一、回歸的主要應用場景
1、股市預測(Stock market forecast)
輸入:過去10年股票的變動、新聞咨詢、公司并購咨詢等
輸出:預測股市明天的平均值
2、自動駕駛(Self-driving Car)
輸入:無人車上的各個sensor的資料,例如路況、測出的車距等
輸出:方向盤的角度
3、商品推薦(Recommendation)
輸入:商品A的特性,商品B的特性
輸出:購買商品B的可能性
二、Regression的三個步驟
Step1 確定model
在regression中我們可以使用Linear Model(線性模型
y
=
b
+
w
?
x
\mathrm{y}=\mathrm{b}+\mathrm{w} \cdot \mathrm{x}
y=b+w?x)
Function set:
y
=
b
+
Σ
w
i
X
i
{
X
i
:
an attribute of input
X
(
Features
)
ω
i
:
Weight of
X
i
b
: bias
y=b+\Sigma w_{i} X_{i}\left\{\begin{array}{l}X_{i}: \text { an attribute of input } X(\text { Features }) \\ \omega_{i}: \text { Weight of } X_{i} \\ b \text { : bias }\end{array}\right.
y=b+Σwi?Xi?????Xi?: an attribute of input X( Features )ωi?: Weight of Xi?b : bias ?
step2 Goodness of function
Loss function — 衡量一組引數的好壞
L
(
f
)
=
L
(
w
,
b
)
=
∑
i
=
1
n
[
y
^
i
?
(
b
+
w
?
x
i
)
]
2
L(f)=L(w, b)=\sum_{i=1}^{n}\left[\hat{y}^{i}-\left(b+w \cdot x^{i}\right)\right]^{2}
L(f)=L(w,b)=i=1∑n?[y^?i?(b+w?xi)]2
L
o
s
s
f
u
n
c
t
i
o
n
{
I
n
p
u
t
:
f
u
n
c
t
i
o
n
O
u
t
p
u
t
:
s
c
o
r
e
Loss function \begin{cases} Input: function\\ Output: score \end{cases}
Lossfunction{Input:functionOutput:score?
Step3 Pick the best function
formulation:
{
f
?
=
arg
?
min
?
f
(
f
)
w
?
?
b
?
=
arg
?
min
?
w
.
b
L
(
w
?
b
)
=
arg
?
min
?
w
,
b
∑
i
=
1
n
[
y
^
i
?
(
b
+
w
?
x
i
)
]
2
\left\{\begin{array}{l}f^{*}=\arg \min _{f}(f) \\ \left.w^{*} \cdot b^{*}=\arg \min _{w . b} L(w \cdot b)=\arg \min _{w, b} \sum_{i=1}^{n} [ \hat{y}^{i}-\left(b+w \cdot x^{i}\right)\right]^{2}\end{array}\right.
{f?=argminf?(f)w??b?=argminw.b?L(w?b)=argminw,b?∑i=1n?[y^?i?(b+w?xi)]2?
