通信方面知識
人語音信號頻率為:300-3400HZ,無失真采樣頻率為6400HZ以上,用8KHZ來采樣,
用8位二進制進行量化,即得到:8bit*8=64kbps
一、頻分復用、時分復用和碼分復用
頻分復用(FDM):按頻率劃分的不同信道,用戶分到一定的頻帶后,在通信程序中自始至終都占用這個頻帶,可見頻分復用的所有用戶在同樣的時間占用不同的帶寬資源(帶寬指頻率帶)
(OFDM: 正交頻分復用: : 將碼流變為并行傳輸然后用很多的載波分別傳輸資料,抗干擾能力增強了,對抗多徑傳輸 )
時分復用(TDM):按時間劃分成不同的信道,每一個時分復用的用戶在每一個TDM幀中占用固定序列號的間隙,可見時分復用的所有用戶是在不同時間占用同樣的頻帶寬度,
碼分復用(CMD):更常用的是碼分多址(CMDA),每一個用戶可以在同樣的時間使用同樣的頻帶進行通信,由于各用戶使用經過特殊挑選的不同碼型,因此各用戶之間不會造成干擾,碼分復用最初用于軍事通信,因為這種系統發送的信號有很強的抗干擾能力,其頻譜類似于白噪聲,不易被敵人發現,后來才廣泛的使用在民用的移動通信中,它的優越性在于可以提高通信的話音質量和資料傳輸的可靠性,減少干擾對通信的影響,增大通信系統的容量,,降低手機的平均發射功率等,其作業原理如下:
在CDMA中,每一個位元時間在劃分為m個短的間隔,稱為碼片(chip),通常m的值為64或128,為了方便說明,取m為8
- 使用CDMA的每一個站被指派一個唯一的m bit碼片序列,一個站如果要發送位元1,則發送它自己的m bit碼片序列,如果要發送0,則發送該碼片序列的二進制反碼,按照慣例將碼片中的0寫成-1,將1寫成+1
- CDMA給每一個站分配的碼片序列不僅必須各不相同,并且還必須互相正交,用數學公式表示,令向量S表示站S的碼片向量,再令T表示其他任何站的碼片向量,兩個不同站的碼片序列正交,就是向量S和T的規格化內積都是S * T = 0
- 任何一個碼片向量和該碼片向量自己的規格化內積都是S * S = 1
- 任何一個碼片向量和該碼片的反碼的向量的規格化內積都是-1
故:所有其他站的信號都被過濾,而只剩下S站發送的信號,當S站發送位元1時,在X站計算內積結果為+1;當S站發送位元0時,內積結果為-1;當S站不發送時,內積結果為0,S與X正交
二、高斯程序
隨機程序ε(t)的任意n階的概率密度分布都滿足高斯分布即為高斯程序;高斯程序的廣義平穩和嚴平穩是等價的;高斯程序通過線性系統仍是高斯程序,
平穩的性質:
1、一階的概率密度函式分布與t無關
2、二階的概率密度函式分布只有τ有關
3、數學期望和方差與t無關
4、自相關函式R只有τ有關
三、信道分類
調制信道:編碼器和解碼器之間
編碼信道:包含編碼器和解碼器的信道
無線信道:地波,天波和視線傳播–無線電中繼,衛星通信,平流層通信
有線信道:明線,對稱電纜,同軸電纜–架空線路,雙紐線,同軸線
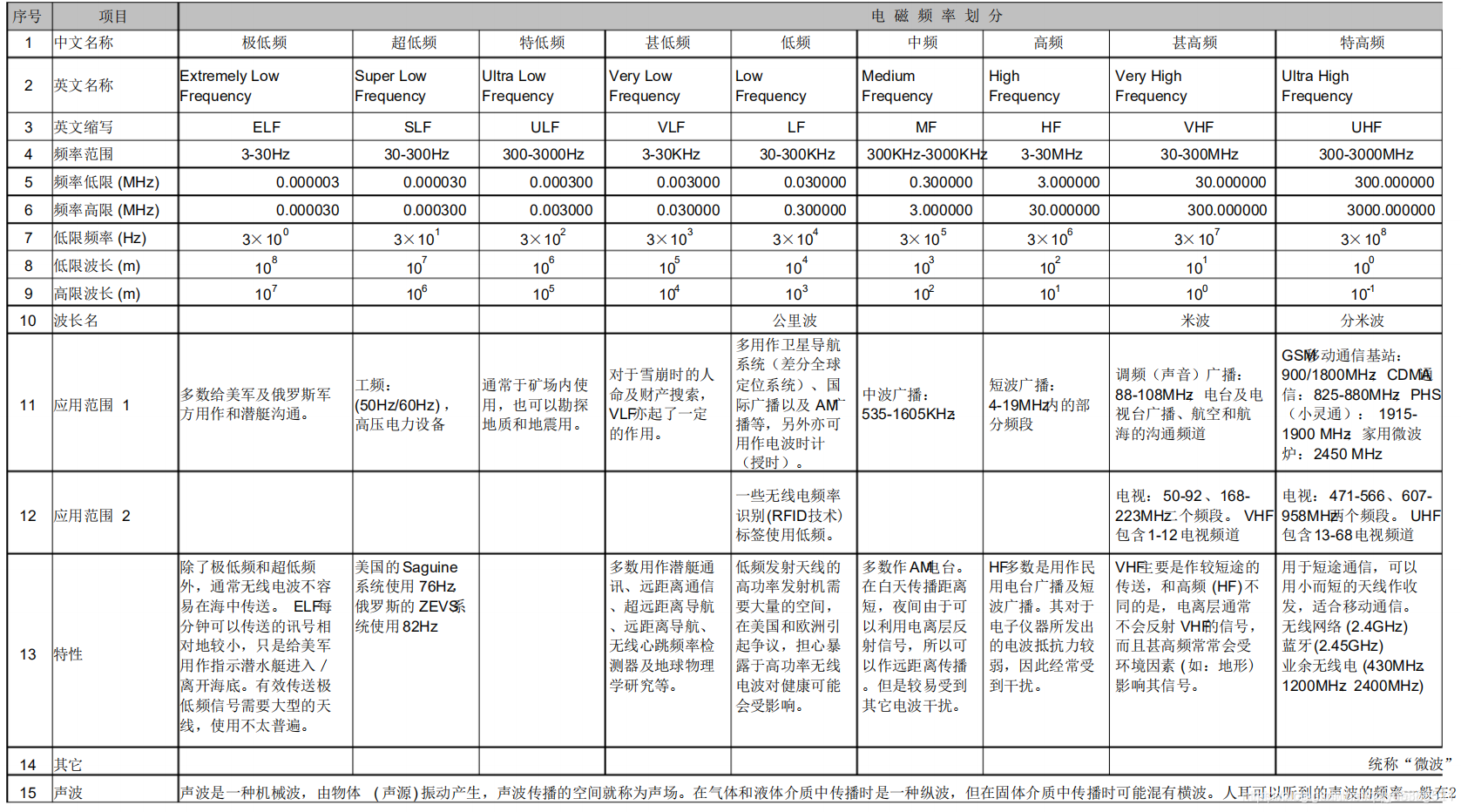
四、頻段分段
射頻(300KHz-300MHz):包括LF,MF,HF,VHF
