引言
從2016年AalphGO橫空出世,驚艷眾人到現在2021世界魔幻,吳簽大碗牢飯已經4年多時間,這四年是機器學習,深度學習的AI智能演算法蓬勃興盛的4年,未來怎么樣,大佬們各有分說,作為普通人,還是好好踏踏實實抓住潮流提升自己,才是應對這魔幻世界的真道理,筆者今年研一,從本科搞前端到現在轉型搞智能,痛苦與快樂并行,今天這篇文章作為之后轉型開始的處女之作,感謝各位賞光垂閱拙作,
今天這篇文章以線性回歸為例,帶領讀者入門機器學習領域,機器學習是AI領域的一個子范疇,所有可以實作機器自學習的演算法都屬于這個領域,但是就目前發展來看,機器學習方法論有一套成熟的流程體系,也即是“學習”的含義,是機器模擬人類進行學習的程序,
機器學習是一門多領域交叉學科,涉及概率論、統計學、逼近論、凸分析、演算法復雜度理論等多門學科,專門研究計算機怎樣模擬或實作人類的學習行為,以獲取新的知識或技能,重新組織已有的知識結構使之不斷改善自身的性能, ———— 引自《百度百科》
區分有監督和無監督任務
機器學習將學習任務中的資料是否經過了人工標注作為有監督或無監督的標準,舉個例子,如果我們想根據一個人的身高體重來判斷這個人是屬于瘦還是胖,那么我們人類先得告訴機器什么樣的身高體重屬于瘦或者胖,這顯然屬于有監督的任務;如果我們想根據一個班級中學生的性格指標給學生分成幾組,那么顯然我們人類并不會直接告訴機器應該怎么分組,而是讓機器通過演算法自己建立一個分組,這屬于無監督任務,一般來說,有監督學習的應用場景是要遠大于無監督的應用場景的,
區分回歸問題與分類問題
在機器學習領域,幾乎所有的有監督問題都被劃分為了回歸和分類問題,所以,在進入機器學習領域中的第一件事情是要學會區分要解決的問題是分類還是回歸,從通俗意義上講,分類是識別誰是誰的問題,而回歸是預測誰有多少的問題,比如,對于一張貓或狗的照片,要分辨到底是貓還是狗,這屬于分類問題;對于根據幾個月的銷售情況預測下一個月的銷售額,這屬于回歸問題,但是有些時候,一個實際問題的定義沒有那么明顯的分類或預測含義,這個時候就需要看資料的Label是連續的,還是離散的,如果是連續的就是回歸問題,離散的就是分類問題,
線性回歸問題
了解了一些機器學習中的基本概念,我們來看看什么是線性回歸問題,形如:
y
=
θ
0
+
∑
i
=
1
n
θ
i
x
i
g
i
v
e
n
y
,
x
i
(
i
=
1
,
2
,
.
.
.
,
n
)
s
o
l
v
e
θ
j
(
j
=
0
,
1
,
2
,
.
.
.