Parameter Description
x
i
{x}^{i}
xi:用上標來表示一個完整的object的編號(下標表示該object中的component)
y
^
i
\hat{y}^{i}
y^?i:用
y
^
i
\hat{y}^{i}
y^?i表示?個實際觀察到的object輸出,上標為i表示是第i個object
注:由于regression的輸出值是scalar,因此 里面并沒有component,只是?個簡單的數值;但是未來如果考慮structured Learning的時候,我們output的object可能是有structured的,所以我們還是會需要用上標下標來表示?個完整的output的object和它包含的component
我們可以通過Gradient Desent(梯度下降)對其進行求解
只要
L
(
f
)
L(f)
L(f)是可微分的,gradient desent都可以對
f
f
f處理得到最佳的parameters
三、Gradient Desent(梯度下降演算法)
1、單個引數
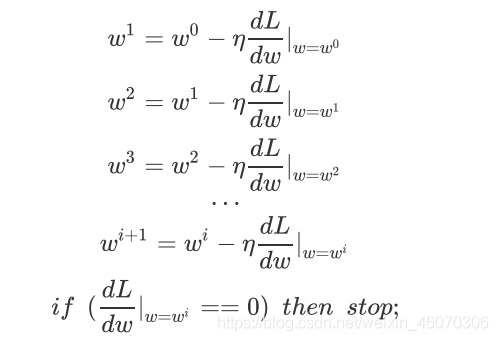
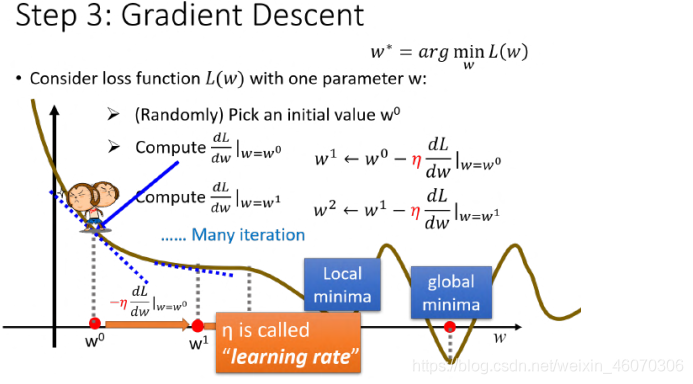
此時,
w
i
w_{i}
wi?對應的斜率為0,找到local minima,因為local minima不一定為global minima,所以Gradient Desent找出來的并不一定為最優解,
但是我們并不需要擔心這個問題,在linear regression中的loss function為凸函式,不存在local minima,所以我們找到的一定是global minima,
2、多個引數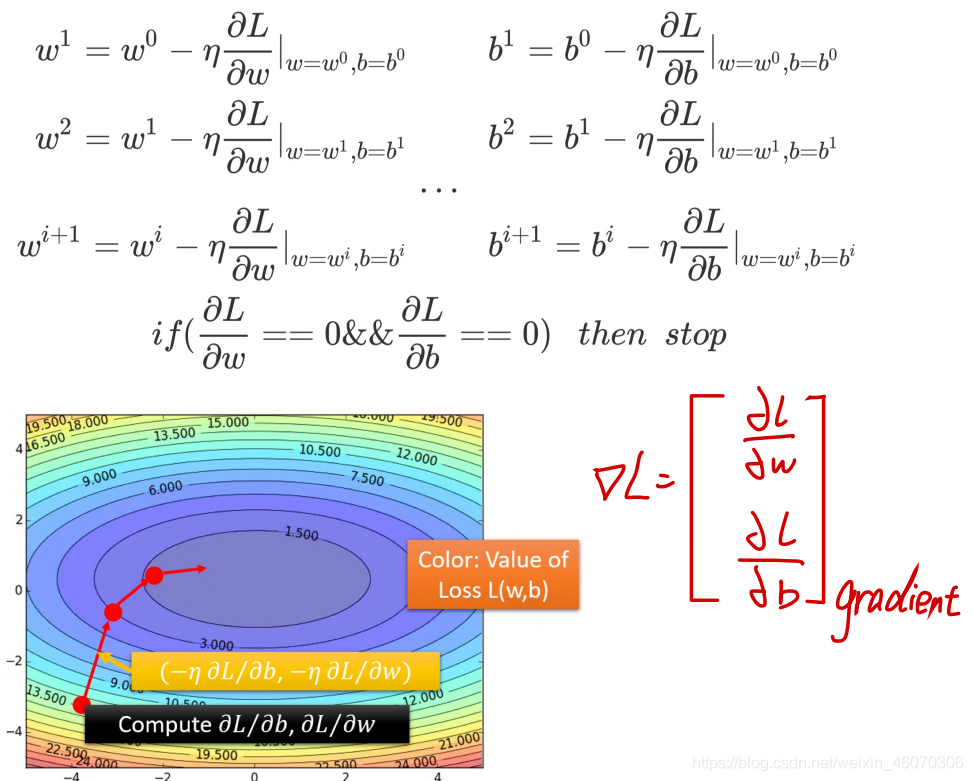
1、gradient為
?
L
?
w
\frac{\partial L}{\partial w}
?w?L?和
?
L
?
b
\frac{\partial L}{\partial b}
?b?L?組成的vector,該等高線的法線方向(圖中紅箭頭的方向)
2、
(
?
