作者:北京交通大學計算機學院 秦梓鑫
學號:21120390
代碼僅供參考,歡迎交流;請勿用于任何形式的課程作業,
- Pytorch實驗一:從零實作Logistic回歸和Softmax回歸
- Pytorch實驗2:手動實作前饋神經網路、Dropout、正則化、K折交叉驗證,解決多分類、二分類、回歸任務
目錄:實作卷積神經網路、空洞卷積、殘差網路
- 實驗內容
- 二維卷積實驗
- 空洞卷積實驗
- 殘差網路實驗
- 實驗環境及實驗資料集
- 實驗程序
- 二維卷積實驗
- 手動實作二維卷積
- 使用torch實作二維卷積
- 對不同超引數的實驗結果對比分析
- 復現AlexNet模型
- 與前饋神經網路的效果進行對比
- 空洞卷積實驗
- 殘差網路實驗
- 實驗結果
- 二維卷積實驗
- 手動實作二維卷積
- 使用torch實作二維卷積
- 對不同超引數的實驗結果對比分析
- 卷積核大小的影響
- 卷積層數的影響
- 復現AlexNet模型
- 與前饋神經網路的效果進行對比
- 空洞卷積實驗
- 空洞卷積實驗結果
- 空洞卷積與普通卷積的效果對比
- 超引數的對比
- 卷積核大小的影響
- 卷積層數的影響
- 殘差網路實驗
- 殘差網路實驗結果
- 殘差空洞卷積實驗結果
- 實驗心得體會
- 參考文獻
實驗內容
二維卷積實驗
卷積神經網路是一種具有區域連接、權重共享特性的深層前饋神經網路,區域連接是指通過引入卷積核,使得每次運算學習的特征只和區域輸入相關,極大地減少了計算量和連接層數;權值共享是指學習的特征具有區域不變性,使得對此類特征提取更加充分,
在深度學習中,卷積的定義和分析數學、信號處理中的定義略有不同,一般地,卷積通過互相關(cross-correlation)計算,給定輸入
X
∈
R
M
×
N
\textbf{X}\in R^{M\times N}
X∈RM×N 和卷積核
W
∈
R
U
×
V
\textbf{W}\in R^{U\times V}
W∈RU×V,它們的互相關為
y
i
,
j
=
∑
u
=
1
U
∑
v
=
1
V
w
u
,
v
x
i
+
u
?
1
,
j
+
v
+
1
y_{i,j}= \sum_{u=1}^{U}{ \sum_{v=1}^{V}{w_{u,v}x_{i+u-1,j+v+1}}}
yi,j?=u=1∑U?v=1∑V?wu,v?xi+u?1,j+v+1?
也記作:
Y
=
W
?
X
\textbf{Y}=\textbf{W}?\textbf{X}
Y=W?X
在考慮特征抽取問題時,互相關和卷積的運算是等價的,在卷積的基礎上,可以引入卷積核的步長(stride)和填充(padding)來控制提取的特征圖的尺寸,
一般地,卷積的輸出大小由引數:卷積核數目(
F
F
F)、卷積核大小(
K
K
K)、步長(
S
S
S)、填充(
P
P
P),和輸入圖片的通道數(
D
D
D)、寬度(
W
W
W)、高度(
H
H
H)共同決定;其中輸出的通道數、寬度、高度分別是:
D
o
u
t
=
F
D_{out}=F
Dout?=F
W
o
u
t
=
W
+
2
P
?
K
S
+
1
W_{out}=\frac{W+2P-K}{S}+1
Wout?=SW+2P?K?+1
H
o
u
t
=
H
+
2
P
?
K
S
+
1
H_{out}=\frac{H+2P-K}{S}+1
Hout?=SH+2P?K?+1
對于每個卷積核,共引入
K
×
K
×
D
+
1
K\times K\ \times D\ +1
K×K ×D +1個引數;由于有F個卷積核,所以共有
F
×
D
×
K
2
+
F
F\times D\times K^2+F
F×D×K2+F個引數,
卷積層(Convolution Layer)通常與匯聚層(Pooling Layer)混合使用,匯聚層是一種下采樣(down sample)操作,作用是減少引數和特征的數量、加快運算速度和增加模型的魯棒性,常用的匯聚包括:最大匯聚和平均匯聚,
二維卷積實驗的目的是:(1)手動實作二維卷積;(2)使用torch實作二維卷積;(3)進行實驗結果的分析、超引數的對比分析;(4)復現AlexNet模型;(5)與前饋神經網路的效果進行對比,
空洞卷積實驗
空洞卷積是指通過在卷積核的元素間插入空隙來增加感受野的方法,對于大小為
K
×
K
K\times K
K×K的卷積核,在每兩個元素中插入
D
?
1
D-1
D?1個元素,則空洞卷積核的有效大小是:
K
′
=
K
+
(
K
?
1
)
×
(
D
?
1
)
K'=K+(K-1)×(D-1)
K′=K+(K?1)×(D?1)
其中:D是空洞卷積的膨脹率,例如:原卷積核大小為
3
×
3
3\times3
3×3,則空洞卷積核的單邊大小為
3
+
(
3
?
1
)
×
(
2
?
1
)
=
5
3+\left(3-1\right)\times\left(2-1\right)=5
3+(3?1)×(2?1)=5,普通卷積可以視為
D
=
1
D=1
D=1時的空洞卷積,
![圖1.1:空洞卷積引發的網格效應(gridding effect)[3]](https://img.uj5u.com/2021/08/21/258553210643382.png)
由于空洞卷積引入了空隙,有一部分特征沒有參與計算,且捕獲具有一定間隔的特征可能是不相關的,Panqu Wang等人在2018年提出混合空洞卷積條件(Hybrid Dilated Convolution, HDC),對網路中每一層的膨脹率變化規律做出規定,滿足此條件的網路可以規避特征空隙、同時捕獲遠程和近距離資訊,
對于卷積核大小均為K\times K的N層卷積神經網路,其每一層膨脹率組成的序列分別為:
[
r
1
,
…
,
r
i
,
…
,
r
n
]
\left[r_1,\ldots,r_i,\ldots,r_n\right]
[r1?,…,ri?,…,rn?],需滿足:
?
1
<
i
<
n
,
M
i
≤
K
?1<i<n,M_i≤K
?1<i<n,Mi?≤K
其中:
M
i
=
m
a
x
[
r
i
+
1
?
2
r
i
,
2
r
i
?
r
i
+
1
,
r
i
]
Mi=max[r_{i+1}-2r_i,2r_i-r_{i+1},r_i]
Mi=max[ri+1??2ri?,2ri??ri+1?,ri?]
本實驗的目的是:(1)利用torch.nn實作空洞卷積,其中:膨脹率序列(dilation)滿足HDC條件,在車輛分類資料集上實驗并輸出結果;(2)比較空洞卷積和普通卷積的結果;(3)選取1-2個超引數進行對比分析,
殘差網路實驗
在深度神經網路中,如果期望非線性單元
f
(
x
;
θ
)
f\left(\textbf{x};\theta\right)
f(x;θ)去逼近目標函式
h
(
x
)
h(\textbf{x})
h(x);可以考慮將目標函式分解為:
h
(
x
)
=
x
+
h
(
x
)
?
x
h(x)=x+h(x)-x
h(x)=x+h(x)?x
其中,
x
\textbf{x}
x稱為恒等函式(identity function),
(
h
(
x
)
?
x
)
(h(\textbf{x})-\textbf{x})
(h(x)?x)稱為殘差函式(residue function),
根據通用近似定理,非線性單元可以在理論上逼近任意函式,因此,原問題可以進行如下轉化:期望
f
(
x
;
θ
)
f\left(\textbf{x};\theta\right)
f(x;θ)逼近殘差函式
(
h
(
x
)
?
