并查集 -- LRU Cache
- 并查集的概念
- 一、并查集的用途
- 并查集的結構解釋
- 并查集的實作
- 并查集相關習題
- 習題1.leetcode 朋友圈
- 習題2.leetcode 等式方程的可滿足性
- 并查集的思考與提升
- 二、LRU Cache的介紹
- 1.什么是LRU Cache
- 習題. LRU 快取機制
- 總結
好文建議收藏!!
并查集的概念
并查集作為一種資料結構在處理需要將n個元素劃分成不相交的集合,在逐步按照某一種規律將某些元素給合并,并在這個程序中要反復查詢某一種元素歸屬于哪個集合的運算,稱之為并查集
一、并查集的用途
劍指 Offer II 116. 朋友圈
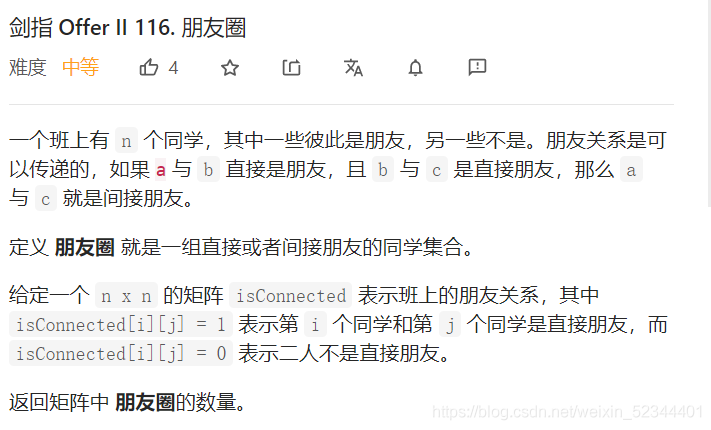
這道題講述就是有一組元素,他們相互之間產生某種關系,形成了集合,面對這種問題,常規的解法弄來弄去可能都會覺得做的不太對,但有了并查集我們解決這類問題是較簡單的,
并查集的結構解釋
注釋:雙親節點或父節點:若一個節點含有子節點,則這個節點稱為其子節點的父節點
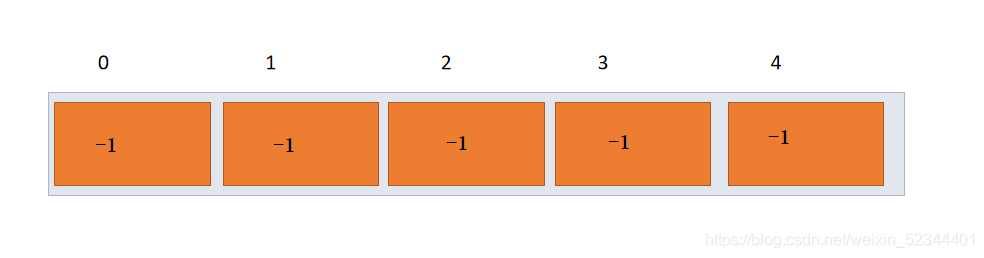
我們簡要的舉個例子,這里我們有5人,他們的編號為 0 - 4,假設他們是一群準大一的學生,他們剛開始各自為一個集合,
