此文章僅代表個人簡介,根據個人親身經歷感受所得,希望給更多同行參考,入行有風險,且行且珍惜,哈哈哈,開個玩笑,
很多人都知道我們這個行業近些年都比較賺錢,工資相對較高,我只能說你們并沒有看見我們的付出、努力和艱辛,各行各業都是這樣,我相信,
作為一個多年經驗的資深程式猿,自14年實習開始就進入該行業,從一名程式小白開始,最早做java開發,一步一步,做到中級,再到高級,終于有一天,我發現整天搞這些一點意思都沒有,每天還得不斷對自己進行技術更新,學習、底層原理、原始碼剖析等等,窩內個天呀,快結束我吧,沒意思、太沒意思了;就這樣我自己想著轉變,剛好大環境下,大資料逐漸成熟,國內需求越來越多,往大資料方向靠靠吧(PS:其實工資誘人 ),就這樣我就考慮,我是自學?從公司轉型(遺憾,當時公司沒有大資料需求)?找個培訓班學習?在自己萬般糾結中,我毅然決然的選擇了裸辭去找家培訓機構學習,我現在想來,我也挺佩服我自己的,不過還好,我有個對我從來都是無條件支持的偉大母親,她信我,這也算是我的一大動力吧,在此,借助這篇文章,默默的對我的母親表達感謝,直到如今,她都一直對我的決定非常的支持,就這樣,我努力學習完六個月,出去找作業,確實,很順利,薪資也大幅度增長,這些年做大資料,同樣我遇到很多問題,各種瓶勁,我不知道為什么,我有一次陷入了盲目,不知道方向在哪,大資料技術很多,我不停的學,不停的報班,不停的總結,不停的看各種書籍、博客、公眾號,我突然感覺我好無知,我簡直是個垃圾,我不知道該怎么辦?我連總結自己的勇氣都沒有了,我明明很努力了,可為什么還是會這樣?
終于我忍不住和我母親溝通交流,母親是位教師,他很懂我,也很會勸導我(細節就不細說了,道理大家都懂),終于我決定重新認識自己,對我自己的經歷做出總結,
- 我覺得我雖然是在做大資料,但是都太過于淺顯,并沒有好的經歷,好的專案,總結起來真正的經驗不足,
- 認知不夠,因為專案局限性,很多公司都是簡單淺顯做一些基礎數倉,簡單計算一些指標就可以了,所以自己認知停留,在大資料體系上面認知不夠,比如:怎么做一個全域數倉?怎么構建指標體系?怎么做資料治理?怎么做資料管理?怎么做資料平臺?怎么做資料中臺?等等,,
- 很多時候,需要停下腳步,鞏固復習,貪多嚼不爛,找準一個方向,一個內容抓實學,必有成長,
就在這個時候,說來也很巧合,抓住自己的弱勢,好的專案經驗不足,不能充分體現大資料場景以及優勢和作用,我被一個培訓的大資料內容所吸引(我自己是做大資料的,仿佛自己被大資料殺熟了 ),同時我也第一次感覺大資料殺熟也挺不錯的,為什么呢?這個其實就是拉鉤教育的大資料高薪訓練營,我為什么著重說下這個呢,其實真正吸引我的是他們的幾個專案,循序漸進,而且做到了真正的大專案,也非常全面,
-
真正達到了PB級,這個是我們在做很多大資料專案中遇不到的,這也是我現在的窘迫,從來沒有遇到過那個公司哪個專案達到PB級別,沒有真正的大資料,很多場景、問題是遇不到的,解決問題的局限性就來了,
-
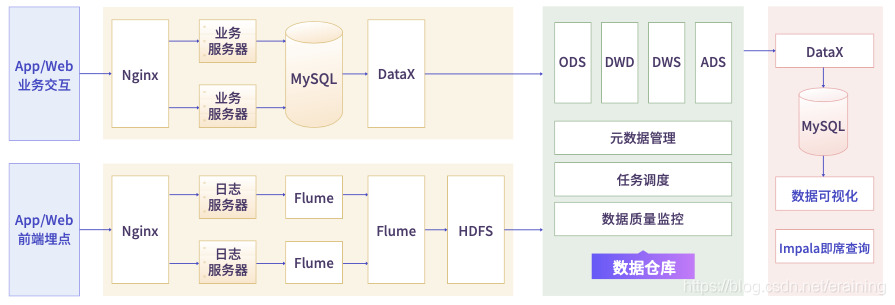
專案全面,我仔細看了專案簡介,而且我當時報班時也很猶豫害怕,怕專案深度不夠,專門還咨詢了授課講師,期間我們也交流了很多,中肯的建議很受用,就拿第一個離線數倉來說,數量級別達到PB級,而且滿足現在市場定位,很全面,不簡簡單單就只是數倉相關的內容,除了指標體系、資料建模、資料計算等之外的還有埋點資料采集、元資料管理、資料質量監控、即席查詢等,這個是很多培訓機構做不到的,我真的很喜歡這個,話不多少,沒圖說個**
-
專案種類多,而且很多企業都遇不到的,智慧物流大資料專案、企業級電商實時數倉專案、人才職位畫像匹配推薦,專案種類很全,而且循序漸進的進行,保證了質量
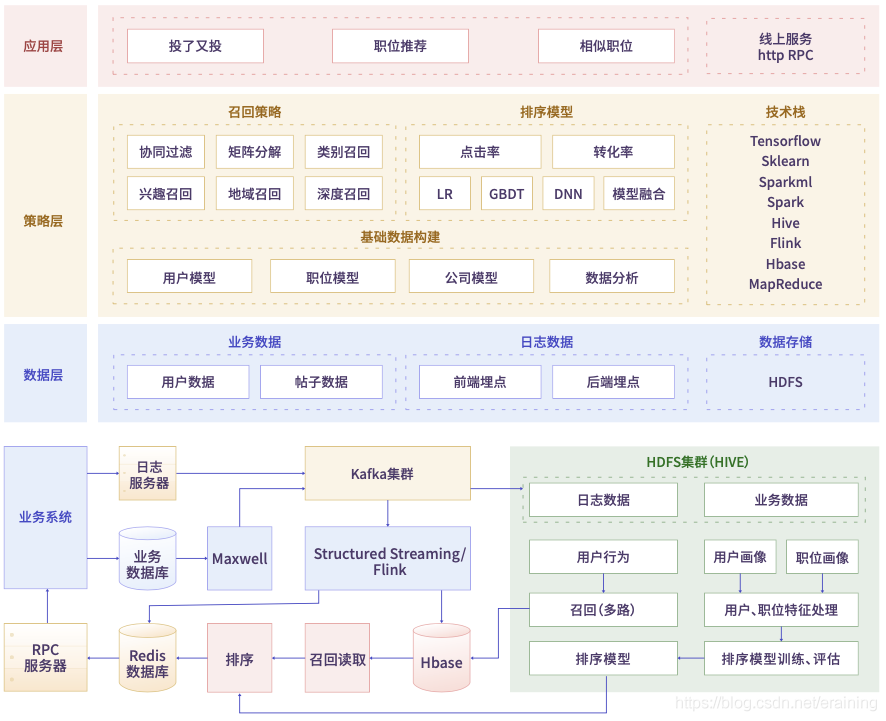
看到了沒,做了這么多年大資料,我真的沒實際做過這樣好的大型專案(慚愧慚愧),就像和別人說的,我只是缺乏一個機會,前提是你要時刻做好準備,可以有勝任這個機會的能力,
我通過多方咨詢、考察、調研,終于做下決定,一個字,“干”就完了;其實我報了很多學習班,真的,因為我總感覺我欠缺太多,我需要不斷補充自己,現在想想,其實不用,找好一個學習機會,扎實去學,調研清楚就行,所以通過我個人推薦,這個高薪訓練營真的很不錯,為啥?你肯定覺得我是臥底,I swear! 我不是,我很中肯的評價,這個為什么好:
