一、Flink應用開發
Flink作為流批一體的計算引擎,其面對的是業務場景,面向的使用者是開發人員和運維管理人員,
Flink應用程式,也叫Flink作業、FlinkJob.Flink作業包含了兩個基本的塊:資料流(DataStream)和轉換(Tranformation),DataStream是邏輯概念,為開發者提供了API介面,Transformation是處理行為的抽象,包含了資料的讀取、計算、寫出,所以Flink的作業中的DataStreamAPI呼叫,實際上構建了多個由Transformation組成的資料處理流水線(Pipline),
執行時,Flink應用被映射成DataFlow,由資料流和轉換操作組成,每個DataFlow從一個或多個資料源開始,并以一個或多個Sink輸出結束,DataFlow本質上是一個有向無環圖(DAG),但是允許通過迭代構造特殊形式的有向無環圖,
Flink應用由相同的基本部分組成:
- 獲取引數(可選)
如果有配置引數,則讀取配置引數,可以是命令輸入的引數,也可以是組態檔,
- 初始化Stream執行環境
這是必須要做的,讀取資料的API依賴于該執行環境,
- 配置引數
讀取到的引數可以是執行環境引數或者業務引數,這些引數會覆寫flink.conf中默認的配置引數,
- 讀取外部資料
Flink作為分布式執行引擎,本身沒有資料存盤能力,所以定義了一系列介面、連接器與外部存盤進行互動,讀寫資料,
- 資料處理流程
呼叫DataStream的API組成資料處理的流程,如呼叫DataStream.map().filter()……組成一個資料流水線,
- 將處理結果寫入外部
在Flink中將資料寫入外部的程序叫做Sink,Flink支持寫出資料到Kafka、HDFS、Hbase等外部存盤,
- 觸發執行
StreamExecutionEnvironment#execute是Flink應用執行的觸發入口,無論是一般的DataStreamAPI開發還是Table&SQL開發都是如此,
二、API層次
API層次如圖:
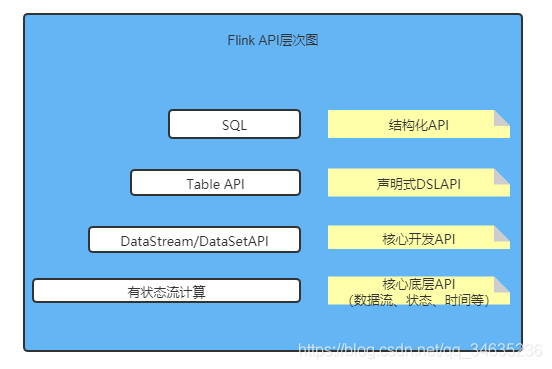
- 核心底層API
核心底層API提供了Flink的最底層的分布式計算構建塊的操作API,包含了ProcessFunction、狀態、時間和視窗等操作的API,
ProcessFunction是Flink提供的最具表現力的底層功能介面,Flink提供單流輸入的ProcessFunction和雙流輸入的CoProcessFuntion,能夠對單個事件進行計算,也能夠按照視窗對時間進行計算,
- 核心開發API(DataStream/DataSet)
DataStream/DataSet使用Fluent風格API,提供了常見資料處理的API介面,如用戶指定的各種轉換形式,包括連接(Join)、聚合(Aggregation)、視窗(Window)、狀態(State)等,
- 宣告式DSL API
Table API是以表為中心的宣告式領域專用語言(Domain Specified Language,DSL),表是關系型資料庫的概念,用在批處理中,在流計算中,為了引入動態表的概念(Dynamic Table),用來表達資料流表,
- 結構化API
SQL是Flink的結構化API,是最高層次的計算API,與Table API基本等價,區別在于使用的方式,SQL與Table API可以混合使用,SQL可以操作Table API 定義的表,Table API也能操作SQL定義的表和中間結果,
三、資料流
資料流是核心資料抽象,表示一個持續產生的資料流,
DataStream體系如圖:
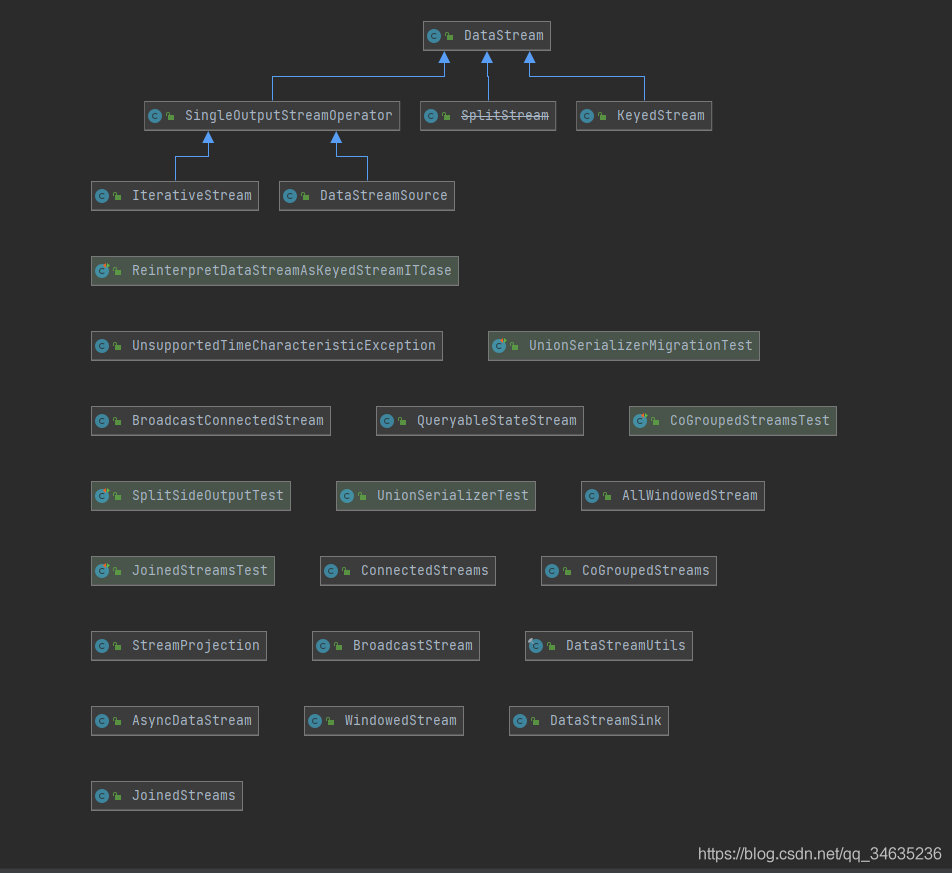
DataStreamSource本身就是一個DataStream,DataStreamSink、AsyncDataStream、BroadcastDataStream、BroadcastConnectedDataStream、QueryableDataStream都是對一般DataStream物件封裝,
- DataStream
