有時在請求一個網頁內容時,發現無論通過GET或者是POST以及其它請求方式,都會出現403錯誤,這種現象多數為服務器拒絕了您的訪問,那是因為這些網頁為了防止惡意采集資訊,所使用的反爬蟲設定,此外可以通過模擬瀏覽器的頭部資訊來進行訪問,這樣就能剞劂以上反爬設定問題,下面以requests模塊為例介紹頭部headers的處理,步驟如下:
(1)通過瀏覽器的網路監視器查看頭部資訊,首先通過火狐瀏覽器打開對應的網頁地址,然后按快捷鍵Ctrl+shift+E打開網路監視器,再重繪當前頁面,網路監視器將如下顯示:

(2)選中第一條資訊,右側的訊息頭面板中將顯示請求頭部資訊,然后復制該資訊,
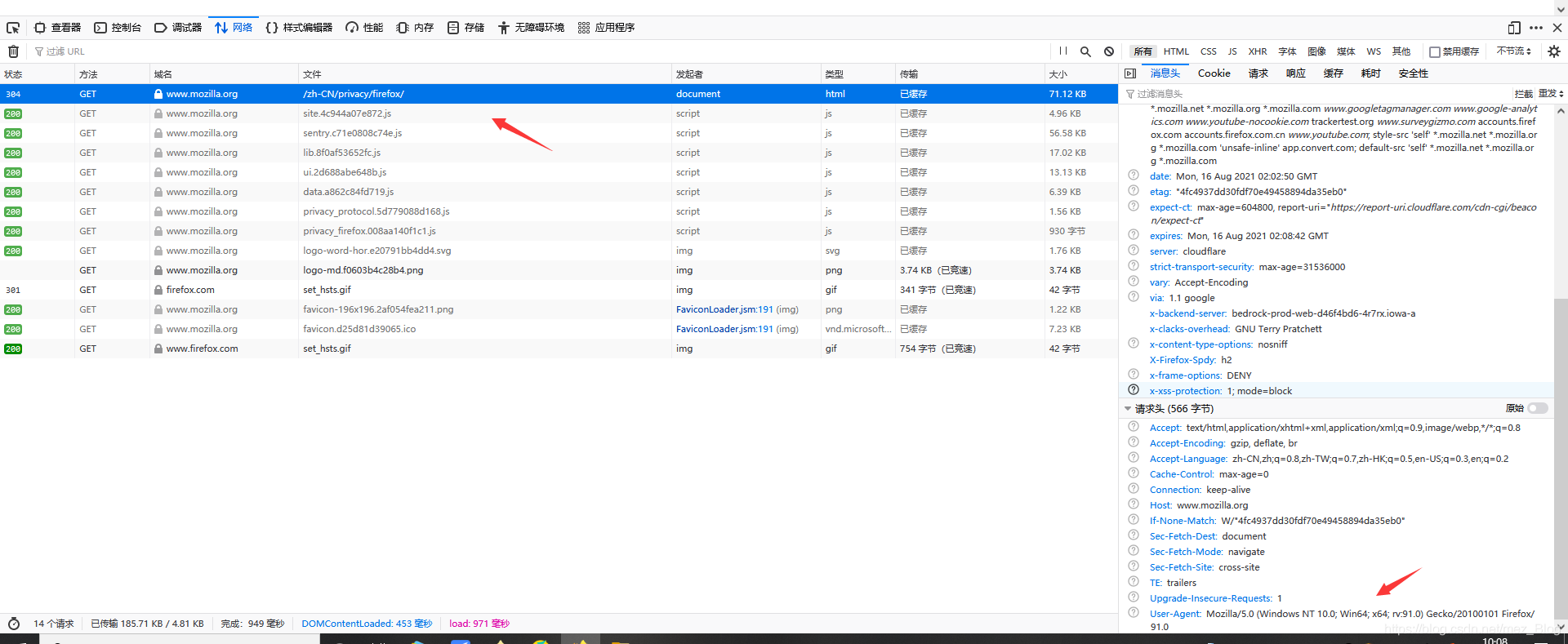
(3)實作diamante,首先創建一個需要爬取的url地址,然后創建headers頭部資訊,在發送請求等待回應,最后列印網頁的代碼資訊,實作代碼如下:
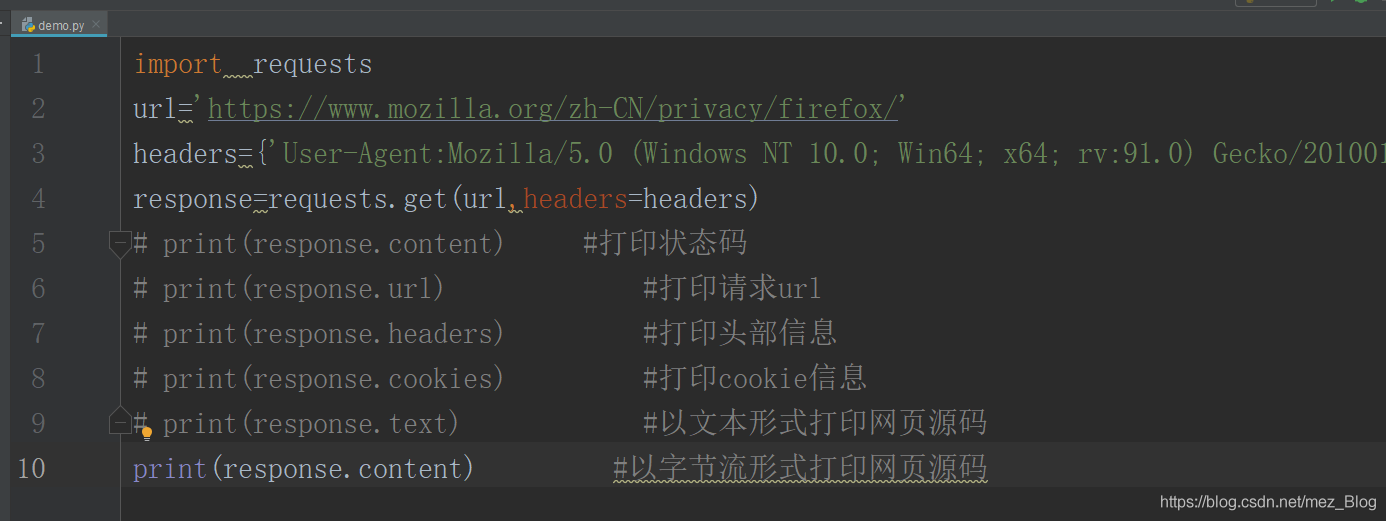