- 學習循序漸進,課時是解鎖模式,沒個課時分為很多節,中間又分了小結作業,用于自測,然后,課時完成會有課時作業,提交后,老師批改,學完一個課時才會解鎖下一個課時,我覺得這樣很有必要,貪多嚼不爛,就像我上面說的,一步一步的走,每個步驟夯實自己,樓才能蓋的更高,雖然前面基礎很多我都會,但是我還是按耐著自己的性子,一點點學習,我覺得查缺補漏真的很好,很多以前沒注意或者不知道的都被填補了,
- 資料齊全,我覺得這個很重要,有時候我們自己搭建什么集群啥的,有點經驗完全自己可以勝任,搭建一次能知道很多為什么,資料寫的也很全面,這么有什么問題,不這樣做又會遇到什么問題,可以解決很多實際問題,
- 每個課時自己學完,會有直播的方式,老師帶著大家一起溫故知新,并且拓展知識面,
- 市面上使用的技術堆疊,訓練營都會有講解,而且非常詳細,最關鍵的是關聯專案,有實踐的經驗,
- 筆記,這個真的是,不用說,很重要,像我們大資料技術堆疊這么多,學習的內容實在是無法用語言表達(高薪-存在即合理),每次提交課時作業時,都會附上自己的學習筆記鏈接,講師會核查糾正,
- 大廠內推的機會,國內屈指可數的一流招聘網站,給你開玩笑呢?為啥要進大廠,還不是工資高?其實也不全是,在我看來,更多的是因為大廠有實力和機會做大專案,對于我們研發人員來說成長很大,
說實話,我挺感謝有這樣的經歷,讓我知道我需要什么,我的目標是什么,也祝愿大家可以找到自己滿意的作業, - 講師基本都是大廠出來的,很多都是大廠在職的,身經百戰,經驗豐富,說不定看中你,直接給你拉進大廠了,哈哈哈
- 還有很多輔助你學習的老師、班主任等,除了學習,其它需要幫助的都隨時幫助您
因為我才剛學不久(為什么不早點讓我遇到這個學習機會 ),附一篇我的學習筆記,大家可以參考:
Hadoop學習筆記
1. MapReduce
Reduce端join缺點:
- 資料聚合功能在reduce端完成,reduce端并行度一般不高,所以執行效率存在隱患
- 相同key的資料去往同一個磁區,如果資料本身存在不平衡,會造成資料傾斜
join的操作是在reduce階段完成,reduce端的處理壓力太大,map節點的運算負載 則很低,資源利用率不高,且在reduce階段極易產生資料傾斜,
解決方案:map端join實作方式
Map端join:
- 適用于關聯表中有小表的情形;
- 避免了reduce端資料傾斜的問題
可以將小表分發到所有的map節點,這樣,map節點就可以在本地對自己所讀到的大表資料進行join并輸出最終結果,可以大大提高join操作的并行度,加快處理速度
mr程式中有大量小檔案如何處理:
- 使用combineInputformat,跳出原先TextInputformat的切片邏輯(一個檔案切一個分片,一個分片對應一個mapTask,也就是一個小檔案對應一個MapTask),使用combineInputformat,可以將多個小檔案合并成一個邏輯分片,由一個mapTask來完成,可以解決mapreduce中一個小檔案對應一個mapTask造成資源浪費的問題,這個只是解決在mapreduce層面的問題,但是,這些資料存盤到HDFS上,對于NameNode來說,記憶體依然存在浪費,
- 自定義InputFormat合并成一個大檔案,可以解決NameNode記憶體浪費的情況,
MR演算法之MergeSort歸并排序:
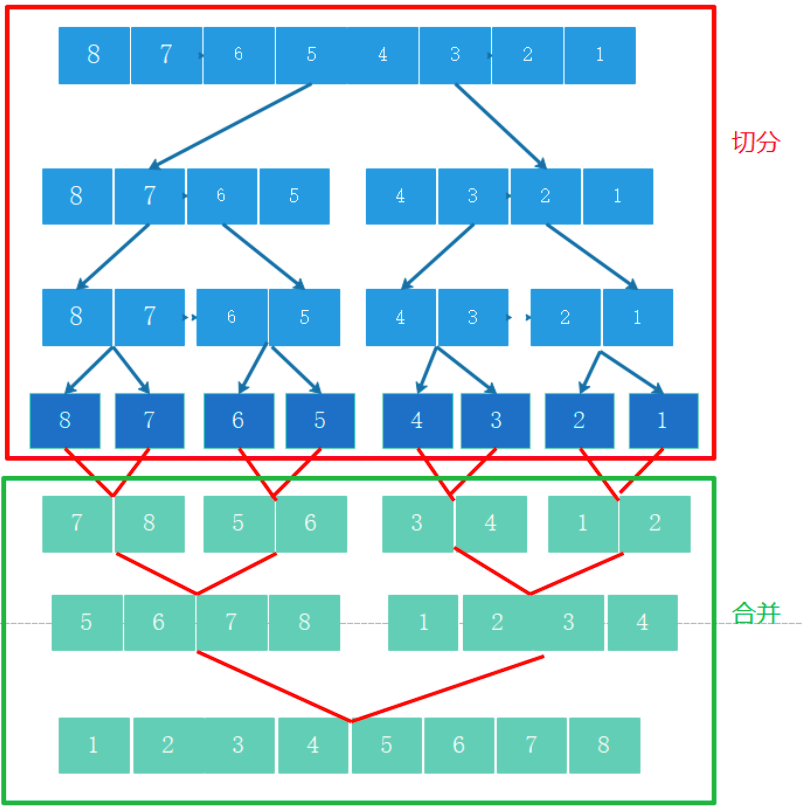
合并
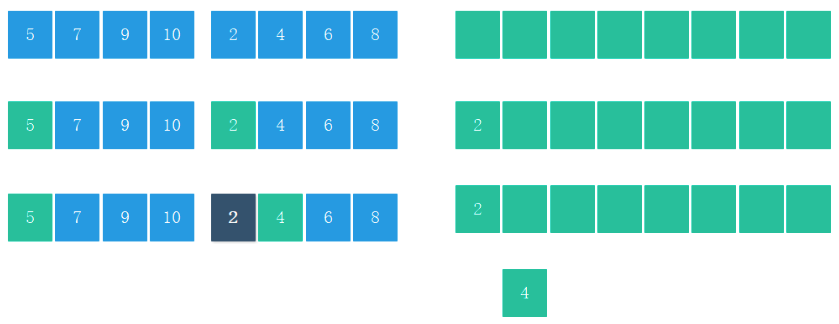
合并細節(降低空間復雜度)
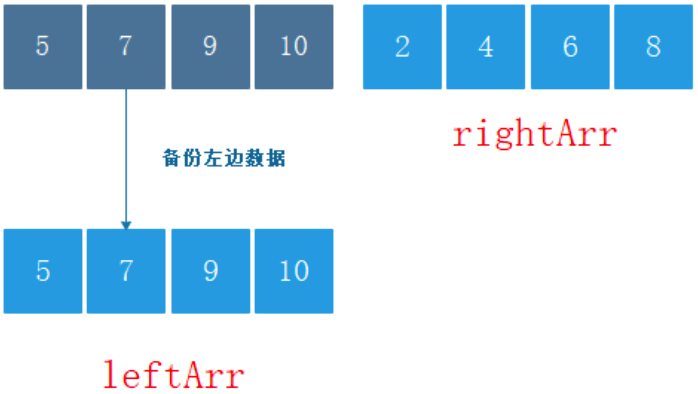
- 不斷地將當前序列平均分割成 2個子序列 直到不能再分割(序列中只剩 1個元素)
- 不斷地將 2個子序列合并成一個有序序列 直到最終只剩下 1個子序列
時間復雜度:O(nlogn)
空間復雜度:O(n)
QuickSort - 快排
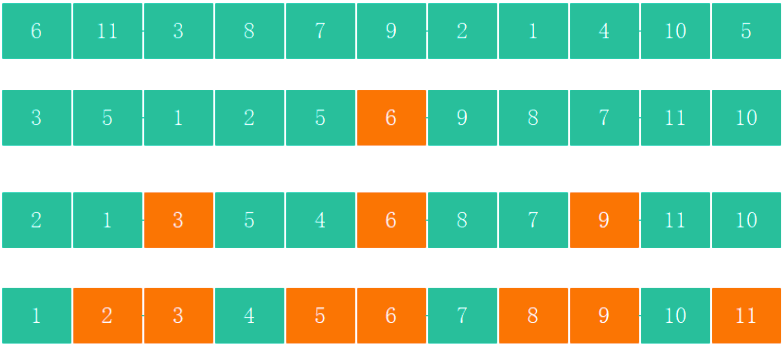
-
第一步
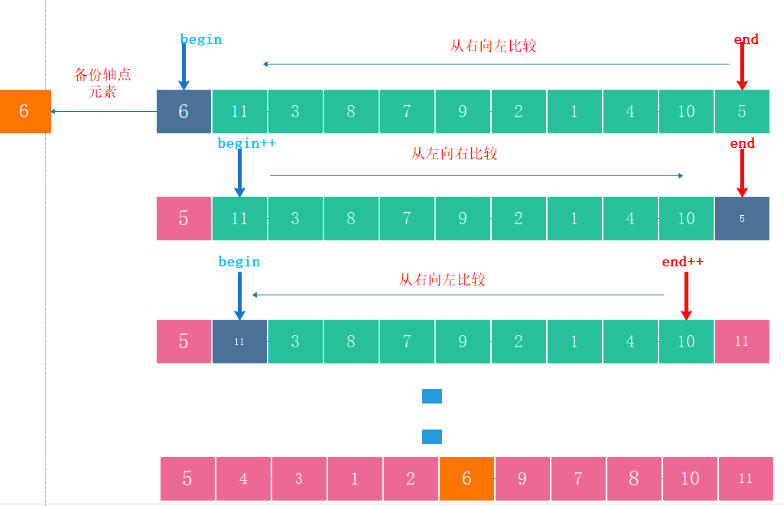
從陣列中選擇一個軸點元素(Pivot element),一般選擇0位置元素為軸點元素 -
第二步
- 利用Pivot將陣列分割成2個子序列
- 將小于 Pivot的元素放在Pivot前面(左側) 、 將大于 Pivot的元素放在Pivot后面(右側) 、 等于Pivot的元素放哪邊都可以(暫定放在左邊)