,
n
)
y = \theta_0 + \sum_{i=1}^{n}\theta_ix_i \newline given\ \ y,x_i(i=1,2,...,n) \newline solve\ \ \theta_j(j=0,1,2,...,n)
y=θ0?+i=1∑n?θi?xi?given y,xi?(i=1,2,...,n)solve θj?(j=0,1,2,...,n)
這類均屬于線性回歸問題,之所以稱之為線性,是因為
y
y
y是
x
x
x的線性組合,考慮一下線性回歸問題屬于有監督還是無監督?顯然屬于有監督,因為不僅有
x
x
x,還有
y
y
y,我們告訴了模型應該具有怎么樣的輸入和輸出,讓模型通過學習得到一組
θ
\theta
θ,使得滿足這樣的輸入輸出,舉個例子,比如對于全國的商品房樣本我們知道其三個維度的資訊:所在城市(
x
1
x_1
x1?),所在區域的人口密度(
x
2
x_2
x2?),所在區域的中小學數目(
x
3
x_3
x3?),以及這個商品房的價格(
y
y
y),請你用線性回歸建模問題并求解模型引數,
從傳統演算法到基于統計的機器學習演算法
當你考慮解決上述線性回歸問題時,你會發現我們很難從已有的傳統演算法思想(例如,分治,動態規劃,貪心等)中找到一個適合解決這個問題的思想,因為往往來說,傳統演算法思想適用于找精確解,但是這個問題的精確解很難求出來,就比如房價的預測涉及到方方面面的因素,因素的作用有大有小,即便是經驗老道的內行去預測也會有所偏差,所以在機器學習領域,我們找到的解往往是近似解,求解近似解的方法,也可以使用基于一定啟發式規則的演算法求解,但是當資料量巨大時,這種方法的效果就有些捉襟見肘,這也就是近年來機器學習與深度學習蓬勃發展的原因,資料流量激增的時代,從資料中挖掘潛在價值是這些AI演算法的使命,
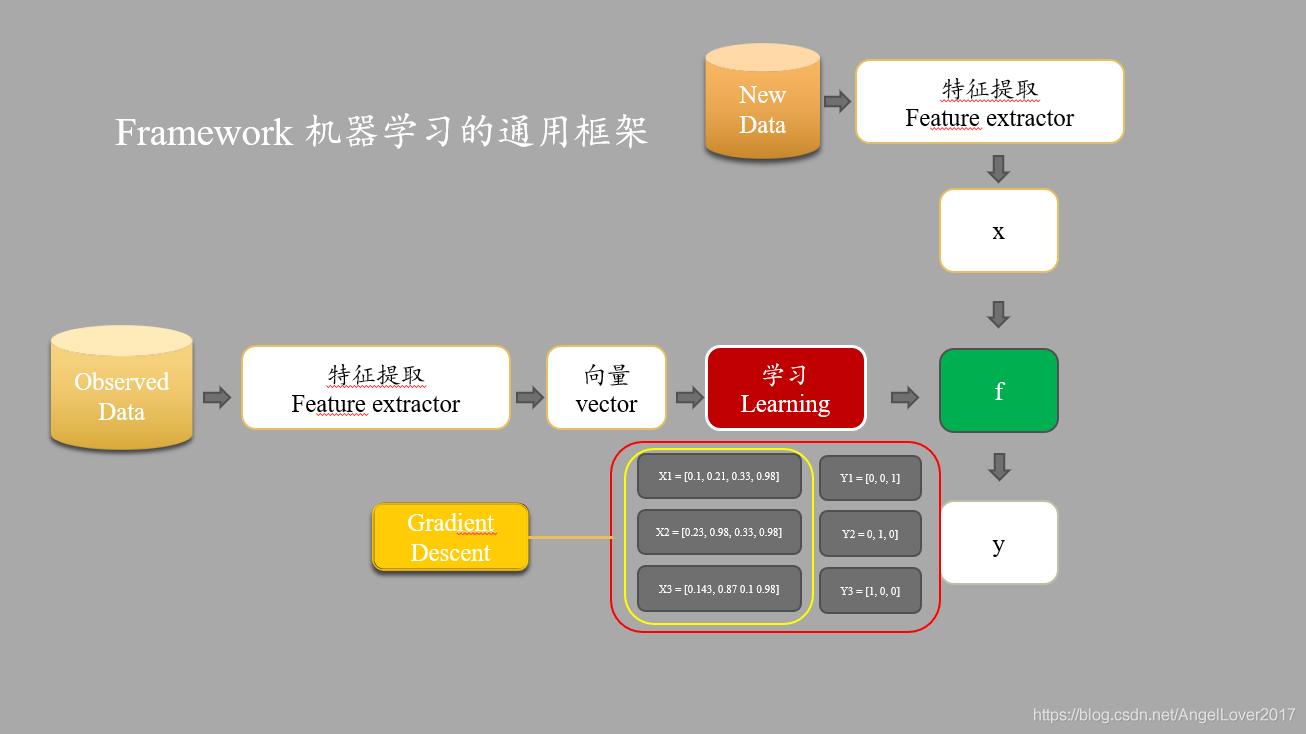
機器學習的通用框架可以簡單理解為四個部分:特征提取,向量化表征,訓練學習,梯度下降,
- 特征提取:從一堆因素中提取出對模型影響更大的一些特征,例如,房價預測中影響房價的因素很多,但是并不是所有的因素都是有用的,可能存在噪聲因素,我們必須在模型學習前剔除這些因素,
- 向量化表征:我們收集來的資料很大程度上不完全是數值型別的,很多可能是字串表示,基于統計的機器學習演算法,只認識數值,因此我們需要用數值表征特征,一個特征的一組數值就是一個向量,
- 訓練學習:訓練學習是將資料不斷送入模型,模型經過多輪學習,不斷調整引數( θ \theta θ)的程序,
- 梯度下降:嚴格意義上講,梯度下降屬于訓練學習范疇,是訓練學習不斷迭代的核心所在,如果讀者學習過凸優化理論,可能會知道,這是求解優化問題的最簡單的迭代方法,
實戰部分
我們接下來將以一個簡單的線性回歸例子,來講述一個完整的機器學習程序,
資料生成
現在,假設我們有一組(
x
,
y
x,y
x,y)資料,要使用線性回歸來建模并求解,我們先來為接下來的例子生成一點資料,我們按照如下公式進行資料生成:
y
=
5
x
+
100
+
θ
r
a
n
d
o
m
x
=
0
,
1
,
.
