前言
1、佇列重平衡概述
如果對RocketMQ或者對訊息中間件有所了解的話,消費端在進行訊息消費時至少需要先進行佇列(磁區)的負載,即一個消費組內的多個消費者如何對訂閱的主題中的佇列進行負載均衡,當消費者新增或減少、佇列增加或減少時能否自動重平衡,做到應用無感知,直接決定了程式伸縮性,其說明圖如下:
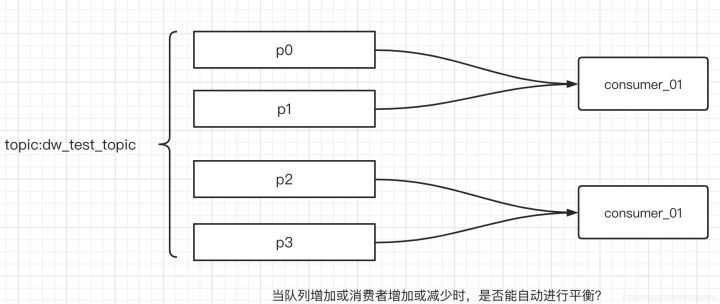
本節將聚集Kafka消費端的重平衡機制,
2、Kafka消費端基本流程
在介紹kafka消費端重平衡機制之前,我們首先簡單來看看消費者拉取訊息的流程,從整個流程來看重平衡的觸發時機、在整個消費流程中所起的重要作用,消費端拉取訊息的簡要流程如下圖所示:
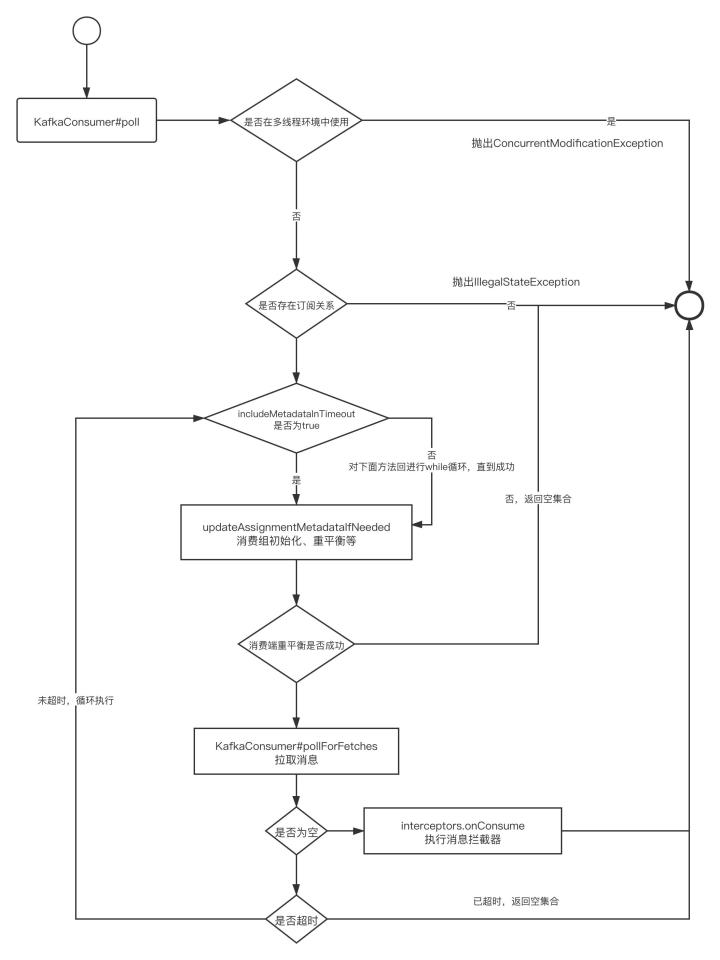
主要的關鍵點如下:
- 判斷KafkaConsumer物件是否處在多執行緒環境中,注意:該物件是多執行緒不安全的,不能有多個 執行緒持有該物件,
- 消費組初始化,包含了佇列負載(重平衡)
- 訊息拉取
- 訊息消費攔截器處理
關于poll方法的核心無非就是兩個:重平衡與消費拉取,本篇文章將重點剖析Kafka消費者的重平衡機制,
3、消費者佇列負載(重平衡)機制
通過對updateAssignmentMetadataIfNeeded方法的原始碼剖析,最終呼叫的核心方法為ConsumerCoordinator的poll方法,核心流程圖如下:
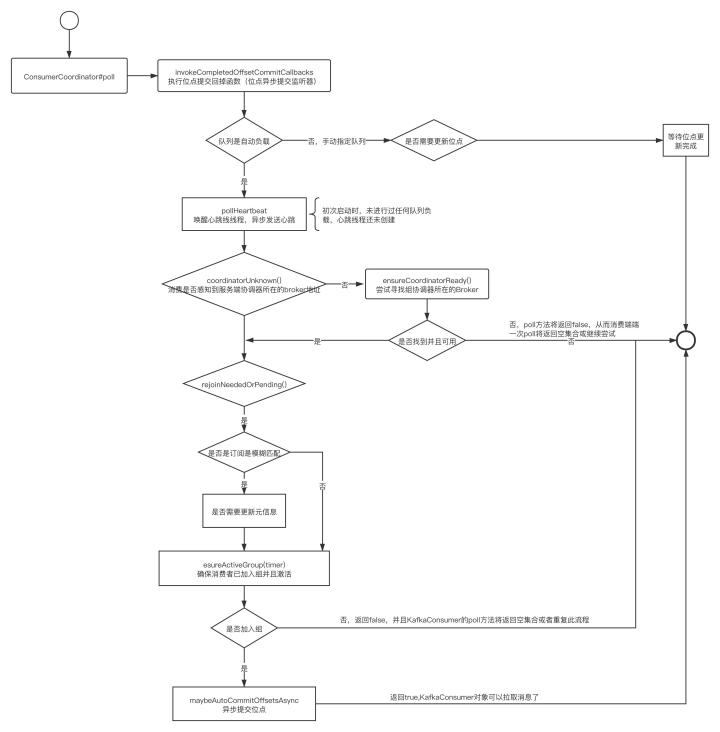
消費者協調器的核心流程關鍵點:
- 消費者協調器尋找組協調器
- 佇列負載(重平衡)
- 提交位點
本篇文章將深入探討Kafka的重平衡機制,
在深入研究kafka重平衡機制之前,首先請簡單思考如下問題:
- 重平衡會阻塞訊息消費嗎?