-
第三步
- 對子陣列進行第一步,第二步操作,直到不能再分割(子陣列中只有一個元素)
-
時間復雜度
- 最壞情況:
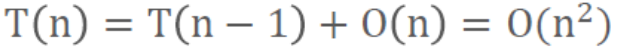
- 最好情況:
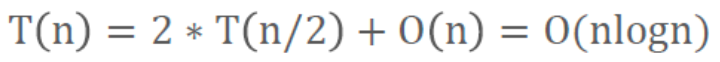
- 最壞情況:
-
空間復雜度
- 由于遞回呼叫,每次類似折半效果所以空間復雜度是O(logn)
2. Yarn資源調度
Yarn架構
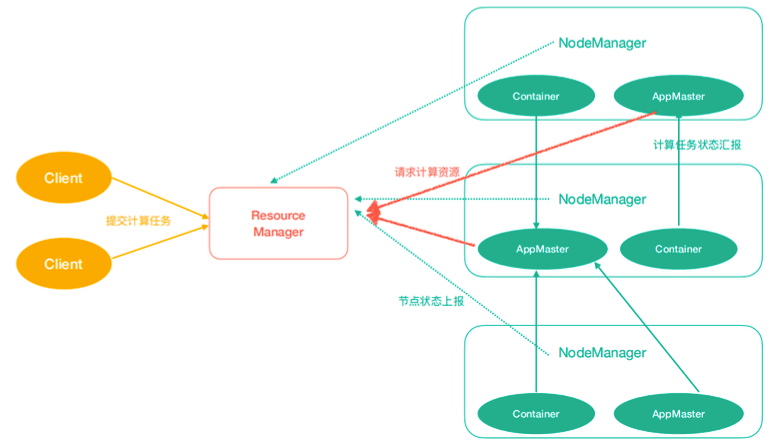
ResourceManager(rm):處理客戶端請求、啟動/監控ApplicationMaster、監控NodeManager、資源分配與調度;
NodeManager(nm):單個節點上的資源管理、處理來自ResourceManager的命令、處理來自 ApplicationMaster的命令;
ApplicationMaster(am):資料切分、為應用程式申請資源,并分配給內部任務、任務監控與容錯, Container:對任務運行環境的抽象,封裝了CPU、記憶體等多維資源以及環境變數、啟動命令等任務運行相關的資訊,
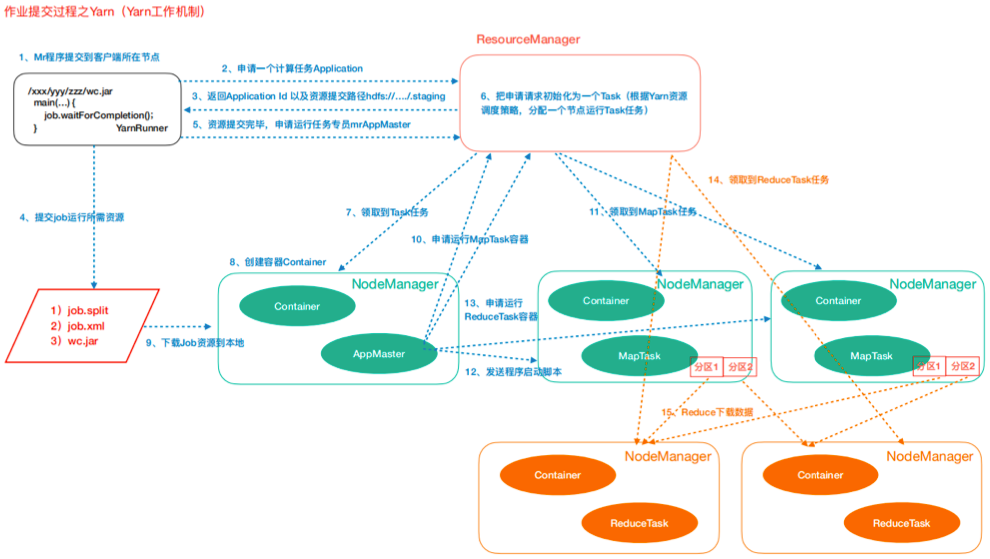
Yarn任務提交(作業機制)
3. Yarn調度策略
FIFO Scheduler
先進先出調度器,按照任務到達時間排序,執行任務
Capacity Scheduler
Apache Hadoop默認調度器
允許多個組織共享整個集群,每個組織獲得集群部分計算能力,通過為每個組織分配專門的佇列,然后再為每個佇列分配一定的集群資源,這樣整個集群就可以通過設定多個佇列的方式給多個組織提供服務,佇列內部又可以垂直劃分,這樣一個組織內部的多個成員就可以共享這個佇列資源,在一個佇列內部資源的調度是采用FIFO策略,

Fair Scheduler
公平調度器,CHD版本的Hadoop默認使用的調度器
設計目標是為所有應用分配公平的資源(公平的定義可通過引數設定),公平調度也可以在多個佇列間作業,
舉個🌰:
假設有兩個用戶A和B,他們分別擁有一個佇列, 當A啟動一個job而B沒有任務時,A會獲得全部集群資源;當B啟動一個job后,A的job會繼續運 行,不過一會兒之后兩個任務會各自獲得一半的集群資源,如果此時B再啟動第二個job并且其它job還在運行,則它將會和B的第一個job共享B這個佇列的資源,也就是B的兩個job會用于四分之一的集群資源,而A的job仍然用于集群一半的資源,結果就是資源最終在兩個用戶之間平等的共享,
4. Yarn多租戶資源隔離配置
Yarn集群資源設定為A,B兩個佇列,
- A佇列設定占用資源70%主要用來運行常規的定時任務,
- B佇列設定占用資源30%主要運行臨時任務,
- 兩個佇列間可相互資源共享,假如A佇列資源占滿,B佇列資源比較充裕,A佇列可以使用B佇列的資源,使總體做到資源利用最大化.
選擇使用Fair Scheduler調度策略!!
具體配置:
1、 yarn-site.xml
<!-- 指定我們的任務調度使用fairScheduler的調度方式 -->
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
<description>In case you do not want to use the default scheduler</description>
</property>
2、創建fair-scheduler.xml檔案
在Hadoop安裝目錄下的/etc/hadoop創建
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<allocations>
<defaultQueueSchedulingPolicy>fair</defaultQueueSchedulingPolicy>
<queue name="root" >
<queue name="default">
<aclAdministerApps>*</aclAdministerApps>
<aclSubmitApps>*</aclSubmitApps>
<maxResources>9216 mb,4 vcores</maxResources>
