目錄
一、注意力機制介紹
1.淺談注意力
2.注意力機制類別
二、計算機視覺中的注意力機制
1.看圖說話
2.存在的問題
3.加入注意力機制
三、序列模型中的注意力機制
1.Seq2Seq的一些問題
2.Seq2Seq加入注意力機制
四、自注意力機制與Transformer
1.自注意力機制介紹
2. 自注意力機制細節
3.位置編碼
總結
一、注意力機制介紹
1.淺談注意力
注意力是人類學習中必不可少的要素,比如說我們去閱讀一個文章,或者試著去理解一本書中作者想表達的意思,我們通常在閱讀程序中會把注意力放在比較重要的環節上,而不是去把每個細節都會一一記住,人的記憶是有限的,抓重點的學習方式往往會得到事半功倍的效果,
那既然注意力這么重要,我們有沒有辦法把它用在AI應用中呢?答案是有的,那就是注意力機制,
注意力機制在過去幾年取得了飛速的發展,而且已經成為很多應用的標配,把注意力機制放到神經網路中,其實就是讓機器學習選擇性地去學習,同時知道如何把注意力放在更重要的事情上,比如對于一段文字來講,理解其含義可能只需要把重點放在幾個核心的單詞上,
2.注意力機制的重要性
在Attention誕生之前,已經有CNN和RNN及其變體模型了,那為什么還要引入attention機制?主要有兩個方面的原因,如下:
(1)計算能力的限制:當要記住很多“資訊“,模型就要變得更復雜,然而目前計算能力依然是限制神經網路發展的瓶頸,
(2)優化演算法的限制:LSTM只能在一定程度上緩解RNN中的長距離依賴問題,且資訊“記憶”能力并不高
注意力機制在不同應用下的使用也大同小異,對于圖片來講,注意力需要放到某一個區域上; 對于文本來講,注意力需要放在某幾個單詞上; 另外,這里所講的自注意力機制跟傳統的注意力機制有所不一樣,能夠更有效地解決梯度,并行化的問題,
二、計算機視覺中的注意力機制
1.看圖說話
看圖說話是指,根據給定的圖片生成一段文本描述,這個描述就是對于圖片的理解, 實際上,這個問題可以理解為把一個圖片轉換成文本,圖片理解這塊可采用CNN模型,文本生成模塊可采用LSTM模塊,
2.存在的問題
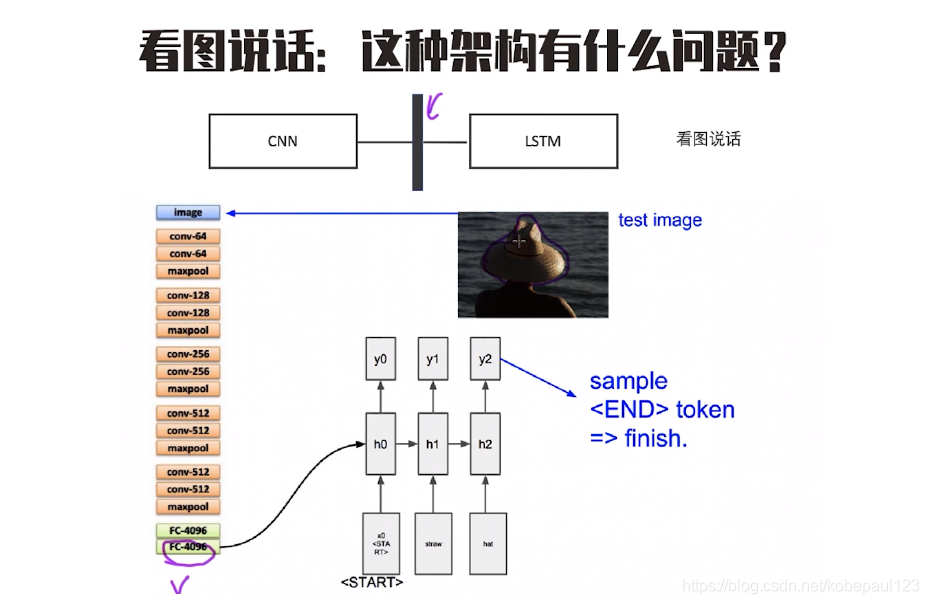