- Kafka的加入組協議哪些變更能有效減少重平衡
架構思維修煉:針對第二個問題,作為一名從原始碼級別去解讀Kafka,深入思考其內部的原理是架構師的一種必備素質,
3.1 消費者協調器
在Kafka中,在客戶端每一個消費者會對應一個消費者協調器(ConsumerCoordinator),在服務端每一個broker會啟動一個組協調器,
接下來將對該程序進行原始碼級別的跟蹤,根據原始碼提練作業機制,該部分對應上面流程圖中的:ensureCoordinatorReady方法,

該方法的關鍵點如下:
- 首先判斷一下當前消費者是否已找到broker端的組協調器,如果已感知,則回傳true,
- 如果當前并沒有感知組協調器,則向服務端(broker)尋找該消費組的組協調器,
- 尋找組協調器的程序是一個同步程序,如果出現例外,則會觸發重試,但引入了重試間隔機制,
- 如果未超時并且沒有獲取組協調器,則再次嘗試(do while),
核心要點為lookupCoordinator方法,該方法的核心是選擇一臺負載最小的broker,構建請求,向broker端查詢消費組的組協調器,代碼如下:
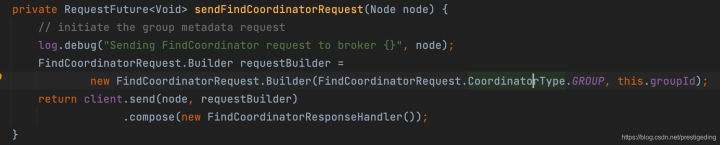
查詢組協調器的請求,核心引數為:
- ApiKeys apiKey
請求API,類比RocketMQ的RequestCode,根據該值很容易找到服務端對應的處理代碼,這里為ApiKeys.FIND_COORDINATOR,
- String coordinatorKey
協調器key,取消費組名稱,
思考題:提前劇透一下:Kafka服務端每一臺Broker會創建一個組協調器(GroupCoordinator),每一個組協調器可以協調多個消費組,但一個消費組只會被分配給一個組協調器,那這里負載機制是什么呢?服務端眾多Broker如何競爭該消費組的控制權呢?