在訪問一個頁面時,如果該網頁長時間未回應,系統就會判斷該網頁超時,所以無法打開網頁,下面通過代碼來模擬一個網路超時的現象,代碼如下:
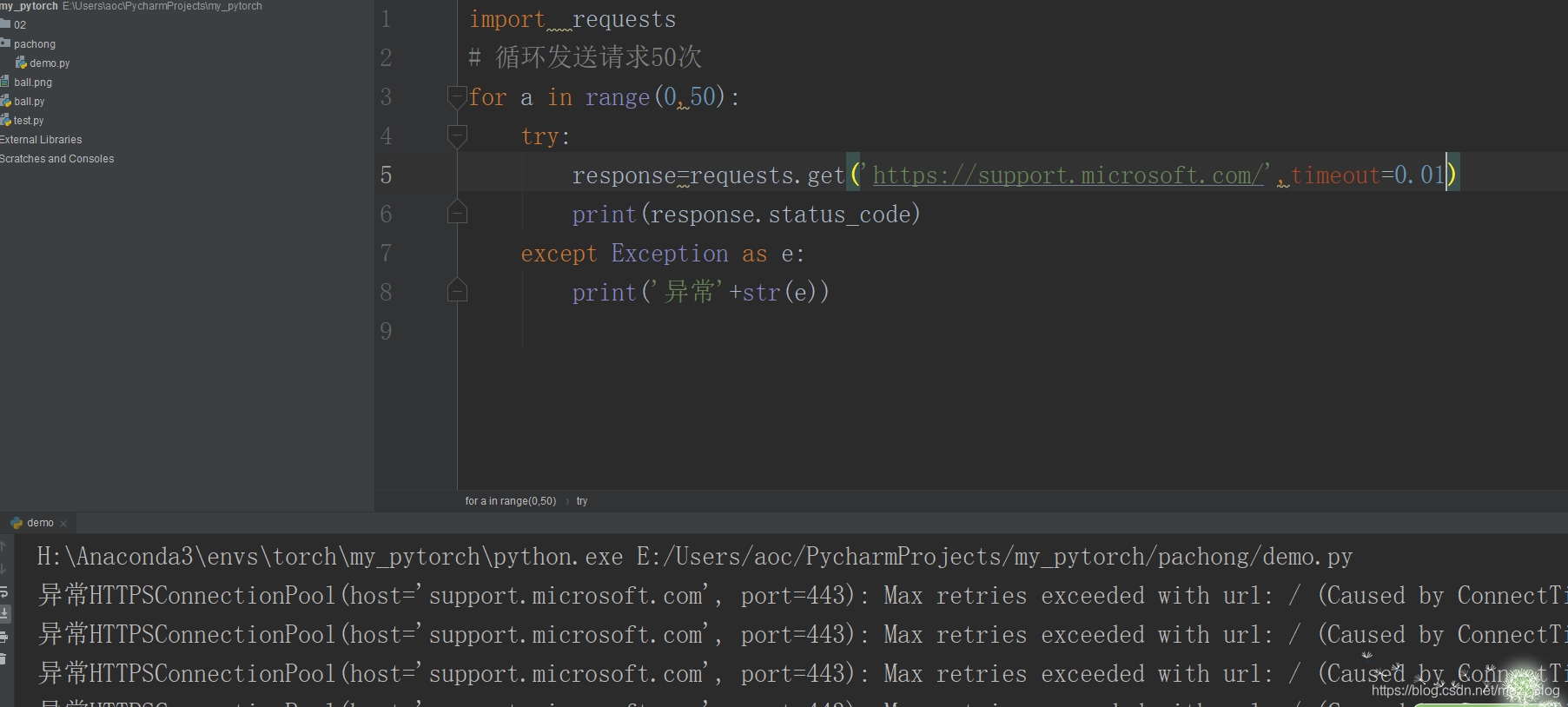
可能和電腦配置和網速有關,延時設定成0.1竟然能正常顯示,所以就把超時時間設定的更小,在指定的timeout秒內服務器未作出回應則視為超時,
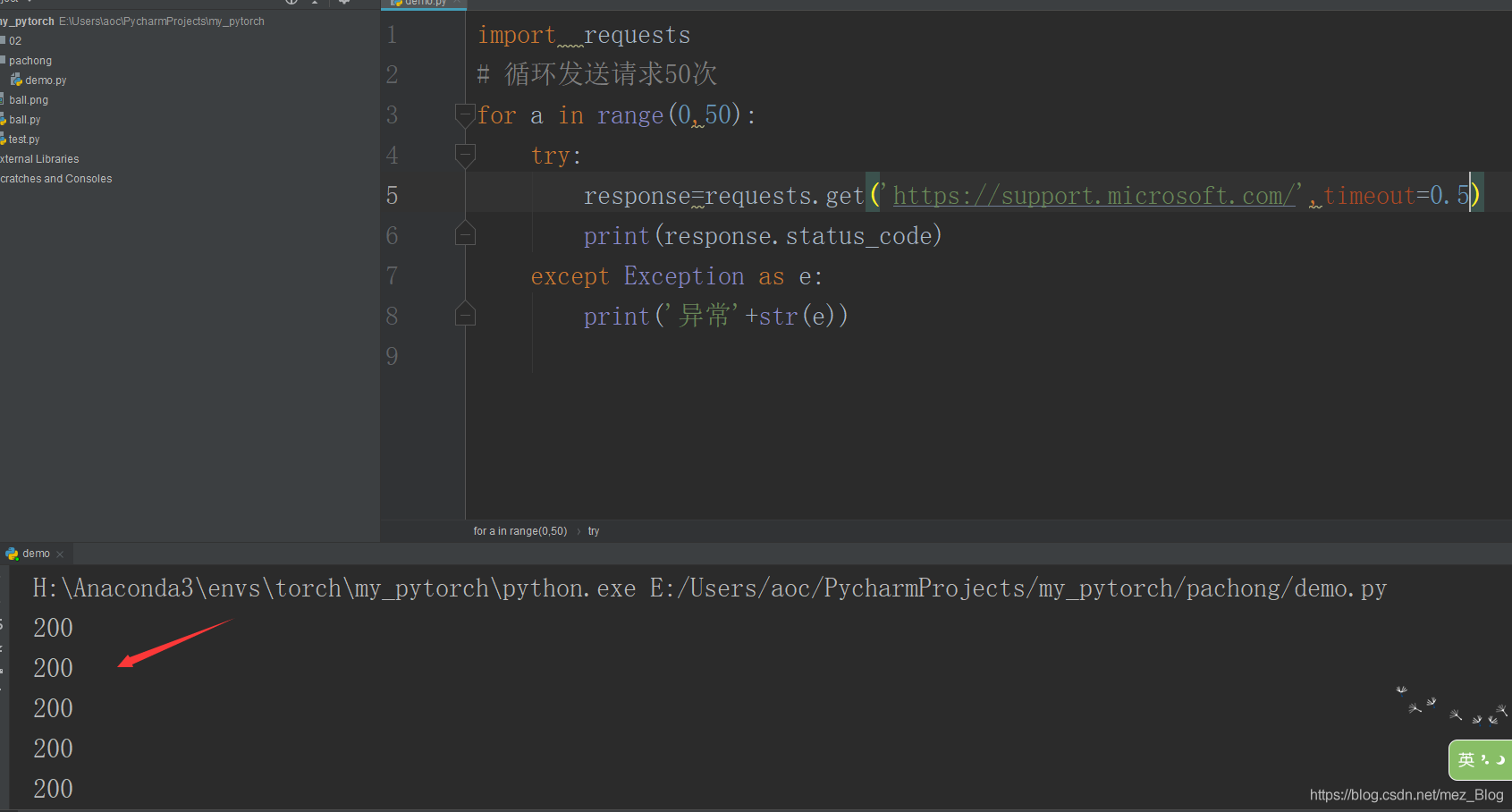
下面是未超時的情況:
說起網路例外資訊,requests模塊同樣提供了3中常見的網路例外類,代碼如下:
import requests
from requests.exceptions import ReadTimeout,HTTPError,RequestException
for a in range(0,50):
try:
response=requests.get('https://www.baidu.com/',timeout=0.5)
