Kafka史上最詳細原理總結
- 一、概念理解
- (1)產生背景
- (2)Kafka的特性
- (3)Kafka場景應用
- (4)Kafka一些重要設計思想
- 二、訊息佇列通信的模式
- (1)點對點模式
- (2)發布訂閱模式
- 三、Kafka的架構原理
- (1)基礎架構與名詞解釋
- (2)作業流程分析
- (1)發送資料
- (2)保存資料
- (3)消費資料
kafka系列
Kafka史上最詳細原理總結(一)
kafka常用的shell命令(二)
一、概念理解
Kafka是最初由Linkedin公司開發,是一個分布式、支持磁區的(partition)、多副本的(replica),基于zookeeper協調的分布式訊息系統,它的最大的特性就是可以實時的處理大量資料以滿足各種需求場景:比如基于hadoop的批處理系統、低延遲的實時系統、storm/Spark流式處理引擎,web/nginx日志、訪問日志,訊息服務等等,用scala語言撰寫,Linkedin于2010年貢獻給了Apache基金會并成為頂級開源 專案,
(1)產生背景
當今社會各種應用系統諸如商業、社交、搜索、瀏覽等像資訊工廠一樣不斷的生產出各種資訊,在大資料時代,我們面臨如下幾個挑戰:
- 如何收集這些巨大的資訊
- 如何分析它
- 如何及時做到如上兩點
以上幾個挑戰形成了一個業務需求模型,即生產者生產(produce)各種資訊,消費者消費(consume)(處理分析)這些資訊,而在生產者與消費者之間,需要一個溝通兩者的橋梁-訊息系統,從一個微觀層面來說,這種需求也可理解為不同的系統之間如何傳遞訊息,
Kafka誕生
Kafka由 linked-in 開源
kafka-即是解決上述這類問題的一個框架,它實作了生產者和消費者之間的無縫連接,
kafka-高產出的分布式訊息系統(A high-throughput distributed messaging system)
(2)Kafka的特性
-
高吞吐量、低延遲:kafka每秒可以處理幾十萬條訊息,它的延遲最低只有幾毫秒
-
可擴展性:kafka集群支持熱擴展
-
持久性、可靠性:訊息被持久化到本地磁盤,并且支持資料備份防止資料丟失
-
容錯性:允許集群中節點失敗(若副本數量為n,則允許n-1個節點失敗)
-
高并發:支持數千個客戶端同時讀寫
(3)Kafka場景應用
-
日志收集:一個公司可以用Kafka可以收集各種服務的log,通過kafka以統一介面服務的方式開放給各種consumer,例如hadoop、Hbase、Solr等,
-
訊息系統:解耦和生產者和消費者、快取訊息等,
-
用戶活動跟蹤:Kafka經常被用來記錄web用戶或者app用戶的各種活動,如瀏覽網頁、搜索、點擊等活動,這些活動資訊被各個服務器發布到kafka的topic中,然后訂閱者通過訂閱這些topic來做實時的監控分析,或者裝載到hadoop、資料倉庫中做離線分析和挖掘,
-
運營指標:Kafka也經常用來記錄運營監控資料,包括收集各種分布式應用的資料,生產各種操作的集中反饋,比如報警和報告,
-
流式處理:比如spark streaming和storm
-
事件源
(4)Kafka一些重要設計思想
-
Consumergroup:各個consumer可以組成一個組,每個訊息只能被組中的一個consumer消費,如果一個訊息可以被多個consumer消費的話,那么這些consumer必須在不同的組,
-
