一、人工智能的發展
人工智能(Artificial Intelligence),重點在“智能”,既然是智能,那它具備判斷和分析的能力,它是由人創造并服務于人的一種技術,
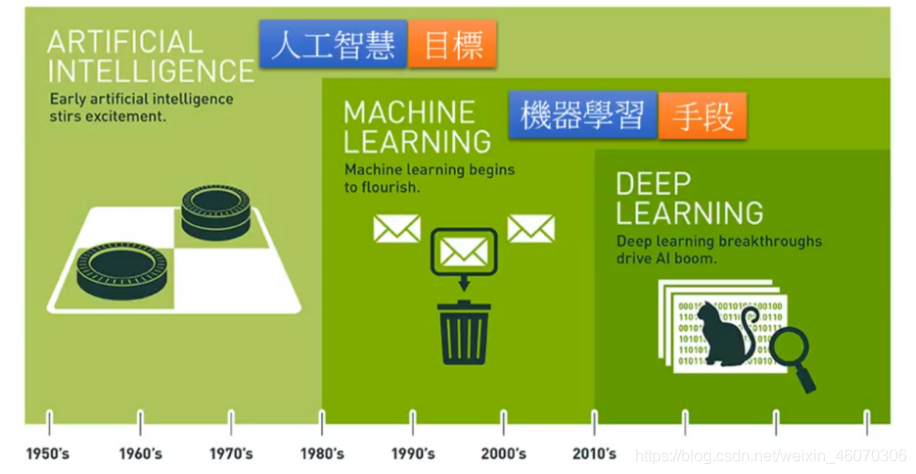 人工智能從1950年開始發展到今天,已經越漸成熟,我們可以將人工智能看作是最終的總目標,而機器學習則是實作這一目標的手段,我們可以通過機器學習這一個手段讓機器也變得跟人一樣有智慧,深度學習則是機器學習的一種方法,隨著算力的提升,GPU和TPU的運用,深度學習也得以發展,
人工智能從1950年開始發展到今天,已經越漸成熟,我們可以將人工智能看作是最終的總目標,而機器學習則是實作這一目標的手段,我們可以通過機器學習這一個手段讓機器也變得跟人一樣有智慧,深度學習則是機器學習的一種方法,隨著算力的提升,GPU和TPU的運用,深度學習也得以發展,
二、如何做到人工智能
1、機器智慧的來源
機器的智慧來源于兩個方面:先天的本能和通過后天學習的手段表現的很有智慧,先天的本能是由設計者一開始就將其設計好的,后天的學習是極其重要的,它會使得機器顯得更加智能和人性化,
 例如,當我們需要假設有一天你想要做一個chat-bot,我們不是用機器學習的方式,而是給他天生的本能的話,這樣就會變成社么樣子呢?
例如,當我們需要假設有一天你想要做一個chat-bot,我們不是用機器學習的方式,而是給他天生的本能的話,這樣就會變成社么樣子呢?
我們可能就會在這個chat-bot里面設定一些規則,這些規則我們通常稱hand-crafted rules,叫做人設定的規則,那假設你今天要設計一個機器人,他可以幫你打開或關掉音樂,那你的做法可能是這樣:設立一條規則,就是寫程式,如果輸入的句子里面看到“turn off”這個詞匯,那chat-bot要做的事情就是把音樂關掉,這個時候,你之后對chat-bot說,Please turn off the music 或can you turn off the music, Smart? 它就會幫你把音樂關掉,看起來好像很聰明,別人就會覺得果然這就是人工智慧,如果今天我們對它說please don‘t turn off the music,但是他還是會把音樂關掉,這種人工智能顯然不是我們想要的人工智能,