- coordinatorType 協調器型別,默認為GROUP,表示普通消費組,
- short minVersion 版本,
針對客戶端端請求,服務端統一入口為KafkaApis.scala,可以根據ApiKeys快速找到其處理入口,如圖所示:
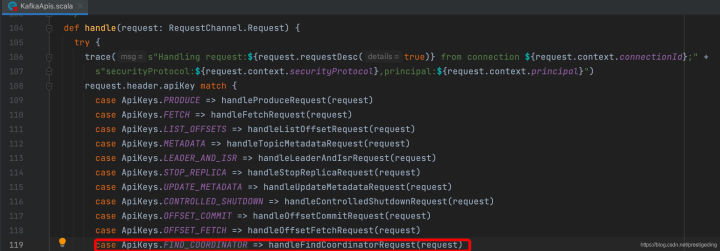
具體的處理邏輯在KafkaApis的handleFindCoordinatorRequest中,如下圖所示:
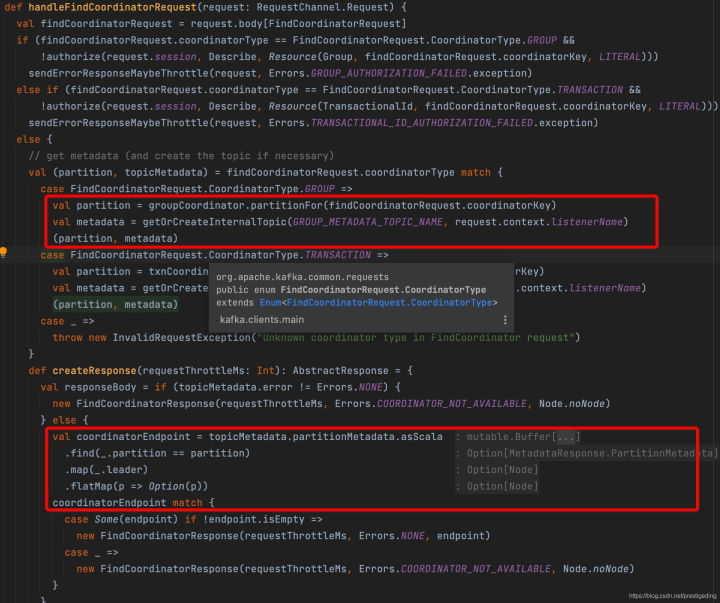
服務端為消費組分配協調器的核心演算法竟然非常簡單:根據消費組的名稱,取hashcode,然后與kafka內部topic(__consumer_offsets)的磁區個數取模,然后回傳該磁區所在的物理broker作為消費組的分組協調器,即內部并沒有復雜的選舉機制,這樣也能更好地說明,客戶端在發送請求時可以挑選負載最低的broker進行查詢的原因,
客戶端收到回應結果后更新ConsumerCoordinator的(Node coordinator)屬性,這樣再次呼叫coordinatorUnknown()方法,將會回傳false,至此完成消費端協調器的查找,
3.2 消費者加入消費組流程剖析
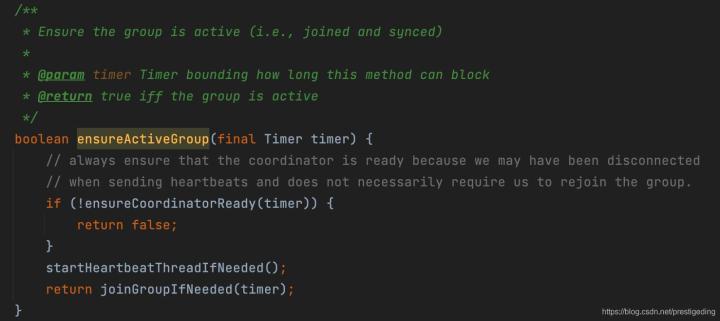
在消費者獲取到協調器后,根據上文提到的協調器處理流程,接下來消費者需要加入到消費者組中,加入到消費組也是參與佇列負載機制的前提,接下來我們從原始碼角度分析一下消費組加入消費組的流程,對應上文中的AbstractCoordinator的ensureActiveGroup方法,
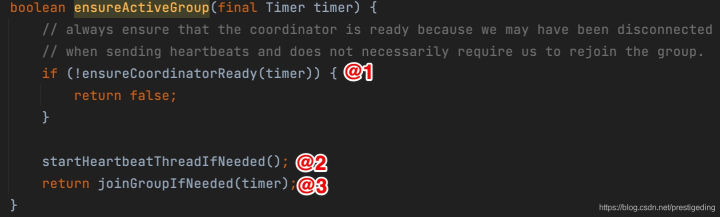
該方法的核心關鍵點:
- 在加入消費組之前必須確保該消費者已經感知到組協調器,
- 啟動心跳執行緒,當消費者加入到消費組后處于MemberState.STABLE后需要定時向協調器上報心跳,表示存活,否則將從消費組中移除,
- 加入消費組,
心跳執行緒稍后會詳細介紹,先跟蹤一下加入消費組的核心流程,具體實作方法為joinGroupIfneeded,接下來對該方法進行分步解讀,

消費端協調器在進行重平衡(加入一個新組)之前通常會執行如下操作:
- 如果開啟了自動提交位點,進行一次位點提交,
- 執行重平衡相關的事件監聽器,
AbstractCoordinator#joinGroupIfneeded
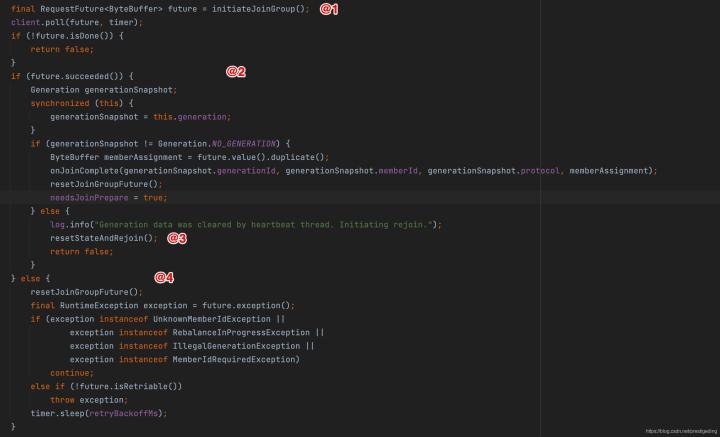
這里有兩個地方值得我們關注:
- 向消費組的組協調器發送加入請求,但加入消費組并不是目的,而是手段,最終要達成的目的是進行佇列的負載均衡,