毫米波頻段沒有太過精確的定義,通常將30~300GHz的頻域(波長為1~10毫米)的電磁波稱毫米波
微波(300MHz-3000GHz):包括UHF,SHF,EHF,PHF
五、
無線物理層安全:從基礎信號層就能防止攻擊
gsm一般指全球移動通信系統,一直移動通信的標準
LTE 4G下的移動通信的標準
MIMO技術(多入多出)是指能在不增加帶寬的情況下,成倍地提高通信系統的容量和頻譜利用率,它可以定義為發送端和接收端之間存在多個獨立信道,也就是說天線單元之間存在充分的間隔,因此,消除了天線間信號的相關性,提高了信號的鏈路性能,增加了資料吞吐量,研究表明,在瑞利衰落信道環境下,OFDM系統會使用MIMO技術來提高容量,
相控陣天線指的是通過控制陣列天線中輻射單元的饋電相位來改變方向圖形狀的天線,控制相位可以改變天線方向圖最大值的指向,以達到波束掃描的目的,
六、常用的正交變換
DFT DCT DST :實作資料的去相關性,能量集中
七、糾錯編碼方式
BCH碼糾正多為錯誤的回圈碼
RS碼非二進制的BCH糾錯碼:伽羅華域內
交織碼:突發誤碼分散為隨機誤碼----分組交織(讀寫順序不一致分散誤碼)和卷積交織(卷積碼多項式–>無法分出監督位和有效位) 和LPDC碼:低密度奇偶校驗碼
八、數字基帶傳輸系統
基帶傳輸系統是沒有經過載波調制直接傳輸的的方式
基帶信號的基本波形:
1、單極性波形 2、雙極性波形 3、單極性歸零波形 4、雙極性歸零波形 5、差分波形 6、多電平波形
基帶傳輸常用的碼型:
1、 AMI碼:傳號或者空號翻轉
2、 HDB3碼:HDB3碼恢復找破壞點V
3、曼徹斯特碼:兩個碼表示一個極性
九、CMOS和TTL區別
1、CMOS是場效應管構成(單極性電路),TTL為雙極晶體管構成(雙極性電路)
2、COMS的邏輯電平范圍比較大(5~15V),TTL只能在5V下作業
3、CMOS的高低電平之間相差比較大、抗干擾性強,TTL則相差小,抗干擾能力差
4、CMOS功耗很小,TTL功耗較大(1~5mA/門)
5、CMOS的作業頻率較TTL略低,但是高速CMOS速度與TTL差不多相當
6、CMOS的噪聲容限比TTL噪聲容限大
7、通常以為TTL門的速度高于“CMOS門電路,影響 TTL門電路作業速度的主要因素是電路內部管子的開關特性、電路結構及內部的各電阻阻數值,電阻數值越大,作業速度越低,管子的開關時間越長,門的作業速度越低,門的速度主要體現在輸出波形相對于輸入波形上有“傳輸延時”tpd,將tpd與空載功耗P的乘積稱為“速度-功耗積”,做為器件性能的一個重要指標,其值越小,表明器件的性能越 好(一般約為幾十皮(10-12)焦耳),與TTL門電路的情況不同,影響CMOS電路作業速度的主要因素在于電路的外部,即負載電容CL,CL是主要影響器件作業速度的原因,由CL所決定的影響CMOS門的傳輸延時約為幾十納秒,
8、TTL電路是電流控制器件,而coms電路是電壓控制器件,
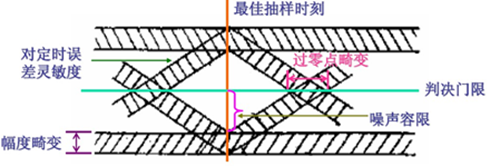
十、眼圖是什么?從眼圖可以得到的資訊?眼睛斜邊反映了什么資訊?
