深度學習—從入門到放棄(二)簡單線性神經網路
1.基本結構
就像昨天說的,我們構建深度學習網路一般適用于資料大,處理難度也大的任務,因此對于網路的結構需要有一個非常深入的了解,這里以一個分類貓狗的線性神經網路分類器作為例子:
1.目標函式
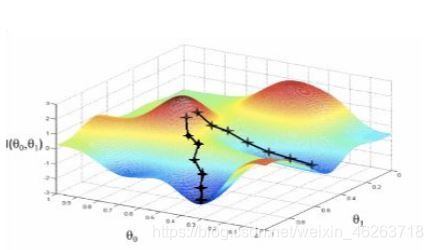
想象一下,如果是想要一個能夠分類出貓和狗的網路,我們的最終目的是什么?應該是使用最短的時間,最好的方法來完成任務,具象的來說就是在崎嶇的山上找一條最優的下山路徑,在神經網路中就是指最大限度降低損失函式的路徑,
2.學習規則
可以繼續聯想剛剛的下山路徑,我們的目標函式是如何最優下山,而學習規則則是我們該如何下山,換言之也就是我們如何通過不斷的學習和迭代獲得最優路徑,最優模型引數,
3.網路架構
什么是神經網路?就如同它的字面意思,是由一層層神經元構成的網路結構,因此我們如何設計神經元間的連接以及網路層數都會對結果產生影響,我們今天的大標題叫簡單線性神經網路,也就是說層和層之間是以線性關系連接,
4.初始化
又回到我們的下山問題,下山的目標(目標函式)和如何下山(學習規則)都找到了,那么還有一個問題,我們該從哪里出發,而這就是初始化,起點決定成敗,一個好的起點會讓我們節省很多力氣,
5.環境
既然是分類問題,那么肯定要給我們的網路一些實體去學習,但對于深度學習網路龐大資料量的需求,我們又該怎么辦呢?如果我說有這么一個開放資料集,里面有成千上萬的圖片資料,且都是預處理好了的,是不是解決了一大難題!在貓狗分類的問題里我們選用了IMAGENET里的圖片資料,
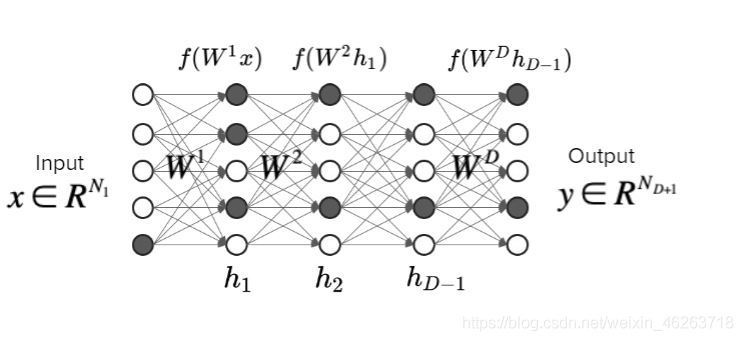 有了一個基本的認知之后我們再來引入一個簡單線性神經網路,可以看到這個神經網路是多層結構的,每一層都有自己的權重w,而我們之前所說的“下山”便是找到損失函式最小的最優引數w,
有了一個基本的認知之后我們再來引入一個簡單線性神經網路,可以看到這個神經網路是多層結構的,每一層都有自己的權重w,而我們之前所說的“下山”便是找到損失函式最小的最優引數w,
2.梯度下降
由于大多數學習演算法的目標是最小化風險(也稱為成本或損失)函式,因此優化通常是大多數機器學習演算法的核心!梯度下降演算法及其變體(例如隨機梯度下降)是用于深度學習的最強大和最流行的優化方法之一,
2.1梯度向量
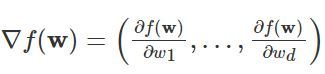
這里有關梯度向量大家只需要有這么一個了解就夠了:梯度向量總是指向區域損失函式增大的方向,可以這么理解:下山程序中如果跟著梯度向量的方向走就可能會變成如何更好攀登頂峰而不是下山,為了解決這個問題,我們在之后引入負的梯度向量的概念,
2.2梯度下降演算法

