學習總結
(1)上一小節主要是先講Encoder,這次是學習Decoder(根據并行性分為AT和NAT兩種)、Encoder和Decoder之間的關系(通過Cross Attention機制)還有訓練的一些tips(好多tips嗚嗚),
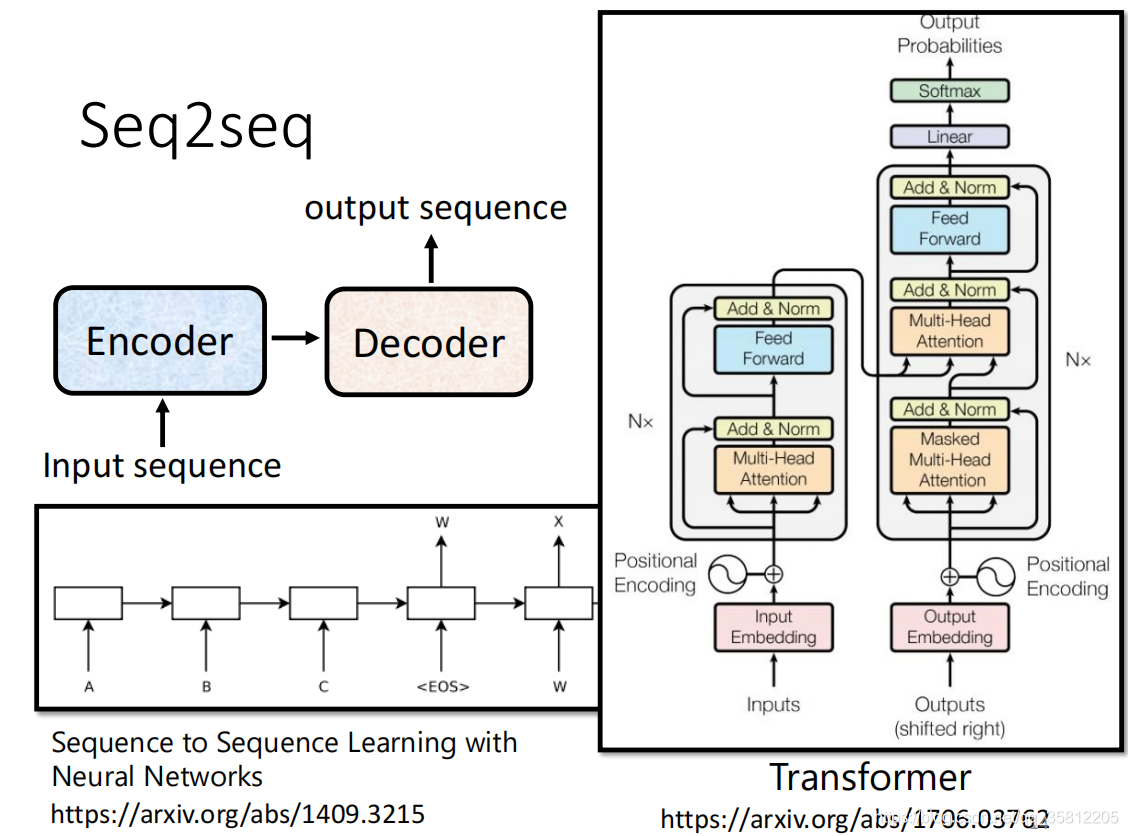
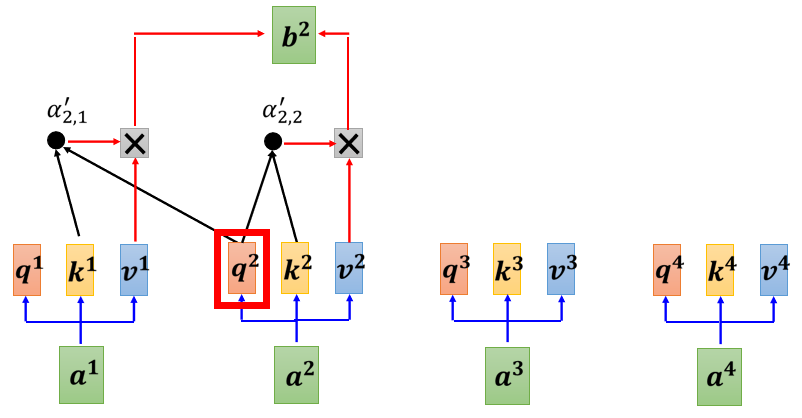
(2)Cross Attention:比如在Decoder輸入 BEGIN 輸入“機”,產生一個向量,該向量一樣乘上一個 Linear 的 Transform 后得到 q’(得到一個 Query),這個 Query 一樣跟
k
1
k
2
k
3
k^1 k^2 k^3
k1k2k3去計算 Attention 的分數(得到
α
1
α
2
α
3
α_1 α_2 α_3
α1?α2?α3?),attention再跟
v
1
v
2
v
3
v^1 v^2 v^3
v1v2v3 做 Weighted Sum 做加權,然后加起來得到 v’,交給接下來 Fully-Connected Network 做處理,
ps:QKV三個矩陣都是來源于詞向量矩陣,
(3)在(2)中是計算完attention即
α
i
α_i
αi?(即對應各個向量value的權重)后還要乘這些value加權求和,就像一張圖,attention只是告訴你你的注意力要注意在左上角,但是沒告訴你左上角是什么你還是不知道這張圖表達了什么——【關系程度】最后要和【背景關系】結合,也即將向量再編碼下,
附:秋陽大佬畫的圖哈哈哈:

文章目錄
- 學習總結
- 一、Decoder – Autoregressive (AT)
- Decoder內部結構
- 1)帶Masked的MHA
- 2)特殊符號END
- 二、Decoder – Non-autoregressive (NAT)
- 2.1 AT v.s. NAT
- 2.2 begin要放幾個
- 2.3 NAT的Decoder的好處
- 三、Encoder-Decoder
- 3.1 Cross Attention的運作流程
- 3.2 其他的Cross Attension 方式
- 四、Training
- 五、訓練的Tips
- 5.1 Copy Mechanism
- 5.2 Summarization摘要
- 5.3 Guided Attention
- 5.4 Beam Search
- 5.5 Optimizing Evaluation Metrics?
- 5.6 Scheduled Sampling
一、Decoder – Autoregressive (AT)
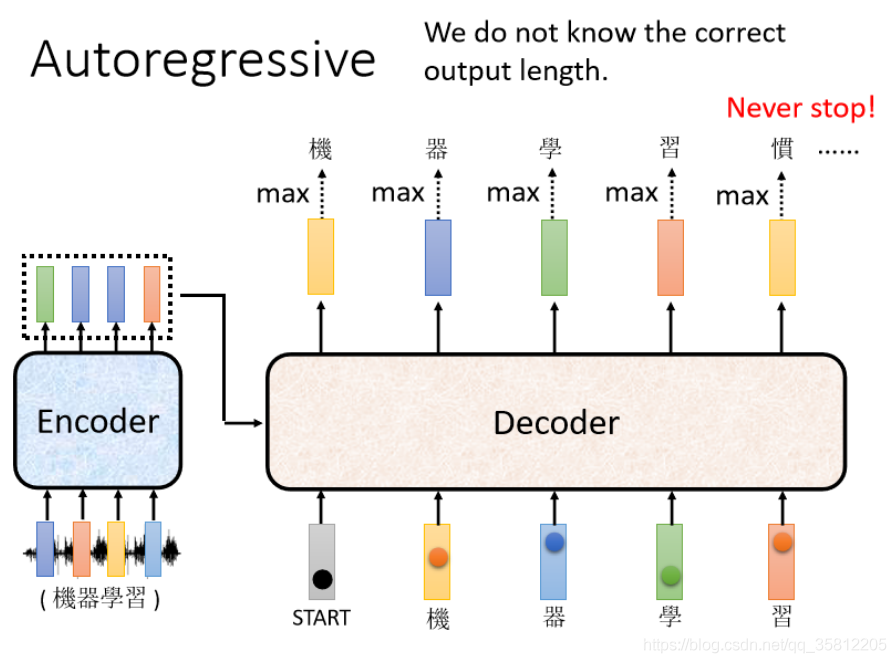
Decoder有兩種,比較常見的是Autoregressive Decoder,我們上小節說了Encoder是做了輸入一個vector sequence,輸出另外一個vector sequence,接下來輪到Decoder產生輸出,如產生語音識別的結果,
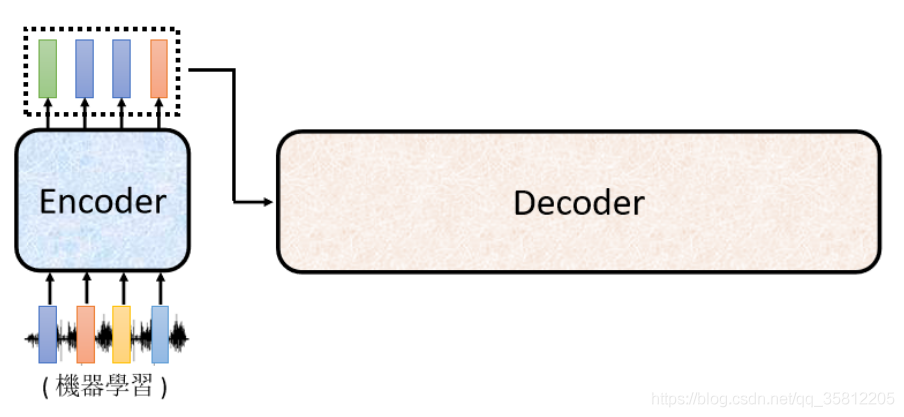
Decoder做的事情是把Encoder的輸出先讀進去,那Decoder是怎么產生一段文字的:
(1)先給它一個特殊的符號——代表開始,在開始的ppt里寫Begin Of Sentence(縮寫是BOS),這是一個special的token,就是在你的Lexicon(字典)里面,即Decoder可能產生的文字里面多加一個特殊的字——該字代表begin(開始),
假設你要處理NLP問題,每一個Token都可以用一個One-Hot的Vector來表示(就其中一維是1,其他是0),所以begin也是用One-Hot Vector來表示,
(2)接著Decoder會吐出一個很長的vector(和vocabulary的size一樣)
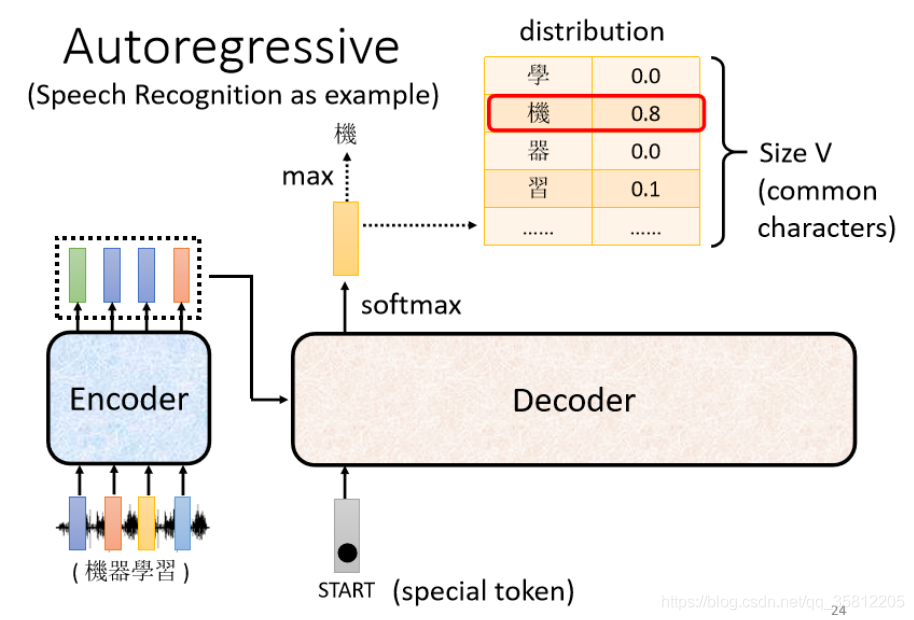
vocabulary size是什么意思?
