一、為什么選擇殘差網路
??在VGG中,卷積網路達到了19層,在GoogLeNet中,網路史無前例的達到了22層,那么,網路的精度會隨著網路的層數增多而增多嗎?在深度學習中,網路層數增多一般會伴著下面幾個問題
- 計算資源的消耗(用GPU集群去懟)
- 模型容易過擬合(擴大資料集、Droupout、批量歸一化、正則化、初始化引數調整等等方法)
- 梯度消失/梯度爆炸問題的產生(批量歸一化)
??隨著網路層數的增加,網路發生了退化(degradation)的現象:隨著網路層數的增多,訓練集loss逐漸下降,然后趨于飽和,當你再增加網路深度的話,訓練集loss反而會增大,注意這并不是過擬合,因為在過擬合中訓練loss是一直減小的,
??當網路退化時,淺層網路能夠達到比深層網路更好的訓練效果,這時如果我們把低層的特征傳到高層,那么效果應該至少不比淺層的網路效果差,或者說如果一個VGG-100網路在第98層使用的是和VGG-16第14層一模一樣的特征,那么VGG-100的效果應該會和VGG-16的效果相同,所以,我們可以在VGG-100的98層和14層之間添加一條直接映射(Identity Mapping)來達到此效果,
??從資訊論的角度講,由于DPI(資料處理不等式)的存在,在前向傳輸的程序中,隨著層數的加深,Feature Map包含的影像資訊會逐層減少,而ResNet的直接映射的加入,保證了 l + 1 l+1 l+1層的網路一定比 l l l層包含更多的影像資訊,
??基于這種使用直接映射來連接網路不同層直接的思想,殘差網路應運而生,
二、殘差網路(ResNet)
??隨著我們設計越來越深的網路,深刻理解“新添加的層如何提升神經網路的性能”變得至關重要,更重要的是設計網路的能力,在這種網路中,添加層會使網路更具表現力,為了取得質的突破,我們需要一些數學基礎知識,
2.1 函式類
??首先,假設有一類特定的神經網路結構 F \mathcal{F} F,它包括學習速率和其他超引數設定,對于所有 f ∈ F f \in \mathcal{F} f∈F,存在一些引數集(例如權重和偏置),這些引數可以通過在合適的資料集上進行訓練而獲得,
??現在假設 f ? f^* f? 是我們真正想要找到的函式,如果是 f ? ∈ F f^* \in \mathcal{F} f?∈F,那我們可以輕而易舉的訓練得到它,但通常我們不會那么幸運,相反,我們將嘗試找到一個函式 f F ? f^*_\mathcal{F} fF??,這是我們在 F \mathcal{F} F 中的最佳選擇,例如,給定一個具有 X \mathbf{X} X 特性和 y \mathbf{y} y 標簽的資料集,我們可以嘗試通過解決以下優化問題來找到它:
f F ? : = a r g m i n f L ( X , y , f ) subject to f ∈ F . (2.1) f^*_\mathcal{F} := \mathop{\mathrm{argmin}}_f L(\mathbf{X}, \mathbf{y}, f) \text{ subject to } f \in \mathcal{F}. \tag{2.1} fF??:=argminf?L(X,y,f) subject to f∈F.(2.1)
那么,怎樣得到更近似真正
f
?
f^*
f? 的函式呢?
??唯一合理的可能性是,我們需要設計一個更強大的結構
F
′
\mathcal{F}'
F′,換句話說,我們預計
f
F
′
?
f^*_{\mathcal{F}'}
fF′?? 比
f
F
?
f^*_{\mathcal{F}}
fF?? “更近似”,然而,如果
F
??