我們這里用負數表示自己為整體,索引指向的內容若為正數表示該索引存放的值為集合當中的雙親結點,
假設過了一段時間后,編號為0,2,4的同學形成了一個集合,編號為1,3的同學形成了一個集合,,如下圖所示
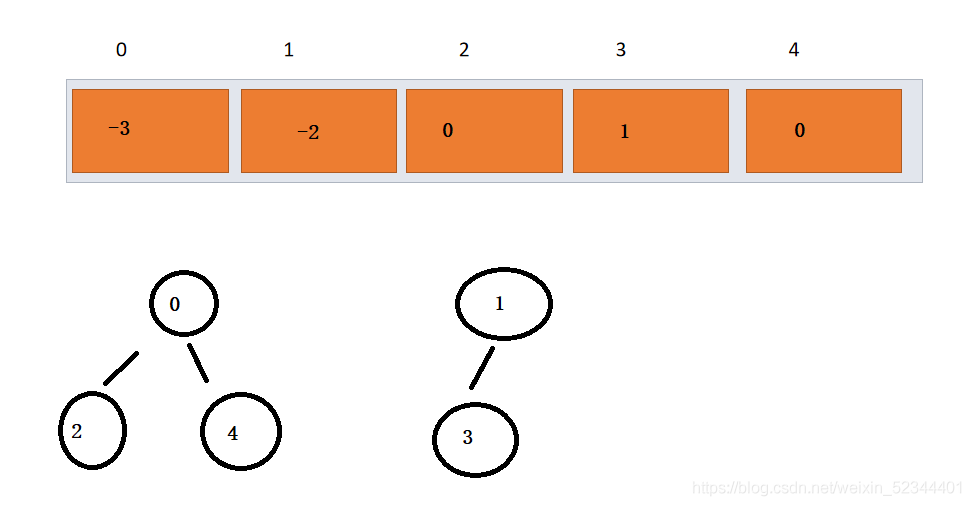 這里的0,1分別是一個集合,索引對應的值是集合中的元素個數的相反數
這里的0,1分別是一個集合,索引對應的值是集合中的元素個數的相反數
解釋: 此時父節點中存放的是集合大小的負值,子節點存放的是父節點的索引,倘若這時編號為4 與編號為3的結點因為一場比賽結識成為了朋友,我們要如何做呢? - -實際上,當4與3結合成朋友,自然兩個集合中的每一個人都成了朋友,我們這時只需要讓其中一個集合成為父節點,兩個集合便成了一個集合了 ,
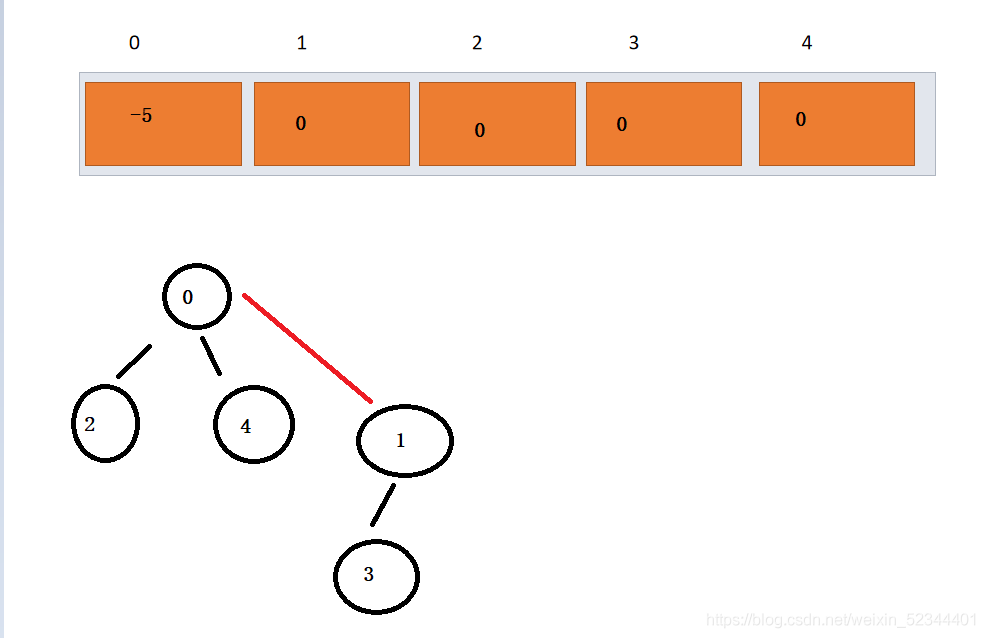
此時我們的人形成了一個整體,每個子節點的存放的都是父節點的下標(0),0位置存放結點的個數的負值(因為我們用負數來區分是否為根)
我們也可以看出來一個并查集所需要具備哪些結論?
1.陣列的下標對應集合中的元素下標
2.負數代表根,數字代表該集合中的元素個數
3.若陣列中為非負數,則為父節點在陣列當中的下標
我們也可以看出來一個并查集所需要具備哪些功能?