x
)
(h(\textbf{x})-\textbf{x})
(h(x)?x),使得
f
(
x
;
θ
)
\ f\left(\textbf{x};\theta\right)
f(x;θ)逼近目標函式
h
(
x
)
h(\textbf{x})
h(x),
一般地,殘差網路可以通過跳層連接(shortcut connection)實作,過往的實驗表明:殘差網路可以解決深層神經網路的梯度爆炸、梯度消失和網路退化問題,
本實驗的目的是:(1)復現給定的殘差網路架構,分析結果;(2)結合空洞卷積,對比分析實驗結果,
實驗環境及實驗資料集
資料集采用車輛分類資料集,共1358張車輛圖片,三個類別,其中:隨機抽取70%作訓練集,30%作測驗集,
實驗環境為Linux 3.10.0-1062.el7.x86_64;運算器為NVIDIA GeForce RTX 2080;框架為:Pytorch 1.6.0;采用Pycharm內置的SSH連接進行互動,
實驗程序
二維卷積實驗
手動實作二維卷積
要實作卷積,需要依次實作:單通道互相關運算、多通道互相關運算、多卷積核互相關運算,需要說明的是,在Open CV讀入的圖片格式中,通道(channel)是最后一個維度,因此需要對讀取的資料進行通道變換,代碼段分別如下,
1. #單通道互相關運算
2. def corr2d(X,K):
3. batch_size,H,W = X.shape
4. h,w = K.shape[0],K.shape[1]
5. Y = torch.zeros(batch_size,H-h+1,W-w+1).to(device)
6. for i in range(Y.shape[1]):
7. for j in range(Y.shape[2]):
8. area = X[:,i:i+h, j:j+w]
9. Y[:,i,j] = (area* K).sum()
10. return Y
11.
12. #多通道互相關運算
13. def corr2d_multi_in(X, K):
14. res = corr2d(X[:,:,:,0],K[:,:,0])
15. for i in range(0,X.shape[3]):
16. res += corr2d(X[:,:,:,i],K[:,:,i])
17. return res
18.
19. #多卷積核互相關運算
20. def corr2d_multi_in_out(X, K):
21. return torch.stack([corr2d_multi_in(X,k) for k in K],dim=1)
定義了互相關運算、二維池化運算后,我們可以把卷積封裝成卷積層模塊,
1. #定義池化層
2. def pool2d(X, pool_size, mode='max'):
3. p_h, p_w = pool_size,pool_size
4. Y = torch.zeros((X.shape[0],X.shape[1],X.shape[2] - p_h + 1, X.shape[3] - p_w + 1))
5. for i in range(Y.shape[2]):
6. for j in range(Y.shape[3]):
7. if mode == 'max':
8. Y[:,:,i, j] = X[:,:,i: i + p_h, j: j + p_w].max()
9. elif mode == 'avg':
10. Y[:,:,i, j] = X[:,:,i: i + p_h, j: j + p_w].mean()
11. return Y
12.
13. #定義卷積模塊
14. class MyConv2D(nn.Module):
15. def __init__(self,in_channels,out_channels,kernel_size):
16. super(MyConv2D,self).__init__()
17. if isinstance(kernel_size,int):
18. kernel_size = (kernel_size,kernel_size)
19. self.weight = nn.Parameter(torch.randn((out_channels,in_channels)+kernel_size))
20. self.bias = nn.Parameter(torch.randn(out_channels,1,1))
21. def forward(self,x):
22. y = corr2d_multi_in_out(x,self.weight) +self.bias
23. return y
使用torch實作二維卷積
使用Pytorch可以直接定義模型完成訓練,值得注意的是,由于卷積層的引數和輸入圖片大小會影響全連接層的引數設定,每一次調整網路架構時,全連接層的維度都需要重新計算,
此次實驗中,我們把資料集中的圖片壓縮為200*100的尺寸,根據公式(3)~(5),我們可以得出全連接層的維度是15532.
1. class ConvModule(nn.Module):
2. def __init__(self):
3. super(ConvModule,self).__init__()
4. self.conv = nn.Sequential(
5. nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, stride=1, padding=0),
6. nn.BatchNorm2d(32),
7. nn.ReLU(inplace=True)
8. )
9. self.pool = nn.MaxPool2d(2,2)
10. self.fc = nn.Linear(155232, num_classes)
11. def forward(self,X):
12. out = self.conv(X.float())
13. out = self.pool(out)
14. out = out.view(out.size(0), -1) # flatten each instance
15. out = self.fc(out)
16. return out
對不同超引數的實驗結果對比分析
此部分,我們試驗了不同的卷積層層數(在ConvModule中定義)和卷積核大小,
復現AlexNet模型
AlexNet中引入了Dropout、ReLU激活和區域相應歸一化技巧,以提升模型的泛化能力,AlexNet中的區域回應歸一化(Local Response Normalization, LRN)是一種對于同層的部分神經元的歸一化方法,它受到生物學中側抑制現象的啟發,即:活躍神經元對鄰近神經元由平衡和約束作用,數學上,可視作在激活函式的基礎上,再做一次簡單線性回歸,此方法現已被池化層取代,很少應用,此處,我們直接采用[1]中的LRN實作.
AlexNet是第一個現代深度網路模型,由Krizhevsky等人在2012年參與ImageNet競賽中提出,由于當時GPU的運算性能限制,當時被拆分為兩個子網路進行分別訓練,它包含5個卷積層、3個匯聚層和3個全連接層,
在本實驗中,我們主要參照[1]中的AlexNet類進行實驗,需要注意的是,多層網路、LRN、ReLU激活可能會帶來大規模的梯度爆炸問題,造成損失為NaN,因此,我們在每一層卷積的末尾額外添加了一個BatchNorm層進行歸一化處理,
與前饋神經網路的效果進行對比
我們將卷積網路與實驗2中的網路(代碼如下)進行對比,
1. layers = collections.OrderedDict([
2. ('L1',nn.Linear(154587,192)),
3. ('A1',nn.Hardswish()),
4. ('drop1', nn.Dropout(p=0.1)),
5. ('L2', nn.Linear(192, 96)),
6. ('A2', nn.LeakyReLU()),
7. ('drop2', nn.Dropout(p=0.1)),
8. ('FC', nn.Linear(96,3))
9. ])
10. AnnNet = nn.Sequential(layers)
空洞卷積實驗
在torch中,定義空洞卷積較為簡便,只需要修改卷積層的dilation引數即可,
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, stride=1, padding=0, dilation=3) #膨脹率為3
殘差網路實驗
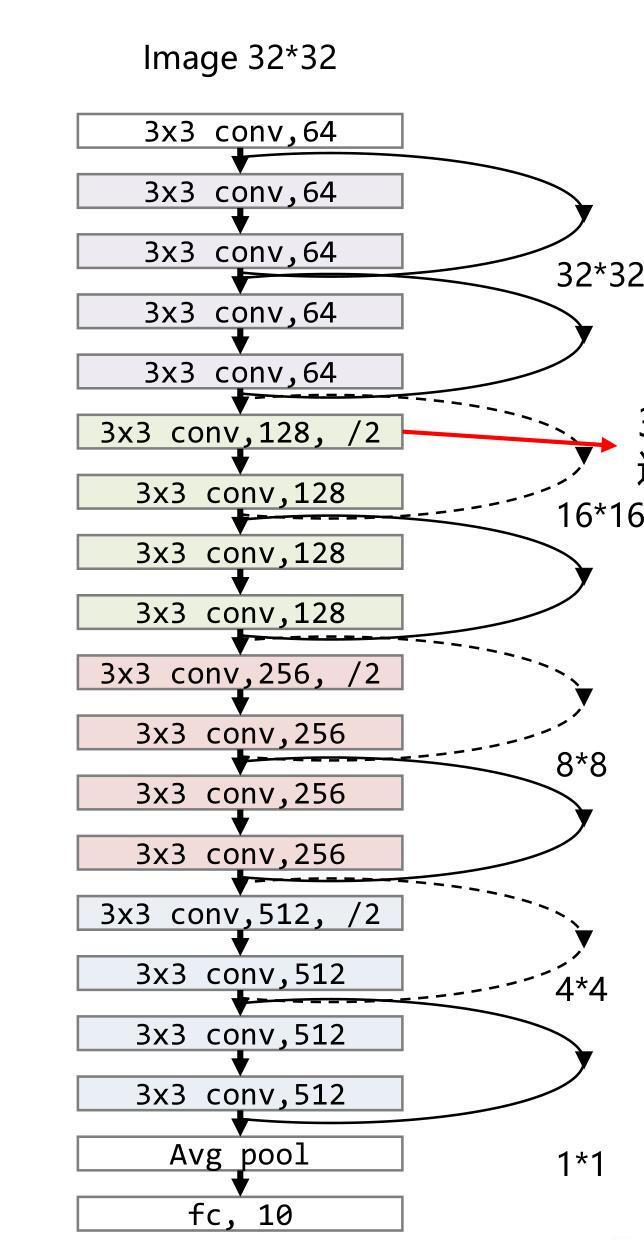
由于復現的殘差網路具有一定的子結構相似性,此處,我們進行了模塊化處理,首先,我們定義兩層卷積的殘差網路:
1. class Residual(nn.Module):
2. def __init__(self, input_channels,num_channels, use_1x1conv=False, strides=1, **kwargs):
3. super(Residual,self).__init__()
4. self.conv1 = nn.Conv2d(input_channels,num_channels, kernel_size=3, padding=1,stride=strides,dilation=2)
5. self.conv2 = nn.Conv2d(num_channels,num_channels, kernel_size=3, padding=1,dilation=5)
6. if use_1x1conv:
7. self.conv3 = nn.Conv2d(num_channels,num_channels, kernel_size=1,stride=strides)
8. else:
9. self.conv3 = None
10. self.bn1 = nn.BatchNorm2d(num_channels)
11. self.bn2 = nn.BatchNorm2d(num_channels)
12.