<maxRunningApps>100</maxRunningApps>
<minResources>1024 mb,1vcores</minResources>
<minSharePreemptionTimeout>1000</minSharePreemptionTimeout>
<schedulingPolicy>fair</schedulingPolicy>
<weight>7</weight>
</queue>
<queue name="queue1">
<aclAdministerApps>*</aclAdministerApps>
<aclSubmitApps>*</aclSubmitApps>
<maxResources>4096 mb,4vcores</maxResources>
<maxRunningApps>5</maxRunningApps>
<minResources>1024 mb, 1vcores</minResources>
<minSharePreemptionTimeout>1000</minSharePreemptionTimeout>
<schedulingPolicy>fair</schedulingPolicy>
<weight>3</weight>
</queue>
</queue>
<queuePlacementPolicy>
<rule create="false" name="specified"/>
<rule create="true" name="default"/>
</queuePlacementPolicy>
</allocations>
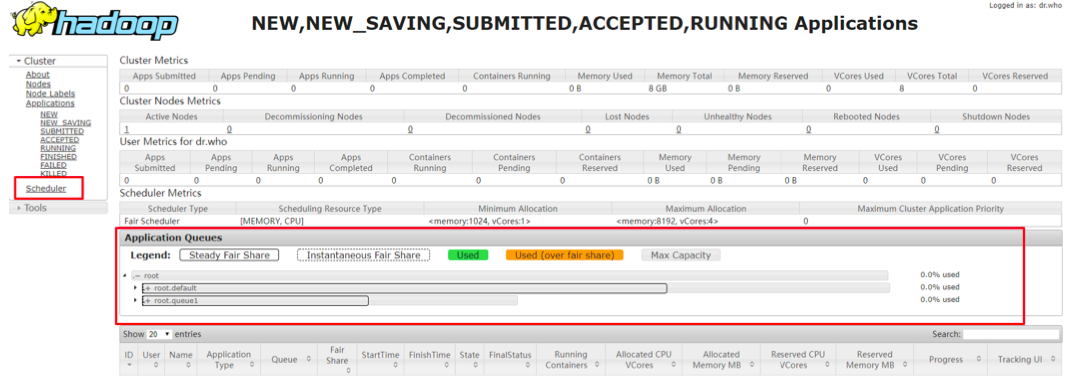
重啟yarn,從界面可以看到
5. MR調優
5.1 Job執行三原則
原則一 充分利用集群資源
Job運行時,盡量讓所有的節點都有任務處理,這樣能盡量保證集群資源被充分利用,任務的并發度達到最大,可以通過調整處理的資料量大小,以及調整map和reduce個數來實作,
- Reduce個數的控制使用“mapreduce.job.reduces”
- Map個數取決于使用了哪種InputFormat,默認的TextFileInputFormat將根據block的個數來分配map數(一個block一個map),
原則二 ReduceTask并發調整
努力避免出現以下場景
- 觀察Job如果大多數ReduceTask在第一輪運行完后,剩下很少甚至一個ReduceTask剛開始運行, 這種情況下,這個ReduceTask的執行時間將決定了該job的運行時間,可以考慮將reduce個數減少,
- 觀察Job的執行情況如果是MapTask運行完成后,只有個別節點有ReduceTask在運行,這時候集 群資源沒有得到充分利用,需要增加Reduce的并行度以便每個節點都有任務處理,
原則三 Task執行時間要合理
一個job中,每個MapTask或ReduceTask的執行時間只有幾秒鐘,這就意味著這個job的大部分時間 都消耗在task的調度和行程啟停上了,因此可以考慮增加每個task處理的資料大小,建議一個task處理時間為1分鐘,
5.2 shuffle調優
Shuffle階段是MapReduce性能的關鍵部分,包括了從MapTaskask將中間資料寫到磁盤一直到ReduceTask拷貝資料并最終放到Reduce函式的全部程序,這一塊Hadoop提供了大量的調優引數,
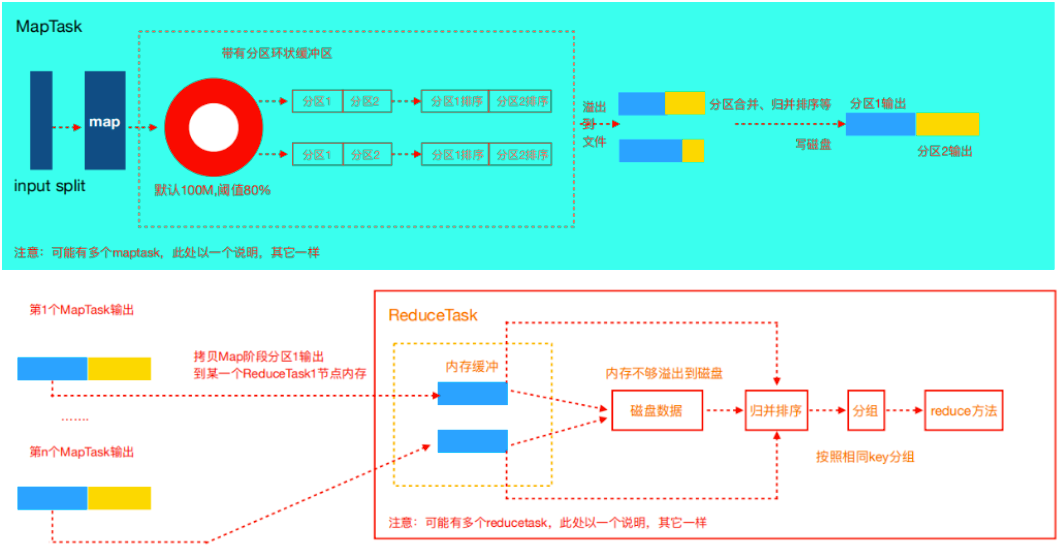
Map階段
1. 判斷Map記憶體使用
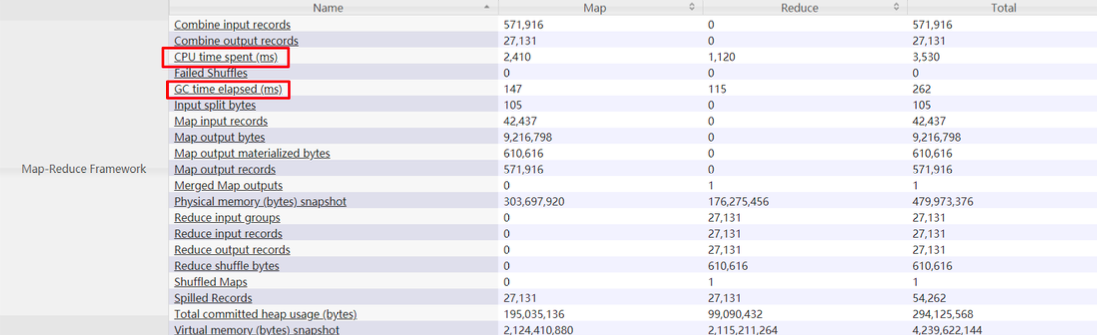
判斷Map分配的記憶體是否夠用,可以查看運行完成的job的Counters中(歷史服務器),對應的task是 否發生過多次GC,以及GC時間占總task運行時間之比,通常,GC時間不應超過task運行時間的10%, 即GC time elapsed (ms)/CPU time spent (ms)<10%,
Map需要的記憶體還需要隨著環形緩沖區的調大而對應調整,可以通過如下引數進行調整,
mapreduce.map.memory.mb
Map需要的CPU核數可以通過如下引數調整
mapreduce.map.cpu.vcores
記憶體默認是1G,CPU默認是1核,