.
.
,
99
θ
r
a
n
d
o
m
∈
{
θ
∣
?
100
≤
θ
≤
100
}
y = 5x+100+\theta_{random} \newline x = 0,1,...,99 \newline \theta_{random}\in\{\theta|-100\leq\theta\leq100\}
y=5x+100+θrandom?x=0,1,...,99θrandom?∈{θ∣?100≤θ≤100}
import random
import numpy as np
import matplotlib.pyplot as plt
def gf(a,b):
def f_(x):
return a*x + b
return f_
def generate_data(count,f_args=(3,4)):
x = np.arange(count)
f = gf(*f_args)
y = f(x) + np.array([random.randint(-100,100) for i in range(count)])
return (y,x)
y,x = generate_data(100,(5,100))
plt.scatter(x,y)
繪制出來的散點圖如下所示:
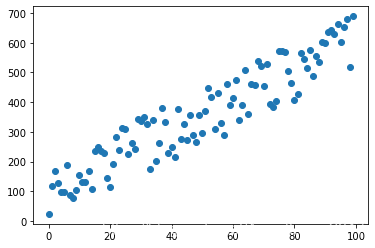
在這個例子中,我們忽略了特征提取和向量化,因為我們生成的資料直接就是可以輸送給模型的向量(
x
?
,
y
?
\vec{x},\vec{y}
x
,y
?),
建模與求解思路
線性模型
很顯然,在這個例子中,我們期望的模型就是
y
=
5
x
+
100
y=5x+100
y=5x+100,但是我們希望機器可能自己學習得到,因此首先建立一個線性模型:
h
θ
(
x
)
=
θ
0
+
θ
1
x
h_\theta(x) = \theta_0 + \theta_1x \newline
hθ?(x)=θ0?+θ1?x
損失函式
有了模型,我們還需要一個評價模型好壞的指標,怎么知道模型能夠很好的擬合上面這些點的分布呢?在回歸問題中,我們常用的最為簡單的評價指標就是MSE(均方誤差函式):
J
(
θ
0
,
θ
1
)
=
1
2
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
?
y
(
i
)
)
2
J(\theta_0,\theta_1) = \frac{1}{2m}\sum_{i=1}^{m}(h_\theta(x^{(i)})-y^{(i)})^2
J(θ0?,θ1?)=2m1?i=1∑m?(hθ?(x(i))?y(i))2
這里之所以是
1
2
m
\frac{1}{2m}
2m1?,而不是
1
m
\frac{1}{m}
m1?的原因是,為了修正MSE求導后的多出來的系數
2
2
2,這里的評價指標函數也常常被稱之為Loss函式,或者Cost函式,事實上,這個指標衡量了真實值(
y
y
y)與模型給出的預測值(
h
θ
(
x
)
h_\theta(x)
hθ?(x))直接的平均誤差,很容易理解,我們希望這個誤差越小越好,因為越小就表示我們的模型更能貼近真實的資料,
def MSE_Loss(x,y,fn):
m = len(x)
y_hat = fn(x)
loss = (1/(2*m)) * (np.sum((y_hat-y)**2))
return loss
梯度下降
所以,我們很容易利用凸優化理論,將這個問題轉換為一個優化問題,
θ
?