1.查找元素屬于哪一個集合
2.查找兩個元素是否為一個集合
3.兩個元素合并成一個集合
4.集合的個數
并查集的實作
注釋中有解釋,詳情請看注釋,并結合下面的兩道習題,其實就是實作了上面概括的四個介面
#include<iostream>
using namespace std;
#include<vector>
#include<assert.h>
class UnionFindSet
{
public:
//建構式,初始化開空間
UnionFindSet(int x)
{
_ufs.resize(x, -1);
//初始化的時候講x個空間初始化成-1
}
//合并兩個元素為集合
bool Union(int x1,int x2)
{
int root1 = FindRoot(x1);
int root2 = FindRoot(x2);
if (root1 == root2)
return false;
else
{
//將root1成為新集合的頭,并計算他的元素個數,root2的內容則指向root1的索引
_ufs[root1] += _ufs[root2];
_ufs[root2] = root1;
return true;
}
}
int FindRoot(int x)
{
assert(x < _ufs.size());
while (_ufs[x] >= 0)
{
x = _ufs[x];
}
return x;
}
//算出陣列當中有多少個集合
int Size()
{
int count = 0;
for (int i = 0; i < _ufs.size(); ++i)
{
//計算陣列中有幾個集合
if (_ufs[i] < 0)
count++;
}
return count;
}
private:
vector<int> _ufs;
};
并查集相關習題
習題1.leetcode 朋友圈
朋友圈
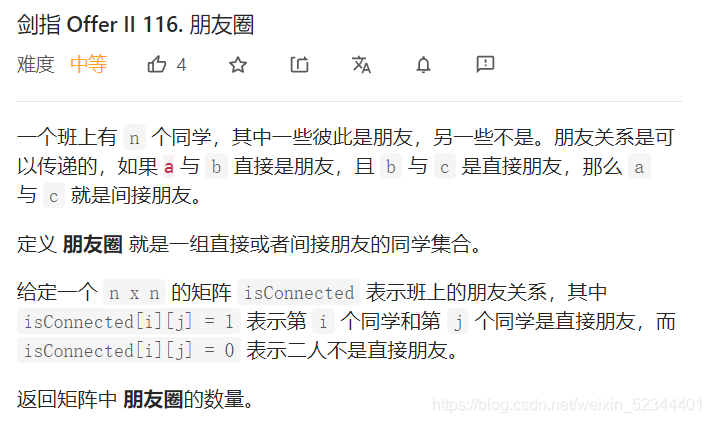
分析: 這題其實就是給了我們一個二維矩陣,然后讓我們確定有多少個朋友圈,這個就很簡單了,我們可以遍歷一遍陣列,用我們的Union的介面將兩個人合并成一個集合,最后在用Size介面來計算集合的個數,
class UnionFindSet
{
public:
UnionFindSet(int x)
{
_ufs.resize(x, -1);
//初始化的時候講x個空間初始化成-1
}
bool Union(int x1,int x2)
{
int root1 = FindRoot(x1);
int root2 = FindRoot(x2);
if (root1 == root2)
return false;
else
{
//將root1成為新集合的頭,并計算他的元素個數,root2的內容則指向root1的索引
_ufs[root1] += _ufs[root2];
_ufs[root2] = root1;
return true;
}
}
int FindRoot(int x)
{
assert(x < _ufs.size());
while (_ufs[x] >= 0)
{
x = _ufs[x];
}
return x;
}
int Size()
{
int count = 0;
for (int i = 0; i < _ufs.size(); ++i)
{
