爬蟲實戰:百度貼吧
- 前言
- 1. 獲取資料
- 2. 決議資料
- 3. 保存資料
- 4. 完整代碼
- 5. 效果展示
前言
百度貼吧—全球領先的中文社區!
里面搜你想知道的 getAll!
既然不能吃瓜,那就玩游戲吧!

使命召喚回歸原味經典!

當年多么熱愛的槍戰游戲哇!
1. 獲取資料
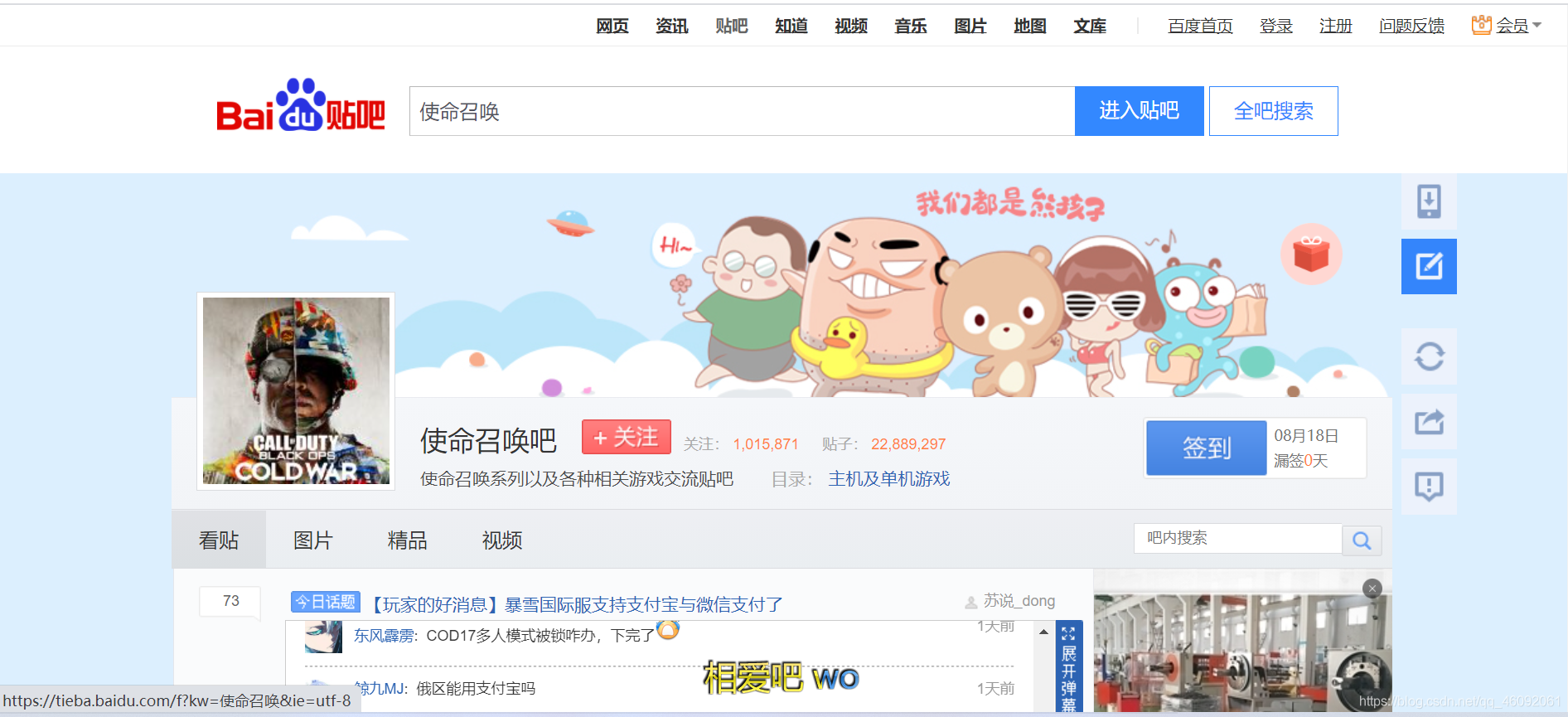
百度貼吧 https://tieba.baidu.com/index.html
關鍵字搜索:https://tieba.baidu.com/f?ie=utf-8&kw=使命召喚
def get_data(self, url):
response = requests.get(url, headers=self.headers)
print(url)
return response.content
2. 決議資料
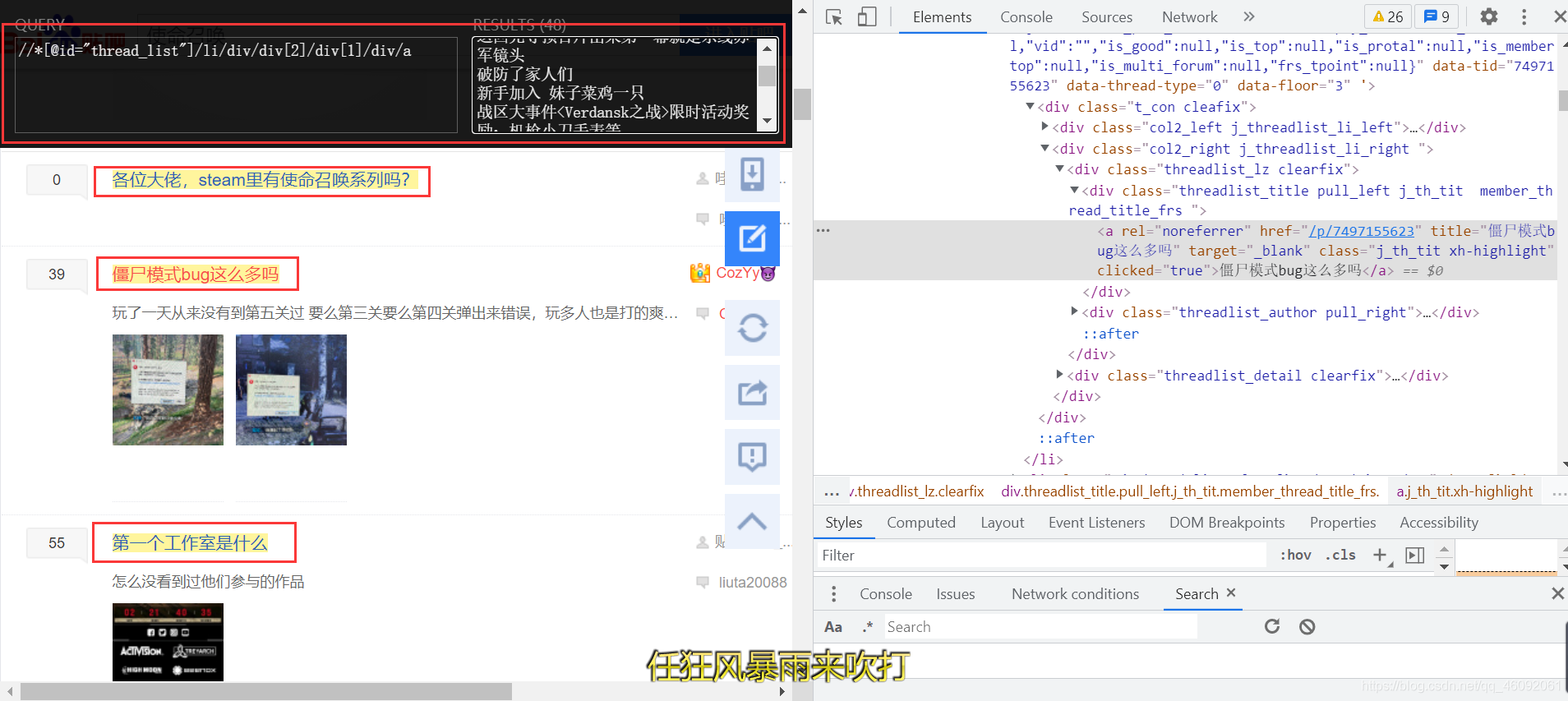
使用XPath獲取所有貼吧內容的title和link,注意:去除廣告,
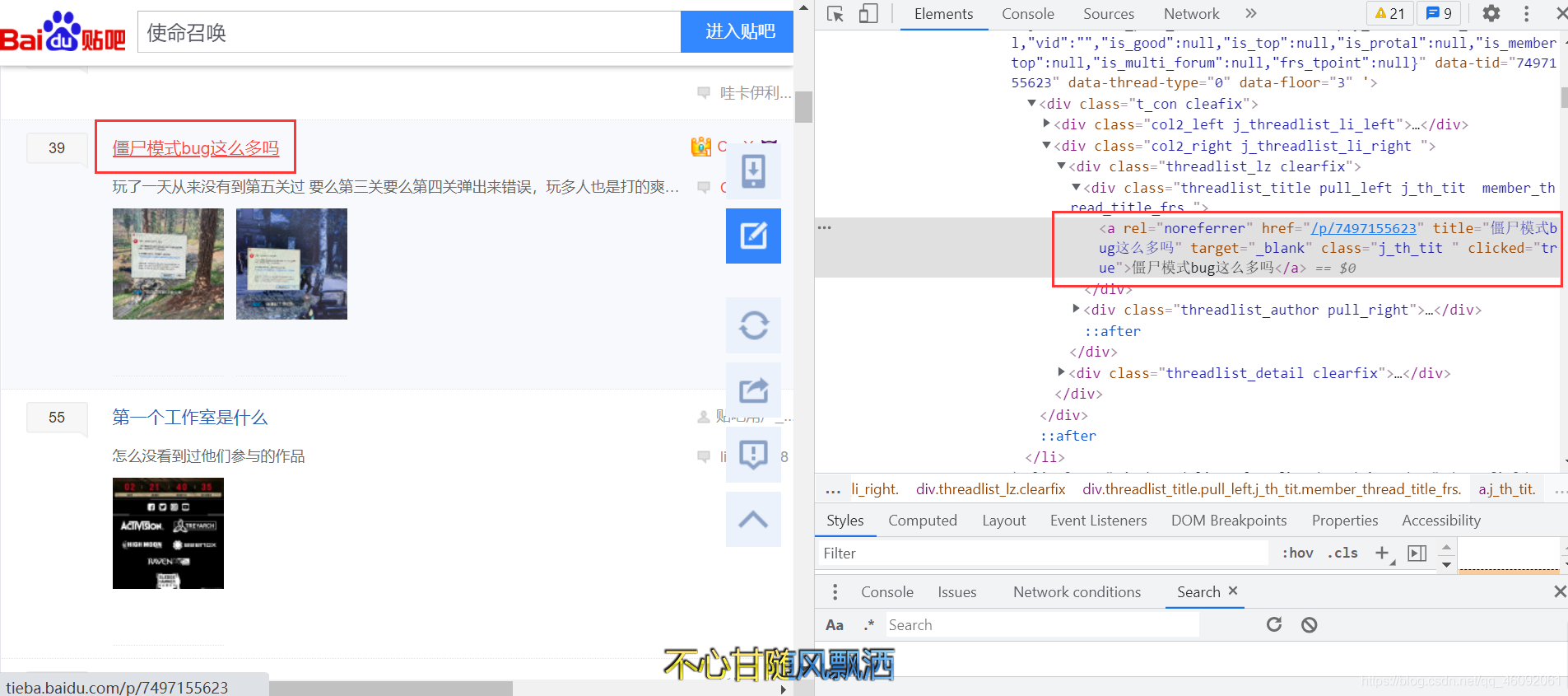
XPath Helper工具不斷除錯,便捷插件安裝請參考:Chrome安裝爬蟲必備插件:Xpath Helper高效決議網頁內容(實測有效)
def parse_data(self, data):
# 創建element物件
data = data.decode().replace('<!--', '').replace('-->', '')
html = etree.HTML(data)
el_list = html.xpath('//li[@class=" j_thread_list clearfix thread_item_box"]/div/div[2]/div[1]/div[1]/a')
# print(len(el_list))
data_list = []
for el in el_list:
temp = {}
temp['title'] = el.xpath('./text()')[0]
temp['link'] = 'https://tieba.baidu.com/' + el.xpath('./@href')[0]
data_list.append(temp)
