深度學習—從入門到放棄(三)多層感知器MLP
1.MLP簡介
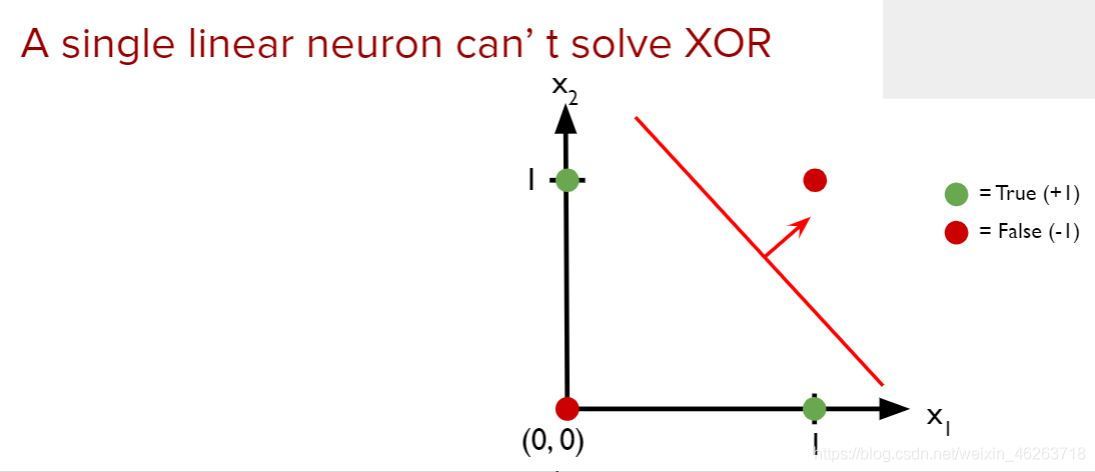
正式進入MLP之前,我們先來看看單個神經元組成的線性神經網路,由上圖可知單個神經元的神經網路無法解決像XOR這樣的非線性問題,這個時候MLP就出場了!
多層感知機(MLP,Multilayer Perceptron)也叫人工神經網路(ANN,Artificial Neural Network),除了輸入輸出層,它中間可以有多個隱藏層,最簡單的MLP只含一個隱藏層,即三層的結構,
MLP最特殊的地方就在于這個隱藏層:隱藏層的激活函式例如ReLU、Tanh、sigmoid都能夠給神經元引入非線性因素,使得神經網路可以任意逼近任何非線性函式,這樣神經網路就可以利用到更多的非線性模型中,
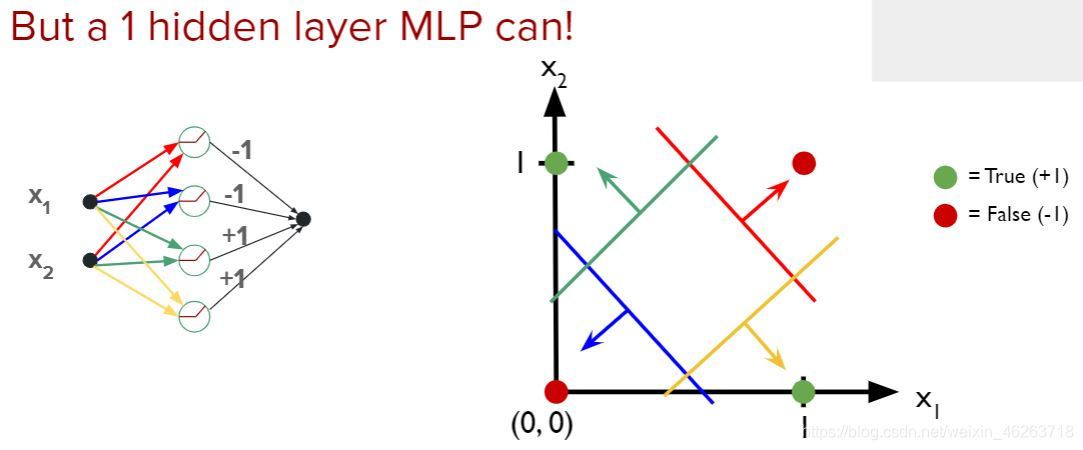
上圖為利用一個隱藏層的MLP解決XOR問題的例子,
2.ReLU
ReLU,正如之前所提到的,是MLP隱藏層激活函式的一種,
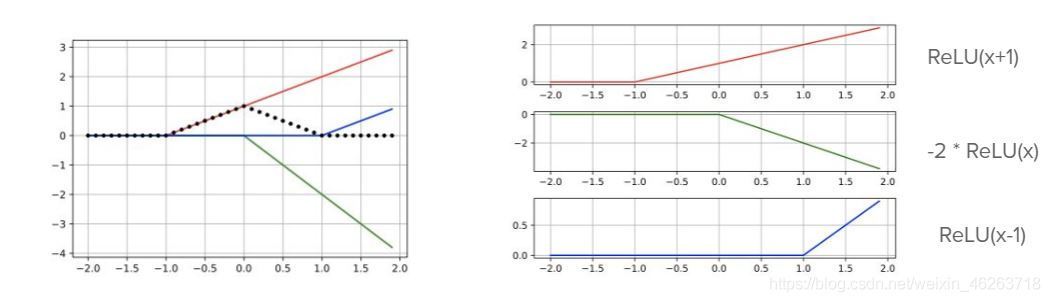
ReLU可以理解為一組分段函線性函式的集合,
y
(
x
)
=
m
a
x
(
0
,
x
+
b
)
y(x)=max(0,x+b)
y(x)=max(0,x+b),其中b為x軸的輸入的負數,按照這樣的規律我們可以將上圖拆分成 :
R
e
L
U
(
x
+
1
)
,
R
e
L
U
(
x
)
,
R
e
L
U
(
x
?
1
)
ReLU(x+1),ReLU(x),ReLU(x-1)
ReLU(x+1),ReLU(x),ReLU(x?1)
除此之外我們需要結合原函式點和點之間的斜率來進行線性修正,即combination_weights:
prev_slope = 0
for i in range(n_relus):
delta_x = x_train[i+1] - x_train[i]
slope = (y_train[i+1] - y_train[i]) / delta_x
combination_weights[i] = slope - prev_slope