先想好Decoder輸出的單位是什么,如果做得是中文的語音識別則我們Decoder輸出的是中文,那么vocabulary size可能就是中文方塊字的數目
不同的字典size可能是不同的,常用的中文方塊字大約三千,一半人可能人的四五千,那么這個Decoder能夠輸出常見的3000個方塊字就好(這個取決于你對該語言的理解),
再舉栗子:可以選擇輸出字母A到Z輸出英文的字母,而如果覺得字母這個單位太小了,可以用英文單詞的“詞根”作為單位,
每一個中文的字對應到一個數值,因為在產生這個向量之前,通常會先跑一個softmax(和分類一樣),所以這個向量里面的分數積一個Distribution,即該向量里面的值全部加起來等于1,分數最高的一個中文字,它就是最終的輸出,
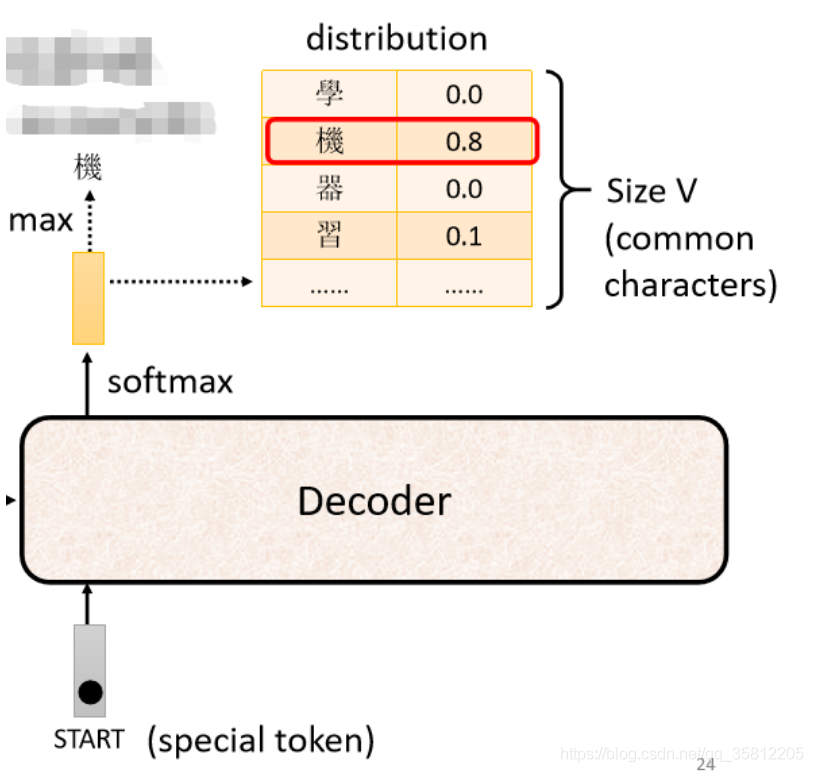
而在上面例子中“機”字的分數最高,所以就是這個Decoder第一個輸出的東東,然后把“機”字當做是Decoder新的input(原來Decoder的input只有begin這個特別的符號,現在它除了begin外還有“機”作為其input),
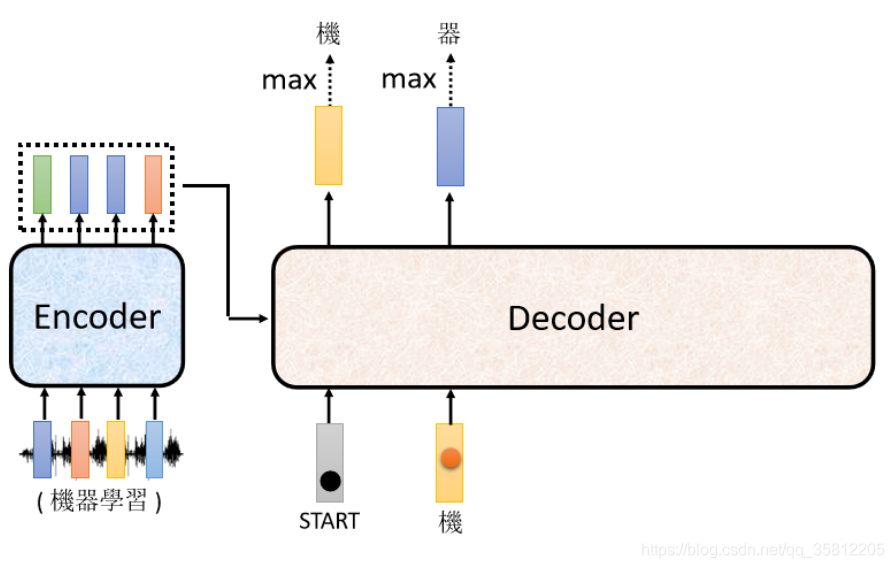
同理:根據這兩個輸入,它輸出一個藍色的向量,根據這個藍色的向量里面,給每一個中文的字的分數,我們會決定第二個輸出,哪一個字的分數最高,它就是輸出,假設"器"的分數最高,"器"就是輸出
最后,現在 Decode:
- 看到了 BEGIN
- 看到了"機"
- 看到了"器"
- 還有"學"
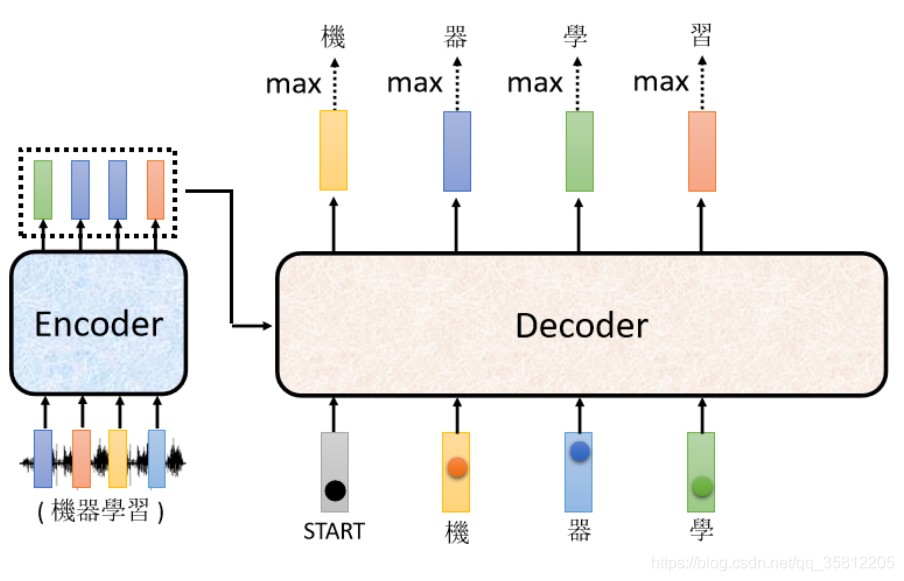
Encoder 這邊其實也有輸入,等一下再講 Encoder 的輸入,Decoder 是怎麼處理的,所以 Decoder 看到 Encoder 這邊的輸入,看到"機" 看到"器" 看到"學",決定接下來輸出一個向量,這個向量里面"習"這個中文字的分數最高的,所以它就輸出"習"
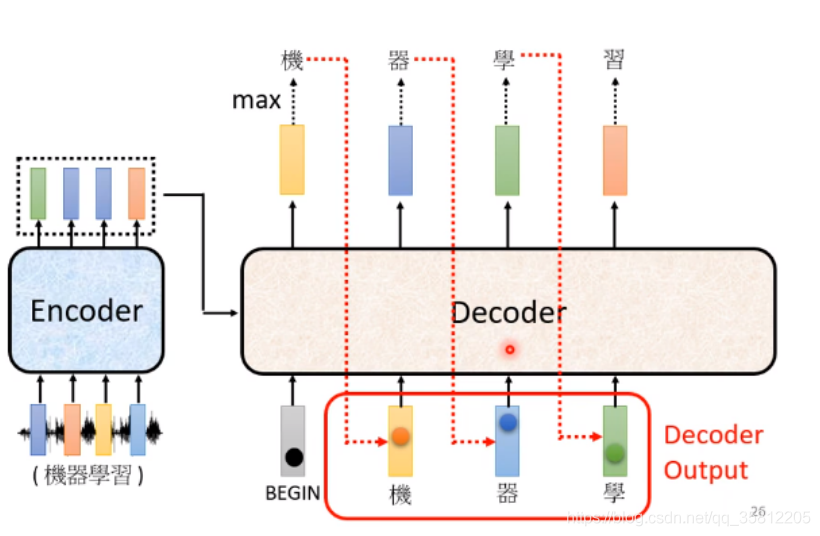
上面這個程序反復持續,其中有個關鍵之處(上圖紅色虛線),Decoder看到的輸入起始是它在前一個時間點自己的輸出,而如果Decoer看到錯誤的輸入后,讓Decoer看到自己錯誤的輸入再被Decoder自己吃進去后,會不會造成Error Propagation(一步錯步步錯)問題?——是有可能的(后面會講),
Decoder內部結構
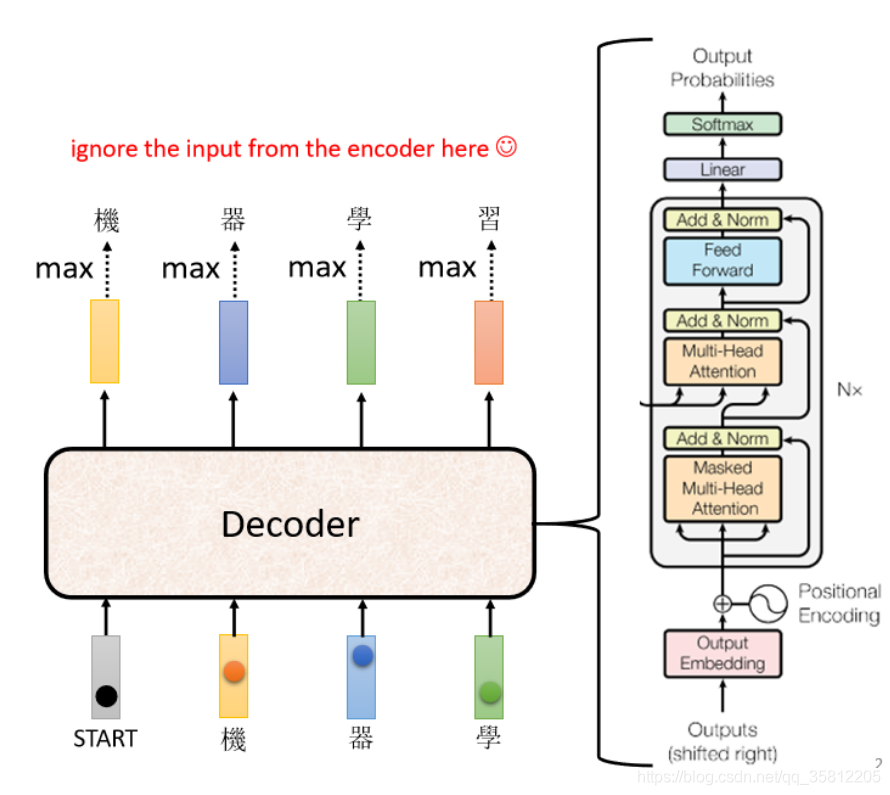
先省略Encoder部分,在transformer里面的Decoder結構如下圖所示,比Encoder稍微復雜點:
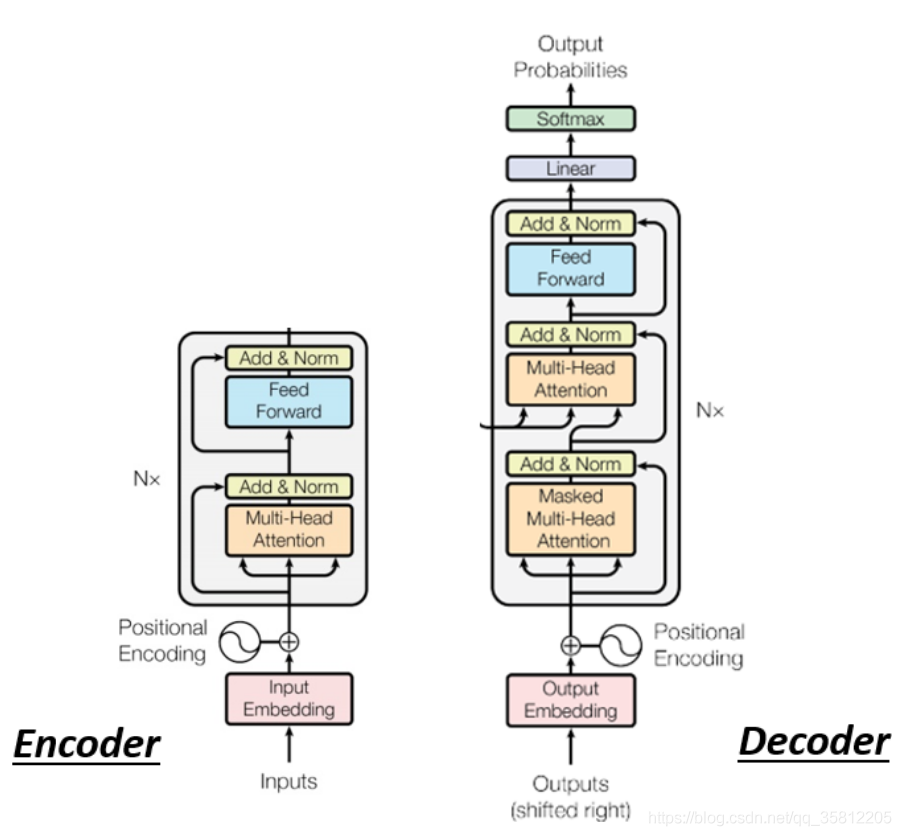
但是我們現在把Decoder中間的一塊先蓋起來,會發現Encoder和Decoder是差不多的(如下圖),兩者都是先Multi-Head Attention,然后Add & Norm,再Feed Forward,Add & Norm,重復N次,只是最后可能會再做一個softmax,使得輸出變成一個概率,
ps:注意有個地方不同,在Decoder的Multi-Head Attention這個Block上面還加了一個Masked,
1)帶Masked的MHA
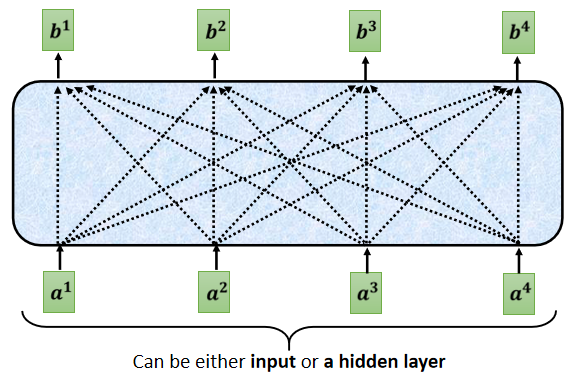
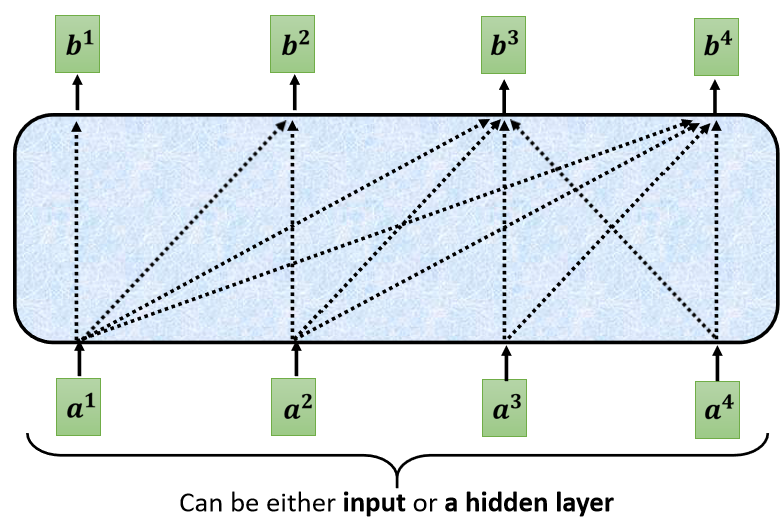
這個 Masked 的意思是這樣子的,首先這是我們原來的 Self-Attention