if (_ufs[i] < 0)
count++;
}
return count;
}
private:
vector<int> _ufs;
};
class Solution {
public:
int findCircleNum(vector<vector<int>>& isConnected) {
UnionFindSet ufs(isConnected.size());
for(int i =0;i<isConnected.size();++i)
{
for(int j =0;j<isConnected.size();++j)
{
//遍歷二維陣列,將 i==j自己與自己的情況過濾
if(i == j)
continue;
//將為朋友的弄成集合
if(isConnected[i][j]==1)
ufs.Union(i,j);
}
}
int ret = ufs.UfsSize();
return ret;
}
};
習題2.leetcode 等式方程的可滿足性
等式方程的可滿足性
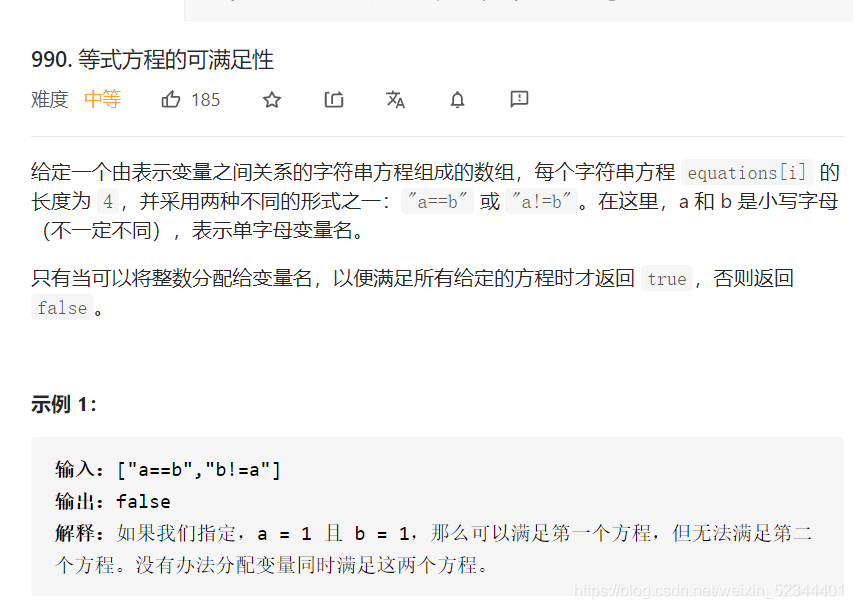
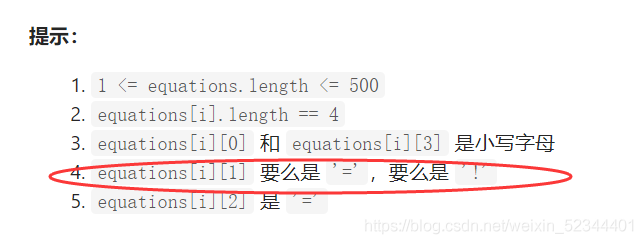
分析:這道題目也是用并查集實作為最優解,我們這道題可以先遍歷一遍陣列,將所有string中的第二個位置為 ‘=’先放入并查集當中,在遍歷一遍從第二個位置’!'查看是否有重復的錯誤邏輯放入
class UnionFindSet
{
public:
UnionFindSet(int x)
{
_ufs.resize(x, -1);
//初始化的時候講x個空間初始化成-1
}
bool Union(int x1,int x2)
{
int root1 = FindRoot(x1);
int root2 = FindRoot(x2);
if (root1 == root2)
return false;
else
{
//將root1成為新集合的頭,并計算他的元素個數,root2的內容則指向root1的索引
_ufs[root1] += _ufs[root2];
_ufs[root2] = root1;
return true;
}
}
int FindRoot(int x)
{
assert(x < _ufs.size());
while (_ufs[x] >= 0)
{
x = _ufs[x];
}
return x;
}
int Size()
{
int count = 0;
for (int i = 0; i < _ufs.size(); ++i)
{
if (_ufs[i] < 0)
count++;
}
return count;
}
private:
vector<int> _ufs;
};
class Solution {
public:
bool equationsPossible(vector<string>& equations) {
UnionFindSet ufs(26);
//先遍歷一遍,將所有==的情況的集合都找出來,再第二次遍歷將!=看==的情況是否存在
for(auto& e: equations)
{
//第一次遍歷,建立映射
if(e[1] =='=')
ufs.Union(e[0]-'a',e[3]-'a');
}
for(auto& e:equations)
{
if(e[1] =='!')
