目錄
1.二分分類
2.logistic 回歸
3.logistic 代價函式
4.梯度下降法
5.計算圖
6.logistic回歸中的梯度下降法
7.向量化
8.向量化logistic回歸
9.Python中的廣播
10.python numpy
1.二分分類

2.logistic 回歸

3.logistic 代價函式





4.梯度下降法

5.計算圖
可以參考劉普洪老師的計算圖
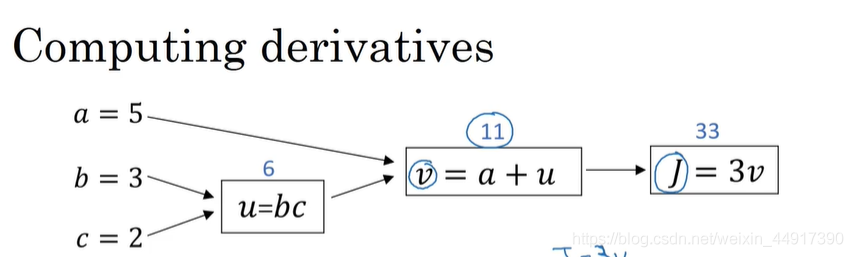
6.logistic回歸中的梯度下降法
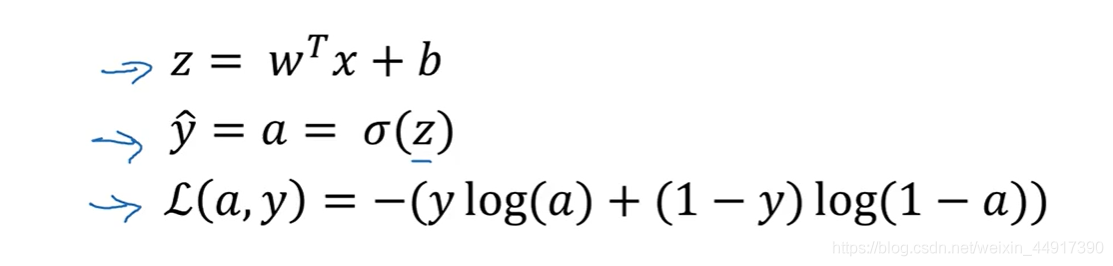
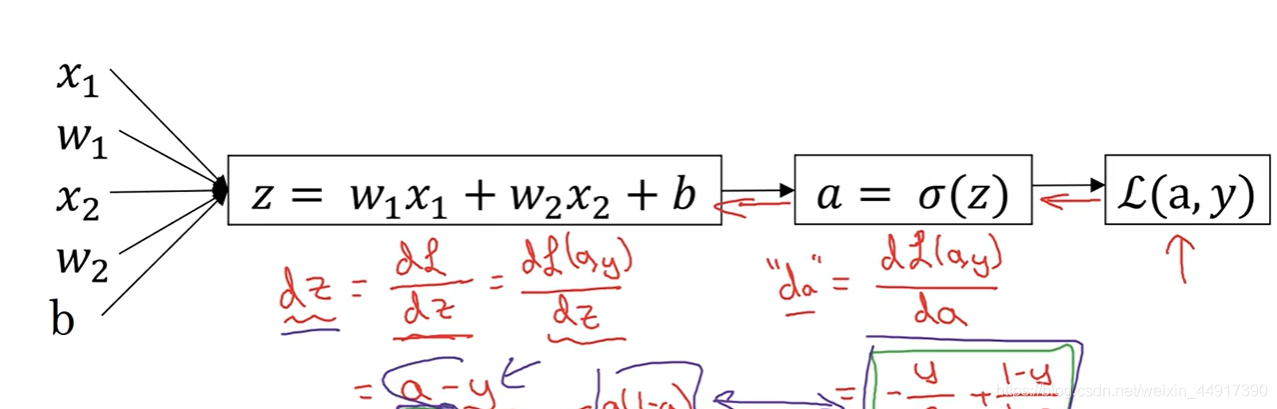