Input 一排 Vector,Output 另外一排 Vector,這一排 Vector 每一個輸出,都要看過完整的 Input 以后,才做決定,所以輸出 b 1 b^1 b1 的時候,其實是根據 a 1 a^1 a1 到 a 4 a^4 a4 所有的資訊,去輸出 b 1 b^1 b1
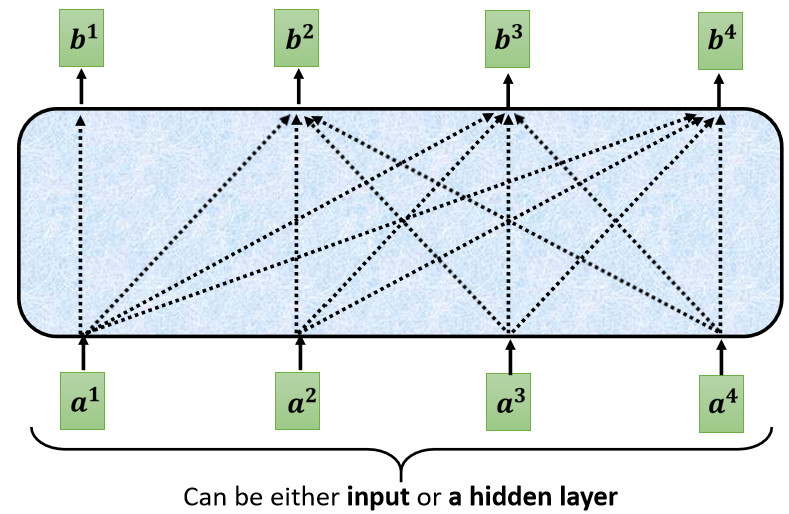
當我們把 Self-Attention,轉成 Masked Attention 的時候,它的不同點是,現在我們不能再看右邊的部分,也就是產生 b 1 b^1 b1 的時候,我們只能考慮 a 1 a^1 a1 的資訊,你不能夠再考慮 a 2 a^2 a2 a 3 a^3 a3 a 4 a^4 a4
產生 b 2 b^2 b2 的時候,你只能考慮 a 1 a^1 a1 a 2 a^2 a2 的資訊,不能再考慮 a 3 a^3 a3 a 4 a^4 a4 的資訊
產生 b 3 b^3 b3 的時候,你就不能考慮 a 4 a^4 a4 的資訊,
產生 b 4 b^4 b4 的時候,你可以用整個 Input Sequence 的資訊,這個就是 Masked 的 Self-Attention,
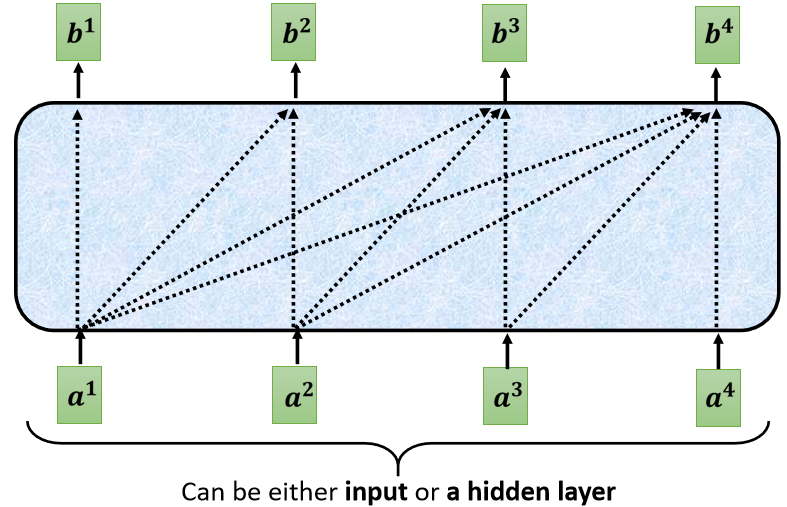
講得更具體一點,你做的事情是,當我們要產生 b 2 b^2 b2 的時候,我們只拿第二個位置的 Query b 2 b^2 b2,去跟第一個位置的 Key,和第二個位置的 Key,去計算 Attention,第三個位置跟第四個位置,就不管它,不去計算 Attention
我們這樣子不去管這個 a 2 a^2 a2 右邊的地方,只考慮 a 1 a^1 a1 跟 a 2 a^2 a2,只考慮 q 1 q^1 q1 q 2 q^2 q2,只考慮 k 1 k^1 k1 k 2 k^2 k2, q 2 q^2 q2 只跟 k 1 k^1 k1 跟 k 2 k^2 k2 去計算 Attention,然后最后只計算 b 1 b^1 b1 跟 b 2 b^2 b2 的 Weighted Sum
然后當我們輸出這個 b 2 b^2 b2 的時候, b 2 b^2 b2 就只考慮了 a 1 a^1 a1 跟 a 2 a^2 a2,就沒有考慮到 a 3 a^3 a3 跟 a 4 a^4 a4
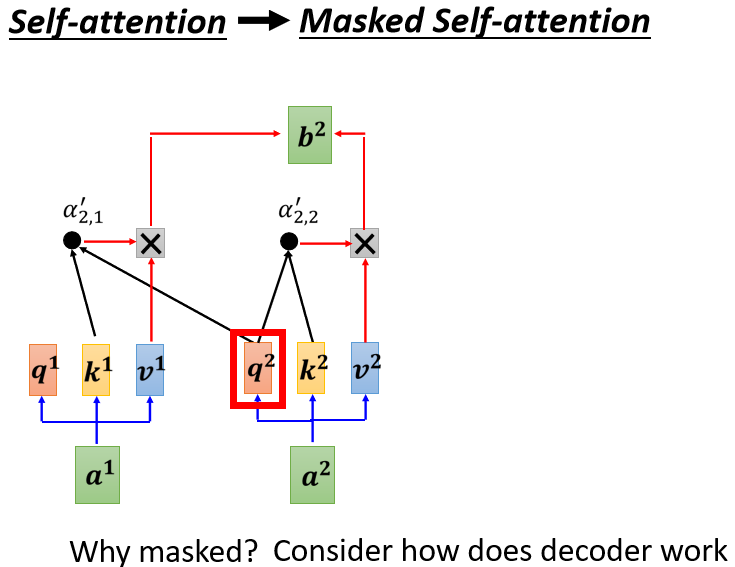
為什么需要加 Masked
這件事情其實非常地直覺:我們一開始 Decoder 的運作方式,它是一個一個輸出,所以是先有 a 1 a^1 a1 再有 a 2 a^2 a2,再有 a 3 a^3 a3 再有 a 4 a^4 a4
這跟原來的 Self-Attention 不一樣,原來的 Self-Attention, a 1 a^1 a1 跟 a 4 a^4 a4 是一次整個輸進去你的 Model 裡面的,在我們講 Encoder 的時候,Encoder 是一次把 a 1 a^1 a1 跟 a 4 a^4 a4,都整個都讀進去
但是對 Decoder 而言,先有 a 1 a^1 a1 才有 a 2 a^2 a2,才有 a 3 a^3 a3 才有 a 4 a^4 a4,所以實際上,當你有 a 2 a^2 a2,你要計算 b 2 b^2 b2 的時候,你是沒有 a 3 a^3 a3 跟 a 4 a^4 a4 的,所以你根本就沒有辦法把 a 3 a^3 a3 a 4 a^4 a4 考慮進來