眼圖是指利用實驗手段方便地估計和改善(通過調整)系統性能時在示波器上觀察到的一種圖形,眼圖定性反映碼間串擾和噪聲的大小,ISI大時,眼圖不端正;有噪聲時,線跡變寬,
從眼圖可以得到的資訊有:最佳抽樣時刻、最佳判決門限、對定時誤差的靈敏度、過零點畸變、幅度畸變、噪聲容限,
眼睛斜邊反映了通信系統對定時誤差的靈敏度,
十一、碼間干擾
因為是使用有一定脈寬的信號進行的采樣,所以在頻域上會是無限延展從而干擾到其他的信號波形,影響輸出的判決
解決方法:除該點信號外其他點信號和為0;其他點在該點的信號恰好為0
通過理想低通—>升余弦滾降—>部分回應系統
頻域均衡和時域均衡:校正信道使其能滿足無ISI的條件
時域均衡通過構建橫向濾波器抽頭電路(手動均衡和自動均衡)
十二、數字調制
模擬調制:AM DSB SSB VSB FM
解調的方式:相干解調和非相干解調(包絡檢波)
數字調制:2ASK(OOK);2FSK;2PSK–>2DPSK;QPSK–>4DPSK;MQAM調制
智能資訊處理
智能計算作業
一、概述
1、根據自己理解,全面描述人工智能的概念,
答:人工智能是人們使機器具有類似人的智能,或者說是人類的智能在機器上模擬,人工智能就是研究如何使一個計算機系統具有像人一樣的智能特征,使其能模擬、延伸、擴展人類智能,人工智能屬于計算機科學的一個分支,旨在設計智能的計算機系統,使得計算機會聽、說、讀、寫、學習、推理,能夠適應環境變化,能夠模擬出人腦思維活動,使計算機能夠像人一樣去思考和行動,完成人類能夠完成的作業,甚至在某些方面比人更強,
總得來說,人工智能可認為是對人類智能的一種模仿,在某些方面甚至可以實作超越,
2、人工智能研究形成三種不同的研究學派,給出這三種學派的主要思想,并談談你對這三種學派的個人看法,
答:(1)符號主義;主要思想:以符號處理為核心,用于模擬人類問題求解程序的心理程序,逐漸形成為物理符號系統,
(2)聯接主義;主要思想:神經網路及神經網路間的連接機制與學習演算法,非邏輯推理方式,
(3)行為主義;主要思想:基于控制論和“動作–感知”型控制系統,人工智能在智能活動中的自適應、自學習,
個人看法:三種學派各有側重點,根據其不同的思想設計出的各式的智能計算機系統可以在解決不同的實際問題有著各自的長處,人的智能在處理各種不同的問題時表現的形式也有不同,既有表現邏輯理性的,也會有模糊不清的非邏輯推理存在,還有其他不同的方面,想用一種思想或學說來概括人的智能,那就只能是以偏概全,
3、根據你的理解,說明生物智能(BI)、人工智能(AI)、計算智能(CI)的聯系和區別,
答:
(1)生物智能:BI是人類從自身的角度來闡述的,由人腦的物理化學程序反映出來,它表征人類智能活動的一些特征,有目的性、綜合性和學習擴展性 ,
(2)人工智能:由非生物生命方法產生的智能,它總是和符號、邏輯、規則、推理聯系起來,
(3)計算智能:它是生物智能的計算模擬,即用計算機模擬和再現人類的某些智能行為,