7.向量化




程式第二、六行錯誤!!!
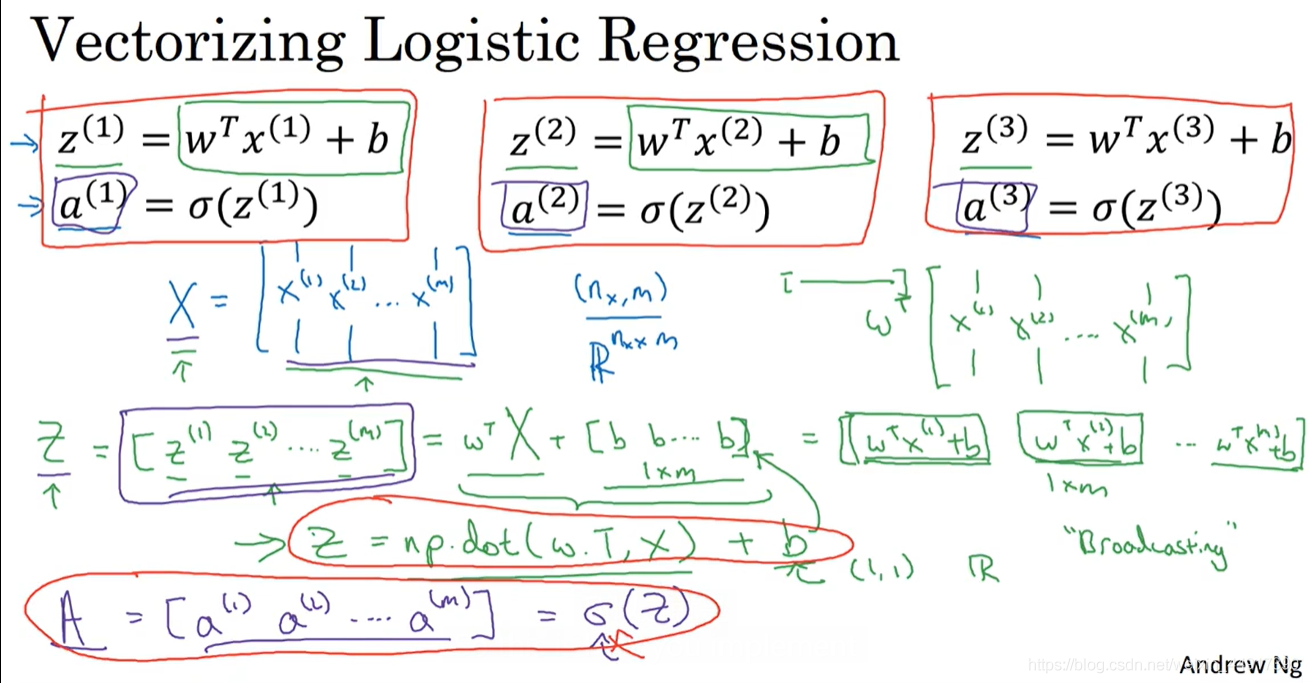
8.向量化logistic回歸


9.Python中的廣播