所以這就是為什麼,在那個 Decoder 的那個圖上面,Transformer 原始的 Paper 特別跟你強調說,那不是一個一般的 Attention,這是一個 Masked 的 Self-Attention,意思只是想要告訴你說,Decoder 它的 Token,它輸出的東西是一個一個產生的,所以它只能考慮它左邊的東西,它沒有辦法考慮它右邊的東西
2)特殊符號END
Decoder 必須自己決定,輸出的 Sequence 的長度,你沒有辦法輕易的從輸入的 Sequence 的長度,就知道輸出的 Sequence 的長度是多少,因為并不是說輸入是 4 個向量,輸出一定就是 4 個向量,按照我們介紹的流程不斷重復,可能會一直像“推文接龍”游戲一樣推出每個字然后不會停止,所以讓Decoder可以輸出一個“斷”END特殊符號(ps:在作業的助教代碼里是將begin和end用同一個符號表示,也沒毛病),
所以我們現在,當把"習"當作輸入以后,就 Decoder 看到 Encoder 輸出的這個 Embedding,看到了 “BEGIN”,然后"機" “器” “學” "習"以后,看到這些資訊以后知道這個語音識別的結果已經結束了(它產生出來的向量END的幾率是最大的,然后輸出斷符號,最后整個Decoder產生Sequence的程序就結束了),
二、Decoder – Non-autoregressive (NAT)
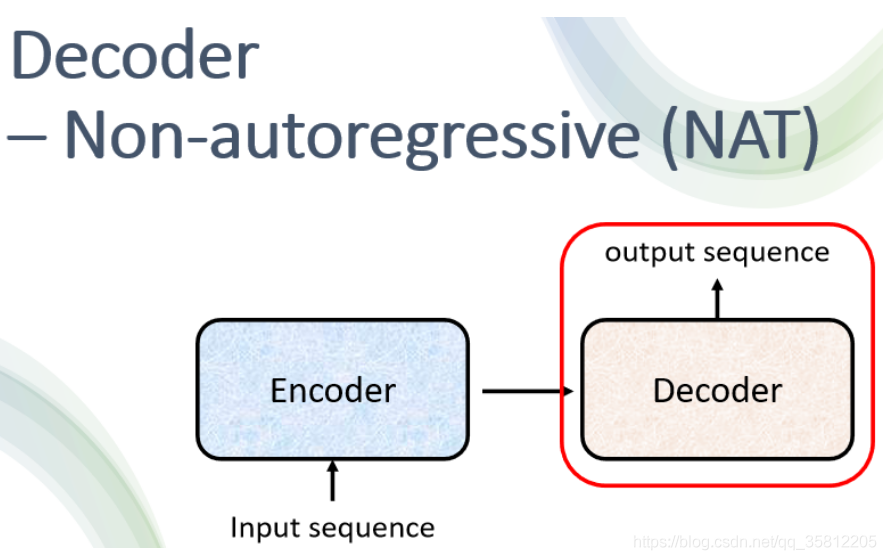
2.1 AT v.s. NAT
這個 Autoregressive 的 Model 是先輸入 BEGIN,然后出現 w1,然后再把 w1 當做輸入,再輸出 w2,直到輸出 END 為止,那 NAT 是這樣,它不是依次產生
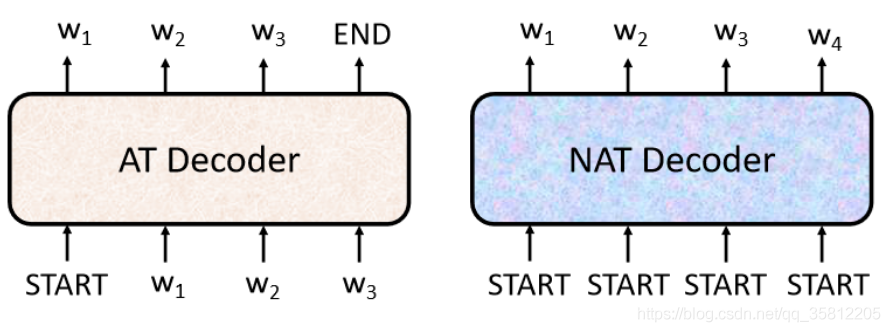
像上圖的例子如果是產生中文的句子,NAT不是依次產生一個字,而是一次把整個句子都產生出來,NAT的Decoder可能吃的是一整排的begin的token,如上圖就是丟進4個begin后就產生4個中文字,變成一個句子后即完成,
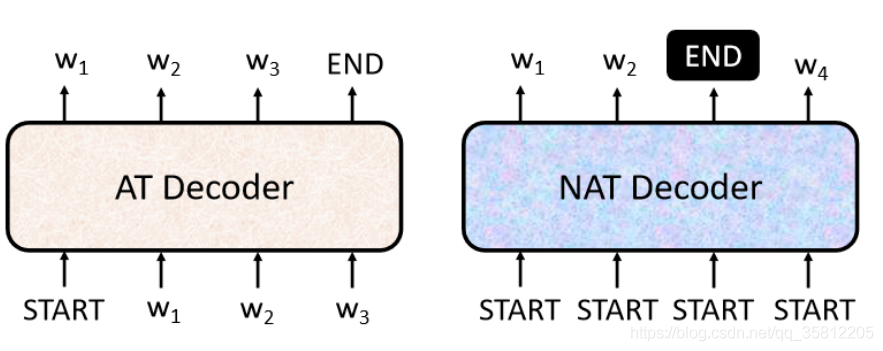
2.2 begin要放幾個
剛才說了不知道輸出的長度是多少,為了解決NAT Decoder的輸入問題,有以下幾個方法:
(1)另外learn一個classifier——吃Encoder的input,然后輸出是一個數字(代表Decoder應該要輸出的長度)
(2)給一堆begin的token,就是假設現在輸出的句子長度不超過300個字,那么給定300個begin然后輸出300個字,然后看什么地方輸出END,輸出的END的右邊就忽略掉(代表結束),
2.3 NAT的Decoder的好處

(1)并行化:NAT比一個一個字產生的AT更快,NAT Decoder是在transformer、self-attention的Decoder以后才有的,因為以前如果你是用按個LSTM或者RNN,就算給它一排begin,它也沒有辦法同時產生所有的輸出(它的輸出還是一個一個產生的),自從有個self-attention后,NAT的Decoder現在算是一個熱門的研究主題了,
(2)能夠控制輸出的長度,如語音合成今天你都可以用Sequence To Sequence 的模型來做,那最知名的是一個叫做 Tacotron 的模型(是 AT 的 Decoder)
那有另外一個模型叫 FastSpeech,那它是 NAT 的 Decoder,那 NAT 的 Decoder 有一個好處,就是你可以控制你輸出的長度,