13. def forward(self, X):
14. Y = self.bn1(self.conv1(X))
15. Y = F.relu(Y)
16. Y = self.bn2(self.conv2(Y))
17. if self.conv3:
18. X = self.conv3(X)
19. return F.relu(Y + X)
20. return F.relu(Y)
之后,我們定義一層上采樣、一層卷積的殘差網路:
1. class UpsampleResidual(nn.Module):
2. def __init__(self, in_channel,out_channel, kernel_size=3,strides=1, **kwargs):
3. super(UpsampleResidual, self).__init__()
4. self.l1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel, kernel_size=kernel_size, stride=strides,padding=1)
5. self.l2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel, kernel_size=kernel_size,stride=1,padding=1)
6. self.shortcut = nn.Conv2d(in_channels=in_channel,out_channels=out_channel,kernel_size=1,stride=strides)
7. def forward(self,X):
8. Y = self.l1(X)
9. Y = F.relu(Y)
10. Y = self.l2(Y)
11. shortcut = self.shortcut(X)
12. return F.relu(Y+ shortcut)
最終,我們將以上兩個模塊進行多次復合,得到需要復現的網路:
class ResidualModule(nn.Module):
def __init__(self):
super(ResidualModule,self).__init__()
self.conv1 = nn.Conv2d(3,64,3)
self.conv2 = Residual(64,64,True)
self.conv3 = UpsampleResidual(64,128,3)
self.conv4 = Residual(128,128, True)
self.conv5 = UpsampleResidual(128,256,3)
self.conv6 = Residual(256,256, True)
self.conv7 = UpsampleResidual(256,512,3)
self.conv8 = Residual(512,512,True)
self.pool = torch.nn.AvgPool2d(kernel_size=3)
self.fc = nn.Linear(460800, num_classes)
self.process = nn.Sequential(self.conv1,self.conv2,self.conv3,
self.conv4,self.conv5,self.conv6,self.conv7,self.conv8)
def forward(self,X):