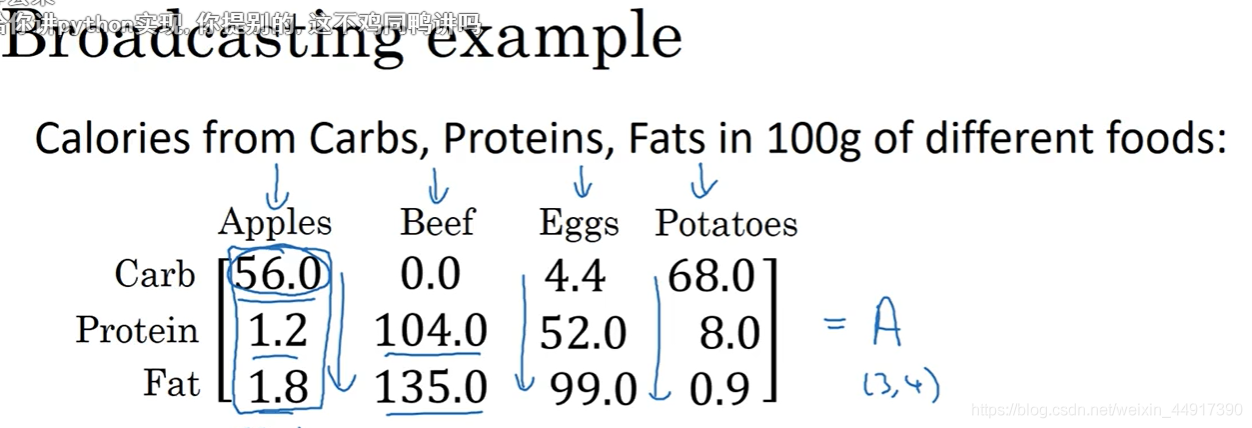
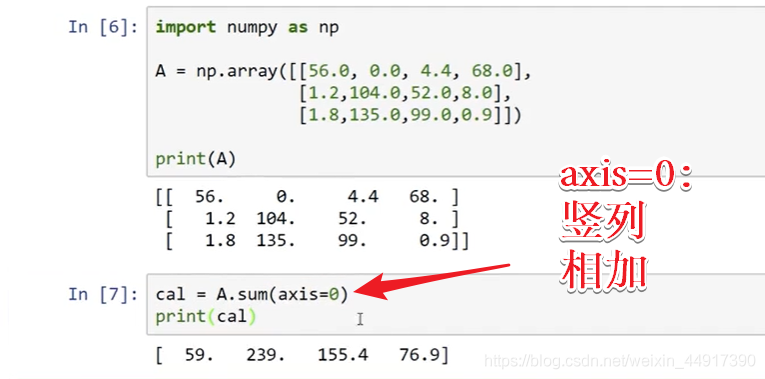
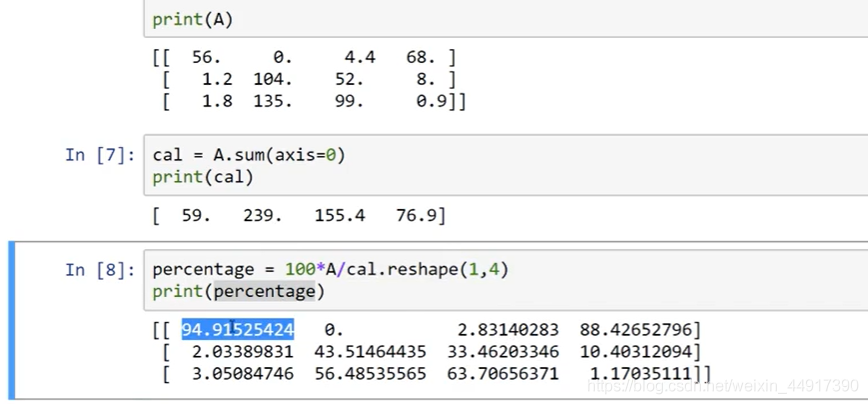