可以看到看圖說話時,生成的文本依賴于全部影像的詞向量,實際上并不需要這樣,因為每一個文本其實對應圖片的某一部分,
基于以上的問題,我們想把注意力機制加入到模型當中,對于看圖說話,一個核心思想:對于每一個生成的單詞實際上我們只需要關注圖片中某一個模塊就可以了,那這種注意力如何獲取的?一種簡單的操作方式是,把圖片分成多個區域,然后學出針對于每個區域的權重,
3.加入注意力機制

可以看到加入注意力機制后,還可以提升模型的解釋性,也就是說生成文本的時候能夠關注到其對應的影像區域是否正確,
三、序列模型中的注意力機制
seq2seq根據字面意思來看就是序列到序列,再具體點就是輸入一個序列(可以是一句話,一個圖片等)輸出另一個序列,的用途有很多,比如機器翻譯,寫詩,作曲,看圖寫文字等等用途很廣泛,
1.Seq2Seq的一些問題
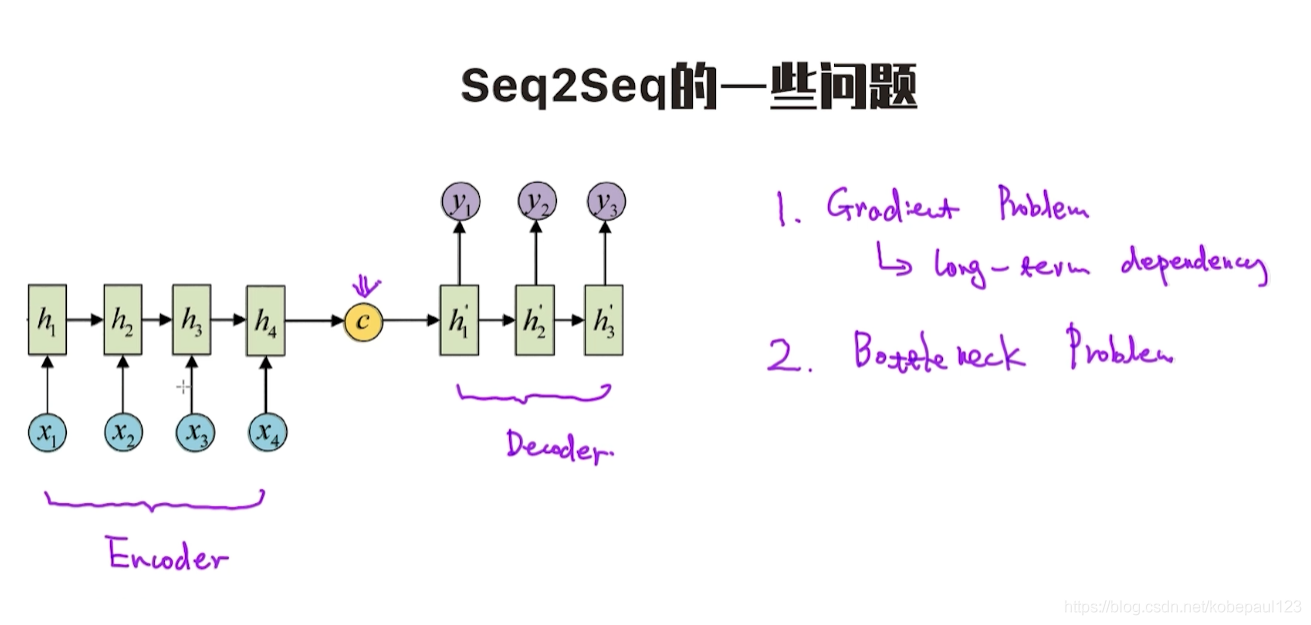
由上圖可知,雖然自然語言處理任務中引入了LSTM等一系列改進模型,但依然會因為長期依賴帶來梯度消失問題,而且由于編碼器最終學習生成一個向量,用這個向量來表示之前的一系列文本,這會使得該向量學習表示起來十分困難,
所以seq2seq存在以下兩個問題:
- 梯度消失問題,
- 瓶頸問題,
所以我們可以將注意力機制引入到seq2seq,
2.Seq2Seq加入注意力機制
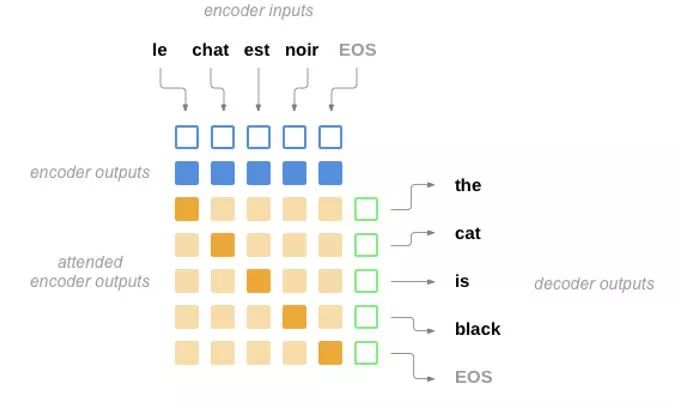
這些黃色的深淺代表當翻譯每個詞的注意力的分配,
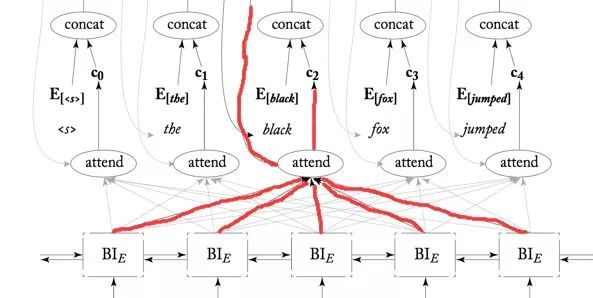
Encoder用的是是雙向RNN,當RNN單元回圈回來的時候都會有一個輸出給了你將要翻譯的詞對應的attend,而此時肯定是它的最下方的詞應該是注意力最集中的,所以它對應的權重肯定是最大的,
這里的權重分配公式為:
從最上面下來的是是第
個Encoder隱層出來的記憶單元,
所有的分打出來后,要做下歸一化:
這個跟Softmax差不多,
然后對他們進行求和傳送給:
這個注意力機制大大提高了機器翻譯的能力當然也包括其他的領域,
四、自注意力機制與Transformer
1.自注意力機制介紹