F
′
\mathcal{F} \not\subseteq \mathcal{F}'
F??F′,則無法保證新的體系“更近似”,
事實上,
f
F
′
?
f^*_{\mathcal{F}'}
fF′?? 可能更糟:
??如下圖所示,對于非嵌套函式(non-nested function)類,較復雜的函式類并不總是向“真”函式
f
?
f^*
f? 靠攏(復雜度由
F
1
\mathcal{F}_1
F1? 向
F
6
\mathcal{F}_6
F6? 遞增),在下圖的左邊,雖然
F
3
\mathcal{F}_3
F3? 比
F
1
\mathcal{F}_1
F1? 更接近
f
?
f^*
f?,但
F
6
\mathcal{F}_6
F6? 卻離的更遠了,相反對于圖右側的嵌套函式(nested function)類
F
1
?
…
?
F
6
\mathcal{F}_1 \subseteq \ldots \subseteq \mathcal{F}_6
F1??…?F6?,我們可以避免上述問題,
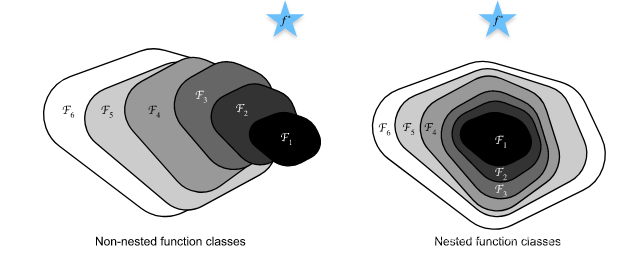
??因此,只有當較復雜的函式類包含較小的函式類時,我們才能確保提高它們的性能,對于深度神經網路,如果我們能將新添加的層訓練成 恒等映射(identity function) f ( x ) = x f(\mathbf{x}) = \mathbf{x} f(x)=x ,新模型和原模型將同樣有效,同時,由于新模型可能得出更優的解來擬合訓練資料集,因此添加層似乎更容易降低訓練誤差,
??針對這一問題,何愷明等人提出了殘差網路(ResNet)He.Zhang.Ren.ea.2016,它在2015年的ImageNet影像識別挑戰賽奪魁,并深刻影響了后來的深度神經網路的設計,殘差網路的核心思想是:每個附加層都應該更容易地包含原始函式作為其元素之一,于是,殘差塊 (residual blocks) 便誕生了,這個設計對如何建立深層神經網路產生了深遠的影響,憑借它,ResNet 贏得了 2015 年 ImageNet 大規模視覺識別挑戰賽,
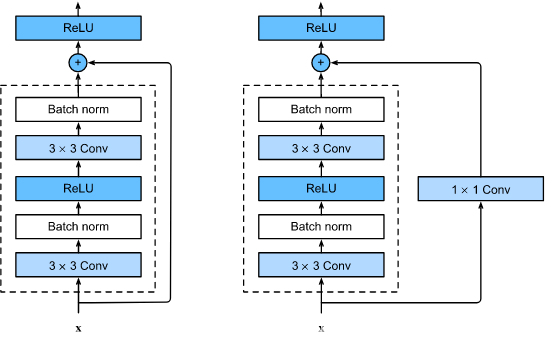
2.2 殘差塊
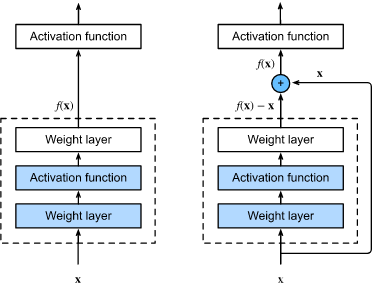
??讓我們聚焦于神經網路區域:如下圖所示,假設我們的原始輸入為
x
x
x ,而希望學出的理想映射為
f
(
x
)
f(\mathbf{x})
f(x) (作為 residual_block 上方激活函式的輸入),下左圖虛線框中的部分需要直接擬合出該映射
f
(
x
)
f(\mathbf{x})
f(x) ,而右圖虛線框中的部分則需要擬合出殘差映射
f
(
x
)
?