如果集群資源充足建議調整:
mapreduce.map.memory.mb=3G(默認1G) mapreduce.map.cpu.vcores=1(默認也是1)
- 環形緩沖區: Map方法執行后首先把資料寫入環形緩沖區,為什么MR框架選擇先寫記憶體而不是直接寫磁盤?這 樣的目的主要是為了減少磁盤i/o
- 環形緩沖默認100M(mapreduce.task.io.sort.mb),當到達80% (mapreduce.map.sort.spill.percent)時就會溢寫磁盤,
- 每達到80%都會重寫溢寫到一個新的檔案
當集群記憶體資源充足,考慮增大mapreduce.task.io.sort.mb提高溢寫的效率,而且會減少中間結 果的檔案數量,
建議:
- 調整mapreduce.task.io.sort.mb=512M,
- 當檔案溢寫完后,會對這些檔案進行合并,默認每次合并 10(mapreduce.task.io.sort.factor)個溢寫的檔案,建議調整 mapreduce.task.io.sort.factor=64,這樣可以提高合并的并行度,減少合并的次數,降低對磁盤操作的次數,
2. Combiner
在Map階段,有一個可選程序,將同一個key值的中間結果合并,叫做Combiner,(一般將reduce類
設定為combiner即可) 通過Combine,一般情況下可以顯著減少Map輸出的中間結果,從而減少shuffle程序的網路帶寬占用,
建議: 不影響最終結果的情況下,加上Combiner!!
Copy階段
- 對Map的中間結果進行壓縮,當資料量大時,會顯著減少網路傳輸的資料量
- 但是也因為多了壓縮和解壓,帶來了更多的CPU消耗,因此需要做好權衡,當任務屬于網路瓶頸型別時,壓縮Map中間結果效果明顯,
- 在實際經驗中Hadoop的運行的瓶頸一般都是IO而不是CPU,壓縮一般可以10倍的減少IO操作
Reduce階段
1、Reduce資
mapreduce.reduce.memory.mb=5G(默認1G)
mapreduce.reduce.cpu.vcores=1(默認為1),
2、Copy
ReduceTask在copy的程序中默認使用5(mapreduce.reduce.shuffle.parallelcopies引數控制)個
并行度進行復制資料,
該值在實際服務器上比較小,建議調整為50-100.
3、溢寫歸并
Copy過來的資料會先放入記憶體緩沖區中,然后當使用記憶體達到一定量的時候spill磁盤,這里的緩沖區 大小要比map端的更為靈活,它基于JVM的heap size設定,這個記憶體大小的控制是通過mapreduce.reduce.shuffle.input.buffer.percent(default 0.7)控制的,
shuffile在reduce記憶體中的資料最多使用記憶體量為:0.7 × maxHeap of reduce task,記憶體到磁盤 merge的啟動可以通過mapreduce.reduce.shuffle.merge.percent(default0.66)配置,
copy完成后,reduce進入歸并排序階段,合并因子默認為10(mapreduce.task.io.sort.factor引數 控制),如果map輸出很多,則需要合并很多趟,所以可以提高此引數來減少合并次數,
mapreduce.reduce.shuffle.parallelcopies #復制資料的并行度,默認5;建議調整為50-100 mapreduce.task.io.sort.factor #一次合并檔案個數,默認10,建議調整為64 mapreduce.reduce.shuffle.input.buffer.percent #在shuffle的復制階段,分配給Reduce輸出 緩沖區占堆記憶體的百分比,默認0.7
mapreduce.reduce.shuffle.merge.percent #Reduce輸出緩沖區的閾值,用于啟動合并輸出和磁盤 溢寫的程序
5.3 Job調優
1、推測執行
集群規模很大時(幾百上千臺節點的集群),個別機器出現軟硬體故障的概率就變大了,并且會因此 延長整個任務的執行時間推測執行通過將一個task分給多臺機器跑,取先運行完的那個,會很好的解決 這個問題,對于小集群,可以將這個功能關閉,

建議:
- 大型集群建議開啟,小集群建議關閉!