out = self.process(X)
out = out.view(out.size(0), -1) # flatten each instance
out = self.fc(out)
return out
實驗結果
二維卷積實驗
手動實作二維卷積
手動定義的卷積沒有進行矩陣優化,時間復雜度為
O
(
n
4
)
\mathcal{O}\left(n^4\right)
O(n4),對運算時間要求較高,經過手動驗證,反向傳播程序耗費時間過長,無法預計完成模型訓練的時間;因此,這里不能提供具體的手動實作的卷積的結果圖表,但是可以觀察到loss的計算程序,

使用torch實作二維卷積
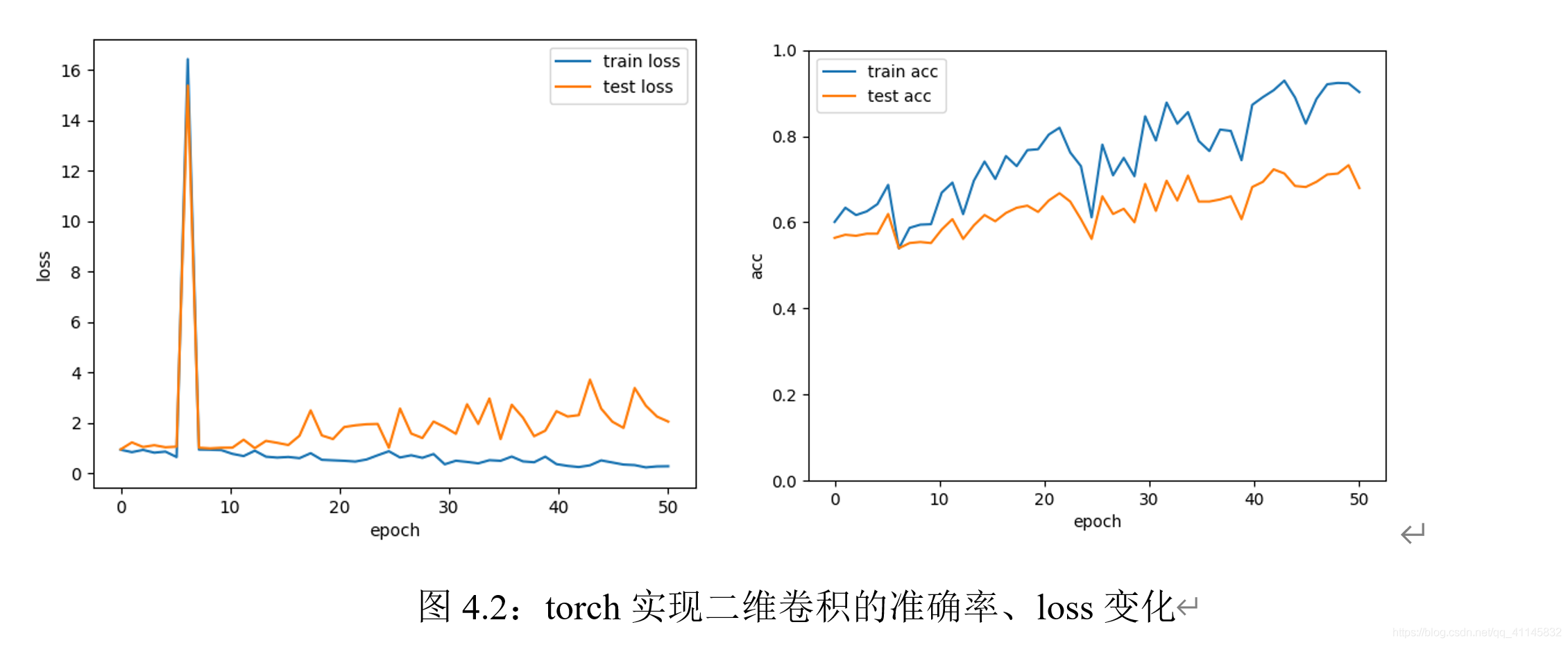
實驗迭代次數為50次時,在測驗集、訓練集上的loss和準確率變化如上圖所示,可以觀察到loss的震蕩變化和準確率的逐漸上升;但訓練集上的表現始終優于測驗集,說明模型存在一定的過擬合現象,在GPU環境下,訓練兩層卷積神經網路模型訓練50次epoch的時間為7分鐘左右,
對不同超引數的實驗結果對比分析
卷積核大小的影響
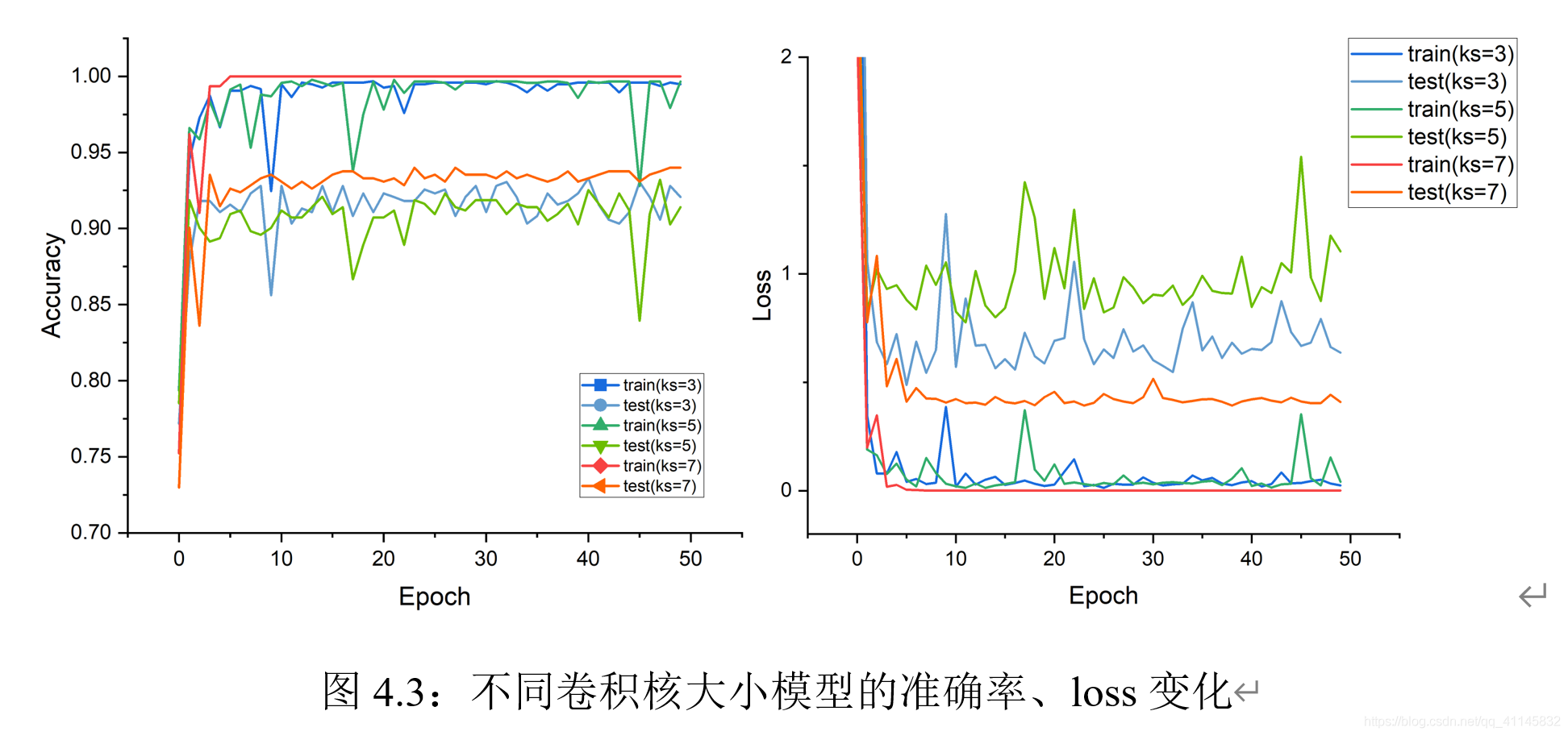
可以觀察到:尺寸相對較大的卷積核在訓練時收斂更快、總體震蕩較小,收斂時精度更高、loss更小,尺寸較小的卷積核在訓練程序種震蕩趨勢明顯,總體而言,不同尺寸卷積核的模型在此次訓練時都存在著過擬合的趨勢;可見,是否過擬合和卷積核大小無關,
卷積層數的影響
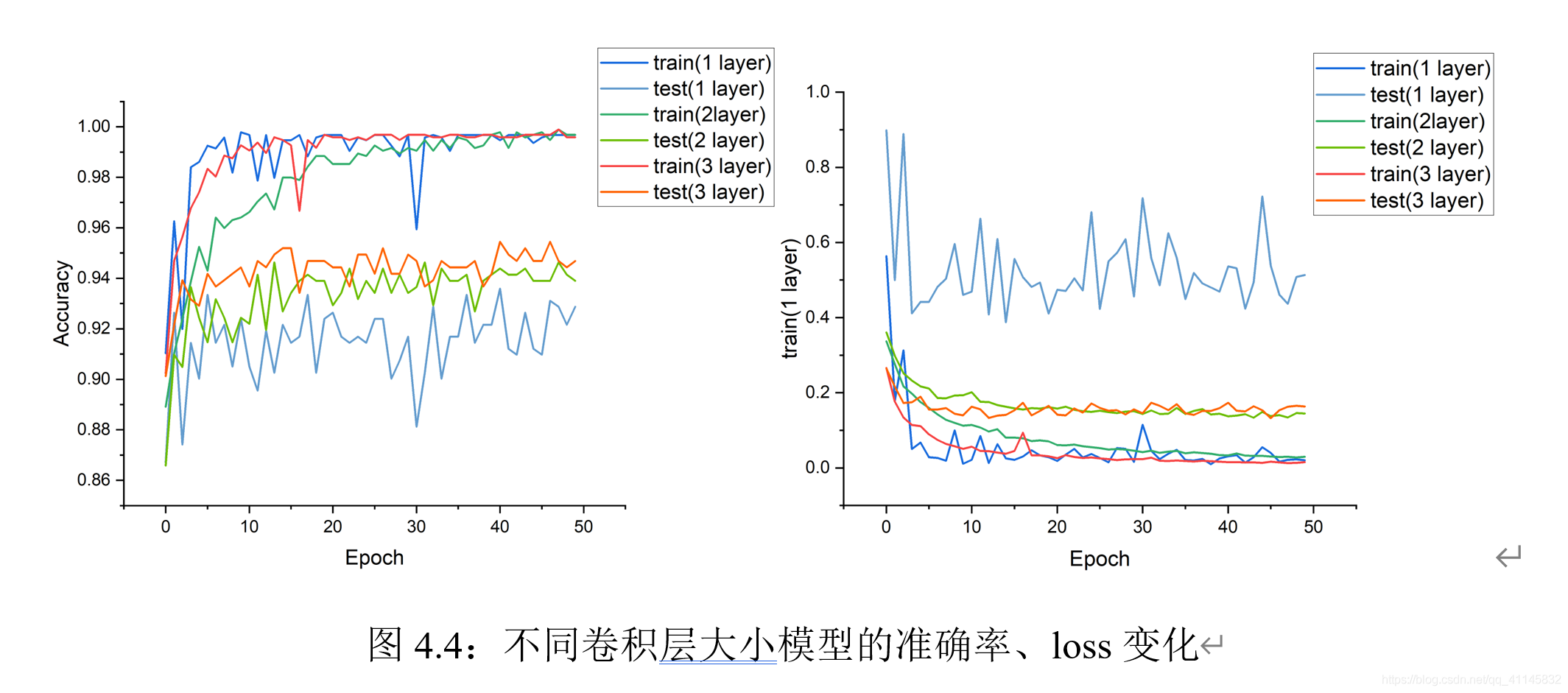
