什么是資訊收集
資訊收集主要是收集服務器的配置資訊和網站的敏感資訊,主要包括域名資訊、子域名資訊、目標網站資訊、目標網站真實IP、目錄檔案、開放埠和服務、中間件資訊等等,在進行滲透測驗之前,第一步也是非常關鍵的一步就是對目標進行資訊收集,我們盡可能收集關于目標的資訊,這將會大大提高發現漏洞的概率,
資訊收集大致分類
第一類:主動資訊收集,通過直接訪問、掃描網站
第二類:被動資訊收集,利用第三方的服務對目標進行訪問了解,比例:谷歌搜索、Shodan搜索等等
Whois
在進行網站注冊的時候,需要申請域名,申請之后這些注冊的資訊將會保存到相關的域名資料庫服務器中,并且這些域名資訊經常是公開的,任何人都可以查詢,
Whois就是一個用于查詢域名是否已經被注冊,如果以及注冊,可以查詢相關資訊的資料庫(注冊人姓名、注冊人的E-mail、電話號、注冊機構、通信地址、郵編、注冊有效時間、失效時間查詢等等),然后利用谷歌的語法搜索,搜索出關于域名的很多資訊,
1)利用網站
網站查詢:https://www.yougetsignal.com
站長之家:http://whois.chinaz.com
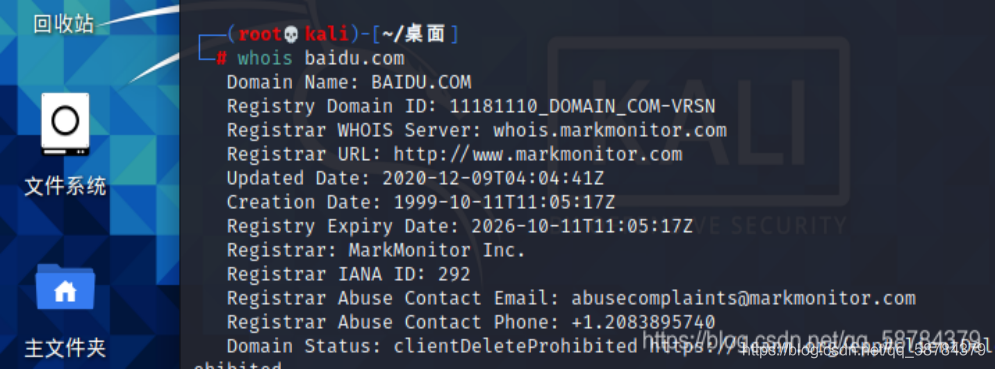
2)利用kali下自帶的whois
kali下的whois+域名
子域名探測
子域名也稱二級域名,當進行滲透測驗的時候,一些目標網站的規模比較大,主站會進行重點防御,安全性強,下手難度高,通過子域名探測,可以對目標網站下發現更多的域或子域,大大提高漏洞發現的概率,再通過這些子域,接近真正的目標,除了不太現實的手動探測外,一般使用工具進行挖掘,如Layer,subDomainsBrute,K8PortScan
一.工具
1)Layer子域名挖掘工具
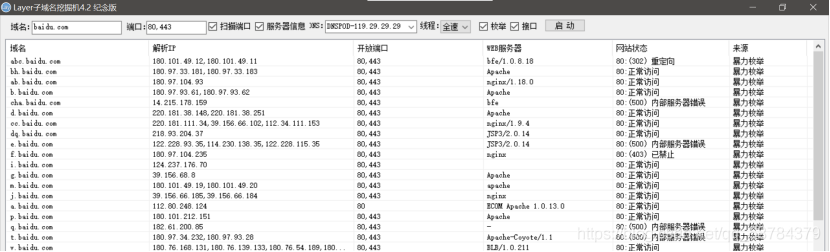
直接輸入域名,選擇要掃描的埠,設定執行緒即可,而且圖形化界面使用起來簡單快捷
2)subDomainsBrute lijiejie
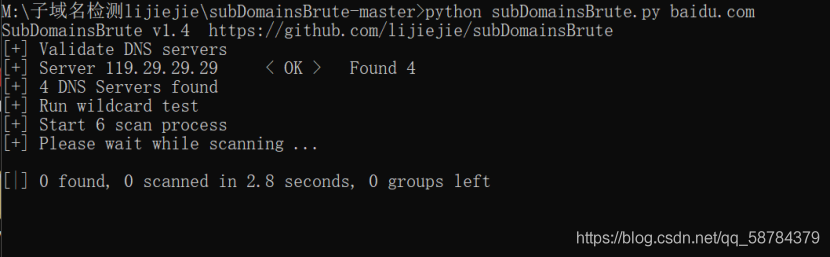
基本命令python subDomainsBrute.py baidu.com
掃描完成之后,在M:\子域名檢測lijiejie\subDomainsBrute-master\tmp下存放著掃描到的子域名
3)scanport

二.語法搜索
利用谷歌的語法搜索子域名
