賽程持續大概了兩個多月的時間,從臨近畢業到作業,算是學生時代最后一個比賽吧,遺憾的是成績并不是很理想,最后只拿到了國二,到了復賽階段又是被迫solo的局面,復賽期間體會到了在職人員的不易,白天上班,晚上熬夜打比賽,真的太難了┭┮﹏┭┮,最后,做為學生時代的“終點”,還是在此記錄下比賽程序中學習到的知識,感謝周周星的分享以及大佬們無私的開源,努力向前排優秀選手學習,
此次賽題:GitHub地址
作者:Wisley
郵箱:903953316@qq.com
GitHub:個人主頁
😄😘😇
- 一、賽題描述w
- 1、資料
- 2、評價指標
- 3、其他說明
- 二、初賽方案
- 1、訓練框架
- 2、模型結構
- (1) PinSage
- (2)RGCN
- (3)Cross Net mix
- 3、特征構建
- 1. Target Encode
- 2. 稀疏特征
- 3、embding★
- 三、復賽方案
- 1、有效嘗試
- 2、無效嘗試
- 四、賽后思考
- 參考文獻
一、賽題描述w
此次比賽基于脫敏和采樣后的資料資訊,對于給定的一定數量到訪過微信視頻號“熱門推薦”的用戶, 根據這些用戶在視頻號內的歷史n天的行為資料,通過演算法在測驗集上預測出這些用戶對于不同視頻內容的互動行為(包括點贊、點擊頭像、收藏、轉發等)的發生概率, 本次比賽以多個行為預測結果的加權uAUC值進行評分,
1、資料
資料主要包含兩個表,feed_info表與user_action表,詳細介紹說明可以查看這里,
- feed_info.csv
Feed資訊表包含了視頻(簡稱feed)的基本資訊,如authorid(視頻號作者ID)、bgm_song_id(背景音樂ID),以及manual_keyword_list(人工標注關鍵詞)等基本ID資訊,同時還包括了脫敏的文本資訊(比如視頻描述),以及音頻資訊asr、影像識別資訊ocr等均以脫敏的字串數字表示,同時賽方額外提供了融合了ocr、asr、影像、文字的多模態的內容理解特征向量,特征維度為512維, - user_action.csv
用戶行為表包含了用戶在視頻號內一段時間內的歷史行為資料(包括停留時長、播放時長和各項互動資料),該表的用戶對應資料按照時間戳順序由小到大排列,表中已提供了用戶點擊行為的標簽,
user action表中主要有七種點擊行為,其中初賽的最終分數為4個行為(查看評論、點贊、點擊頭像、轉發)的uAUC值的加權平均,復賽的最終分數為7個行為(查看評論、點贊、點擊頭像、轉發、收藏、評論和關注)的uAUC值的加權平均,
2、評價指標
本次比賽采用uAUC作為單個行為預測結果的評估指標,uAUC定義為不同用戶下AUC的平均值,計算公式如下:
u
A
U
C
=
1
n
∑
i
=
1
n
A
U
C
i
u A U C=\frac{1}{n} \sum_{i=1}^{n} A U C_{i}
uAUC=n1?i=1∑n?AUCi?