DataStream是Flink資料流的抽象核心,其上定義了對資料流的一系列操作,同時也定義了與其他型別DataStream的相互轉換關系,每個DataStream都有一個Transformation物件,表示該DataStream從上游的DataStream使用該Transformation而來,
- DataStreamSource
DataStreamSource是DataStream的起點,DataStreamSource在StreamExecutionEnvironment中創建,由StreamExecutionEnvrionment.addSource(SourceFunction)創建而來,其中SourceFunction中包含了DataStreamSource從資料源讀取資料的具體邏輯,
- DataStreamSink
資料從DataSourceStream中讀取,經過中間的一系列處理操作,最終需要寫出到外部存盤,通過DataStream.addSink(SinkFunction)創建而來,其中SinkFunction定義了寫出資料到外部存盤的邏輯,
- KeyedStream
KeyedStream用來表示根據指定的key進行分組的資料流,一個KeyedStream可以通過呼叫DataStream.keyBy()來獲得,而在KeyedStream上進行任何Transformation都將轉變回DataStream,在現實中,KeyedStream把key的資訊寫入了Transformation中,每條記錄只能訪問所屬Key的狀態,其上的聚合函式可以方便地操作和保存對應key的狀態,
- WindowedStream & AllWindowedStream
WindowedStream代表了根據key分組且基于WindowAssigner切分視窗的資料流,所以WindowedStream都是從KeyedStream衍生而來的,在WindowedStream上進行任何Transformation也都將轉變回DataStream,
- JoinedStreams & CoGroupedStreams
Join是CoGroup的一種特例,JoinedStreams底層 使用CoGroupedStreams來實作,
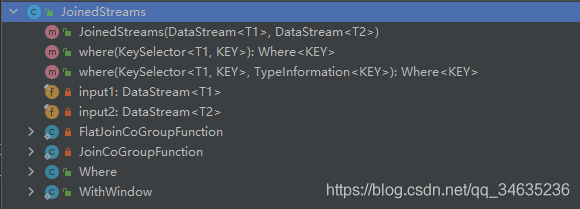
兩者區別如下:
CoGrouped側重的是Group,對資料進行分組,是對同一個key上的兩組集合進行操作,
Join側重的是資料對,對同一個key的每一對元素進行操作,
- ConnectedStreams
ConnectedStreams表示兩個資料流的組合,兩個資料流可以型別一樣,也可以型別不一樣,ConnectedStreams適用于兩個有關系的資料流的操作,共享state,
- BroadcastStream & BroadcastConnectedStream
BroadcastStream 實際上是對一個普通DataStream的封裝,提供了DataStream的廣播行為,
BroadcastConnectedStream 一般由DataStream/KeyedDataStream與BroadcastStream 連接而來,類似于ConnectedStream,
- IterativeStream
IterativeDataStream 是對一個DataStream的迭代操作,從邏輯上來說,包含IterativeStream的Dataflow是一個有向有環圖,在底層執行層面上,Flink對其進行了特殊處理,
- AsyncDataStream
AysncDataStream是個工具,提供在DataStream上使用異步函式的能力,
四、資料流API
DataStreamAPI是Flink流計算的最常用的API,相比于Table & SQL API更加底層,
4.1 資料讀取
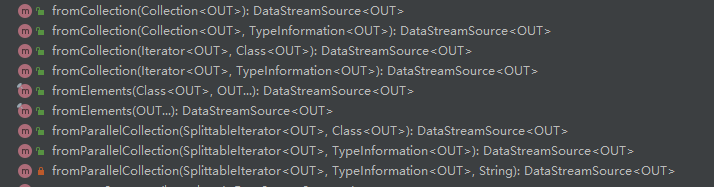
資料讀取的API定義在StreamExecutionEnvironmanet,這是Flink流計算應用的起點,第一個DataStream就是從資料讀取API中構造出來的,
- 從記憶體中讀取
- 檔案中讀取