x
f(\mathbf{x}) - \mathbf{x}
f(x)?x ,
??殘差映射在現實中往往更容易優化,以上一節中提到的恒等映射作為我們希望學出的理想映射
f
(
x
)
f(\mathbf{x})
f(x) ,我們只需將 residual_block 中右圖虛線框內上方的加權運算(如仿射)的權重和偏置引數設成 0,那么
f
(
x
)
f(\mathbf{x})
f(x) 即為恒等映射,
??實際中,當理想映射
f
(
x
)
f(\mathbf{x})
f(x) 極接近于恒等映射時,殘差映射也易于捕捉恒等映射的細微波動,residual_block 右圖是 ResNet 的基礎結構-- 殘差塊(residual block),在殘差塊中,輸入可通過跨層資料線路更快地向前傳播,
這里可能會讓人有一些混淆,梳理一下:
- 網路的每一層我們看作是: y = H ( x ) y = H(x) y=H(x),也就是這里的輸出 f ( x ) f(x) f(x)
- 殘差網路的一個殘差塊可以表示為:
H
(
x
)
=
F
(
x
)
+
x
H(x) = F(x) + x
H(x)=F(x)+x,這里的
F
(
x
)
F(x)
F(x)等價于
residual_block右圖虛線框中的部分 - 那么就可以得到: F ( x ) = H ( x ) ? x F(x) = H(x) -x F(x)=H(x)?x,也就是 f ( x ) ? x f(x) - x f(x)?x
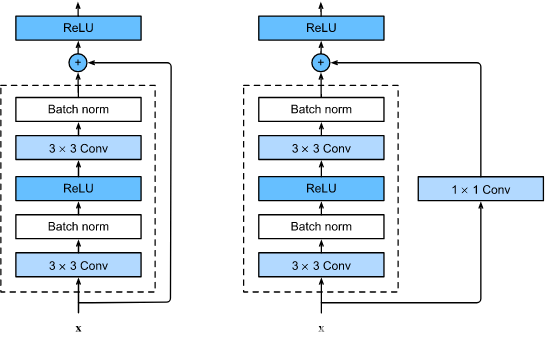
殘差塊的結構:
- ResNet 沿用了 VGG 完整的 3 × 3 3\times 3 3×3 卷積層設計,
- 殘差塊里首先有 2 個有相同輸出通道數的 3 × 3 3\times 3 3×3 卷積層,
- 每個卷積層后接一個批量歸一化層和 ReLU 激活函式,
- 然后我們通過跨層資料通路,跳過這 2 個卷積運算,將輸入直接加在最后的 ReLU 激活函式前,
- 這樣的設計要求 2 個卷積層的輸出與輸入形狀一樣,從而可以相加,
- 如果想改變通道數,就需要引入一個額外的 1 × 1 1\times 1 1×1 卷積層來將輸入變換成需要的形狀后再做相加運算,
2.3 殘差網路的數學原理
參差網路的通用表示方式是:
y
l
=
h
(
x
l
)
+
F
(
x
l
,
W
l
)
(2.2)
y_l = h(x_l)+ F(x_l,W_l) \tag{2.2}
yl?=h(xl?)+F(xl?,Wl?)(2.2)
x
l
+
1
=
f
(
y
l
)
(2.3)
x_{l+1} = f(y_l) \tag{2.3}
xl+1?=f(yl?)(2.3)
現在我們先不考慮升維或者降維的情況,那么假設公式2.2和2.3中
- h ( . ) h(.) h(.)是直接映射
- f ( . ) f(.) f(.)是激活函式,一般使用ReLU,
那么殘差塊兒可表示為:
x
l
+
1
=
x
l
+
F
(
x
l
,
W
l
)
(2.4)
x_{l+1} = x_l + F(x_l,W_l) \tag{2.4}
xl+1?=xl?+F(xl?,Wl?)(2.4)
對于一個更深的層L,其與l層的關系可以表示為:
x
L
=
x
l
+
∑
i
=
l
L
?
