Elasticsearch 分詞器安裝與使用
ES內置分詞器
- standard:默認分詞器,簡單會被拆分,英文統一轉換為小寫
- simlle:按照非字母分詞,英文統一轉換為小寫
- whitespace:按照空格分詞
- stop:去除無意義的單詞,比如:the、is、a、an
- keyword:不做分詞,把文本的整體當作一個單獨的關鍵詞
測驗分詞結果
指定分詞器測驗結果
GET http://192.168.213.154:9200/_analyze
POST http://192.168.213.154:9200/_analyze
{
"text":"The Super Man",
"analyzer":"standard"
}
測驗文本中的欄位分詞結果
GET http://192.168.213.154:9200/index_test_1/_analyze
POST http://192.168.213.154:9200/index_test_1/_analyze
{
"analyzer": "standard",
"field": "name",
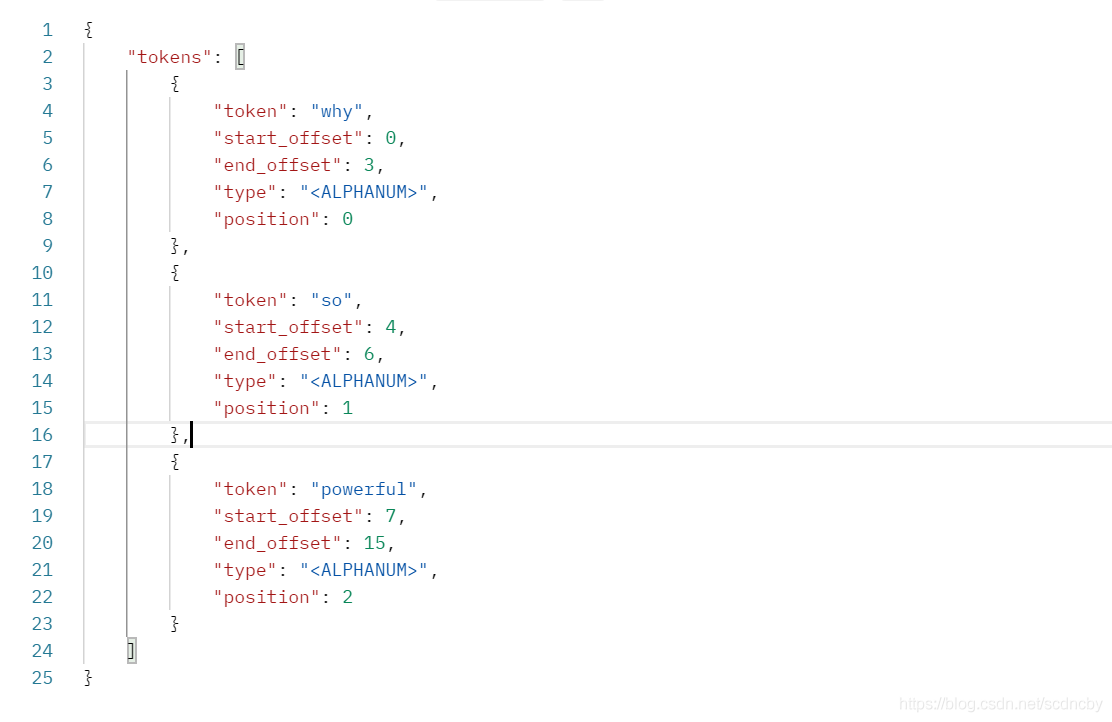
"text": "Why so powerful "
}
索引中使用分詞器
- 可以在創建索引的時候同時創建映射關系的時候使用
- 也可以在為索引創建映射關系的時候使用
PUT http://192.168.213.154:9200/index_test_1
{
"mappings": {
"properties": {
"realname": {
"type": "text",
"index": true
},
"username": {
"type": "keyword",
"index": false
}
}
}
}
---------------------------------------------------------------------
POST http://192.168.213.154:9200/index_test_1/mapping
{
"properties": {
"name": {
"type": "text",
"analyzer":"stop"
}
}
}
安裝中文IK分詞器
- github IK分詞器下載地址,選擇對應ES版本的分詞器即可
- 進入elasticsearch安裝目錄
- 在./plugins檔案加下創建一個ik檔案夾
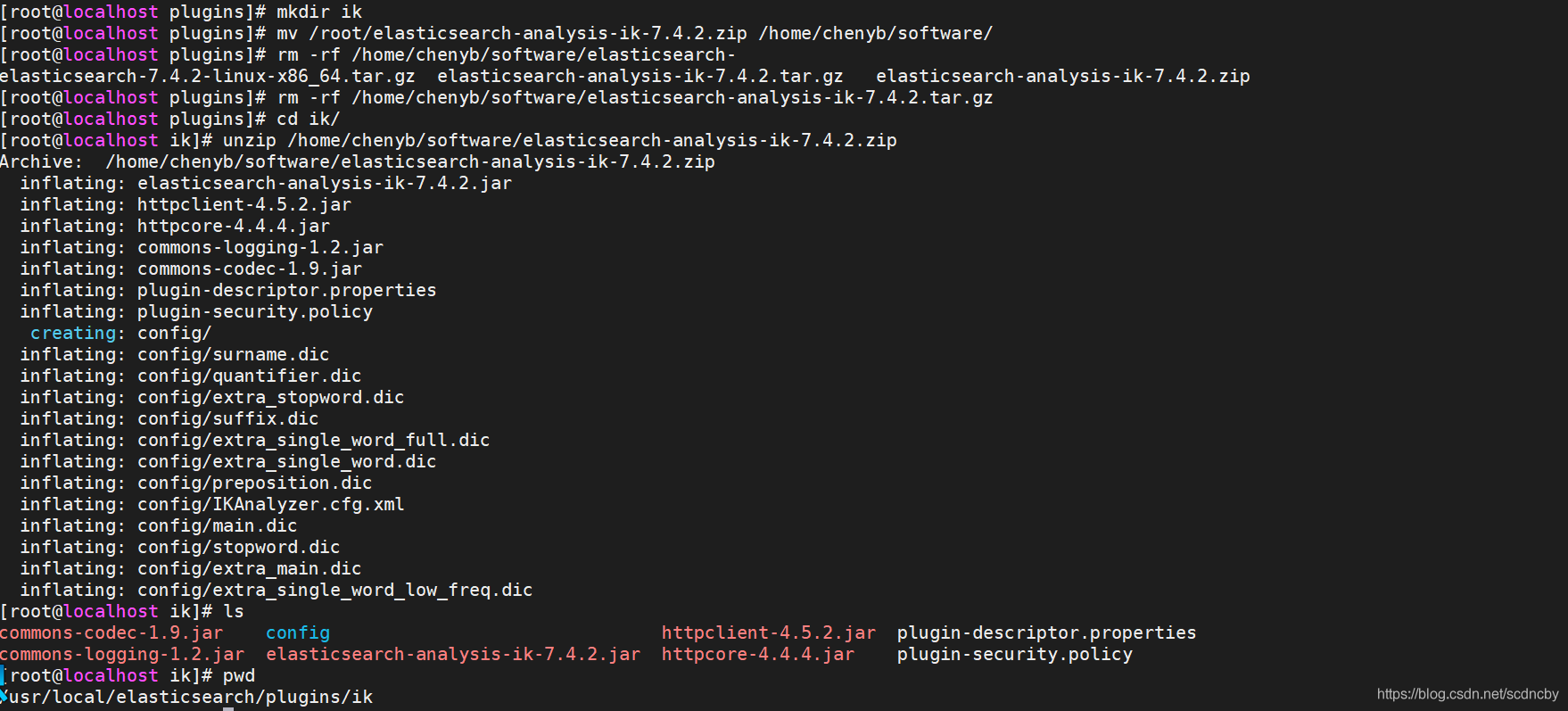
- cd /usr/local/elasticsearch/plugins/
- mkdir ik
- 然后將下載的壓縮包解壓到這個檔案夾下,重啟ES即可
- cd ik
- unzip /home/chenyb/software/elasticsearch-analysis-ik-7.4.2.zip