谷歌常用語法及其說明
| 關鍵字 | 說明 | 舉例 |
| site | 限制搜索范圍的域名 | site:edu.cn |
| inurl | URL中存在關鍵字的網頁 | Inurl:ganyu |
| intext | 搜索網頁<body>部分的關鍵字 | Intext:ganyu |
| filetype | 搜索檔案的特定后綴或者擴展名 | filetype:txt |
| intitle | 搜索網頁標題的關鍵字 | intitle:ganyu |
| link | 回傳所有與baidu.com做鏈接的URL | link:baidu.com |
| info | 查找指定站點的一些基本資訊 | Info:baidu |

CDN繞過
什么是CDN?
CDN全稱是Content Delivery Network(內容分發網路),用處是將源站內容分發存盤至各個節點,當用戶需求源站資源時,只需取得距用戶最近的一個節點,獲取所需內容,大大提高了用戶訪問時的回應速度,解決因分布距離、帶寬大小、服務器性能帶來的訪問延遲問題,其實就是將內容快取在終端用戶附近,
舉個例子,當用戶點擊網站的一個URL時,DNS會根據點擊的這個URL去尋求IP地址決議,如果網站開啟了CDN服務,會由CDN專用DNS服務器去處理這個IP,然后將CDN的全域負載均衡設備IP地址回傳用戶,用戶根據給的IP,訪問全域負載均衡,負載均衡按照用戶的URL,選擇一臺舉例用戶最近快取服務器,將這臺服務器的IP告訴用戶,用戶向快取服務器發起請求,最后將資源傳輸給用戶終端,
所以如果資訊收集目標開啟了CDN服務,雖然可以直接ping域名,但是得到的并非真正的IP,只是距離我們最近一臺目標節點的CND服務器IP,所以使得我們無法或者真實的IP地址,
一.判斷是否開啟了CDN繞過
1)在不同的地方ping同一個域名【有時候ping出的ip不唯一但是固定的幾個,可能未使用CDN而使用的是雙線,】
2)利用在線網站進行多地區ping http://ping.chinaz.com/
3)利用在線nslookup查詢,如果查詢多次發現返還的IP不同,說明開啟
二.繞過CDN,尋求真實IP
1)利用國外在線網站ping(利用國內CDN往往只是對國內用戶進行訪問加速的原理)
https://www.host-tracker.com
2)利用御劍CDN逆向IP查詢(簡潔高效)
3)利用一臺國外主機進行ping
埠探測
