一、特征處理
特征處理是通過特定的統計方法,將資料轉化成演算法要求的資料,其API為sklearn.preprocessing,先來看一組資料:

第一組中的特征1 相比于特征2而言大了幾十倍,在正常處理時這些點即可視為例外點,影響統計結果分析,采用特征處理后轉變為右側的資料,可以更加方便的處理而不會產生例外值,
常見的處理方法如下:
| 資料型別 | 處理方法 |
|---|---|
| 數值型資料 | 歸一化、標準化、缺失值 |
| 類別型資料 | one hot編碼 |
| 時間型資料 | 時間的切分 |
( 一)歸一化
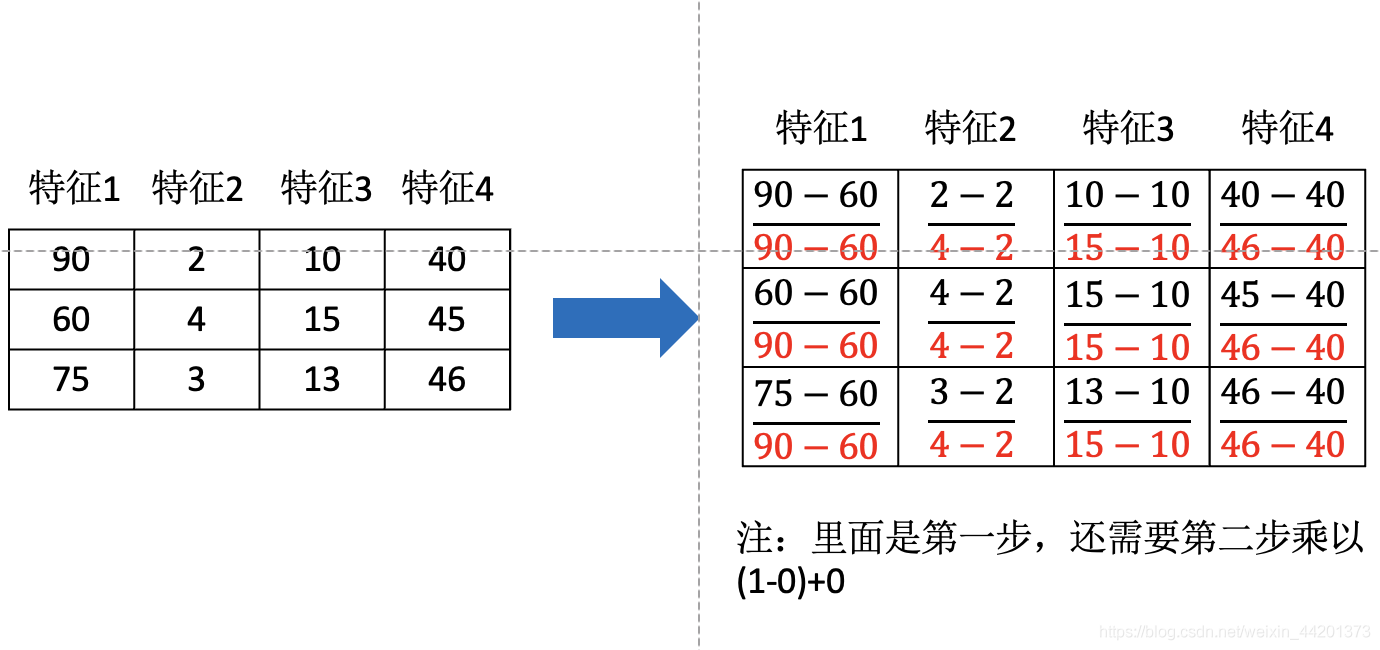
歸一化是通過對原始資料進行變換把資料映射到一定范圍(默認0-1)之間,其公式為:

歸一化實體:
# 匯入特征處理api及其子庫
from sklearn.preprocessing import MinMaxScaler,StandardScaler,Imputer
# 定義一個歸一化處理函式
def mm(data):
"""歸一化處理"""
# 實體化mm
mm=MinMaxScaler(feature_range=(2,3))
# 呼叫fit_transform來處理資料
data=mm.fit_transform(data)
print("歸一化處理后的資料為:")
print(data)
return None
data=[[90, 2, 10, 40], [60, 4, 15, 45], [75, 3, 13, 46]]
mm(data=data)
歸一化處理后,原本的資料全部集中在(2-3)之間,