訊息狀態:在Kafka中,訊息的狀態被保存在consumer中,broker不會關心哪個訊息被消費了被誰消費了,只記錄一個offset值(指向partition中下一個要被消費的訊息位置),這就意味著如果consumer處理不好的話,broker上的一個訊息可能會被消費多次,
-
訊息持久化:Kafka中會把訊息持久化到本地檔案系統中,并且保持極高的效率,
-
訊息有效期:Kafka會長久保留其中的訊息,以便consumer可以多次消費,當然其中很多細節是可配置的,
-
批量發送:Kafka支持以訊息集合為單位進行批量發送,以提高push效率,
-
push-and-pull: Kafka中的Producer和consumer采用的是push-and-pull模式,即Producer只管向broker push訊息,consumer只管從broker pull訊息,兩者對訊息的生產和消費是異步的,
-
Kafka集群中broker之間的關系:不是主從關系,各個broker在集群中地位一樣,我們可以隨意的增加或洗掉任何一個broker節點,
-
負載均衡方面: Kafka提供了一個 metadata API來管理broker之間的負載(對Kafka0.8.x而言,對于0.7.x主要靠zookeeper來實作負載均衡),
-
同步異步:Producer采用異步push方式,極大提高Kafka系統的吞吐率(可以通過引數控制是采用同步還是異步方式),
-
磁區機制partition:Kafka的broker端支持訊息磁區,Producer可以決定把訊息發到哪個磁區,在一個磁區中訊息的順序就是Producer發送訊息的順序,一個主題中可以有多個磁區,具體磁區的數量是可配置的,磁區的意義很重大,后面的內容會逐漸體現,
-
離線資料裝載:Kafka由于對可拓展的資料持久化的支持,它也非常適合向Hadoop或者資料倉庫中進行資料裝載,
-
插件支持:現在不少活躍的社區已經開發出不少插件來拓展Kafka的功能,如用來配合Storm、Hadoop、flume相關的插件,
二、訊息佇列通信的模式
(1)點對點模式
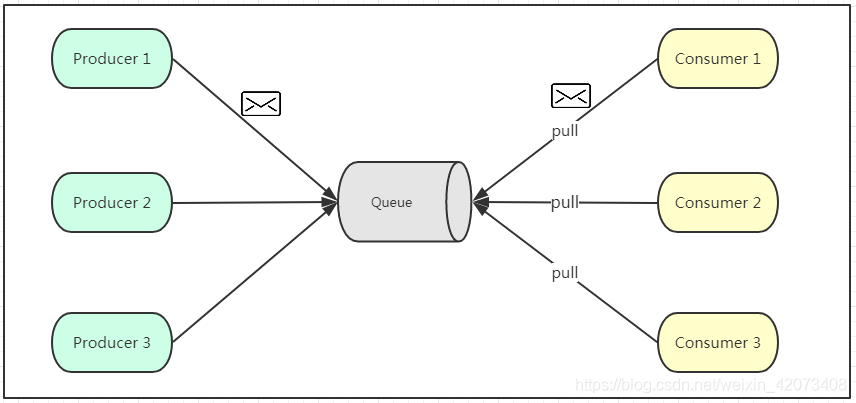
如上圖所示,點對點模式通常是基于拉取或者輪詢的訊息傳送模型,這個模型的特點是發送到佇列的訊息被一個且只有一個消費者進行處理,生產者將訊息放入訊息佇列后,由消費者主動的去拉取訊息進行消費,點對點模型的的優點是消費者拉取訊息的頻率可以由自己控制,但是訊息佇列是否有訊息需要消費,在消費者端無法感知,所以在消費者端需要額外的執行緒去監控,
(2)發布訂閱模式
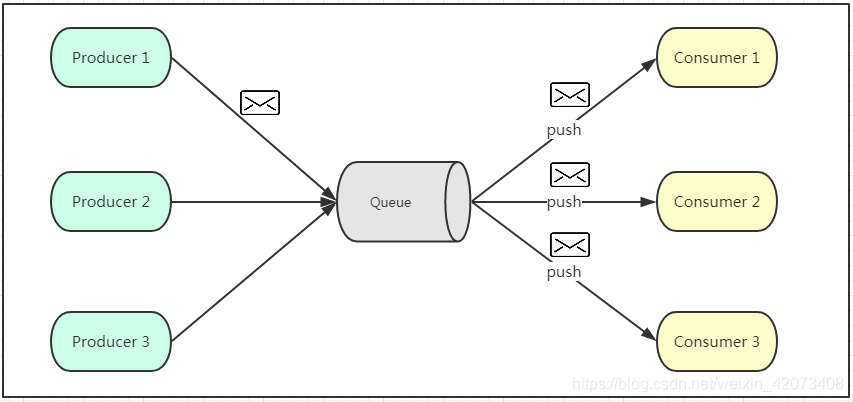
如上圖所示,發布訂閱模式是一個基于訊息送的訊息傳送模型,改模型可以有多種不同的訂閱者,生產者將訊息放入訊息佇列后,佇列會將訊息推送給訂閱過該類訊息的消費者(類似微信公眾號),由于是消費者被動接收推送,所以無需感知訊息佇列是否有待消費的訊息!但是consumer1、consumer2、consumer3由于機器性能不一樣,所以處理訊息的能力也會不一樣,但訊息佇列卻無法感知消費者消費的速度!所以推送的速度成了發布訂閱模模式的一個問題!假設三個消費者處理速度分別是8M/s、5M/s、2M/s,如果佇列推送的速度為5M/s,則consumer3無法承受!如果佇列推送的速度為2M/s,則consumer1、consumer2會出現資源的極大浪費!