在滲透測驗中,對埠資訊的收集極為重要,服務器開了幾個埠,埠后面的服務是什么,這些都是十分關鍵的資訊,一個IP地址標識了一臺主機,而一臺主機可以提供多種服務,如web服務、ftp服務、SMTP 服務等,但是如果說IP地址與主機提供的服務是一對多的關系的話呢,光靠IP地址是不行的,這時就需要埠號進行區分,就好比一棟房子,我們得知道有哪些窗戶是打開或是閉合的,從哪里入手,因此埠探測就顯得尤為關鍵,
除了手動探測外,最常見的就是利用Nmap掃描、Zmap或者御劍進行掃描,
Namp的基本使用
主要作用
目標探測:探測目標主機
埠探測:探測目標開放埠
版本探測:探測目標主機的網路服務,名稱及版本號等等
腳本檢測:漏洞掃描、檢測病毒,入侵掃描等等
可以支持撰寫探測腳本或運行
同時可以進行c段嗅探,每個IP有ABCD四個段,舉個例子,192.168.0.1,A段就是192,B段是168,C段是0,D段是1,而C段嗅探的意思就是專注于C段中0,對D段的1-255進行嗅探,然后獲取敏感資訊,
基本命令
1.【掃描單個ip地址】nmap 127.0.0.1
2.【掃描多個ip】nmap 127.0.0.1 127.0.0.1
3.【掃描指定的ip范圍】nmap 127.0.0.1-2
4.【掃描整個d段】nmap 127.0.0.1/24
5.【掃描檔案內的所有目標地址】nmap -iL M:\1.txt
6.【掃描除了127.0.0.1以外的地址】nmap 127.0.0.1/24 -exclude 127.0.0.1
7.【掃描除了M:\1.txt以外的地址】nmap 127.0.0.1/24 -exclude M:\1.txt
8.【掃描目標的20、21、22埠】nmap 127.0.0.1 -p 21,22,23
9.【對目標地址進行路由跟蹤】nmap --traceroute 127.0.0.1
10.【掃描目標地址所在c段的在線狀況】nmap -sP 127.0.0.1
11.【目標地址的作業系統的指紋識別】nmap -O 127.0.0.1
12.【服務器版本探測】nmap -sV 127.0.0.1
13.【探測防火墻狀態】nmap -sF -T4 127.0.0.1
一些常見的埠號:
| 21埠 | FTP 檔案傳輸服務 |
| 22埠 | SSH 遠程連接服務 |
| 23埠 | TELNET 終端仿真服務 |
| 25埠 | SMTP 簡單郵件傳輸服務 |