η
?
L
?
b
,
?
η
?
L
?
w
)
\left(-\eta \frac{\partial L}{\partial b},-\eta \frac{\partial L}{\partial w}\right)
(?η?b?L?,?η?w?L?)的作用為:讓原先的
(
ω
i
,
b
i
)
\left(\omega^{i}, b^{i}\right)
(ωi,bi)朝著gradient的方向前進
3、
η
\eta
η(learning rate)的作用為控制每次跨度
4、最終經過多次迭代,使得gradient達到最小點
四、How can we do better?
1、考慮更復雜的model
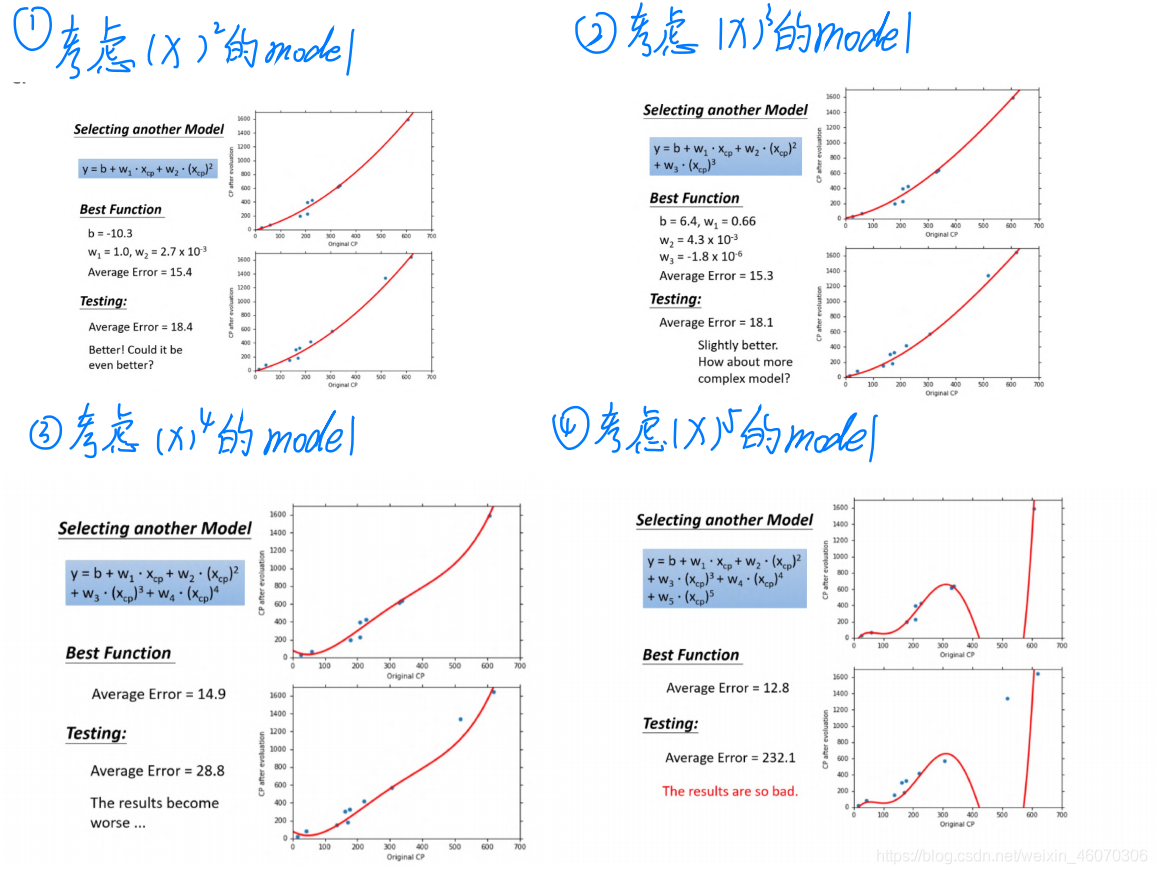 由圖中的結果我們可以發現:training data的error一定小于testing data,但是我們更加應該關心testing data的error,
由圖中的結果我們可以發現:training data的error一定小于testing data,但是我們更加應該關心testing data的error,
在training data中:隨著的高次項的增加,其Average Error就減小,但我們并不關心training data中的error,我們更關心model在testing data中的表現,
在testing data中:model復雜到一定的程度之后,error不但不減小,反而會暴增(over fitting現象)
因此,model并非是越復雜越好,我們需要找到一個合適的model
2、我們還可以考慮more features
重新設計model(已預測寶可夢的cp值為例)
Q : 我們能期望根據已有的寶可夢進化前后的資訊,預測出某只寶可夢在進化后的cp大小,
若只考慮進化前后的cp,顯然過于片面,我們可以加入物種這個feature
model:
If
x
s
=
x_{s}=
xs?= Pidgey,
y
=
b
1
+
w
?