三、Kafka的架構原理
上面簡單的介紹了為什么需要訊息佇列以及訊息佇列通信的兩種模式,下面主角介紹Kafka,Kafka是一種高吞吐量的分布式發布訂閱訊息系統,它可以處理消費者規模的網站中的所有動作流資料,具有高性能、持久化、多副本備份、橫向擴展能力,,
(1)基礎架構與名詞解釋
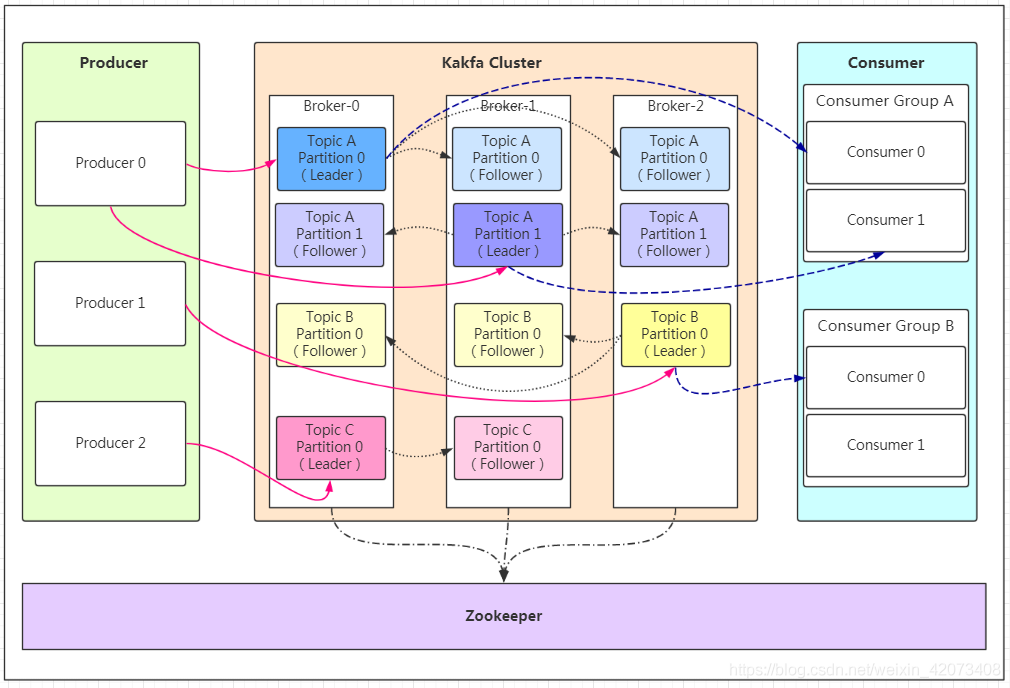
- Producer:Producer即生產者,訊息的產生者,是訊息的入口,
- Broker:Broker是kafka實體,每個服務器上有一個或多個kafka的實體,我們姑且認為每個broker對應一臺服務器,每個kafka集群內的broker都有一個不重復的編號,如圖中的broker-0、broker-1等……
- Topic:訊息的主題,可以理解為訊息的分類,kafka的資料就保存在topic,在每個broker上都可以創建多個topic,
- Partition:Topic的磁區,每個topic可以有多個磁區,磁區的作用是做負載,提高kafka的吞吐量,同一個topic在不同的磁區的資料是不重復的,partition的表現形式就是一個一個的檔案夾!
- Replication: 每一個磁區都有多個副本,副本的作用是做備胎,當主磁區(Leader)故障的時候會選擇一個備胎(Follower)上位,成為Leader,在kafka中默認副本的最大數量是10個,且副本的數量不能大于Broker的數量,follower和leader絕對是在不同的機器,同一機器對同一個磁區也只可能存放一個副本(包括自己),
- Message:每一條發送的訊息主體,
- Consumer:消費者,即訊息的消費方,是訊息的出口,
- ConsumerGroup:我們可以將多個消費組組成一個消費者組,在kafka的設計中同一個磁區的資料只能被消費者組中的某一個消費者消費,同一個消費者組的消費者可以消費同一個topic的不同磁區的資料,這也是為了提高kafka的吞吐量!