注意在特定場景下最大值最小值是變化的,另外,最大值與最小值非常容易受例外點影響,所以這種方法魯棒性較差,只適合傳統精確小資料場景,
(二)標準化

對于歸一化來說:如果出現例外點,影響了最大值和最小值,那么結果顯然會發生改變
對于標準化來說:如果出現例外點,由于具有一定資料量,少量的例外點對于平均值的影響并不大,從而方差改變較小,
def std(data):
"""標準化處理資料"""
# 實體化
sd=StandardScaler()
data=sd.fit_transform(data)
print("標準化處理后的資料為:")
print(data)
return None
data=[[90, 2, 10, 40], [60, 4, 15, 45], [75, 3, 13, 46]]
std(data=data)

標準化方法,在已有樣本足夠多的情況下比較穩定,適合現代嘈雜大資料場景,
(三)缺失值處理方法
缺失值的處理一般分為兩種,其一為洗掉,其一為填補,當缺失資料達到一定比例時,采取洗掉法,當資料量較小,可填補每行或每列的平均值或中位數,其api為Imputer

def im(data):
"""缺失值處理"""
# 實體化,將平均值填充至缺失值
im=Imputer(missing_values='NaN', strategy='mean', axis=0)
data=im.fit_transform(data)
print("缺失值處理后的資料為:")
print(data)
return None
data=[[90, 2, 10, np.nan], [60, np.nan, 15, 45], [75, 3, 13, 46]]
im(data=data)

二、特征選擇
在實際的資料中,資料量大、特征冗雜且很多特征之間存在較大的相關性,部分噪聲對預測結果有負影響,

如上圖,在機器學習識別鳥的種類時,如上四個特征哪幾個是需要的?可以看出,第三個特征和第四個有較大的相關性,較為冗余,因此在處理之前有必要對資料的特征進行一次選擇,
特征選擇就是單純地從提取到的所有特征中選擇部分特征作為訓練集特征,特征在選擇前和選擇后可以改變值、也不改變值,但是選擇后的特征維數肯定比選擇前小,畢竟我們只選擇了其中的一部分特征,同時也降低了識別學習的難度,
(一)Filter(過濾式):VarianceThreshold

低方差意味著資料較為集中,差異不大,因此選擇過濾式方法過濾掉方差較小的特征是一個不錯的辦法,
from sklearn.feature_selection import VarianceThreshold
def var(data):
"""
特征選擇-洗掉低方差的特征
:return: None
"""
# 將方差小于1的資料舍棄
var = VarianceThreshold(threshold=1.0)
data = var.fit_transform(data)
print("方差處理后的資料為:")
print(data)
return None
data=[[0, 2, 0, 3], [0, 1, 4, 3], [0, 1, 1, 3]]
var(data=data)

(二)降維處理 主成分分析法(PCA)
PCA的本質是一種簡化分析的技術,其目的是將資料維數壓縮,盡可能降低原資料的維度,損失少量資訊,
簡化前 簡化后

from sklearn.decomposition import PCA
def pca(data):
"""主成分分析"""
# n_components=0.9-損失的資料資訊為10%
pca=PCA(n_components=0.9)
data=pca.fit_transform(data)
print("降維后的資料為:")
print(data)
return None
data=[[2, 8, 4, 5], [6, 3, 0, 8], [5, 4, 9, 1]]
pca(data=data)
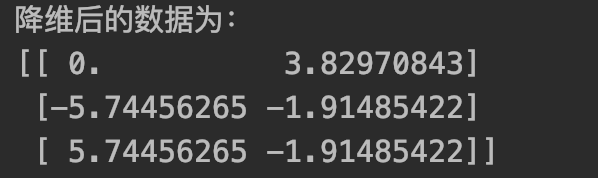
保留了原始資料90%的資訊的同時,將原資料從三維降低至二維,
以上為機器學習中特征的處理與選擇相關的方法,后續將介紹機器學習常用的模擬器,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/294388.html
標籤:AI
上一篇:機器學習模型評估指標