prev_slope = slope
最后只需將combination_weights與relu點乘,便可得出最終結果,
有關其他激活函式
3.Pytorch實作簡單MLP
class Net(nn.Module):
def __init__(self, actv, input_feature_num, hidden_unit_nums, output_feature_num):
super(Net, self).__init__()
self.input_feature_num = input_feature_num # save the input size for reshapinng later
self.mlp = nn.Sequential() # 初始化MLP的所有層
in_num = input_feature_num # initialize the temporary input feature to each layer
for i in range(len(hidden_unit_nums)): # 創建hidden_unit_nums個隱藏層
out_num = hidden_unit_nums[i] # 定位目前處在回圈的隱藏層
layer = nn.Linear(in_num, out_num) # 用nn.Linear定義層
in_num = out_num # 定位下一個隱藏層,此時input_num變為上一層output_num
self.mlp.add_module('Linear_%d'%i, layer) # 添加到模型并命名
actv_layer = eval('nn.%s'%actv) # 激活函式 (eval 可以將object轉換為str)
self.mlp.add_module('Activation_%d'%i, actv_layer) # 添加到模型并命名
out_layer = nn.Linear(in_num, output_feature_num) # 創建輸出層
self.mlp.add_module('Output_Linear', out_layer) #添加到模型并命名
def forward(self, x):