self attention是注意力機制中的一種,也是transformer中的重要組成部分,
自注意力機制是注意力機制的變體,其減少了對外部資訊的依賴,更擅長捕捉資料或特征的內部相關性,
自注意力機制在文本中的應用,主要是通過計算單詞間的互相影響,來解決長距離依賴問題,
自注意力機制的計算程序:
1.將輸入單詞轉化成嵌入向量;
2.根據嵌入向量得到q,k,v三個向量;
3.為每個向量計算一個score:score =q . k ;
4.為了梯度的穩定,Transformer使用了score歸一化,即除以 ;
5.對score施以softmax激活函式;
6.softmax點乘Value值v,得到加權的每個輸入向量的評分v;
7.相加之后得到最終的輸出結果z :z= v,
2. 自注意力機制細節
對于一段文本來講,自注意力機制可以計算每兩個單詞之間的關系,并根據這個關系來理解單詞在背景關系中的意思,通過上述可視化方式,我們也可以觀察到這種關系,另外,這種方式的一個缺點在于復雜度會比較高,特別是對于很長的文本,
3.位置編碼
在文本中,單詞之間是有順序的,但上面提到的self-attention并沒有把位置資訊考慮了進來,只是計算了每兩個單詞之間的關系,那我們又如何把位置資訊融合到模型當中呢?在Transformer中,我們在輸入端額外地加入了位置向量,
總結
注意力機制的優點
1.引數少:相比于 CNN、RNN ,其復雜度更小,引數也更少,所以對算力的要求也就更小,
2.速度快:Attention 解決了 RNN及其變體模型 不能并行計算的問題,Attention機制每一步計算不依賴于上一步的計算結果,因此可以和CNN一樣并行處理,
3.效果好:在Attention 機制引入之前,有一個問題大家一直很苦惱:長距離的資訊會被榷訓,就好像記憶能力弱的人,記不住過去的事情是一樣的,
本文是從零開始學NLP系列文章第十四篇,希望小伙伴們多多支持,互相交流,
參考:
貪心學院nlp
基于注意力機制的seq2seq網路
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/294391.html
標籤:AI