其中,n為測驗集中的有效用戶數,有效用戶指的是對于某個待預測的行為,過濾掉測驗集中全是正樣本或全是負樣本的用戶后剩下的用戶,AUCi為第i個有效用戶的預測結果的AUC(Area Under Curve),
從計算公式可以看出,我們只針對每個用戶的AUC計算并取平均,那么整體排序上,不同用戶的行為相互是不受影響的,同時由于是AUC的計算,所以結果與預測概率大小也無關,只與該用戶行為預測的排序有關,
3、其他說明
- 比賽全程不允許使用外部資料集,
- 允許使用開源的詞典、embedding和預訓練模型,以上資料和模型需在2021/07/12日期前開源,且需通過郵件的形式向組委會報備開源鏈接地址和md5,
- 復賽階段允許使用初賽階段的資料集,
二、初賽方案
初賽主要基于deep_ctr[1]的框架進行的,其中,隊友近西使用lightgbm機器學習方法,對feed表與action進行特征工程后,將特征送入lgb訓練預測,隊友kitty是借鑒baseline的深度學習方法,采用deepfm模型將連續特征、離散特征、以及可變長特征(序列文本特征)送入模型預測,兩個隊友的方案都是單任務預測,最后匯總成多任務的,這部分隊友的作業不過多介紹,主要介紹下筆者初賽的方案和思路,
1、訓練框架
由于賽題是個多標簽預測任務,考慮到復賽會在更大規模的資料上進行,所以一開始便沒有采用單任務預測的方式,而是采用了多標簽預測的方案,模型在最后的輸出層使用MMOE進行多任務輸出,
在訓練框架的設計上,受GNN異構圖的構建啟發,筆者單獨建立了user表與feed表,其中user表用于存放用戶側的相關特征,feed表用于存放視頻側的相關特征,兩個表用字典的方式進行存盤,特征名作為key進行索引,我們對feedid按照順序從0開始重新編碼為feedid_node,每個特征的排序按照重新編碼后的順序排列,因此只要知道feedid_node的編號以及特征key,就能取出該feed對應的特征,同理userid也重新編碼為了userid_node,我們在構建完兩個特征表后,在build模型時,將其放到GPU上,而在模型前向傳播時,只需將feedid_node與userid_node送進去,根據id來索引對應的特征,將其拼接即可,這樣就大大降低了記憶體開銷,普通的訓練方式是將特征與user action行為表進行拼接,以Sequence batch的方式送入模型訓練,這樣記憶體占用的大小與action的大小以及user與feed特征維度數有關,而我們采取的方式,只與user的數量與feed數量與維度有關,與action的大小無關,由于本賽題的userid與feedid是固定數量的(測驗集的userid一定出現在訓練集中,可能出現的feed賽方已全部給出),所以這樣的方式將原本需要的 a*(di+ui) 的記憶體空間,縮減到只需要 u*ui+d*di 大小的記憶體空間,其中a表示用戶行為數,d表示feed數量,u表示user數量,di表示feed特征維度,ui表示user特征維度,除此之外,對于嵌入特征,可以只保存對應序列id,在模型通過模型內部的embedding矩陣來得到特征向量,可以大大縮減記憶體和顯存的占用,在初賽階段,我們4096的batcsize 顯存占用也只有5g,且顯存占用大小與batchsize大小無關,
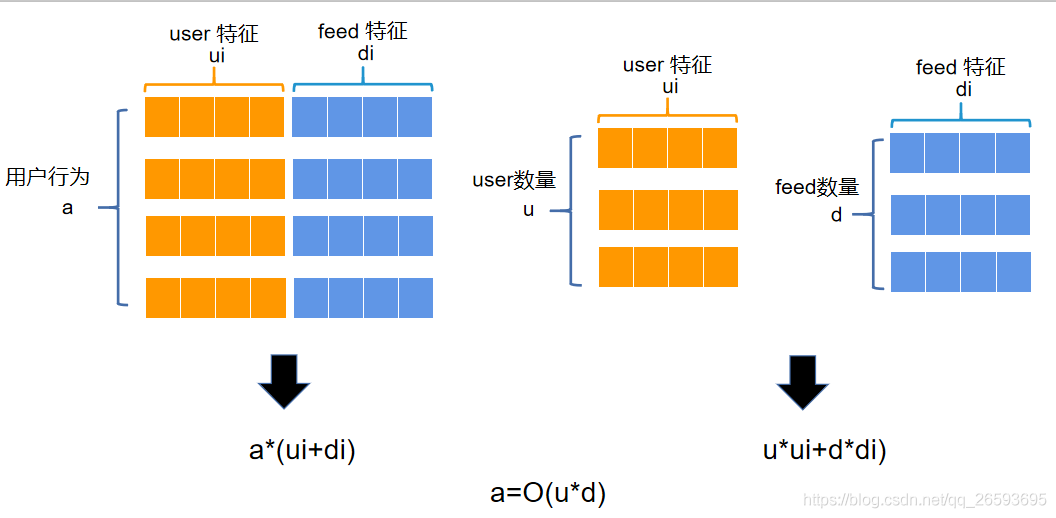
特征表建立與訓練部分示例代碼如下:
#構建feed表與user表
feed_data={}
user_data={}
#feed
feed_data['dense']=torch.from_numpy(feeds[dense_features].values.astype('float32'))