- Socke接入資料

- 自定義讀取


4.2 處理資料
DataStreamAPI 使用Fluent風格處理資料,在開發的時候其實是在撰寫一個DataStream轉換程序,形成了DataStream處理鏈,
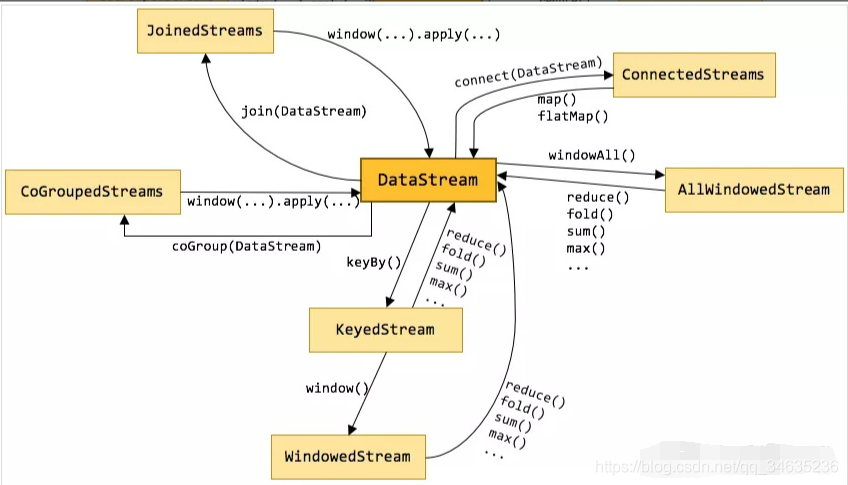
從圖中可以看到,并不是所有的DataStream都可以互相轉換,
- Map
接收1個元素,輸出1個元素,Map應用在DataStream上,輸出結果為DataStream, DataStream#map運算對應的是MapFunction,其類泛型為MapFunction<T,O>,T代表輸入資料型別,O代表操作結果輸出型別,

