再將資料存盤到redis中,回傳,
當然了,要是我們中間的邏輯使用java語言進行邏輯代碼的撰寫,也是對速度來說有著一定的損失,因為當請求來到了之后,要經過servlet、spring、我們的controller層、service層、以及Dao層,最后還需要去操作資料庫,這都是需要消耗時間的,這個時候我們可以利用LUA語言嵌入到程式中查詢相關的業務,
至于什么是LUA語言,可以查看:Lua語言基礎
? 我們在使用SpringBoot開發時,Tomcat服務器所支持的并發量通常為300-500,而nginx的并發量正常情況下為2-3萬,但是OpenResty可以 快速構造出足以勝任 10K 以上并發連接回應的超高性能 Web 應用系統,
2、OpenResty
OpenResty(又稱:ngx_openresty) 是一個基于 nginx的可伸縮的 Web 平臺,由中國人章亦春發起,提供了很多高質量的第三方模塊,
OpenResty 是一個強大的 Web 應用服務器,Web 開發人員可以使用 Lua 腳本語言調動 Nginx 支持的各種 C 以及 Lua 模塊,更主要的是在性能方面,OpenResty可以 快速構造出足以勝任 10K 以上并發連接回應的超高性能 Web 應用系統,
360,UPYUN,阿里云,新浪,騰訊網,去哪兒網,酷狗音樂等都是 OpenResty 的深度用戶,
OpenResty 簡單理解成 就相當于封裝了nginx,并且集成了LUA腳本,開發人員只需要簡單的其提供了模塊就可以實作相關的邏輯,而不再像之前,還需要在nginx中自己撰寫lua的腳本,再進行呼叫了,
2.1、安裝openresty
linux安裝openresty:
1.添加倉庫執行命令
yum install yum-utils
yum-config-manager --add-repo https://openresty.org/package/centos/openresty.repo
2.執行安裝
yum install openresty
3.安裝成功后 會在默認的目錄如下:
/usr/local/openresty
3、廣告快取的載入與讀取
3.1、Lua+nginx配置
需求:利用lua+nginx配置,nginx為入口,用戶訪問后,將mysql中的資料通過lua腳本存入到redis資料庫中
實作思路:
- 連接mysql,按照廣告的分類id讀取廣告串列,裝換為json字串
- 連接redis,將廣告串列json字串存入redis中,
在一個目錄下創建一個lua腳本檔案,在我這里為/root/lua下創建update_content,目的就是連接mysql,查詢資料,并存盤到redis中,
lua腳本代碼如下:
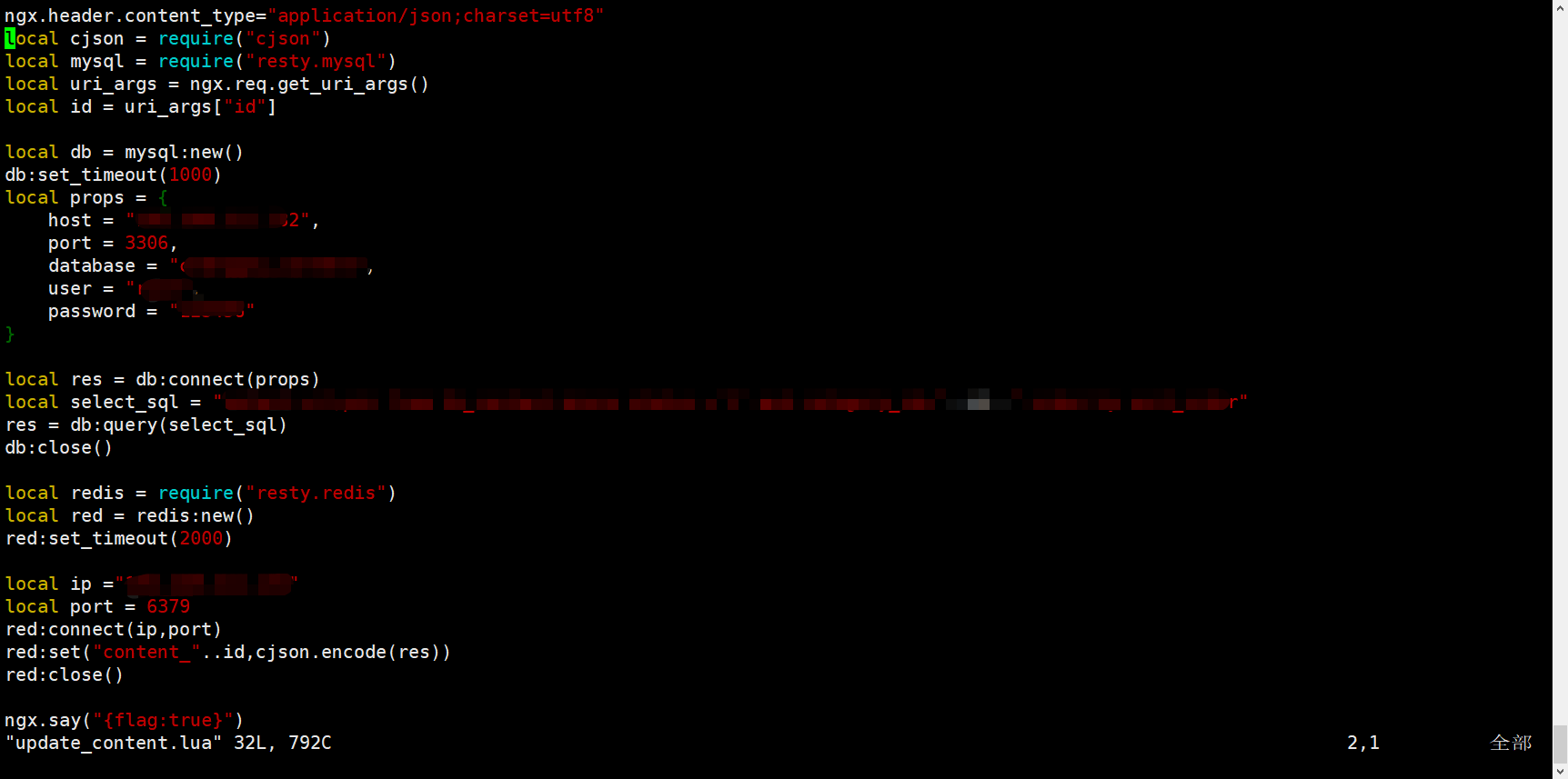
代碼:
ngx.header.content_type="application/json;charset=utf8" -- 將請求頭中的資料轉為json格式
local cjson = require("cjson") -- 引入cjson
local mysql = require("resty.mysql") -- 引入mysql
local redis = require("resty.redis")
local uri_args = ngx.req.get_uri_args() -- 獲取uri的引數
local id = uri_args["id"] -- 獲取請求中的id引數
local db = mysql:new() -- 創建MySQL連接
db:set_timeout(1000) -- 設定超市時間
local props = {
host = "ip_address",
port = 3306,
database = "database",
user = "root",
password = "123456"
}
local res = db:connect(props)