- 集群的推測執行都是關閉的,在需要推測執行的作業執行的時候開啟
2、Slow Start
MapReduce的AM在申請資源的時候,會一次性申請所有的Map資源,延后申請reduce的資源,這樣就能達到先執行完大部分Map再執行Reduce的目的,
mapreduce.job.reduce.slowstart.completedmaps
當多少占比的Map執行完后開始執行Reduce,默認5%的Map跑完后開始起Reduce, 如果想要Map完全結束后執行Reduce調整該值為1
3、小檔案優化
- HDFS:hadoop的存盤每個檔案都會在NameNode上記錄元資料,如果同樣大小的檔案,檔案很 小的話,就會產生很多檔案,造成NameNode的壓力,
- MR:Mapreduce中一個map默認處理一個分片或者一個小檔案,如果map的啟動時間都比資料處理的時間還要長,那么就會造成性能低,而且在map端溢寫磁盤的時候每一個map最侄訓產生 reduce數量個數的中間結果,如果map數量特別多,就會造成臨時檔案很多,而且在reduce拉取資料的時候增加磁盤的IO,
如何處理小檔案?
- 從源頭解決,盡量在HDFS上不存盤小檔案,也就是資料上傳HDFS的時候就合并小檔案
- 通過運行MR程式合并HDFS上已經存在的小檔案
- MR計算的時候可以使用CombineTextInputFormat來降低MapTask并行度
4、資料傾斜
MR是一個并行處理的任務,整個Job花費的時間是作業中所有Task最慢的那個了, 為什么會這樣呢?為什么會有的Task快有的Task慢?
- 資料傾斜,每個Reduce處理的資料量不是同一個級別的,所有資料量少的Task已經跑完了,資料量大的Task則需要更多時間,
- 有可能就是某些作業所在的NodeManager有問題或者container有問題,導致作業執行緩慢,
那么為什么會產生資料傾斜呢?
資料本身就不平衡,所以在默認的hashpartition時造成磁區資料不一致問題;那如何解決資料傾斜的問題呢?
- 默認的是hash演算法進行磁區,我們可以嘗試自定義磁區,修改磁區實作邏輯,結合業務特點,使得每個磁區資料基本平衡
- 可以嘗試修改磁區的鍵,讓其符合hash磁區,并且使得最后的磁區平衡,比如在key前加亂數n- key,
- 抽取導致傾斜的key對應的資料單獨處理,
如果不是資料傾斜帶來的問題,而是節點服務有問題造成某些map和reduce執行緩慢呢?
使用推測執行找個其他的節點重啟一樣的任務競爭,誰快誰為準,推測執行時以空間換時間的優化,
會帶來集群資源的浪費,會給集群增加壓力,
5.4 YARN調優
1、NM配置
- 可用記憶體
刨除分配給作業系統、其他服務的記憶體外,剩余的資源應盡量分配給YARN,
默認情況下,Map或Reduce container會使用1個虛擬CPU內核和1024MB記憶體, ApplicationMaster使用1536MB記憶體,
yarn.nodemanager.resource.memory-mb 默認是8192
-
CPU虛擬核數
建議將此配置設定在邏輯核數的1.5~2倍之間,如果CPU的計算能力要求不高,可以配置為2倍的邏輯CPU,yarn.nodemanager.resource.cpu-vcores
該節點上YARN可使用的虛擬CPU個數,默認是8,
目前推薦將該值設值為邏輯CPU核數的1.5~2倍之間
2、Container啟動模式
YARN的NodeManager提供2種Container的啟動模式,
默認,YARN為每一個Container啟動一個JVM,JVM行程間不能實作資源共享,導致資源本地化的時間開銷較大,針對啟動時間較長的問題,新增了基于執行緒資源本地化啟動模式,能夠有效提升container啟動效率,
yarn.nodemanager.container-executor.class
- 設定為“org.apache.hadoop.yarn.server.nodemanager.DefaultContainerExecutor”,則每次啟 動container將會啟動一個執行緒來實作資源本地化,
該模式下,啟動時間較短,但無法做到資源(CPU、記憶體)隔離, - 設定為“org.apache.hadoop.yarn.server.nodemanager.LinuxContainerExecutor” ,則每次啟動container都會啟動一個JVM行程來實作資源本地化,
該模式下,啟動時間較長,但可以提供較好的資源(CPU、記憶體)隔離能力,
3、AM調優
運行的一個大任務,map總數達到了上萬的規模,任務失敗,發現是ApplicationMaster(以下簡稱AM)反應緩慢,最終超時失敗, 失敗原因是Task數量變多時,AM管理的物件也線性增長,因此就需要更多的記憶體來管理,AM默認分配的記憶體大小是1.5GB,
建議: 任務數量多時增大AM記憶體
yarn.app.mapreduce.am.resource.mb
5.5 Namenode Full GC
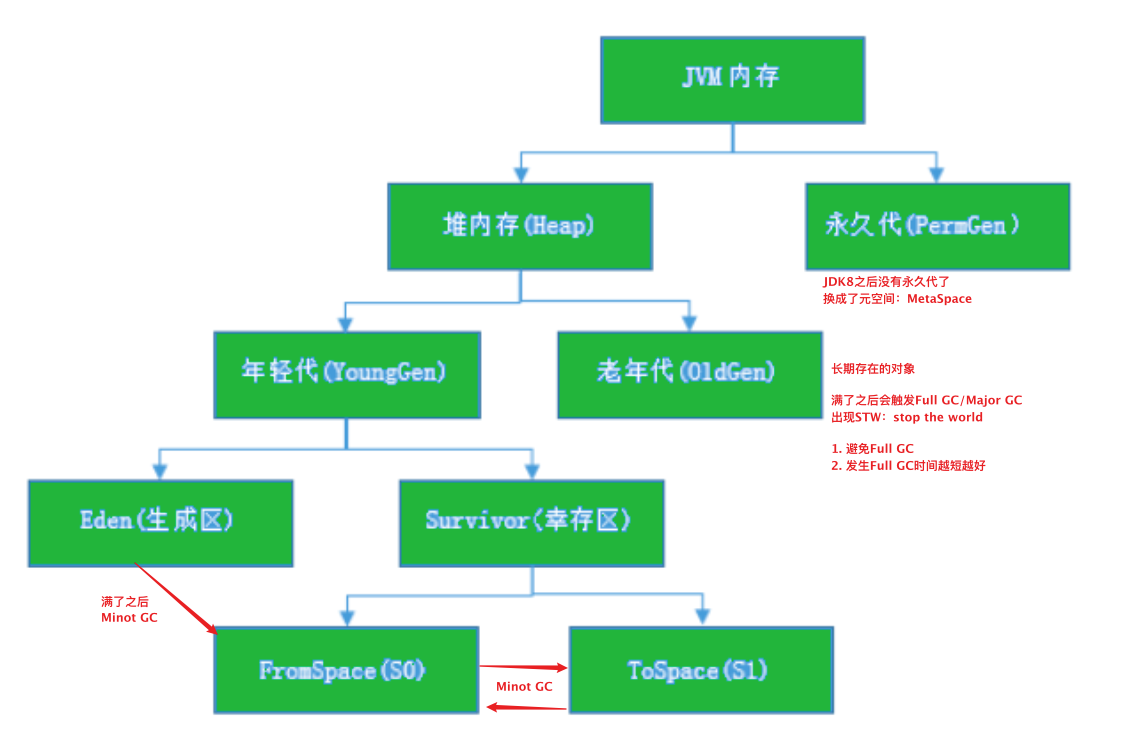
JVM堆記憶體
-
JVM記憶體劃分為堆記憶體和非堆記憶體,堆記憶體分為年輕代(Young Generation)、老年代(Old Generation),非堆記憶體就一個永久代(Permanent Generation),
-
年輕代又分為Eden和Survivor區,Survivor區由FromSpace和ToSpace組成,Eden區占大容量, Survivor兩個區占小容量,默認比例是8:1:1,
-
堆記憶體用途:存放的是物件,垃圾收集器就是收集這些物件,然后根據GC演算法回收, 非堆記憶體用途:永久代,也稱為方法區,存盤程式運行時長期存活的物件,比如類的元資料、方法、常量、屬性等,
JDK1.8版本廢棄了永久代,替代的是元空間(MetaSpace),元空間與永久代上類似,都是方法區的實作,他們最大區別是:元空間并不在JVM中,而是使用本地記憶體,1、物件分代
-
新生成的物件首先放到年輕代Eden區
-
當Eden空間滿了,觸發Minor GC,存活下來的物件移動到Survivor0區,
-
Survivor0區滿后觸發執行Minor GC,Survivor0區存活物件移動到Suvivor1區,這樣保證了一段 時間內總有一個survivor區為空,
-
經過多次Minor GC仍然存活的物件移動到老年代,
-
老年代存盤長期存活的物件,占滿時會觸發Major GC(Full GC),GC期間會停止所有執行緒等待GC完成,所以對回應要求高的應用盡量減少發生Major GC,避免回應超時,
Minor GC : 清理年輕代
Major GC(Full GC) : 清理老年代,清理整個堆空間,會停止應用所有執行緒,
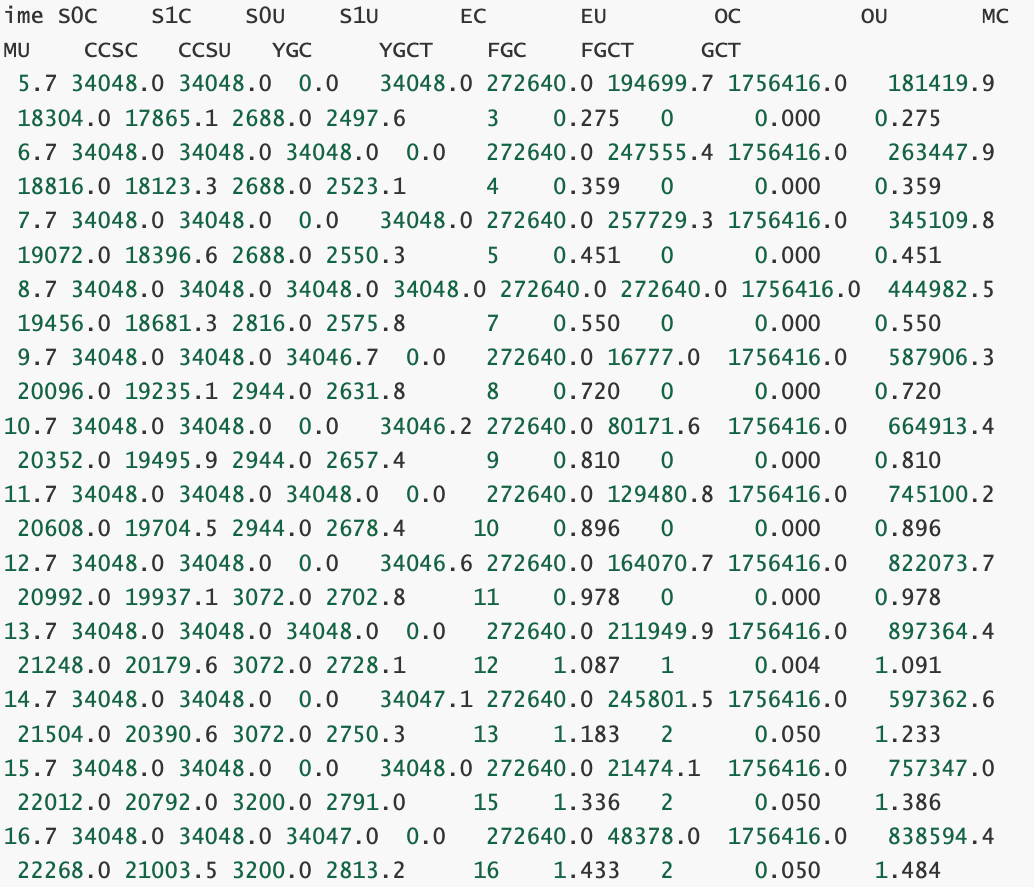