# reshape inputs to (batch_size, input_feature_num)
# just in case the input vector is not 2D, like an image!
x = x.view(-1, self.input_feature_num)
logits = self.mlp(x) # 指定了當資料通過網路時網路需要進行的計算
return logits
input = torch.zeros((100, 2))
net = Net(actv='LeakyReLU(0.1)', input_feature_num=2, hidden_unit_nums=[100, 10, 5], output_feature_num=1).to(DEVICE)
y = net(input.to(DEVICE))
我們這里實作了一個有三個隱藏層,激活函式為leakyReLU的MLP,
4.MLP應用于分類任務
4.1交叉熵損失
交叉熵是用來衡量兩個概率分布的距離(也可以叫差別),只要把p作為正確結果(如[0,0,0,1,0,0]),把q作為預測結果(如[0.1,0.1,0.4,0.1,0.2,0.1]),就可以得到兩個概率分布的交叉熵了,交叉熵值越低,表示兩個概率分布越靠近,
交叉熵損失一般作為深度學習分類任務的目標函式,
4.2 資料準備
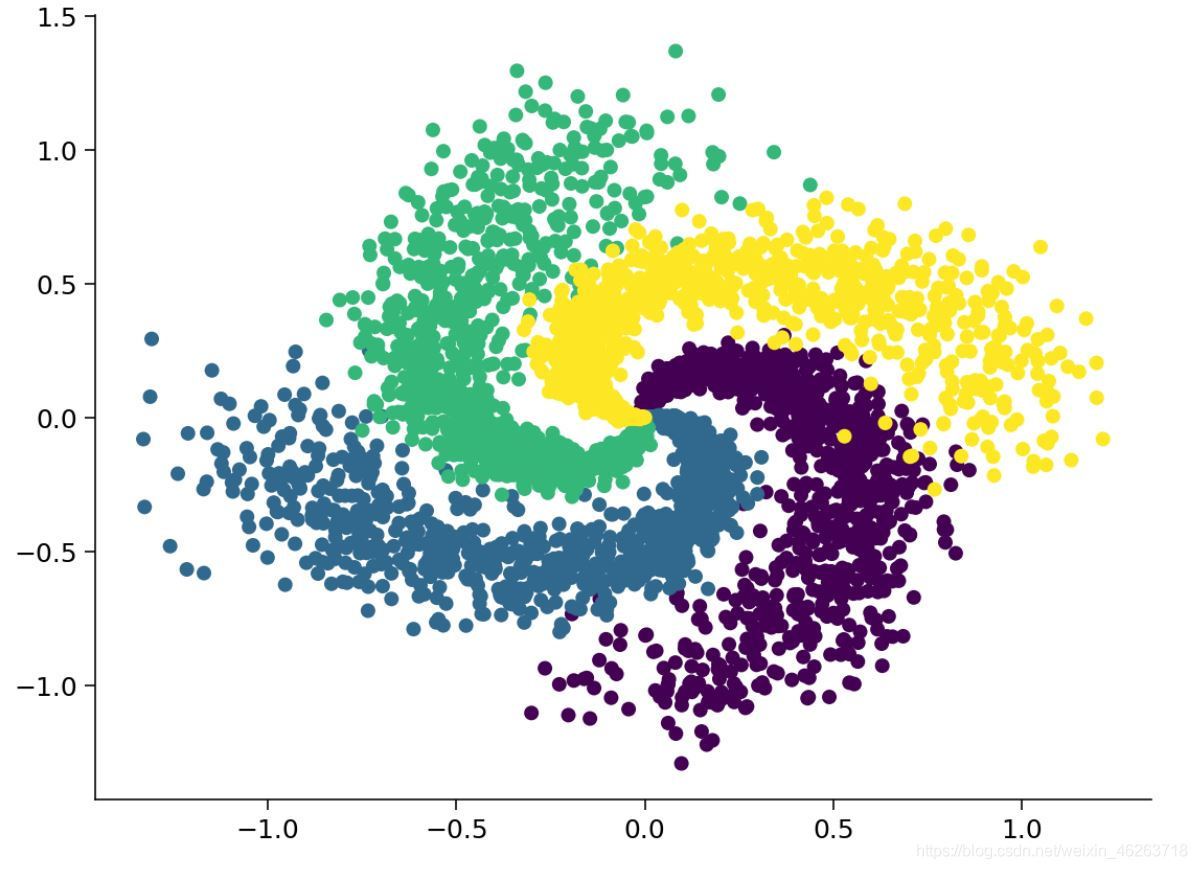
def create_spiral_dataset(K, sigma, N):
# Initialize t, X, y
t = torch.linspace(0, 1, N)
X = torch.zeros(K*N, 2)
y = torch.zeros(K*N)
# Create data
for k in range(K):
X[k*N:(k+1)*N, 0] = t*(torch.sin(2*np.pi/K*(2*t+k)) + sigma*torch.randn(N))
X[k*N:(k+1)*N, 1] = t*(torch.cos(2*np.pi/K*(2*t+k)) + sigma*torch.randn(N))
y[k*N:(k+1)*N] = k
return X, y
# Set parameters
K = 4
sigma = 0.16
N = 1000
set_seed(seed=SEED)
