文章目錄
- 1.堆空間的基本結構:
- 2.空間分配擔保機制
- 3.如何判斷一個物件已經無效
- 4 不可達的物件并非“非死不可”
- 5 如何判斷一個常量是廢棄常量?
- 6 如何判斷一個類是無用的類
- 7.垃圾回收演算法
如何判斷物件是否死亡(兩種方法),
簡單的介紹一下強參考、軟參考、弱參考、虛參考(虛參考與軟參考和弱參考的區別、使用軟參考能帶來的好處),
如何判斷一個常量是廢棄常量
如何判斷一個類是無用的類
垃圾收集有哪些演算法,各自的特點?
HotSpot 為什么要分為新生代和老年代?
常見的垃圾回收器有哪些?
介紹一下 CMS,G1 收集器,
Minor Gc 和 Full GC 有什么不同呢?
1.堆空間的基本結構:
現在的垃圾回收器基本上都采用分代垃圾回收演算法,可分為新生代和老年代,新生代又可分為Eden區、From Survivor0、To Survivor區,
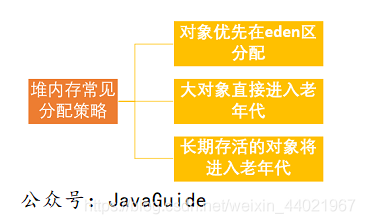
物件首先在eden區域分配,再經歷一次垃圾回收后,如果物件還存會,就年齡加一,并進入From Survive區,當年齡增加到一定程度(默認15歲)時,會進入老年代,物件進入老年代的年齡閾值可通過-Xx:MaxTenuringThreshold設定,這個值會在虛擬機運行程序中進行調整,HotSpot遍歷所有物件,按照年齡從小到大累計占用的區域,當累計區域超過一半時,取此時的年齡和設定的-Xx:MaxTenuringThreshold中較小值作為晉升老年代的年齡閾值,
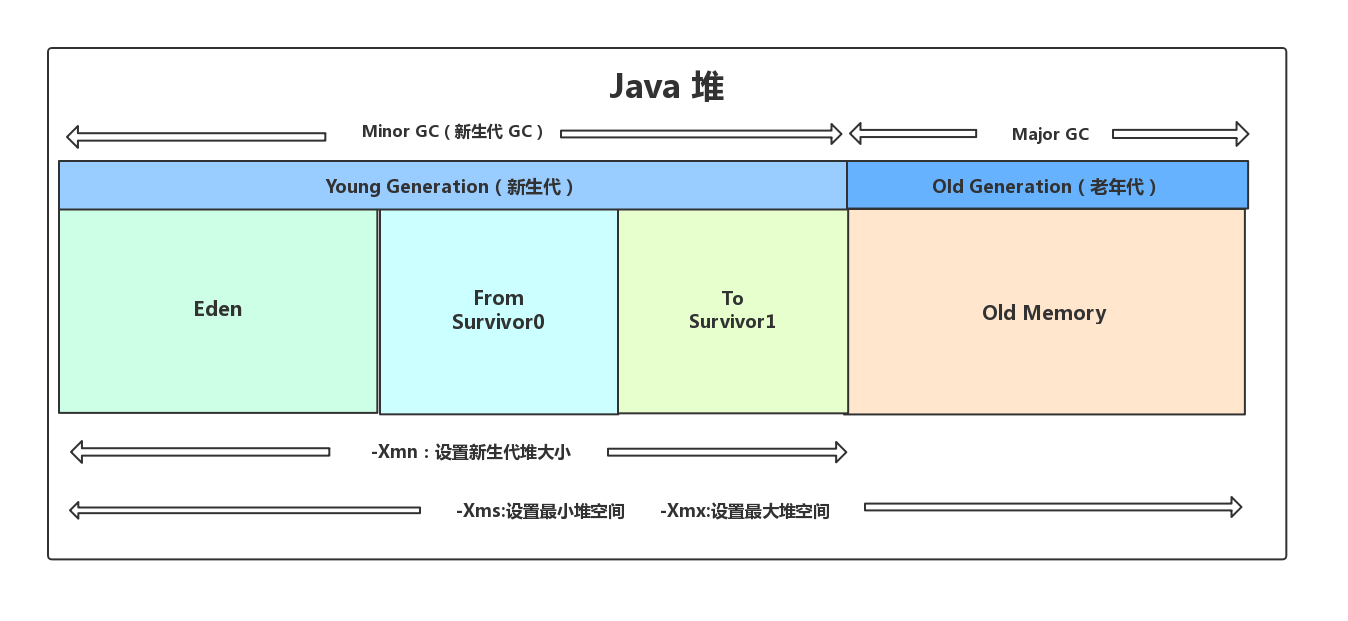
針對 HotSpot VM 的實作,它里面的 GC 其實準確分類只有兩大種:
-
部分收集 (Partial GC):
- 新生代收集(Minor GC / Young GC):只對新生代進行垃圾收集;
- 老年代收集(Major GC / Old GC):只對老年代進行垃圾收集,需要注意的是 Major GC 在有的語境中也用于指代整堆收集;
- 混合收集(MixedGC):對整個新生代和部分老年代進行垃圾收集,
-
整堆收集 (Full GC):收集整個 Java 堆和方法區,
2.空間分配擔保機制
為了確保Major GC時,老年代有足夠的空間容納新生代的所有物件,
《深入理解Java虛擬機》第三章對于空間分配擔保的描述如下:
JDK 6 Update 24 之前,在發生 Minor GC 之前,虛擬機必須先檢查老年代最大可用的連續空間是否大于新生代所有物件總空間,如果這個條件成立,那這一次 Minor GC可以確保是安全的,如果不成立,則虛擬機會先查看 -XX:HandlePromotionFailure引數的設定值是否允許擔保失敗(Handle Promotion Failure);如果允許,那會繼續檢查老年代最大可用的連續空間是否大于歷次晉升到老年代物件的平均大小,如果大于,將嘗試進行一次 MinorGC,盡管這次 Minor GC 是有風險的;如果小于,或者 -XX: HandlePromotionFailure設定不允許冒險,那這時就要改為進行一次 Full GC,
JDK 6 Update 24之后的規則變為只要老年代的連續空間大于新生代物件總大小或者歷次晉升的平均大小,就會進行 MinorGC,否則將進行 Full GC,
3.如何判斷一個物件已經無效
參考計數法
給物件中添加一個參考計數器,每當有一個地方參考它,計數器就加 1;當參考失效,計數器就減 1;任何時候計數器為 0 的物件就是不可能再被使用的,
這個方法實作簡單,效率高,但是目前主流的虛擬機中并沒有選擇這個演算法來管理記憶體,其最主要的原因是它很難解決物件之間相互回圈參考的問題,
2.2 可達性分析演算法
這個演算法的基本思想就是通過一系列的稱為 “GC Roots” 的物件作為起點,從這些節點開始向下搜索,節點所走過的路徑稱為參考鏈,當一個物件到 GC Roots 沒有任何參考鏈相連的話,則證明此物件是不可用的,
可作為 GC Roots 的物件包括下面幾種:
虛擬機堆疊(堆疊幀中的本地變數表)中參考的物件
本地方法堆疊(Native 方法)中參考的物件
方法區中類靜態屬性參考的物件
方法區中常量參考的物件
所有被同步鎖持有的物件
4 不可達的物件并非“非死不可”
即使在可達性分析法中不可達的物件,也并非是“非死不可”的,這時候它們暫時處于“緩刑階段”,要真正宣告一個物件死亡,至少要經歷兩次標記程序;可達性分析法中不可達的物件被第一次標記并且進行一次篩選,篩選的條件是此物件是否有必要執行 finalize 方法,當物件沒有覆寫 finalize 方法,或 finalize 方法已經被虛擬機呼叫過時,虛擬機將這兩種情況視為沒有必要執行,
被判定為需要執行的物件將會被放在一個佇列中進行第二次標記,除非這個物件與參考鏈上的任何一個物件建立關聯,否則就會被真的回收,
5 如何判斷一個常量是廢棄常量?