{
//第二次遍歷,查錯
//若他們的頭結點為同一個,說明在一個集合,則與邏輯錯誤
if(ufs.FindRoot(e[0]-'a') == ufs.FindRoot(e[3]-'a'))
return false;
}
}
//當走到這里的時候,表示并查集中沒有出現邏輯錯誤的
return true;
}
};
并查集的思考與提升
這里大家思考一下,朋友圈這樣的題型,倘若他給我們的不是編號,而是人名,那么我們如何利用我們的并查集呢,我們的并查集都是通過下標來實作的,
我們這里可以用vector< string > nameV={“小明”,“小紅”,“小綠”…},這樣子我們就可以通過下標找到對應的人,
我們用人找下標就可以用map<string,int> nameIndexmap 來通過人名找到對應下標,這樣我們的并查集就可以實作通用了

通用分析:
map 可以由名字找到下標_ufs[下標] 可以找到對應的頭結點
vector 可以由下標找到人
我們想要進行人名對應查找頭節點的時候,map(人名)首先可以找到下標,vector[下標]可以找到對應的雙親結點的人,相當于找到了對應的雙親結點的名字,我們就可以利用這種結構對_ufs這個陣列進行更改
二、LRU Cache的介紹
1.什么是LRU Cache
LRU是Least Recently Used的縮寫,意思是最近最少使用,Cache則是CPU和主存間的快速RAM,而且因為Cache的容量有限,當我們呢容量用完之后,需要加入新的內容,我們就要洗掉掉部分已經存入的資料,從而騰出空間,LRU Cache的替換原則就是將最近最少使用的內容進行替換
習題. LRU 快取機制
146. LRU 快取機制
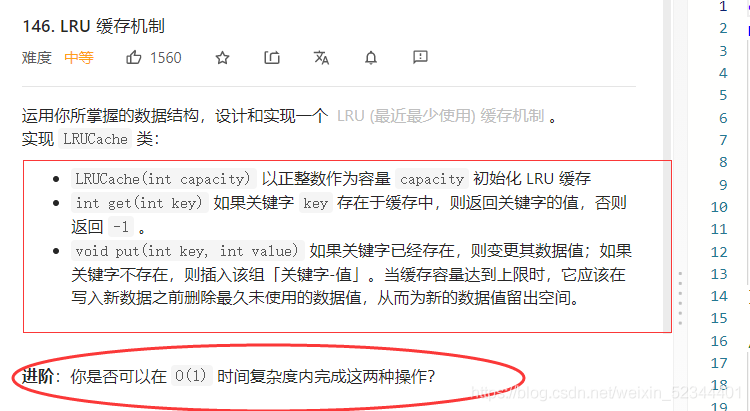
仔細觀察題意,我們可以得知,他要求我們設計一種資料結構來實作O(1)的時間復雜度去完成get和put這兩個介面,
思路1:我們要實作get相對簡單一些,我們都知道哈希表中的查找就是O(1)的時間復雜度,但是每次get資料時,相當于我們也呼叫了一次這個資料,這個資料的優先級就會提高
怎么去實作呢,我們可以用一個vector用來開固定大小的空間,我們規定資料尾為優先級高的,每次get資料時我們將資料拿出來放到最后,
put資料的時候我們先檢查是否存在相同的key,存在的話就更新一下list的value,不存在則檢查容量,容量不夠的時候我們就洗掉最久未使用的,夠的話就直接尾插, -
但是如何把資料找到并且放到后面,并且保證洗掉資料保持時間復雜度為O(1),所以我們拿到這個位置的時間復雜度必須是O(1),洗掉資料的時候用 vector(順序表) 的時間復雜度是O(N),所以思路一可以實作,但是不符合題目要求,于是我們有了下面的思路二,
思路2:
get: 使用list,把最近訪問的放在尾上,最久不訪問的放在頭上, list在一個位置的洗掉是O(1)的時間復雜度,因為他底層是一個帶頭回圈雙向鏈表,但是我們要洗掉資料的時候要有這個位置的資訊吧,所以我們這里哈希表的value存盤這個list迭代器,我們的哈希表可以在key位置存盤pair<first,second>,value位置就可以存盤list的迭代器了,這樣我們通過哈希表找到要洗掉的key之后,可以直接找到list中的迭代器位置,洗掉之后再到鏈表尾插,洗掉了之后迭代器失效了,所以我們要更新哈希表中存盤的迭代器位置,
put:put資料的時候我們也是先在哈希表中查找是否存在,存在的話更新pair的second,不存在的話我們就可以頭部洗掉,再到尾上插入,
上述結構就能實作O(1)的時間復雜度,也是LRU Cache常用的搭配,哈希表+鏈表的組合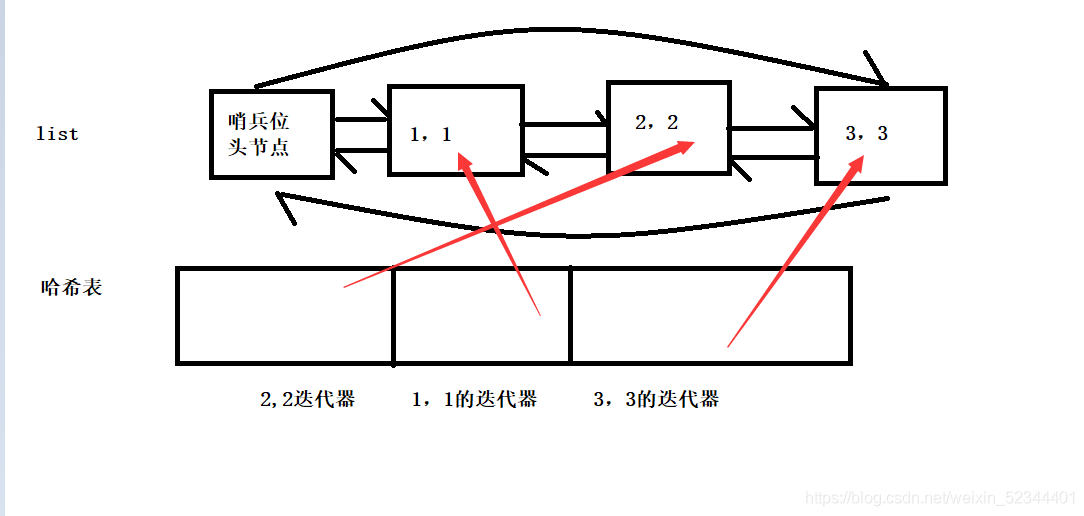