# 獲取下一頁
try:
next_url = 'https:' + html.xpath('//a[contains(text(), "下一頁")]/@href')[0] # //a[@class="next pagination-item"]/@href
except:
next_url = None
return data_list, next_url
3. 保存資料
def save_data(self, data_list):
for data in data_list:
self.ws.append(list(data.values())) # 添加字典的values
self.num += 1
4. 完整代碼
import requests
from lxml import etree
import openpyxl
class Tieba(object):
def __init__(self, name):
self.url = 'https://tieba.baidu.com/f?kw={}&ie=utf-8&pn=0'.format(name)
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4542.2 Safari/537.36',
}
self.wb = openpyxl.Workbook() # 創建作業簿
self.ws = self.wb.active # 激活作業表sheet
self.ws.title = 'call of duty' # 更改sheet名
self.ws.append(['title', 'link']) # 設定表頭
self.num = 0
def get_data(self, url):
response = requests.get(url, headers=self.headers)
print(url)
return response.content
def parse_data(self, data):
# 創建element物件
data = data.decode().replace('<!--', '').replace('-->', '')
html = etree.HTML(data)
el_list = html.xpath('//li[@class=" j_thread_list clearfix thread_item_box"]/div/div[2]/div[1]/div[1]/a')
# print(len(el_list))
data_list = []
for el in el_list:
temp = {}
temp['title'] = el.xpath('./text()')[0]
temp['link'] = 'https://tieba.baidu.com/' + el.xpath('./@href')[0]
data_list.append(temp)
# 獲取下一頁
try:
next_url = 'https:' + html.xpath('//a[contains(text(), "下一頁")]/@href')[0] # //a[@class="next pagination-item"]/@href
except:
next_url = None
return data_list, next_url
def save_data(self, data_list):
for data in data_list:
self.ws.append(list(data.values())) # 添加字典的values
self.num += 1
def run(self):
# url
# headers
next_url = self.url
while next_url: # 不到最后一頁,不為None
# 發送請求獲取回應
data = self.get_data(next_url)
# 從回應中提取資料和翻頁用的資料
data_list, next_url = self.parse_data(data)
self.save_data(data_list)
# 測驗需要
# if self.num > 200:
# break
# # 判斷是否終結
# if not next_url:
# break
if __name__ == '__main__':
tieba = Tieba('使命召喚')
tieba.run()
tieba.wb.save('call of duty’s tieba_data.xlsx')
print(f'總有{tieba.num}條貼吧資料獲取完畢!')