2、Jstat
查看當前jvm記憶體使用以及垃圾回收情況
jstat -gc -t 2876 1s #顯示pid是2876的垃圾回收堆的行為統計

結果解釋:
#C即Capacity 總容量,U即Used 已使用的容量
S0C: 當前survivor0區容量(kB),
S1C: 當前survivor1區容量(kB),
S0U: survivor0區已使用的容量(KB)
S1U: survivor1區已使用的容量(KB)
EC: Eden區的總容量(KB)
EU: 當前Eden區已使用的容量(KB)
OC: Old空間容量(kB),
OU: Old區已使用的容量(KB)
MC: Metaspace空間容量(KB)
MU: Metacspace使用量(KB)
CCSC: 壓縮類空間容量(kB),
CCSU: 壓縮類空間使用(kB),
YGC: 新生代垃圾回收次數
YGCT: 新生代垃圾回收時間
FGC: 老年代 full GC垃圾回收次數
FGCT: 老年代垃圾回收時間
GCT: 垃圾回收總消耗時間
開啟HDFS GC詳細日志輸出
編輯hadoop-env.sh
export HADOOP_LOG_DIR=/hadoop/logs/
增加JMX配置列印詳細GC資訊
指定一個日志輸出目錄;注釋掉之前的ops
增加新的列印配置
#JMX配置
export HADOOP_JMX_OPTS="-Dcom.sun.management.jmxremote.authenticate=false - Dcom.sun.management.jmxremote.ssl=false"
export HADOOP_NAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:- INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_NAMENODE_OPTS"
export HADOOP_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS $HADOOP_DATANODE_OPTS"
export NAMENODE_OPTS="-verbose:gc -XX:+PrintGCDetails -Xloggc:${HADOOP_LOG_DIR}/logs/hadoop-gc.log \
-XX:+PrintGCDateStamps -XX:+PrintGCApplicationConcurrentTime -XX:+PrintGCApplicationStoppedTime \
-server -Xms150g -Xmx150g -Xmn20g -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=15 \
-XX:ParallelGCThreads=18 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+UseCMSCompactAtFullCollection -XX:+DisableExplicitGC -XX:+CMSParallelRemarkEnabled \
-XX:+CMSClassUnloadingEnabled -XX:CMSInitiatingOccupancyFraction=70 -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSMaxAbortablePrecleanTime=5000 \
-XX:+UseGCLogFileRotation -XX:GCLogFileSize=20m -XX:ErrorFile=${HADOOP_LOG_DIR}/logs/hs_err.log.%p -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=${HADOOP_LOG_DIR}/logs/%p.hprof \
"
export DATENODE_OPTS="-verbose:gc -XX:+PrintGCDetails -Xloggc:${HADOOP_LOG_DIR}/hadoop-gc.log \
-XX:+PrintGCDateStamps -XX:+PrintGCApplicationConcurrentTime -XX:+PrintGCApplicationStoppedTime \
-server -Xms15g -Xmx15g -Xmn4g -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=15 \
-XX:ParallelGCThreads=18 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+UseCMSCompactAtFullCollection -XX:+DisableExplicitGC -XX:+CMSParallelRemarkEnabled \
-XX:+CMSClassUnloadingEnabled -XX:CMSInitiatingOccupancyFraction=70 -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSMaxAbortablePrecleanTime=5000 \
-XX:+UseGCLogFileRotation -XX:GCLogFileSize=20m -XX:ErrorFile=${HADOOP_LOG_DIR}/logs/hs_err.log.%p -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=${HADOOP_LOG_DIR}/logs/%p.hprof
\
"
export HADOOP_NAMENODE_OPTS="$NAMENODE_OPTS $HADOOP_NAMENODE_OPTS"
export HADOOP_DATANODE_OPTS="$DATENODE_OPTS $HADOOP_DATANODE_OPTS"
- -Xms150g -Xmx150g:堆記憶體大小最大和最小都是150g
- -Xmn20g :新生代大小為20g,等于eden+2*survivor,意味著老年代為150-20=130g,
- -XX:SurvivorRatio=8 :Eden和Survivor的大小比值為8,意味著兩個Survivor區和一個Eden區的比值為2:8,一個Survivor占整個年輕代的1/10
- -XX:ParallelGCThreads=10 :設定ParNew GC的執行緒并行數,默認為8+(Runtime.availableProcessors-8) * 5/8,24核機器為18.