1
F
(
x
i
,
W
i
)
(2.5)
x_L = x_l + \sum_{i=l}^{L-1}F(x_i,W_i) \tag{2.5}
xL?=xl?+i=l∑L?1?F(xi?,Wi?)(2.5)
公式2.5 反映殘差網路的兩個特性:
- L層可以用任意一個比它淺的l層網路和他們之間的殘差部分之和進行表示
- 公式中L是各個殘差塊特征的單位累和,而MLP是特征矩陣累積
根據向后傳播中使用的導數的鏈式法則,損失函式
?
\epsilon
?關于
x
l
x_l
xl?的梯度可以表示為:
?
?
?
x
l
=
?
?
?
x
L
?
x
L
?
x
l
=
?
?
?
x
L
(
1
+
?
?
x
l
∑
i
=
l
L
?
1
F
(
x
i
,
W
i
)
)
=
?
?
?
x
L
+
?
?
?
x
L
?
?
x
l
∑
i
=
l
L
?
1
F
(
x
i
,
W
i
)
(2.6)
\begin{aligned} \frac{\partial{\epsilon}}{\partial{x_l}} &= \frac{\partial{\epsilon}}{\partial{x_L}}\frac{\partial{x_L}}{\partial{x_l}} \\ &= \frac{\partial{\epsilon}}{\partial{x_L}}(1+\frac{\partial{}}{\partial{x_l}}\sum_{i=l}^{L-1}F(x_i,W_i))\\ &= \frac{\partial{\epsilon}}{\partial{x_L}}+ \frac{\partial{\epsilon}}{\partial{x_L}}\frac{\partial{}}{\partial{x_l}}\sum_{i=l}^{L-1}F(x_i,W_i)\\ \end{aligned} \tag{2.6}
?xl?????=?xL?????xl??xL??=?xL????(1+?xl???i=l∑L?1?F(xi?,Wi?))=?xL????+?xL?????xl???i=l∑L?1?F(xi?,Wi?)?(2.6)
公式2.6 中反映了:
- 在整個訓練程序中, ? x l ∑ i = l L ? 1 F ( x i , W i ) {\partial{x_l}}\sum_{i=l}^{L-1}F(x_i,W_i) ?xl?∑i=lL?1?F(xi?,Wi?)不可能一直為-1,所以殘差網路中不會出現梯度消失的問題
- ? ? ? x l \frac{\partial{\epsilon}}{\partial{x_l}} ?xl????表示L層的梯度可以直接傳遞給任何一個比其淺的l層
2.4 直接映射是最好選擇?
1.3 中我們假設了
- h ( . ) h(.) h(.)是直接映射
- f ( . ) f(.) f(.)是激活函式,一般使用ReLU,
對于假設1,采用反證法:假設
h
(
x
l
)
=
λ
l
x
l
h(x_l) = \lambda_{l}x_l
h(xl?)=λl?xl?,那么這個時候殘差塊可以表示為:
x
l
+
1
=
λ
l
x
l
+
F
(
x
l
,
W
l
)
(2.7)
x_{l+1} = \lambda_lx_l+F(x_l,W_l) \tag{2.7}
xl+1?=λl?xl?+F(xl?,Wl?)(2.7)
對于更深的層:
x
L
=
(
∏
i
=
l
L
?
1
λ
i
)
x
l
+
∑
i
=
l
L
?
1
F
(
x
i
,
W
i
)
(2.8)
x_L = (\prod_{i=l}^{L-1}\lambda_i)x_l + \sum_{i=l}^{L-1}F(x_i,W_i) \tag{2.8}
xL?=(i=l∏L?1?λi?)xl?+i=l∑L?1?F(xi?,Wi?)(2.8)
為了簡化問題,只考慮公式左半部分
x
L
=
(
∏
i
=
l
L
?
1
λ
i
)
x
l
x_L = (\prod_{i=l}^{L-1}\lambda_i)x_l
xL?=(∏i=lL?1?λi?)xl?,損失函式
?
\epsilon
?關于
x
l
x_l
xl?的梯度可以表示為:
?
?
?
x
l
=
?
?
?
x
L
(
(
∏
i
=
l
L
?