- FlatMap
接收1個元素,輸出0、1、...、N個元素,該類運算應用在DataStream上,輸出結果為DataStream,DataStream#flatMap對應的介面是FlatMapFuncion,其類泛型為FlatMapFunction<T,O>,T代表輸入資料型別,O代表操作結果輸出型別,

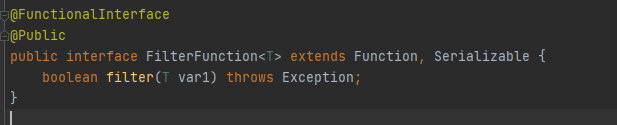
- Filter
過濾資料,如果回傳true則該元素繼續向下傳遞,如果為false則將該元素過濾掉,該類運算應用在DataStream上,輸出結果為DataStream,DataStream#filter介面對應的是FilterFunction,其類泛型為FilterFunction<T>,T代表輸出和輸出的資料型別,
- KeyBy
將資料流元素進行邏輯上的分組,具有相同Key的記錄將被劃分到同一組,KeyBy()使用Hash Partition實作,該運算應用在DataStream上,輸出結果為KeyedStream,輸出的資料流型別為KeyedStream<T,KEY>,其中T代表KeyedStream中元素資料型別,KEY代表邏輯Key的資料型別,

注意以下兩種資料不能作為key,
- POJO類未重寫hashCode(),使用了默認的Object.hashCode(),
- 陣列型別,
- Reduce
按照KeyedStream中的邏輯分組,將當前資料與最后一次的Reduce結果進行合并,合并邏輯由開發者自己實作,該類運算應用在KeyedStream上,輸出結果為DataStream,ReduceFuntion<T>中T代表KeyedStream中元素的資料型別,

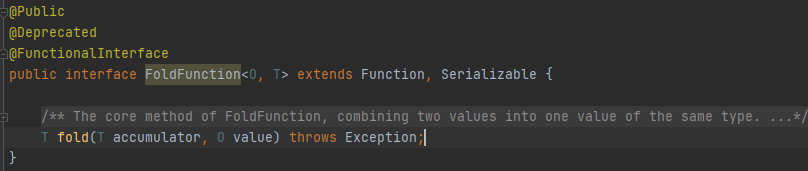
- Fold
Fold與Reduce類似,區別在于Fold是一個提供了初始值的Reduce,用初始值進行合并運算,該類運算應用在KeyedStream上,輸出結果為DataStream,Folder介面對應的是FoldFunction,其類泛型為FoldFunction<O,T>,O為KeyStream中的資料型別,T為初始值型別和Fold方法回傳值型別,
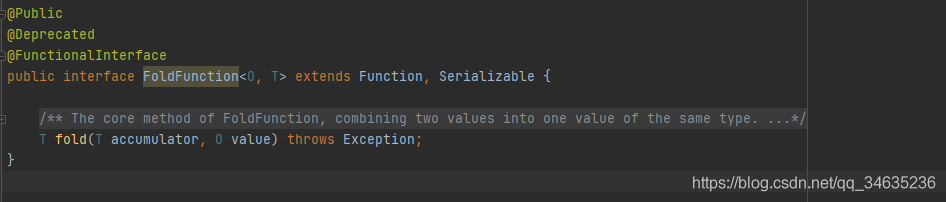
FoldFunction<O,T>已經被標記為Deprecated廢棄,替代介面是AggregateFunction<IN,ACC,OUT>,
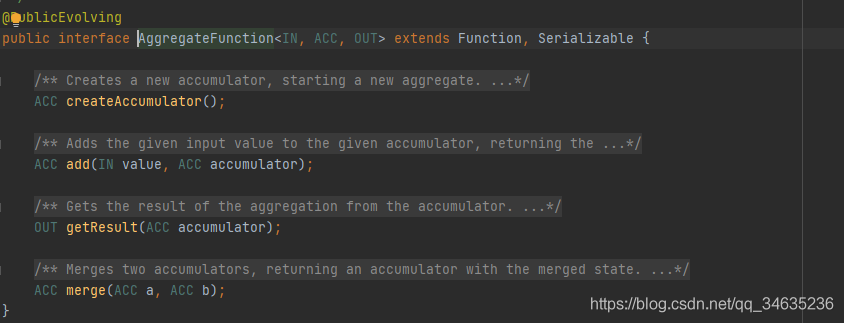
- Aggregation
漸進聚合具有相同Key的資料流元素,以min和minBy為例,min回傳的是整個KeyedStream的最小值,按照Key進行分組,回傳每個組的最小值,聚合運算輸出結果為DataStream,
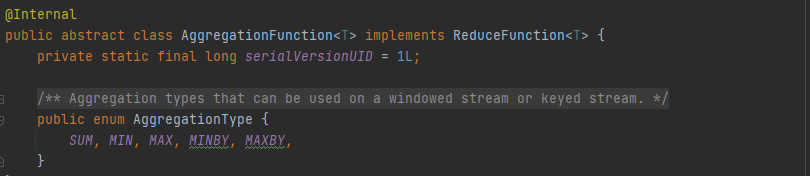
- Window
對KeyedStream資料,按照Key進行時間視窗切分,輸出結果為WindowedStream,輸出結果的類泛型為<T,K,W extends Window>,T為KeyedStream中的元素資料型別,K為指定Key的資料型別,W為視窗型別,

