消費者Rebaleance機制
當磁區以及給消費者分配好 然后又添加了一個磁區或者消費者掛了一個或者多個前提這個消費者有消費的磁區 這就會觸發rebaleance機制 這個機制就會重新給磁區分配消費者 它有三種分配策略range、round-robin、sticky,
range分配策略會 給前m個消費者分配n+1個磁區 后面的就分配n個磁區 假設10個磁區0-3分配給 consumer1,4-6分配給consumer2,7-9分配給consumer3 當添加了一個磁區或者消費者掛了也就是觸發了rebaleance機制 就會把之前消費者跟磁區的連接全部關閉重新根據range分配策略分配
round-robin策略會輪詢分配 比如有0-9個磁區 三個消費者 這樣就會消費者1會分配0、3、6、9 消費者2會分配1、4、7 消費者3會2、5、8 當觸發rabaleance機制也是會把所有消費者跟磁區全部關閉 然后重新根據round-robin策略分配
sticky分配策略剛開始是跟round-robin一樣 但是在觸發了rebalance的時候 需要保持兩個原則
磁區的分配要盡可能均勻 ,
磁區的分配盡可能與上次分配的保持相同,
也就是說 當消費者掛了 只會給那個對應的磁區分配消費者 那些沒事的磁區不會動 如果當消費者3掛了 那么就會把2、5、8平均分配 消費者1就變成0、3、6、9、2
消費者2就變成1、4、7、5、8
消費者剛開始啟動的時候磁區與消費者分配關系都是根據上面的策略決定的
Rebalance大體程序
第一階段選擇組協調器
磁區的時候 每個消費者組會首先從主題的磁區中選一個broker當組長 這個組長會監控消費組里的所有消費者心跳 以及判斷是否宕機 然后開啟消費者的rebalance
consumer group中的每個consumer啟動時會向kafka集群中的某個節點發送 FindCoordinatorRequest 請求來查找對應的組協調器GroupCoordinator,并跟其建立網路連接,
組協調器選擇方式:
consumer消費的offset要提交到__consumer_offsets的哪個磁區,這個磁區leader對應的broker就是這個consumer group的coordinator
第二階段:加入消費組JOIN GROUP
在成功找到消費組所對應的 GroupCoordinator(組協調器 也就是組長) 之后就進入加入消費組的階段,在此階段的消費者會向 GroupCoordinator 發送 JoinGroupRequest 請求,并處理回應,然后GroupCoordinator 會從消費者組中選第一個連接到它的消費者讓它升級為組長 然后會把消費者組的情況發給這個組長讓這個組長組織磁區方案
第三階段( SYNC GROUP)