=
a
r
g
m
i
n
θ
J
(
θ
)
,
θ
=
[
θ
0
,
θ
1
]
T
\theta^* = arg\ \mathop{min}\limits_{\theta} J(\theta) , \theta = [\theta_0,\theta_1]^T
θ?=arg θmin?J(θ),θ=[θ0?,θ1?]T
求解這個優化問題,可以使用梯度下降方法,梯度下降公式如下:
θ
n
=
θ
n
?
1
?
α
?
J
(
θ
n
?
1
)
?
θ
n
?
1
\theta^{n} = \theta^{n-1} - \alpha\frac{\partial J(\theta^{n-1})}{\partial\theta^{n-1}}
θn=θn?1?α?θn?1?J(θn?1)?
我們可以簡單理解一下梯度下降的真實含義,
α
\alpha
α代表就是learning rate(學習率),常設為0.1~0.001之間的常數,
θ
n
\theta^{n}
θn和
θ
n
?
1
\theta^{n-1}
θn?1分別代表本次迭代得到的新的引數向量和上次迭代的引數向量,最關鍵的是梯度(
?
J
(
θ
n
?
1
)
?
θ
n
?
1
\frac{\partial J(\theta^{n-1})}{\partial\theta^{n-1}}
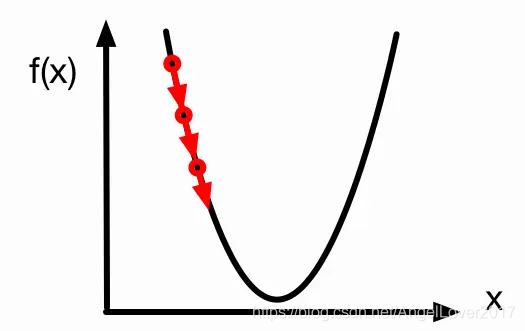
?θn?1?J(θn?1)?)的含義,不嚴格的說,我們可以把梯度理解為導數,例如二次函式
f
(
x
)
f(x)
f(x)的最低點是我們想要到達的目的地,此刻我在最低點的左邊函式曲線上,我想要往最低點走,就要向著導數的負方向走才是正確的方向,反應到數值上就是我下一次更新的引數應該增大,而不是減小,那么增大多少呢?顯然是
α
\alpha
α乘以導數,這么大,你理解了嗎?
最后需要注意的地方是,在最開始,機器顯然并不知道正確的引數(
θ
0
,
θ
1
\theta_0,\theta_1
θ0?,θ1?)是多少,因此第一次我們可以隨機初始化一個
θ
0
\theta_0
θ0?和
θ
1
\theta_1
θ1?,之后就按照梯度下降對引數進行更新即可,
def gradient_descent(arg,lr,grad):
return arg - lr * grad
求導程序
?
J
(
θ
n
?
1
)
?
θ
n
?
1
\frac{\partial J(\theta^{n-1})}{\partial\theta^{n-1}}
?θn?1?J(θn?1)? 具體怎么求解呢?因為機器自己不會求導,因此這部分還需要我們自己手動去推導,并轉換成代碼,這里我們使用鏈式求導法則,先對
h
h
h求偏導,在對
θ
\theta
θ求偏導,
?
J
(
θ
0
,
θ
1
)
?
θ
0
=
?
J
?
h
?
h
?
θ
0
=
1
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
?
y
(
i
)
)
?
J
(
θ
0
,
θ
1
)
?
θ
1
=
?
J
?
h
?
h
?