- -XX:MaxTenuringThreshold=15 :設定物件在年輕代的最大年齡,超過這個年齡則會晉升到老年代
- -XX:+UseParNewGC :設定新生代使用Parallel New GC
- -XX:+UseConcMarkSweepGC :設定老年代使用CMS GC,當此項設定時候自動設定新生代為ParNew GC
- -XX:CMSInitiatingOccupancyFraction=70 : 老年代第一次占用達到該百分比時候,就會引發CMS的第一次垃圾回收周期,后繼CMS GC由 HotSpot自動優化計算得到,
3、GC 日志決議
jstat命令輸出
查看GC日志輸出

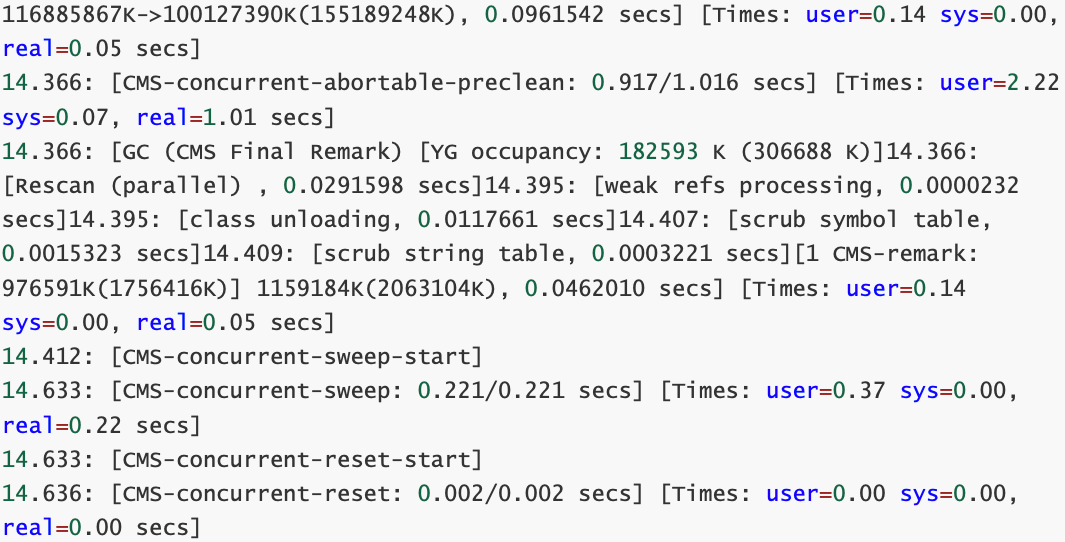
- ParNew: 16844397K->85085K(18874368K), 0.0960456 secs
其中, 16844397K 表示GC前的新生代占用量, 85085K 表示GC后的新生代占用量,GC后Eden和 一個Survivor為空,所以 85085K 也是另一個Survivor的占用量,括號中的 18874368K 是Eden+一 個被占用Survivor的總和(18g),
- 116885867K->100127390K(155189248K), 0.0961542 secs
其中,分別是Java堆在垃圾回收前后的大小,和Java堆大小,說明堆使用為 116885867K=111.47g,回收大小為100127390K=95.49g,堆大小為155189248K=148g(去掉 其中一個Survivor),回收了16g空間.
總結:
在HDFS Namenode記憶體中的物件大都是檔案,目錄和blocks,這些資料只要不被程式或者資料的擁 有者人為的洗掉,就會在Namenode的運 行生命期內一直存在,所以這些物件通常是存在在old區中, 所以,如果整個hdfs檔案和目錄數多,blocks數也多,記憶體資料也會很大,如何降低Full GC的影響?
- 計算NN所需的記憶體大小,合理配置JVM
- 使用低卡頓G1收集器
為什么會有G1呢?
因為并發、并行和CMS垃圾收集器都有2個共同的問題:
- 老年代收集器大部分操作都必須掃描整個老年代空間(標記,清除和壓縮),這就導致了GC隨著Java堆空間而線性增加或減少
- 年輕代和老年代是獨立的連續記憶體塊,所以要先決定年輕代和年老代放在虛擬地址空間的位置
G1垃圾收集器利用分而治之的思想將堆進行磁區,劃分為一個個的區域,
G1垃圾收集器將堆拆成一系列的磁區,這樣的話,大部分的垃圾收集操作就只在一個磁區內執行,從而避免很多GC操作在整個Java堆或者整個年輕代進行,
編輯hadoop-env.sh
export HADOOP_NAMENODE_OPTS="-server -Xmx220G -Xms200G -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:+UnlockExperimentalVMOptions -XX:+ParallelRefProcEnabled -XX:-ResizePLAB -XX:+PerfDisableSharedMem -XX:-OmitStackTraceInFastThrow -XX:G1NewSizePercent=2 -XX:ParallelGCThreads=23 -XX:InitiatingHeapOccupancyPercent=40 -XX:G1HeapRegionSize=32M -XX:G1HeapWastePercent=10 -XX:G1MixedGCCountTarget=16 -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=5 -XX:GCLogFileSize=100M -Xloggc:/var/log/hbase/gc.log -Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-
INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender}
$HADOOP_NAMENODE_OPTS"
注意:如果現在采用的垃圾收集器沒有問題,就不要選擇G1,如果追求低停頓,可以嘗試使用G1
這還只是針對我個人寫的筆記,是不是超級詳細,也有很多你沒接觸到的?
技術沒有上限,學習永不止步,同樣年齡不是問題!
大家加油,一起努力
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/294421.html
標籤:其他
上一篇:解決: Establishing SSL connection without server‘s identity verification is not recommended. Accord
下一篇:20210810-基于CentOS7/Linux Grafana 集成 Prometheus并實作對ClickHouse監控