【論文泛讀】 YOLO v1:統一、實時的目標檢測框架
文章目錄
- 【論文泛讀】 YOLO v1:統一、實時的目標檢測框架
- 摘要 Abstract
- 介紹 Introduction
- 統一的目標檢測框架
- YOLO v1網路架構
- 損失函式的設計
- YOLO的缺陷
- 比較性能
- 總結
論文鏈接: You Only Look Once: Unified, Real-Time Object Detection
這次來講解一下YOLO v1演算法(CVPR2016的文章),YOLO是目前比較流行的object detection演算法,速度快且結構簡單,其他的object detection演算法如faster RCNN(之前已經解讀了一下),YOLO模型指標準化、實時的目標檢測,有了YOLO,不需要一張影像看一千次,來產生檢測結果,你只需要看一次,這就是我們為什么把它叫"YOLO"物體探測方法(You only look once),
摘要 Abstract
作者提出了YOLO,一種新的目標檢測方法,以前的目標檢測作業重新利用分類器來執行檢測,相反,我們將目標檢測框架看作回歸問題從空間上分割邊界框和相關的類別概率,單個神經網路在一次評估中直接從完整影像上預測邊界框和類別概率,由于整個檢測流水線是單一網路,因此可以直接對檢測性能進行end-to-end(端到端)的優化,
我們的統一架構非常快,我們的基礎YOLO模型以45幀/秒的速度實時處理影像,網路的一個較小版本,快速YOLO,每秒能處理驚人的155幀,同時實作其它實時檢測器兩倍的mAP,相較于其他的state-of-the-art (先進的物體檢測系統),YOLO在物體定位時更容易出錯,但是在背景上預測出不存在的物體(false positives)的情況會少一些,而且,YOLO比DPM、R-CNN等物體檢測系統能夠學到更加抽象的物體的特征,這使得YOLO可以從真實影像領域遷移到其他領域,如藝術,
介紹 Introduction
這里就簡單介紹一下,在傳統的目標檢測中,一般是傳統兩階段的目標檢測模型two-stage,而YOLO是一個單階段的模型one-stage,
在之前介紹了DOM和Faster RCNN都是傳統兩階段目標檢測模型,一般包含兩個階段
- 提取潛在的候選框(Region Proposal)
- 用分類器足以篩選候選框
所以說這需要兩個階段,常常就會花更多的時間,從而導致不能達到實時檢測的結果,并且這些復雜的流程很慢,很難優化,因為每個單獨的組件都必須單獨進行訓練,
論文中提出的YOLO就很簡單,我們可以將其看作一個單一的回歸問題,直接從影像像素到邊界框坐標和類概率,只需要在影像上看一次(YOLO),就可以預測出現的目標和位置,并且YOLO利用了卷積神經網路,用單個卷積網路同時預測這些盒子的多個邊界框和類概率