1
λ
i
)
+
?
?
x
l
F
(
x
i
,
W
i
)
)
(2.9)
\frac{\partial{\epsilon}}{\partial{x_l}} = \frac{\partial{\epsilon}}{\partial{x_L}}((\prod_{i=l}^{L-1}\lambda_i)+\frac{\partial{}}{\partial{x_l}}F(xi,Wi)) \tag{2.9}
?xl????=?xL????((i=l∏L?1?λi?)+?xl???F(xi,Wi))(2.9)
這個公式反映了:
- 當 λ > 1 \lambda > 1 λ>1,很有可能發生梯度爆炸(因為是連乘)
- 當 λ < 1 \lambda < 1 λ<1, 多層的影響下,梯度變為0,梯度消失,阻礙殘差網路資訊的反向傳遞,影響殘差網路的訓練
這里參考詳解殘差網路
2.5 從梯度下降上看為什么殘差網路為什么可以保證模型不變差
假設一個10層網路的輸出為
y
=
f
(
x
)
y = f(x)
y=f(x),關于底層的一個引數w的梯度為(不考慮loss,直接用輸出表示了)
y
′
=
?
y
?
w
(2.10)
y' = \frac{\partial{y}}{\partial{w}} \tag{2.10}
y′=?w?y?(2.10)
w的更新為:
w
=
w
?
D
?
y
?
w
(2.11)
w = w - D\frac{\partial{y}}{\partial{w}} \tag{2.11}
w=w?D?w?y?(2.11)
在其上面再添加10層得到的輸出為
y
^
=
g
(
y
)
=
g
(
f
(
x
)
)
(2.12)
\hat{y} = g(y) = g(f(x)) \tag{2.12}
y^?=g(y)=g(f(x))(2.12)
關于同樣一個引數w的梯度為:
y
^
′
=
g
(
f
(
x
)
)
′
=
?
y
^
?
y
?
y
?
w
(2.13)
\hat{y} ' = g(f(x))' = \frac{\partial{\hat{y}}}{\partial{y}} \frac{\partial{y}}{\partial{w}} \tag{2.13}
y^?′=g(f(x))′=?y?y^???w?y?(2.13)
問題就來了: ? y ^ ? y \frac{\partial{\hat{y}}}{\partial{y}} ?y?y^?? 相當于是頂部層的一個結果和真實結果的一個偏差,如果這個部分特別小的話,梯度就會特別小,導致沒有辦法更新(特別是頂部如果是全連接層這種可以極大地提取特征的層影響非常大)
看看ResNet如何解決的:
ResNet其實是將上一層網路的輸出和該層網路的輸出組合起來作為下一層網路的輸入:
y
r
e
s
i
d
u
a
l
=
f
(
x
)
+
g
(
f
(
x
)
)
(2.14)
y_{residual} = f(x) + g(f(x)) \tag{2.14}
yresidual?=f(x)+g(f(x))(2.14)
那么它的梯度就是:
y
r
e
s
i
d
u
a
l
′
=
?
y
?
w
+
?
y
^
?
y
?
y
?