print(response.status_code)
except ReadTimeout: #超時例外
print('timeout')
except HTTPError: #HTTP例外
print('httperror')
except RequestException:
print('reqerror') #請求例外在爬取網頁的程序中,經常會出現不久前可以爬取的網頁現在無法爬取了,這是因為您的IP被爬取網站服務器屏蔽了,此時代理服務可以為您解決這一麻煩,設定代理是,首先需要找到代理地址,如122.114.31.177,對應的埠號為808,完整的格式為122.114.31.177:808.代碼如下:
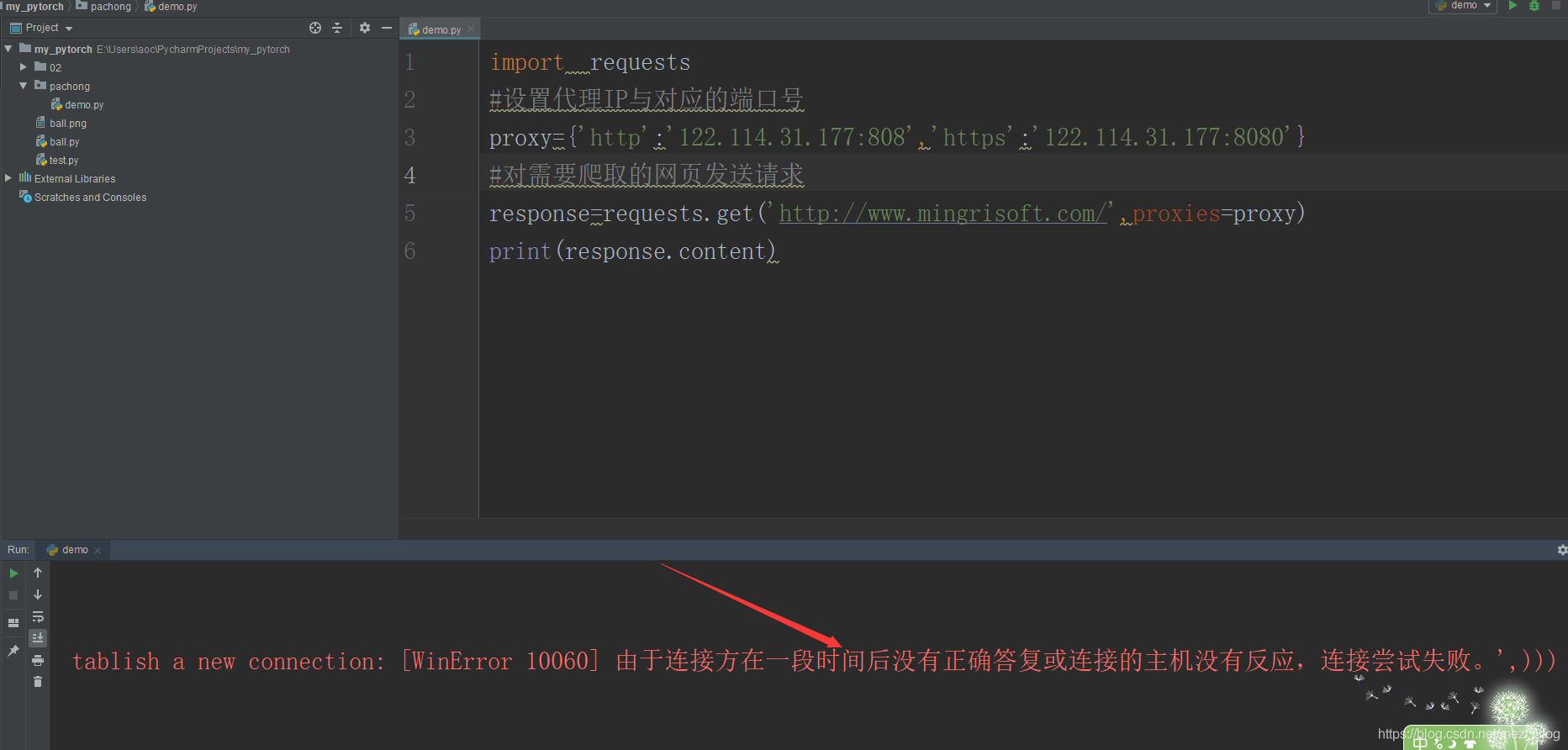
由于上面代碼中的IP是免費的,所以使用的時間不固定,超出使用的時間范圍內該地址將失效,僅供參考,
HTML決議之BeautifulSoup
BeautifulSoup是一個用于從HTML和xml檔案中提取資料的Python庫,BeautifulSoup提供一些簡單的函式用來處理導航、搜索、修改分析樹等功能,BeautifulSoup模塊中的查找提取功能非常強大,而且非常便捷,它通常可以節省程式員數小時或數天的作業時間,
BeautifulSoup自動將輸入檔案轉換為Unicode編碼,輸出檔案轉換為utf-8編碼,用戶不需要考慮編碼方式,癡肥檔案沒有指定一個編碼方式,這是,BeautifulSoup就不能自動識別編碼方式了,然后,用戶僅僅需要說明一下原式編碼方式就可以了,
BeautifulSoup 3已經停止開發,目前使用的是BeautifulSoup 4,不過它已經被移植到bs4當中了,所以在匯入時需要from bs4,然后再匯入BeautifulSoup,安裝BeautifulSoup有3中方式:
1.如果你使用的是最新版本的Debian或Ubuntu Linux,這可以使用系統軟體包管理器安裝BeautifulSoup,安裝命令為:apt-get install python-bs4.