- WindowAll
對一般的DataStream進行視窗切分,即全域一個視窗,輸出結果為AllWindowedStream,

注意:在一般的DataStream上進行視窗切分,往往會導致無法并行計算,所有的資料都集中在WindowAll算子的一個Task上,
- Window Apply
將Window函式應用到視窗上,Window函式將一個視窗的資料作為整體進行處理,Window Stream有兩種:分組后的WindowedStream和未分組的AllWindowedStream,
1、WindowedStream
WindowedStream上應用的是WindowFunction,輸出結果為DataStream,WindowFunction<IN,OUT,KEY,W extends Window>中IN表示輸入值的型別,OUT表示輸出值的型別,KEY表示Key的型別,W表示視窗的型別,

2、AllWindowedStream
AllWindowedStream上應用的是AllWindowFunction,輸出結果為DataStream,AllWindowFunction<IN,OUT,KEY,W extends Window>中IN表示輸入值的型別,OUT表示輸出值的型別,KEY表示Key的型別,W表示視窗的型別,

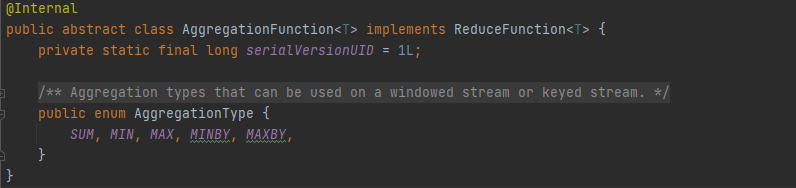
- Window Reduce
在WindowedStream上應用ReduceFunction,結果輸出為DataStream,

- Window Fold
在WindowedStream上應用FoldFunction,結果輸出為DataStream,
- Window Aggregation
統計聚合運算,在WindowedStream應用該運算,應用AggregationFunction,輸出結果為DataStream,
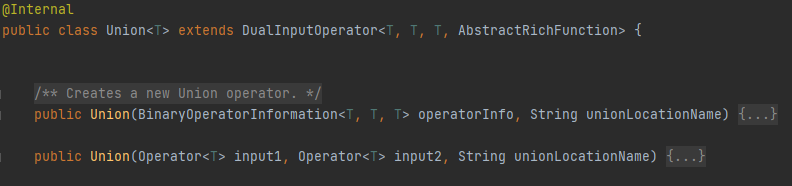
- Union
把兩個或多個DataStream合并,所有DataStream中的元素都會組合成一個新的DataStream,但是不去重,如果在自身上應用Union運算,則每個元素在新的DataStram出現兩次,
- Window Join
在相同時間范圍的視窗上Join兩個DataStream資料流,輸出結果為DataStream,Join核心邏輯在JoinFunction<IN1,IN2,OUT>中實作,IN1為第一個DataStream中的資料型別,IN2為第二個DataStream中的資料型別,OUT為Join結果的資料型別,