- Zookeeper:kafka集群依賴zookeeper來保存集群的的元資訊,來保證系統的可用性,
(2)作業流程分析
(1)發送資料
我們看上面的架構圖中,producer就是生產者,是資料的入口,注意看圖中的紅色箭頭,Producer在寫入資料的時候永遠的找leader,不會直接將資料寫入follower!那leader怎么找呢?寫入的流程又是什么樣的呢?我們看下圖:
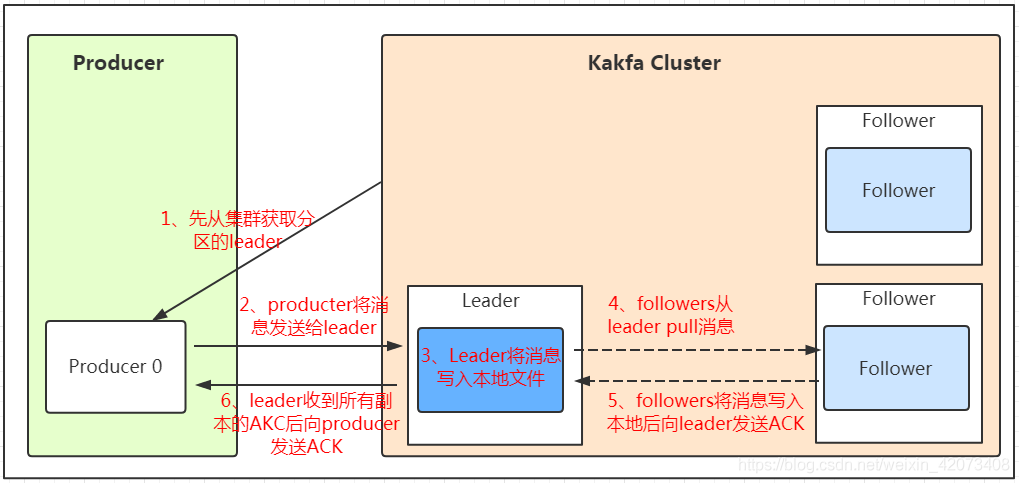
發送的流程就在圖中已經說明了,就不單獨在文字列出來了!需要注意的一點是,訊息寫入leader后,follower是主動的去leader進行同步的!producer采用push模式將資料發布到broker,每條訊息追加到磁區中,順序寫入磁盤,所以保證同一磁區內的資料是有序的!寫入示意圖如下:
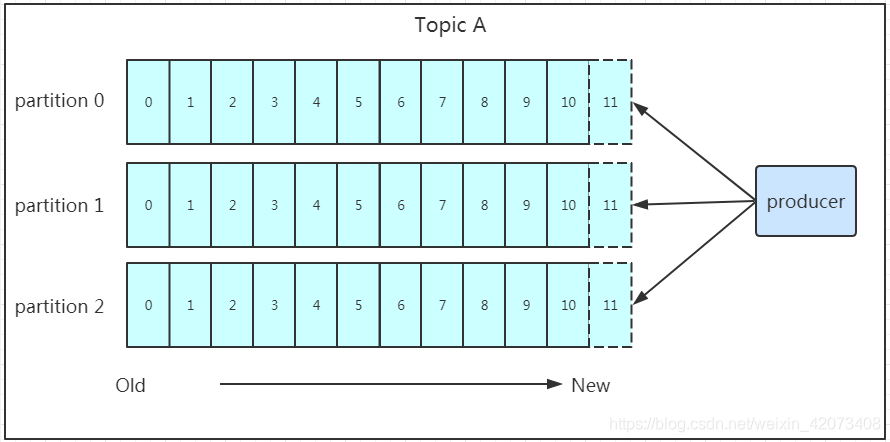
上面說到資料會寫入到不同的磁區,那kafka為什么要做磁區呢?相信大家應該也能猜到,磁區的主要目的是:
- 方便擴展:因為一個topic可以有多個partition,所以我們可以通過擴展機器去輕松的應對日益增長的資料量,
- 提高并發:以partition為讀寫單位,可以多個消費者同時消費資料,提高了訊息的處理效率,
熟悉負載均衡的朋友應該知道,當我們向某個服務器發送請求的時候,服務端可能會對請求做一個負載,將流量分發到不同的服務器,那在kafka中,如果某個topic有多個partition,producer又怎么知道該將資料發往哪個partition呢?kafka中有幾個原則:
- partition在寫入的時候可以指定需要寫入的partition,如果有指定,則寫入對應的partition,
- 如果沒有指定partition,但是設定了資料的key,則會根據key的值hash出一個partition,
- 如果既沒指定partition,又沒有設定key,則會輪詢選出一個partition,
保證訊息不丟失是一個訊息佇列中間件的基本保證,那producer在向kafka寫入訊息的時候,怎么保證訊息不丟失呢?其實上面的寫入流程圖中有描述出來,那就是通過ACK應答機制!在生產者向佇列寫入資料的時候可以設定引數來確定是否確認kafka接收到資料,這個引數可設定的值為0、1、all, - 0 代表producer往集群發送資料不需要等到集群的回傳,不確保訊息發送成功,安全性最低但是效率最高,
- 1 代表producer往集群發送資料只要leader應答就可以發送下一條,只確保leader發送成功,
- all 代表producer往集群發送資料需要所有的follower都完成從leader的同步才會發送下一條,確保leader發送成功和所有的副本都完成備份,安全性最高,但是效率最低,
最后要注意的是,如果往不存在的topic寫資料,能不能寫入成功呢?kafka會自動創建topic,磁區和副本的數量根據默認配置都是1,
(2)保存資料
Producer將資料寫入kafka后,集群就需要對資料進行保存了!kafka將資料保存在磁盤,可能在我們的一般的認知里,寫入磁盤是比較耗時的操作,不適合這種高并發的組件,Kafka初始會單獨開辟一塊磁盤空間,順序寫入資料(效率比隨機寫入高),