代碼邏輯是利用_size,_capacity來控制鏈表的長度_size初始化給0,_capacity就給capacity,其中get邏輯就是哈希表有對應的key值的時候我們就在list當中洗掉他,在尾插,在哈希表更新,沒有對應的key值就在list中尾插,在哈希表中添加這個key和list的迭代器
put的邏輯我們先復用get的介面,當put的資料已經在list中,我們可以很好的使用get的邏輯,就是記得要將list的pair的second更新,當不存在的時候就需要判斷鏈表大小和容量是否相等,當_size和_capacity相等的時候,list頭刪,在尾插,在哈希表更新迭代器,(這里的_size其實也可以用list.size(),但是這是一個O(N)的介面,他是遍歷一遍,所以我們成員變數給多一個_size),當_size和_capacity不相等的時候就直接在list當中尾插,在哈希表中也插入,詳細請看代碼決議,
class LRUCache {
public:
LRUCache(int capacity)
:_size(0),
_capacity(capacity)
{}
int get(int key) {
//找的時候在哈希表中,若存在就更改在list的位置,更改哈希表的迭代器值
if(um.find(key) != um.end())
{
//這里現在list后面插入后再洗掉,防止迭代器失效
list<pair<int,int>>::iterator it = um[key];
int value = it->second;
lt.push_back(make_pair(it->first,it->second));
lt.erase(it);//erase 可以給一個迭代器的位置iterator erase (iterator position);
//更新之后對應的key的迭代器就是再最后一個位置
um[key] = (--lt.end());
return value;
}
else
{
return -1;//找不到
}
}
void put(int key, int value) {
//若改變了list的迭代器位置還要更新哈希表中的迭代器值,若已經存在的會在get的邏輯中處理好,只需要將list的value更新
int ret = get(key);
if(ret != -1)
{
//表示已經在list中有了,我們要把這個放在list的最后,并且更新list的value就可以了
um[key]->second = value;
}
else
{
//表示沒有找到
//要考慮是否容量是否有滿
if(_size >=_capacity)
{
//list中洗掉最久未使用的,并且在哈希表中洗掉這個值
um.erase((lt.front()).first);//洗掉掉list第一個位置的迭代器
//再將list位置的第一個位置洗掉
lt.pop_front();
}
//list當中放入新的值,并且在哈希表中也放入list的映射
lt.push_back(make_pair(key,value));
um[key] = (--lt.end());
++_size;
}
}
private:
int _size;//鏈表當前大小
int _capacity;//鏈表最大容量
list<pair<int,int>> lt;//鏈表
unordered_map<int,list<pair<int,int>>::iterator> um;//哈希表
};
get的寫法2: 可以使用list當中的一個介面splice來實作,他的實作方式也就是拿出一個結點之后,往另一個迭代器的position這個位置前面插入,改變了list的鏈接關系,list的迭代器其實也只是封裝了一下結點,模擬成指標的基本使用,結點沒有被釋放,迭代器就不會失效,所以這樣子是可行的!