consumer leader(就是消費者的哪個組長)通過給GroupCoordinator(讀音 谷如破考務得內則 中文意思組協調器)發送SyncGroupRequest,接著GroupCoordinator就把磁區方案下發給各個consumer,他們會根據指定磁區的leader broker進行網路連接以及訊息消費,
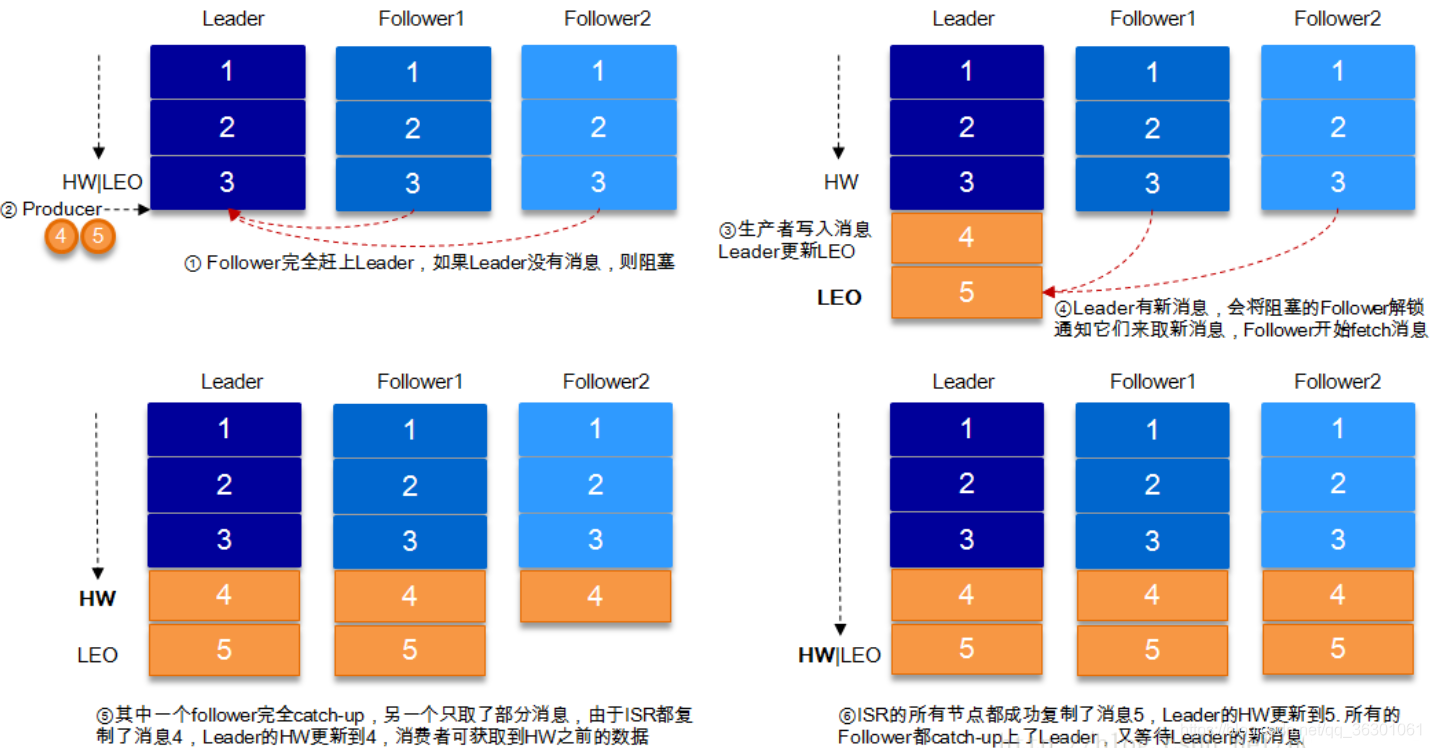
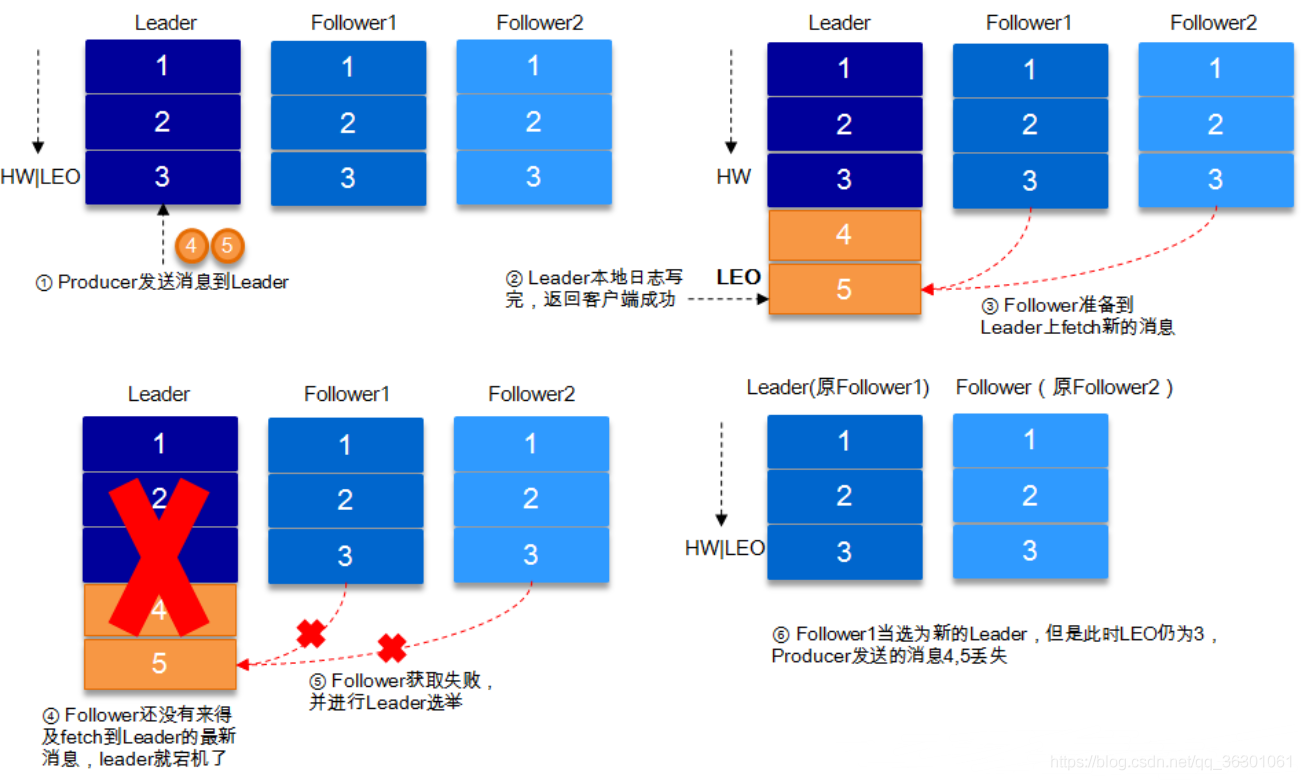
HW可以解決leader節點掛了資料不一致問題
HW與LEO示意圖
當發送者為異步發送
HW高水位與LEO詳解
HW俗稱高水位
LEO為log-end-offset 這個就是當生產者發送一條訊息到broker 然后leader把這個消費放到了log檔案中就會增長LEO 其他follower同步的時候也會吧LEO同步過去 每個節點都自己維護這個leo
高水位是針對消費者的 意思就是 當生產者發送了一個訊息到broker 前提broker的主題有多個備份 然后broker會備份訊息 當這個訊息只被這個主題的broker leader給實體化 其它的節點還沒同步 這時消費者是消費不了這條訊息的 因為在發送訊息的時候會保存一個值 判斷這個值在其他的備份的檔案中有沒有 如果沒有就不能被消費 如果都同步了 才能讓消費者看到
kafka的可視化管理界面 kafka-manager
安裝及基本使用可參考:https://www.cnblogs.com/dadonggg/p/8205302.html
一般線上jvm引數設定 機器記憶體為16核32g 3T磁盤容量
export KAFKA_HEAP_OPTS="-Xmx16G -Xms16G -Xmn10G -XX:MetaspaceSize=256M -XX:+UseG1GC -XX:MaxGCPauseMillis=50 -XX:G1HeapRegionSize=16M"
訊息丟失情況
訊息發送端
(1)acks=0: 表示producer不需要等待任何broker確認收到訊息的回復,就可以繼續發送下一條訊息,性能最高,但是最容易丟訊息,大資料統計報表場景,對性能要求很高,對資料丟失不敏感的情況可以用這種,
(2)acks=1: 至少要等待leader已經成功將資料寫入本地log,但是不需要等待所有follower是否成功寫入,就可以繼續發送下一條訊息,這種情況下,如果follower沒有成功備份資料,而此時leader又掛掉,則訊息會丟失,
(3)acks=-1或all: 這意味著leader需要等待所有備份(min.insync.replicas配置的備份個數)都成功寫入日志,這種策略會保證只要有一個備份存活就不會丟失資料,這是最強的資料保證,一般除非是金融級別,或跟錢打交道的場景才會使用這種配置,當然如果min.insync.replicas配置的是1則也可能丟訊息,跟acks=1情況類似,