聯系:人工智能與計算智能之間有重合,但計算智能是一個全新的學科領域,無論是生物智能還是機器智能,計算智能都是其最核心的部分,而人工智能則是外層,CI和傳統的AI只是智能的兩個不同層次,各自都有自身的優勢和局限性,相互之間只應該互補,而不能取代,
4、述人工神經元模型,
答:組成:連接鏈(突觸)、加法器、激活函式
連接鏈(突觸):每一個都有其權值或者強度作為特征,權值可取正值也可取負值,
加法器:用于求輸入信號中神經元的相應突觸加權的和,
激活函式:用來限制神經元輸出振幅,
作業程序:累加各部分的加權輸入,然后比較累加和是否超過閾值,如果超過,輸出為興奮狀態,否則,輸出為抑制狀態,
說明:輸入權值和閾值對于輸出狀態影響巨大,輸入權值和閾值是神經元學習的基礎,權值和閾值調整的程序就是學習的程序,
特點:(1)多個輸入 (2)一個輸出 (3)輸出只有抑制、興奮兩種狀態
X1,X2,X3…Xn表示神經元的n個輸入
W1,W2,W3…Wn表示n個神經元的連接權值
θ為神經元的輸出閾值
y為神經元的輸出
一、神經網路
1、簡述感知器的作業原理,
答:感知器可將外部輸入分為兩類和,當感知器的輸出為+1時,輸入屬于L1類,當感知器的輸出為-1時,輸入屬于L2類,從而實作兩類目標的識別,在多維空間,單層感知器進行模式識別的判決超平面由下式決定 :
2、詳細介紹BP神經網路,如何理解BP網路中誤差是反向傳播的?
答:基本原理:利用輸出后的誤差來估計輸出層的直接前導層的誤差,再用這個誤差估計更前一層的誤差,如此一層一層的反傳下去,就獲得了所有其他各層的誤差估計,
BP神經網路通常由輸入層、隱含層和輸出層組成,層與層指尖全互連,每層節點之間不相連,輸入層節點數通常取輸入向量維數,輸出層節點數通常取輸出向量維數,隱含層節點個數一般需反復測驗得出,
BP學習演算法:是一種有導師的學習演算法,是梯度下降法在多層前饋網中的應用
(1)學習程序:神經網路在外界輸入樣本的刺激下不斷改變網路的連接權值,以使網路的輸出不斷地接近期望的輸出,本質上就是對各連接權值的動態調整,
(2)學習規則:權值調整規則,即在學習程序中網路中各神經元的連接權變化所依據的一定的調整規則,
(3)步驟:第一步,網路初始化;第二步,隨機選取第K個輸入樣本及對應期望輸出;第三步,計算隱含層各神經元的輸入和輸出;第四步,利用網路期望輸出和實際輸出,計算誤差函式對輸出層的各神經元的偏導數 ;第五步,利用隱含層到輸出層的連接權值、輸出層的和隱含層的輸出計算誤差函式對隱含層各神經元的偏導數;第六步,利用輸出層各神經元的和隱含層各神經元的輸出來修正連接權值;第七步,利用隱含層各神經元的和輸入層各神經元的輸入修正連接權值 ; 第八步,計算全域誤差;第九步,判斷網路誤差是否滿足要求,當誤差達到預設精度或學習次數大于設定的最大次數,則結束演算法,否則,選取下一個學習樣本及對應的期望輸出,回傳到第三步,進入下一輪學習,
誤差反向傳播:將輸出誤差以某種形式通過隱層向輸入層逐層反傳,將誤差分攤給各層的所有單元,得到各層的誤差信號,再由此修正各單元權值,這樣看起來信號是在正向傳播,但誤差是反向傳播的,
3、前饋式神經元網路與反饋式神經元網路有何不同?