x
c
p
\quad y=b_{1}+w \cdot x_{c p}
y=b1?+w?xcp?
If
x
s
=
x_{s}=
xs?= Weedle,
y
=
b
2
+
w
2
?
x
c
p
y=b_{2}+w_{2} \cdot x_{c p}
y=b2?+w2??xcp?
If
x
s
=
x_{s}=
xs?= Caterpie,
y
=
b
3
+
w
3
?
x
c
p
y=b_{3}+w_{3} \cdot x_{c p}
y=b3?+w3??xcp?
If
x
s
=
x_{s}=
xs?= Eevee,
y
=
b
4
+
w
4
?
x
c
p
y=b_{4}+w_{4} \cdot x_{c p}
y=b4?+w4??xcp?
我們參考
δ
(
x
)
\delta(x)
δ(x)來做判斷,當條件為true,
δ
(
x
)
\delta(x)
δ(x)=1;當條件為false,
δ
(
x
)
\delta(x)
δ(x)=0
從而我們得到
y
=
(
b
1
+
w
1
?
x
c
p
)
δ
(
x
s
=
p
i
d
g
e
y
)
+
(
b
2
+
w
2
x
c
p
)
δ
(
x
s
=
y=\left(b_{1}+w_{1} \cdot x_{c p}\right) \delta\left(x_{s}=p_{i} d g e y\right)+\left(b_{2}+w_{2} x_{c p}\right) \delta\left(x_{s}=\right.
y=(b1?+w1??xcp?)δ(xs?=pi?dgey)+(b2?+w2?xcp?)δ(xs?= weede
)
)
)
+
(
b
3
+
w
3
?
x
c
p
)
δ
(
x
s
=
\quad+\left(b_{3}+w_{3} \cdot x_{c p}\right) \delta\left(x_{s}=\right.
+(b3?+w3??xcp?)δ(xs?= Caterpie
)
+
(
b
4
+
w
4
?
x
c
p
)
δ
(
x
s
=
)+\left(b_{4}+w_{4} \cdot x_{c p}\right) \delta\left(x_{s}=\right.
)+(b4?+w4??xcp?)δ(xs?= Eevee)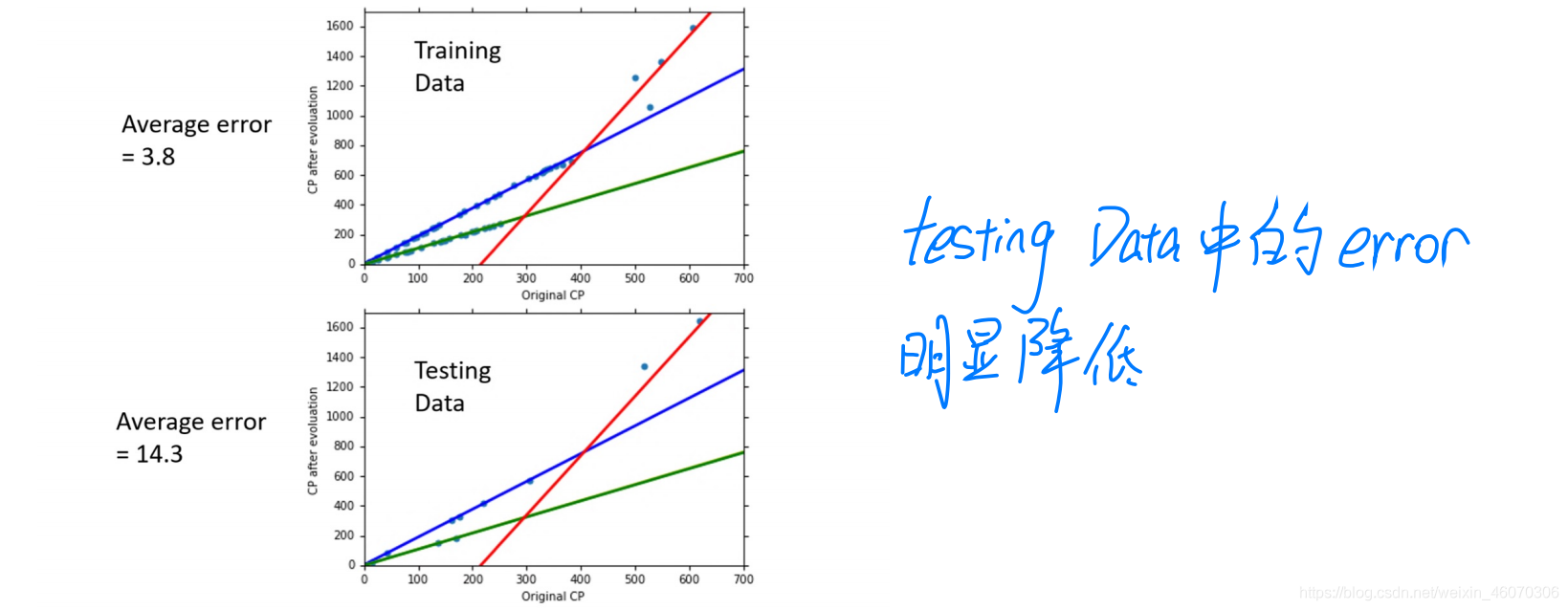