你可能有一個 Classifier,決定 NAT 的 Decoder 應該輸出的長度,那如果在做語音合成的時候,假設你現在突然想要讓你的系統講快一點,加速,那你就把那個 Classifier 的 Output 除以二,它講話速度就變兩倍快,然后如果你想要這個講話放慢速度,那你就把那個 Classifier 輸出的那個長度,它 Predict 出來的長度乘兩倍,那你的這個 Decoder ,說話的速度就變兩倍慢,
所以你可以如果有這種 NAT 的 Decoder,那你有 Explicit 去 Model,Output 長度應該是多少的話,你就比較有機會去控制,你的 Decoder 輸出的長度應該是多少,你就可以做種種的變化,
(3)注意雖然平行化是NAT的Decoder的最大優勢,但其performance往往不如AT的Decoder,現在很多研究提升其performance,但往往需要很多trick,NAT的Decoder performance不好的原因是有個Multi-Modality的問題,如果想要深入了解NAT可參考之前助教課程:https://youtu.be/jvyKmU4OM3c
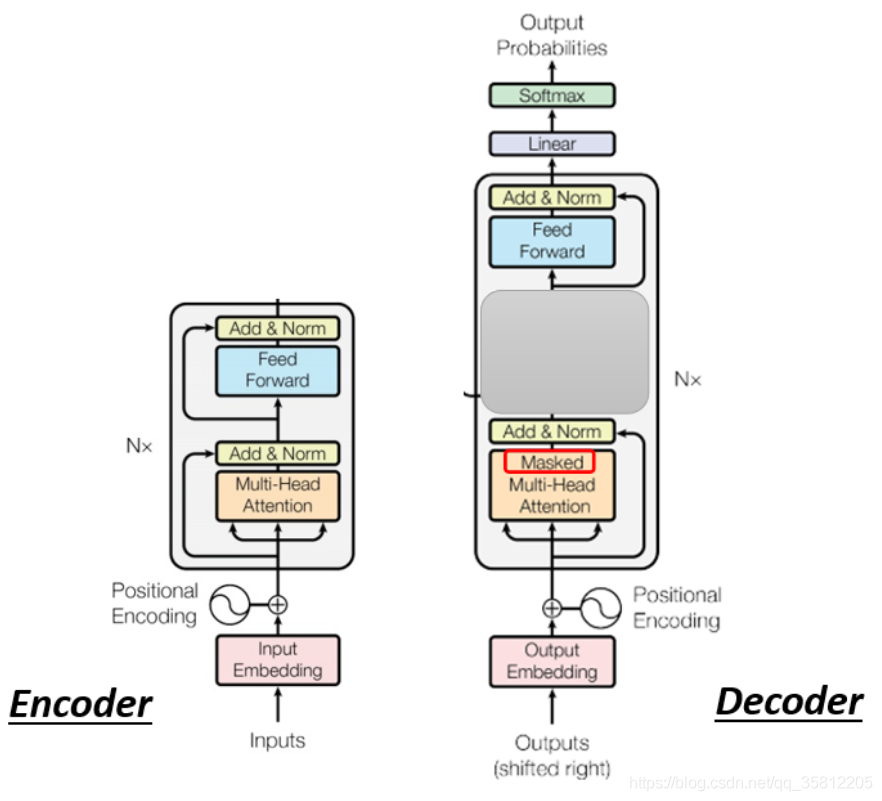
三、Encoder-Decoder
Encoder和Decoder是通過【cross attention】傳遞資訊,剛才遮住的那塊就是【cross attention】,會發現有2個輸入來自Encoder,Encoder提供2個箭頭(Decoder可以讀到Encoder的輸出),然后Decoder提供了一個箭頭,
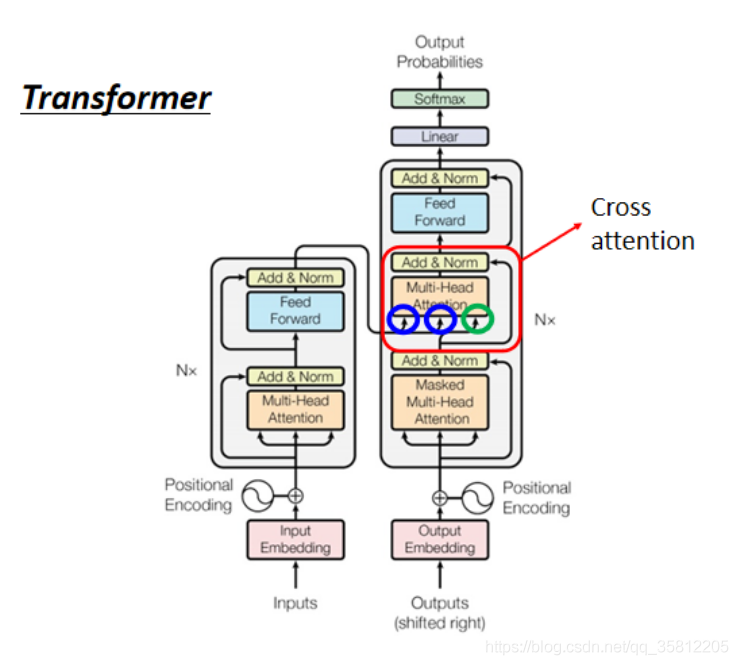
3.1 Cross Attention的運作流程
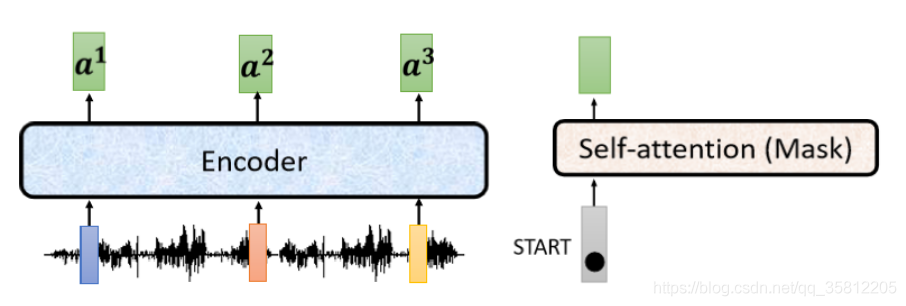
(1)上圖左邊是Encoder,輸入一排向量,輸出一排向量,我們叫它 a 1 、 a 2 、 a 3 a^1、a^2、a^3 a1、a2、a3;接著是Decoder,它會先吃begin這個special的token,經過有做mask的self-attention后得到一個向量(即使是有做mask,越是輸入多少長度的向量就輸出多少向量),所以輸入一個向量輸出以向量后,把這個向量乘一個矩陣做一個transform,得到一個Query(叫做q)
(2)然后像下圖一樣,左邊的
a
1
a
2
a
3
a^1 a^2 a^3
a1a2a3 產生 Key——Key1 Key2 Key3,那把這個 q 跟
k
1
k
2
k
3
k^1 k^2 k^3
k1k2k3去計算 Attention 的分數,得到
α
1
α
2
α
3
α_1 α_2 α_3
α1?α2?α3?,當然你可能一樣會做 Softmax,把它稍微做一下 Normalization,所以下圖這邊加一個 '代表它可能是做過 Normalization,
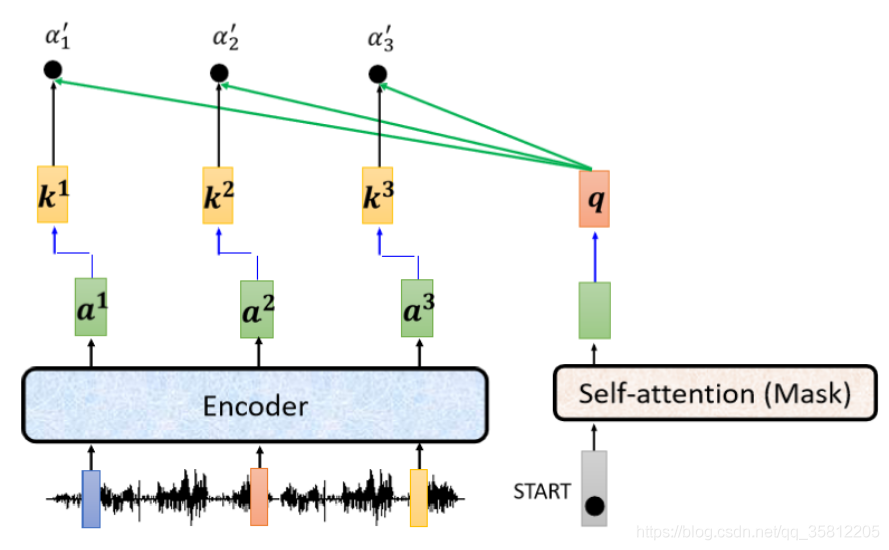
(3)將
α
1
α
2
α
3
α_1 α_2 α_3
α1?α2?α3?就乘上
v
1
v
2
v
3
v^1 v^2 v^3
v1v2v3,再把它 Weighted Sum 加起來會得到 v
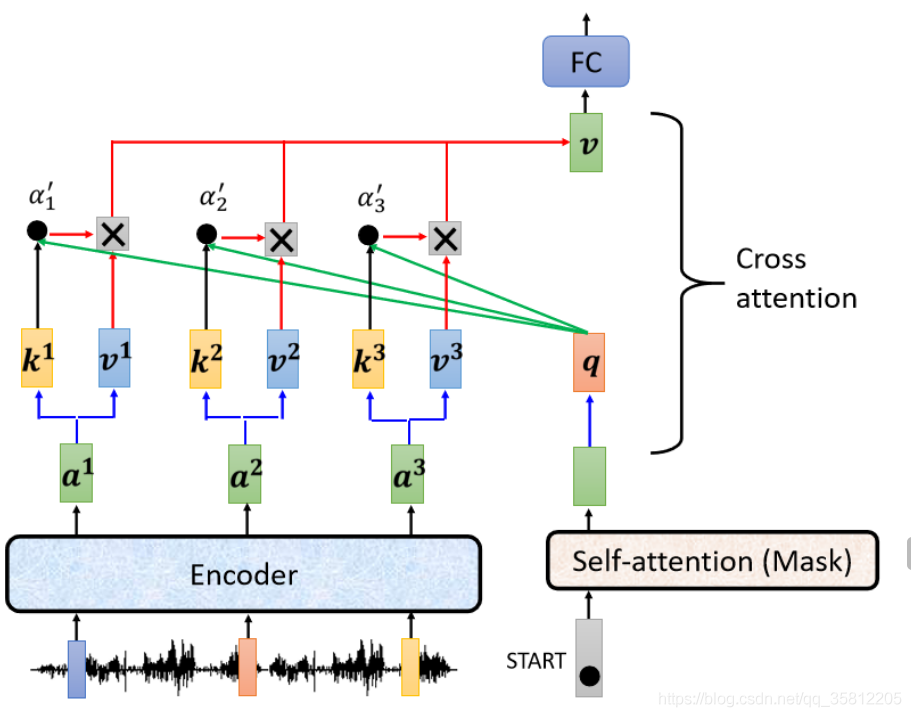
(4)最后就是將V丟進Fully-Connected 的Network 做接下來的處理,那這個步驟就是 q 來自于 Decoder,k 跟 v 來自于 Encoder,這個步驟就叫做 Cross Attention,