當然,我們在使用hand-crafted rules的時候,也會暴露出許多的弊端,我們是無法考慮到所有的可能性的,我們使用hand-crafted rules創造的機器都是只有先天的本能的,而不具備后天的學習能力,這種機器就只能在特定的場景里面做特定的事情,顯然并不能算的上是人工智能,
通過這兩個例子我們可以發現,先天的本能并非是非重要,極其關鍵的應該是后天機器的學習能力,只有賦予機器極強的學習能力,人工智能才有可能超過人類,成為真正意義上的人工智能,
2、Machine Learning
在機器學習中我們最主要的任務就是找到一個合適的function,通過我們給這個function一些input從而得到output,進而實作一些功能,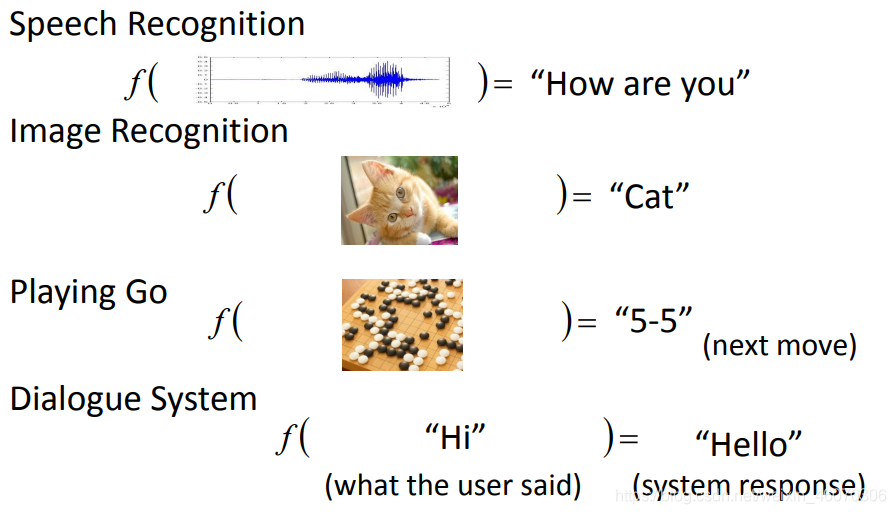
機器學習主要分成三個步驟:
1、找到一個函式集
2、寫出評價函式好壞的方程(這主要是用來訓練模型)
3、選擇一個最合適的方程
完成這三步將會是之后機器學習最重要的三個步驟,
三、機器學習的相關技術
1、Supervised Learning(監督學習)
supervised learning 需要大量的training data,這些training data告訴我們說,一個我們要找的function,它的input和output之間有什么樣的關系而這種function的output,通常被叫做label(標簽),也就是說,要使用supervised learning這樣?種技 術,我們需要告訴機器,function的input和output分別是什么,而這種output通常是通過?工的方式標注出來的,因此也被稱為人工標注的標簽(label),它的缺點是需要大量的人力勞動(effort)
Regression(回歸)
regression是machine learning的?個task,特點是通過regression找到的function,它的輸出是?個scalar數值,
比如PM2.5的預測,給machine的training data是過去的PM2.5資料,而輸出的是對未來PM2.5的預測數值,這就是一個典型的regression的問題,
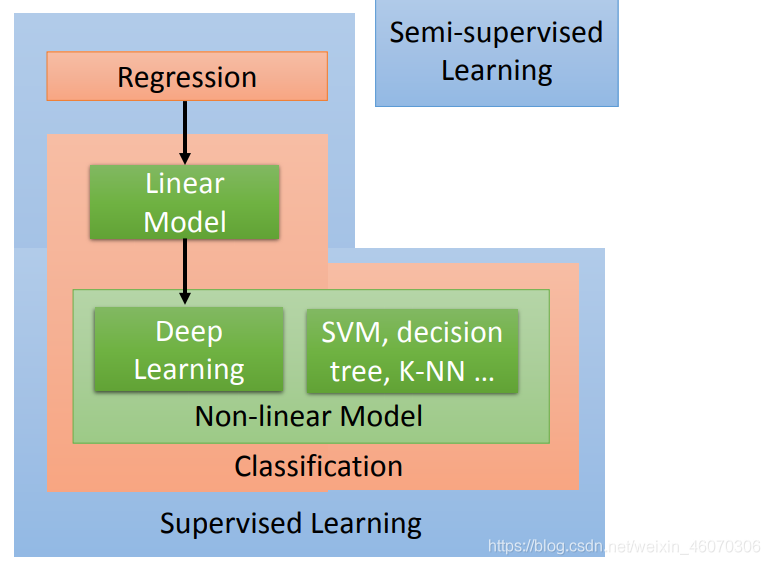