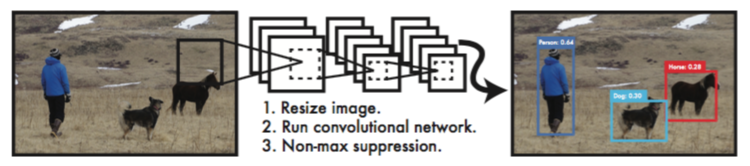
YOLO演算法有較為明顯的優點:
1、YOLO的速度非常快,在Titan X GPU上的速度是45 fps(frames per second),加速版的YOLO差不多是150fps,
2、YOLO是基于影像的全域資訊進行預測的,這一點和基于sliding window以及region proposal等檢測演算法不一樣,與Fast R-CNN相比,YOLO在誤檢測(將背景檢測為物體)方面的錯誤率能降低一半多,
3、YOLO可以學到物體的generalizable representations,可以理解為泛化能力強,
4、準確率高,有實驗證明,
統一的目標檢測框架
演算法首先把輸入影像劃分成S*S的格子,然后對每個格子都預測B個bounding boxes,每個bounding box都包含5個預測值:x,y,w,h和confidence,x,y就是bounding box的中心坐標,與grid cell對齊(即相對于當前grid cell的偏移值),使得范圍變成0到1;w和h進行歸一化(分別除以影像的w和h,這樣最后的w和h就在0到1范圍),
另外每個格子都預測C個假定類別的概率,在本文中作者取S=7,B=2,C=20(因為PASCAL VOC有20個類別),所以最后有7*7*30個tensor,如下圖所示
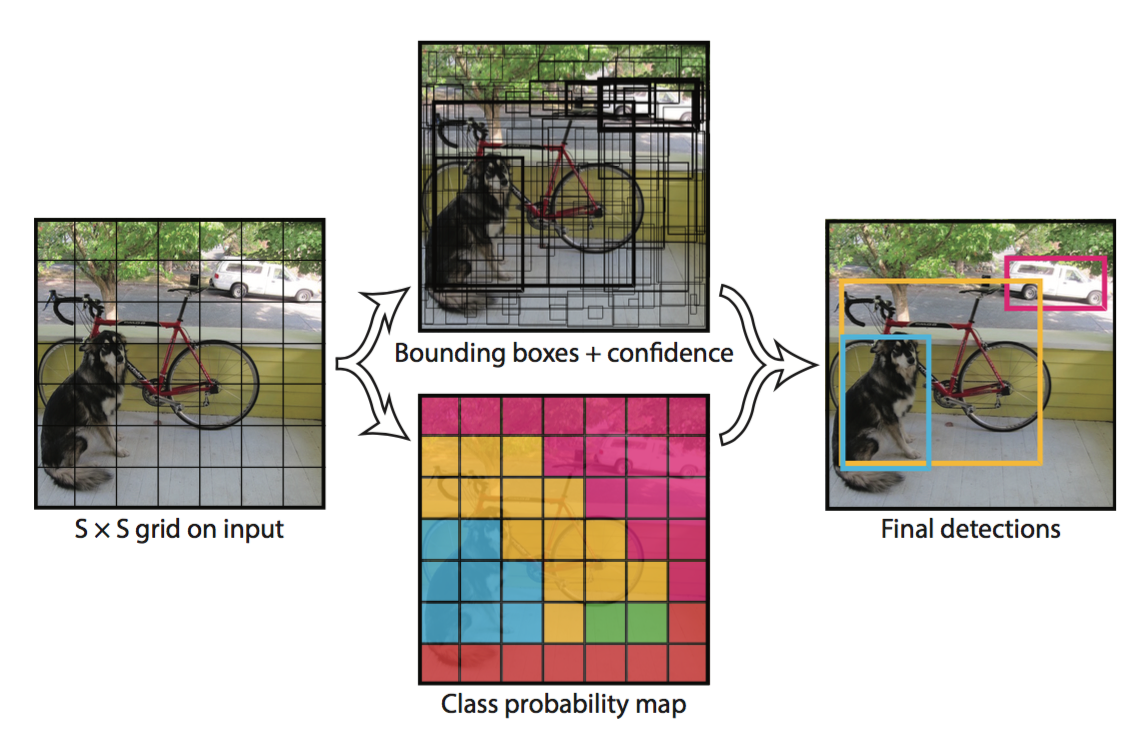
除此之外,每個bounding box都對應一個confidence score,如果grid cell里面沒有object,confidence就是0,如果有,則confidence score等于預測的box和ground truth的IOU值,
c
o
n
f
i
d
e
n
c
e
=
P
r
(
O
b
j
e
c
t
)
?
I
O
U
p
r
e
d
t
r
u
t
h
confidence = Pr(Object)*IOU_{pred}^{truth}
confidence=Pr(Object)?IOUpredtruth?
我們還需要判斷一個grid cell中是否包含object如果一個object的ground truth的中心點坐標在一個grid cell中,那么這個grid cell就是包含這個object,也就是說這個object的預測就由該grid cell負責,
除此之外每個grid cell都預測C個類別概率,表示一個grid cell在包含object的條件下屬于某個類別的概率 P r ( C l a s s i ∣ O b j e c t ) Pr(Class_i|Object) Pr(Classi?∣Object)
在測驗時,我們乘以條件類概率和單個盒子的置信度預測,
Pr
?