- 記得給ik檔案夾授權
- chown es:es ./ik/
IK分詞器
ik:ik_max_word,細粒度分詞
{
"tokens": [
{
"token": "中華人民共和國",
"start_offset": 0,
"end_offset": 7,
"type": "CN_WORD",
"position": 0
},
{
"token": "中華人民",
"start_offset": 0,
"end_offset": 4,
"type": "CN_WORD",
"position": 1
},
{
"token": "中華",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 2
},
{
"token": "華人",
"start_offset": 1,
"end_offset": 3,
"type": "CN_WORD",
"position": 3
},
{
"token": "人民共和國",
"start_offset": 2,
"end_offset": 7,
"type": "CN_WORD",
"position": 4
},
{
"token": "人民",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 5
},
{
"token": "共和國",
"start_offset": 4,
"end_offset": 7,
"type": "CN_WORD",
"position": 6
},
{
"token": "共和",
"start_offset": 4,
"end_offset": 6,
"type": "CN_WORD",
"position": 7
},
{
"token": "國",
"start_offset": 6,
"end_offset": 7,
"type": "CN_CHAR",
"position": 8
}
]
}ik:ik_smart,粗力度分詞
{
"tokens": [
{
"token": "中華人民共和國",
"start_offset": 0,
"end_offset": 7,
"type": "CN_WORD",
"position": 0
}
]
}自定義詞庫
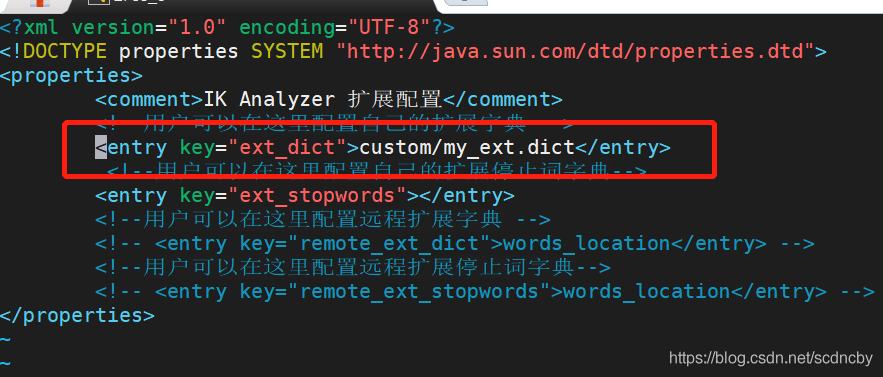
- 編輯組態檔
- 絕對路徑,相對路徑都可以,多個配置用“;”間隔
- 命名沒有要求,建議dic后綴規范而已
- vim ./elasticsearch/plugins/ik/config/IKAnalyzer.cfg.xml
- 重啟ES服務生效
??????? ???????
???????
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293900.html
標籤:其他