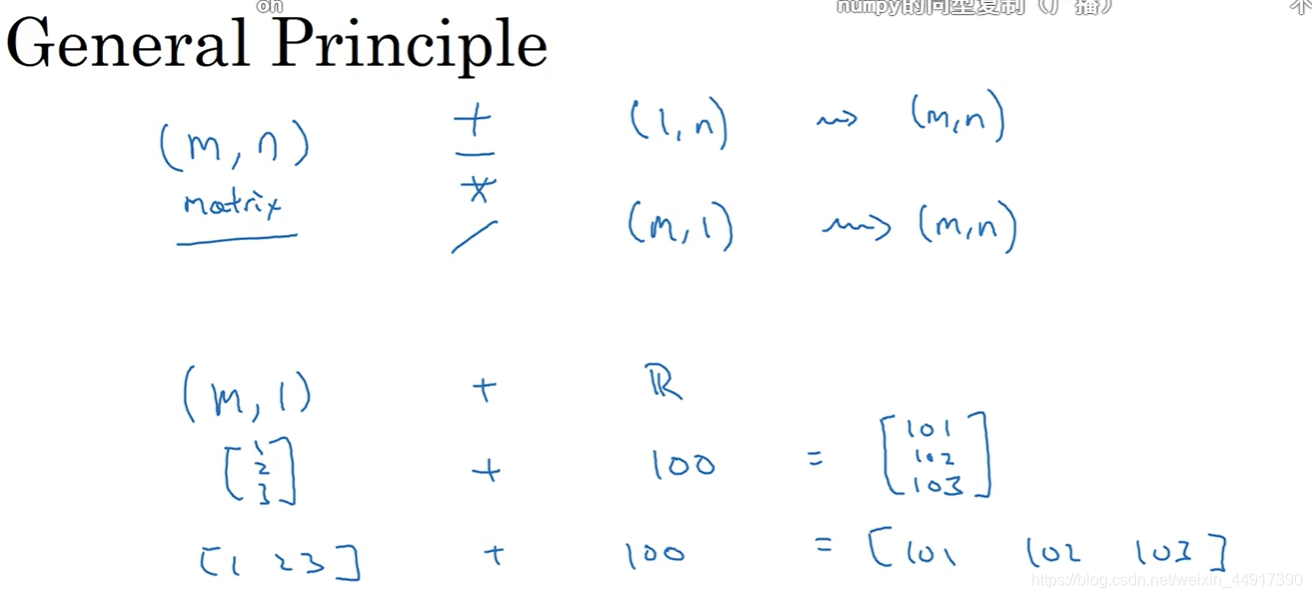
10.python numpy

(測驗)作業:



(編程)作業
資料集測驗:
#! /usr/bin/env python
# -*- coding: utf-8 -*-
"""
============================================
時間:2021.8.15
作者:手可摘星辰不去高聲語
檔案名:lr_utils.py
功能:參考資料集(訓練集 + 測驗集),輸出資料集的圖片和標簽
1、Ctrl + Enter 在下方新建行但不移動游標;
2、Shift + Enter 在下方新建行并移到新行行首;
3、Shift + Enter 任意位置換行
4、Ctrl + D 向下復制當前行
5、Ctrl + Y 洗掉當前行
6、Ctrl + Shift + V 打開剪切板
7、Ctrl + / 注釋(取消注釋)選擇的行;
8、Ctrl + E 可打開最近訪問過的檔案
9、Double Shift + / 萬能搜索
============================================
"""
import numpy as np
import matplotlib.pyplot as plt
import h5py
class Load_data:
def __init__(self):
self.train_dataset = h5py.File('datasets/train_catvnoncat.h5', "r")
self.test_dataset = h5py.File('datasets/test_catvnoncat.h5', "r")
def load_dataset(self):
"""
運行檔案可以查看函式輸出的具體資訊
"""
# your train set features(訓練集里面的影像資料:本訓練集中209張64×64的影像)
train_set_x_orig = np.array(self.train_dataset["train_set_x"][:])
# your train set labels(訓練集的影像的分類值:0不是貓,1是貓)
train_set_y_orig = np.array(self.train_dataset["train_set_y"][:])
# your test set features(測驗集里面的影像資料:本訓練集中50張64×64的影像)
test_set_x_orig = np.array(self.test_dataset["test_set_x"][:])
# your test set labels(測驗集的影像的分類值:0不是貓,1是貓)
test_set_y_orig = np.array(self.test_dataset["test_set_y"][:])
# the list of classes(保存的是以bytes型別保存的兩個字串資料,資料為:[b’non-cat’ b’cat’])
classes = np.array(self.test_dataset["list_classes"][:])
train_set_y_orig = train_set_y_orig.reshape((1, train_set_y_orig.shape[0]))
test_set_y_orig = test_set_y_orig.reshape((1, test_set_y_orig.shape[0]))
return train_set_x_orig, train_set_y_orig, test_set_x_orig, test_set_y_orig, classes
if __name__ == '__main__':
Load_dataset = Load_data()
train_set_x_orig, train_set_y_orig, test_set_x_orig, test_set_y_orig, classes = Load_dataset.load_dataset()
# 查看訓練集的資訊
m_train = train_set_y_orig.shape[1] # 訓練集里圖片的數量,
m_test = test_set_y_orig.shape[1] # 測驗集里圖片的數量,
num_px = train_set_x_orig.shape[1] # 訓練、測驗集里面的圖片的寬度和高度(均為64x64),
# 現在看一看我們加載的東西的具體情況
print("訓練集的數量: m_train = " + str(m_train))
print("測驗集的數量 : m_test = " + str(m_test))
print("每張圖片的寬/高 : num_px = " + str(num_px))
print("每張圖片的大小 : (" + str(num_px) + ", " + str(num_px) + ", 3)")
print("訓練集_圖片的維數 : " + str(train_set_x_orig.shape))
print("訓練集_標簽的維數 : " + str(train_set_y_orig.shape))
print("測驗集_圖片的維數: " + str(test_set_x_orig.shape))
print("測驗集_標簽的維數: " + str(test_set_y_orig.shape))
# 查看1:4張圖片以及分類
for numb in range(0, 4):
plt.subplot(2, 2, numb+1)
index = numb
plt.imshow(train_set_x_orig[index])
# 標題顯示訓練集的圖片的分類
# np.squeeze表示降維([]-> 數值)
# decode("utf-8")進行解碼(classes是以bytes型別保存的兩個字串資料)
plt.title(str(classes[np.squeeze(train_set_y_orig[:, index])].decode("utf-8")))
plt.xlabel("index:" + str(index))
plt.ylabel("y:" + str(train_set_y_orig[:, index]))
plt.show()