(
Class
i
∣
Object
)
?
Pr
?
(
Object
)
?
IOU
pred
truth
=
Pr
?
(
Class
i
)
?
IOU
pred
truth
\Pr(\textrm{Class}_i | \textrm{Object}) * \Pr(\textrm{Object}) * \textrm{IOU}_{\textrm{pred}}^{\textrm{truth}} = \Pr(\textrm{Class}_i)*\textrm{IOU}_{\textrm{pred}}^{\textrm{truth}}
Pr(Classi?∣Object)?Pr(Object)?IOUpredtruth?=Pr(Classi?)?IOUpredtruth?
它為我們提供了每個框特定類別的置信度分數,這些分數編碼了該類出現在框中的概率以及預測框擬合目標的程度,
為了在Pascal VOC上評估YOLO,我們使用 S = 7 S=7 S=7, B = 2 B=2 B=2,Pascal VOC有20個標注類,所以 C = 20 C=20 C=20,我們最終的預測是 7 × 7 × 30 7\times 7 \times 30 7×7×30的張量,
YOLO v1網路架構
YOLO1的網路架構受到GoogLeNet影像分類模型的啟發,我們的網路有24個卷積層,后面是2個全連接層,我們只使用 1 × 1 1 \times 1 1×1降維層,后面是 3 × 3 3 \times 3 3×3卷積層,而不是GoogLeNet使用的Inception模塊,具體如下圖所示
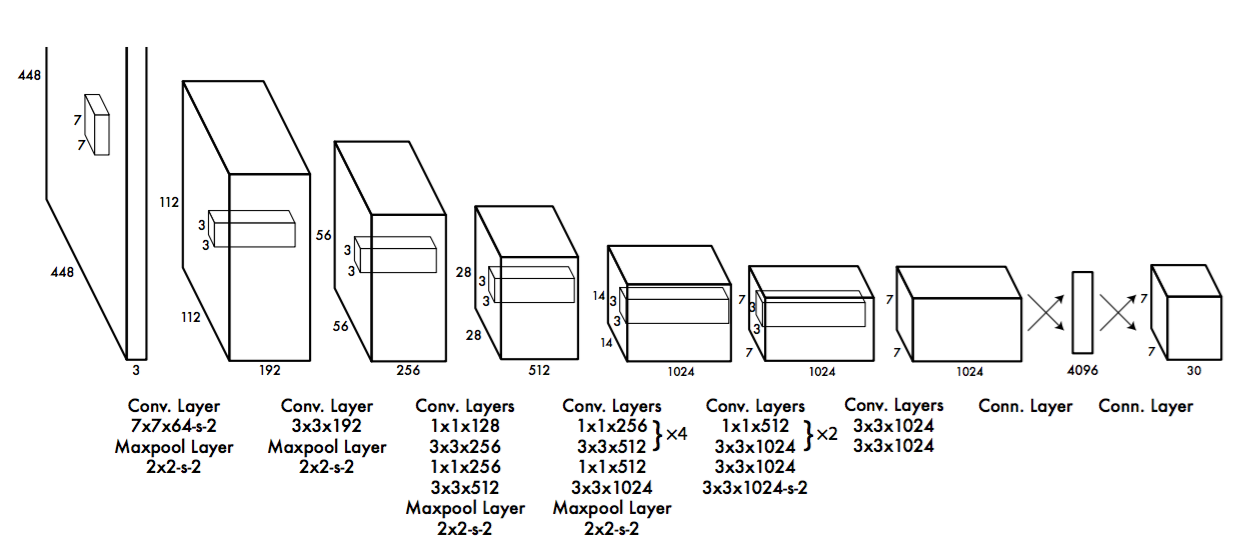
我們網路的最終輸出是 7 × 7 × 30 7 \times 7 \times 30 7×7×30的預測張量,
損失函式的設計
我覺得很重要的一個點就是這個損失函式,對于這個網路來說本質上是一個回歸問題,所以我們可以用平方和誤差來進行優化我們的模型,但是這會出現一個問題,我們可能會對分類誤差和定位誤差都一視同仁,對大框和小框都一視同仁,這樣就有可能會導致一些問題,特別是如果碰見資料集比較單一的時候,很有可能導致不穩定,最后模型發散,