- Interval Join
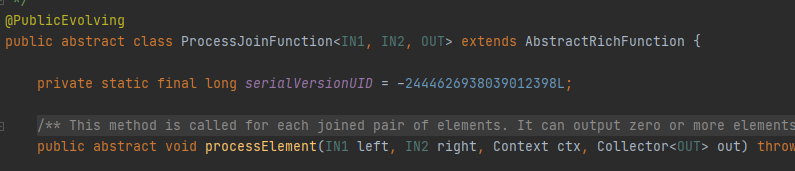
對兩次KeyedStream進行Join,需要指定時間范圍和Join時使用的Key,輸出結果為DataStream,Join的核心邏輯在ProcessJoinFunction<IN1,IN2,OUT>中實作,IN1為第一個DataStream中的元素資料型別,IN2為第2個DataStream中的元素資料型別,OUT為結果輸出型別,
- WindowCoGroup
兩個DataStream在相同時間視窗上應用CoGroup運算,輸出結果為DataStream,CoGroup和Join功能類似,CoGroup介面對應的是CoGroupFunction,其類泛型為CoGroupFunction<IN1,IN2,O>,IN1代表第一個DataStream中是元素型別,IN2代表第二個DataStream中是元素型別,O為輸出結果型別,

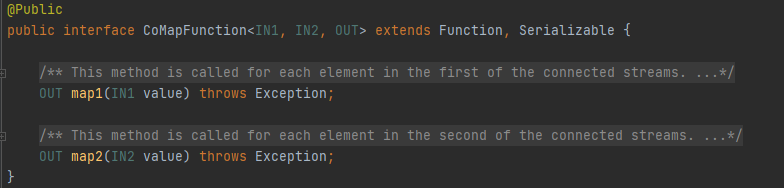
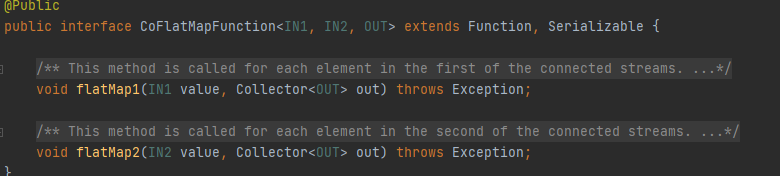
- CoMap和CoFlatMap
在ConnectedStream上應用Map和FlatMap運算,輸出流為DataStream,其基本邏輯類似于在一般DataStream上的Map和FlatMap運算,區別在于CoMap轉換有2個輸入,Map轉換有1個輸入,CoFlatMap同理,
- Split
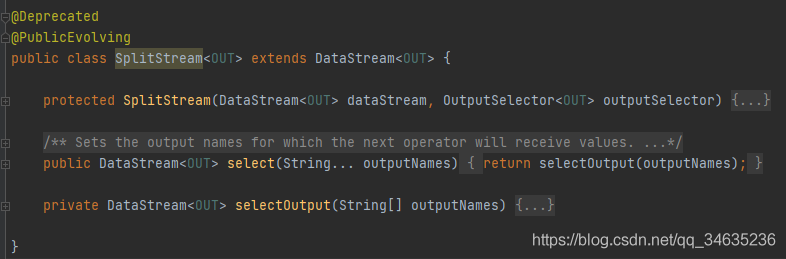
將DataStream按照條件切分多個DataStream,輸出流為SplitDataStream,該方法已經標記為廢棄,推薦使用SideOutput,
- Select
Select與Split運算配合使用,在Split運算中切分的多個DataStream中,Select用來選擇其中某一個具體的DataStream,

- Iterate
在API層面上,對DataStream應用迭代會生成1個IteractiveStream,然后在IteractiveSteram應用業務處理邏輯,最終生成一個新的DataStream,在資料流中創建一個迭代回圈,將下游的輸出發送給上游重新處理,