w
(2.15)
y_{residual}' = \frac{\partial{y}}{\partial{w}} + \frac{\partial{\hat{y}}}{\partial{y}} \frac{\partial{y}}{\partial{w}} \tag{2.15}
yresidual′?=?w?y?+?y?y^???w?y?(2.15)
華點出來:即使后面部分是一個非常小的數,$f(x)'$仍然能保證這梯度不是特別小
三、動手實作殘差網路
3.1 定義殘差塊
兩種型別的網路:
- 一種是在
use_1x1conv=False、應用 ReLU 非線性函式之前,將輸入添加到輸出, - 另一種是在
use_1x1conv=True,添加通過 1 × 1 1 \times 1 1×1 卷積調整通道和解析度,
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
class Residual(nn.Module):
def __init__(self,input_channels,num_channels,use_1x1conv=False,strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels,num_channels,kernel_size=3,padding=1,stride=strides)
self.conv2 = nn.Conv2d(num_channels,num_channels,kernel_size=3,padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels,num_channels,kernel_size=1,stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self,X):
Y = self.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return self.relu(Y)
# 驗證塊
blk = Residual(3, 3)
X = torch.rand(4, 3, 6, 6)
Y = blk(X)
Y.shape
torch.Size([4, 3, 6, 6])
# 也可以在增加通道數的同時,高寬減半
blk = Residual(3, 6, use_1x1conv=True, strides=2)
blk(X).shape
torch.Size([4, 6, 3, 3])
3.2 構建ResNet模型
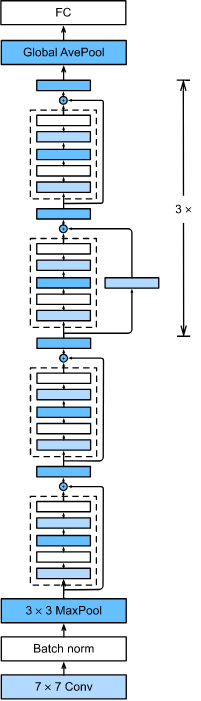
(1)ResNet 的前兩層跟 GoogLeNet 中的一樣:
在輸出通道數為 64、步幅為 2 的
7
×
7
7 \times 7
7×7 卷積層后,接步幅為 2 的
3
×
3
3 \times 3
3×3 的最大池化層,
不同之處在于 ResNet 每個卷積層后增加了批量歸一化層,
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
(2)使用ResNet block構建完整的ResNet
GoogLeNet 在后面接了 4 個由Inception塊組成的模塊,ResNet 則使用 4 個由殘差塊組成的模塊,每個模塊使用若干個同樣輸出通道數的殘差塊,
- 第一個模塊的通道數同輸入通道數一致,由于之前已經使用了步幅為 2 的最大池化層,所以無須減小高和寬,
- 之后的每個模塊在第一個殘差塊里將上一個模塊的通道數翻倍,并將高和寬減半,
def resnet_block(input_channels,num_channels,num_residuals,first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(
Residual(input_channels,num_channels,use_1x1conv=True,strides=2)
)
else:
blk.append(
Residual(num_channels,num_channels)
)
return blk
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True)) # 這個高寬不減半,通道數加倍
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
(3)在ResNet加入平均池化層和全連接層輸出
net = nn.Sequential(b1, b2, b3, b4, b5, nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(), nn.Linear(512, 10))
(4)看一看網路輸出的大小
X = torch.rand(size=(1, 1, 224, 224))
for layer in net:
X = layer(X)
print(layer.__class__.__name__, 'output shape:\t', X.shape)
Sequential output shape: torch.Size([1, 64, 56, 56])
Sequential output shape: torch.Size([1, 64, 56, 56])
Sequential output shape: torch.Size([1, 128, 28, 28])
Sequential output shape: torch.Size([1, 256, 14, 14])
Sequential output shape: torch.Size([1, 512, 7, 7])
AdaptiveAvgPool2d output shape: torch.Size([1, 512, 1, 1])
Flatten output shape: torch.Size([1, 512])
Linear output shape: torch.Size([1, 10])
3.3 訓練模型
# 讀取資料
from torchvision import transforms
import torchvision
from torch.utils import data
batch_size = 256
def get_dataloader_workers():
"""使用四個行程讀取資料"""
return 4
def load_data_fashion_mnist(batch_size,resize=None):