X, y = create_spiral_dataset(K, sigma, N)
plt.scatter(X[:, 0], X[:, 1], c = y)
plt.show()
4.2.1 Pytorch訓練集測驗集隨機劃分
1.shuffle
torch.randperm(N) :回傳一個0到n-1的陣列
def shuffle_and_split_data(X, y, seed):
# set seed for reproducibility
torch.manual_seed(seed)
# Number of samples
N = X.shape[0]
# Shuffle data
shuffled_indices = torch.randperm(N) #回傳一個0到n-1的陣列
X = X[shuffled_indices]
y = y[shuffled_indices]
# Split data into train/test
test_size = int(0.2 * N) # 20%作為測驗集
X_test = X[:test_size]
y_test = y[:test_size]
X_train = X[test_size:]
y_train = y[test_size:]
return X_test, y_test, X_train, y_train
4.3 訓練模型
def train_test_classification(net, criterion, optimizer, train_loader,
test_loader, num_epochs=1, verbose=True,
training_plot=False, device='cpu'):
net.train()
training_losses = []
for epoch in tqdm(range(num_epochs)): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
inputs = inputs.to(device).float()
labels = labels.to(device).long()
###梯度下降
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
###梯度下降
# print statistics
if verbose:
training_losses += [loss.item()]
net.eval()
def test(data_loader):
correct = 0
total = 0
for data in data_loader:
inputs, labels = data
inputs = inputs.to(device).float()
labels = labels.to(device).long()
outputs = net(inputs)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
acc = 100 * correct / total
return total, acc
train_total, train_acc = test(train_loader)
test_total, test_acc = test(test_loader)
if verbose:
print(f"Accuracy on the {train_total} training samples: {train_acc:0.2f}")
print(f"Accuracy on the {test_total} testing samples: {test_acc:0.2f}")
if training_plot:
plt.plot(training_losses)
plt.xlabel('Batch')
plt.ylabel('Training loss')
plt.show()
return train_acc, test_acc
以上為構建train_test_classification功能,包含了對于訓練資料權重的梯度下降,以及每一epoch的損失變化的計算,
set_seed(SEED)
net = Net('ReLU()', X_train.shape[1], [128], K).to(DEVICE)#用的我們之前定義的簡單MLP
criterion = nn.CrossEntropyLoss()#目標函式為交叉熵損失
optimizer = optim.Adam(net.parameters(), lr=1e-3)#優化器為Adam優化器
num_epochs = 100#訓練epoch為100
_, _ = train_test_classification(net, criterion, optimizer, train_loader,