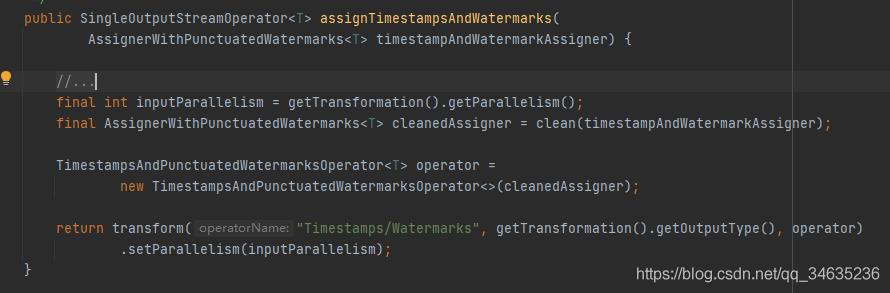
- Extract Timestamps
從記錄中提取時間戳,并生成WaterMark,該類運算不會改變DataStram,
- Project
該類運算只適用于Tuple型別的DataStream,使用Project選取子Tuple,可以選擇Tuple的部分元素,可以改變元素順序,類似于SQL陳述句中的Select子句,輸出流仍然是DataStream,

4.3 旁路輸出
旁路輸出在Flink中叫做SideOutput,類似于DataStream#split,本質上是一個資料流的切分行為,按照條件將DataStream切分為多個子資料流,子資料流叫做旁路輸出資料流,每個旁路輸出資料流可以有自己的下游處理邏輯,
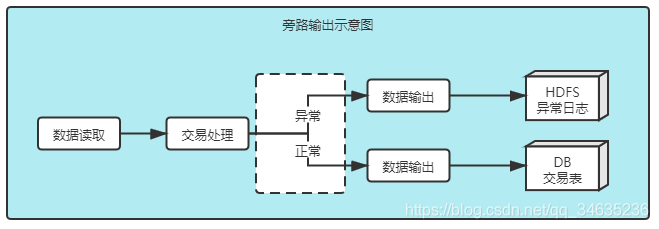
旁路輸出資料流的資料型別可以與上游資料流不同,多個旁路輸出資料流的資料型別也不必相同,
如何使用旁路輸出:
1、定義OutputTag,OutpuTag是每一個下游分支的標識,
![]()
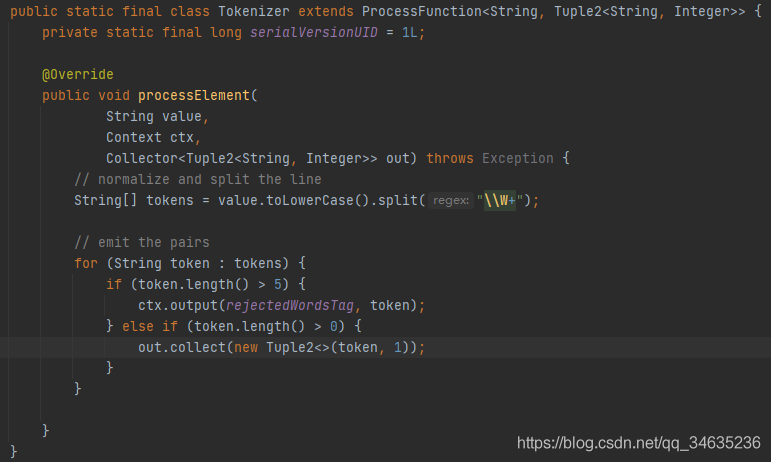
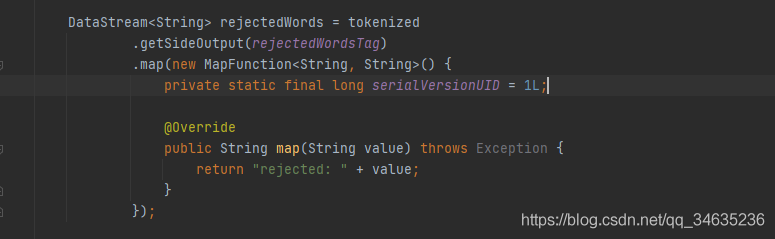
2、獲取旁路輸出
接下來Flink核心篇,如果對Flink感興趣或者正在使用的小伙伴,可以加我入群一起探討學習,
參考書籍《Flink 內核原理與實作》

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/294165.html
標籤:其他
上一篇:Flink 的 Time 三兄弟