這里就用到了上一節提到的負梯度向量的概念,而這里的學習率可以理解為我們下山程序中每邁一步的步長,通過不斷的迭代更新(計算損失函式相對于可學習引數(即權重)的梯度),神經網路中的權重最侄訓傳我們想要的“下山最優解”
2.3計算圖和反向傳播
對于梯度下降演算法的結構分析后我們不難發現:隨著變數和嵌套函式數量的增加,梯度的推導將變得十分艱難(梯度向量的計算需要對函式微分),這違背了我們設定梯度下降的初衷—不僅沒有找到最優引數還會加大計算負擔,
這里我們以一個嵌套函式為例:
我們可以構建一個所謂的計算圖(如下所示),將原始函式分解為更小、更易于理解的運算式,
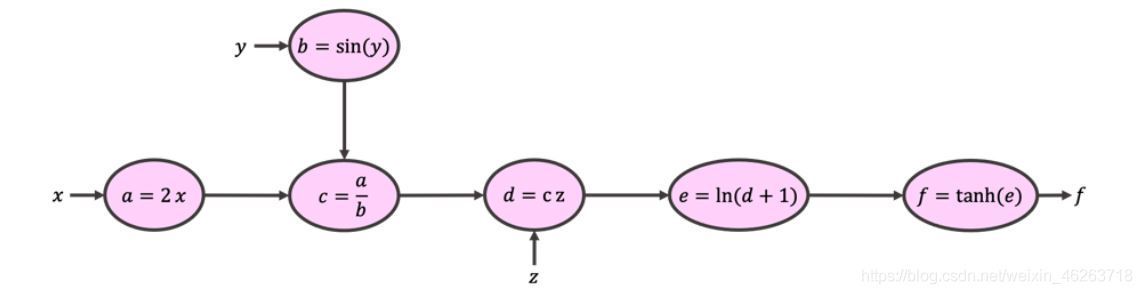
我們將上圖稱為前向傳播,經過前向傳播后的函式變得十分簡潔,隨后我們從前向傳播末端出發逐步向前微分,這個程序為反向傳播,
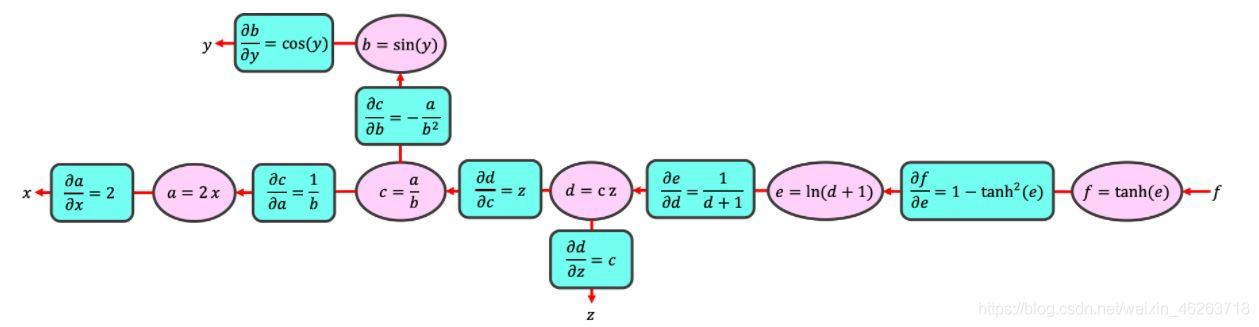
通過將計算分解為對中間變數的簡單操作,我們可以使用鏈式法則來計算任何梯度,
3.PyTorch 梯度下降
AutoGrad 是 PyTorch 的自動微分引擎,在Pytorch里梯度下降也是從前向傳播開始的,當我們宣告變數和操作時,PyTorch 會跟蹤所有指令,并在我們呼叫.backward(),即反向傳播時構建計算圖,PyTorch 每次迭代或更改圖時都會重建計算圖,
總結來說Pytorch梯度下降分為以下幾個步驟:
1.重置梯度
2.計算圖前向傳播
3.計算損失函式
4.計算圖反向傳播,計算損失函式相對于可學習引數(即權重)的梯度
5.梯度下降
# Reset all gradients to zero
sgd_optimizer.zero_grad()
# Forward pass (Compute the output of the model on the features (inputs))
prediction = wide_net(inputs)
# Compute the loss
loss = loss_function(prediction, targets)
print(f'Loss: {loss.item()}')
# Perform backpropagation to build the graph and compute the gradients
loss.backward()
# Optimizer takes a tiny step in the steepest direction (negative of gradient)
# and "updates" the weights and biases of the network
sgd_optimizer.step()
4.nn.Moudle
PyTorch 為我們提供了現成的神經網路構建塊,例如層(例如線性、回圈等)、不同的激活和損失函式等等,都打包在torch.nn模塊中.