| 53埠 | DNS 域名決議服務 |
| 80埠 | HTTP 超文本傳輸服務 |
| 110埠 | POP3 |
| 443埠 | HTTPS 加密的超文本傳輸服務 |
| 1080埠 | SOCKS代理協議服務器 |
| 1521埠 | Oracle資料庫 |
| 3306埠 | MYSQL資料庫埠 |
| 5432埠 | PostgreSQL資料庫埠 |
| 6379埠 | Redis資料庫埠 |
| 8080埠 | TCP服務端默認埠 |
| 8888埠 | Nginx服務器的埠 |
| 9200埠 | Elasticsearch服務器埠 |
| 27017埠 | mongoDB資料庫默認埠 |
| 22122埠 | fastdfs服務器默認埠 |
目錄掃描
掃描目標站點的目錄,尋找敏感資訊【如目錄名、檔案(phpinfo.php、readme.php)、后臺(admin.php)、robots.txt(告訴網路搜索引擎漫游器,此網站中的哪些內容是應該或者不應該被搜索引擎的漫游器獲取的)、備份檔案等(.bak .zip www.rar)】,
利用工具
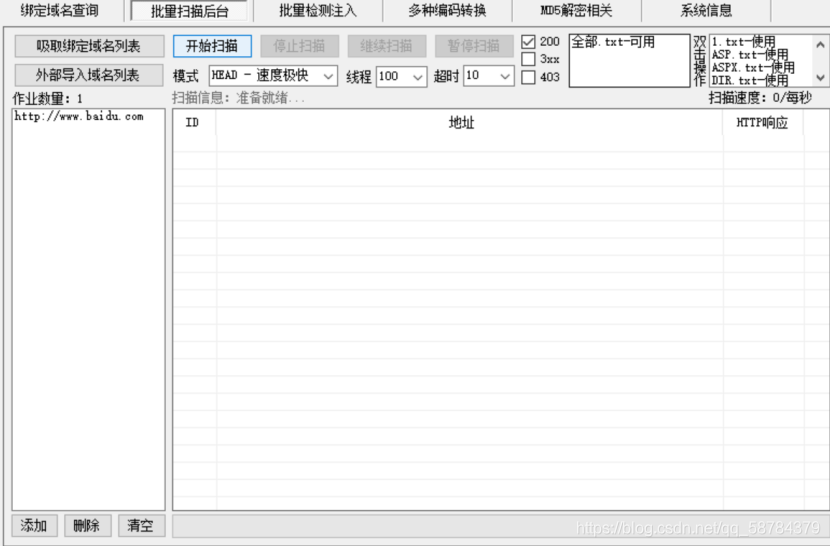
1)御劍
輸入域名,加入字典,選擇執行緒和超時時間,點擊開始,同時御劍還可以用于SQL注入檢測,各種加密解密,cdn逆向ip查詢,查詢目標主機的資訊
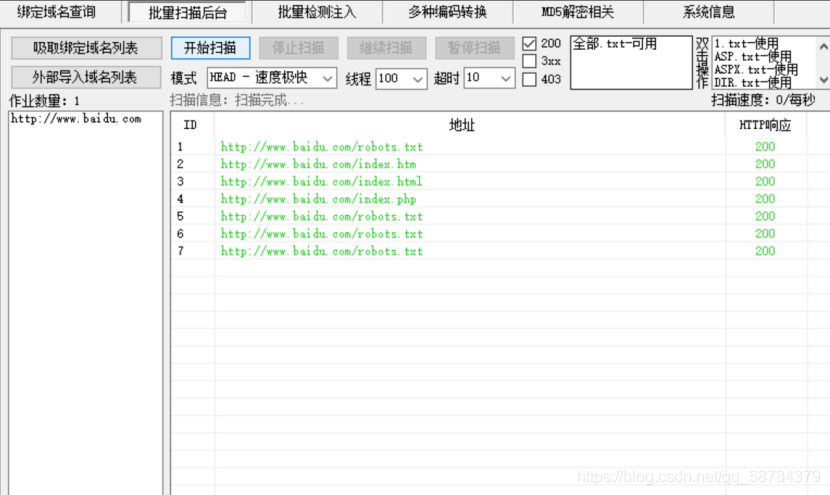
2)Dirsearch
基本命令:python dirsearch.py -e * -u www.baidu.com
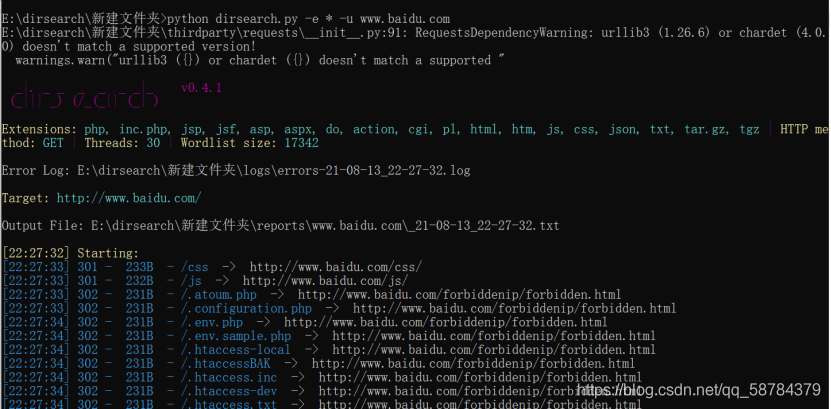
指紋識別
通常來說指紋識別就是人的手指末端正面皮膚上凹凸不平的紋路,紋路規律的排列形成特有的獨一無二的的指紋,這里講的指紋識別其實就是網站cms指紋識別,計算機作業系統以及web容器的指紋識別,
常見指紋工具:御劍web指紋識別、輕量級web指紋識別、whatweb等
常見網站資訊識別網站:
潮汐指紋:http://finger.tidesec.net/
CMS指紋識別:http://whatweb.bugscaner.com/look/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293880.html
標籤:其他
上一篇:單例模式(餓漢模式和懶漢模式)