(1)Partition 結構
前面說過了每個topic都可以分為一個或多個partition,如果你覺得topic比較抽象,那partition就是比較具體的東西了!Partition在服務器上的表現形式就是一個一個的檔案夾,每個partition的檔案夾下面會有多組segment檔案,每組segment檔案又包含.index檔案、.log檔案、.timeindex檔案(早期版本中沒有)三個檔案, log檔案就實際是存盤message的地方,而index和timeindex檔案為索引檔案,用于檢索訊息,

如上圖,這個partition有三組segment檔案,每個log檔案的大小是一樣的,但是存盤的message數量是不一定相等的(每條的message大小不一致),檔案的命名是以該segment最小offset來命名的,如000.index存盤offset為0~368795的訊息,kafka就是利用分段+索引的方式來解決查找效率的問題,
(2)Message結構
上面說到log檔案就實際是存盤message的地方,我們在producer往kafka寫入的也是一條一條的message,那存盤在log中的message是什么樣子的呢?訊息主要包含訊息體、訊息大小、offset、壓縮型別……等等!我們重點需要知道的是下面三個:
- offset:offset是一個占8byte的有序id號,它可以唯一確定每條訊息在parition內的位置!
- 訊息大小:訊息大小占用4byte,用于描述訊息的大小,
- 訊息體:訊息體存放的是實際的訊息資料(被壓縮過),占用的空間根據具體的訊息而不一樣,
(3)存盤策略
無論訊息是否被消費,kafka都會保存所有的訊息,那對于舊資料有什么洗掉策略呢?
- 基于時間,默認配置是168小時(7天),
- 基于大小,默認配置是1073741824,
需要注意的是,kafka讀取特定訊息的時間復雜度是O(1),所以這里洗掉過期的檔案并不會提高kafka的性能!
(3)消費資料
訊息存盤在log檔案后,消費者就可以進行消費了,在講訊息佇列通信的兩種模式的時候講到過點對點模式和發布訂閱模式,Kafka采用的是發布訂閱模式,消費者主動的去kafka集群拉取訊息,與producer相同的是,消費者在拉取訊息的時候也是找leader去拉取,
多個消費者可以組成一個消費者組(consumer group),每個消費者組都有一個組id!同一個消費組者的消費者可以消費同一topic下不同磁區的資料,但是不會組內多個消費者消費同一磁區的資料!!!我們看下圖:
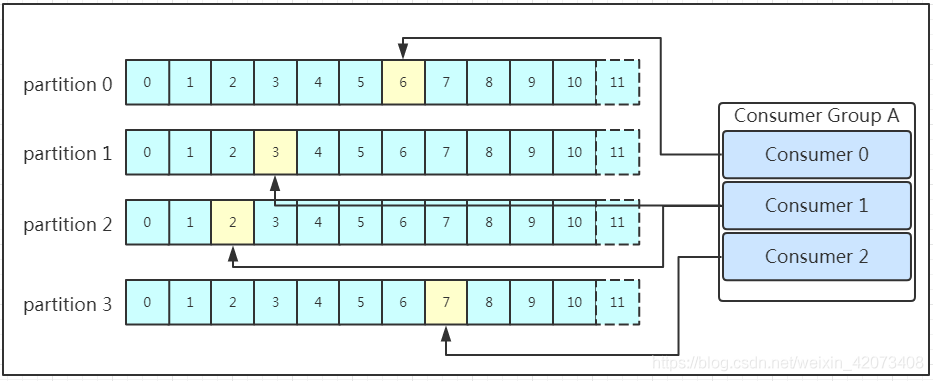
圖示是消費者組內的消費者小于partition數量的情況,所以會出現某個消費者消費多個partition資料的情況,消費的速度也就不及只處理一個partition的消費者的處理速度!如果是消費者組的消費者多于partition的數量,那會不會出現多個消費者消費同一個partition的資料呢?上面已經提到過不會出現這種情況!多出來的消費者不消費任何partition的資料,所以在實際的應用中,建議消費者組的consumer的數量與partition的數量一致!