local select_sql = "select url,pic from table where status ='1' and category_id="..id.." order by sort_order"
res = db:query(select_sql) -- 執行sql陳述句
db:close()
local red = redis:new()
red:set_timeout(2000)
local ip ="ip_address"
local port = 6379
red:connect(ip,port)
red:set("content_"..id,cjson.encode(res)) -- 存入redis中
red:close()
ngx.say("{flag:true}")
此時,我們在nginx中的配置如下:

在需要的服務中添加頭資訊,和 location資訊(也就是lua腳本的路徑)
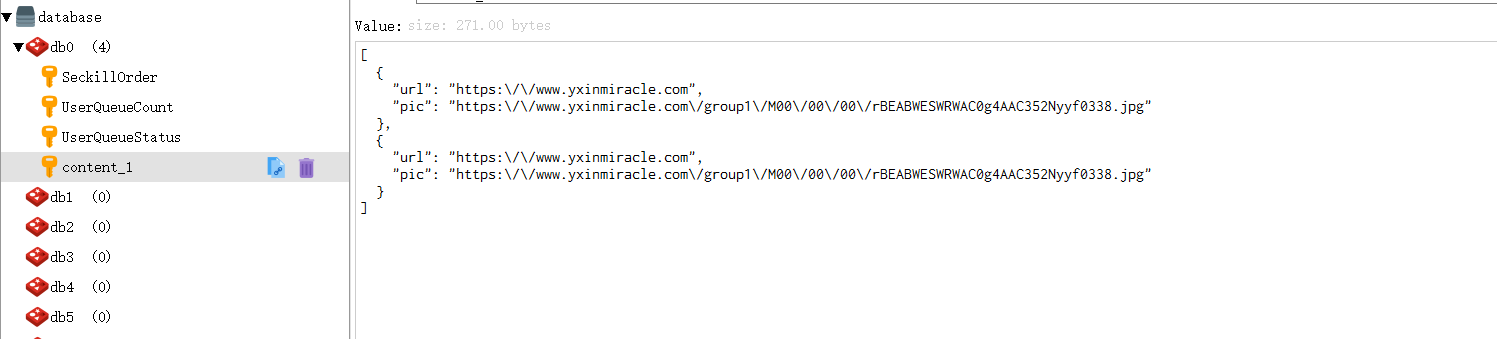
此時我們可以訪問該路徑,看看資料是否存入到了redis中,這里我們使用redis遠程連接客戶端進行查看,查看之前redis資料庫中資料:
此時訪問路徑ipaddress/update_content/?id=1
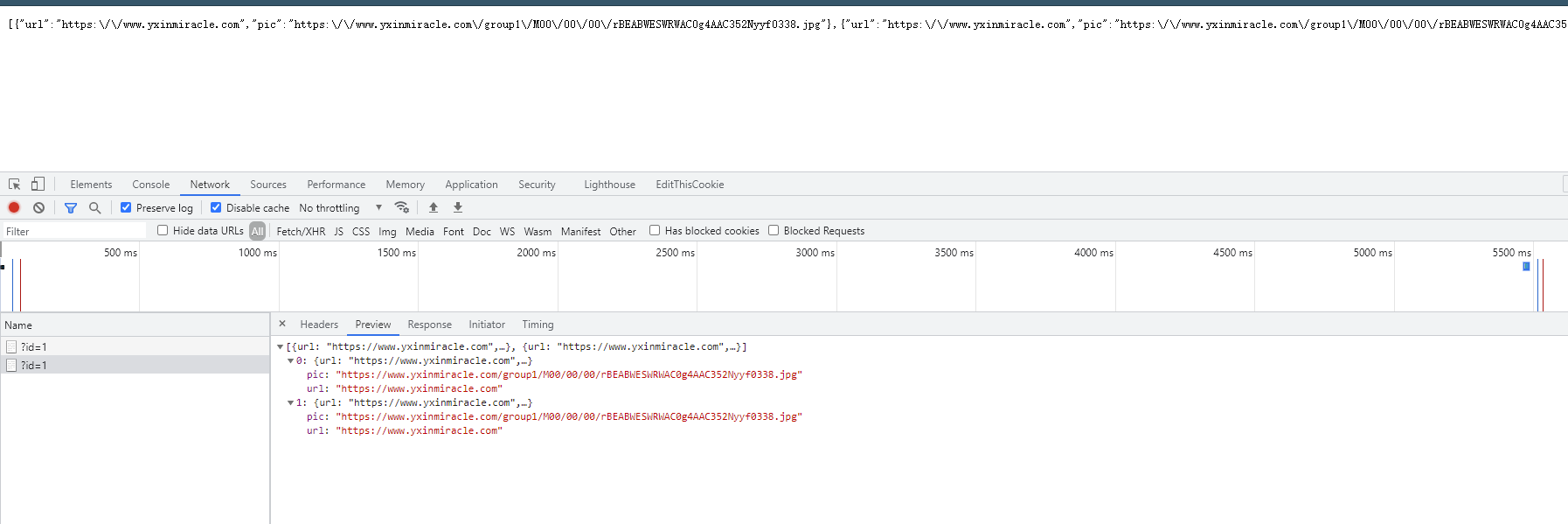
此時訪問后放回資料為:

此時資料庫的資料為:
3.2、Lua+nginx配置(從redis中獲取資料)
? 此時我們通過3.1步我們可以將資料從mysql中取出來然后放入redis中
? 這一步我們需要將redis中的資料取出來,然后回傳給前端,
? 在/root/lua目錄下創建read_content.lua:
--設定回應頭型別
ngx.header.content_type="application/json;charset=utf8"
--獲取請求中的引數ID
local uri_args = ngx.req.get_uri_args();
local id = uri_args["id"];
--引入redis庫
local redis = require("resty.redis");
--創建redis物件
local red = redis:new()
--設定超時時間
red:set_timeout(2000)
--連接
local ok, err = red:connect("ipaddr", 6379)
--獲取key的值
local rescontent=red:get("content_"..id)
--輸出到回傳回應中
ngx.say(rescontent)
--關閉連接
red:close()
? 同樣的,我們需要配置nginx中的服務配置:
location /read_content{
content_by_lua_file /root/lua/read_content.lua;
}
? 此時我們訪問路徑ipaddress/read_content?id=1
? 回傳的資料為:

? 也就是我們剛剛的從mysql中讀出來的資料,
3.3、添加openresty快取
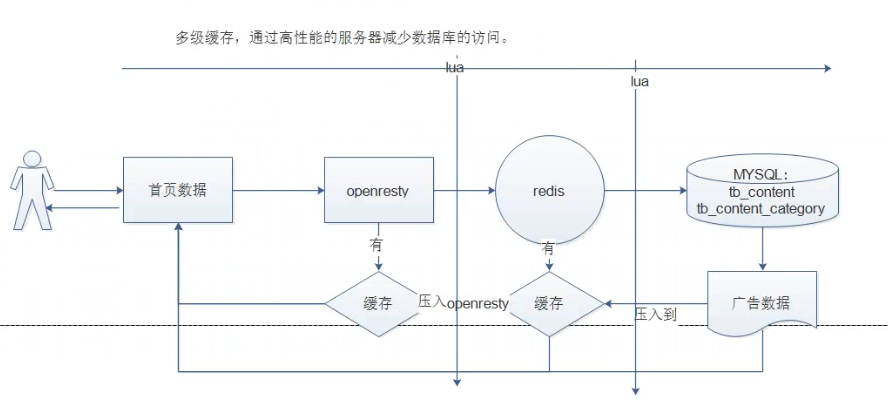
如上的方式沒有問題,但是如果請求都到redis,redis壓力也很大,所以我們一般采用多級快取的方式來減少下游系統的服務壓力,參考基本思路圖的實作,
先查詢openresty本地快取(需要開啟) 如果 沒有
lua_shared_dict dis_cache 128m; #nginx服務外配置 定義lua快取命名空間極其大小
再查詢redis中的資料,如果沒有
再查詢mysql中的資料,但凡有資料 則回傳即可,
修改read_content.lua檔案,代碼如下:
ngx.header.content_type="application/json;charset=utf8"
local uri_args = ngx.req.get_uri_args();