Classification(分類) regression和classification的區別是,我們要機器輸出的東西的型別是不?樣的,在regression里機器輸出的是scalar,
而classification又分為兩類:
Binary Classification(?元分類):在binary classification里,我們要機器輸出的是yes or no,
比如G-mail的spam filtering(垃圾郵件過濾器),輸?是郵件,輸出是該郵件是否是垃圾郵件,
Multi-class classification(多元分類):在multi-class classification?,機器要做的是選擇題,等于給他數個選項,每?個選項就是?個類別, 它要從數個類別??選擇正確的類別
比如document classification(新聞文章分類),輸?是一則新聞,輸出是這個新聞屬于哪?個類別(選項)
2、Semi-supervised Learning(半監督學習)
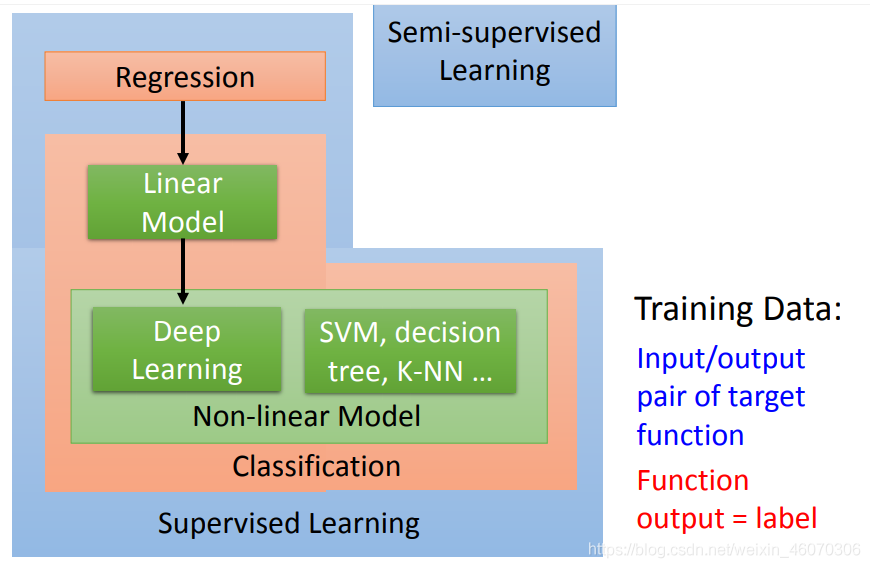 如果想要做一個區分貓和狗的function
如果想要做一個區分貓和狗的function
手頭上有少量的labeled data,它們標注了圖片上哪只是貓哪只是狗;同時又有大量的unlabeleddata,它們僅僅只有貓和狗的圖片,但沒有標注去告訴機器哪只是貓哪只是狗,在Semi-supervised Learning的技術里面,這些沒有labeled的data,對機器學習也是有幫助的,
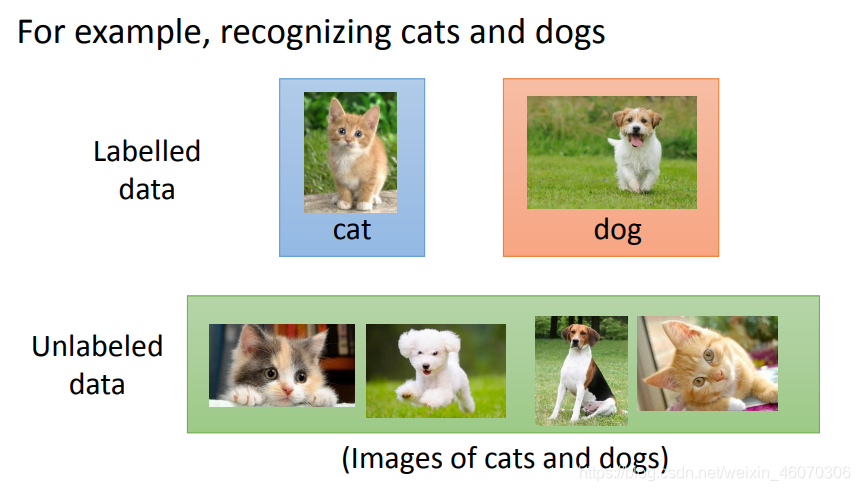
3、Transfer Learning(遷移學習)
假如,我們還是做做貓和狗的分類問題,我們也一樣只有少量的有labeled的data;但是我們現在有?量的不相干的data(不是貓和狗的圖片,而是一些其他不相干的圖片),在這些?量的data里面,它可能有label也可能沒label,
Transfer Learning要解決的問題是,這一堆不相干的data可以對結果帶來什么樣的幫助,在遷移學習中我們可以減少data的用量
4、Unsupervised Learning(無監督學習)
與監督學習不同的是:在無監督模型中,data全部沒有對應的label,我們給入模型大量的資料,讓機器去學習,機器學到什么就是什么,