所以 Decoder 就是憑借著產生一個 q,去 Encoder 這邊抽取資訊出來,當做接下來的 Decoder 的 Fully-Connected 的 Network 的 Input,現在假設產生第二個,第一個這個中文的字產生一個“機”,接下來的運作也是一模一樣的,
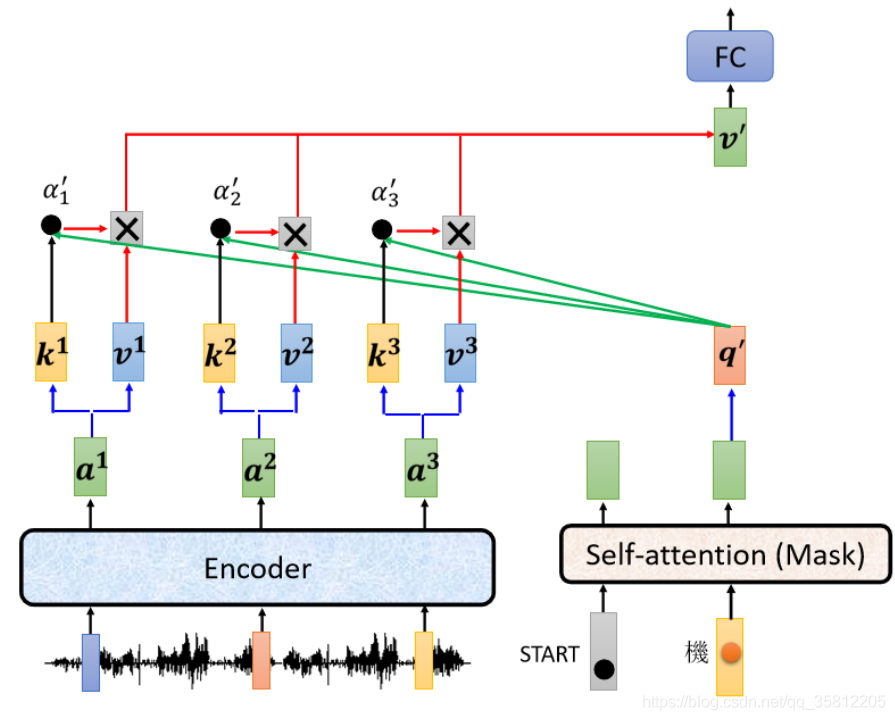
輸入 BEGIN 輸入“機”,產生一個向量(該向量后面的操作和上面描述的1-4步驟相同),該向量一樣乘上一個 Linear 的 Transform 后得到 q’(得到一個 Query),這個 Query 一樣跟 k 1 k 2 k 3 k^1 k^2 k^3 k1k2k3去計算 Attention 的分數,一樣跟 v 1 v 2 v 3 v^1 v^2 v^3 v1v2v3 做 Weighted Sum 做加權,然后加起來得到 v’,交給接下來 Fully-Connected Network 做處理,這就是Cross Attention 的運作的程序,
3.2 其他的Cross Attension 方式
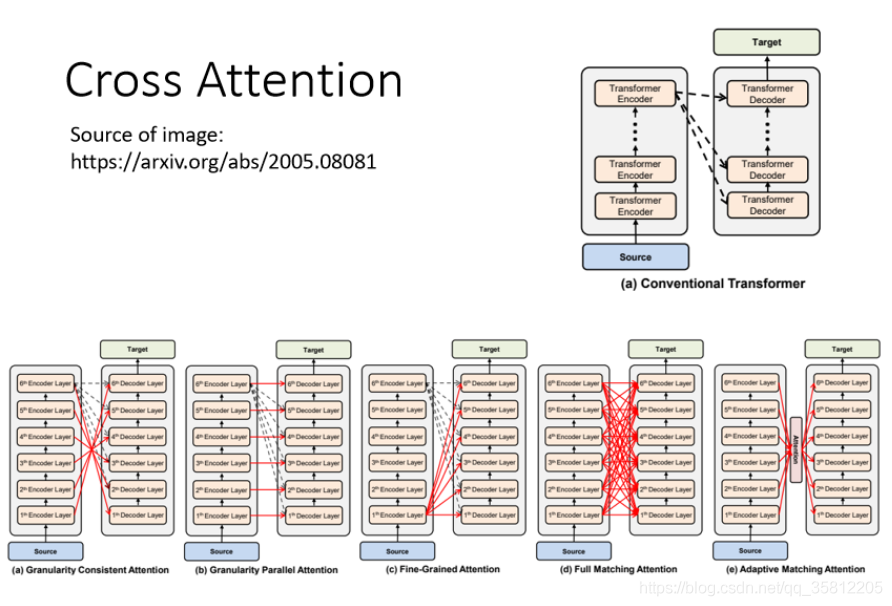
Encoder 這邊有很多層,Decoder 這邊有很多層,為什么 Decoder 這邊每一層都一定要看Encoder 的最后一層輸出呢,能不能夠有各式各樣不同的連接方式,這完全可以當做一個研究的問題來 Study,可以參考上圖的paper鏈接(有人就嘗試了不同的Cross Attension 方式),
四、Training
上面講的都是假設模型訓練好后怎么運作的,即怎么做testing(即inference),接下來說如何training的:
如果是做語音識別,需要有大量的聲音訊號的訓練資料,聽到“機器學習”四個字后,人工標簽該對應的中文字,而要讓機器學到這件事:我們先把begin丟給Encoder時,期待它第一個輸出應該跟“機”越接近越好,而“機”這個字會被表示成一個One-Hot的Vector(只有機字對應的那個維度是1,其他都是0),而Decoder的輸出是一個distribution(一個概率的分布),所以你會去計算Ground Truth和這個distribution之間的cross Entropy,并且希望這個值越小越好,
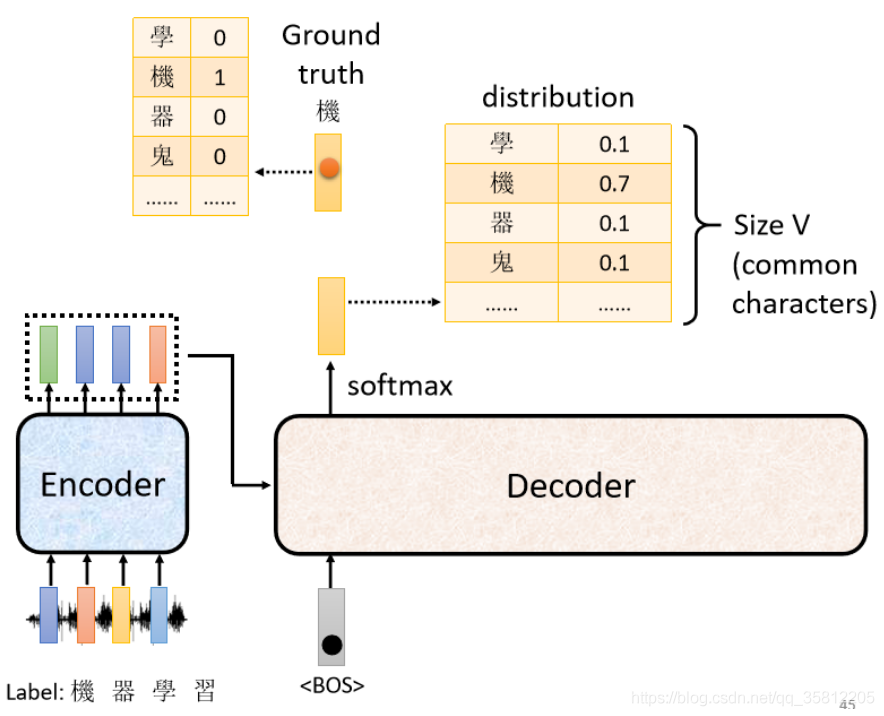
上面的步驟和分類很像,可以想成每一次在產生一個中文文字就是做了一次分類的問題,希望第一二三四次輸出的字分別是機、器、學、習四個文字,和四個字的One-Hot Vector越接近越好(每一個輸出跟 One-Hot Vector,跟它對應的正確答案都有一個 Cross Entropy,我們要希望所有的 Cross Entropy 的總和最小,越小越好,注意還有END符號),
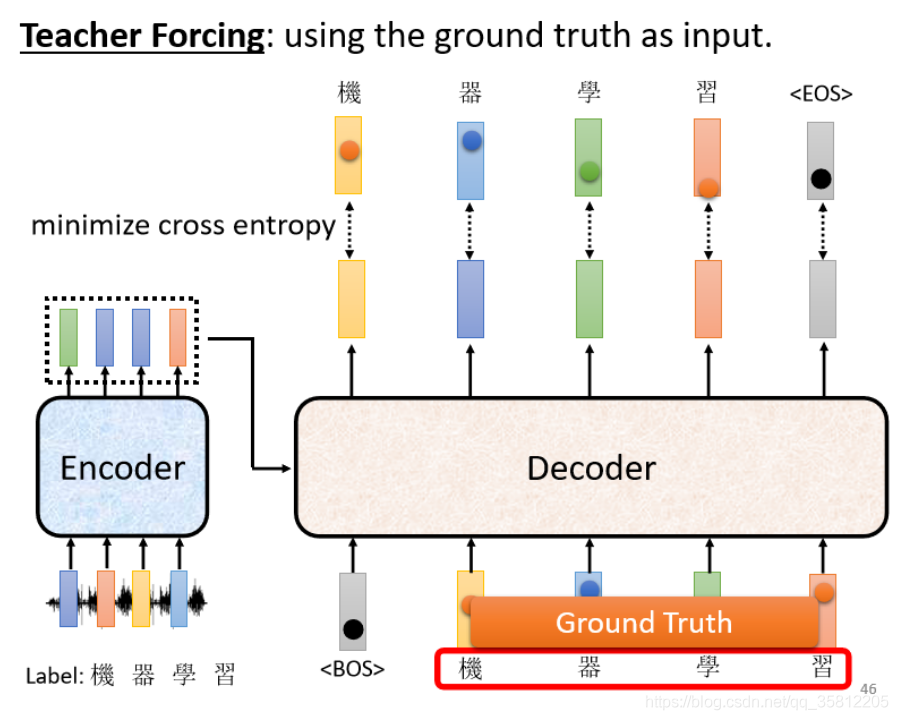
那這個就是 Decoder 的訓練:把 Ground Truth ,正確答案給它,希望 Decoder 的輸出跟正確答案越接近越好,在訓練的時候我們會給 Decoder 看正確答案,也就是我們會告訴它說:
- 在已經有 “BEGIN”,在有"機"的情況下你就要輸出"器"
- 有 “BEGIN” 有"機" 有"器"的情況下輸出"學"
- 有 “BEGIN” 有"機" 有"器" 有"學"的情況下輸出"習"
- 有 “BEGIN” 有"機" 有"器" 有"學" 有"習"的情況下,你就要輸出"斷"
在 Decoder 訓練的時候,我們會在輸入的時候給它正確的答案,那這件事情叫做 Teacher Forcing,