feed_data['hash_dense']=torch.from_numpy(np.hstack([dense_arry1,dense_arry2,dense_arry4,dense_arry3]).astype('float32'))
# user
user_feats=['userid','device']
for f in user_feats:
user_info[f]=user_info[f].fillna(0)
for f in ['device']:
gens=LabelEncoder()
user_info[f]=gens.fit_transform(user_info[f])
user_data[f]=torch.from_numpy(user_info[f].values)
# 放到GPU上
for f,d in user_data.items():
user_data[f]=d.to(torch.device('cuda'))
for f,d in feed_data.items():
feed_data[f]=d.to(torch.device('cuda'))
#訓練
batch_size=4096
src=train_ratings['userid'].apply(lambda x: userid2nid[x]).values
dst=train_ratings['feedid'].apply(lambda x: feedid2nid[x]).values
for ind in tqdm(range(0,n_pos//batch_size+1)):
batch=batch_index[ind*batch_size:(ind+1)*batch_size]
batch_src=src[batch] # user node
batch_dst=dst[batch] # feed node
logits = model(batch_src,batch_dst)
2、模型結構
由于筆者在校期間,自研過一些GNN相關知識,而最近GNN在推薦領域也是炒的熱火朝天,所以在比賽初期一直想嘗試使用GNN 的一些模型,這部分模型是基于DGL實作的,
(1) PinSage
PinSage是斯坦福和Pinterest公司合作提出的工業級GCN推薦系統,并將其應用在了Pinterest上,PinSage模型使用隨機游走和圖卷積來捕獲圖結構的特征以及節點的特征,以生成節點的嵌入表示,該演算法的特點在于通過采樣節點的鄰居并動態地從采樣鄰居構建計算圖,實作了有效的區域的卷積,從而在訓練時不需要在整張圖上進行操作,這里我們可以對user節點的feed鄰居進行采樣,來構建feed節點的子圖,采樣方式同樣是選擇隨機游走的方式,
關于GCN部分 筆者嘗試了GAT、GraphSAGE等 效果都不理想,嘗試將學到的node embedding與原始特征的embedding進行合并,通過DNN輸出,有比較大的提升,但是線上分數只有0.63左右,后來發現不使用GNN中的embedding反倒分數更高,遂放棄了這個方案,pinsage代碼參考
(2)RGCN
在PinSage中,采用二部圖進行構圖,這本身可以當作一個異質的圖神經網路,而不同任務關系就是異質的邊關系,因此筆者又嘗試構建異質圖神經網路,并利用RGCN作為圖卷積進行訊息聚合,對于不同的邊關系(比賽中我們用不同的點擊任務構建邊),都有一組可學習的引數矩陣對應(圖卷積),異構圖RGCN的代碼可以參考DGL官方手冊示例代碼,如下:
import dgl.nn as dglnn
class RGCN(nn.Module):