對于訓練,我們需要知道三點:
1.模型引數
模型引數是指模型的所有可學習引數,可通過呼叫.parameters()模型訪問,
2.損失函式
梯度下降的優化物件
3.優化器
PyTorch 為我們提供了許多優化方法(不同版本的梯度下降),優化器保存模型的當前狀態,并通過呼叫該step()方法,將根據計算出的梯度更新引數
4.1 定義一個簡單的神經網路
## A Wide neural network with a single hidden layer
class WideNet(nn.Module):
def __init__(self):
"""Initializing the WideNet"""
n_cells = 512
super().__init__()
self.layers = nn.Sequential(
nn.Linear(1, n_cells),
nn.Tanh(),
nn.Linear(n_cells, 1),
)
def forward(self, x):
"""Forward pass
Args:
x (torch.Tensor): 2D tensor of features
Returns:
torch.Tensor: model predictions
"""
return self.layers(x)
# Create a mse loss function
loss_function = nn.MSELoss()
# Stochstic Gradient Descent optimizer (you will learn about momentum soon)
lr = 0.003 # learning rate
#這里使用了隨機梯度下降中的momentum方法
sgd_optimizer = torch.optim.SGD(wide_net.parameters(), lr=lr, momentum=0.9)
網路結構為:
WideNet(
(layers): Sequential(
(0): Linear(in_features=1, out_features=512, bias=True)
(1): Tanh()
(2): Linear(in_features=512, out_features=1, bias=True)
)
)
4.2 訓練網路
def train(features, labels, model, loss_fun, optimizer, n_epochs):
"""Training function
Args:
features (torch.Tensor): features (input) with shape torch.Size([n_samples, 1])
labels (torch.Tensor): labels (targets) with shape torch.Size([n_samples, 1])
model (torch nn.Module): the neural network
loss_fun (function): loss function
optimizer(function): optimizer
n_epochs (int): number of training iterations
Returns:
list: record (evolution) of training losses
"""