- 呼叫onJoinComplete方法,通知消費端協調器佇列負載的最終結果,關于這點我們可以從其引數得知:
- String generationId
- String memberId 成員id
- String protocol 協議名稱,這里是consumer,
- ByteBuffer memberAssignment
佇列負載結果,包含了分配給當前消費者的佇列資訊,其序列后的結果如圖所示:

發起一次組加入請求,請求體主要包含如下資訊:
- 消費組的名稱
- session timeout,會話超時時間,默認為10s
- memberId 消費組成員id,第一次為null,后續服務端會為該消費者分配一個唯一的id,構成為客戶端id + uuid,
- protocolType 協議型別,消費者加入消費組固定為 consumer
- 消費端支持的所有佇列負載演算法
收到服務端回應后將會呼叫JoinGroupResponseHandler回掉,稍后會詳細介紹,
3.2.2 服務端回應邏輯
服務端處理入口:KafkaApis的handleJoinGroupRequest方法,該方法為委托給GroupCoordinator,
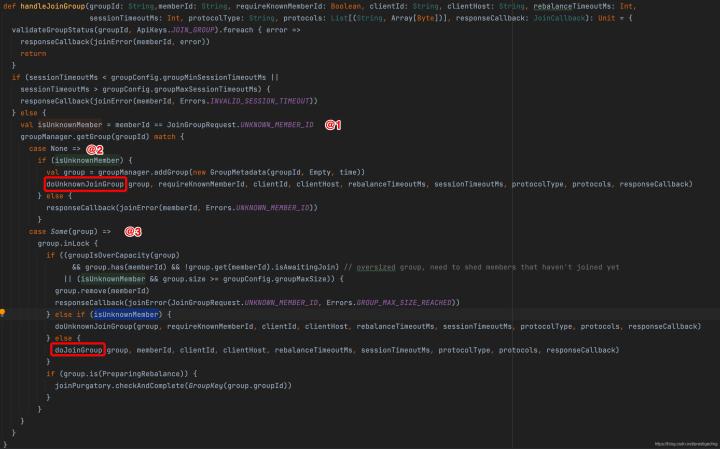
通過這個入口,基本可以看到服務端處理加入請求的關鍵點:
- 從客戶端請求中提取客戶端的memberId,如果為空,表示第一次加入消費組,還未分配memberId,
- 如果協調器中不存在該消費組的資訊,表示第一次加入,創建一個,并執行doUnknownJoinGroup(第一次加入消費組邏輯)
- 如果協調器中已存在消費組的資訊,判斷一下是否已達到最大消費者個數限制默認不限制),超過則會拋出例外;然后根據消費者是否是第一次加入進行對應的邏輯處理,
組協調器會為每一個路由到的消費組維護一個組元資訊(GroupMetadata),存盤在HashMap< String, GroupMetadata>,每一個消費組云資訊中存盤了當前的所有的消費者,由消費者主動加入,組協調器可以主動剔除消費者,
接下來分情況處理,來看一下第一次加入(doUnknownJoinGroup)與重新加入(doJoinGroup)分別詳細探討,
3.2.2.1 初次加入消費組
初次加入消費組的代碼如下:
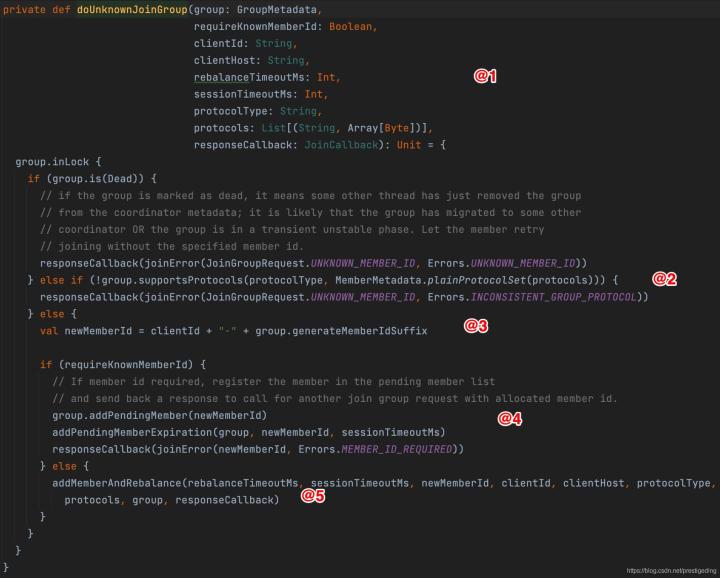
關鍵點如下:
- 首先來看一下該方法的引數含義:
- GroupMetadata group:消費組的元資訊,并未持久化,存盤在記憶體中,一個消費組當前消費者的資訊,
- boolean requireKnownMemberId:是否一定需要知道客戶端id,如果客戶端請求版本為4,在加入消費組時需要明確知道對方的memberId,