local id = uri_args["id"];
--獲取本地快取
local cache_ngx = ngx.shared.dis_cache;
--根據ID 獲取本地快取資料
local contentCache = cache_ngx:get('content_cache_'..id);
if contentCache == "" or contentCache == nil then -- 如果在本地快取中沒有找到資料
local redis = require("resty.redis");
local red = redis:new()
red:set_timeout(2000)
red:connect("ipaddr", 6379)
local rescontent=red:get("content_"..id);
if ngx.null == rescontent then -- redis中沒有資料
local cjson = require("cjson");
local mysql = require("resty.mysql");
local db = mysql:new();
db:set_timeout(2000)
local props = {
host = "ipaddr",
port = 3306,
database = "database",
user = "username",
password = "password"
}
local res = db:connect(props);
local select_sql = "select url,pic from table where status ='1' and category_id="..id.." order by sort_order";
res = db:query(select_sql);
local responsejson = cjson.encode(res);
red:set("content_"..id,responsejson);
ngx.say(responsejson);
db:close()
else -- redis中有資料,存入本地快取中,時長為10分鐘
cache_ngx:set('content_cache_'..id, rescontent, 10*60);
ngx.say(rescontent)
end
red:close()
else -- 如果本地快取中有資料,那么直接回傳
ngx.say(contentCache)
end
這個時候我們來訪問一下
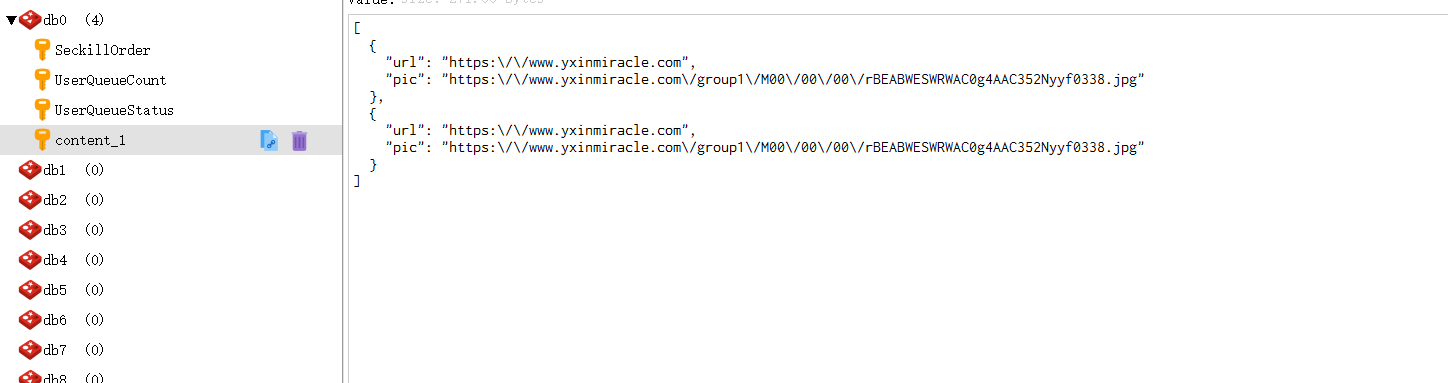
ipaddress/update_content?id=1
此時redis中的資料:什么都沒有

訪問后:
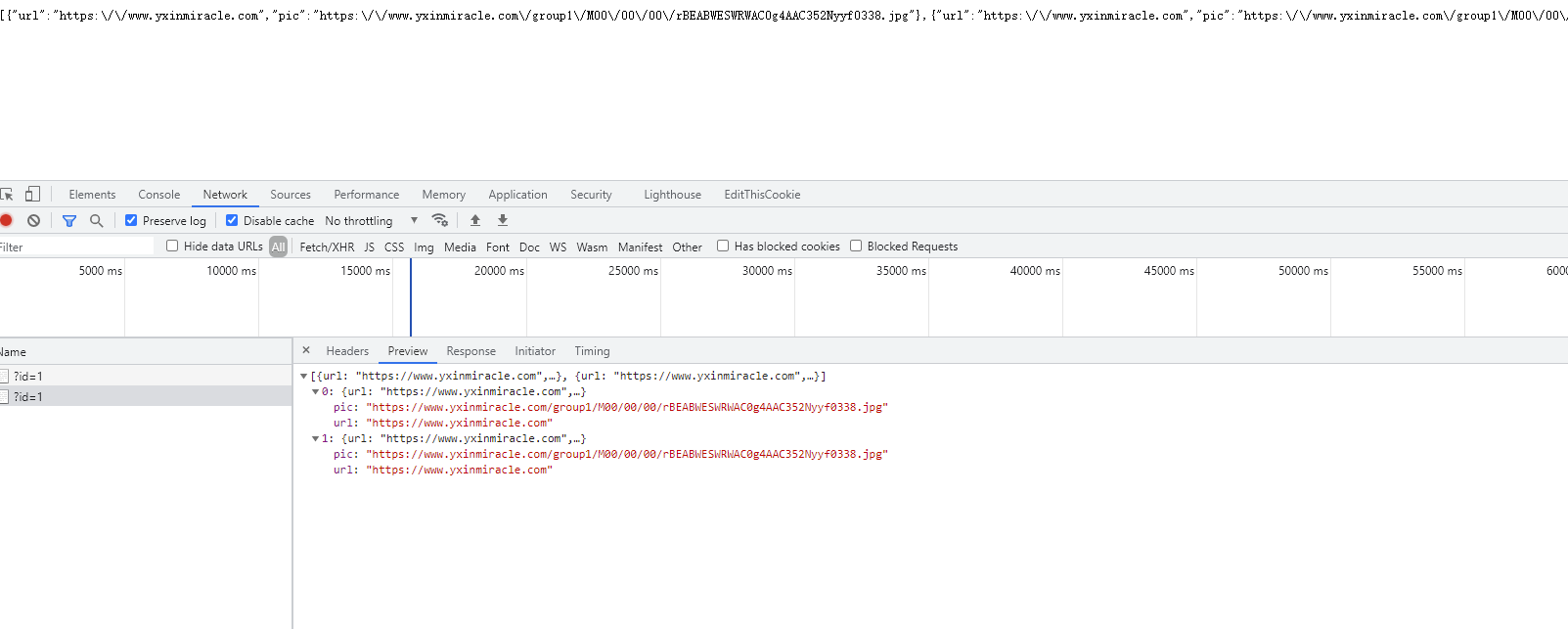
ipaddress/read_content?id=1
訪問完update_content的連接后,接下來應該就是從redis中取出資料了,我們可以訪問該鏈接:
? 此時我們可以將redis中的資料洗掉,那么他應該就是從openresty中的快取中拿取資料:
? 再次進行訪問:
? 還是能獲取到資料:
4、限流配置
一般情況下,首頁的并發量是比較大的,即使 有了多級快取,當用戶不停的重繪頁面的時候,也是沒有必要的,另外如果有惡意的請求 大量達到,也會對系統造成影響,
而限流就是保護措施之一,
nginx提供兩種限流的方式:
-
一是控制速率
-
二是控制并發連接數
4.1、控制速率
控制速率的方式之一就是采用漏桶演算法,
(1)漏桶演算法實作控制速率限流
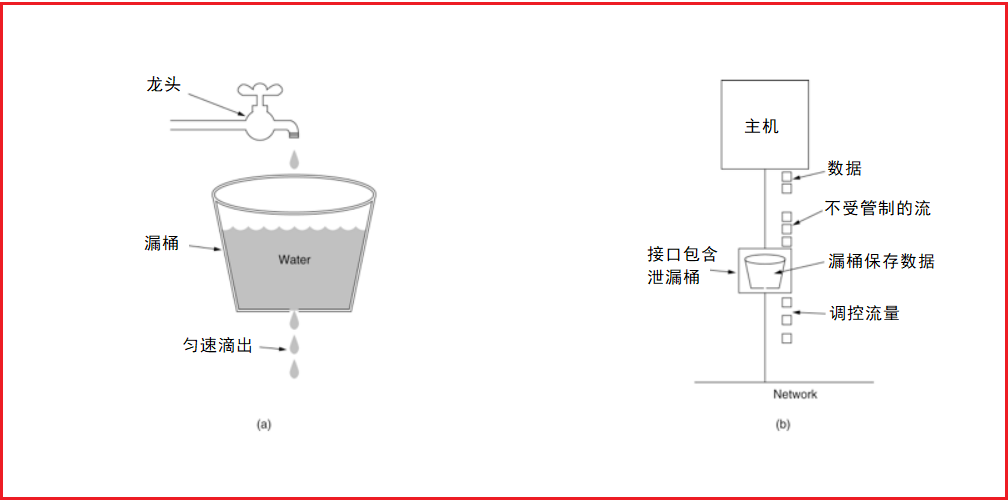
漏桶(Leaky Bucket)演算法思路很簡單,水(請求)先進入到漏桶里,漏桶以一定的速度出水(介面有回應速率),當水流入速度過大會直接溢位(訪問頻率超過介面回應速率),然后就拒絕請求,可以看出漏桶演算法能強行限制資料的傳輸速率.示意圖如下:
(2)nginx的配置
配置示意圖如下:
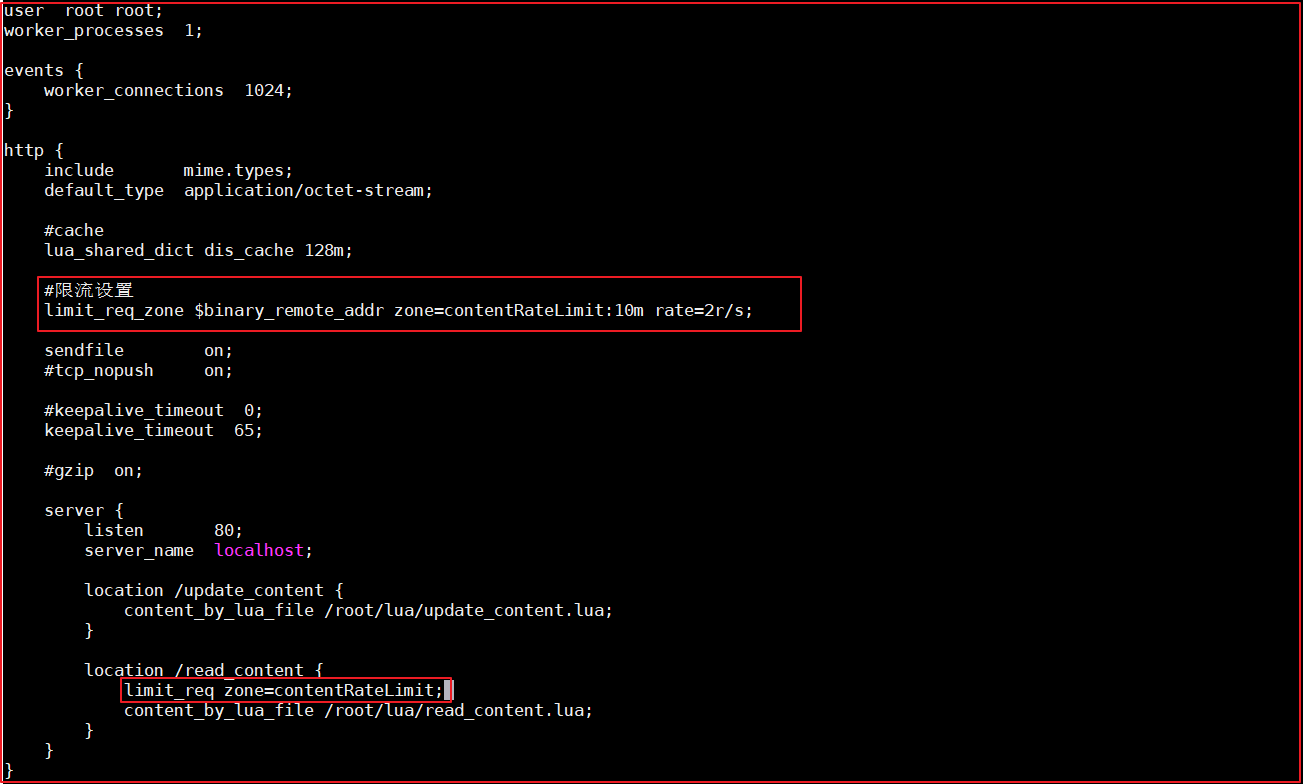
修改/usr/local/openresty/nginx/conf/nginx.conf:
user root root;
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
#cache
lua_shared_dict dis_cache 128m;
#限流設定
limit_req_zone $binary_remote_addr zone=contentRateLimit:10m rate=2r/s;
sendfile on;
#tcp_nopush on;
#keepalive_timeout 0;
keepalive_timeout 65;
#gzip on;
server {
listen 80;
server_name localhost;
location /update_content {
content_by_lua_file /root/lua/update_content.lua;
}
location /read_content {
#使用限流配置
limit_req zone=contentRateLimit;
content_by_lua_file /root/lua/read_content.lua;
}
}
}
配置說明:
binary_remote_addr 是一種key,表示基于 remote_addr(客戶端IP) 來做限流,binary_ 的目的是壓縮記憶體占用量,
zone:定義共享記憶體區來存盤訪問資訊, contentRateLimit:10m 表示一個大小為10M,名字為contentRateLimit的記憶體區域,1M能存盤16000 IP地址的訪問資訊,10M可以存盤16W IP地址訪問資訊,
rate 用于設定最大訪問速率,rate=10r/s 表示每秒最多處理10個請求,Nginx 實際上以毫秒為粒度來跟蹤請求資訊,因此 10r/s 實際上是限制:每100毫秒處理一個請求,這意味著,自上一個請求處理完后,若后續100毫秒內又有請求到達,將拒絕處理該請求.我們這里設定成2 方便測驗,
測驗:
我們可以限制給注釋掉再看看,
這就很大程度上進行了限流
(3)處理突發流量
上面例子限制 2r/s,如果有時正常流量突然增大,超出的請求將被拒絕,無法處理突發流量,可以結合 burst 引數使用來解決該問題,
例如,如下配置表示:
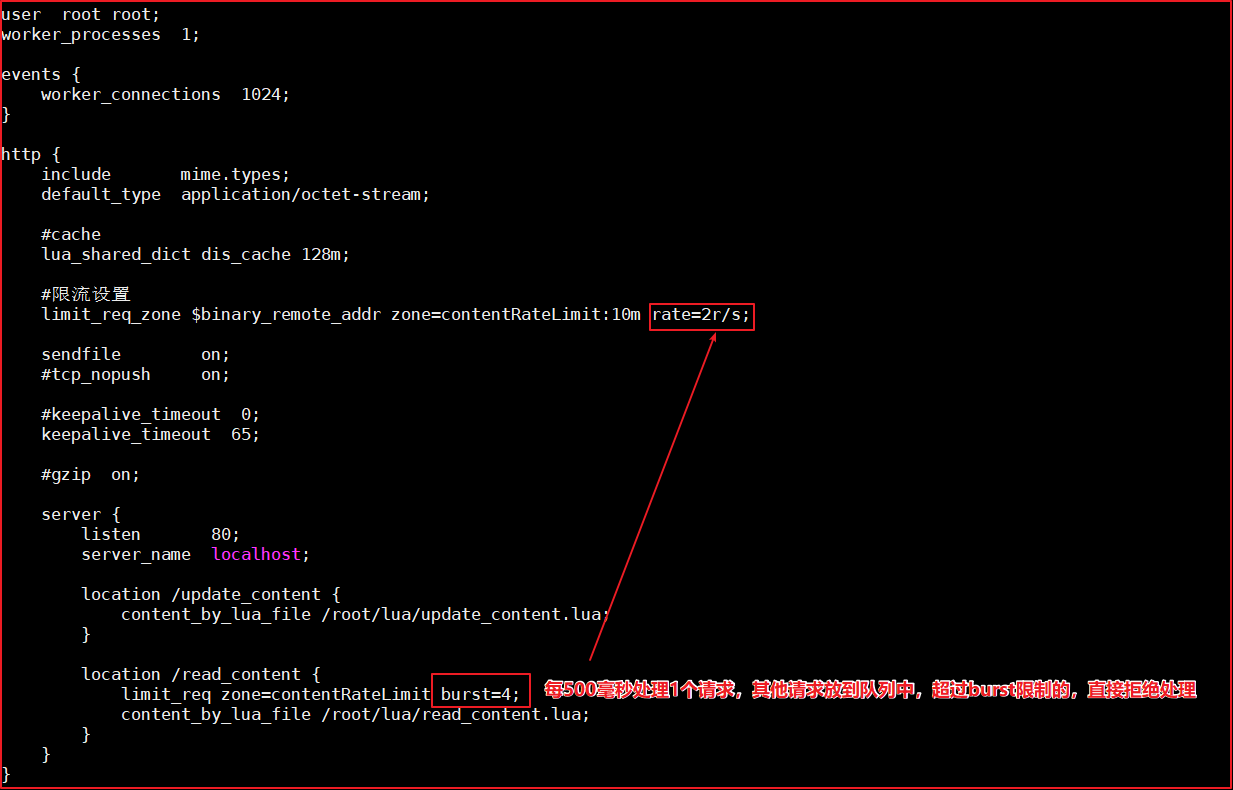
上圖代碼如下:
server {
listen 80;
server_name localhost;
location /update_content {
content_by_lua_file /root/lua/update_content.lua;
}
location /read_content {
limit_req zone=contentRateLimit burst=4;
content_by_lua_file /root/lua/read_content.lua;
}
}
burst 譯為突發、爆發,表示在超過設定的處理速率后能額外處理的請求數,當 rate=2r/s 時,將1s拆成2份,即每500ms可處理1個請求,
此處,**burst=4 **,若同時有4個請求到達,Nginx 會處理第一個請求,剩余3個請求將放入佇列,然后每隔500ms從佇列中獲取一個請求進行處理,若請求數大于4,將拒絕處理多余的請求,直接回傳503.
現象解釋:
? 之所以會出現前六個中會有五個訪問不成功,是因為我們設定了**burst=4 **,nginx處理了第一個請求之后,再將剩余3個請求將放入佇列,其余的請求每隔500ms從佇列中獲取一個請求進行處理,