3、我們加入更多的features再做嘗試
我們繼續加入Hp值( x нр x_{\text {нр }} xнр ?),height值( x h x_{\text {h }} xh ?),weight值( x w x_{\text {w }} xw ?)這些features:
model:
if
x
s
=
x_{s}=
xs?= Pidgey
:
y
′
=
b
1
+
w
1
?
x
c
p
+
w
5
?
(
x
φ
p
)
2
: y^{\prime}=b_{1}+w_{1} \cdot x_{c p}+w_{5} \cdot\left(x_{\varphi p}\right)^{2}
:y′=b1?+w1??xcp?+w5??(xφp?)2
if
x
s
=
x_{s}=
xs?= weedle:
y
′
=
b
2
+
w
2
?
x
φ
+
W
6
?
(
x
c
p
)
2
y^{\prime}=b_{2}+w_{2} \cdot x_{\varphi}+W_{6} \cdot\left(x_{c p}\right)^{2}
y′=b2?+w2??xφ?+W6??(xcp?)2
if
x
s
=
x_{s}=
xs?= Caterpie:
y
′
=
b
3
+
w
3
?
x
c
p
+
W
7
?
(
x
p
p
)
2
y^{\prime}=b_{3}+w_{3} \cdot x_{c} p+W_{7} \cdot\left(x_{p p}\right)^{2}
y′=b3?+w3??xc?p+W7??(xpp?)2
if
X
s
=
X_{s}=
Xs?= Eevee:
y
′
=
b
4
+
w
4
?
x
q
+
W
8
?
(
x
c
p
)
2
y^{\prime}=b_{4}+w_{4} \cdot x_{q}+W_{8} \cdot\left(x_{c p}\right)^{2}
y′=b4?+w4??xq?+W8??(xcp?)2
這個我們都變成二次方,并加入更多的features
y
=
y
1
+
w
9
?
x
k
p
+
w
10
?
(
x
n
p
)
2
+
w
11
?
x
h
+
w
12
?
(
x
h
)
2
+
w
13
?
x
w
+
w
14
?