- String clientId:客戶端ID,訊息組的memberId生成規則為 clientId + uuid
- String clientHost:消費端端ip地址
- int rebalanceTimeoutMs:重平衡超時時間,取自消費端引數max.poll.interval.ms,默認為5分鐘,
- int sessionTimeoutMs:會話超時時間,默認為10s
- String protocolType:協議型別,默認為consumer
- List protocols:客戶端支持的佇列負載演算法,
- 對客戶端進行狀態驗證,其校驗如下:
- 如果消費者狀態為dead,則回傳UNKNOWN_MEMBER_ID
- 如果當前消費組的負載演算法協議不支持新客戶端端佇列負載協議,則拋出UNKNOWN_MEMBER_ID,并提示不一致的佇列負載協議,
- Kafka 的加入請求版本4在加入消費端組時使用有明確的客戶端memberId,消費組將創建的memberId加入到組的pendingMember中,并向客戶端回傳MEMBER_ID_REQUIRED,引導客戶端重新加入,客戶端會使用服務端生成的memberId,重新發起加入消費組,
- 呼叫addMemberAndRebalance方法加入消費組并觸發重平衡,
接下來繼續探究加入消費組并觸發重平衡的具體邏輯,具體實作見GroupCoordinator的addMemberAndRebalance,
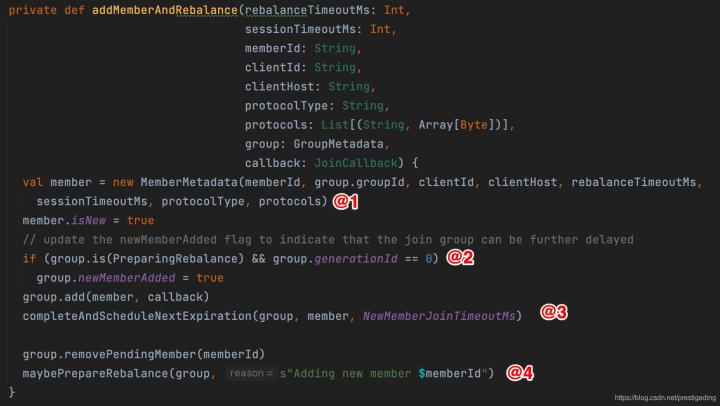
核心要點如下:
- 組協調器為每一個消費者創建一個MemberMetadata物件,
- 如果消費組的狀態為PreparingRebalance(此狀態表示正在等待消費組加入),并將組的newMemberAdded設定為true,表示有新成員加入,后續需要觸發重平衡,并將消費組添加到組中,這里會觸發一次消費組選主,選主邏輯:該消費組的第一個加入的消費者成為該消費組中的Leader,Leader的職責是什么呢?
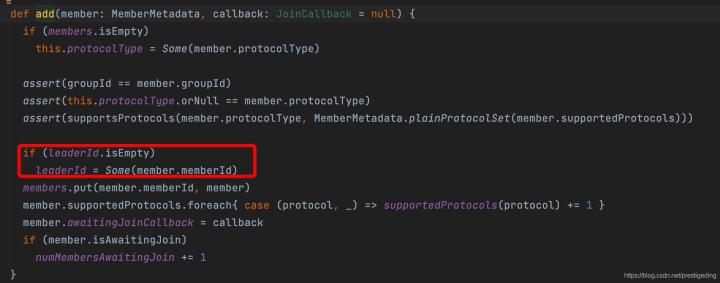
- 為每一個消費者創建一個DelayedHeartbeat物件,用于檢測會話超時,組協調器如果檢測會話超時,會將該消費者移除組,會重新觸發重平衡,消費者為了避免被組協調器移除消費組,需要按間隔發送心跳包,
- 根據當前消費組的狀態是否需要進行重平衡,
接下來繼續深入跟蹤maybePrepareRebalance方法,其實作如下圖所示:
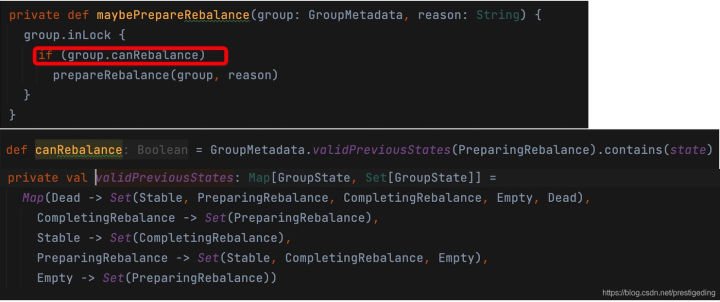