那這個時候你馬上就會有一個問題——訓練的時候,Decoder 有偷看到正確答案了;但是測驗的時候,顯然沒有正確答案可以給 Decoder 看,剛才也有強調說在真正使用這個模型,在 Inference 的時候,Decoder 看到的是自己的輸入,這中間顯然有一個 Mismatch,后面會提到解決方案,
五、訓練的Tips
不局限與Transformer,以下是訓練這種Seq2Seq model的tips
5.1 Copy Mechanism

如上圖中對話的例子,復制“庫洛洛”的能力是需要的,而沒必要創造出來(訓練結果),
5.2 Summarization摘要
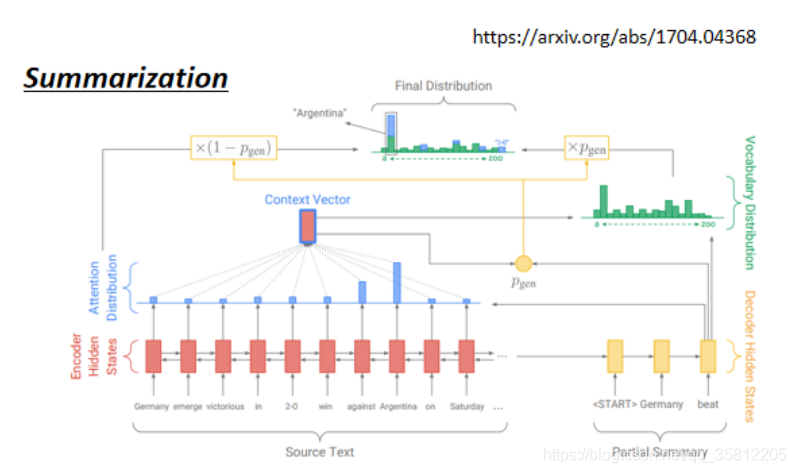
最早有從輸入復制東西的能力的模型叫做Pointer Network,后來還有一個變形Copy Network,生成摘要是需要訓練大量(百萬篇文章)得到的模型,需要從文章里面賦值一些資訊出來,Seq2Seq是能做到這樣的,
過去視頻:(https://youtu.be/VdOyqNQ9aww)
5.3 Guided Attention
語音合成TTS有時會訓練出的模型有點怪,李老師舉的栗子是機器讀 發財發財發財 沒問題,但是讀 發財 就只讀出一個財字,即機器漏字了,想讓機器一定把輸入的每個東西通通看過,可以用Guided Attention
Guiding Attention 要做的事情就是,要求機器它在做 Attention 的時候,是有固定的方式的,舉例來說,對語音合成或者是語音辨識來說,我們想像中的 Attention,應該就是由左向右
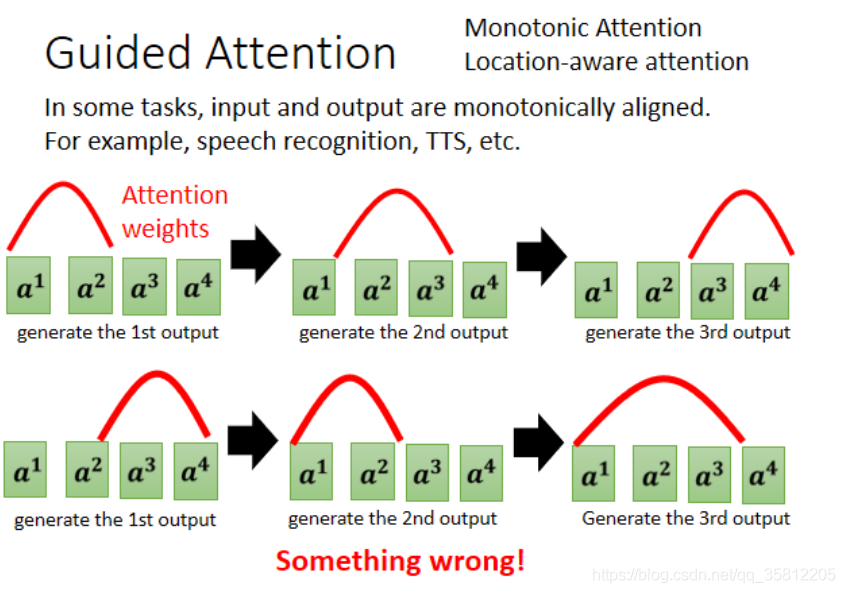
在這個例子裡面,我們用紅色的這個曲線,來代表 Attention 的分數,這個越高就代表 Attention 的值越大
我們以語音合成為例,那你的輸入就是一串文字,那你在合成聲音的時候,顯然是由左念到右,所以機器應該是,先看最左邊輸入的詞匯產生聲音,再看中間的詞匯產生聲音,再看右邊的詞匯產生聲音,如果你今天在做語音合成的時候,你發現機器的 Attention,是顛三倒四的,它先看最后面,接下來再看前面,那再胡亂看整個句子,那顯然有些是做錯了,顯然有些是,Something is wrong,有些是做錯了,
所以 Guiding Attention 要做的事情就是,強迫 Attention 有一個固定的樣貌,那如果你對這個問題,本身就已經有理解知道說,語音合成 TTS 這樣的問題,你的 Attention 的分數,Attention 的位置都應該由左向右,那不如就直接把這個限制,放進你的 Training 裡面,要求機器學到 Attention,就應該要由左向右
那這件事怎麼做呢,有一些關鍵詞匯我就放在這邊,讓大家自己 Google 了,比如說某某 Mnotonic Attention,或 Location-Aware 的 Attention,那這個部分也是大坑,也不細講,那就留給大家自己研究
5.4 Beam Search
Greedy Decoding用來找到類似下圖的分數最高的那個token,橙色的數字為路徑分數,有的路一開始雖然低分(0.4),但后面的路徑最后加起來的score更高,也就是說Greedy Decoding不一定是最好的方法,可以使用Beam Search——能夠找一個估測的solution,
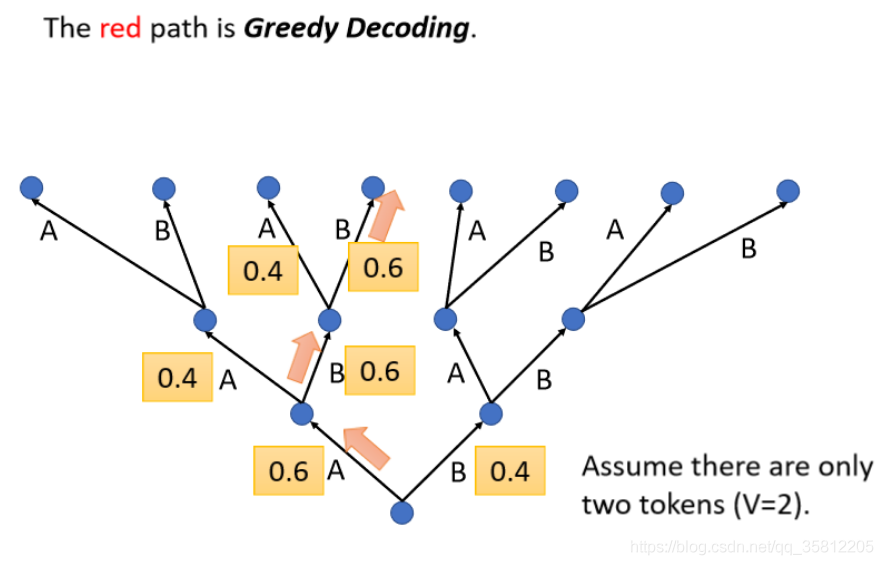