loss_record = [] # keeping recods of loss
### 梯度下降
for i in range(n_epochs):
optimizer.zero_grad() # set gradients to 0
predictions = model(features) # Compute model prediction (output)
loss = loss_fun(predictions, labels) # Compute the loss
loss.backward() # Compute gradients (backward pass)
optimizer.step() # update parameters (optimizer takes a step)
loss_record.append(loss.item())
return loss_record
set_seed(seed=2021)
epochs = 1847 # Cauchy, Exercices d'analyse et de physique mathematique (1847)
losses = train(inputs, targets, wide_net, loss_function, sgd_optimizer, epochs)
with plt.xkcd():
ex3_plot(wide_net, inputs, targets, epochs, losses)
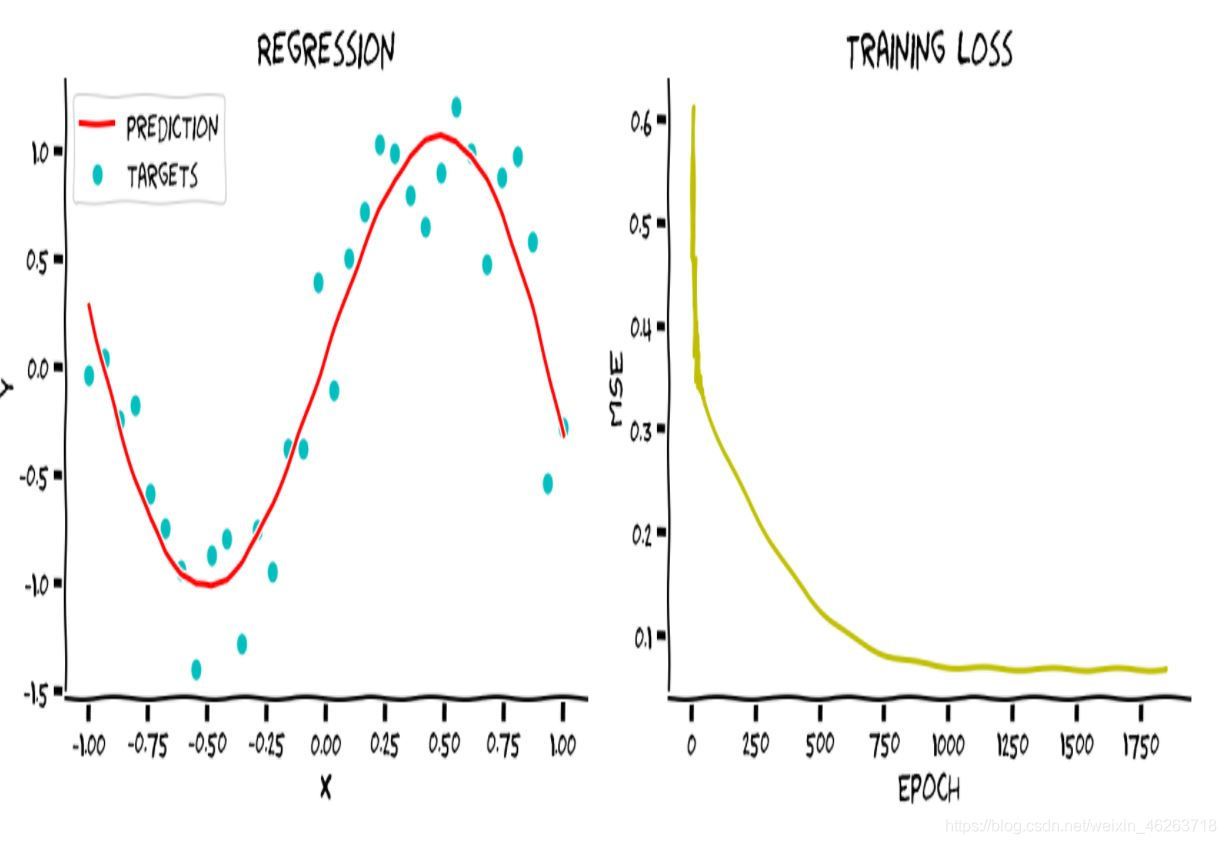
對應一開始深度學習網路的五大成分,我們可以這么理解:
1.目標函式–MSE損失
loss_function = nn.MSELoss()
2.學習規則–隨機梯度下降和momentum方法
sgd_optimizer = torch.optim.SGD(wide_net.parameters(), lr=lr, momentum=0.9)
3.網路結構–512個神經元,1個隱藏層,1個Tanh激活層
def init(self):
n_cells = 512
super().init()
self.layers = nn.Sequential(
nn.Linear(1, n_cells),
nn.Tanh(),
nn.Linear(n_cells, 1),
)
4.初始化–隨機
5.環境
5.超引數
5.1 網路深度
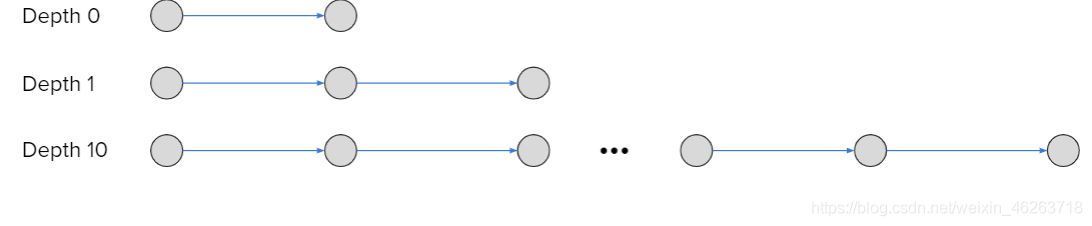
在了解”深度“這個概念前,我們先來看看神經網路的結構:輸入層,隱藏層,輸出層,因此深度在這里指的就是隱藏層的數量,隱藏層數量越多,網路深度越大,
那么讓我們來看看深度在訓練神經網路時帶來的挑戰,想象一個具有 50 個隱藏層且每層只有一個神經元的單輸入單輸出線性網路,網路的輸出很容易計算:
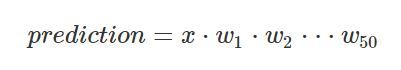
如果所有權重的初始值為
w
i
=
2
wi=2
wi=2,
y
(
p
)
=
2
50
≈
1.1256
×
1
0
15
y(p)=2^{50}≈1.1256×10^{15}
y(p)=250≈1.1256×1015,這時候的預測值趨近于無限大,此時這種情況稱為梯度爆炸,
如果所有權重的初始值為
w
i
=
0.5
wi=0.5
wi=0.5,
y
(
p
)
=
0.