根據狀態機的驅動規則,判斷是否可以進入到PrepareRebalance,其判斷邏輯就是根據狀態機的驅動,判斷當前狀態是否可以進入到該狀態,其具體實作是為每一個狀態存盤了一個可以進入當前狀態的前驅狀態集合,
如果符合狀態驅動流程,消費組將進入到PrepareRebalance,其具體實作如下圖所示:
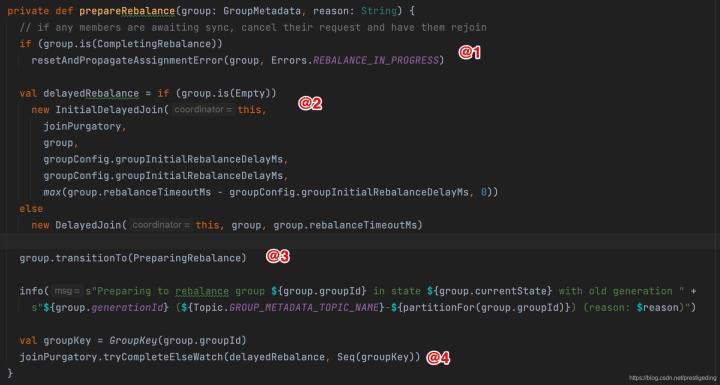
- 如果當前消費組的狀態為CompletingRebalance,需要重置佇列分配動作,并讓消費組重新加入到消費組,即重新發送JOIN_GROUP請求,具體實作技巧:
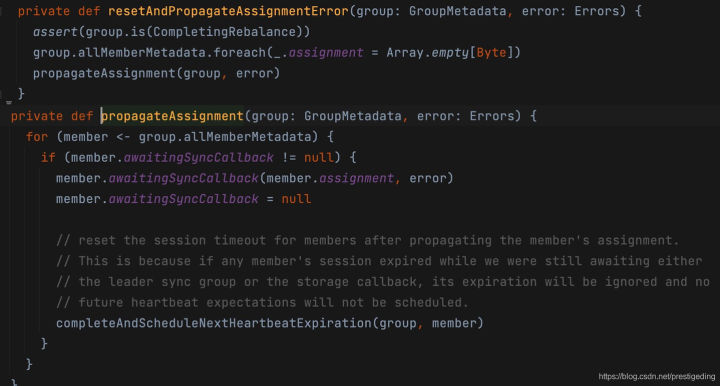
- 將所有消費者已按分配演算法分配到的佇列資訊置空
- 將空的分配結果回傳給消費者,并且錯誤碼為REBALANCE_IN_PROGRESS,客戶端收到該錯會重新加入消費組,
- 如果當前沒有消費者,則創建InitialDelayedJoin,否則則創建DelayedJoin,值得注意的是這里有一個引數:group.initial.rebalance.delay.ms,用于設定消費組進入到PreparingRebalance真正執行其業務邏輯的延遲時間,其主要目的是等待更多的消費者進入,
- 驅動消費組狀態為PreparingRebalance,
- 嘗試執行initialDelayedJoin或DelayedJoin的tryComplete方法,如果沒有完成,則創建watch,等待執行完成,最終執行的是組協調器的相關方法,其說明如下:

接下來看一下組協調器的tryCompleteJoin方法,其實作如下圖所示:
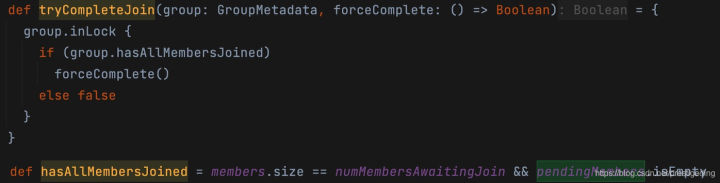
- 完成PreparingRebalance狀態的條件是:已知的消費組都成功加入到消費組,該方法回傳true后,onCompleteJoin方法將被執行,
接下來看一下GroupCoordinator的onCompleteJoin方法的實作
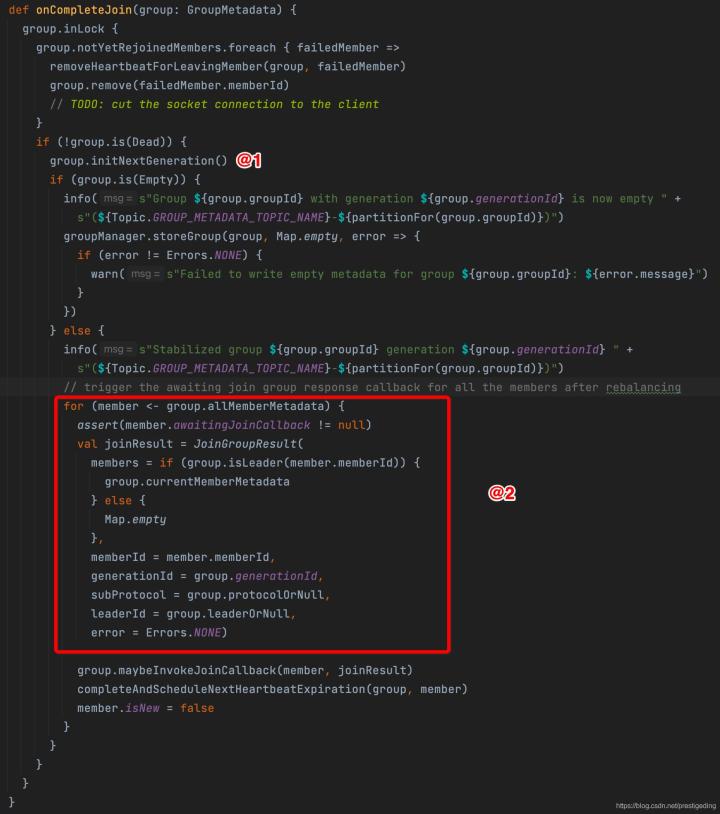
核心的關鍵點如下:
- 驅動消費組的狀態轉化為CompletingRebalance,將進入到重平衡的第二個階段(佇列負載)
- 為每一個成員構建對應JoinResponse物件,其中三個關鍵點
- generationId 消費組每一次狀態變更,該值加一
- subProtocol 當前消費者組中所有消費者都支持的佇列負載演算法
- leaderId 消費組中的leader,一個消費組中第一個加入的消費者為leader
接下來,消費者協調器將根據服務端回傳的回應結果,進行第二階段的重平衡,即進入到佇列負載演算法,
服務端對于客戶端第一次加入消費組的流程就介紹到這里,再將目光放到客戶端對重平衡的回應結果之前,我們再看看組協調器是如何處理已知memberId的消費者加入處理邏輯,