不過,單獨使用 burst 引數并不實用,假設 burst=50 ,rate依然為10r/s,排隊中的50個請求雖然每100ms會處理一個,但第50個請求卻需要等待 50 * 100ms即 5s,這么長的處理時間自然難以接受,等待時間太久了,
因此,burst 往往結合 nodelay 一起使用,
例如:如下配置:
server {
listen 80;
server_name localhost;
location /update_content {
content_by_lua_file /root/lua/update_content.lua;
}
location /read_content {
limit_req zone=contentRateLimit burst=4 nodelay;
content_by_lua_file /root/lua/read_content.lua;
}
}
這下就是這個情況了,就不會出現延遲了:
4.2、控制并發量(連接數)
ngx_http_limit_conn_module 提供了限制連接數的能力,主要是利用limit_conn_zone和limit_conn兩個指令,
利用連接數限制 某一個用戶的ip連接的數量來控制流量,
注意:并非所有連接都被計算在內 只有當服務器正在處理請求并且已經讀取了整個請求頭時,才會計算有效連接,此處忽略測驗,
配置語法:
Syntax: limit_conn zone number;
Default: —;
Context: http, server, location;
(1)配置限制固定連接數
配置如下:
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
# 設定nginx快取 空間 為128M 快取物件名稱為dis_cache
lua_shared_dict dis_cache 128m;
limit_conn_zone $binary_remote_addr zone=addr:10m;
server {
listen 80;
server_name localhost;
location /brand/test{
limit_conn addr 2;
proxy_pass http://192.168.211.1:18081;
}
}
}
我們可以自己設定一個服務,該服務需要運行的時長為1s,然后nginx 反向代理到這個服務中:
@GetMapping("/test")
public Result testConne(){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
return new Result(true,StatusCode.OK,"ok");
}
表示:
limit_conn_zone $binary_remote_addr zone=addr:10m; 表示限制根據用戶的IP地址來顯示,設定存盤地址為的記憶體大小10M
limit_conn addr 2; 表示 同一個地址只允許連接2次,
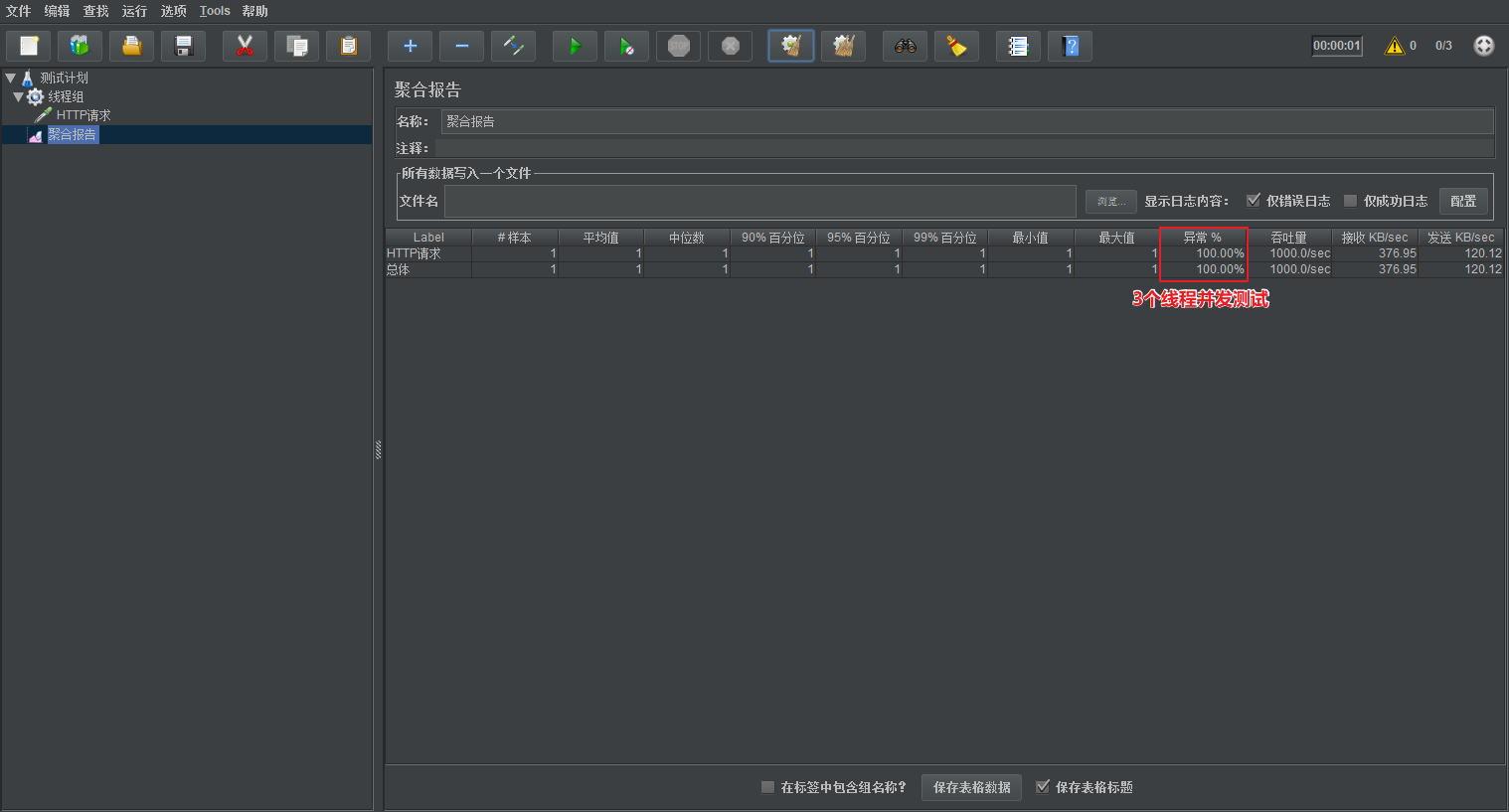
測驗:
此時開3個執行緒,測驗的時候會發生例外,開2個就不會有例外
5、資料同步的問題
? 如下圖所示,雖然高并發的問題是得到了相對應的解決,但是當我們的管理員去更改資料的時候,我們怎么才能讓redis知道我們已經改動了資料呢?所以這里就設計一個方法來處理我們的資料同步問題,
? 我們可以利用Mysql的主從,使用一個客戶端,讓主Mysql以為他是一個從Mysql,使用這個客戶端去讀取主Mysql的biglog,也就是二進制log,讓這個客戶端去監聽主mysql,然后我們再利用java微服務去監聽那些被修改的資料,要是監聽到資料被更改,那么就進行資料同步的處理,
? 主要的結構流程如下圖所示:
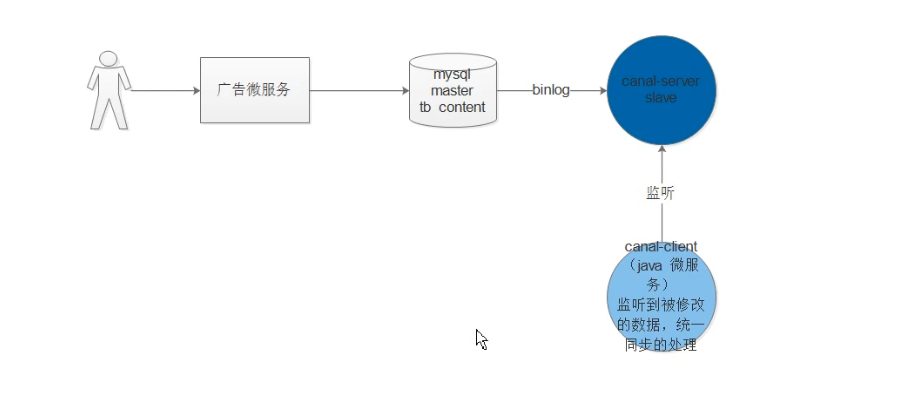
? 思路:
? 首先canal有兩個角色:
- canal-server 服務端 偽裝他自己是一個malserter的slave