主函式:
#! /usr/bin/env python
# -*- coding: utf-8 -*-
"""
============================================
時間:2021.8.15
作者:手可摘星辰不去高聲語
檔案名:具有神經網路思想的Logistic回歸-實作貓貓識別.py
功能:
1、Ctrl + Enter 在下方新建行但不移動游標;
2、Shift + Enter 在下方新建行并移到新行行首;
3、Shift + Enter 任意位置換行
4、Ctrl + D 向下復制當前行
5、Ctrl + Y 洗掉當前行
6、Ctrl + Shift + V 打開剪切板
7、Ctrl + / 注釋(取消注釋)選擇的行;
8、Ctrl + E 可打開最近訪問過的檔案
9、Double Shift + / 萬能搜索
============================================
"""
import numpy as np
import matplotlib.pyplot as plt
import h5py
from lr_utils import Load_data
# 1. 準備資料集=========================================================================================
train_set_x_orig, train_set_y, test_set_x_orig, test_set_y, classes = Load_data().load_dataset()
# 由于訓練集_圖片的維數 : (209, 64, 64, 3)
# 為了方便,我們要把維度為(64,64,3)的numpy陣列重新構造為(64 x 64 x 3,1)的陣列
# 把陣列變為209行的矩陣(因為訓練集里有209張圖片),-1 表示自動計算,轉置:由列變行
# 將訓練集的維度降低并轉置,此時維度: (12288, 209),一串列示一張圖片樣本,一共是209行,那就是209張圖片
train_set_x_flatten = np.array(train_set_x_orig.reshape(train_set_x_orig.shape[0], -1)).T
# 將測驗集的維度降低并轉置,此時維度: (12288, 50)
test_set_x_flatten = np.array(test_set_x_orig.reshape(test_set_x_orig.shape[0], -1)).T
# 標準化資料
train_set_x = train_set_x_flatten / 255
test_set_x = test_set_x_flatten / 255
# 一張圖片的資料 [:, 0]表示取X中的第1列的資料,即一張圖片
one_picture_train = train_set_x_flatten[:, 25]
# 這段代碼是是抽出其中的一列資料,重新組合成一張圖片的三維矩陣,然后顯示出來,以驗證reshape矩陣轉換的正確性
# picture_data = one_picture_train.reshape(-1, 64, 64, 3)
# print(picture_data)
# plt.imshow(np.squeeze(picture_data))
# plt.show()
# 2. 設計模型==========================================================================================
# 2.1 前向傳播函式
def forward(train_x, train_w, train_b):
Z = np.dot(train_w.T, train_x) + train_b
A = sigmoid(Z)
return A
# 2.2 定義損失函式
def loss(train_A, train_y):