答: (1) 前饋型神經網路只表達輸入輸出之間的映射關系,實作非線性映射;反饋型神經網路考慮輸入輸出之間在時間上的延遲,需要用動態方程來描述,反饋型神經網路是一個非線性動力學系統,
(2) 前饋型神經網路學習訓練的目的是快速收斂,一般用誤差函式來判定其收斂程度;反饋型神經網路的學習目的是快速尋找到穩定點,一般用能量函式來判別是否趨于穩定點,
4、簡述RBF的基本原理,
答:RBF 神經網路通常是一種三層前向網路,第一層是輸入層,由信號源節點組成;第二層為隱含層,其節點基函式是一種區域分布的、對中心徑向對稱衰減的非負非線性函式;第三層為輸出層,
RBF神經網路的訓練:第一步采用非監督式學習訓練隱含層的權重值;第二步是采用監督式學習訓練線性輸出值,
梯度下降法: RBF 神經網路的梯度下降訓練方法是通過最小化目標函式,實作對各隱節點資料中心、寬度和輸出權值的學習
5、對比BP與RBF網路,
答:BP網路通過誤差的反向傳播不斷的修改輸入層節點與隱含層間的權值來學習,
RBF網路權值可由隱層節點引數得到,通過最小化目標函式,實作對各隱節點資料中心、寬度和輸出權值的學習,
6、網路的穩定吸引子和吸引子的吸引域分別指什么?
答:處于穩定時的網路狀態叫做穩定狀態,又稱為穩定吸引子
在穩定點Ae周圍的A(σ)區域內,從任一個初始狀態A(t0)出發,當t→∞時都收斂于Ae,則稱A(σ)為吸引子的吸引域,
7、試述離散型Hopfield神經元網路的結構及作業原理,
答:結構:在離散Hopfield網路中,所采用的神經元是二值神經元;所輸出的離散值1和0分別表示神經元處于激活和抑制狀態,一個離散的Hopfield網路,其網路狀態是輸出神經元資訊的集合,對于一個輸出層是n個神經元的網路,則其t時刻的狀態為一個n維向量:
A=[a1,a2…,an]T
故而,網路狀態有2n個狀態;因為Aj(t)(j=1……n)可以取值為1或0;故n維向量A(t)有2n種狀態,即是網路狀態,
作業原理:Hopfield網路按動力學方式運行,其作業程序為狀態的演化程序,即從初始狀態按“能量” 減小的方向進行演化,直到達到穩定狀態,穩定狀態即為網路的輸出
8、簡述SOM神經網路學習演算法,
答:自組織特征映射網,簡稱SOM網,SOM網共有兩層,輸入層模擬感知外界輸入資訊的視網膜,輸出層模擬做出回應的大腦皮層,
競爭學習原理,網路的輸出神經元之間相互競爭以求被激活,結果在每一時刻只有一個輸出神經元被激活,這個被激活的神經元稱為競爭獲勝神經元,而其它神經元的狀態被抑制, 步驟:首先將當前輸入模式向量X和競爭層中各神經元對應的內星向量Wj 全部進行歸一化處理;尋找獲勝神經元 當網路得到一個輸入模式向量時,競爭層的所有神經元對應的內星權向量均與其進行相似性比較,并將最相似的內星權向量判為競爭獲勝神經元,即兩向量點積最大,
SOM網的學習演算法
二、遺傳演算法
-
試述遺傳演算法的基本原理,并說明遺傳演算法的求解步驟,
答:?基本原理:在遺傳演算法里,優化問題的解被稱為個體,它表示為一個引數串列,叫做染色體或者基因串,染色體一般被表達為簡單的數字串,不過也有其他的表示方法適用,這一程序稱為編碼,一開始,演算法隨機生成一定數量的個體,有時候操作者也可以對這個隨機產生程序進行干預,播下已經部分優化的種子,在每一代中,每一個個體都被評價,并通過計算適應度函式得到一個適應度數值,種群中的個體被按照適應度排序,適應度高的在前面,
下一步是產生下一代個體并組成種群,這個程序是通過選擇、交叉、變異完成的,選擇是根據新個體的適應度進行的,適應度越高,被選擇的機會越高,而適應度低的,被選擇的機會就低,初始的資料可以通過這樣的選擇程序組成一個相對優化的群體,被選擇的個體進行交叉,一般的遺傳演算法都有一個交叉概率,每兩(多)個個體通過交叉產生新個體,再通過變異產生新的“子”個體,
求解步驟:(1) 選擇編碼策略,將問題搜索空間中每個可能的點用相應的編碼策略表示出來,即形成染色體;
(2) 定義遺傳策略,包括種群規模N,交叉、變異方法,以及選擇概率Pr、交叉概率Pc、變異概率Pm等遺傳引數;
(3) 令t=0,隨機選擇N個染色體初始化種群P(0);
(4) 定義適應度函式f(f>0);
(5) 計算P(t)中每個染色體的適應值;
(6) t=t+1;
(7) 運用選擇算子,從P(t)中得到P(t+1);
(8) 對P(t+1)中的每個染色體,按概率Pc參與交叉;
(9) 對染色體中的基因,以概率Pm參與變異運算;
(10) 判斷群體性能是否滿足預先設定的終止標準,若不滿足則回傳(5), -
遺傳演算法、進化策略和進化規劃有何區別?
