目錄
- 關于想了好幾年學機器學習,如今才翻開書的這件事
- 第二章 模型評估與選擇
- 模型評估方法(訓練集S和測驗集T劃分)
- 1、留出法
- 2、交叉驗證法
- 3、自助法
關于想了好幾年學機器學習,如今才翻開書的這件事
更新學習中~
起因是在夏令營面試程序中,被老師問道,你學過機器學習嗎?看過西瓜書嗎?被傷了自尊心…但是在npy的熏陶下對這方面也有部分自己的思考,但是一直沒有系統地學習,原理其實是不是很懂的,
我: 神經網路的原理你能給我講講嗎?連的每條線都什么意思呀?
npy:它就是個黑盒!你會用就行了!
我:既然能設計出來!那肯定能解釋!
npy:·······
抱著它一定可以被我解釋的心態,我翻開了西瓜書…
介紹一個有比較好的資源的GitHub地址:
https://github.com/apachecn/AiLearning/blob/master/README.md
當然西瓜書講得非常詳細,但是自己能力也有限,選取了一些自己認為可能比較重點的內容進行深讀,
第二章 模型評估與選擇
模型評估方法(訓練集S和測驗集T劃分)
1、留出法
直接將資料集劃分成兩個互斥的集合,使用其中一個作為訓練集S,另一個作為測驗集T,在S上進行模型訓練后,用T進行評估,
ATTENTION:
(1)S/T的劃分要盡可能保證資料的一致性,避免因資料劃分程序引入額外的偏差而對最終結果產生影響,例如:分類任務中至少保持樣本類別的比例相似,
(2)即便給定訓練/測驗集樣本比例后,仍有多種方式對資料集D進行分割,所以使用單詞留出法的估計結果并不夠穩定可靠,在使用留出法時,一般要采用若干次隨機劃分、重復進行試驗評估后取平均值作為評估結果,
缺點:
(1)訓練集S過于接近資料集D,此時測驗集T較小,使得測驗結果不夠穩定,
(2)測驗集T過于接近資料集D,此時訓練集S較小,使得訓練結果與預期模型差別較大,
常用解決方法:將2/3~4/5的樣本用于訓練,
2、交叉驗證法
將資料集D劃分成k個互斥大小相似的集合,盡可能保持資料分布的一致性,然后將前k-1個子集作為訓練集S,余下的子集作為測驗集T,這樣就可以得到k組訓練集/測驗集,進行k次訓練,并回傳k次的均值,
k常用的取值是10、5、20,
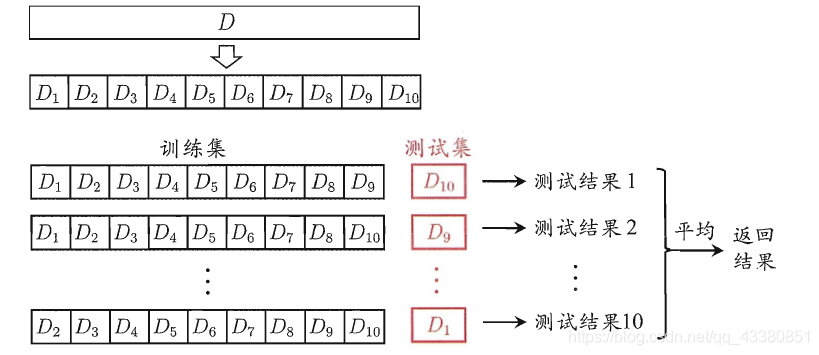
比較特殊的情況是,若資料集D有m個樣本,取k值為m,則每個測驗集為1,此時不受隨機樣本劃分影響,易得這種方法得出的樣本與期望評估的D非常相似,往往比較準確,但是缺點也十分明顯,當m足夠大時,計算開銷時無法忍受的,
3、自助法
自助法在某種程度上減少訓練樣本規模不同造成的影響,同時還能比較高效地進行實驗估計,
以自助采樣為基礎,從有m個樣本的資料集D,對其進行采樣,隨機挑選一個拷貝到D’,并放回,進行m次,得到一個大小為m的資料集,其中有一部分樣本會重復多次,而另一部分不出現,其中始終不被采集到的概率經微積分取極限計算大概為0.368,此時D’作為訓練集,D/D’作為測驗集,測驗集中有近1/3的資料未曾出現過,
這種方法適用于資料集較小,難以有效劃分訓練/測驗集的情況,
但是改變了初始資料集分布,會引入估計誤差,
在資料量足夠時,方法1、2使用更多,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/294109.html
標籤:AI