return -1*(np.dot(np.squeeze(train_y), np.squeeze(np.log(train_A))) + np.dot(np.squeeze((1-train_y)), np.log(np.squeeze(1-train_A))))
# 2.3 定義sigmoid函式
# 對sigmoid函式的優化,避免了出現極大的資料溢位
def sigmoid(inx):
if np.mean(inx) >= 0:
return 1.0 / (1 + np.exp(-inx))
else:
return np.exp(inx) / (1 + np.exp(inx))
# 3. 初始化引數========================================================================================
train_w = np.zeros((12288, 1), dtype=int)
train_b = np.zeros((1, 209), dtype=int)
learn_rate = 0.01
num_train = train_set_y.shape[1]
loss_list = []
iter_list = []
# 4. 回圈=============================================================================================
for iter in range(2000):
# 4.1 計算當前損失(前向傳播)
A = forward(train_set_x, train_w, train_b)
cost = loss(A, train_set_y)/num_train
# 4.2 計算當前梯度(反向傳播)
dZ = A - train_set_y
dW = np.dot(train_set_x, dZ.T) / num_train
dB = np.sum(dZ) / num_train
# 4.3 更新引數
train_w = train_w - learn_rate * dW
train_b = train_b - learn_rate * dB
iter_list.append(iter)
loss_list.append(cost)
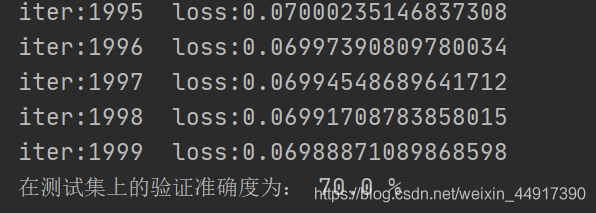
print("iter:{} loss:{}".format(iter, cost))
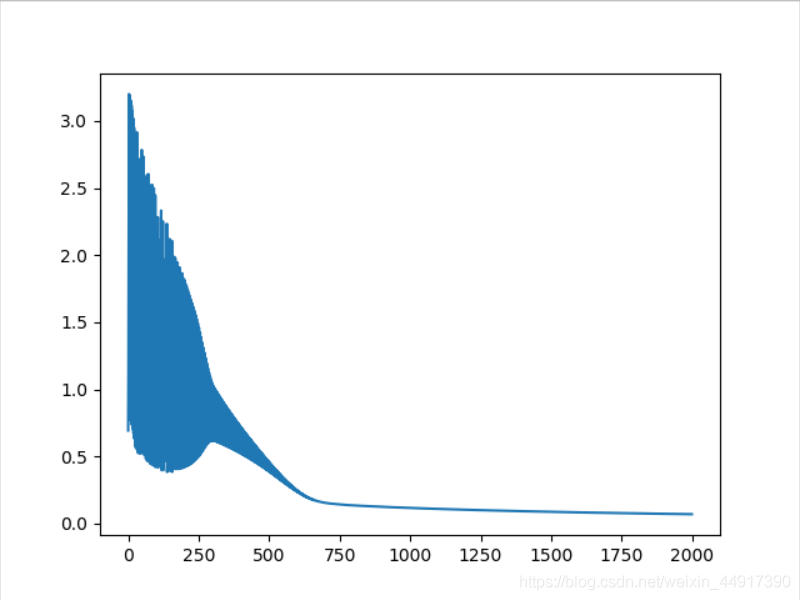
# 輸出loss函式的變化圖
plt.plot(iter_list, loss_list)
plt.show()
# 驗證測驗集結果=======================================================================================
numb_test = test_set_y.shape[1]
result = 0
for i in range(0, numb_test):
one_picture_test = test_set_x_flatten[:, i]
pred_value = forward(one_picture_test, train_w, train_b)
pred_value = np.mean(pred_value)
if pred_value > 0.5:
pred_value = 1
else:
pred_value = 0
test_value = test_set_y[0][i]
if test_value == pred_value:
result = result + 1
print("在測驗集上的驗證準確度為:", result/numb_test * 100, "%")
最需要注意的地方是:輸入圖片矩陣那一塊!!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/294116.html
標籤:AI