θ
1
=
1
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
?
y
(
i
)
)
x
(
i
)
\frac{\partial J(\theta_0,\theta_1)}{\partial\theta_0} = \frac{\partial J}{\partial h}\frac{\partial h}{\partial\theta_0} = \frac{1}{m}\sum_{i=1}^{m}(h_\theta(x^{(i)})-y^{(i)})\newline \frac{\partial J(\theta_0,\theta_1)}{\partial\theta_1} =\frac{\partial J}{\partial h}\frac{\partial h}{\partial\theta_1} =\frac{1}{m}\sum_{i=1}^{m}(h_\theta(x^{(i)})-y^{(i)})x^{(i)} \newline
?θ0??J(θ0?,θ1?)?=?h?J??θ0??h?=m1?i=1∑m?(hθ?(x(i))?y(i))?θ1??J(θ0?,θ1?)?=?h?J??θ1??h?=m1?i=1∑m?(hθ?(x(i))?y(i))x(i)
def mse_linear_gradient(x,y,fn):
m = len(x)
y_hat = fn(x)
a_grad,b_grad = (1/m) * np.sum((y_hat-y)*x) , (1/m) * np.sum((y_hat-y))
return (a_grad,b_grad)
模型撰寫
有了上面的思路和基礎,就萬事俱備,只欠東風了,我們只需要把梯度下降迭代的程序用代碼表達出來就可以了,為了使得介面更通用,可以設定兩個超引數max_iter和lr,分別表示最大迭代次數和學習率,
class linear_model:
def __init__(self,max_iter=100,lr=0.01):
self.max_iter = max_iter
self.lr = lr
def fit(self,data):
x,y = data
# 初始再一定范圍內隨機 a,b
a,b = [random.randint(-1,1) for i in range(2)]
f = gf(a,b)
# 使用梯度下降優化 + MSE_Loss 迭代求解線性模型的引數
for i in range(self.max_iter):
# 計算Loss
loss = MSE_Loss(x,y,f)
print("loss",loss)
# 計算梯度
a_grad,b_grad = gradient(x,y,f)
# 梯度下降,更新引數
a = gradient_descent(a,self.lr,a_grad)
b = gradient_descent(b,self.lr,b_grad)
print(a,b)
# 更新模型
f = gf(a,b)
return f
模型訓練與驗證
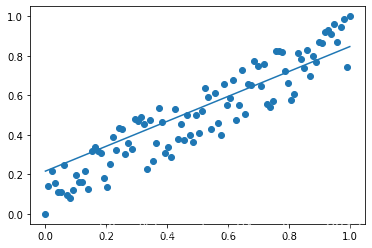
可以看到,經過300次的迭代,最終得到了一潭訓算不錯的函式,大致反應了資料點的分布趨勢情況,細心的讀者可能會發現這張圖中
x
,
y
x,y
x,y的數值范圍被放縮到了
[
0
,
1
]
[0,1]
[0,1]之間,對應的操作就是minmax_normalize,這就是機器學習中常用到的歸一化操作,這步操作的目的有很多,例如,歸一化可以使得梯度朝著最優解方向,進而加快尋優速度;歸一化還可以將不同量綱的資料放縮到同一量綱內,使得各個特征權重分布合理;歸一化還有一個優點,就是防止梯度爆炸和梯度消失,這也是這個例子中不得不進行歸一化的原因,我將在下一節詳細闡述這個事情,到目前為止,我們用一個線性回歸的簡單例子,講述了機器學習的通用的框架步驟,不知道你明白了嗎?
# Normalization
def minmax_normalize(x):
return (x-np.min(x))/(np.max(x)-np.min(x))
model = linear_model(max_iter=300)
# 資料歸一化 MinMax
x,y = minmax_normalize(x),minmax_normalize(y)
f = model.fit((x,y))
plt.scatter(x,y)
plt.plot(x,f(x))
plt.show()
未歸一化導致的梯度爆炸
如果你嘗試將這個例子中歸一化操作去掉,并把max_iter改為100,就像這樣,
model = linear_model(max_iter=100)
f = model.fit((x,y))
plt.scatter(x,y)
plt.plot(x,f(x))
plt.show()
那我們會得到一個匪夷所思的結果,
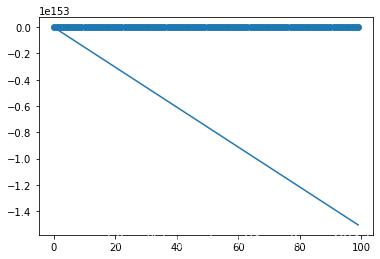
查看中間的loss輸出以及
a
,
b
a,b
a,b的更新,我們會發現loss不減反增,甚至增大到了
3.7
e
+
302
3.7e+302
3.7e+302這樣的數量級,
a
,
b
a,b
a,b也是同樣情況,如果我們繼續增大max_iter到300,我們會發現loss的輸出中多了很多inf和nan,inf是python中的無窮大的表示方法,也即梯度增大到了無窮大,nan表示 Not A Number,產生nan的情況有很多,比如
i
n
f
/
i
n
f
,
i
n
f
?