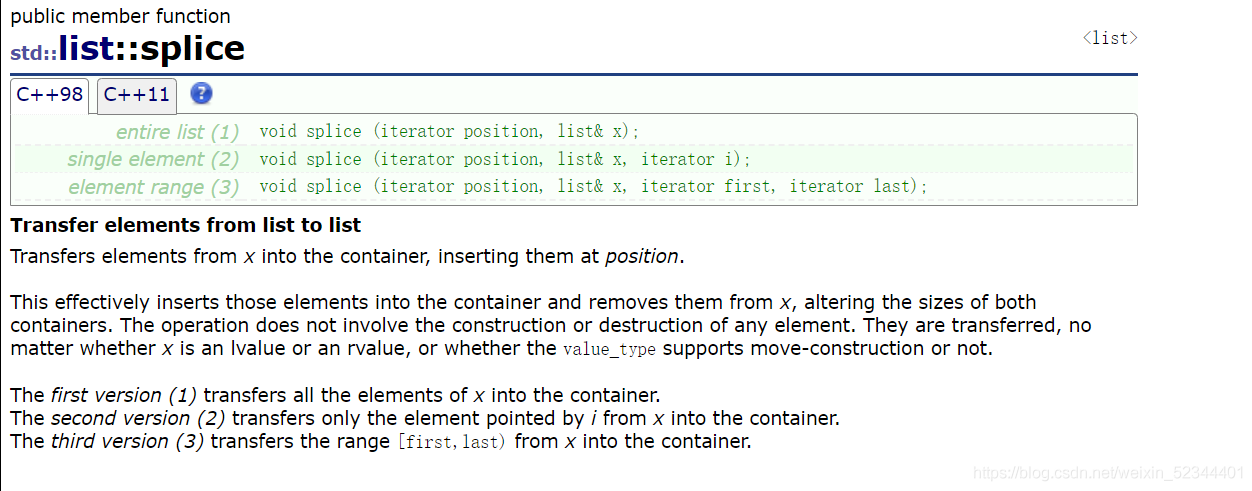
介面get的代碼就可以進行簡單的更改代碼如下:
int get(int key) {
if(um.find(key) != um.end())
{
//倘若哈希表中存在key,就用splice放到list的尾
list<pair<int,int>>::iterator it = um[key];
int value = it->second;
lt.splice(lt.end(),lt,it);//將第二個引數的it這個位置放到第一個引數的前面
return value;
}
else
{
return -1;//找不到
}
}
總結
并查集,LRU Cache的講解就到這里了,其中的并查集其實結構比較簡單,但是后面的LRU Cache大家仔細看我的分析程序,其實也還好,大家如果發現有什么錯誤歡迎指正,
文章制作不易,一鍵三連!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/294471.html
標籤:其他
上一篇:嵌入式Linux開發19——Linux設備樹(萬字總結)
下一篇:Linux系統編程之行程控制