最近剛剛完成了服務器流量收集這一塊兒的代碼,就順便整理一下思路什么的吧,
首先就是流量包的抓取和決議,因為我們使用的是python語言,而python中的關于資料包抓取的模塊是scapy,而不是scrapy,這個是爬蟲里面需要用到的模塊,當然,不僅僅是scapy,還有檔案夾操作的os模塊和實行多執行緒的threading模塊,
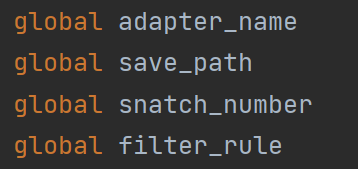
首先就是對網卡/網路配接器,過濾規則(我們這里采用的是BPF規則去對協議進行過濾),抓包數量以及保存路徑的定義,將其設為全域變數:
接著就是對資料包的操作,先創建或者說是查找資料包保存路徑,利用os模塊和其中的mkdir函式去進行操作,
然后便是利用scapy模塊中的sniff(嗅探/流量監控)函式去進行資料包的抓取,sniff函式的一些引數如下:

因為我們要用到的是多執行緒的抓取,所以需要用到threading模塊,而threading模塊兒的具體詳解我也不詳細闡述了在這里面,附加一個鏈接,在CSDN中也算是高閱讀量的解釋吧:Python多執行緒編程(一):threading 模塊 Thread 類的用法詳解
并且要記得定義一個全域變數表示我們已經抓取的資料包的數量,
而且,因為我們要在命令列中也能使用,便要呼叫命令列決議器argparse模塊,它是python自帶的一個命令列決議包,而其效果如下:
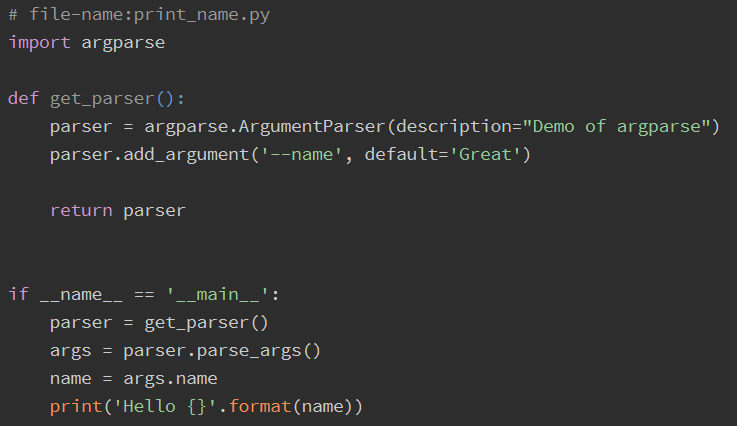

命令列決議器的使用方法我是參考知乎上的一篇文章:argparse模塊用法實體詳解,大家不會的也可以去看看,因為我覺得我自己講的話可能效果甚微,
最后,便是抓取資料包之后的保存,利用os模塊去創建或者查找檔案夾,然后利用wrpcap函式將每個資料包保存為pcap檔案,

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/295091.html
標籤:其他
上一篇:系統安全及應用 --系統引導、登錄控制、弱口令檢測、埠掃描
下一篇:ctfshow-WEB-web3