訊息消費端
如果消費這邊配置的是自動提交,萬一消費到資料還沒處理完,就自動提交offset了,但是此時你consumer直接宕機了,未處理完的資料丟失了,下次也消費不到了,
訊息重復消費
訊息發送端:
發送訊息如果配置了重試機制,比如網路抖動時間過長導致發送端發送超時,實際broker可能已經接收到訊息,但發送方會重新發送訊息
訊息消費端:
如果消費這邊配置的是自動提交,剛拉取了一批資料處理了一部分,但還沒來得及提交,服務掛了,下次重啟又會拉取相同的一批資料重復處理
一般消費端都是要做消費冪等處理的,
訊息亂序
使用一個磁區一個消費者 這樣性能可能會變差 所以我們可以 創建多個記憶體佇列 然后創建多個執行緒 讓這個消費者往佇列中丟訊息 然后異步執行緒慢慢處理
訊息積壓
一個磁區只能對應一個消費者 我們可以讓這個消費者 把消費發送到另一個主題中 然后給這個主題創建多個磁區進行消費
延時佇列
可以創建個主題 然后用定時任務 進行對這個訊息的消費
訊息回溯/重新消費
如果某段時間對已消費訊息計算的結果覺得有問題,可能是由于程式bug導致的計算錯誤,當程式bug修復后,這時可能需要對之前已消費的訊息重新消費,可以指定從多久之前的訊息回溯消費,這種可以用consumer的offsetsForTimes、seek等方法指定從某個offset偏移的訊息開始消費,參見上節課的內容,
訊息傳遞保障
at most once(消費者最多收到一次訊息,0–1次):acks = 0 可以實作,
at least once(消費者至少收到一次訊息,1–多次):ack = all 可以實作,
exactly once(消費者剛好收到一次訊息):at least once 加上消費者冪等性可以實作,還可以用kafka生產者的冪等性來實作,
kafka生產者的冪等性:因為發送端重試導致的訊息重復發送問題,kafka的冪等性可以保證重復發送的訊息只接收一次,只需在生產者加上引數 props.put(“enable.idempotence”, true) 即可,默認是false不開啟,
kafka的事物
kafka的事物 只針對kafka 當kafka發送訊息到不同的主題時 出例外了 會把這些主題中發送成功的主題進行回滾
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("transactional.id", "my-transactional-id");
Producer<String, String> producer = new KafkaProducer<>(props, new StringSerializer(), new StringSerializer());
//初始化事務