運行時常量池主要回收的是廢棄的常量,那么,我們如何判斷一個常量是廢棄常量呢?
JDK1.7 之前運行時常量池邏輯包含字串常量池存放在方法區, 此時 hotspot 虛擬機對方法區的實作為永久代
JDK1.7字串常量池被從方法區拿到了堆中, 這里沒有提到運行時常量池,也就是說字串常量池被單獨拿到堆,運行時常量池剩下的東西還在方法區, 也就是hotspot 中的永久代 ,
JDK1.8 hotspot 移除了永久代用元空間(Metaspace)取而代之,這時候字串常量池還在堆, 運行時常量池還在方法區, 只不過方法區的實作從永久代變成了元空間(Metaspace)
假如在字串常量池中存在字串 “abc”,如果當前沒有任何 String 物件參考該字串常量的話,就說明常量 “abc” 就是廢棄常量,如果這時發生記憶體回收的話而且有必要的話,“abc” 就會被系統清理出常量池了,
6 如何判斷一個類是無用的類
方法區主要回收的是無用的類,那么如何判斷一個類是無用的類的呢?
判定一個常量是否是“廢棄常量”比較簡單,而要判定一個類是否是“無用的類”的條件則相對苛刻許多,類需要同時滿足下面 3 個條件才能算是 “無用的類” :
- 該類所有的實體都已經被回收,也就是 Java 堆中不存在該類的任何實體,
- 加載該類的ClassLoader 已經被回收, 該類對應的
- java.lang.Class 物件沒有在任何地方被參考,無法在任何地方通過反射訪問該類的方法,
7.垃圾回收演算法
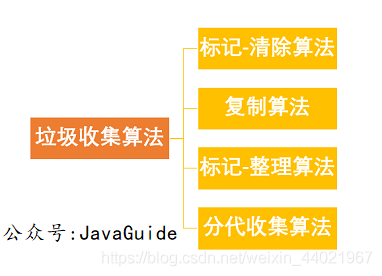
7.1 標記-清除演算法
該演算法分為“標記”和“清除”階段:首先標記出所有不需要回收的物件,在標記完成后統一回收掉所有沒有被標記的物件,它是最基礎的收集演算法,后續的演算法都是對其不足進行改進得到,這種垃圾收集演算法會帶來兩個明顯的問題:
效率問題
空間問題(標記清除后會產生大量不連續的碎片)
7.2 標記-復制演算法
為了解決效率問題,“標記-復制”收集演算法出現了,它可以將記憶體分為大小相同的兩塊,每次使用其中的一塊,當這一塊的記憶體使用完后,就將還存活的物件復制到另一塊去,然后再把使用的空間一次清理掉,這樣就使每次的記憶體回收都是對記憶體區間的一半進行回收,
7.3 標記-整理演算法
根據老年代的特點提出的一種標記演算法,標記程序仍然與“標記-清除”演算法一樣,但后續步驟不是直接對可回收物件回收,而是讓所有存活的物件向一端移動,然后直接清理掉端邊界以外的記憶體,
7.4 分代收集演算法
當前虛擬機的垃圾收集都采用分代收集演算法,這種演算法沒有什么新的思想,只是根據物件存活周期的不同將記憶體分為幾塊,一般將 java 堆分為新生代和老年代,這樣我們就可以根據各個年代的特點選擇合適的垃圾收集演算法,
比如在新生代中,每次收集都會有大量物件死去,所以可以選擇”標記-復制“演算法,只需要付出少量物件的復制成本就可以完成每次垃圾收集,而老年代的物件存活幾率是比較高的,而且沒有額外的空間對它進行分配擔保,所以我們必須選擇“標記-清除”或“標記-整理”演算法進行垃圾收集,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/294333.html
標籤:其他