- canal-client 客戶端 用來監聽canal-server客戶端(java的客戶端 處理資料以及業務邏輯)
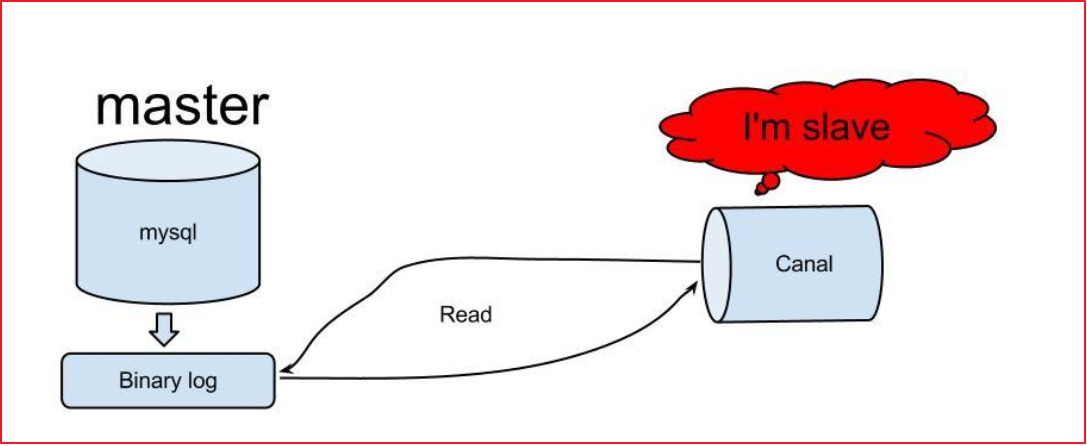
? canal搭建完之后的資料同步設計思路:
- 有個資料庫,是一個master(需要進行配置)
- canal-server 是slave(偽裝的)
- canal-client 進行監聽canal-server
- 一旦資料庫master發生資料的更新,canal-server就獲取到資料,canal-client監聽到資料變化,在客戶端中代碼實作,統一獲取到資料進行同步,
? 搭建canal并實作監聽資料的變化的步驟:
- mysql 需要開啟binlog(master角色)
- mysql 創建一個賬號 用于slave專門使用,授予權限slave的權限,進行遠程連接
- 通過docker 安裝canal-server
- 配置canal-server(配置,連接到的master的ip埠,以及自身的賬號和密碼以及要監聽的資料庫 和表有哪些)
- 搭建canal-client(java微服務:監聽canal-server 獲取被修改的資料,然后做業務處理:同步到redis中)
使用的是alibaba開發的專案:
canal [k?'n?l],譯意為水道/管道/溝渠,主要用途是基于 MySQL 資料庫增量日志決議,提供增量資料訂閱和消費
早期阿里巴巴因為杭州和美國雙機房部署,存在跨機房同步的業務需求,實作方式主要是基于業務 trigger 獲取增量變更,從 2010 年開始,業務逐步嘗試資料庫日志決議獲取增量變更進行同步,由此衍生出了大量的資料庫增量訂閱和消費業務,
專案地址:https://github.com/alibaba/canal
5.1、配置master Mysql(開啟binlog模式)
(1) 連接到mysql中,并修改/etc/mysql/mysql.conf.d/mysqld.cnf 需要開啟主 從模式,開啟binlog模式,
執行如下命令,編輯mysql組態檔

命令列如下:
docker exec -it mysql /bin/bash
cd /etc/mysql/mysql.conf.d
vi mysqld.cnf
修改mysqld.cnf組態檔,添加如下配置:
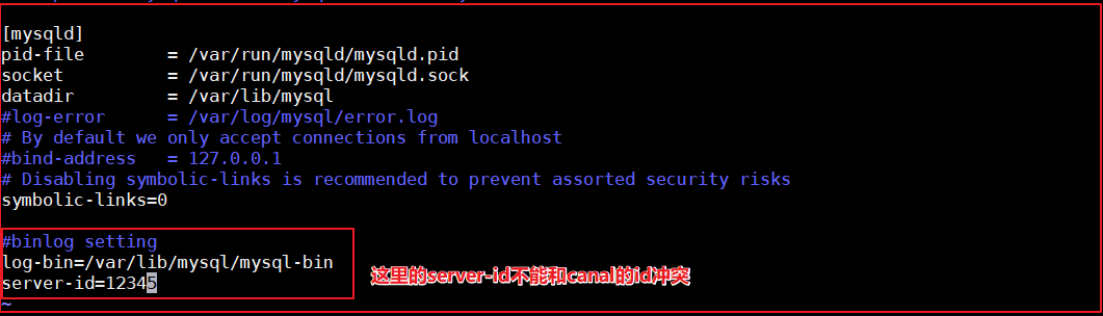
上圖配置如下:
log-bin=/var/lib/mysql/mysql-bin
server-id=12345
(2) 創建賬號 用于測驗使用,
使用root賬號創建用戶并授予權限
create user canal@'%' IDENTIFIED by 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;
(3)重啟mysql容器
docker restart mysql
5.2、canal的安裝
下載鏡像:
docker pull docker.io/canal/canal-server
容器安裝
docker run -p 11111:11111 --name canal -d docker.io/canal/canal-server
進入容器,修改核心配置canal.properties 和instance.properties,canal.properties 是canal自身的配置,instance.properties是需要同步資料的資料庫連接配置,
執行代碼如下:
docker exec -it canal /bin/bash
cd canal-server/conf/
vi canal.properties
cd example/
vi instance.properties
修改canal.properties的id,不能和mysql的server-id重復,如下圖:

修改instance.properties,配置資料庫連接地址:
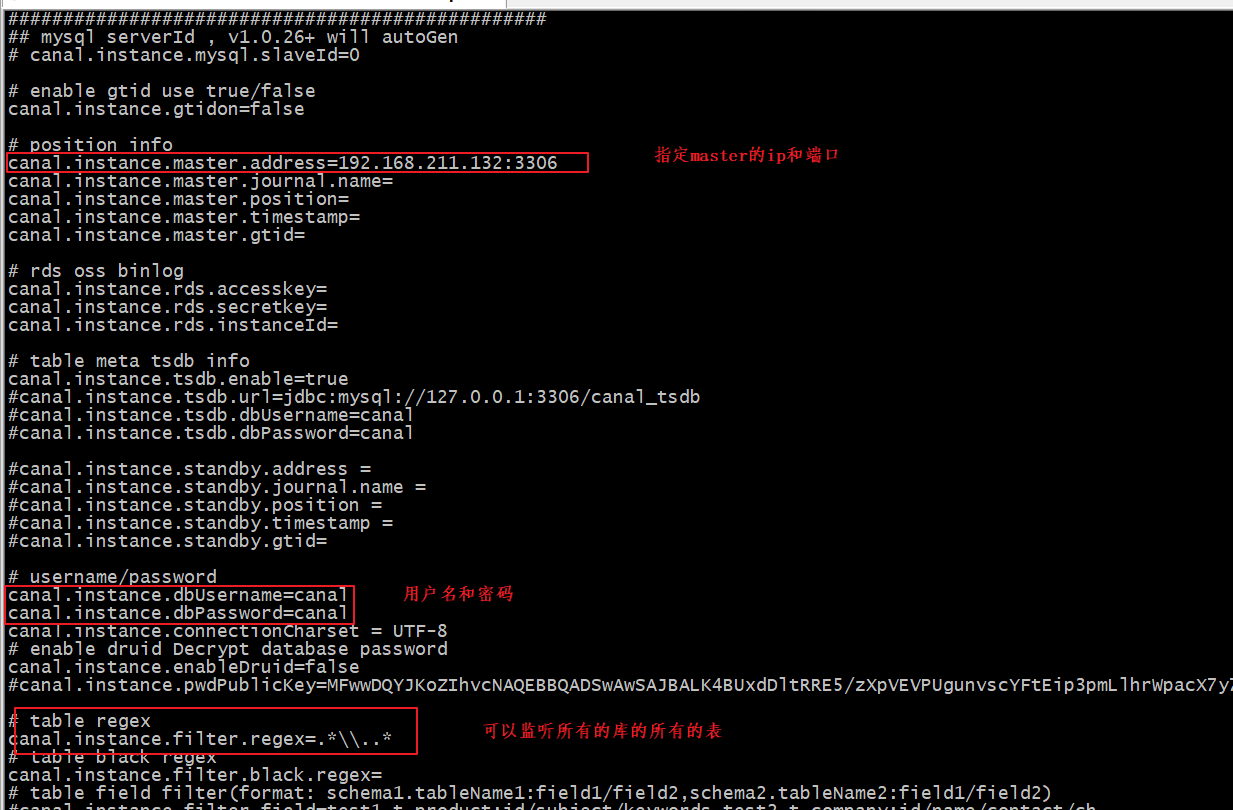
? 這里的canal.instance.filter.regex有多種配置,如下:
? 可以參考地址如下:
https://github.com/alibaba/canal/wiki/AdminGuide
mysql 資料決議關注的表,Perl正則運算式.
多個正則之間以逗號(,)分隔,轉義符需要雙斜杠(\\)
常見例子:
1. 所有表:.* or .*\\..*
2. canal schema下所有表: canal\\..*
3. canal下的以canal打頭的表:canal\\.canal.*
4. canal schema下的一張表:canal.test1
5. 多個規則組合使用:canal\\..*,mysql.test1,mysql.test2 (逗號分隔)
注意:此過濾條件只針對row模式的資料有效(ps. mixed/statement因為不決議sql,所以無法準確提取tableName進行過濾)
配置完成后,設定開機啟動,并記得重啟canal,
docker update --restart=always canal
docker restart canal
5.3、canal微服務的搭建
? 由于官方沒有提供springboot的依賴,我們就需要自定義起步依賴了,
? 也就是:https://github.com/chenqian56131/spring-boot-starter-canal
? 它主要提供了SpringBoot環境下canal的支持,我們需要先安裝該工程,在starter-canal目錄下執行mvn install,如下圖:
? 之后添加我們的啟動依賴:
<dependency>
<groupId>com.xpand</groupId>
<artifactId>starter-canal</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
? 在啟動類中啟動canal注解:
@SpringBootApplication(exclude = DataSourceAutoConfiguration.class)
@EnableEurekaClient
@EnableCanalClient //在啟動類中啟動canal注解
@EnableFeignClients(basePackages = "com.yxinmiracle.content.feign")
public class CanalApplication {
public static void main(String[] args) {
SpringApplication.run(CanalApplication.class,args);
}
}
? 撰寫組態檔:
server:
port: 18083
spring:
application:
name: canal
redis:
host: 192.168.211.132
port: 6379
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:7001/eureka
instance:
prefer-ip-address: true
feign:
hystrix:
enabled: true
ribbon:
eager-load:
enabled: true
ReadTimeout: 100000
#canal配置
canal:
client:
instances:
example:
host: 192.168.211.132
port: 11111
? 業務代碼:
@CanalEventListener
public class MyEventListener {
@InsertListenPoint
public void onEvent(CanalEntry.EventType eventType, CanalEntry.RowData rowData) {
//do something...