def __init__(self, in_feats, hid_feats, out_feats, rel_names):
super().__init__()
self.conv1 = dglnn.HeteroGraphConv({
rel: dglnn.GraphConv(in_feats, hid_feats)
for rel in rel_names}, aggregate='sum')
self.conv2 = dglnn.HeteroGraphConv({
rel: dglnn.GraphConv(hid_feats, out_feats)
for rel in rel_names}, aggregate='sum')
def forward(self, graph, inputs):
# inputs are features of nodes
h = self.conv1(graph, inputs)
h = {k: F.relu(v) for k, v in h.items()}
h = self.conv2(graph, h)
return h
經過實驗發現,對于比賽資料,將與用戶互動的商品作為邊,比以點擊任務作為邊關系效果要好,另外對于卷積操作,普通的圖卷積也要優于其他卷積操作,相比Pinsage,異質RGCN的表現要更好,初賽分數能達到0.65左右,經過進一步的調參和特征優化,可以達到0.66左右的分數,但是后續的一周時間里筆者卻始終沒有繼續上分了,所以不得已,還是把注意力放在了傳統NN方法上,
(3)Cross Net mix
在不同的業務場景下,CTR任務更多是依賴細致的特征工程,一般來說,最簡單的線性模型就是將原始特征進行組合變換,它非常容易理解并且容易擴展,但是表達能力有限,而有效的組合特征通常需要人工不斷的探索與嘗試,NN方法,則是為了代替費時費力的手工特征,讓模型自動探索和組合高階特征,現有的很多成熟且有效的NN模型,如Deepfm、DIN、AutoInt,都是嘗試從不同的方面來提高特征的表達能力,使模型能更有效地挖掘離散、連續、文本序列等特征的組合,理論上,DNN能夠在特定平滑假設下以任意的精度逼近任意函式,而在實際中大多數函式并不是任意的,所以DNN能夠利用可行的引數量達到很好的效果,通過DNN能夠對離散和序列等特征的Embedding向量以及非線性激活函式學習到高階的特征組合,并且殘差網路使得我們能夠訓練很深的網路,然而隱式的學習了所有的特征組合,對于模型效果和學習效率可能并不都是有利的,而且缺乏一定的可解釋性,所以FM和FFM 提出了顯式去構造特征的二階或者更高階的組合,但是淺層的結構反而限制了特征的表達能力,更高階的擴展則產生了大量額外的計算開銷,并且在比賽中,很多有效的特征組合往往都是低階的,因此,作者提出了一種高效的方式進行顯性的特征組合,Cross Network
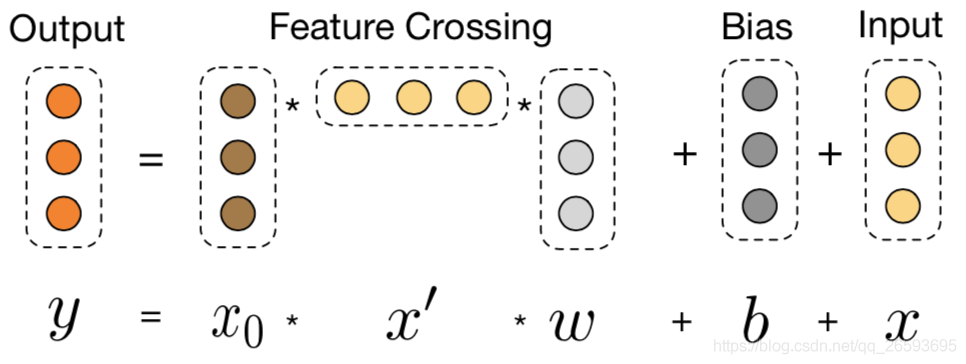
每一層的神經元數量都相同而且等于輸入向量
X
0
X_0
X0?的維度,每一層都有如下公式所示(都是列向量),其中函式
f
f
f擬合的是
X
l
+
1
X_{l+1}
Xl+1??
X
l
X_l
Xl?的殘差,進一步
X
l
+
1
=
X
0
X
l
T
W
l
+
B
l
+
X
l
=
f
(
X
l
,
W
l
,
B
l
)
+
X
l
X_{l+1}=X_{0} X_{l}^{T} W_{l}+B_{l}+X_{l}=f\left(X_{l}, W_{l}, B_{l}\right)+X_{l}
Xl+1?=X0?XlT?Wl?+Bl?+Xl?=f(Xl?,Wl?,Bl?)+Xl?