在保存資料的小節里面,我們聊到了partition劃分為多組segment,每個segment又包含.log、.index、.timeindex檔案,存放的每條message包含offset、訊息大小、訊息體……我們多次提到segment和offset,查找訊息的時候是怎么利用segment+offset配合查找的呢?假如現在需要查找一個offset為368801的message是什么樣的程序呢?我們先看看下面的圖:
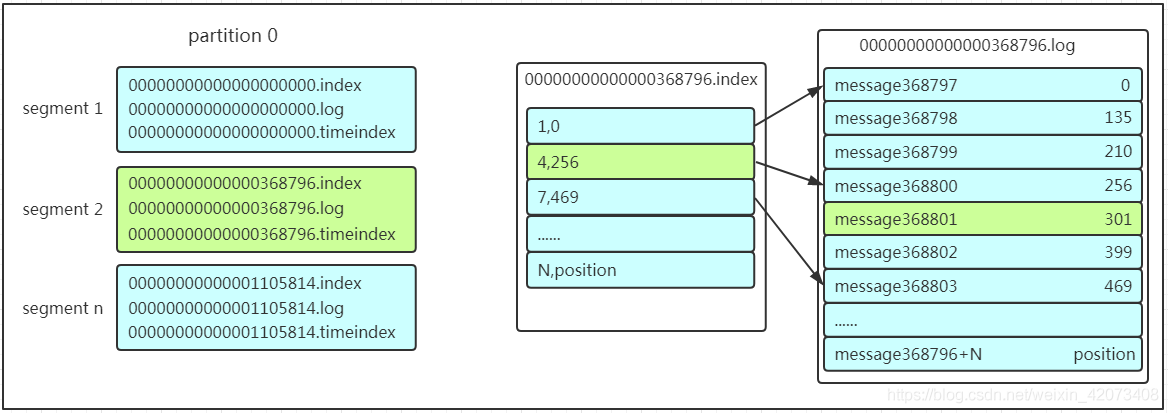
- 先找到offset的368801message所在的segment檔案(利用二分法查找),這里找到的就是在第二個segment檔案,
- 打開找到的segment中的.index檔案(也就是368796.index檔案,該檔案起始偏移量為368796+1,我們要查找的offset為368801的message在該index內的偏移量為368796+5=368801,所以這里要查找的相對offset為5),由于該檔案采用的是稀疏索引的方式存盤著相對offset及對應message物理偏移量的關系,所以直接找相對offset為5的索引找不到,這里同樣利用二分法查找相對offset小于或者等于指定的相對offset的索引條目中最大的那個相對offset,所以找到的是相對offset為4的這個索引,
- 根據找到的相對offset為4的索引確定message存盤的物理偏移位置為256,打開資料檔案,從位置為256的那個地方開始順序掃描直到找到offset為368801的那條Message,
這套機制是建立在offset為有序的基礎上,利用segment+有序offset+稀疏索引+二分查找+順序查找等多種手段來高效的查找資料!至此,消費者就能拿到需要處理的資料進行處理了,那每個消費者又是怎么記錄自己消費的位置呢?在早期的版本中,消費者將消費到的offset維護zookeeper中,consumer每間隔一段時間上報一次,這里容易導致重復消費,且性能不好!在新的版本中消費者消費到的offset已經直接維護在kafk集群的__consumer_offsets這個topic中!
參考文章
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/294891.html
標籤:其他
上一篇:33.搭建DNS服務