(
X
w
)
2
y=y^{1}+w_{9} \cdot x_{k p}+w_{10} \cdot\left(x_{n p}\right)^{2}+w_{11} \cdot x_{h}+w_{12} \cdot\left(x_{h}\right)^{2}+w_{13} \cdot x_{w}+w_{14}-\left(X_{w}\right)^{2}
y=y1+w9??xkp?+w10??(xnp?)2+w11??xh?+w12??(xh?)2+w13??xw?+w14??(Xw?)2
將同樣的data帶入到model中算出的training error=1.9,但是,testing error=102.3!這么復雜的model很大概率會發生 overfitting!
(按照我的理解,overfitting實際上是我們多使用了?些input的變數或是變數的高次項使曲線跟training data擬合的更好,但不幸的是這些項并不是實際情況下被使用的,于是這個model在testing data上會表現得很糟糕),overfitting就相當于是那個范圍更大的韋恩圖,它包含了更多的函式更大的范圍,代價就是在準確度上表現得更糟糕)
4、解決overfitting的方法之一:Regularzation(正則化)

regularization可以使我們曲線變得more smooth(受到noise的干擾降低)
training data上的error變大,但是testing data上的error變小,
我們更喜歡較為平滑的function,因為它對noise并不sensitive,但又不能太過平滑(失去對data的擬合能力)因此我們通過調整
λ
\lambda
λ來找到合適的平滑度
五、代碼演示
1、匯入模塊
import numpy as np
import matplotlib.pyplot as plt
#可視化匯入的包
from ipywidgets import
2、準備資料
x_data = [338., 333., 328., 207., 226., 25., 179., 60., 208., 606.]
y_data = [640., 633., 619., 393., 428., 27., 193., 66., 226., 1591.]
x = np.arange(-200,-100,1)
y = np.arange(-5,5,0.1)
#損失函式
Z = np.zeros((len(x), len(y)))
for i in range(len(x)):
for j in range(len(y)):
b = x[i]
w = y[j]
Z[j][i] = 0
for n in range(len(x_data)):
Z[j][i] = Z[j][i] + (y_data[n] - b - w*x_data[n])**2
Z[j][i] = Z[j][i] / len(x_data)
3、訓練函式
#訓練函式,我把原始的封裝了下,方便下面可視化呼叫
def train(lr,iteration):
# 線性回歸原始版
b = -120
w = -4
b_history = [b]
w_history = [w]
for i in range(iteration):
b_grad=0.0
w_grad=0.0
for n in range(len(x_data)):
b_grad= b_grad-2.0*(y_data[n]-b-w*x_data[n])*1.0
w_grad= w_grad-2.0*(y_data[n]-b-w*x_data[n])*x_data[n]
# 更新引數
b -= lr * b_grad
w -= lr * w_grad
b_history.append(b)
w_history.append(w)
return b_history,w_history
4、顯示結果影像
#顯示影像
def plot(b_history,w_history):
plt.contourf(x, y, Z, 50, alpha=0.5, cmap=plt.get_cmap('jet'))
plt.plot([-188.4], [2.67], 'x', ms=12, markeredgewidth=3, color='orange')
plt.plot(b_history, w_history, 'o-', ms=3, lw=1.5, color='black')
plt.xlim(-200, -100)
plt.ylim(-5, 5)
plt.xlabel(r'$b$', fontsize=16)
plt.ylabel(r'$w$', fontsize=16)
plt.show()
#原始呼叫lr=0.0000001
iteration = 100000
lr = 0.0000001
b_history,w_history=train(lr,iteration)
plot(b_history,w_history)
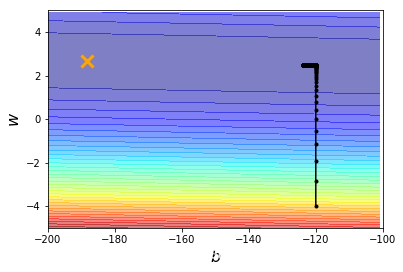
當然,我們還可以根據調整lr的值,進一步尋找到最佳的一組【w,b】
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/294861.html
標籤:AI
上一篇:Python3.6.8 + Pytorch1.4.0 + CUDA10.0 + openCV4.2.0 配置mmtracking
下一篇:密碼學基本概念與古典密碼