5
50
≈
8.88
×
1
0
?
16
y(p)=0.5^{50}≈8.88×10^{-16}
y(p)=0.550≈8.88×10?16,這時候的預測值趨近于無限小,此時這種情況稱為梯度消失,
因此為了有效的避免這兩種情況發生,我們需要了解深度對于網路訓練帶來的影響:

不難看出,淺層網路的學習是一個循序漸進的程序,而對于深層網路而言它的學習程序更像sigmoid函式,即通過一定時間的學習后突然掌握資料集的某些特征,這兩種學習方式是截然不同的,
5.2 學習率
學習率是大多數優化演算法的常見超引數,我們可以把學習率想成梯度下降程序中每一步的步長,
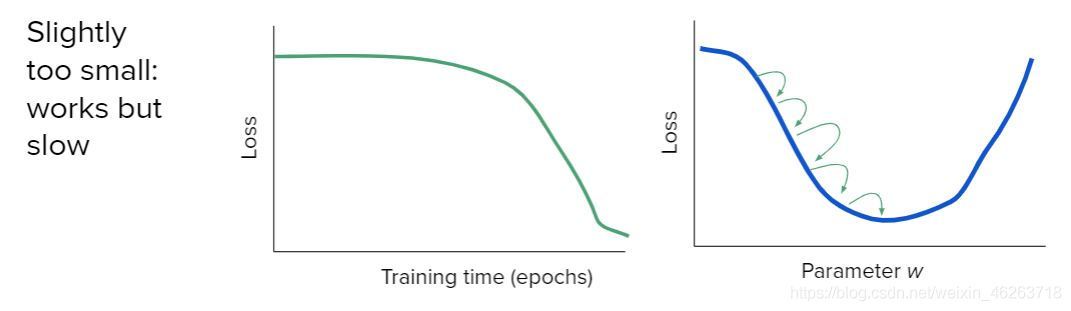
1.學習率過小
學習率過小將會導致損失函式收斂過慢,即梯度下降邁步太小,花費很長時間都不能走到損失函式最小的最優引數的位置
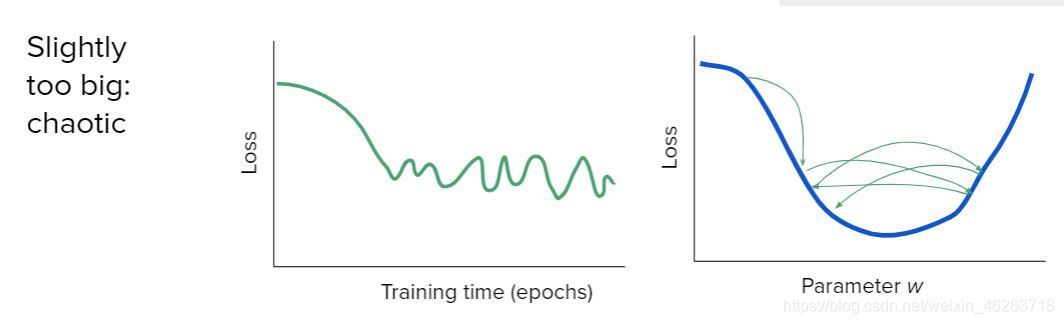