可以觀察到:隨著卷積層數的增加:在訓練階段,訓練集上的震蕩更小;在收斂階段,loss更低,在訓練集上的準確率更高,在測驗集上,三種網路的精確度表現近似,但卷積層數更多的網路相對收斂更快,
復現AlexNet模型
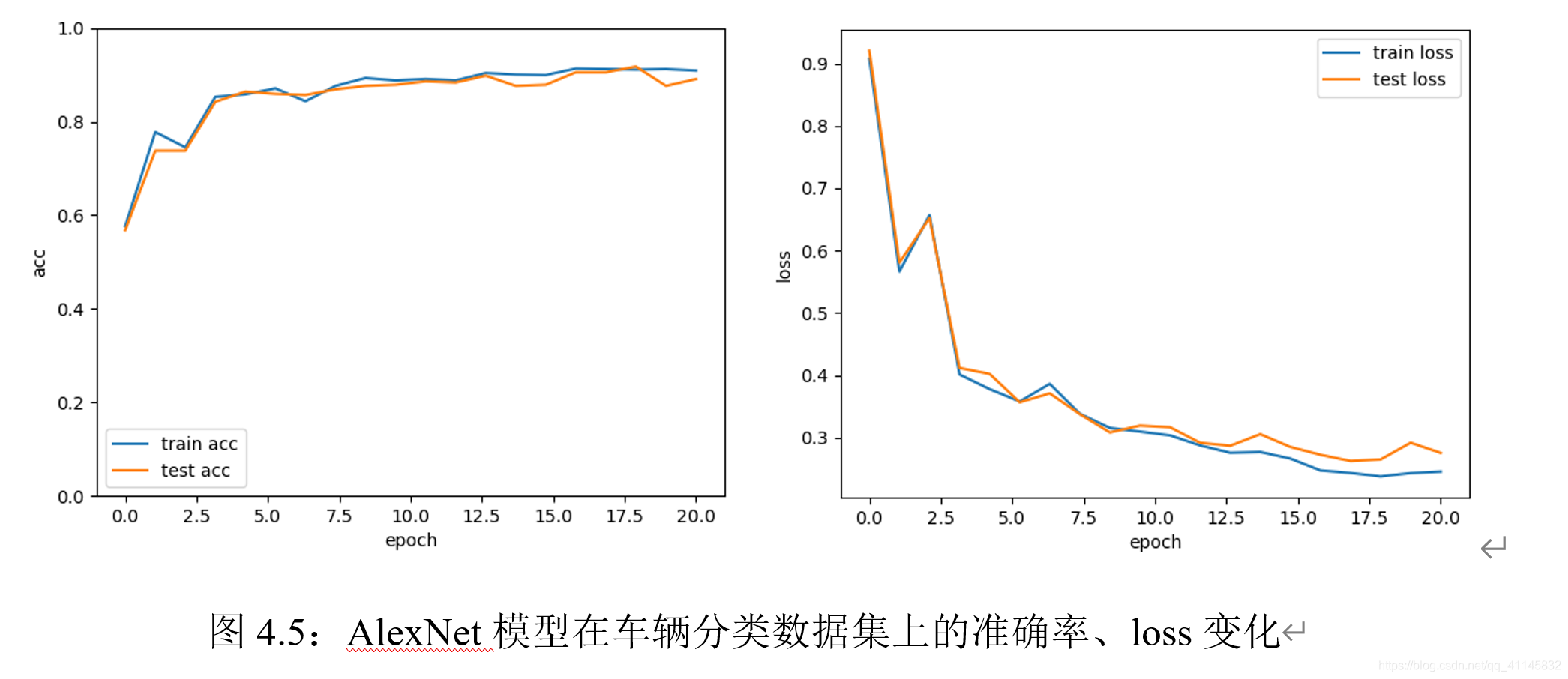
在AlexNet上迭代50次的結果如上,可以觀察到,隨著層數的加深,網路收斂所需的epoch數明顯增加,
與前饋神經網路的效果進行對比
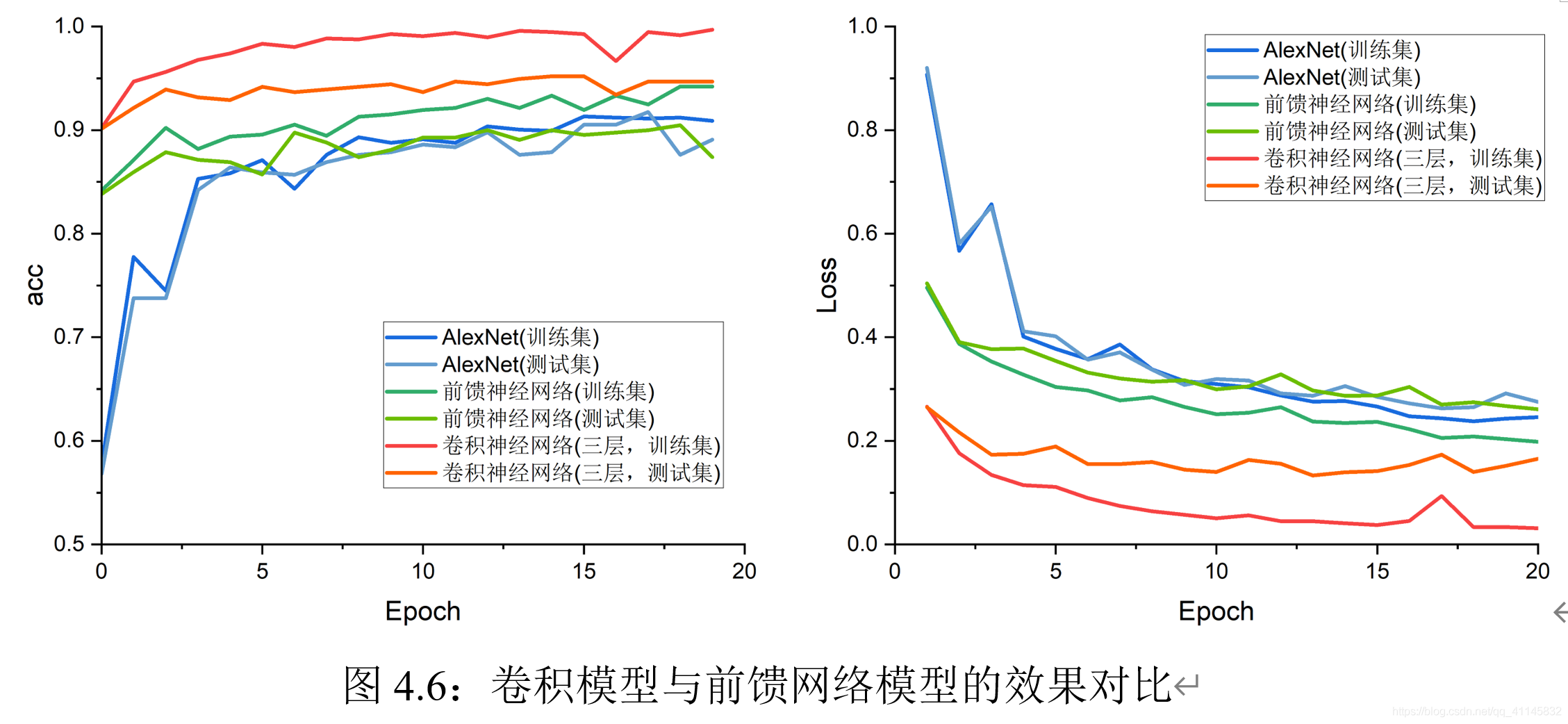
實驗結果表明,在本實驗所用的車輛分類資料集上,迭代20次時,前饋神經網路的效果適中,效果最優的是三層卷積神經網路,AlexNet在預測準確度的效果不佳,可能是原因是:(1)資料集過小,模型無法充分學習特征;(2)訓練次數不夠,模型沒有收斂,但值得注意的是,AlexNet在測驗集和訓練集上的表現都非常接近,說明沒有出現過擬合現象,
空洞卷積實驗
空洞卷積實驗結果
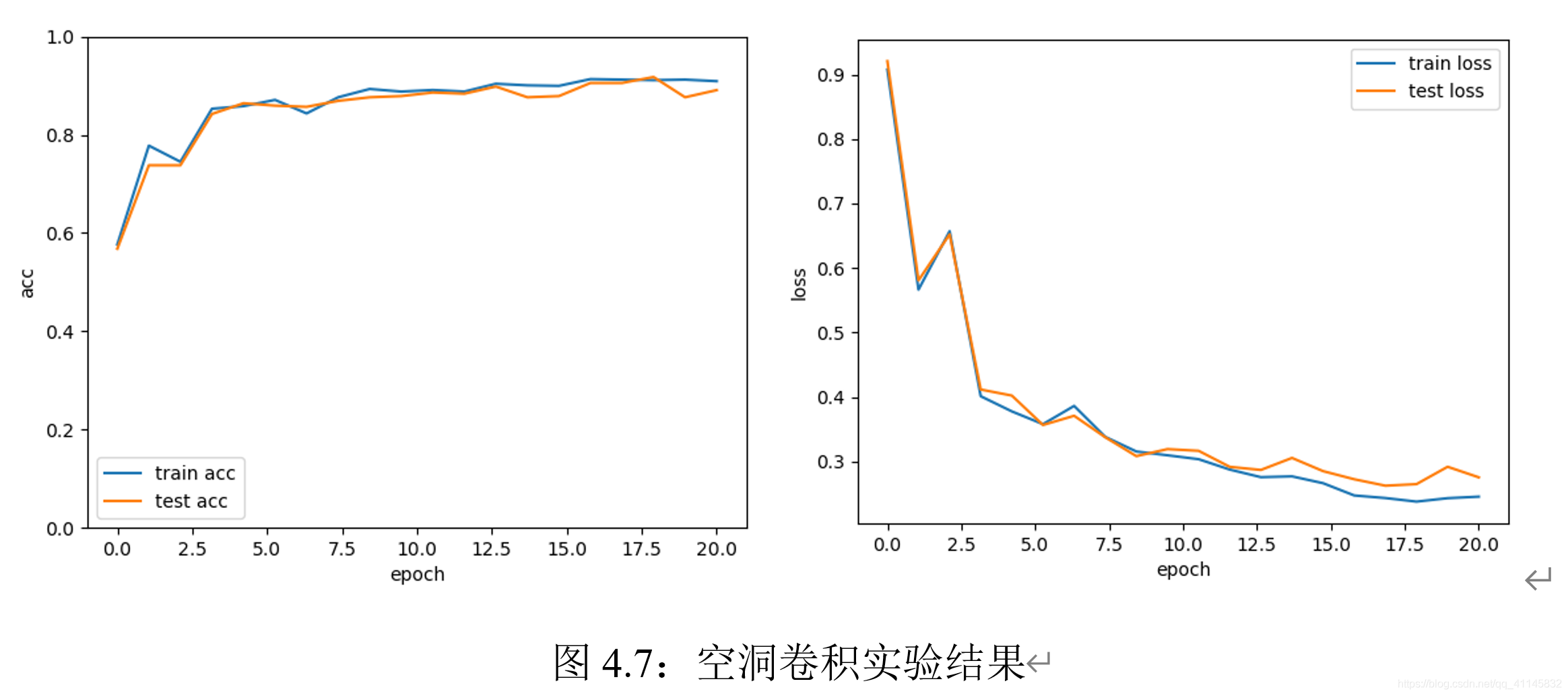
空洞卷積的實驗結果如上,可以觀察到:相比于振蕩現象明顯的普通卷積,空洞卷積模型沒有出現過擬合現象,可能是由于空洞卷積能很好地同時提取遠近距離特征,
空洞卷積與普通卷積的效果對比
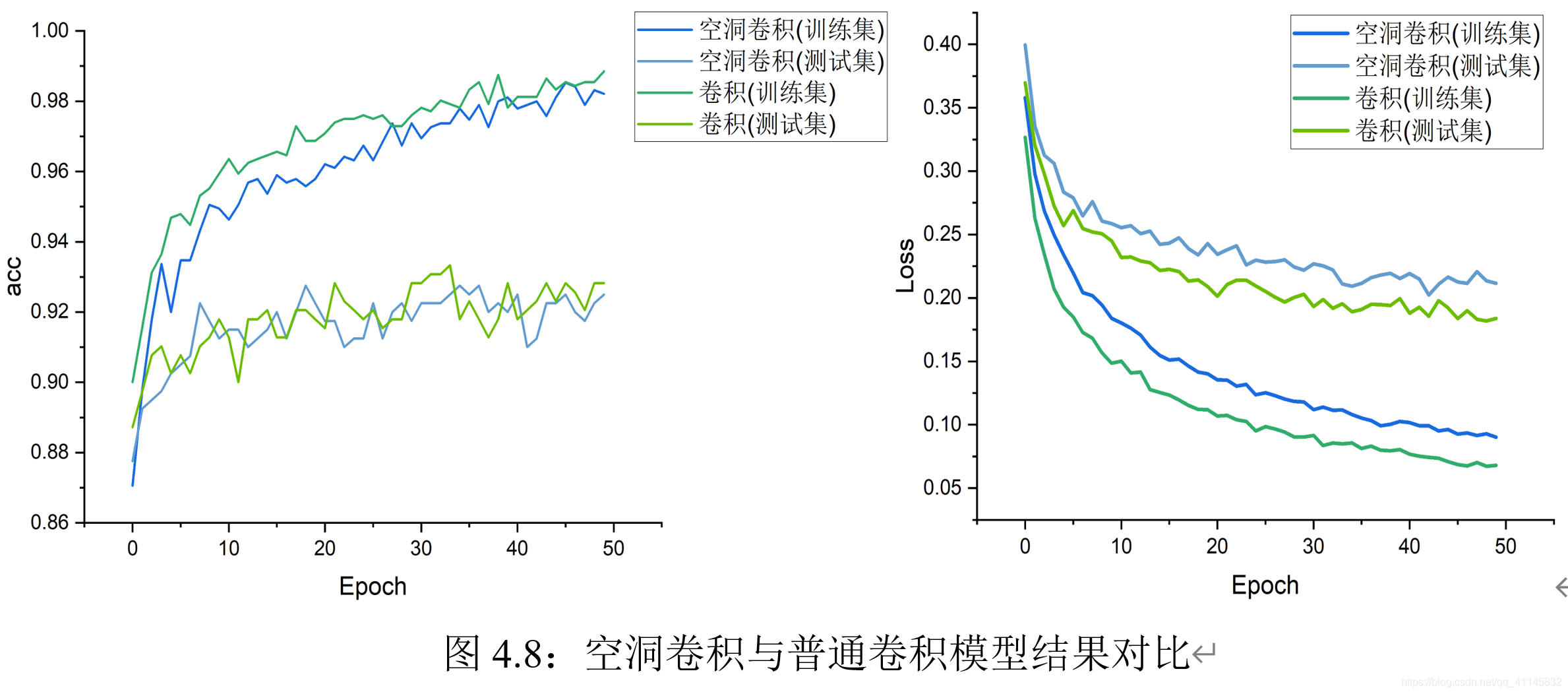
從影像可以看出:空洞卷積的準確度變化更平穩、在測驗集上的精度和普通卷積類似;在同樣訓練次數下,空洞卷積模型訓練集上的精度略低于普通卷積,可能原因是:空洞卷積提取了更多的層次特征,需要更多的迭代次數才能收斂,
空洞卷積模型相比于普通卷積在時間上略有增加,每次訓練平均實際在8分鐘左右;但空洞卷積在不同超引數設定下,運行時間變化較大,經過實驗驗證,可以發現主要耗時的模塊在于反向傳播部分,