}
@UpdateListenPoint
public void onEvent1(CanalEntry.RowData rowData) {
//do something...
}
@DeleteListenPoint
public void onEvent3(CanalEntry.EventType eventType) {
//do something...
}
@ListenPoint(destination = "example", schema = "canal-test", table = {"t_user", "test_table"}, eventType = CanalEntry.EventType.UPDATE)
public void onEvent4(CanalEntry.EventType eventType, CanalEntry.RowData rowData) {
//do something...
}
}
? 測驗代碼(獲取更新之前的資料,以及更新之后的資料)
@UpdateListenPoint
public void onEvent1(CanalEntry.RowData rowData) {
//do something...
List<CanalEntry.Column> beforeColumnsList = rowData.getBeforeColumnsList();
for (CanalEntry.Column column : beforeColumnsList) {
System.out.println(column.getName()+" : "+column.getValue());
}
System.out.println("===================更新之后==================");
List<CanalEntry.Column> afterColumnsList = rowData.getAfterColumnsList();
for (CanalEntry.Column column : afterColumnsList) {
System.out.println(column.getName()+" : "+column.getValue());
}
}
? 其中需要注意的是:這個canal微服務啟動可能會報錯,原因是他有參考資料庫的依賴,但是并沒有連接資料庫,所以我們需要進行排除,也就是在啟動類上加上注解:
@SpringBootApplication(exclude = DataSourceAutoConfiguration.class)
5.4、邏輯分析
- 當table被人寫了之后
- canal-server端監聽到了資料變化
- canal-client監聽資料,并獲得被修改的那個行記錄中的id,執行一個sql陳述句獲取那一行的資料
- 通過feign呼叫content微服務獲取到最新的資料
- 先根據id查看redis中有無這個資料的值,如果有,那么就將那個條資料覆寫,如果沒有,就直接添加
5.5、代碼撰寫
? 這里我們使用ListenPoint的方法
? 代碼:
/**
* destination 是linux中的目錄 也是目的地址
* schema 資料庫的庫名
* table 要監聽的表名
*
* @param eventType
* @param rowData
*/
@ListenPoint(destination = "example",
schema = "database",
table = {"tb_content",
"tb_content_category"},
eventType = {CanalEntry.EventType.UPDATE,
CanalEntry.EventType.DELETE,
CanalEntry.EventType.INSERT}
)
public void onEventCustomUpdate(CanalEntry.EventType eventType, CanalEntry.RowData rowData) {
// 判斷
String categoryId = getColumnValue(eventType, rowData);
// 呼叫feign 獲取更新后的資料
Result<List<Content>> result = contentFeign.findByCategory(Long.valueOf(categoryId));
// 得到廣告資料
List<Content> data = result.getData();
// 存入redis中,進行資料覆寫
stringRedisTemplate.boundValueOps("content_"+categoryId).set(JSON.toJSONString(data));
}
/**
* 獲取categoryId
* @param eventType
* @param rowData
* @return
*/
private String getColumnValue(CanalEntry.EventType eventType, CanalEntry.RowData rowData){
// 1. 判斷如果是insert 和 update 那么就獲取after的資料
String categoryId = "";
if(eventType== CanalEntry.EventType.DELETE){
List<CanalEntry.Column> beforeColumnsList = rowData.getBeforeColumnsList();
for (CanalEntry.Column column : beforeColumnsList) {
if (column.getName().equals("category_id")) {
categoryId = column.getValue();
break;
}
}
}else { // 如果是洗掉,那么就獲取洗掉之前
List<CanalEntry.Column> afterColumnsList = rowData.getAfterColumnsList();
for (CanalEntry.Column column : afterColumnsList) {
if (column.getName().equals("category_id")) {
categoryId = column.getValue();
break;
}
}
}
return categoryId;
}
? 服務邏輯代碼:
@GetMapping("/list/category/{id}")
public Result<List<Content>> findByCategory(@PathVariable(name = "id" ) Long id){
Content content = new Content();
content.setCategoryId(id);
List<Content> contentList = contentService.select(content);
return new Result<>(true, StatusCode.OK,"獲取串列成功",contentList);
}
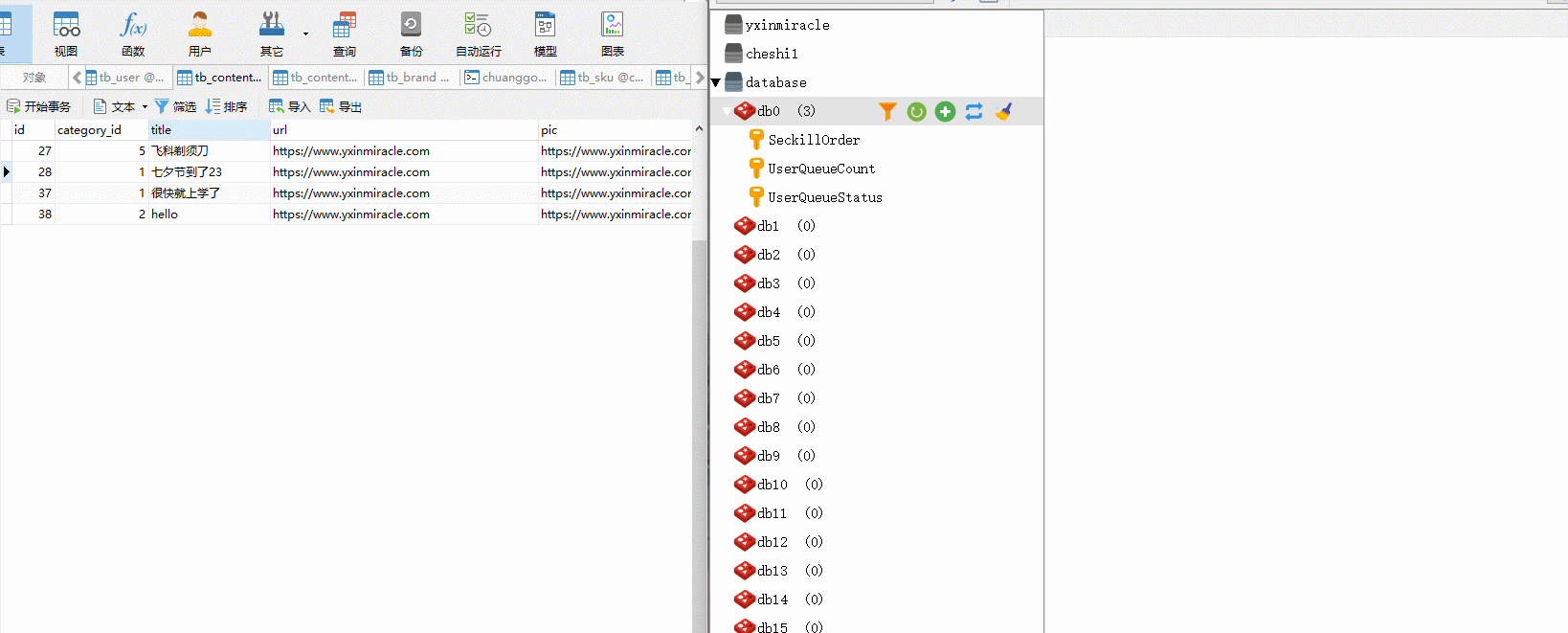
? 測驗:
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293845.html
標籤:其他
上一篇:2021-08-12虛擬機堆疊
下一篇:http_load的安裝與使用