為了補償改進,我們增加了邊界框坐標預測損失,并減少了不包含目標邊界框的置信度預測損失,我們使用兩個引數 λ coord \lambda_\textrm{coord} λcoord?和 λ noobj \lambda_\textrm{noobj} λnoobj?來完成這個作業,我們設定 λ coord = 5 \lambda_\textrm{coord} = 5 λcoord?=5和 λ noobj = . 5 \lambda_\textrm{noobj} = .5 λnoobj?=.5,
平方和誤差也可以在大框和小框中同樣加權誤差,我們的錯誤指標應該反映出,大框小偏差的重要性不如小框小偏差的重要性,為了部分解決這個問題,我們直接預測邊界框寬度和高度的平方根,而不是寬度和高度,
YOLO每個網格單元預測多個邊界框,在訓練時,每個目標我們只需要一個邊界框預測器來負責,我們指定一個預測器“負責”根據哪個預測與真實值之間具有當前最高的IOU來預測目標,這導致邊界框預測器之間的專業化,每個預測器可以更好地預測特定大小,方向角,或目標的類別,從而改善整體召回率,
在訓練期間,我們優化以下多部分損失函式:

我在圖中標了一下各個損失函式意義,希望對你有幫助,
最后提一下作者在論文中說,對Pascal VOC 2007和2012的訓練和驗證資料集進行了大約135個迭代周期的網路訓練,在Pascal VOC 2012上進行測驗時,我們的訓練包含了Pascal VOC 2007的測驗資料,在整個訓練程序中,我們使用了 64 64 64的批大小, 0.9 0.9 0.9的動量和 0.0005 0.0005 0.0005的衰減,
我們的學習率方案如下:對于第一個迭代周期,我們慢慢地將學習率從 1 0 ? 3 10^{-3} 10?3?提高到 1 0 ? 2 10^{-2} 10?2?,如果我們從高學習率開始,我們的模型往往會由于不穩定的梯度而發散,我們繼續以 10 ? 2 10{-2} 10?2?的學習率訓練75個迭代周期,然后用 1 0 ? 3 10^{-3} 10?3?的學習率訓練30個迭代周期,最后用 1 0 ? 4 10^{-4} 10?4?的學習率訓練30個迭代周期,