超引數的對比
卷積核大小的影響
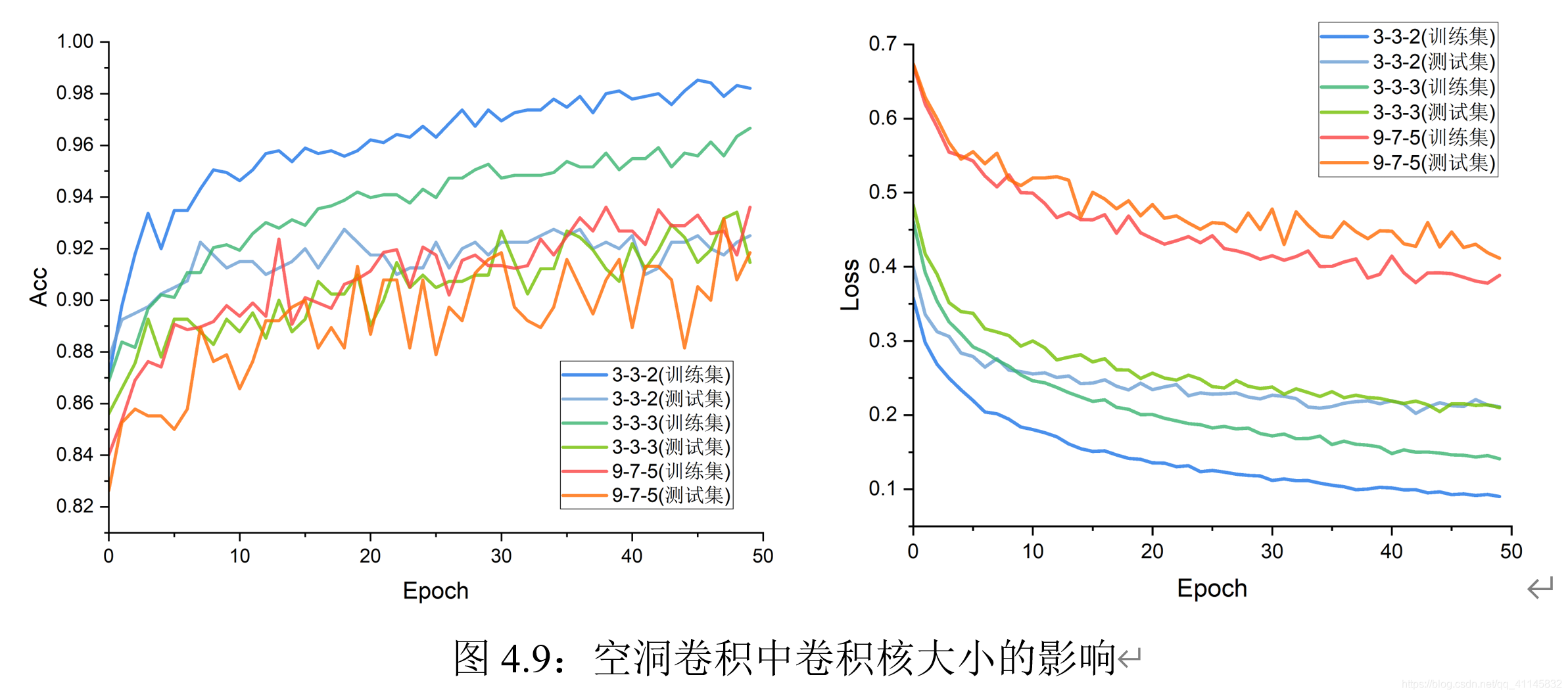
實驗結果表明:在空洞卷積模型訓練前期,卷積核大小分別設定為3、3、2時在測驗集上的表現較優、且變化趨勢較穩定;在訓練后期,模型逐漸收斂,卷積核大小對實驗結果的影響減少,可能原因是:卷積核的尺寸增加等價于模型引數量增加,所以在訓練前期可能會有更好的表達力,在空洞卷積中,尺寸大的卷積核并沒有表現出普通卷積中出現的巨大性能提升,
卷積層數的影響
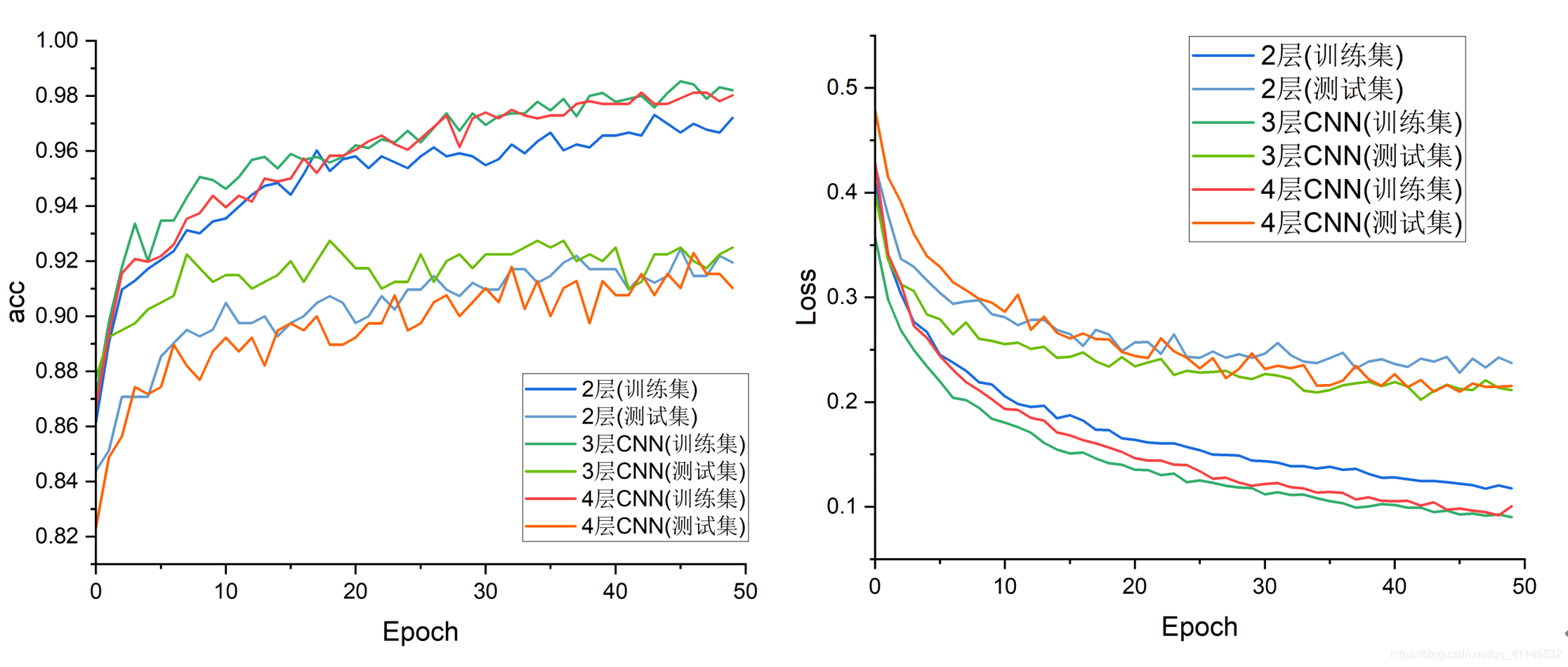
可以觀察到:在收斂階段,深層的網路在訓練集上準確度和loss上表現更好,但在測驗集上沒有突出的優勢,
殘差網路實驗
殘差網路實驗結果
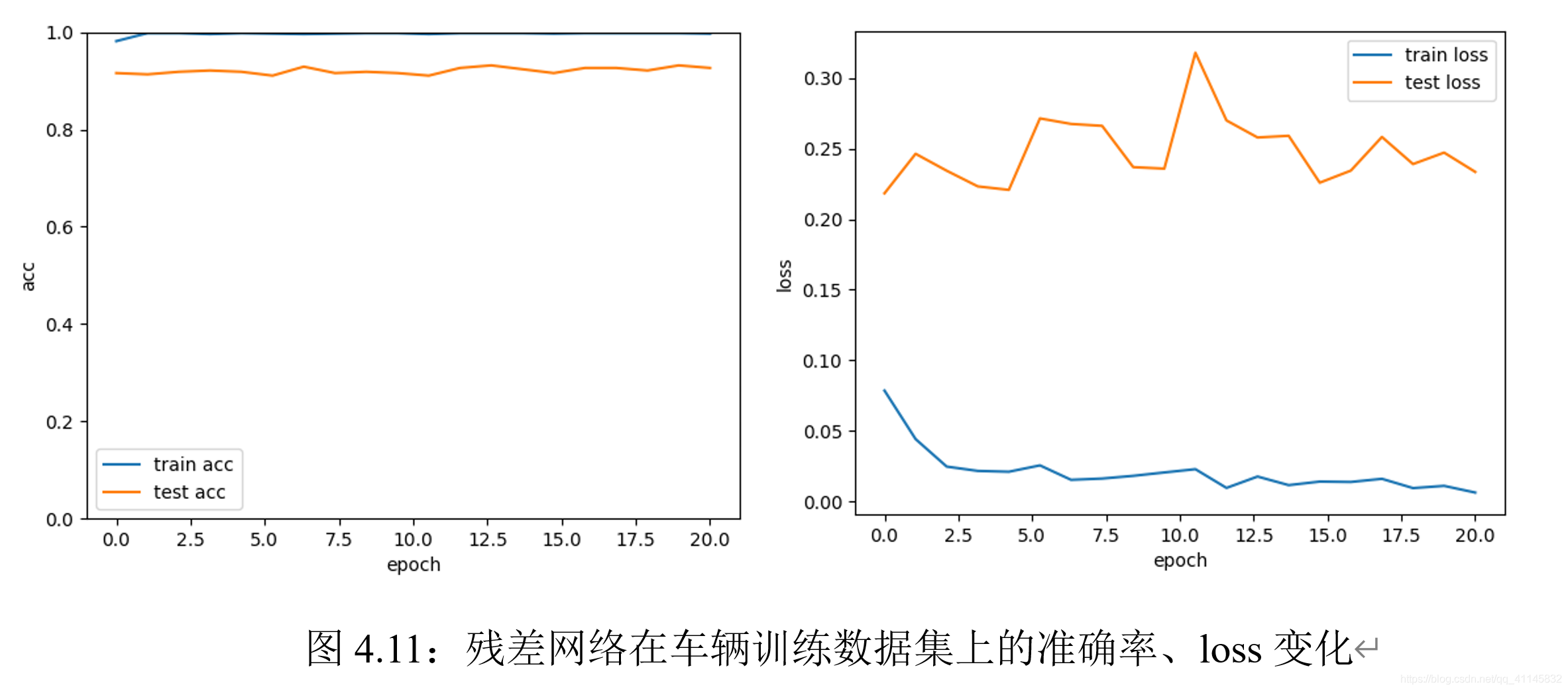
觀察實驗結果可知:殘差網路在訓練集上迭代20次即可達到接近99%的準確率;此外,模型收斂速度非常快,可見,轉化后的函式逼近問題更容易學習,
殘差空洞卷積實驗結果
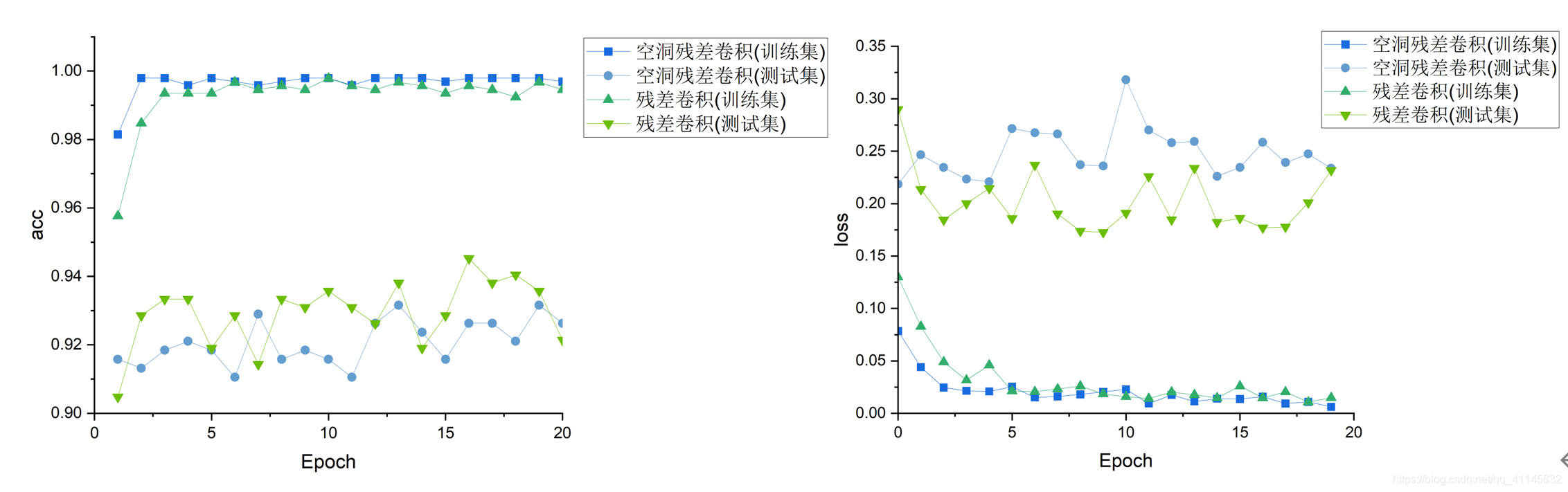
實驗結果顯示,在訓練集上,空洞殘差卷積具有更高的精度;在測驗集上,空洞殘差卷積和普通殘差卷積表現相似,兩者均具有較高的精度,
實驗心得體會
本次實驗遇到的最大的問題是計算效率的問題;此外,在實驗中,還有一些細節可以優化::
- 進入卷積神經網路部分后,定義的網路在CPU上的訓練時間已遠遠超出預期;因此,模型遷移到顯存、使用GPU進行訓練是必須的,在獲取服務器使用權限后、進行模型訓練后,我直觀地體會到GPU帶來的效率提升,