test_loader, num_epochs=num_epochs,
training_plot=True, device=DEVICE)
5. MLP寬度 vs 深度
1.MLP的深度:
神經網路的深度,之前也說過,指的就是網路中的層數,放在MLP里就是指隱藏層的數量,那么隱藏層的數量是不是越多越有利于我們解決問題呢?
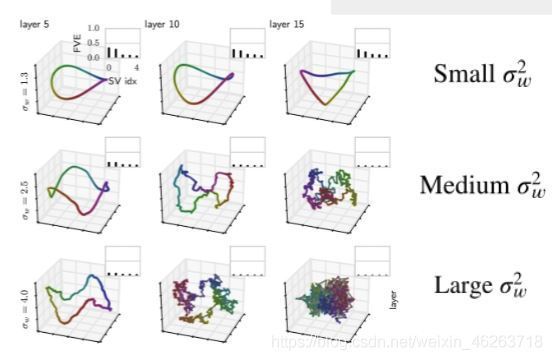
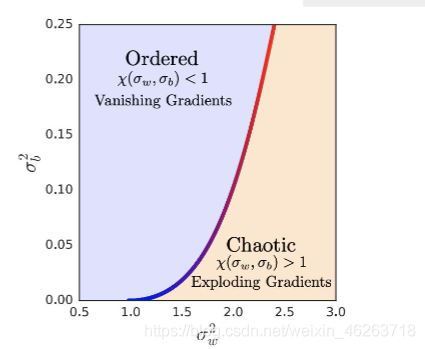
從上圖中我們不難看出隨著我們網路中權重的方差增大,網路中資料的混亂程度也越大,而這種混亂狀態隨著網路深度的增加而變得明顯,換言之,增大的權重方差也就意味著
x
(
δ
w
,
δ
b
)
>
1
x(\delta_w,\delta_b)>1
x(δw?,δb?)>1也就是說在梯度下降的反向傳播程序中可能會造成梯度爆炸,同樣
x
(
δ
w
,
δ
b
)
<
1
x(\delta_w,\delta_b)<1
x(δw?,δb?)<1會造成梯度消失
2.MLP的寬度
神經網路的寬度是指每層中神經元的數量,淺層神經網路可以通過指數級增加自己每層神經元的個數來達到和深層神經網路相同的效果,但是模型的可學習性通常會大打折扣,因此一般不會用單純的淺層神經網路,
5.1 MLP深度與模型效果的關系
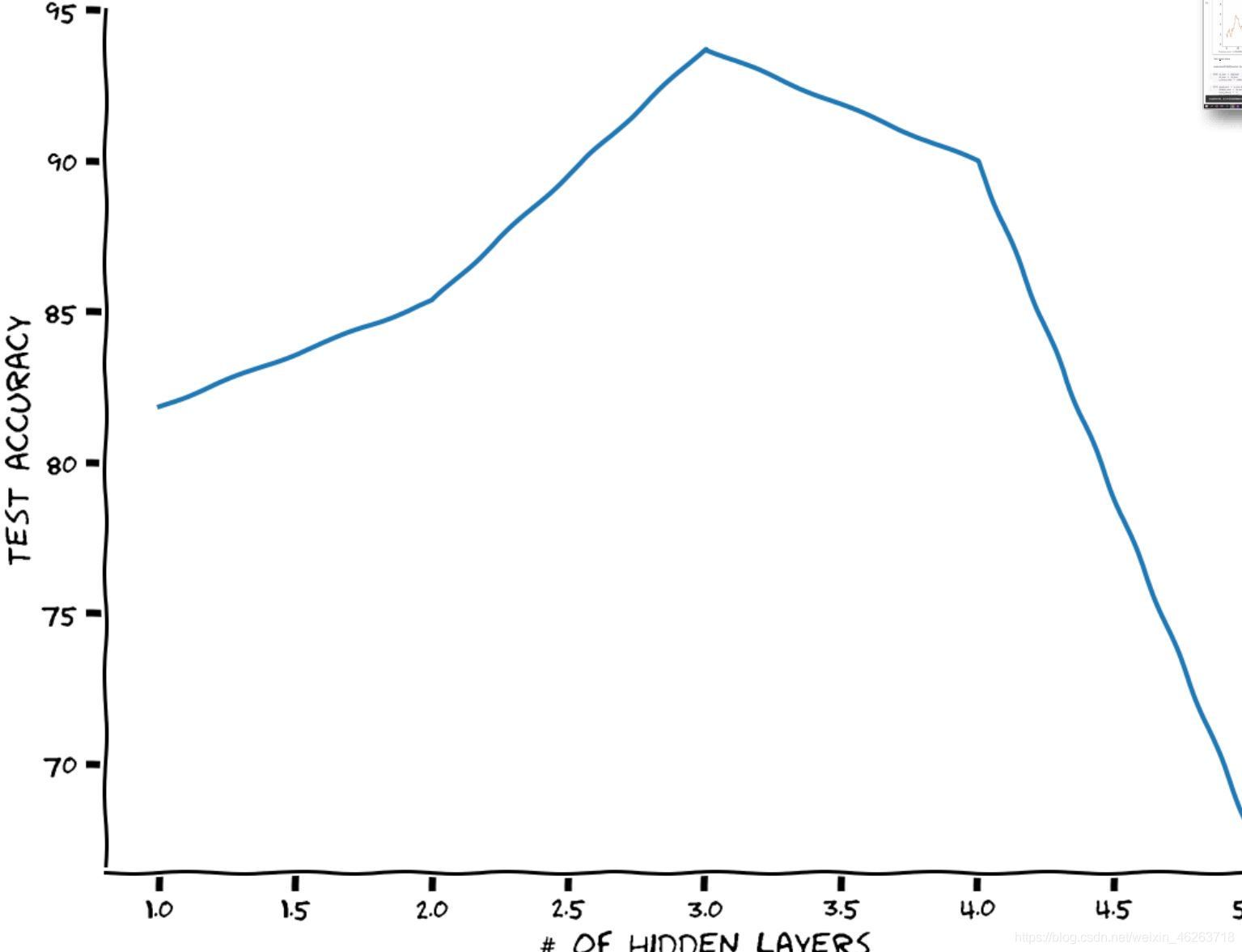
結合上文提到的對于深度的理解我們可以發現對于深層MLP而言,隱藏層的數量不是越多越好,存在一個最優隱藏層數,
5.2 MLP寬度與模型效果的關系
在這里我們先建立一個單層神經網路,為了增加網路的寬度,我們選擇在網路中添加多項式特征,隨后訓練該網路,與4.3中用MLP訓練后的結果作對比,
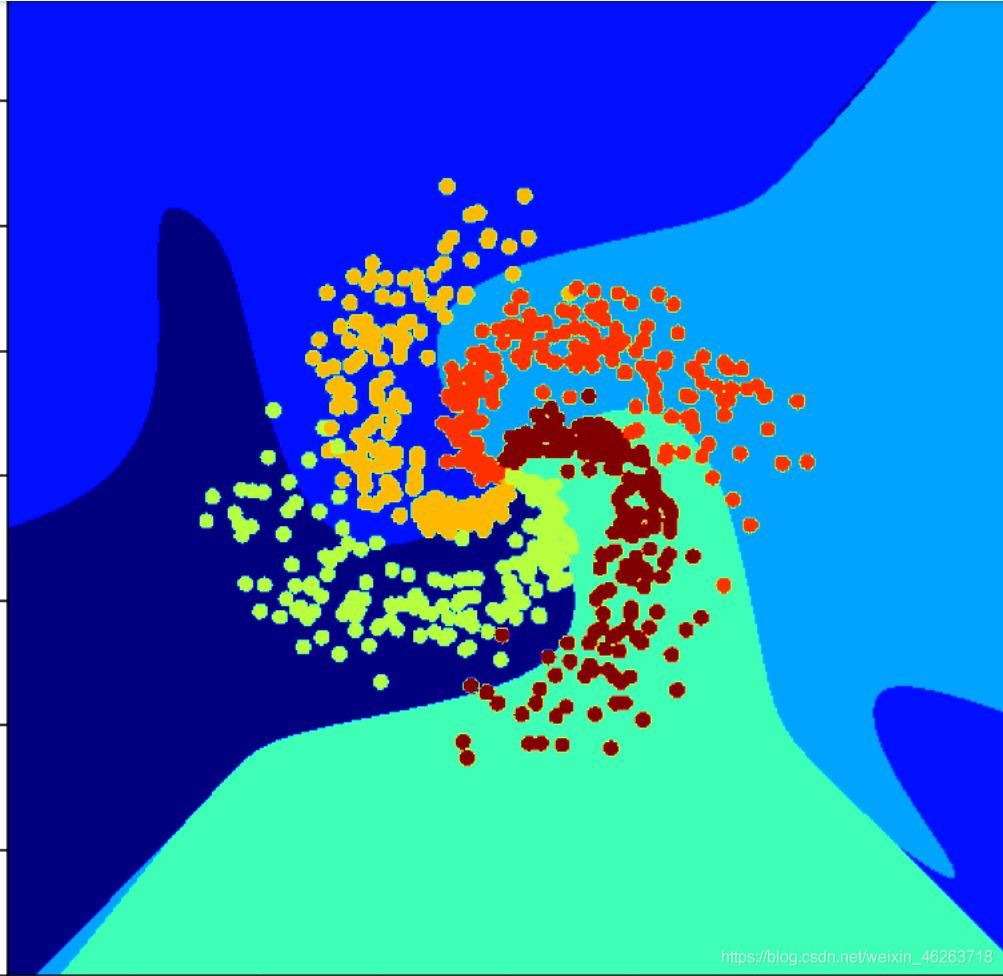
可以看出淺層神經網路的分類效果較差,對于相對簡單的分類任務都如此,可以想象到如果是真實案例的準確率會有多低,
歡迎大家關注公眾號奇趣多多一起交流!

深度學習—從入門到放棄(一)pytorch基礎
深度學習—從入門到放棄(二)簡單線性神經網路
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/294625.html
標籤:AI