2.學習率過大
學習率過大會導致梯度下降時跳過損失函式最小值,造成損失函式的波動
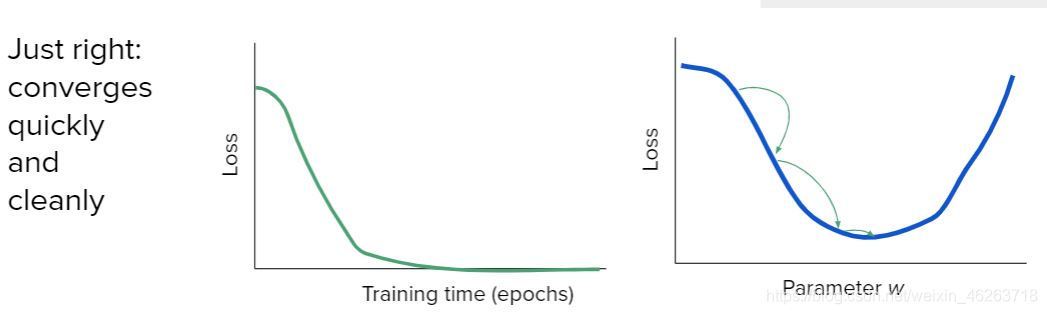
上圖為適宜學習率下的神經網路損失隨訓練時間的變化
5.3 深度,學習率的相互影響
一般來說,深度越深的網路需要的是更小的學習率,可以想象成它的處理程序更為復雜,因而也就更需要小心翼翼的走好每一步,而淺層神經網路則正好相反,它可以承受較大學習率帶來的影響,
5.4 初始化
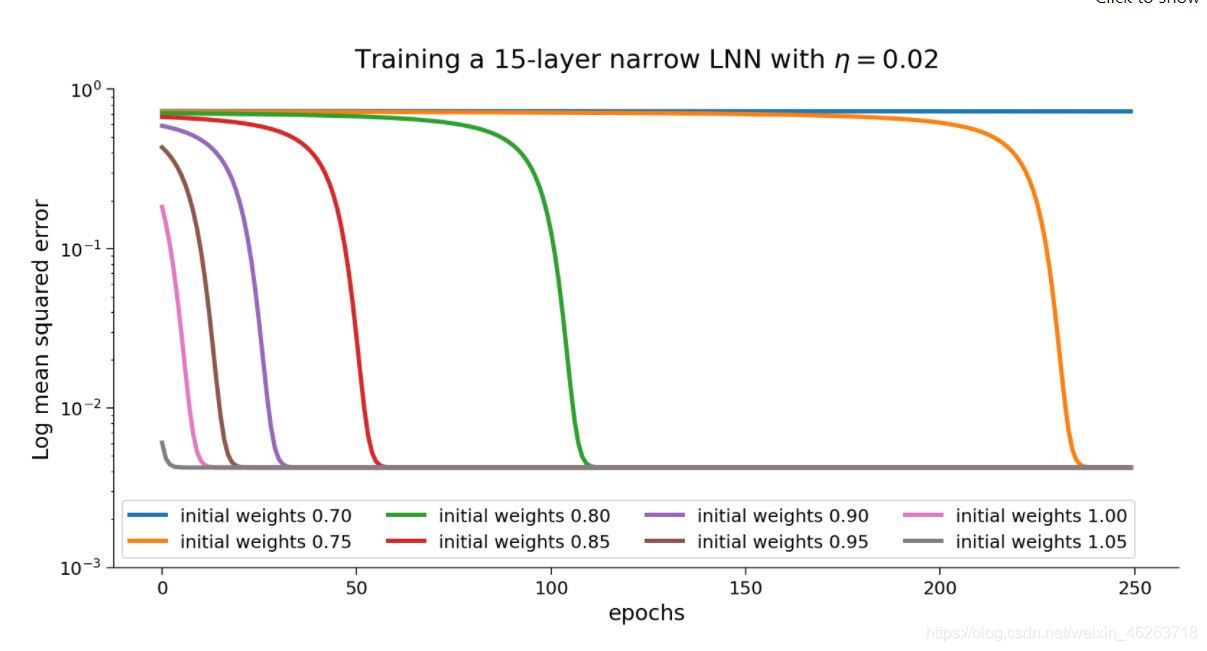
詳見之前說到的梯度爆炸和梯度消失,
歡迎大家關注公眾號奇趣多多一起交流!

深度學習—從入門到放棄(一)pytorch基礎
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/294380.html
標籤:AI