答:遺傳演算法通過交叉(重組)算子和突變操作產生新個體;進化規劃中沒有任何重組算子,新個體的出現只依賴于個體的突變;進化策略的選擇運算按確定方式進行,即每次從群體中選取最好的幾個個體保留到下一代群體中, -
什么是階和定義距?簡述模式定理,
答: 模式的階:模式H中確定位置的個數為模式H的階,記作O(H);
模式的定義距/長度:模式中第一個確定位置和最后一個確定位置之間的距離,記作δ(H) ;
模式定理:假定在第t代,種群A(t)中有m個個體屬于模式H,記為m=m(H,t),即第t代時,有m個個體屬于H模式,在再生階段(即種群個體的選擇階段),每個串根據它的適應值進行復制(選擇),一個串被復制(選中)的概率為 :,因此復制后在下一代A(t+1)中,群體A內屬于模式H的個體數目m(H,t+1)可用平均適應度按下式近似計算:其中表示在t代屬于模式H的個體的平均適應度, n為種群中的個體數目,
若用表示種群平均適應度,則前式可表示為:
上式表明:一個特定的模式按照其平均適應度值與種群的平均適應度值之間的比率生長,換句話說就是:那些適應度值高于種群平均適應度值的模式,在下一代中將會有更多的代表串處于 中,因為在 時,有
總結: 假設從t=0 開始,某一特定模式適應度比種群平均適應度高出 ,c為常數,則模式選擇生長方程為:
從t=0開始,若模式H以常數c繁殖到第t+1代,其個體數目為:
上式表明,在種群平均值以上的模式將按指數增長的方式被復制,
- 什么是積木塊
答:遺傳演算法通過短定義距、低階以及高適應度的模式(積木塊),在遺傳操作作用下相互結合,最終接近全域最優解,滿足這個假設的條件有兩個:(1)表現型相近的個體基因型類似;(2)遺傳因子間相關性較低,
積木塊假設指出,遺傳演算法具備尋找全域最優解的能力,即積木塊在遺傳算子作用下,能生成低階、短定義距、高平均適應度的模式,最終生成全域最優解,
中間還有模糊的計算
一、禁忌搜索演算法
- 簡述禁忌搜索演算法的基本原理,
基本思想:基于爬山演算法的改進,標記已經解得的區域最優解或求解程序,并在進一步的迭代中避開這些區域最優解或求解程序,區域搜索的缺點在于,太過于對某一區域區域以及其鄰域的搜索,導致一葉障目,為了找到全域最優解,禁忌搜索就是對于找到的一部磁區域最優解,有意識地避開它,從而獲得更多的搜索區域,
演算法采用鄰域選優的搜索方法,為了逃離區域最優解,演算法必須能夠接受劣解,也就是每一次得到的解不一定優于原來的解,但是,一旦接受了劣解,演算法迭代即可能陷入回圈,為了避免回圈,演算法將最近接受的一些移動放在禁忌表中,在以后的迭代中加以禁止,即只有不再禁忌表中的較好解(可能比當前解差)才能接受作為下一代迭代的初始解,隨著迭代的進行,禁忌表不斷更新,經過一定的迭代次數后,最早進入禁忌表的移動就從禁忌表中解禁退出, - 簡述分散搜索和集中搜索策略
分散搜索策略(Diversification strategy):該策略是為了對整個解的空間進行更廣泛的覆寫,而不是僅僅局限在某個區域的區域,在當前搜索區域內進行了一定次數的搜索了之后(如25次),若不能發現更好的解,那么就執行分散搜索策略,清空tabu list,然后從一個新的初始解開始搜索,
集中搜索策略(Intensification strategy):如果當前搜索區域內發現了比較好的解,如果進一步對當前區域進行更集中的搜索,那么可能會發現更多更好的解,當前最好解的記錄被更新,那么就執行集中搜索策略,清空tabu list. 這樣可以在當前區域進行更自由的搜索,
二、模擬退火演算法
-
簡述Metropolis準則
Metropolis準則(1953)即以概率接受新狀態準則,它引入了接收狀態的隨機性,
若在溫度𝑇時,從狀態𝑖變化到狀態𝑗