相比DNN,交叉網路顯示地構建了交叉項,且引數量要小很多,同時每一層就是特征的一次交叉組合,模型更具有可解釋性,進一步,受MOE結構啟發DCN-M模型對DCN進行了改進,將W變成引數矩陣,將矩陣分解至多個子空間,隨后通過門控機制來對這些子空間進行融合,其有效地學習顯式和隱式特征交叉,使模型高效、簡單的同時,增強了表達能力,如下圖所示,
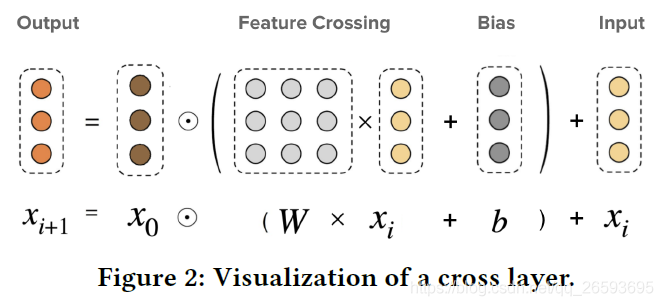
在比賽中,我們將稀疏特征與連續特征以及embedding特征拼接后,送入cross net,專家數默認4,交叉網路層數4,最后與DNN的輸出拼接,經過一層線性層輸出,線上能達到0.669左右的成績,相比于之前GNN的表現都要好很多,在deep_ctr中可以直接呼叫:
CrossNetMix(128*3+64,layer_num=4)
筆者通過消融實驗,對比deepfm,在相同特征的情況下,cross network相比deepfm有將近一個百的提升,
3、特征構建
這里簡單列舉下比較有用的特征,一些原始特征輸入不過多解釋,
1. Target Encode
對feedid、authorid、userid等或進行組合,通過滑窗(前N天)計算label的均值作為編碼后的特征,(詳細可在代碼中查看)
2. 稀疏特征
maunual_keyword_list等序列特征取其中的id作為稀疏特征,或者使用tfidf+svd得到embdding,
3、embding★
這個特征算是整個比賽中的強特了,發現前排很多隊伍都是靠這個上分的,類似GNN的思想,通過groupby userid得到feedid序列,當作句子來訓練w2v,得到feedid的embedding,這里嘗試了分任務embedding,效果遠沒有直接把所有互動做embedding好,我們認為,比賽方提供的資料可能是已經粗排后的結果,給用戶曝光的feed其實在一定程度上表現了用戶一定的喜好趨勢,同時如果分任務做emb也會造成資訊泄露的問題,這里的embedding可以嘗試多種的組合,對feedid和userid都可以做,如果顯存不夠的話可以用svd分解來降維,通過一些實驗我們發現最有用的還是通過userid對feedid的emb,同時我們還嘗試了deepwalk和node2vec的方式,和groupby的方式差別不大,
三、復賽方案
復賽由于資料量是初賽的10倍,所以大多數選手的主要作業是如何在有限的記憶體下來復現初賽的方案,筆者初賽時考慮了復賽的情況,所以并不需要對原本的方案欄位外的改動,在統計特征方面,由于測驗集不可見,所以在做特征的時候,保存了訓練集的統計特征分布,用于推斷時提供給測驗集,在不做任何優化改進時,復賽第一次提交就有0.695的分數,
1、有效嘗試
1、feedid emb 的改進,采用sg 和hs 模式分別訓練emb最后進行拼接,
2、通過計算相關系數,發現有些任務比較相關,可以采用共享線性層的方式,
3、DNN層使用BN和dropout 增加模型的泛化能力
4、訓練上采用 lookahead+admw ,兩個epoch即可,
5、 借鑒DIN的結構,增加user的行為序列輸入,通過attention pool得到興趣feed的emb,(這部分可以構建一個新的模型,但是最后分數和cross network是差不多的,可以作為最后的多模融合,詳細可以參考deep_ctr中的代碼以及筆者git上的代碼),也有前排選手是借鑒transform的結構來做,并取得了不錯的效果,但是筆者使用tansformer的效果非常差,等后面開源了可以學習下大佬是怎么做的,
2、無效嘗試
1、對action表進行負采樣(負樣本的定義有多種,但是都不太理想),由于線上資料是非常寶貴的,雖然存在噪聲的可能,但是我們沒有一個有效的判斷噪聲的方法,所以如無必要,盡量用全量資料訓練是最好的,
2、userid 的embedding,這部分的做法和feedid的emb是一樣的,但是效果并不明顯,在初賽還有降分的跡象,
3、增加ple層,PLE號稱是比MMOE在多任務上有更好的表現,筆者基于torch實作了ple層,線下確實有一點點提升,但是線上結果和mmoe是差不多的,引數量卻更大,所以最后放棄了這個方案,