3.2.2.2 已知memberId加入消費組處理邏輯
組協調在已知memberid處理加入請求的核心處理代碼在GroupCoordinator的doJoinGroup中,即重新加入請求,
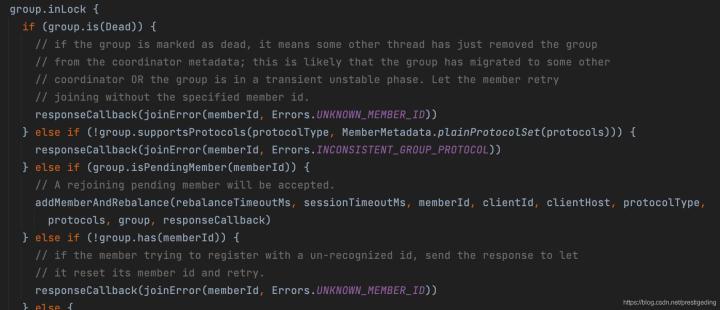
Step1:首先進行相關的錯誤校驗:
- 如果消費組狀態為Dead,回傳錯誤unknown_member_id錯誤,
- 如果當前消費者支持的佇列負載演算法消費組并不支持
- 如果當前的memberid處在pendingMember中,對于這種重新加入的消費者會接受并觸發重平衡,
值得注意的是,在Kafka JOIN_REQUEST版本為4后,首先會在服務端生成memberId,并加入到pendingMember中,并立即向客戶端回傳memberId,引導客戶端重新加入,
- 如果消費組不存在該成員,回傳錯誤,說明消費組已經將該消費者移除,
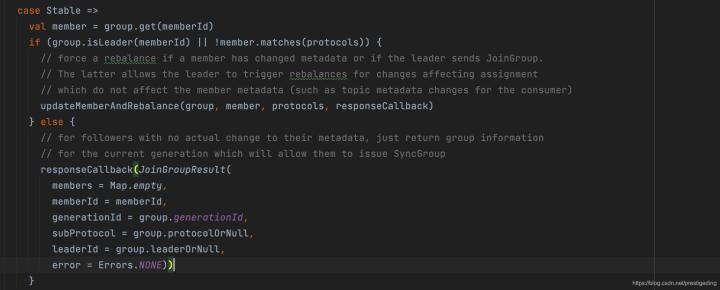
 Step2:根據消費組的狀態采取不同的行為,如果當前狀態為PreparingRebalance,則更新成員的元資訊,按照需要觸發重平衡,
Step2:根據消費組的狀態采取不同的行為,如果當前狀態為PreparingRebalance,則更新成員的元資訊,按照需要觸發重平衡,
PreparingRebalance狀態,消費組在等待消費組中的消費者加入,
Step3:如果狀態為CompletingRebalance,如果收到join group請求,但其元資訊并沒有發生變化(佇列負載演算法),只需將最新的資訊回傳給消費者;如果狀態發生變更,則會進行再次回到重平衡的第一階段,消費組重新加入,
消費組如果處于CompletingRebalance狀態,其實不希望再收到Join Group請求,因為處于CompletingRebalance狀態的消費組,正在等待消費者Leader分配佇列,
Step4:如果消費組處于Stable狀態,如果成員是leader并且支持的協議發生變化,則進行重平衡,否則只需要將元資訊發生給客戶端即可,
3.2.3 客戶端處理組協調器的Join Group 回應包
客戶端對Join_Group的回應處理在:JoinGroupResponseHandler,其核心實作如下:

關鍵點:佇列的負載演算法是由Leader節點來分配,將分配結果通過向組協調器發送SYNC_GROUP請求,然后組協調器從Leader節點獲取分配演算法后,再回傳給所有的消費者,從而開始進行消費,
3.3 心跳與離開
消費者通過消費者協調器與組協調器互動完成消費組的加入,但如何退出呢?例如當消費者宕機,協調器如何感知呢?