Beam Search也不一定牛逼,有篇paper《The Curious Case Of Neural Text Degeneration》在做Sentence Completion(讓機器先讀一段句子,然后讓機器發揮想象力完成后半部分),但是用Beam Search后機器不斷講重復的話(效果不好),所以不見得分數最高的路是最好的——取決于任務的特性:
(1)如果任務的答案非常明確,Beam Search通常效果好
(2)如果任務需要機器發揮一點創造力時,Beam Search效果就一般,如剛才說的Sentence Completion要機器完成后半段的創造,答案不唯一,往往需要在Decoder里面加入隨機性,語音合成TTS也需要加入一定隨機性,

5.5 Optimizing Evaluation Metrics?
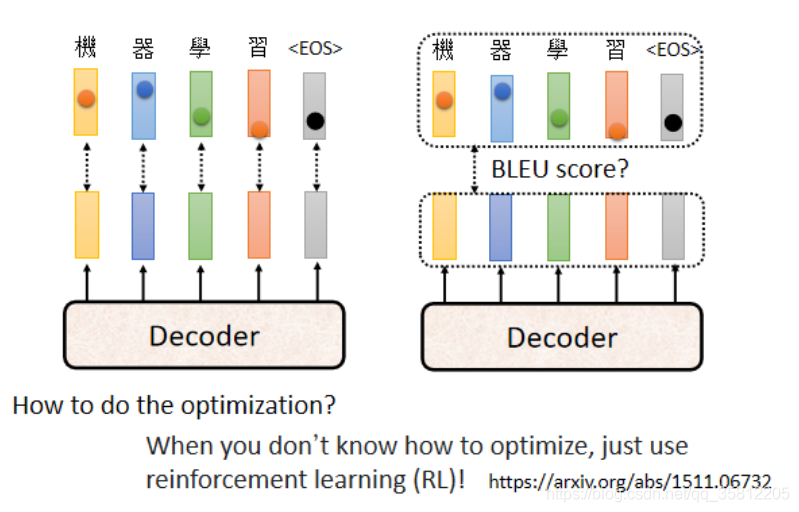
在李宏毅課程作業里評估用的是BLEU Score,是你的Decoder先產生一個完整的句子后再和答案一整句作比較計算score;但是在訓練時不時這樣,訓練時每一個詞匯是分開考慮的——我們是Minimize的是Cross Entropy,注意如果想在Training時就考慮BLEU Score(假設loss是BLEU Score乘一個負號),但這樣不好搞,因為BLEU Score本身很復雜(不能微分的),
Minimize Cross Entropy不一定可以Maximize BLEU Score:因為兩者可能只有一點聯系,但沒有直接關系,所以在課程助教代碼里,助教在做validation時并不是拿Cross Entropy來挑最好的model,
如果在Optimization遇到無法解決的問題,就用RL硬train一發,這樣即使遇到BLEU Score不能微分,即無法optimize的loss function時,把它當做是RL的reward,把Decoer當做是Agent,就當做強化學習任務硬做是可以完成的(但是做法比較難),
5.6 Scheduled Sampling
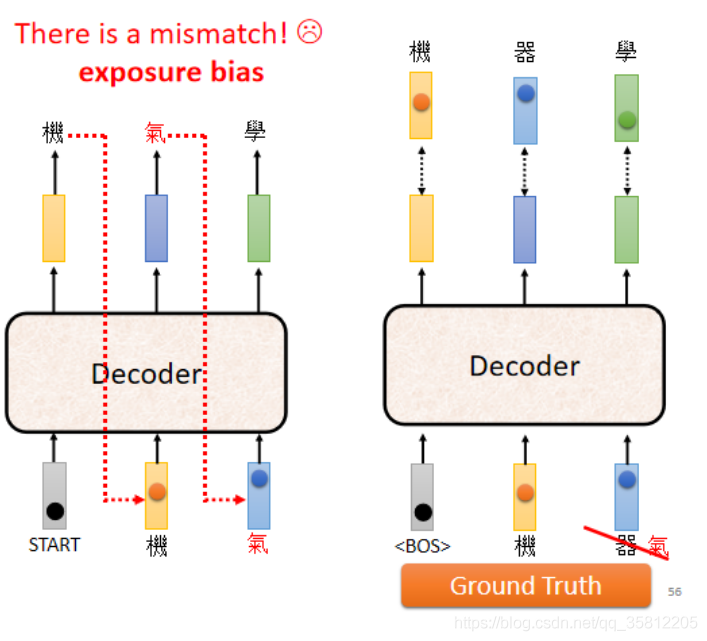
訓練的時候Decoder看到的是自己的輸出,所以測驗的時候Decoder會看到一些錯誤的東西;但是在訓練的時候,Decoder看到的是完全正確的,這個不一致的現象叫做Exposure Bias,
為了解決一個問題:因為Decoder在訓練時只看到過正確的東西,那在測驗時可能只要有一個錯就步步錯,對Decoder來說從來沒看過錯的東西,
可以參考的方向:給Decoder的輸入加入一些錯誤的東西,即不要給Decoder全部正確的答案(偶爾給一些錯誤的東西),反而會學得更好點——這招叫做Scheduled Sampling,不是那個Schedule learning rate,
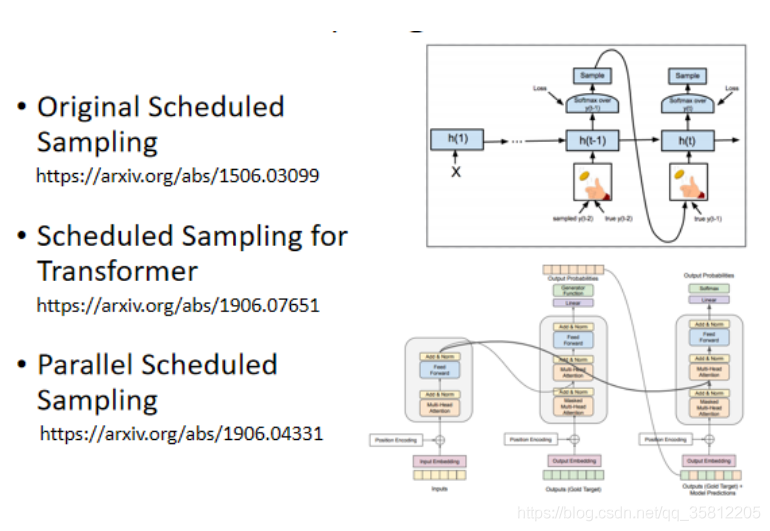
Scheduled Sampling 其實很早就有了,下圖的這個是 15 年的 Paper,很早就有 Scheduled Sampling,在還沒有 Transformer,只有 LSTM 的時候就已經有 Scheduled Sampling,但是 Scheduled Sampling 這一招,它其實會傷害到Transformer 的平行化的能力,那細節可以再自己去了解一下,所以對 Transformer 來說,它的 Scheduled Sampling,另有招數跟傳統的招數,跟原來最早提在,這個 LSTM上被提出來的招數也不太一樣,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/294118.html
標籤:AI