若𝐸𝑗<𝐸𝑖,則接受j為新狀態;否則若概率𝑝=exp[?(𝐸𝑗?𝐸𝑖)/𝐾𝑇]大于[0,1]區間的亂數,則接受狀態𝑗為當前狀態,否則仍保留𝑖為當前狀態,
對于概率𝑝=exp[?(𝐸𝑗?𝐸𝑖)/𝐾𝑇],(該公式不僅考慮的能力差還考慮了溫度影響)
在高溫下,可接受與當前狀態能量差距較大的狀態;
在低溫下,只接受與當前能量差較小的狀態, -
簡述模擬退火演算法的基本原理(三函式兩準則),
三函式:狀態產生函式、狀態接收函式、退溫函式
兩個準則:抽樣穩定準則、退火結束準則
(1)狀態產生函式(鄰域函式):盡可能保證產生的候選解遍布全部解空間
(2)狀態接收函式:盡可能接收優化解,Metropolis接受準則
(3)溫度更新函式:溫度的下降方式,用具外回圈修改溫度值
(4)Metropolis抽樣穩定準則:用于決定在各溫度下產生候選解的數目,Metropolis抽樣 程序就是在一確定溫度下,使系統達到熱平衡的程序,
(5)收斂準則:決定演算法何時終止,
常用的方法:設定終止溫度的閥值,設定外回圈迭代次數(6-50),演算法搜索到的最 優值連續若干步保持不變,檢驗系統熵是否穩定
三、蟻群演算法
-
簡述蟻群演算法的基本原理,
基本原理
蟻群演算法是對自然界螞蟻的尋徑方式進行模似而得出的一種仿生演算法,
螞蟻在運動程序中,能夠在它所經過的路徑上留下一種稱之為資訊素(pheromone)的物質進行資訊傳遞,而且螞蟻在運動程序中能夠感知這種物質,并以此指導自己的運動方向,因此由大量螞蟻組成的蟻群集體行為便表現出一種資訊正反饋現象:某一路徑上走過的螞蟻越多,則后來者選擇該路徑的概率就越大,
人工蟻群的新特點:具有一定的記憶能力,能夠記憶已經訪問過的節點,同時,人工蟻群在選擇下一條路徑的時候是按一定演算法規律有意識地尋找最短路徑,而不是盲目的,例如在TSP問題中,可以預先知道當前城市到下一個目的地的距離, -
試舉出2種蟻群改進演算法,并指出主要的改進之處,
(1)帶精英策略的螞蟻系統 Aselite
在資訊素更新時給予當前最優解以額外的資訊素量,使最優解得到更好的利用,找到全域最優解的螞蟻稱為“精英螞蟻”,引入這種額外的資訊素強化手段有助于更好地引導螞蟻搜索的偏向,使演算法更快收斂,但是也可能存在陷入區域極值的問題
(2)最大最小螞蟻系統MMAS
a、每次迭代后,只對最優解所屬路徑上的資訊素更新,
b、對每條邊的資訊素量限制在范圍 內,目的是防止某一條路徑上的資訊素 量遠大于其余路徑,避免過早收斂于區域最優解,
c、資訊素初始值為資訊素取值區間的上限,并伴隨一個較小的資訊素蒸發速率,
利好:增強演算法在初始階段的探索能力,有助于螞蟻“視野開闊地”進行全域范圍內的 搜索,隨后螞蟻逐漸縮小搜索范圍,
d、每當系統進入停滯狀態,問題空間內所有邊上的資訊素量都會被重新初始化,(我們 通常通過對各條邊上資訊素量大小的統計或是觀察演算法在指定次數的迭代內至今最優 路徑有無被更新來判斷演算法是否停滯,)有效地利用系統進入停滯狀態后的迭代周期繼 續進行搜索,使演算法具有更強的全域尋優能力
四、粒子群演算法
1.簡述粒子群優化演算法,
設想這樣一個場景:一群鳥在隨機搜索食物,在這個區域里只有一塊食物,所有的鳥都不知道食物在那里,但是他們知道當前的位置離食物還有多遠,那么找到食物的最優策略是什么呢,最簡單有效的就是搜尋目前離食物最近的鳥的周圍區域,PSO正是從這種模型中得到啟發并用于解決優化問題
粒子群演算法在求解優化問題時,問題的解對應于搜索空間中一只鳥的位置,這
些鳥被稱為粒子(particle),每個粒子都有自己的位置和速度,粒子位置
好壞由被優化問題的適應值決定,各個粒子記憶、追尋當前的最優位置,在解空間
中迭代搜尋最優值,
2.粒子的速度更新公式主要包括哪三部分?各表示什么含義?