為了避免過度擬合,我們使用丟棄和大量的資料增強,在第一個連接層之后,丟棄層使用 = . 5 =.5 =.5的比例,防止層之間的互相適應,對于資料增強,我們引入高達原始影像 20 20% 20大小的隨機縮放和轉換,我們還在HSV色彩空間中使用高達 1.5 1.5 1.5的因子來隨機調整影像的曝光和飽和度,
YOLO的缺陷
YOLO對邊界框預測強加空間約束,因為每個網格單元只預測兩個盒子,只能有一個類別,這個空間約束限制了我們的模型可以預測的鄰近目標的數量,
1、位置精確性差,對于小目標物體以及物體比較密集的也檢測不好,比如一群小鳥,
2、YOLO雖然可以降低將背景檢測為物體的概率,但同時導致召回率較低,
從圖中也可以看奧,對于小的物體,YOLO的準確率較低
比較性能
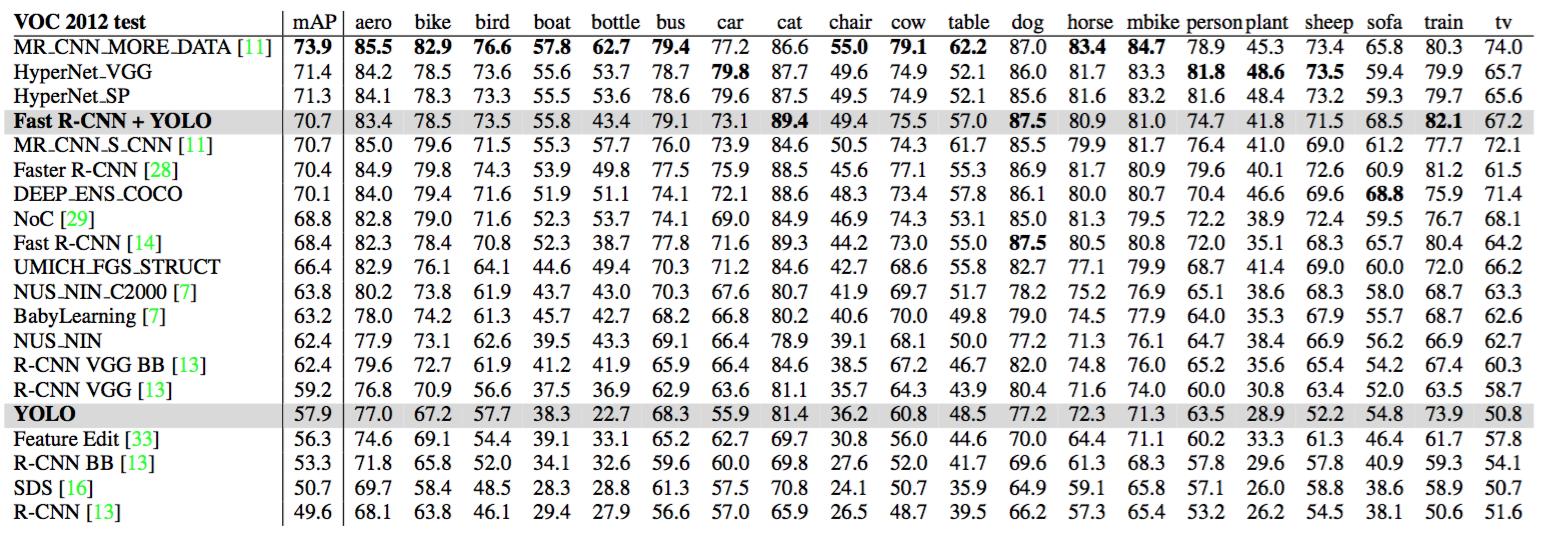
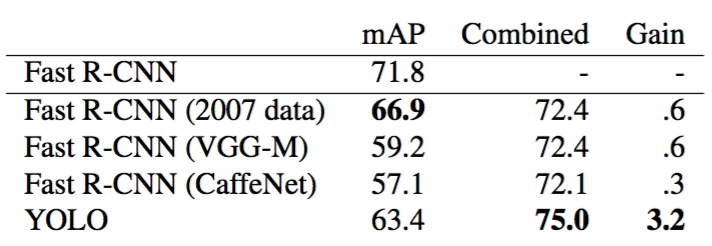
最后論文中對YOLO與各個目標檢測模型進行比較,最后發現Fast RCNN + YOLO模型會有一個比較大的提高,雖然YOLO的準確率沒有Fast RCNN準,但是它比Fast RCNN快,他可以說是又快又準,可以達到實時的預測,從而對我們的生活也造成了一些影響,比如我們可以通過此進行一個追蹤的功能,視頻的目標檢測,并且現在的技術也已經很成熟了,當連接到網路攝像頭時,其功能類似于跟蹤系統,可在目標移動和外觀變化時檢測目標,
總結
作者介紹了YOLO,一種統一的目標檢測模型,我們的模型構建簡單,可以直接在整張影像上進行訓練,與基于分類器的方法不同,YOLO直接在對應檢測性能的損失函式上訓練,并且整個模型聯合訓練,
快速YOLO是文獻中最快的通用目的的目標檢測器,YOLO推動了實時目標檢測的最新技術,YOLO還很好地泛化到新領域,使其成為依賴快速,強大的目標檢測應用的理想選擇,
現在的YOLO也已經出現了YOLO v5,之后也會對其論文進行研究,并且實作其代碼,還請持續關注,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/294937.html
標籤:其他
上一篇:C++之記憶體管理:申請與釋放