producer.initTransactions();
try {
//開啟事務
producer.beginTransaction();
for (int i = 0; i < 100; i++){
//發到不同的主題的不同磁區
producer.send(new ProducerRecord<>("hdfs-topic", Integer.toString(i), Integer.toString(i)));
producer.send(new ProducerRecord<>("es-topic", Integer.toString(i), Integer.toString(i)));
producer.send(new ProducerRecord<>("redis-topic", Integer.toString(i), Integer.toString(i)));
}
//提交事務
producer.commitTransaction();
} catch (ProducerFencedException | OutOfOrderSequenceException | AuthorizationException e) {
// We can't recover from these exceptions, so our only option is to close the producer and exit.
producer.close();
} catch (KafkaException e) {
// For all other exceptions, just abort the transaction and try again.
//回滾事務
producer.abortTransaction();
}
producer.close();
kafka高性能
磁盤順序讀寫 卡發卡訊息不能修改以及不會從檔案中洗掉保證了磁盤順序讀 kafka的訊息寫入檔案都是追加在檔案末尾,不會寫入檔案中的某個位置(隨機寫)保證了磁盤順序寫
資料傳輸的零拷貝
讀寫資料的批量batch(讀音 辦吃 中文意思 一批;一爐;一次所制之量)處理以及壓縮傳輸 這里體現在 消費者消費訊息是一次性拉取多條訊息
資料傳輸零拷貝原理
當讀取broker的訊息磁盤檔案時會先把檔案復制到內核讀取快取區 然后再從這個緩沖區復制到用戶緩沖區 然后從用戶緩沖區 復制到socket緩沖區 然后從socket緩沖區復制到網卡介面 然后發送給消費者 而kafka底層通過作業系統的sendfile來實作零拷貝 sendfile會直接從內核讀取資料緩沖區把檔案復制到網卡介面然后發送給消費者
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/294160.html
標籤:其他