2.BeautifulSoup 4是通過Pypi發布的,可以通過easy_install或pip來安裝,包名是beautifulsoup 4,它可以兼容python 2和Python 3.安裝命令為:easy_install beautifulsoup4或者是pip install beautifulsoup 4,注:在使用BeautifulSoup4之前需要先通過命令pip install bs4進行bs4庫的安裝,
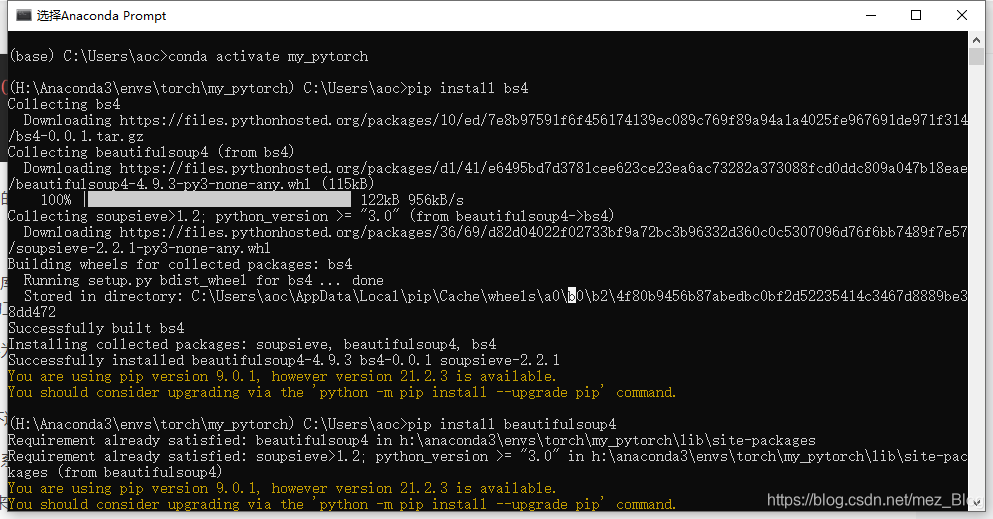
原來安裝完bs4自動安裝了beautifulsoup4,這樣就方便需要,然后我們來驗證一下,
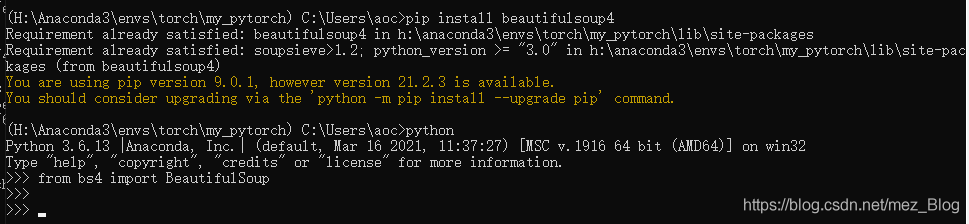
import沒有報錯說明已經成功安裝,
3.如果當前的BeautifulSoup不是你想要的版本,可以通過下載原始碼的方式進行安裝,原始碼的下載地址為https://www.crummy.com/software/BeautifulSoup/bs4/download/,然后再控制臺中打開指定的路徑,輸入命令python