假設我們今天帶機器去動物園讓它看一大堆的動物,它能不能夠在看了一大堆動物以后,它就學會自己創造一些動物,那這個都是真實體子,仔細看了大量的動物以后,它就可以自己的畫一些狗出來,有眼睛長在身上的狗、還有乳牛狗等等,

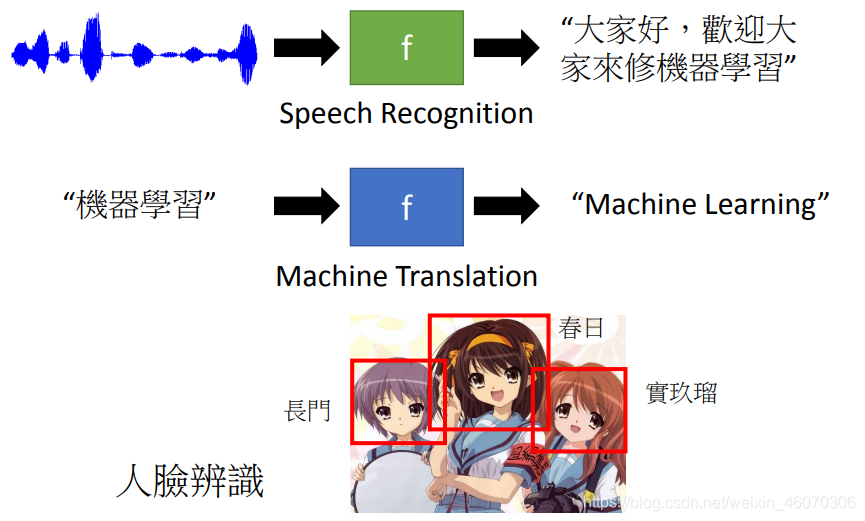
4、Structured Learning(結構化學習)
顧名思義,在structured Learning里,我們要機器輸出的是,一個有結構性的東西
舉例來說,在語?識別的情境下,機器的輸入是?個聲音信號,輸出是?個句子;句子是由許多詞匯拼湊而成,它是一個有結構性的object,或者說機器翻譯、人臉識別(標出不同的人的名稱)
5、Reinforcement Learning(強化學習)
在Supervised Learning中,我們會告訴機器正確的答案是什么 ,其特點Learning from teacher
比如訓練?個聊天機器?,告訴他如果使用者說了“Hello”,你就說“Hi”;如果使用者說了“Byebye”,你就說“Good bye”;就好像有?個家教在它的旁邊手把手地教他每?件事情
而在Reinforcement Learning中:我們沒有告訴機器正確的答案是什么,機器最終得到的只有一個分數,就 是它做的好還是不好,但他不知道自己到底哪里做的不好,他也沒有正確的答案;很像真實社會中的學習,你沒有一個正確的答案,你只知道自己是做得好還是不好,
比如訓練?個聊天機器人,讓它跟客人直接對話;如果客人勃然大怒把電話掛掉了,那機器就學到 一件事情,剛才做錯了,它不知道自己哪里做錯了,必須自己回去反省檢討到底要如何改進,比如 一開始不應該打招呼嗎?還是中間不能罵臟話之類的,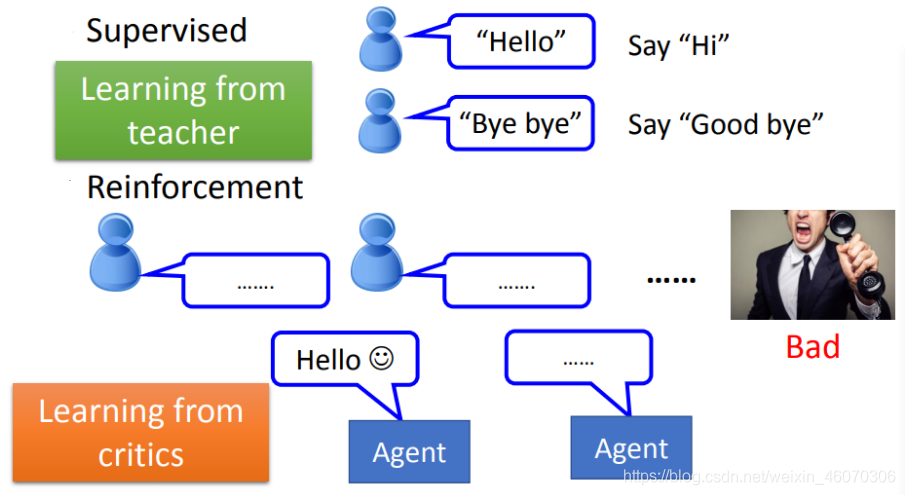
其實在很多人都熟知的Alpha Go中就是用supervisedLearning+reinforcement Learning的方式去學習的,機器先是從棋譜學習,有棋譜就可以做supervised的學習;之后再做reinforcement Learning,機器的對手是另外一臺機器,Alpha Go就是和自己下棋,然后不斷的進步,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/294393.html
標籤:AI