"""下載Fashion-MNIST資料集,并將其保存至記憶體中"""
trans = [transforms.ToTensor()]
if resize:
trans.insert(0,transforms.Resize(resize)) # transforms.Resize將圖片最小的一條邊縮放到指定大小,另一邊縮放對應比例
trans = transforms.Compose(trans) # compose用于串聯多個操作
mnist_train = torchvision.datasets.FashionMNIST(root="./data",
train=True,
transform=trans,
download=True)
mnist_test = torchvision.datasets.FashionMNIST(root="./data",
train=False,
transform=trans,
download=True)
return (data.DataLoader(mnist_train,batch_size,shuffle=True,
num_workers=get_dataloader_workers()),
data.DataLoader(mnist_test,batch_size,shuffle=True,
num_workers = get_dataloader_workers()))
def evaluate_accuracy_gpu(net, data_iter, device=None): #@save
"""使用GPU計算模型在資料集上的精度,"""
if isinstance(net, torch.nn.Module):
net.eval() # 設定為評估模式
if not device:
device = next(iter(net.parameters())).device
# 正確預測的數量,總預測的數量
metric = d2l.Accumulator(2)
for X, y in data_iter:
if isinstance(X, list):
# BERT微調所需的(之后將介紹)
X = [x.to(device) for x in X]
else:
X = X.to(device)
y = y.to(device)
metric.add(d2l.accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
#@save
def train(net, train_iter, test_iter, num_epochs, lr, device):
"""用GPU訓練模型"""
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print('training on', device)
net.to(device) # 將網路挪到gpu上
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['train loss', 'train acc', 'test acc'])
timer, num_batches = d2l.Timer(), len(train_iter)
for epoch in range(num_epochs):
# 訓練損失之和,訓練準確率之和,范例數
metric = d2l.Accumulator(3)
net.train()
for i, (X, y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
with torch.no_grad():
metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(train_l, train_acc, None))
test_acc = evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, '
f'test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec '
f'on {str(device)}')
lr, num_epochs, batch_size = 0.05, 10, 256
train_iter, test_iter = load_data_fashion_mnist(batch_size, resize=96)
train(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
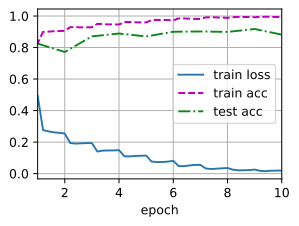
loss 0.019, train acc 0.994, test acc 0.882
854.6 examples/sec on cuda:0
四、總結及問題
4.1 總結
- 學習嵌套函式(nested function)是訓練神經網路的理想情況,在深層神經網路中,學習另一層作為恒等映射(identity function)較容易(盡管這是一個極端情況),
- 殘差映射可以更容易地學習同一函式,例如將權重層中的引數近似為零,
- 利用殘差塊(residual blocks)可以訓練出一個有效的深層神經網路:輸入可以通過層間的殘余連接更快地向前傳播,
- 殘差網路(ResNet)對隨后的深層神經網路設計產生了深遠影響,無論是卷積類網路還是全連接類網路,
4.2 問題
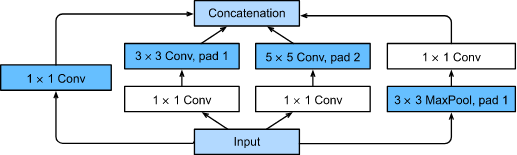
- Inception塊與殘差塊之間的主要區別是什么?在洗掉了Inception塊中的一些路徑之后,它們是如何相互關聯的?
- 參考 ResNet 論文
He.Zhang.Ren.ea.2016中的表 1,以實作不同的變體,
參考文章詳解殘差網路
- 對于更深層次的網路,ResNet 引入了“bottleneck”架構來降低模型復雜性,請你試著去實作它,
之后再實作
- 在 ResNet 的后續版本中,作者將“卷積層、批量歸一化層和激活層”結構更改為“批量歸一化層、激活層和卷積層”結構,請你做這個改進,詳見
He.Zhang.Ren.ea.2016*1中的圖 1,
調整一下結構即可,效果還不錯
- 為什么即使函式類是嵌套的,我們仍然要限制增加函式的復雜性呢?
我認為第一是因為復雜的函式會增加擬合的計算要求,第二是增加了過擬合的風險,第三是復雜的函式對網路結構底層訓練的要求太大,實作起來效果會很差
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/294113.html
標籤:AI