4、 增加各類特征embedding的維度,增加dnn層數、expert數等,均無法提升,反而會有過擬合的風險,
四、賽后思考
(1)在初賽時,統計特征、目標編碼等方式,對分數有較為明顯的提升,但是在復賽階段,這部分卻沒那么重要,筆者在復賽時,意外發現,即使去除所有互動的統計特征,只保留embedding特征,模型依然能達到相當甚至更好的分數,
(2)根據現在已開源的前排方法,筆者分析主要差距是沒有對emb做進一步深入嘗試,對其他id做emb+svd以及對文本特征做tfidf+svd 會有微妙的效果,我們在一些長文本特征上采用截斷的方式也不是很合理,不同特征組合也會相互影響,同時發現在復賽階段,統計特征可能對模型預測還會有一定的副作用,但是沒有進一步去研究和實驗,
(3)賽后思考了下,為什么幾種GNN的建模都不理想,我們使用的都是訊息傳遞的框架,賽方給的主要是feed側的特征,那么不管是user node還是feed node 基本都是由feed emb的資訊傳遞產生的,而有的user互動非常少,有的user互動feed特別多,這種不平衡是否會影響節點的表達? 另外GNN本身就存在過平滑的問題,最近的研究發現,GCN中的線性變換會加速模型的退化,是否我們可以簡單地只構建一層GCN 進行資訊聚合? 本次雖然在最后比賽中并沒有使用GNN模型,但是通過groupby userid 對feedid預訓練和GNN有異曲同工的作用,而這部分的提升是非常大的,這說明GNN 的結構是非常值得借鑒的,那么實作一個端到端的GNN+DNN的模型,是否會比預訓練+dnn的形式要更好更優雅,
(4) 本題用戶的行為序列并未表現出很強的時序性,雖然資料按照用戶的點擊時間進行了排序,但是當使用時序模型如LSTM去提取深度特征時,表現并不好,筆者認為,對于視頻推薦的用戶主體,點擊事件不太受視頻的曝光序列影響,它與推薦不同,并沒有表現出很強的時序性,比如:上個星期我喜歡并點贊的視頻,大概率這星期還會喜歡(但推薦曝光的視頻會根據短期的用戶興趣進行推薦),
以上是筆者自己的一些思考和猜想,歡迎讀者討論發表有趣的觀點一起討論,
在此再次感謝前人無私的開源與分享,我們是站在巨人的肩膀才看的更高更遠!
參考文獻
【1】DeepCTR: Easy-to-use,Modular and Extendible package of deep-learning based CTR models ,Weichen Shen
【2】 「【Paper】Deep & Cross Network for Ad Click Predictions - 一只背影 - 博客園」- https://www.cnblogs.com/cling-cling/p/9922766.html
【3】 「深度特征工程:[google]DCN-M: Improved Deep & Cross Network for Feature Cross Learning in Web-scale Learning_knight的博客-CSDN博客」- https://blog.csdn.net/u012852385/article/details/109197384
【4】 「Deep and Cross Network原理及實作 Andante」- https://nirvanada.github.io/2017/12/14/DCN/
【5】 「deepctr.models.dcnmix module — DeepCTR 0.8.7 documentation」- https://deepctr-doc.readthedocs.io/en/latest/deepctr.models.dcnmix.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/294665.html
標籤:其他
上一篇:分布式搜索引擎ElasticSearch(六)--- Java API 操作ES
下一篇:Hive中的多維分析函式