- 手動實作的卷積時間復雜度太高,目前仍然無法使用,本實驗主要使用torch的實作,沒有采用手動卷積,如果后續有可能對此部分進行優化,需要對矩陣乘法部分進行Image to Column的并行化處理,
- 資料集的生成,實驗中采用的是OpenCV框架進行讀取,但其實OpenCV的通道和RGB顏色的定義和torch中有較大的區別,因此,后續可以考慮使用其它的圖片讀取框架,
- 超引數的匯入,實驗中每一層的超引數(卷積層數、卷積核通道數等)是固定的,但這不方便對超引數進行網格搜索,后續可以針對此問題,設定層數的傳參,
參考文獻
[1] Pytorch手撕經典網路之AlexNet. https://zhuanlan.zhihu.com/p/29786939
[2] 邱錫鵬,神經網路與深度學習,機械工業出版社,https://nndl.github.io/ , 2020.
[3] Krizhevsky A, Sutskever I, Hinton G E. Wang P, Chen P, Yuan Y, et al. Understanding convolution for semantic segmentation[C]//2018 IEEE Winter Conference on Applications of Computer Vision (WACV). IEEE, 2018: 1451-1460.
[4] Zhang, Aston and Lipton, Zachary C. and Li, Mu and Smola, Alexander J. Dive into Deep Learning
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/295068.html
標籤:AI