i
n
f
inf/inf,inf-inf
inf/inf,inf?inf等都會產生nan值,因此綜合來看,我們的模型發生了梯度爆炸,也即梯度在計算的程序中大的離譜,
我們來看看,梯度爆炸是如何產生的,下面是未經歸一化的資料在訓練程序中的一組值,
y
_
h
y\_h
y_h 表示模型當前預測值,
y
y
y表示原始資料中的值,經過一次梯度的計算,我們發現梯度的數量級已經到了千萬量級,這樣大的梯度會導致引數的更新也發生極大的改變,進一步導致
y
_
h
y\_h
y_h中的值范圍變得更大,這樣下一次計算梯度會更大,依次惡行迭代,導致Loss的值越來越大,梯度也越來越大,最終大到無窮大或無窮小,無法繼續計算,便會得到nan值,
y_h = np.array([-76,-166,-256,-346,-436,-526,-616,-706,-796,-886,-976 ,-1066
,-1156 ,-1246 ,-1336 ,-1426 ,-1516 ,-1606 ,-1696 ,-1786 ,-1876 ,-1966 ,-2056 ,-2146
,-2236 ,-2326 ,-2416 ,-2506 ,-2596 ,-2686 ,-2776 ,-2866 ,-2956 ,-3046 ,-3136 ,-3226
,-3316 ,-3406 ,-3496 ,-3586 ,-3676 ,-3766 ,-3856 ,-3946 ,-4036 ,-4126 ,-4216 ,-4306
,-4396 ,-4486 ,-4576 ,-4666 ,-4756 ,-4846 ,-4936 ,-5026 ,-5116 ,-5206 ,-5296 ,-5386
,-5476 ,-5566 ,-5656 ,-5746 ,-5836 ,-5926 ,-6016 ,-6106 ,-6196 ,-6286 ,-6376 ,-6466
,-6556 ,-6646 ,-6736 ,-6826 ,-6916 ,-7006 ,-7096 ,-7186 ,-7276 ,-7366 ,-7456 ,-7546
,-7636 ,-7726 ,-7816 ,-7906 ,-7996 ,-8086 ,-8176 ,-8266 ,-8356 ,-8446 ,-8536 ,-8626
,-8716 ,-8806 ,-8896 ,-8986])
y = np.array([145 ,129 ,78 ,107 ,48 ,178 ,55 ,151 ,229 ,169 ,145 ,81 ,231 ,210 ,128 ,88 ,242 ,259
,95 ,217 ,188 ,280 ,131 ,157 ,182 ,302 ,174 ,262 ,251 ,210 ,342 ,248 ,246 ,337 ,318 ,261
,335 ,360 ,212 ,244 ,316 ,263 ,229 ,378 ,324 ,344 ,417 ,306 ,353 ,378 ,346 ,257 ,354 ,393
,321 ,431 ,382 ,436 ,458 ,295 ,426 ,479 ,462 ,458 ,484 ,497 ,495 ,489 ,437 ,484 ,484 ,537
,469 ,389 ,438 ,393 ,471 ,432 ,550 ,504 ,582 ,496 ,555 ,539 ,607 ,523 ,431 ,632 ,548 ,537
,585 ,586 ,584 ,624 ,610 ,477 ,534 ,587 ,527 ,501])
np.sum((y_h-y)*x)
# output : -32103025
最后劃個重點: 如果訓練程序中遇到梯度或Loss值大的離譜,甚至出現inf或nan值時,就可以考慮應該是發生梯度爆炸了,歸一化只是解決梯度爆炸的策略之一,還有其他方法,讀者可以自行查閱,
感謝讀完整篇文章,如有不對的地方,望評論指出,如果覺得有所識訓,給我來個三連吧!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/295076.html
標籤:AI