C1=0社會模型:只有社會,沒有自;我迅速喪失群體多樣性;易陷入局優而無法跳出
C2=0認知模型:只有自我,沒有社會;完全沒有社會資訊共享;演算法收斂速度緩慢
粒子速度更新公式包含三部分:
第一部分稱為慣性部分,表示粒子對當前自身運動狀態的信任,為粒子提供一個必要動量,使其依據自身速度進行慣性運動
第二部分稱為“個體認知”部分,代表粒子本身的思考行為,鼓勵粒子飛飛向自身曾經發現的最佳位置
第三部分稱為“社會認知”部分,表示粒子間的資訊共享與合作,它引導粒子飛向粒子群中的最佳位置
粒子速度更新公式的第一項對應多樣化的特點,第二、三項對應于搜索程序的集中化的特點,這三項之間的相互平衡和制約決定了演算法的主要性能,
電賽積累的東西
1、
阻帶范圍內,頻率每改變10倍(增大10倍或減小10倍),例如從1MHz變成10MHz,對信號的衰減增加40dB,折算到電壓倍數,也就是100倍,如果頻率改變100倍,衰減則為80dB(10000倍),以此類推,濾波器階數越高,這個衰減數值越大,濾波性能越好,
2、
有部分組測驗放大器,低頻截止頻率偏高,把耦合電容改大就能解決
同時,只要存在耦合電容,仿真時從1mHz開始觀測,一定呈現帶通現象
電容特性是隔直通交,1mHz非常接近直流了,阻抗必然非常大
關于波特圖儀的設定
為了盡可能看清細節,需要合理設定水平和垂直坐標的范圍,建議剛好覆寫關心的范圍,必要時適當拓寬一些,
例如,測量放大器的增益時,頻率和幅度可以卡在3dB帶寬的范圍,再稍稍拓寬,給微調器件引數留出余地,
又如,測量濾波器的特性時,除了關心3dB通頻帶,還需要觀察過渡帶和阻帶,那么起始和結束頻率,需要覆寫阻帶(如低通濾波器的10倍頻程)
3、
畫PCB圖有時會遇到線走不過去,需要飛線的情況
如果需要飛線的跨度很小,比如只跨越一條寬度20mil以內的線,就可以用0歐姆電阻替代飛線
4、壓控放大器,顧名思義就是利用電壓來控制運放的增益,而利用MCU控制的放大器叫做程控增益放大器,下面我們來看看壓控增益放大器,
5、電流型反饋運放和電壓反饋運放直接的區別
led導通電壓
白光 2.7
紅色 1.8
器件手冊能到官方找最好
電路中不宜出現可調電阻,阻值不穩定
5秒內焊頭發黑發黃
5v以上才考慮反向漏電,一般用二極管解決
背面走線盡量少而短
去耦電容要盡量靠近vcc或者給gnd
pcb盡量并排走線
小板過空不要太多也不要密集排布
絲印離焊盤10mil以上
設計板子大小,把禁止布線范圍設定好后,選中生成就可以開始畫了,格子也不要太小
統一設定點元件右鍵尋找相似物件,string type
same 查找后統一設定
板子1.6mm的厚度,插孔,方槽設計在機械層1
自己腐蝕電路可以比10mil寬一點,加粗降低直流電阻,供電更穩定
高器件靠邊,或者低器件焊盤離遠一點減少陰影效應
主要器件大器件優先布局
模擬器件和數字器件要磁區,模擬數字供電也要分開
封裝可以盡量靠實際設計這樣不容易出現機械錯誤
數字地和模擬地之間電壓差要小
去耦電容就近打過孔就近連接
大片銅片連接過去耦要隔開,去耦單獨進行
蛇形線做等長控制,信號到達時間相同
多組信號配合對信號建立和保持要求更高
十字花連接,降低散熱速度
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/294120.html
標籤:AI
上一篇:【機器學習】主成分分析(PCA)——利用奇異值分解(SVD)(理論+圖解+公式推導)
下一篇:task01-熟悉規則,學習概覽