原來在Kafka中,消費者協調器會引入心跳機制,即定時向組協調器發送心跳包,在指定時間內未收到客戶端的心跳包,表示會話過期,過期時間通過引數session.timeout.ms設定,默認為10s,
通過對ConsumerCoordinator的poll流程可知,消費者協調器在得知消費組的組協調器后,就會啟動心跳執行緒,其代碼如下:
啟動心跳執行緒后,主要關注HeartbeatThread的run方法,
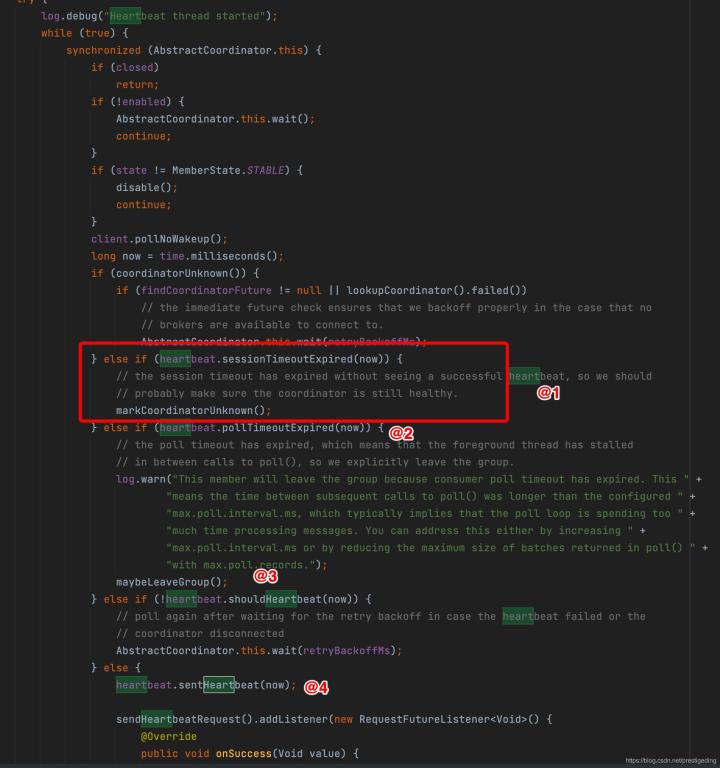
心跳執行緒的核心要點如下:
- 如果距離上一次心跳超過了會話時間,會斷開與GroupCoordinator斷開鏈接,并設定為coordinatorUnknow 為true,需要重新尋找組協調器,
- 如果此次心跳發送時間距離上一次心跳發送時間超過了pollTimeout,客戶端將發送LEAVE_GROUP,離開消費組,并在下一個poll方法呼叫時重新進入加入消費組的操作,會再次觸發重平衡,
- 如果兩次心跳時間超過了單次心跳發送間隔,將發送訊息,
溫馨提示:盡管心跳包通常是定時類任務,但kafka的心跳機制另辟蹊徑,使用了Object的wait與notify,心跳執行緒與訊息拉取執行緒相互協助,每一次訊息拉取,都會進行判斷是否應該發送心跳包,
關于消費組的離開,服務端端處理邏輯比較簡單,就不在這一一介紹了,
4、重平衡機制總結
Kafka的重平衡其實包含兩個非常重要的階段:消費組加入階段(PreparingRebalance)、佇列負載(CompletingRebalance).
PreparingRebalance:此階段是消費者陸續加入消費組,該組第一個加入的消費者被推舉為Leader,當該組所有已知memberId的消費者全部加入后,狀態驅動到CompletingRebalance,
CompletingRebalance:PreparingRebalance狀態完成后,如果消費者被推舉為Leader,Leader會采用該消費組中都支持的佇列負載演算法進行佇列分布,然后將結果回報給組協調器;如果消費者的角色為非Leader,會向組協調器發送同步佇列磁區演算法,組協調器會將Leader節點分配的結果分配給消費者,
消費組如果在進行重平衡操作,將會暫停訊息消費,頻繁的重平衡會導致佇列訊息消費的速度受到極大的影響,
與重平衡相關的消費端引數:
- max.poll.interval.ms
兩次poll方法呼叫的最大間隔時間,單位毫秒,默認為5分鐘,如果消費端在該間隔內沒有發起poll操作,該消費者將被剔除,觸發重平衡,將該消費者分配的佇列分配給其他消費者,
- session.timeout.ms
消費者與broker的心跳超時時間,默認10s,broker在指定時間內沒有收到心跳請求,broker端將會將該消費者移出,并觸發重平衡,
- heartbeat.interval.ms
心跳間隔時間,消費者會以該頻率向broker發送心跳,默認為3s,主要是確保session不會失效,
最后

全套的Java面試寶典手冊:性能調優+微服務架構+并發編程+開源框架+分布式”等七大面試專欄,包含Tomcat、JVM、MySQL、SpringCloud、SpringBoot、Dubbo、并發、Spring、SpringMVC、MyBatis、Zookeeper、Ngnix、Kafka、MQ、Redis、MongoDB、memcached等等,
有需要的朋友可以關注公眾號【程式媛小琬】即可獲取,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293906.html
標籤:其他