setup.py install即可,
beautifulsoup支持Python標準庫中包含的HTML決議器,但他也支持許多第三方Python決議器,其中包含lxml決議器,根據不同的作業系統,用戶可以使用以下命令安裝lxml,
【1】apt-get install python-lxml
【2】easy_install lxml
【3】pip install lxml
另一個決議器是html5lib,他是一個用于決議HTML的Python庫,按照web瀏覽器的方式決議HTML,用戶可以使用以下命令安裝html5lib
【1】apt-get install python-html5lib
【2】easy_install html5lib
【3】pip install html5lib
下面來比較以下各個決議器的優缺點
| 決議器 | 用法 | 優點 | 缺點 |
| Python標準庫 | BeautifulSoup(markup,"html.parser") | Python標準庫執行速度適中 | 在Python2.7.3或3.2.2之前的版本中檔案容錯能力差 |
| lxml的HTML決議器 | BeautifulSoup(markup,"lxml") | 速度快,檔案容錯能力強 | 需要安裝C語言庫 |
| lxml的XML決議器 | BeautifulSoup(markup,"lxml-xml") BeautifulSoup(markup,"xml") | 速度快,位移支持xml的決議器 | 需要安裝C語言庫 |
| html5lib | BeautifulSoup(markup,"html5lib") | 最好的容錯性,以瀏覽器的方式決議檔案,生成HTML5格式檔案 | 速度慢,不依賴外部擴展 |
BeautifulSoup安裝完成以后,下面將介紹如何通過BeautifulSoup庫進行HTML的決議作業,步驟如下:
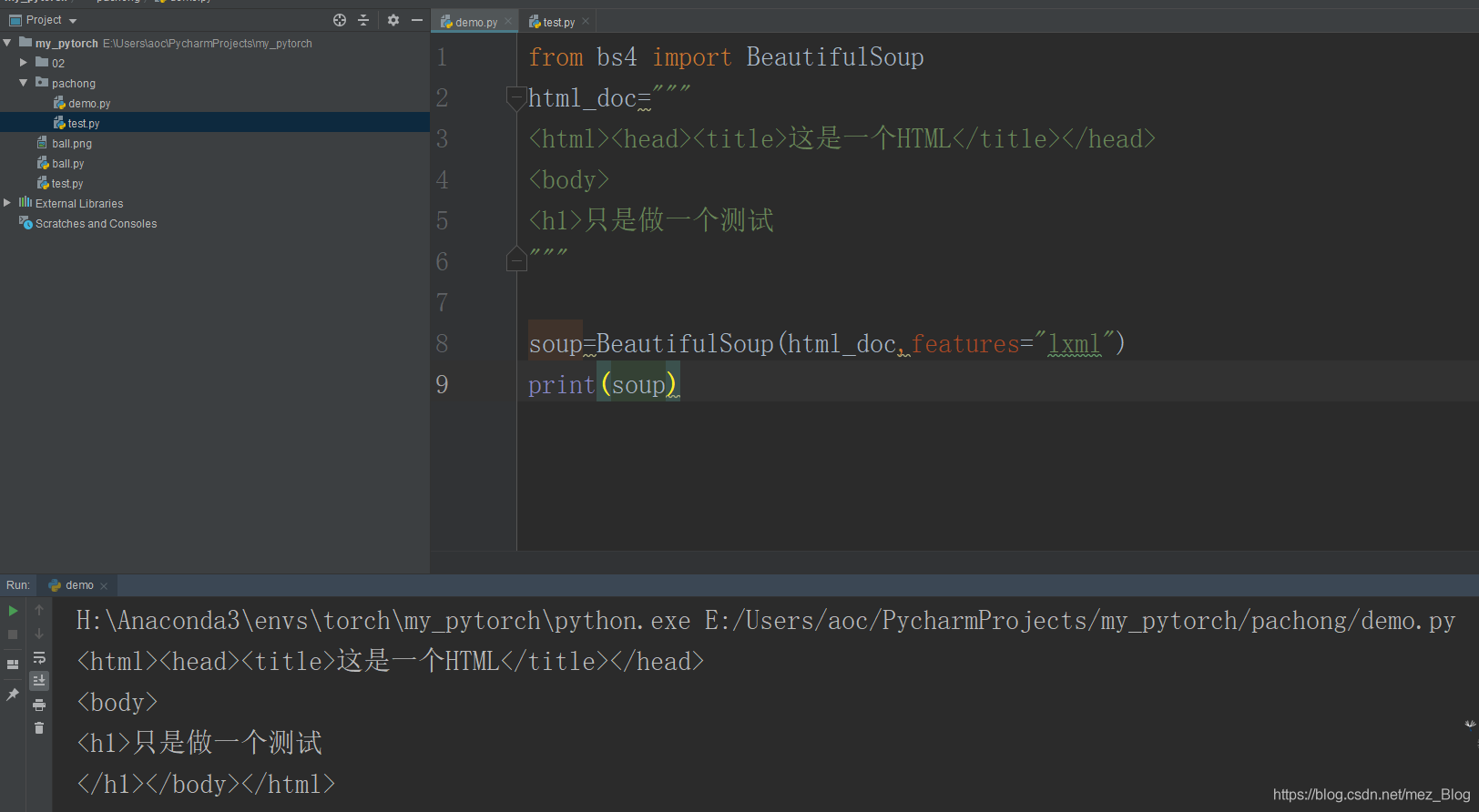
(1)匯入bs4庫,然后創建一個模擬HTML代碼的字串,代碼如下: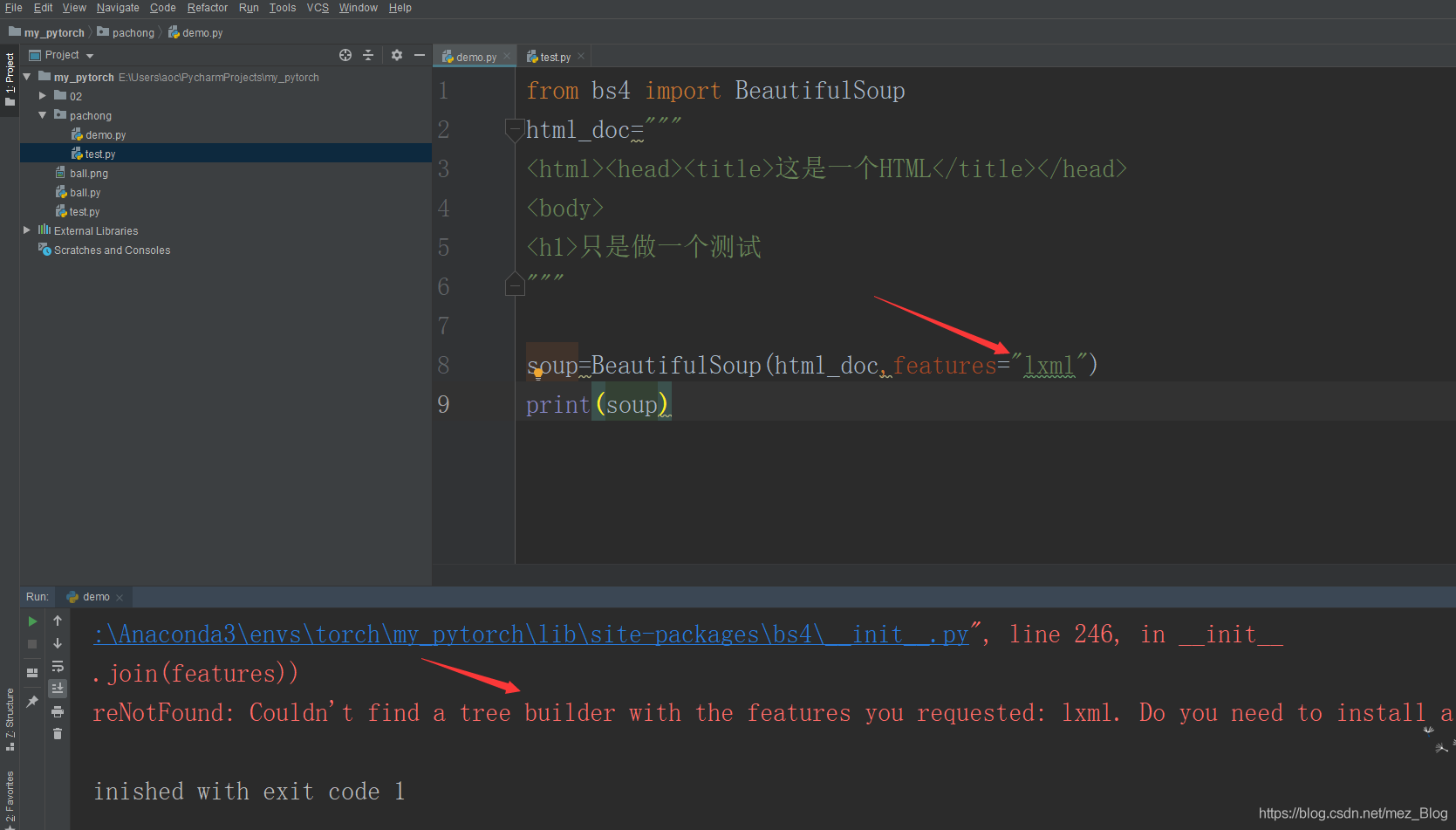
顯示lxml還未安裝,我們在terminal進行安裝
再次運行:
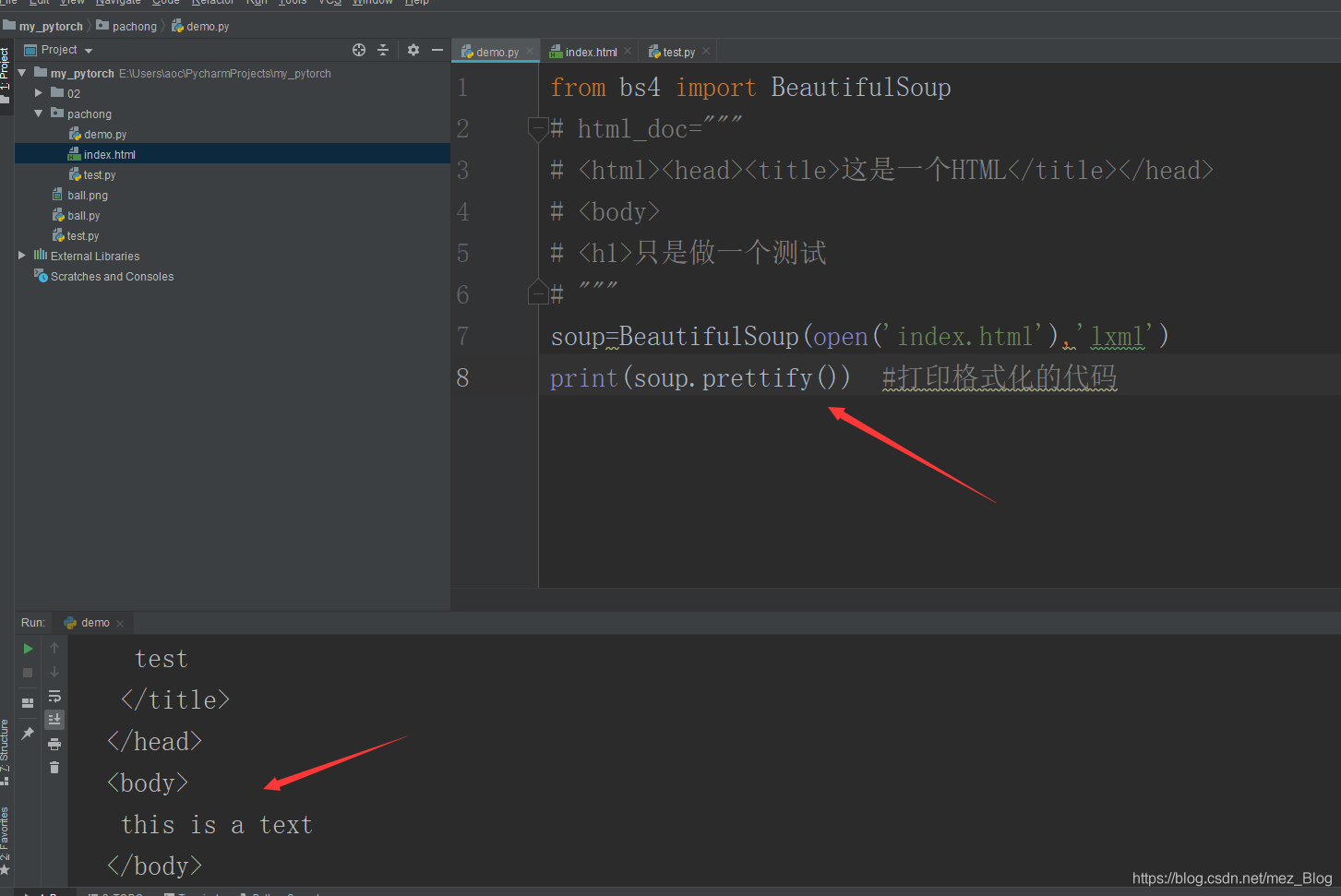
這是在一個Python檔案中,如果將html_doc字串中的代碼保存在index.html檔案中,可以通過打開HTML檔案的方式對代碼進行決議,并且可以通過prettify()方法進行代碼的格式化處理,代碼如下:
HTML檔案如下: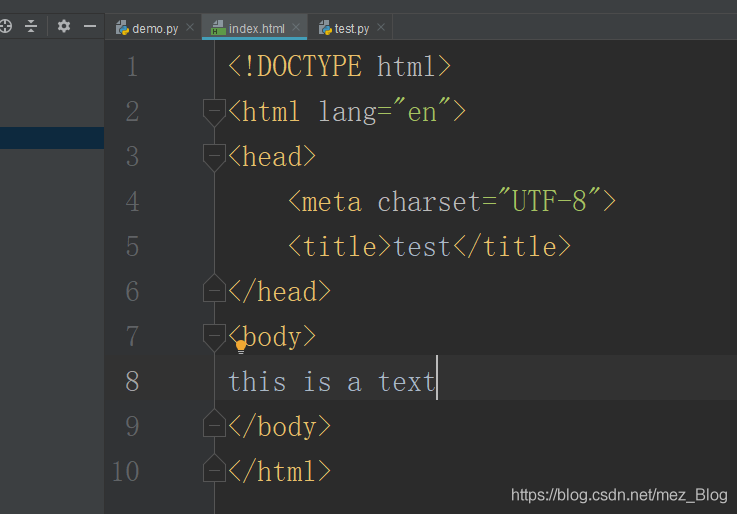
我們看到,正常的把HTML檔案中的代碼輸出,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/294452.html
標籤:其他