5. 效果展示
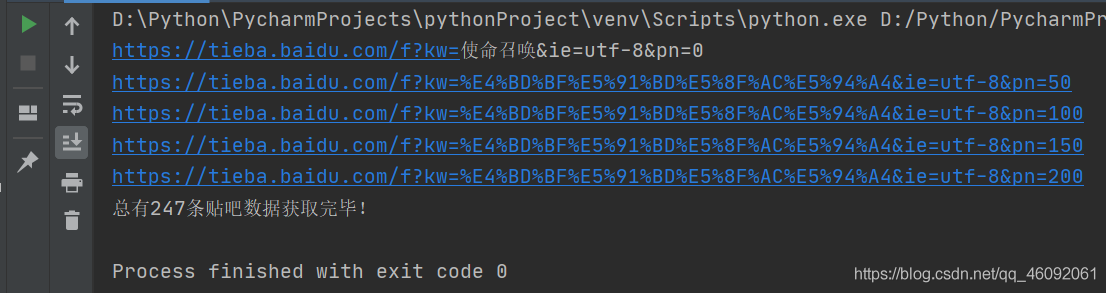
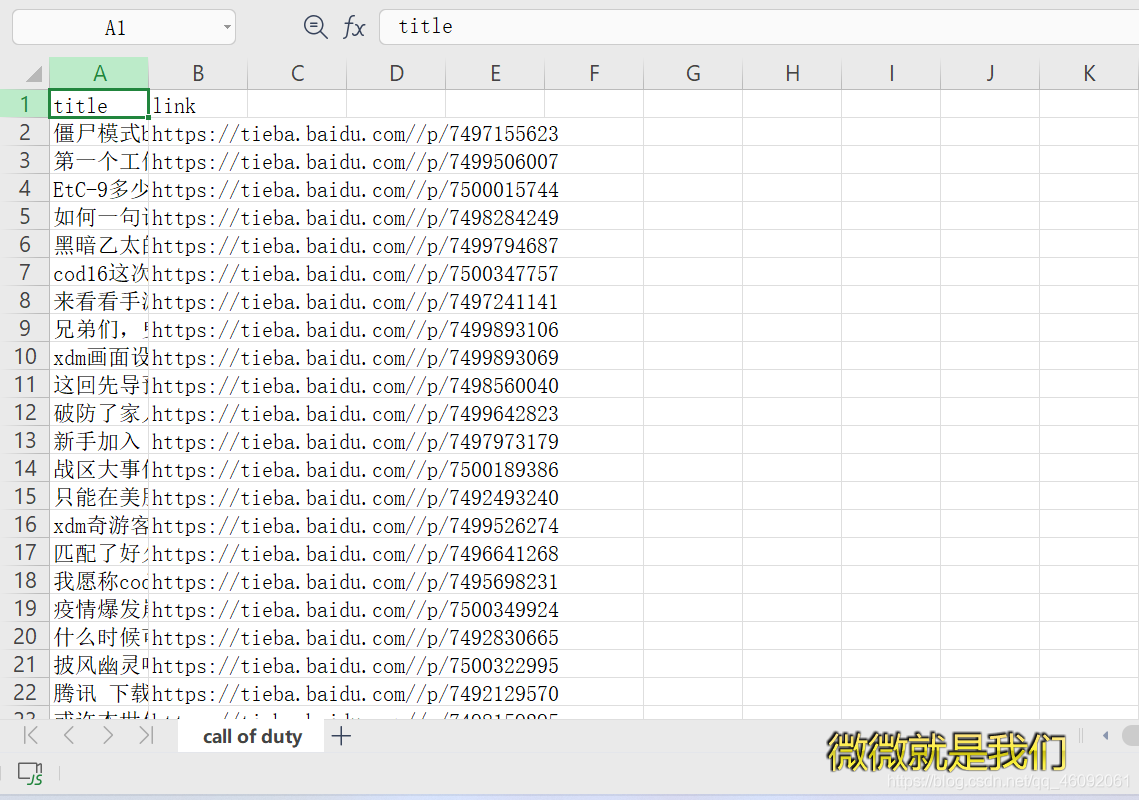
加油!
感謝!
努力!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/295054.html
標籤:其他